本記事は2026年7月2日時点の情報に基づく内容です。一次情報(主に英語)の読み取りやリサーチの過程で、事実誤認や誤りが含まれている可能性があります。数値・仕様・各社ポリシーは、実務判断の前に必ず最新の一次情報でご確認ください。あわせて、業務でAIを利用する際は、必ず自社の社内ポリシーも確認してください。
データエンジニアリング連載 の4本目です。今回の担当は棚井です。
はじめに: Fableが帰ってきた
ついに、Claude Fable 5の利用が再開されました。6月に発表されたばかりのモデルだったのが、6月12日に米国政府の輸出規制がかかって全ユーザー向けにアクセスが止まっていたところからの復帰です(Anthropic: Redeploying Claude Fable 5)。6月30日に規制が解除され、7月2日から再開されたという経緯です。使えなくなっていたモデルが戻ってきて、正直やったぜと思いました。
ただし、トークン消費量の多さとは別に、押さえておきたい注意点があります。Fable 5は、ZDRではなく30日のデータ保持が必須という仕様です。同じClaudeでも、他の多くのモデルはZDR下で会話内容を残さないサービス仕様ですが、Fable 5はこの点が異なります。同じサービス・同じAPIキーでも、どのモデルを呼ぶかでデータ保持のルールが変わることがありますので、それならば主要モデルのデータ保持の扱いを一度横断で整理しておこう、と思ったのが今回のきっかけです。
テーマは、生成AIをデータ基盤やアプリに組み込むときに毎回引っかかる「入力したデータがプロバイダ側にどれだけ残るのか」です。いわゆるデータ保持期間(Data Retention)と、ZDR(Zero Data Retention、ゼロデータ保持)です。2026年7月2日時点の各社公式ドキュメント・利用規約を一次情報として整理しました。
また最近、セキュリティチェック項目に「AIの利用可否」と「データ保持の有無」について問われる機会が増えてきました。ここでつまずきやすいのが「学習に使われない」と「サーバに残らない」を同じものと扱ってしまう点です。この2つを分けずに「APIなら安全」と判断すると、監査で足をすくわれます。
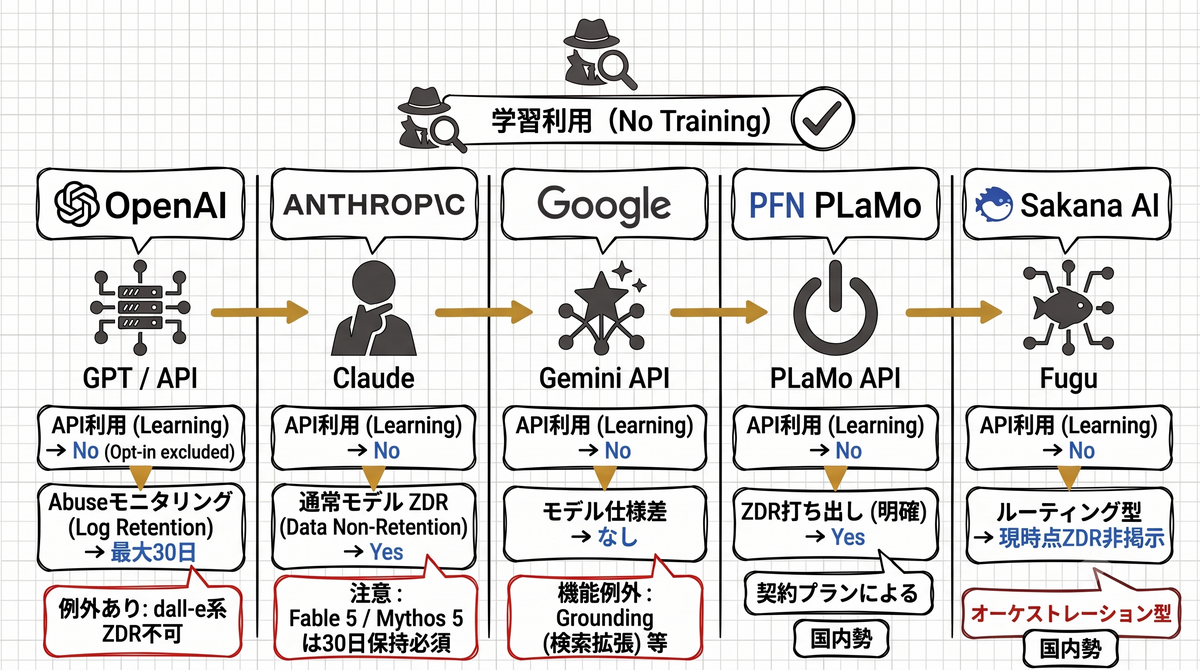
先に、5サービスの要点を表でまとめます。今回は「API/エンタープライズ利用」を前提に取り上げます(個人向けアプリは別ポリシーなので、必要な範囲でのみ触れます)。細かい根拠は各節で扱うので、ここでは全体像だけ押さえてください。
| サービス | ZDR・データ保持の特徴 | 例外・注意点 |
|---|---|---|
| OpenAI(GPT / Codex / API) | エンドポイント単位で保持挙動が最も細かく公開されている | 画像モデルによってZDRの可否が分かれる |
| Anthropic(Claude / Claude Code) | 通常モデルはZDR下で非保持 | Fable 5 / Mythos 5は30日保持必須(ZDR不可) |
| Google(Gemini API) | モデルによる仕様差はなし | Grounding(検索拡張)など機能側に例外あり |
| Preferred Networks(PLaMo API) | 国内勢で最も明確にZDRを打ち出している | モデルの差ではなく、契約プランによって決まる |
| Sakana AI(Fugu) | 外部モデルにルーティングするオーケストレーション型 | 現時点ではZDRを掲げているサービスではない |
便宜的に3つのレイヤに分けて考える
実際のデータ保持のメカニズムは、サービスごとに細かい差分があります。その差分を一度に並べると読みづらいので、ここでは説明のための便宜的なグルーピングとして、次の3つの軸を使います。公式な規格や定義ではなく、あくまでこの記事での整理軸です。
| レイヤ | 何を指すか | よくある勘違い |
|---|---|---|
| ① 学習利用(Training) | 入力・出力を将来のモデルの重み更新(学習・ファインチューニング)に使うか | 「学習に使わない」=「保存もされない」と思い込む |
| ② ログ保持(Retention / Abuse Monitoring) | 不正利用監視・デバッグ・法令対応のため、入出力を一定期間サーバに保存するか | 学習に使わなくても保存はされていることを見落とす |
| ③ ゼロデータ保持(ZDR) | そもそも②の保存自体を行わず、処理直後に破棄するか | ZDRにすれば全機能で何も残らないと思い込む |
同じ②の中でも、サービスによっては「不正利用監視用の保持」と「デバッグ/運用ログ」で期間が違ったり、ZDRを有効にしても特定の機能だけ②が残ったりします。その細かい差分は各節で拾います。まずはこの3つを分けて見る、というところを押さえておいてください。
エンタープライズ向けの主要API(OpenAI / Anthropic / Google Gemini API)は、①の学習利用がデフォルトでオフです。各社が規約で明記しています(Homula: エンタープライズLLMのデータ主権)。
問題は②です。学習には使わないが、Abuse Monitoring(不正利用監視)のために入出力を最大30日ほど保存する、というのが多くのサービスのデフォルトになっています。「入れたデータが一切残らない環境」ではない、という認識のズレはここから来ます。
③のZDRは、その②の保存をやめる仕組みです。ただし後述のとおり、ZDRを有効にしても保存が残る例外が各社にあります。「魔法の全消し設定」だと思っていると危ないです。
ZDRの定義としては、XIMIX(NTTインテグレーション)の説明が端的でした。ZDRとは「ユーザーが入力したプロンプトやAIが生成した回答データを、サービス提供者側のサーバに一切保存せず、処理直後に破棄すること」であり、「学習に利用しない」より厳格なアプローチだとしています(XIMIX: 生成AI時代のゼロデータリテンション)。ただし、ZDRの具体的な定義はサービスごとに異なります。各サービスの定義は、それぞれが公開している情報で確認してください。
OpenAI(GPT / Codex / API)
OpenAIはエンドポイント単位の保持挙動を表で公開していて、ここが一番細かく追えます(OpenAI: Data controls in the OpenAI platform)。
API経由のデータは、2023年3月以降、明示的にopt-inしない限りモデル学習に使われません。Abuse Monitoring目的のログは全APIで生成され、最大30日保持されます(法令上より長期の保持を求められる場合を除く)。このログにはprompts / responsesや分類器の出力などのメタデータが含まれえます。
ZDRやMAM(Modified Abuse Monitoring)は、Eligible customers(適格な顧客)が事前承認と追加要件への同意を経て使えます。組織またはプロジェクト単位です。ZDR有効時、/v1/responses と /v1/chat/completions の store パラメータは、リクエストで true を指定してもfalse扱いに固定されます。
モデル単位で挙動が変わるところ
テキストモデルは、同じエンドポイントを使う限り保持挙動も同じです。テキスト側に「モデルを変えたらZDR可否が変わる」という差は見当たりません。公式のData controlsページで明示されているモデル単位の差は、画像生成モデルの間にあります。
| モデル | 種別 | ZDR対象 |
|---|---|---|
| gpt-image-1 / gpt-image-1.5 / gpt-image-1-mini | 画像生成 | 可 |
| dall-e-3 / dall-e-2 | 画像生成 | 不可 |
画像生成でdall-e系を選ぶとZDRから外れます。同じ「OpenAIで画像を作る」でも、gpt-image系に寄せるかどうかで結論が反転します(OpenAI: Data controls in the OpenAI platform)。
エンドポイント単位のZDR対象可否
モデル以上に効いてくるのがエンドポイントの違いです。主要なものを抜粋します。
| エンドポイント | 学習利用 | Abuse監視保持 | ZDR対象 |
|---|---|---|---|
/v1/chat/completions |
No | 30日 | 可(制限あり) |
/v1/responses |
No | 30日(store=true時) |
可(制限あり) |
/v1/embeddings |
No | 30日 | 可 |
/v1/moderations |
No | なし | 可 |
/v1/conversations |
No | 削除まで | 不可 |
/v1/assistants, /v1/threads系, /v1/vector_stores |
No | 30日 | 不可 |
/v1/files, /v1/batches, /v1/fine_tuning/jobs |
No | 30日 | 不可 |
/v1/videos |
No | 30日 | 不可 |
出典はOpenAI公式のData controlsページです。
OpenAIのZDRがしっかり効くのは、chat/completionsやresponsesで、余計な機能を付けずに推論だけをシンプルに実行する場合です。拡張キャッシュのような便利機能を足すほど、その分ZDRの対象から外れる部分が出てきます。Codexも同様で、内部でどのエンドポイント・機能を叩くかで保持挙動が変わるので、「Codexだから安全」ではなく利用エンドポイント単位で判断してください。
データレジデンシー(保存先リージョン)については、対象エンドポイントで欧州/米国を明示選択できるオプションがあります(OpenAI: ビジネスデータのプライバシー)。
Anthropic(Claude / Claude Code)
Anthropicは個人向けと法人向けでポリシーページが分かれています。そしてここが今回の主題そのもので、同じClaudeでもモデルによってZDR可否が違います。
再開したFable 5とMythos 5の保持要件
Claude Fable 5とClaude Mythos 5は「Covered Models」に指定されていて、30日のデータ保持が必須です。ZDRは選べません(Anthropic: API and data retention)。Claude APIでは、この30日保持を満たさないZDR組織からのリクエストは 400 invalid_request_error を返します。この30日要件はどのプラットフォームでも同じで、Bedrock、Google Cloud、Microsoft Foundry経由でも保持データは各クラウドプロバイダの環境内に残ります。
冒頭で触れたとおり、Fable 5は再開直後です。戻ってきたばかりのタイミングだからこそ、ここで30日保持の要件を改めて確認しておきましょう。それ以外のClaudeモデルは、ZDR下で会話内容をデフォルト保持しません。同じアカウント・同じAPIキーでも、Fable 5 / Mythos 5を呼ぶかどうかでデータ保持のルールが変わってきます。この点を運用ルールに落とし込んでください。
個人向けプラン
個人向け(Claude Free / Pro / Max、およびそのアカウントで使うClaude Code)の保持は次のとおりです。会話削除時、履歴からは即時、バックエンドからは30日以内に削除されます。モデル改善を許可した場合、de-identified形式で最長5年、学習パイプラインに保持されえます(設定を有効にした後の新規・再開チャットに適用)。Usage Policy違反時は入出力を最長2年、trust & safetyの分類スコアを最長7年保持します。Incognito chatsはモデル改善に使われません(Anthropic: How long do you store my data?)。
特に注意したいのが、モデル改善を許可した状態の保持期間です。プライバシー設定はいつでも変更できますが、デフォルトの学習利用可否は利用時点の設定を自分で確認してください。業務データを個人向けプランに入れる行為は、会社の管理下にないAI利用、いわゆる「シャドーAI」にあたります。個人向けプランは学習利用や保持期間のデフォルトが法人向けと異なるため、業務データは法人向けプランで扱い、個人向けプランには入れないよう徹底してください。
法人向けプランとZDR契約
法人向け(Anthropic API、Claude Team / Enterprise)は学習利用がデフォルトでオフです。ここで注目したいのがClaude Codeで、同じClaude Codeでも、どの経路で動かすかでログの保持が変わります。
APIキー(Anthropic API)で動かすClaude Codeは、APIの保持ルールに従います。会話コンテンツ(プロンプトとClaudeの出力)はデフォルトで保持されず、バックエンドに残る場合も受領・生成から30日以内に自動削除されます(Files APIなどユーザー管理下の長期保持、ZDR等の別途合意、Usage Policy執行、法令対応は例外)(Anthropic: API and data retention、Anthropic: How long do you store my organization’s data?)。
一方、Team / Enterpriseで使う場合は、その組織のデータポリシーに従います。会話やプロジェクトを保存して継続できる製品では、保存したデータが製品内に残ります。Enterpriseプランではカスタムデータ保持期間を設定でき、最小は30日です。設定しなければ無期限保持になります。削除は指定日のUTC 0時に実行され、監査ログに記録されます(Anthropic: Configure custom data retention for Enterprise plans)。
ZDR契約の対象は、Messages APIなどの適格なAnthropic API、法人向けの組織APIキーで使う製品(APIキー経由のClaude Codeを含む)、そしてEnterpriseプランのClaude Codeです。Teamプランや個人向けのClaude Codeは対象外になります。ZDR時、Anthropicは法令遵守や不正・危害対策に必要な場合を除き、入出力を保存しません。ただし、入出力そのものではなく、コンテンツが利用規約に反していないかを判定する安全性チェック(User Safety分類器)の結果だけは、規約違反への対応のために残ります。承認制で組織単位、申請はSales Team経由です。HIPAA対応サービス/BAA(Business Associate Agreement)には構成上の制約があり、たとえばWeb検索機能にはBAAが適用されません(Anthropic: ZDR agreement — supported products)。
Google(Gemini API)
GoogleはGemini Developer APIでZDRドキュメントを公開しています。ドキュメントはモデル別のZDR可否を列挙しておらず、保持の可否はモデルではなく使う機能側で差が出る構造です。
有料サービスでは、プロンプト(システム指示・キャッシュ・画像/動画/ドキュメント等のファイルを含む)や回答は製品改善に使われません。Abuse Monitoring目的では、Prohibited Use Policy違反検出に限りプロンプト・回答を一定期間ログ記録します。ZDR承認が下りると、ログ記録前にユーザーコンテンツと識別可能メタデータ(IPアドレス、GoogleアカウントID等)がクリアされ、サニタイズ済みレコードとしてマークされます。
ZDRを有効にしても残る、または無効化できない機能があります。
| 機能 | 挙動 | ZDR達成のための対応 | 保持期間 |
|---|---|---|---|
| Grounding with Google Search | プロンプト・文脈・出力を保存 | 無効化不可 | 30日 |
| Grounding with Google Maps | プロンプト・文脈・出力を保存 | 無効化不可 | 30日 |
| Interactions API | デフォルトで状態保存 | store=false を明示指定 |
デフォルト状態保存 |
| Live API | 状態保存で再接続可能 | SessionResumptionConfig を構成しない |
セッションハンドル生成時24時間 |
| File API | ファイルをat-rest保存 | 手動削除が必要 | 削除/期限まで |
| 明示的コンテキストキャッシュ | cached_contentで保存 |
当機能を使わない | ユーザー定義TTL |
| 暗黙的インメモリキャッシュ | RAM上のみ | ZDR違反にはならない | 24時間TTL |
出典はGoogle AI for Developers: Zero data retention in the Gemini Developer APIです。
実務で一番のハマりどころはGroundingです。Google検索・Maps連携を使うと、ZDR契約下でもプロンプト・文脈・出力が30日保存され、これはオプトアウトできません。「精度を上げたいからGrounding ON、でもZDRだから安心」という構成は成立しません。外部知識を足す機能とZDRが両立しないのは、OpenAIのCode Interpreterやキャッシュと同じ構造です。片方が立てば片方が崩れると覚えておくと応用が効きます。
Preferred Networks(PLaMo API)
国内のAPI勢のなかで、ZDRを正面から掲げているのがPLaMoです。現行モデルはplamo-3.0-prime(262kコンテキストのフラッグシップ)、plamo-3.0-prime-beta(2026年7月31日で提供終了)、plamo-2.2-prime(2026年9月30日で提供終了)です(PLaMo API ドキュメント)。
保持と学習の扱いは、どのプランを選ぶかで変わります。プラン比較表ではStandardプランの「ZDR(入力データの非保持)」欄に「入力データを学習に利用しない」と記載され、Freeプランは同欄が「―」で対象外です。Standardプランの特徴欄には「入力したデータを保存せず、モデル学習にも使わない」とも明記されています(PLaMo API プラン)。利用規約側では、有償サービスのコンテンツを「本サービス、新サービス又はAIモデルの開発若しくは改善の目的で、閲覧又は利用することはありません」と定める一方、Freeプラン及び無償サービスのコンテンツは同目的で「閲覧又は利用する場合があります」としています。あわせて「当社は利用者に対して本コンテンツを保存する義務を負いません」とも定めています(PLaMo API 利用規約)。規約は個人情報保護法(APPI)の遵守を明記し、無償サービスでの個人データ入力を禁止するなど、国内のコンプラ要件を意識して作られているのが分かります。
Sakana AI(Fugu)
SakanaのFuguは、受け取ったリクエストを内部でいくつかの小さな作業に分け、それぞれを外部のフロンティアモデル(OpenAI / Anthropic / Google等)に振り分けて処理させるサービスです。たとえば、難しい推論が必要な部分と単純な整形で済む部分を、それぞれ得意なモデルへ自動で割り振ります。こうして複数のモデルを束ねて使い分ける仕組みを、オーケストレーション型と呼びます(Sakana Fugu Terms of Service)。入力は外部LLMへ転送され、各プロバイダのポリシーが適用されます。ここが保持を考えるうえで効いてきます。
学習利用については、ContentをTraining Use(再学習・ファインチューニング含む)に利用しうるとしています。コンソールでopt-out可能ですが遡及しません。保持については、入力・出力の保存義務を負わないと定めています。加えて、Contentを基に学習したモデルの重み・外部ベンダーの一時キャッシュ・監査ログについても、削除義務を負わないと明記しています。品質・安全性向上のため人間レビュアーがContentを注釈・処理する場合があり、フィルタで個人・機密情報のレビューを完全には制限できないとも書いています。金融個人データについては別途「金融個人データ保護指針」(2025年6月施行)で安全管理措置を定めますが、保持期間・学習利用・ZDRの具体的記載はありません。
現時点のFuguはZDRを掲げるサービスではありません。オーケストレーション型なので、データ保持は「Sakana自身」と「転送先の外部LLM」の二重で評価する必要があります。機密データを入れる用途では、この二重評価をやりきれるかがそのまま採否の判断になります。
横断比較表(2026年7月時点)
「API/エンタープライズ利用」を前提とした比較です(個人向けアプリは別ポリシー)。モデル固有の差がある行は「主なモデル差」に書きました。
| サービス | 学習利用(デフォルト) | 標準保持 | ZDR/非保持 | 主なモデル差 | 主な例外・注意 |
|---|---|---|---|---|---|
| OpenAI API | なし | Abuse監視30日 | 可(承認制、組織/プロジェクト単位) | dall-e系はZDR不可、gpt-image系は可 | conversations/assistants/files等は対象外。拡張キャッシュ・Code Interpreter・Backgroundは非対応。CSAM検出は保持 |
| Anthropic API / Enterprise | なし | API(Messages API等)は非保持がデフォルト(残っても30日以内に自動削除)。会話保存型のTeam/Enterpriseは無期限(Enterpriseはカスタム設定可・最小30日) | 可(承認制・組織単位、Sales経由) | Fable 5 / Mythos 5は30日保持必須・ZDR不可。他モデルはZDR下で非保持 | ZDRはMessages API・API経由/EnterpriseのClaude Codeが対象(Team・個人向けは対象外)。User Safety分類は保持。違反時入出力2年/スコア7年 |
| Google Gemini API | なし | Abuse監視ログ(ZDR承認でサニタイズ) | 可(プロジェクト単位、承認制) | モデル別のZDR可否はドキュメント上未列挙(機能側で差) | Grounding(Search/Maps)は30日保持でオプトアウト不可。Live API 24h、暗黙キャッシュ24h(RAM) |
| PFN PLaMo API | Standard(有償)はなし、Free(無償)はあり | Standardは非保持 | Standardで標準提供 | plamo-3.0-prime等でモデル差なし(プランで決まる) | Freeは学習利用されうる・ZDR対象外(2026年7月時点は準備中)。APPI意識の国内設計 |
| Sakana AI(Fugu) | あり(opt-out可・非遡及) | 保存義務なし(削除義務も負わないと明記) | 明示なし | 転送先の外部モデルのポリシーに依存 | 外部LLMへルーティング、二重評価が必要。人間レビューあり |
各セルの出典は本文の該当節を参照してください。
実務でどう判断するか
整理して見えてきた勘所は4点です。
「学習しない」と「保存しない」は別物です。エンタープライズAPIは学習利用こそデフォルトオフですが、Abuse Monitoring目的の保持(多くは30日)は別に走っています。
ZDRは全消し設定ではありません。OpenAIのキャッシュやCode Interpreter、GoogleのGrounding、AnthropicのUser Safety分類スコアなど、ZDRを有効にしても残るものが各社にあります。機能単位で棚卸ししてください。
同じサービスでも、選んだモデルで結論が変わります。Claude Fable 5 / Mythos 5はZDR契約下でも30日保持が必須、OpenAIはdall-e系がZDR不可・gpt-image系が可です。実際に叩くモデルまで落として確認してください。
デフォルトの保持挙動はサービスやプランで真逆になることがあります。同じAnthropicでも素のAPIは非保持、Team / Enterpriseはカスタム設定しない限り無期限で、PLaMoも有償Standardは非保持・無償Freeは対象外です。ZDRも各社とも承認制・上位契約前提なので、全業務に引くのは過剰です。データを分類し、極秘データを扱う経路には確実にZDRを当てるのが現実的です。
セキュリティレビューでは、AIサービスについて「①学習利用 ②保持期間 ③ZDR可否と例外 ④利用モデル ⑤リージョン/契約要件(承認制か・BAA/DPA〈データ処理契約〉有無)」の5点を、最低限のチェック項目として確認すべきだと思われます。モデルが1つ増えても、この5軸に当てはめれば整理できます。今回のFable 5のように同じサービスでもモデルで結論が変わることがあるため、④利用モデルは独立した観点として持っておくとよいでしょう。
各社ポリシーは改定が速い領域です。この記事の数値も、実務判断の前には必ず一次情報で再確認してください。
参考(主な一次情報)
- OpenAI: Data controls in the OpenAI platform / Enterprise privacy at OpenAI
- Anthropic: API and data retention / How long do you store my data? / How long do you store my organization’s data? / Custom data retention for Enterprise / ZDR agreement — supported products
- Google: Zero data retention in the Gemini Developer API
- Preferred Networks: PLaMo API ドキュメント / PLaMo API プラン / PLaMo API 利用規約
- Sakana AI: Fugu Terms of Service / 金融個人データ保護指針