データエンジニアリング連載の3本目です。
はじめに
こんにちは、フューチャーの鈴木風真です!
S3 Tables(Iceberg形式)にはtimestamptz(タイムゾーンつきタイムスタンプ)という型があります。今回、このtimestamptz型でカラムを登録しようとしたとき、いろいろ面白い発見があったので、記事にしたいと思います。
timestamptzとは
timestamptzはApache Icebergにおける型の種類の一つで、タイムゾーン付きタイムスタンプと呼ばれます。その名の通り、「日本時間」などのタイムゾーン情報とともに時刻を保持できる型です。時差に左右されない世界中の「まさにあの瞬間!」という絶対的なタイミングを記録できる便利なデータ型です。
日本時間で書き込んでも別の国の時間で書き込んでも、内部的にはすべてUTC(協定世界時)に揃えて保存してくれるため、あとから時間を計算し直すような面倒な手間がかかりません。
Athenaから登録することはできない!?
Athenaからtimestamptz型を含むCREATE文を書いてS3 Tablesを登録してみましょう。するとこんなエラーがでます。
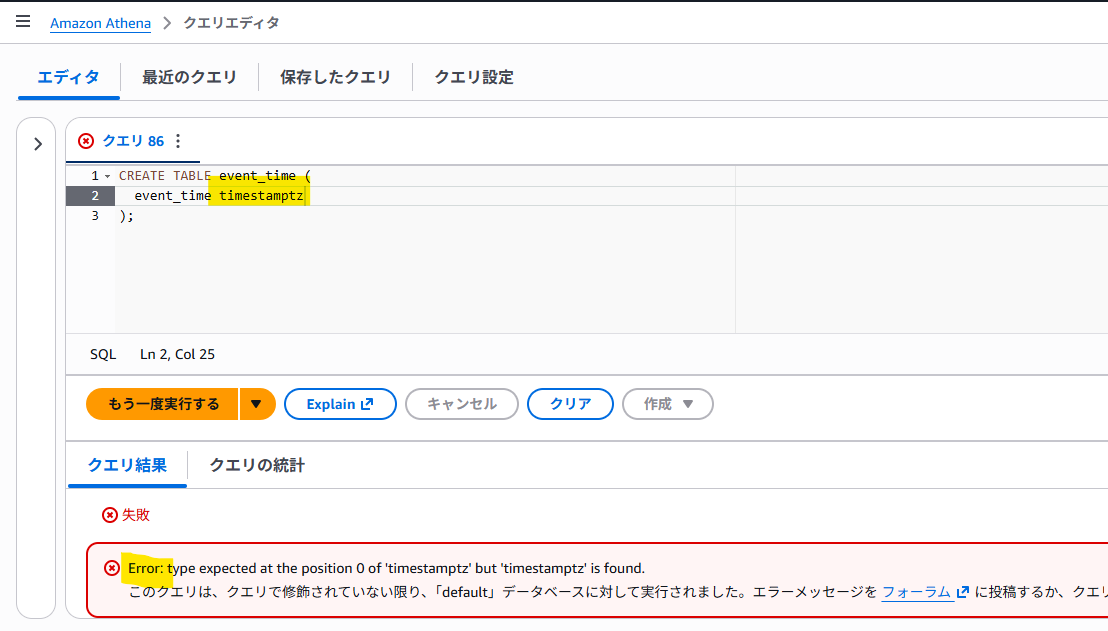
timestamp with timezoneに変えて実行してもうまくいきません。AWS公式サイトを確認してみると、以下の文言が。。。
CREATE TABLE などの Athena Iceberg DDL ステートメントでサポートされているのは、Iceberg タイムスタンプ (タイムゾーンなし) のみですが、Athena を介してすべてのタイムスタンプ型をクエリできます。
Athena の Iceberg テーブルでサポートされているデータ型
つまり、AthenaではtimestamptzのSELECTはできるがCREATEはできないということです。(なんじゃそれ!)この時点で、AthenaでDDLを実行してテーブルを作成する選択肢はなくなりました。
調べてみると、AWS Glue経由でDDLを実行すると、timetamptz型も登録できるようです。DDL実行用のGlueジョブを作成するのは少々面倒でしたが、Glueを使えば、DDLファイルの配置→配置をトリガーにDDLを実行 みたいなパイプラインを作るのもやりやすいかなと思い、Glueでやることにしました。
Glue経由でDDLを実行
というわけで、簡単なDDL実行用のGlueジョブを作ってみました。
DDLファイルには複数のCREATE文を含む想定で、Glueジョブ側でステートメントごとにループ処理させるようにしました。既存のテーブルを登録しようとするとエラーになりますが、かといってDROP TABLE IF EXISTSみたいなことをやって事故るのは怖かったので、あえてそのままエラーになるようにしています。結果として、100行程度のシンプルなGlueジョブになりました。
# ... (boto3やGlue、Spark関連の標準的なimport文は省略) ... |
次にDDLファイルを用意します。その前に、S3 Tables(Iceberg)と、Glue(Spark SQL)、AthenaのSQLにおけるtimestamp型の対応を確認します。
Icebergのタイムスタンプ型対応表
| Icebergの型 | 説明 | Spark SQLのDDL | AthenaのDDL |
|---|---|---|---|
timestamptz |
タイムゾーンつきタイムスタンプ | TIMESTAMP |
定義不可 (※Spark等で作成する必要あり) |
timestamp |
タイムゾーンなしタイムスタンプ | TIMESTAMP_NTZ |
TIMESTAMP |
表で書くと分かりやすいですが、ここに大きなトラップがありますね!
つまり、
- Spark SQLで TIMESTAMP と書く → timestamptz(タイムゾーンあり)になる
- Athenaで TIMESTAMP と書く → timestamp(タイムゾーンなし)になる
という風に、同じTIMESTAMPと指定しても真逆になるということです。
したがって、Spark SQLだとtimestamptzに相当するのが「TIMESTAMP」になるので、作成するSQLファイルでは単にTIMESTAMPと定義しておきます。
※当然「timestamptz」と定義すると「そんな型はない!」とエラーになります。
CREATE TABLE event_time ( |
このDDLファイルをS3に配置します。Glue側でSQLファイルパスをパラメータで指定してあげると、それをGlueが見に行って実行してくれるようにしました。
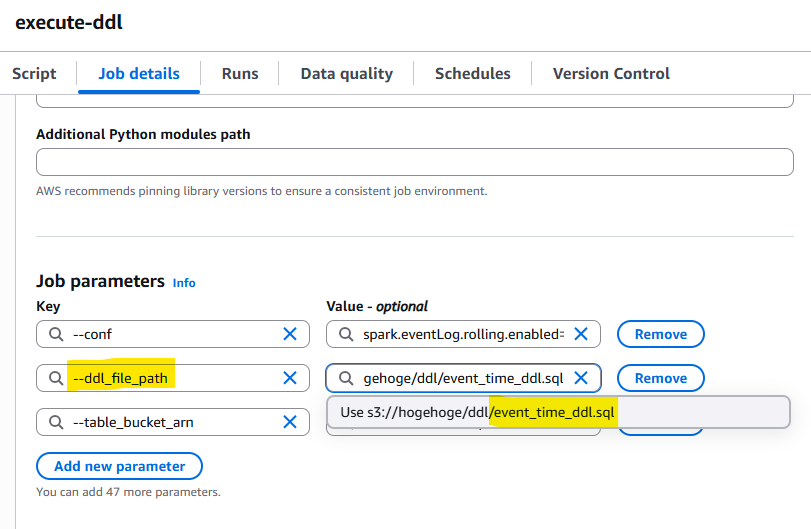
試しに実行してみます。すると1分ほどで成功します。簡単な処理でもGlueって結構遅いんですよね。
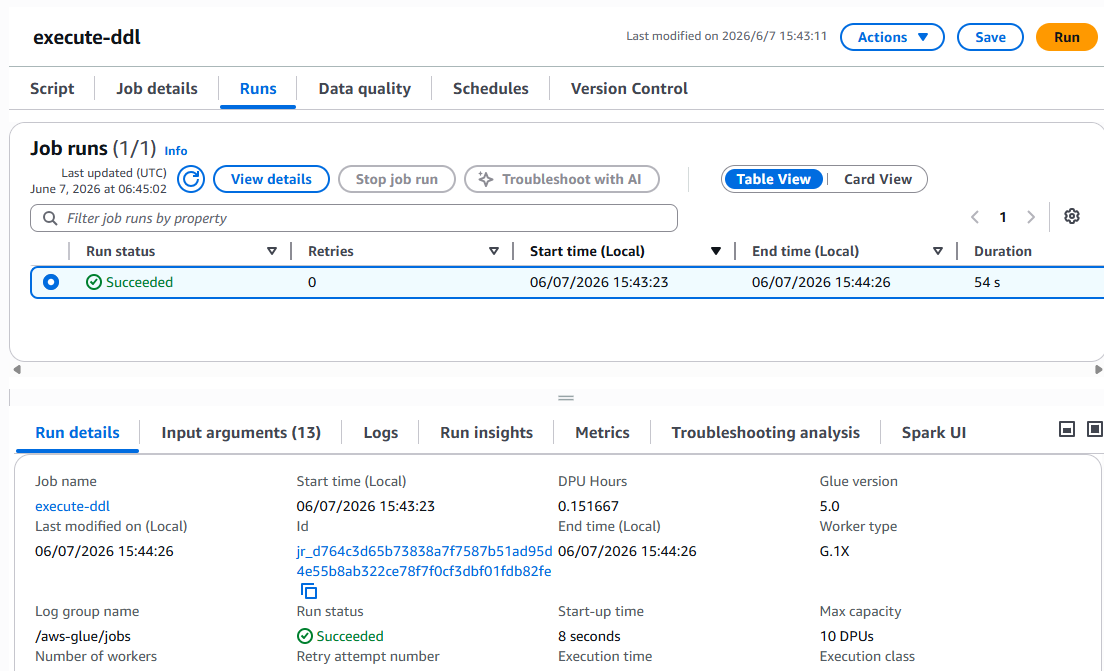
実際にテーブルが作成されているかを見てみましょう。S3の画面から作成されたテーブルを見てみます。
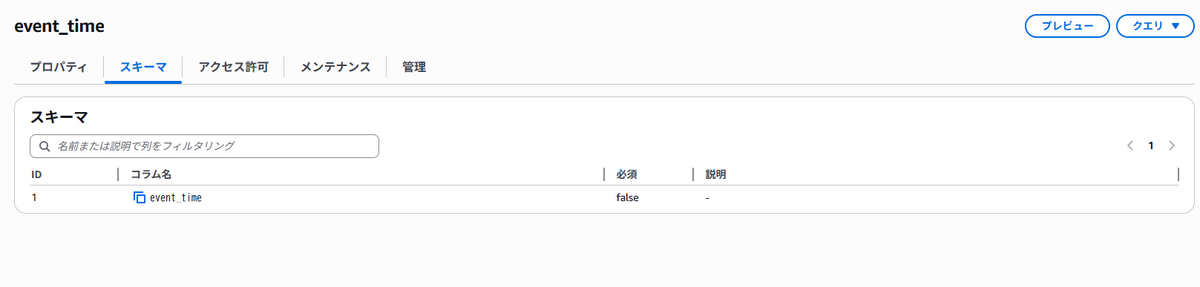
たしかに、テーブルが作成されていることを確認できます。しかしこれだと、型が確認できないので肝心のtimestamptz型が登録されているかが分かりません。そこで、Athenaから登録されたテーブルを見てみます。Athenaからはエディタの画面からテーブルのデータ型が確認できます。
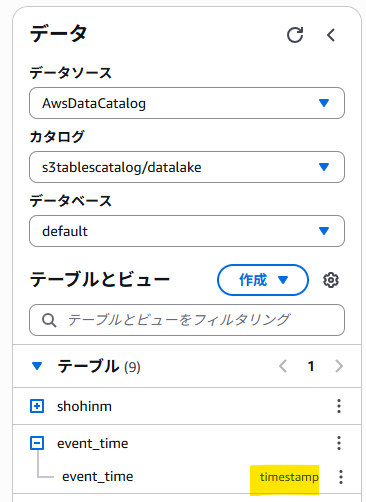
よしよし、ってあれっ?timestamptzになってない!
Athenaからtimestamptzは確認できない!?
どういうわけか、わざわざGlue経由でDDLを実行したのに、timestamptzで登録されていないです。しかし、SparkにおけるtimestampはIcebergだとtimestamptzになるはず、、もしかして、Athena画面上の表示の問題か? …というわけで、テーブル定義そのものを覗いてみることにしました。テーブルの実体は、S3のテーブルバケットから確認できるように、メタデータで定義されています。
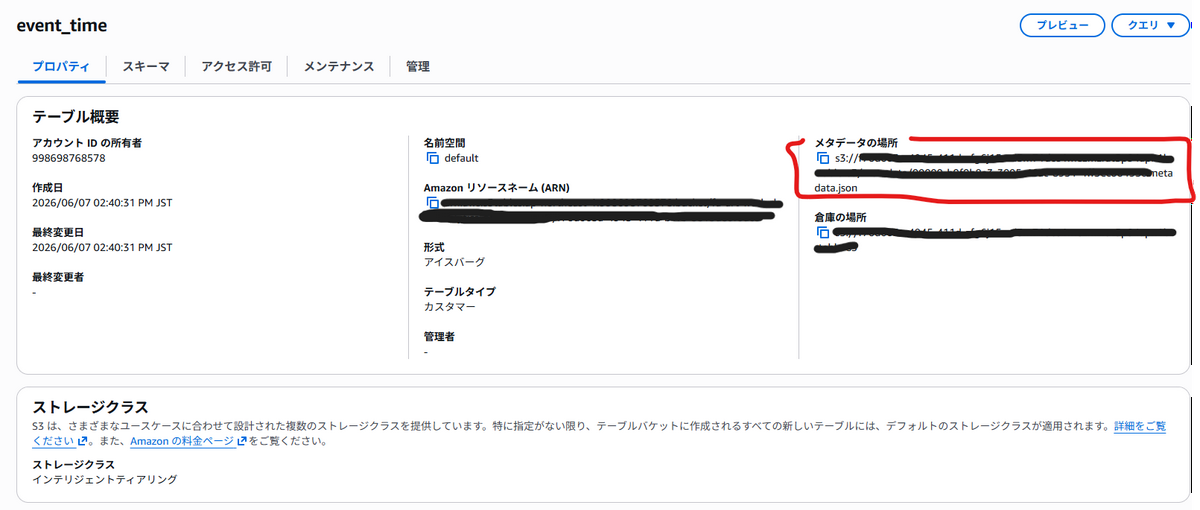
このファイルはダウンロードしてみることはできないので、AWSコマンドを叩いて覗くしかないです。以下コマンドを実行してみます。
aws s3 cp [テーブルメタデータARN] - | jq . |
(jsonファイルの中身を取得し、コマンドライン上で見やすく表示させる簡単なコマンドです)
すると、こんな結果が返ってきます。
"schemas": [ |
いや、ちゃんとtimetamptzで登録されてる笑
逆にAthenaで登録したテーブルはしっかりタイムゾーン無しtimestamp型で登録されていることも確認できます。つまり、Athenaではtimestamp型もtimestamptz型も、画面上では書き分けずに表示する仕様っぽいです!ややこしいですね!
S3 Tablesの型定義がS3の画面上から確認できないなど、S3 Tablesは新しい技術だからか、まだ整備されていない感があるなと思いました。
おわりに~AI時代の技術ブログについて~
この記事では、試行錯誤する中での驚きだったり笑いなどの感情を乗せて書くことを意識しました。
AIで答えがすぐに得られる時代に、技術ブログに求められることは何だろうかと考えたとき、それはファクトと人間味なのではないかと思います。AIはハルシネーションも起こすし、結局のところ「言っているだけ」です。だからこそ、「実際にやってみた」というファクトが価値を持つと思います。その次に人間っぽい感想。筆者が何を考え、感じたのか。一読者としてはそれが見たいです。
今回の記事も、せんじ詰めれば「timestamptzはAthenaからだと登録できないが、Glue経由なら登録が可能。型の確認はメタデータを直接見る必要がある」というだけです。でも、それだけだと面白くない。その答えにたどり着くまでの、推理・発見・驚き・笑いといった、人間味のある試行錯誤の過程が、一読者としては読みたいです。
自分含め、トラブルシュートで「ググる」人はどんどん減っている気がします。それに伴いあらゆるWebサイトは徐々に見られなくなっている。そんな時代でも「フューチャーの技術ブログは読みたい」と思ってもらえる記事を出していきたいなと思っています。最後まで読んでいただきありがとうございました!