はじめに
こんにちは!2025年入社で流通サービス事業部の鈴木風真です。
データ分析基盤(データレイク)の構築を行う中で、現代の企業のデータ分析基盤はどうあるべきか、 Amazon S3 Tables を通して、モダンなデータ分析基盤のベストプラクティスを活用事例とともに紹介いたします。
データ分析基盤のベストプラクティスとは
多くの企業は、日々の業務を遂行するための基幹システムとは別に、蓄積された売上や発注データを分析し、経営判断に活かすためのデータ分析基盤である「情報系システム(情報基盤)」を構築しています。近年では、そんな情報系システムのあるべき姿として、以下の点が語られます。
基幹システムと情報系システムの「疎結合」
本来、情報系システムは「新たな分析軸を追加したい」といったビジネス側の要求に対し、素早く対応できる必要があります。しかし、絶対に止めることが許されない基幹システムと密結合してしまっていると、改修のたびに厳密な影響調査が必要となり、身動きが取れなくなってしまいます。そのため、両者の間に中立なデータ保管層(データレイク)を挟み、切り離された疎結合なアーキテクチャであることが理想とされています。
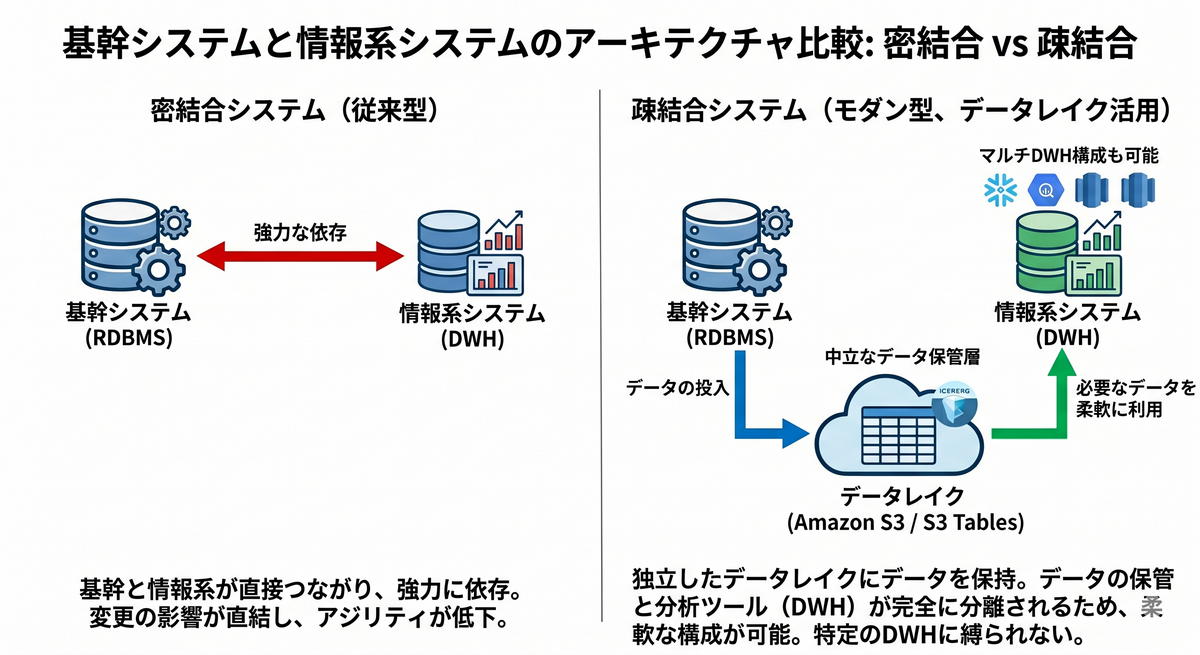
この「疎結合化」は、単にシステム間の影響を切り離すだけでなく、特定のDWH(データウェアハウス)製品に縛られない柔軟な情報基盤の構築にも直結します。
なぜなら、密結合な状態(基幹システムから特定のDWHの内部ストレージへ直接データを流し込む構成)から脱却し、独立したデータレイク(S3など)にオープンなフォーマットでデータを保持する形になるからです。データという資産の保管場所と、それを分析するDWH(列指向型データベース)が完全に分離されるため、強固なベンダーロックインを回避できます。
これにより、将来的に要件が変わった際にDWHを別の製品にスムーズに乗り換えたり、あるいは用途に応じて複数のDWHを併用するマルチDWH構成を採用したりすることも、疎結合なアーキテクチャであれば容易に実現可能になります。
膨大なデータの長期保持が安価に実現できる
情報系システムでは、トレンド分析のために10年以上前の過去データを掘り起こすことも珍しくありません。しかし、継続して増え続ける膨大なデータを、一般的なRDBMSや、分析に特化したDWHにすべて保持し続けると、ストレージ費用が莫大なものになってしまいます。「データは長期保管していつでも活用したいが、インフラコストは抑えたい」という、ジレンマを解決することが求められます。
これらの「疎結合化」と「コストを抑えた長期保管」というあるべきを同時に解決するアーキテクチャとして我々が採用したのは、安価なS3をベースにしたデータレイクであり、その後続のDWH連携の要となるのが S3 Tables です。
S3 Tablesとは
Amazon S3 Tablesは、2024年末の「AWS re:Invent」で発表されたばかりの比較的新しい技術で、S3上にフルマネージドなApache Icebergテーブルを構築できるサービスです。
ベースがS3であるためストレージ費用が非常に安価であり、膨大なデータの長期保管に最適です。従来のデータレイクで必須だった煩雑なファイルのメンテナンス作業をAWSが自動で行ってくれるため、後続のDWHから直接かつ超高速なデータ分析が可能になります。運用負荷の削減と圧倒的なパフォーマンスを両立できることから、間違いなく今後のデータレイク構築における新定番になっていくのではないかなと思います。
S3 Tablesでデータレイクを構築する利点
DWHへのデータのコピーが不要
従来のアーキテクチャでは、S3の生ファイル(CSVやJSON)をDWH(例えばAmazon RedshiftやSnowflake)で高速に分析するためには、DWHの内部ストレージにデータをロード(コピー)する必要がありました。
しかし、S3 Tables(Icebergフォーマット)に変換しておけば、RedshiftやSnowflakeなどのモダンなDWHは、S3上のテーブルを直接、しかも内部ストレージと遜色ない超高速なパフォーマンスでクエリできます。 これにより、DWHのストレージコストを大幅に削減し、データ連携の手間を省くことができます。
データ品質が保証される
データレイク(S3の生ファイル)は「とりあえず何でも放り込める」のがメリットですが、ファイルの形式が変わったり、カラムが増減したり(スキーマ変更)すると、後続のDWHのロード処理がエラーに陥りがちです。S3 Tablesを通すことで、型が厳密に定義されたテーブルとしてデータを扱えるため、DWH側は常に整理された信頼できるデータだけを安心して読み込むことができます。近年では、ただのデータレイク(S3)とDWHの間にIcebergなどのテーブルフォーマット層を挟むアーキテクチャは、「データレイクハウス(Data Lakehouse)」とも呼ばれているようです。
S3 TablesにロードするETLスクリプト(Glue)を自動生成する仕組みを構築
前置きが長くなりましたが、こうした背景を踏まえ、今回は基幹システムから受け取ったデータを S3 Tables へ自動投入するパイプラインを構築しました。
要件上、連携される S3 Tables(テーブルの種類)ごとに個別のETLスクリプトを用意する必要がありましたが、それら数十〜数百に及ぶスクリプトをすべてエンジニアが手書きで実装・保守するのは非常に辛く、現実的ではありません。しかし一方で、各スクリプト自体は個別であるものの、その内部で実装すべき型変換や桁数・フォーマットのバリデーションといった処理ロジックはワンパターンであるという性質がありました。
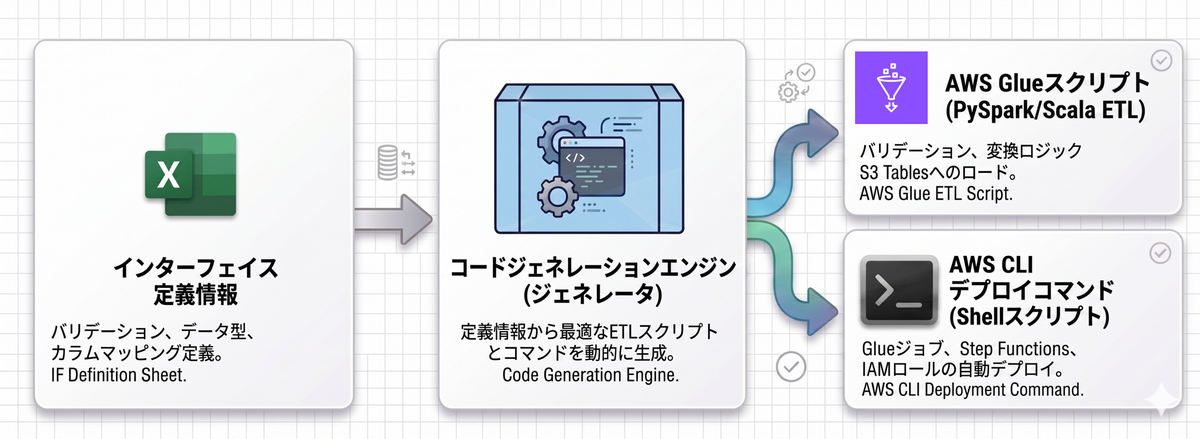
そこで今回は、連携ファイルのインターフェイス定義情報(Excel)をインプットとして、各テーブルに特化したバリデーションチェックやETL処理を含む Glue スクリプトをジェネレータで自動生成。さらに、生成したスクリプトのデプロイまでをワンコマンドで完結できる仕組みを整えました。
S3 TablesにロードするETLスクリプト(Glue)
今回ETLツールとして採用したのはAWS Glueというサービスです。Glue自体はPython(PySpark)でスクリプトを記述することでETLを実装できる仕組みになっています。
バリデーションチェック
実は、Glueの裏側で動いている分散処理エンジン「Apache Spark」は、型変換(キャスト)の際に不正なデータを受け取ると、デフォルトではエラーで処理を落とさず、サイレントにNULLへ変換して処理を続行する仕様になっています。
従来型のデータレイクであれば「とりあえずエラーで止めずに全件取り込む」という思想も許容されましたが、S3 Tablesは後続のDWHが直接参照する「データレイクハウス」の要です。ここでSparkのデフォルトの挙動のまま不正データをNULLとして混入させてしまうと、後続の分析基盤のデータ品質が著しく低下してしまいます。
不正データはS3 Tablesの手前で確実にエラーとして弾き、綺麗なデータだけをロードするという、DWHと同等の厳格な品質管理を実現するために、ジェネレータを用いたバリデーションの実装が不可欠でした。
以下は、ジェネレータが自動出力したバリデーションコードの一部(文字列長チェック)と、エラー時の早期終了処理の抜粋です。
# 7. バリデーション(フォーマット・桁数チェック)の一部抜粋 |
ただエラーで弾いて落とすだけでなく、運用フェーズで原因調査がしやすいように「どのレコードの、どの主キー(PK群)でエラーが起きたか」を最大20件サンプリングしてログに書き出す工夫を入れています。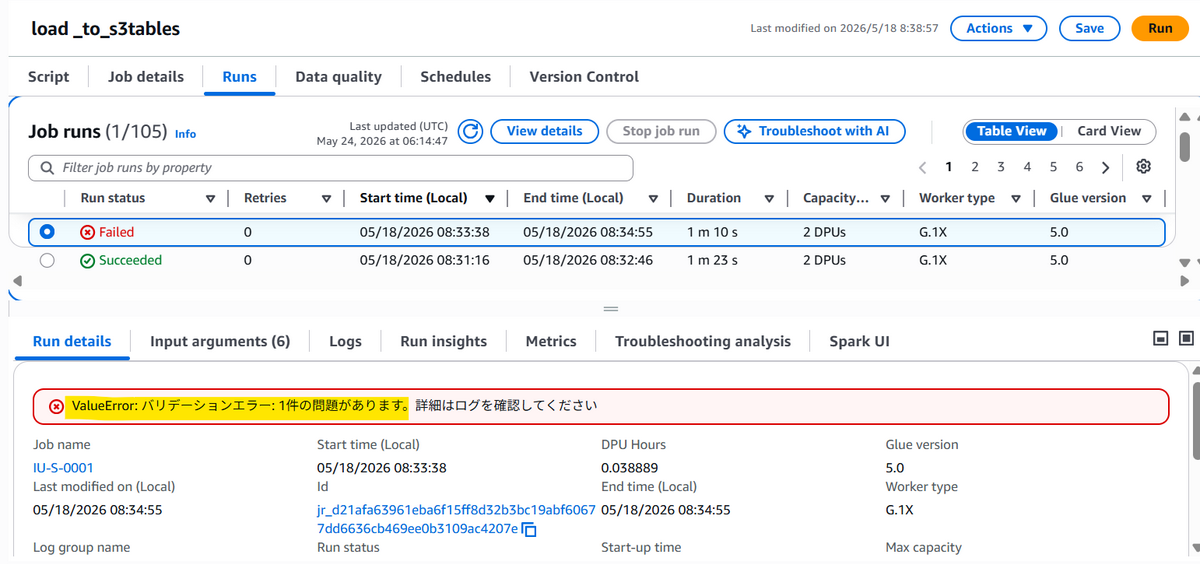
↑エラー時のGlueの画面
===== Validation Error Summary ===== |
↑詳細なエラーログ
ORDER_TYPEの最大2文字という制約に引っかかったデータ行が1つあること、そしてそのデータのPK項目が示されます。これにより、ユーザーはデータのどこに不正があったかを確認できます。
バリデーションチェックはカラムごとに実装しますが、「これをテーブルの全カラム分(数百カラム)手書きするのは絶対にやりたくない!」と思いました。コピペで量産しようものなら、保守性は最悪です。
本システムでは、インターフェース定義書(Excel)に「型:文字列、最大桁数:2」と記載しておくだけで、ジェネレータが上記のようなチェックロジックをカラムの数だけ動的に組み立ててくれます。これにより、人的ミスを完全に排除しつつ、実運用に耐えうる保守性を担保しています。
※ジェネレータのコードは非公開です
二重取込防止
S3 Tablesに取り込まれるファイルが二重で取り込まれないようにする仕組みも実装しました。例えば、送信元のシステムが間違えて同じファイルを2回アップロードしてしまった場合や、リトライ処理が走った場合、何も対策していないとS3 Tablesに同じデータが重複してインサートされてしまいます。
そこで今回のスクリプトでは、Icebergフォーマットの恩恵を活かし、データの投入(Load)直前に以下のようなチェック処理を実装しています。
# 12. Amazon S3 Tables へのロード (Load) |
従来のS3上のParquetファイル群に対して同様の重複チェックを行う場合、Athenaを叩いたり、S3のオブジェクト一覧を取得したりと一手間必要でした。しかし、S3 TablesはフルマネージドなIcebergテーブルとして機能するため、PySparkの spark.sql を使って、ロード先のテーブルを直接かつ高速にクエリすることが可能です。
ここで取り込み対象のファイル名(source_file)が既にテーブル内に存在するかをカウントし、存在する場合は意図的にValueErrorを発生させてジョブを落とします。
そして、安全が確認されたデータのみが、.writeTo().using("iceberg").append()というAPIによってS3 Tablesへ投入されます。
なぜGlue標準の「Job Bookmark」を使わなかったのか?
実はAWS Glueには「Job Bookmark」という機能があり、これを有効にするとすでに処理した入力ファイルを自動的にスキップ(重複排除)してくれます。一見するとこの標準機能を使えば良いように思えますが、今回のアーキテクチャではあえて不採用としました。
その理由は、Bookmark機能が重複ファイルを検知した際の 「ファイル読み込みは成功するが、中身が0件の空データとして扱われる」 という仕様にあります。テーブルのデータを全件入れ替える「洗替型(Overwrite)」のバッチ処理にこの仕様が適用された場合、空のデータで既存テーブルを上書きしてしまう(=テーブルのデータが全件消失する)という致命的な事故に繋がります。
環境に依存しない一括デプロイ
自動生成されたGlueスクリプトは、AWS環境(S3へのスクリプト配置やGlueジョブの登録)へデプロイして初めて機能します。しかし、数十個のジョブをマネジメントコンソールから手作業でポチポチと登録していくのは、面倒です!
そこで今回のシステムでは、出力したGlueスクリプト群をまとめてデプロイするための AWS CLIデプロイコマンド(シェルスクリプト)も、ジェネレータに一緒に生成させるようにしました。
このデプロイコマンドには、以下2つの工夫が組み込まれています。
1. デプロイ対象(機能ID)の絞り込み
ジェネレータが生成したシェルスクリプト内には、対象となる機能ID(ジョブ名)の配列が自動で組み込まれます。これにより、デプロイコマンドを実行するだけで、対象機能のスクリプトだけがS3にアップロードされ、Glueジョブとして作成(または更新)される仕組みになっています。
2. 実行時パラメータ(環境変数)による環境差異の吸収
開発環境(dev)、テスト環境(test)、本番環境(prod)では、利用するIAMロールやS3バケット名が当然異なります。これらをスクリプト内にハードコーディングせず、コマンド実行時の引数(DEPLOY_ENV=dev など)に応じて設定ファイル(.env)から動的に読み込むようにしました。これにより、環境を切り替えるだけで、Glueジョブ内の設定(S3 TablesのバケットARNなど)が自動的に適切な値に置き換わります。
実際のシェルスクリプトのコア部分(抜粋)は以下のようになっています。
|
【このコードのポイント】
aws glue create-job (または update-job) を実行する際、–default-arguments パラメータを通じて、環境変数から取得した ${TABLE_BUCKET_ARN} などの値をGlueジョブに渡し込んでいます。
この仕組みにより、開発者は「Excelでテーブルを定義する」→「ジェネレータを実行する」→「環境を指定してデプロイコマンドを叩く」というわずか3ステップで、S3 Tablesへデータを投入するデータパイプラインを本番環境へ安全に展開できるようになりました。
例えば、デプロイコマンドで DEPLOY_ENV=dev と指定した際に読み込まれる、開発環境用の設定ファイル(dev.env)の中身は以下のようになっています。
Properties |
【この設定ファイルのポイント】
単なる変数の外出しに見えますが、S3 Tablesを扱う上で非常に重要な設定が含まれています。
DEPENDENT_JARS_PATH の指定
Glue(PySpark)からS3 Tables上のIcebergテーブルを操作するためには、専用のランタイムライブラリ(s3-tables-catalog-for-iceberg-runtime-*.jar)が必要です。このJARファイルのS3パスを環境変数として切り出しておくことで、将来ライブラリのバージョンアップが必要になった際も、コードを修正することなく .env のファイル名を書き換えるだけで対応できます。
TABLE_BUCKET_ARN の扱い
S3 Tablesは、従来のS3(s3://…)とは異なり、専用の Table Bucket ARN(arn:aws:s3tables:…)を用いてアクセス先を指定します。開発環境・テスト環境・本番環境でこのARNは確実に変わるため、環境変数からGlueジョブの –table_bucket_arn パラメータへ動的に注入するこの設計が非常に活きてきます。
このように、AWSのインフラ情報やライブラリのパスを .env に集約させることで、ジェネレータが生成するGlueスクリプト本体には環境依存のハードコードが一切含まれない、パイプラインを実現しています。
おわりに
S3 TablesとAWS Glueを利用し、基幹システムと疎結合かつ安価なデータレイクを構築する手法をご紹介しました。
データ基盤の最適化や、膨大なETLパイプラインの実装・運用に悩む方々にとって、本記事のアプローチが少しでも参考になれば幸いです。
最後までお読みいただき、ありがとうございました!