Goならわかるシステムプログラミングなどのウェブ連載や書籍化でお世話になりまくりの鹿野さんのブログ記事が話題となっています。
- golden-luckyの日記: AI時代のコンピューター技術書
これを読んで、今までモヤモヤ思っていたことに光明が射してきたので、ちょっと実験してみました。
AI開発のボトルネックは今どこか
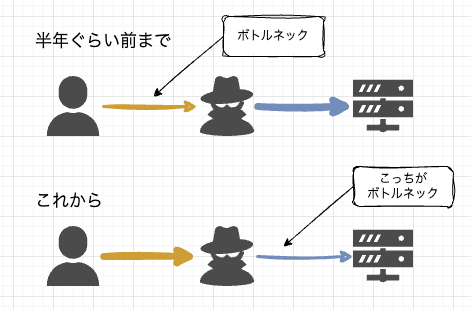
1年ほど前はあまり長時間モデルが働き続けることもなく、生成AIの月あたりのクオータを使い切るということはあまりありませんでした。そのため、AI開発のボトルネックは主に、人間とAIのコミュニケーション部分にあると思っていました。
ここ1-2か月ぐらい、Planモードで走り続けて一回の消費が大きくなったせいか、5時間枠を使い切ることが増えてきました。ボトルネックはAPIリクエストのクレジット数になってきたのを感じます。それに追い打ちをかけてGitHub Copilotのモデルの乗数の変更。Claude Opus 4.6はx3からx27へと9倍になりますし、課金体系も、リクエスト数ではなくて、API呼び出し数に変わるということで、こちらも深刻です。
そうなると、トークン数の節約が大切となります。
例えばコンテキスト数の節約はトークン数の節約になります。コンテキスト節約は推論コスト削減になり、APIコスト削減になります。APIコストも削減され、レイテンシーも改善されます。いいことばっかりですね。
今まではコミュニケーション速度がボトルネックだったので得意な日本語でガンガン情報をインプットするのが最適かなと思っていましたが、コンテキスト数を節約する場合は日本語よりも英語の方が良いと言われています。ということは英語で読み書きするのが良いということですね。
まあ無理に英語を使うことで会話のスピードが1/10になったら良くないわけですし、そもそも技術的に難易度が高すぎて言葉で表現できない!となったら元も子もなかったりはしますね。1週間のクオータを使い切って待つのと、人間が情報を伝えるのと、どちらの待ち時間が長いか次第かと。
大規模開発ではドキュメントが大事だが・・・
趣味開発だと、自分の頭にあるものをどんどん伝えていけばいいのですが、仕事の開発だと作るものを決定するのは開発者ではなくユーザーだったりステークホルダーだったりが多いかと思います。こちらの場合はドキュメントをしっかり書いて、要件を固めてすテークホルダと合意して実装、みたいな方式が基本的に採用される流れですね。AmazonのAI-DLCもそうですね。ドキュメントをしっかり書くことで、手戻りを減らしたり、複数のエージェントを活用したりとか。Codexには/goalというexperimentalな機能も追加されました。
で、AI-DLCをやってみたのですが、どうもドキュメント作成が重い。AI-DLCのサンプル実装というワークフローをCopilotに入れてみて試しましたが、隅々までAIから質疑応答を受けてそれに回答してそれでドキュメントを更新し・・・と。1サイクルがかなり時間がかかる。また、「後回しでもいいのに」というような細かいところまで聞かれるのでフロントローディングで設計を考える必要があります。結果として2サイクル回しましたが、それで1月のCopilotのProのクレジットの6割ぐらい消費し、3000行ぐらいのコードと、12000行のドキュメントができました。趣味開発でもウォーターフォールを強制時短適用しているような、なんかすごい疲れたな、という感想です。
そもそも、AI-DLCの基本的に大量のドキュメントが生成されて、それを人間がチェックをして・・・という流れは「AIは解読が得意」という鹿野さんの記事とは真逆です。AIが大量に生成したドキュメントを人間が確認し・・・これは苦痛です。もちろん、AI-DLCのワークフローはサンプルのフローであって、これそのものが将来の開発の姿というわけではないと思いますが、何かしらのアップデートが今後必要となるのは間違いないでしょう。
AI時代のドキュメント
鹿野さんの考える未来の読書では、技術書は人間が読むものではなく、AIの中にあり、人間はAIというフィルタを通じて情報を得れば良いということであり、ドキュメントの苦痛を減らす方向性としても魅力的に感じます。今までの延長線上では、たとえMarkdownになったとしても、ドキュメントをの整合性をとりつつ、全体構成を考えるのは人間のタスクになります。しかし、人間が読みやすい構造ではなく、AIが理解しやすい構造としてドキュメントを表現してあげて、AIを通じて必要な情報を得れば良い、という方針の方に未来がありそうと感じます。
構成の改善
今までの設計書のまま、MarkdownにしてAIが読みやすいように、というのを今まで考えてツールを作りかけてたこともありますが、単純にMarkdown化しようとすると表現力が劣るという問題がでてきます。
そもそも、人間が仕様書を書く場合は、あらかじめ「○○○詳細設計書」などの形式を決め、それを穴埋めしていくことで設計の抜け漏れがないか、またはレビューのしやすさを維持して、全体の生産性が落ちないようにしますが、そもそもAIが書いて読むならそのような形式化は不要となります。AI自身が書いてAI自身が検証できるようになれば、このような今までに近い仕様で書こうという必要性は減りそうです。
読み込みの改善
AIフレンドリーなプロンプトというと、MCPサーバーよりもコンテキスト消費が少ないというskillsがあります。必要な情報を必要なタイミングで読み込むことで、常駐コンテキストを大幅に減らしますし、編集などは専用のスクリプトを使って決定性の高い方法で行えるようにしています。
AIでMarkdownでドキュメントを作成する場合も、SkillsのSKILL.mdで行われているように、リンクで別のファイルに飛ばすような構成にすることで一度に消費するコンテキストを抑えられるということを聞きました(@ryushi曰く)つまり、ドキュメントはAIが消費しやすいように小さくしていけば良いと。AI時代よりも前に、意味を表現しようとする「セマンティックウェブ」というものがありました。ウェブの父であるティム・バーナーズ=リーが提唱したもので、XMLを使って意味の定義を作り込む必要があります。
これを人力でボトムアップで作り上げて、意味のある知識構造を作り出すのは相当至難の業ですが、今のAI時代であれば大きい情報は小さく分割して、また適切なリンクテキストを張り巡らせるという感じでやればよさそうです。リンク切れなどを起こさないように自動チェックをスクリプトで行えば良さそうです。
完全性を後回しにできる要件
AI-DLCワークフローの場合は、おそらく与えられた要件から完全なドキュメントを最初に作成してレビューを受けようとしているように見えます。今回作ったのは「未完了」を許容するようにしています。アジャイル開発の「スループットの高さ」は要件定義を「次の1イテレーション分回すのに十分な量だけ行う」ことにあります。優先度が低いものは後回し。AIでドキュメントのワークフローを作ると「要件が満たせるまでループする」という指示を入れようとする記事などをよく見る気がしますが、人間側がまだ細かいところまで把握できていないのにAIだけに完全を求めると、やたらと待ち時間が長くなるし、投機的に決めたことの修正が必要になった時のトークン消費もかなり多くなると思われます。
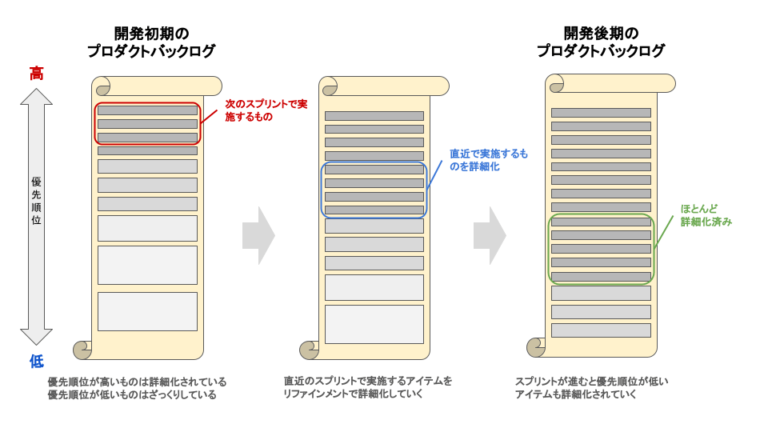
https://do-scrum.com/pbl: 【完全攻略】スクラム開発におけるプロダクトバックログの作り方より引用
システム全体を見て、先に開発が必要で要件をまとめない、これ以外の部分はまだ手をつけなくていい、みたいなところは、結構ファジーな直感に頼るところが多いのかな、と思います。まだまだアーキテクトスキルを持ってアジャイルに優先度別に考えられるような人間がやった方が圧倒的に効率は高いと感じます。
まだ定義が完了していないものはバックログとしてまとめるようにもしています(もうちょっと表現とかワークフローは工夫できそう)
仕様書をAIチューンするskill
さっそくこのようなskillを作ってみました。
ドキュメント種別を毎回ゼロから再発明させるのは結果が安定しなくなりそうなので、デフォルトのドキュメントの種別を定義して、テンプレートから作れるようにしています。ただ、テンプレートは今までのものよりかはだいぶ少ない内容としています。それに従って文章を作っていくのですが、1つ1つの文書は小さく、そして文書の間にリンクをいっぱい作成するようなskillとなっています。また、スクリプトでビルドするとインデックスなどはJSONL形式で書き出します。DuckDBで扱いやすいように。人間が作る時は一覧表も作りつつ詳細を作ったりしますが、詳細だけ作りインデックスや文書間リンクはAIが自動で貼っていく、ローカルWikiみたいな感じとなっています。ちなみに本文はコンテキストを節約するために英語ですが、末尾に人間向けの日本語向けの説明も軽くいれる形式としました。
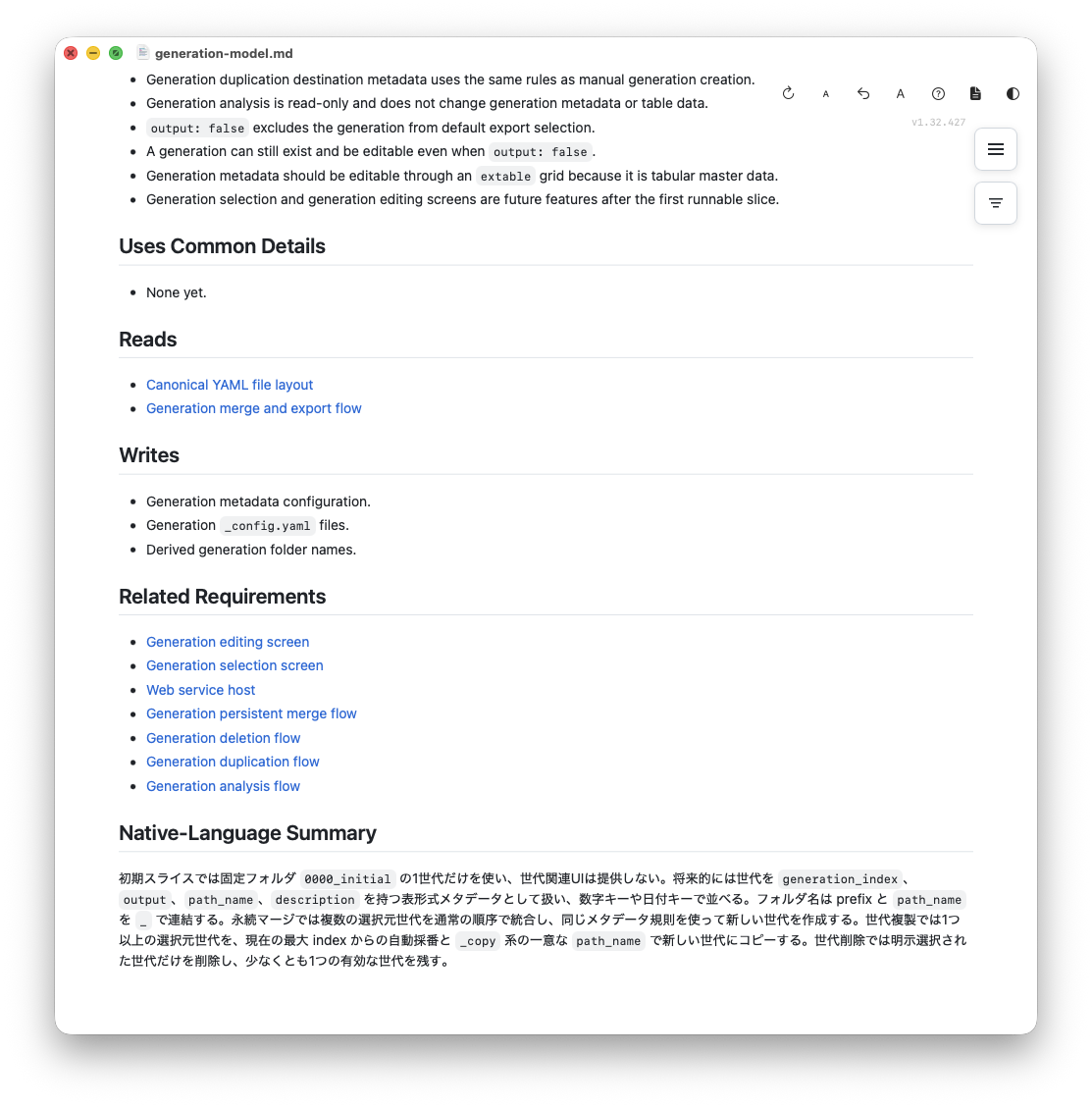
サンプルのデータモデルのドキュメントからは、データ構造からそれを編集する画面のリンク、シリアライズ形式、それを使うプロセスの情報などにリンクが貼られています。これは下の方1/3ぐらいで、上の方には概要、フィールド一覧、ルールや制約、みたいなのがざっと書かれています。
このような文書管理はRAGを使う手もありますが、結局類似文章が見つかったらそれから見つかった全件メモリに入れて分析するような動きになるかと思います。ヒットするものの関係がないかもしれないものも一度コンテキストに格納して・・・となると効率が悪い。RAGの検索の精度が悪いと必要な情報がヒットしない。リンクのラベルから必要性がわかっているものを順次辿る方が早いだろう、という目論見です。
AI用ドキュメントをAIを使って読む
ドキュメント形式はプロジェクトの特性によって変更できるようにしています。そんな感じで人間に合わせた目次分けとかにはなっていませんので、どこに何が書いてあるか人間が扱うのはやや扱いにくいと言えます。鹿野さん方式で、AIに読み込ませ、何かあればAIにお願いすることになります。結構軽快です。編集を依頼してもすぐに返ってきます。ドキュメントはコンテキストを節約するために英語ですが、日本語で聞いたり修正の依頼を投げても大丈夫です。横断的に必要な情報を集めてサマリーしてくれます。
- 仕様の確認: AIに聞く
- ドキュメントの修正: AIに聞く
- 要件定義の足りない部分: AIに聞く
今回考えてみて何本かやってみて、この仕組みはかなりうまくいきそうです。ある程度AIと一緒にドキュメントを作り、あとはゴール機能を使って一気に実装完了まで依頼する、という流れでコードを書いてもらうというのを行いましたが、実装を開始したら止まることなく最後まで毎回作ってくれます。
内製開発では不要だと思いますが、ウォーターフォールみたいな、フェーズでの設計品質のチェックゲート的なものも、おそらくAIとやりとりしながら抜けがないか確認していけば良さそうな気がします。あるいは、この形式のドキュメントから従来方式のドキュメントを生成させるとかですかね。構造化されたソースコードが生成できるので、ドキュメントも出せるでしょう。
まとめ
思いつきでぱっとつくったスキルでしたが、思った以上にうまくいきました。やはり、AIが大量に作ったものを人間が読まされるのはストレスとなりますし、そこがボトルネックとなります。AIは読むのが得意、という能力を活かさないのはもったいないですね。
ドキュメントの形式一覧は「デフォルト設定」で、プロジェクトごとにカスタマイズできるような構成にはしています。今回はあまり大きくないコードだったのでそれを使うことはなかったのですが、より大きいものでも触ってみて、必要に応じてドキュメントタイプを追加し、1つ1つのドキュメントを小さく保つ、というのは引き続き試してみたいですね。
今後やりたいこと
まだまだスキルが正しく期待通りの動きをしているかは精査が必要です。CodexはOpenTelemetryでアクティビティが取得できるのですが、おそらくそのような仕組みを使って、モニタリングを行い、期待されたスクリプトが呼ばれているのか、呼ばれていないのか、呼ばれていないなら何が原因かなどの追求が必要な気がします。skillの仕様の評価の仕方もありますが、skill creatorスキルと組み合わせていかに効率よく検証して改善していくかは、まだ課題かなと思いました。
あとはテストの連携もしたいですね。各ドキュメントごとにテスト観点などを書いたドキュメントのリンクを貼り、テストの仕様をきちんと書けるようにしてそれを元にコード生成ができたりすると良さそうです。テストコードからはそれが定義されているドキュメントがリンクされている、ということはあんまりなく情報が一方通行になりがちなので、そのあたりもAI中心のドキュメントだと利便性を上げられるんじゃないかと思います。