免責事項
- 有志で作成したドキュメントである。フューチャーには多様なプロジェクトが存在し、それぞれの状況に合わせて工夫された開発プロセスや高度な開発支援環境が存在する。本ガイドラインはフューチャーの全ての部署/プロジェクトで適用されているわけではなく、有志が観点を持ち寄って新たに整理したものである
- 相容れない部分があればその領域を書き換えて利用することを想定している。プロジェクト固有の背景や要件への配慮は、ガイドライン利用者が最終的に判断すること。本ガイドラインに必ず従うことは求めておらず、設計案の提示と、それらの評価観点を利用者に提供することを主目的としている
- 掲載内容および利用に際して発生した問題、それに伴う損害については、フューチャー株式会社は一切の責務を負わないものとする。掲載している情報は予告なく変更する場合がある
はじめに
バッチ処理とは、大量のデータを一括で処理するための手法であり、システム開発において今なお重要な位置づけにある。バッチ処理の対義語は逐次処理(リアルタイム処理・ストリーム処理とも呼ぶ)であり、業務イベントが発生する度に何かしらの処理を実行することを指す。逐次処理は処理結果を即時確認できるが、それによってユーザー体験(UX)の向上しない場合や、開発コストの低減(基本的には逐次処理の方が設計・運用の難易度が高い)・コンピュータ資源を下げたいなどに、バッチ処理を選択することが多い。
バッチ処理は多くのシステムで存在するが、その規模や複雑度、システムにおける重要度は千差万別である。最も単純なケースではcronのようなスケジューラを用いて、バッチプログラムを単発起動で事足りるケースもある。より複雑なシステムでは、ワークフローエンジンを用いてDAGやジョブネットで管理すべきケースもある。
また、バッチ処理はバックグラウンドで起動するため、データ量によっては実行時間が数十分に達することもよくある。フロントエンドから呼ばれるWeb APIは1、2秒以内での応答速度を求められることと対象的である。そのため、バッチ処理はその特性上システム全体のパフォーマンスや運用効率に大きな影響を与える。本ガイドラインでは、バッチ処理設計におけるベストプラクティス、設計時の考慮点、運用における課題とその対策について詳述する。
適用範囲
本ガイドラインは、バッチの設計、開発時に利用することを想定しているが、バックエンド領域で関連性が高いと考えられる以下の内容も含む。
- ジョブスケジューラ
対象とする技術は以下を想定している。
- AWS、Google Cloud、Azureなどのクラウドサービスを用いての開発。設計観点などの説明には、特にAWSを例に上げることが多い
定義
- バッチ処理: 大量のデータを一括で処理するプログラミングモデルのこと
- バッチ設計: 本ガイドラインでは、「バッチ処理を行うプログラムの設計」を指す
- ジョブ: バックグラウンドで動かす1つ1つのタスクを定義・実行するための基本単位。AirflowでいうOperatorに該当。ジョブで行う処理は様々で、ヘルスチェックのWeb APIを呼び出し成功失敗の判定するだけのジョブもありえる。本ガイドラインではジョブからバッチ処理を呼び出すことを指すことが多い
- ワークフロー: 相互に依存関係を持つ複数ジョブの流れを定義したもの。JP1ではジョブネット、AirflowではDAGに相当する
- オンライン操作: 画面操作のこと
ワークフローエンジン
概要
ワークフローエンジンとは、一連のタスクを自動化し、定義済みの順序に基づいた実行を管理するツールである。他にも、業務プロセスの承認フローを制御するようなツールもワークフローエンジンと呼ぶが、本ガイドラインでは前者をワークフローエンジンと呼ぶ。
ワークフローエンジンに求められる主な要件は以下である。
| 分類 | 項目 | 説明 |
|---|---|---|
| 起動制御 | 定時起動 | cronジョブのように、日次 20:00 といった起動が可能かどうか |
| サイクル起動 | 5分間隔といったスケジュール起動が可能かどうか | |
| イベント起動 | オブジェクトストレージへのputイベントなどによる起動が可能かどうか | |
| 繰越実行 | 前回のジョブが失敗で終了した場合に、次の起動条件を満たした場合に再実行するかどうか。サイクル起動などで制御したい場合がある | |
| 追い越し実行 | 前回のジョブが実行中に、次の起動条件を満たした場合に実行するかどうか。サイクル起動やイベント起動での重複起動を防ぎたい場合 | |
| フロー制御 | 順序制御 | タスク間に依存関係を作ることができるか |
| エラー制御 | 上流のタスクが失敗したら、下流のタスクを停止させることができるか | |
| 並行分岐 | タスクAが終了後、タスクB、Cを2つとも起動させることができるか | |
| 合流(待ち合わせ) | 並行分岐したフローのタスクが全て正常終了したことを待ち合わせて、別のタスクを起動させることができるか。定時起動と順序起動のAND条件も含む | |
| 条件分岐(排他分岐) | タスクAの終了後に特定の条件に従って、タスクBまたはCを実行できるか | |
| 並列実行(分散) | 例えば4並列などに分散実行ができるか。分散数は固定/動的の両方とする | |
| 集約 | 分散実行された全タスクの成功を待ってから、次のタスクを実行できるか | |
| パラメータ | タスク間パラメータ連携 | あるタスクで生成したパラメータを下流のタスクに引き継げるか |
| 構造化 | グループ化 | タスク定義をシステム種別などの単位でグルーピングして管理できるか。視認性や影響度調査のため |
| ネスト定義 | タスク定義をネストして表現できるか。視認性や影響度調査のため | |
| 可視化 | フロー定義ビューア | タスクの依存関係をビューアで確認できるか |
| 実行ビューア | タスクの実行状態をビューアで確認できるか。実行前、実行中、異常終了、正常終了などが区別できることが望ましい | |
| 手動操作 | フローのリラン | 失敗したタスクが保続するフローを最初から再実行できるか |
| 個別タスクのリラン | 失敗したタスクだけを後からリランできるか | |
| 手動実行 | 成功/失敗を問わず、そのタスクだけを手動で実行できるか | |
| パラメータ上書き | リラン/手動実行を問わず、実行時のパラメータを手動で上書きできるか | |
| タスクの強制終了 | 予期せぬ長時間起動したタスクを終了させることができる | |
| タスクの無効化 | タスクを一時的に停止でき、起動条件を満たしても、起動が無視される | |
| タスクの有効化 | 停止されたタスクを再開できる。停止中に発生した起動は無視され、次の起動条件を満たすまで待機する。上流のタスクが正常終了済みであれば、下流タスクはそこから再開する | |
| スキップ | 特定のタスクをフロー定義から一時的にスキップできるか(該当タスクの無効化+次のタスクを手動再実行でも再現可能) | |
| その他 | QoS | タスクの起動について抜け漏れはないか(At Least once 以上か) |
| 可用性 | ワークフローエンジンが単一障害点とならないように、可用性を高める仕組みが必要 | |
| コード管理 | ワークフロー定義はコードで管理できるか(Gitでバージョン管理できるか) |
プロダクト選定(AWS)
システム開発におけるワークフローエンジンは、保守運用性に大きく影響する。そのため、組織で統一した仕組みを導入することが望ましい。例えば、すでに存在する保守運用体制がJP1のような製品を利用しており、構築したシステムやサービスの運用引き継ぎが将来的に現行の保守体制に行われるのであれば、利用するワークフローエンジンも統一させることが自然である。
一方で、新規事業開発やデータエンジニアリングのように、細かいサイクルで試行錯誤が求められる領域ではより軽量なワークフローエンジンを導入することが有効な場面もある。AWSではStepFunctions、Airflow(MWAA: Amazon Managed Workflows for Apache Airflow)が比較されることが多い。
【製品比較例 ※2025年2月時点】
| 分類 | 項目 | StepFunctions | Airflow |
|---|---|---|---|
| 起動制御 | 定時起動 | ✅️Event Bridgeと組み合わせ | ✅️`schedule_interval` |
| サイクル起動 | ✅️Event Bridgeと組み合わせ | ✅️`schedule_interval` | |
| イベント起動 | ✅️ | ✅️Task Sensor | |
| 繰越実行 | ❌️個別開発(外部DBを利用した状態管理など) | ✅️ `depends_on_past=true` や `trigger_rule` | |
| 追い越し実行 | ✅️ステート名で制御 | ✅️ `depends_on_past=true` | |
| フロー制御 | 順序制御 | ✅️ | ✅️DAG定義 |
| エラー制御 | ✅️Retry、Catch | ✅️ | |
| 並行分岐 | ✅️Parallelステート | ✅️DAG定義 | |
| 合流(待ち合わせ) | ✅️Parallelステート | ✅️DAG定義 | |
| 条件分岐(排他分岐) | ✅️Choiceステート | ✅️BranchOperator | |
| 並列実行(分散) | ✅️Parallelステート | ✅️DAG定義 | |
| 集約 | ✅️Parallel、Mapステート | ✅️DAG定義 | |
| パラメータ | タスク間パラメータ連携 | ✅️XComなど | ✅️InputPath ResultPath など |
| 構造化 | グループ化 | ✅️ステートマシン分離 | ✅️`TaskGroup` |
| ネスト定義 | ✅️Nested Workflows | ✅️`TaskGroup` | |
| 可視化 | フロー定義ビューア | ✅️AWSコンソール | ✅️Web UIある |
| 実行ビューア | ✅️AWSコンソール | ✅️Web UIある | |
| 手動操作 | フローのリラン | ✅️ | ✅️ |
| 個別タスクのリラン | ✅️2024年にサポート | ✅️ | |
| 手動実行 | ⚠️最初のタスクからのみ実行可能 | ✅️ | |
| パラメータ上書き | ✅️ | ✅️ | |
| タスクの強制終了 | ✅️ | ✅️ | |
| タスクの無効化 | ❌️ | ❌️条件文で制御(UIから一時スキップは可能) | |
| タスクの有効化 | ❌️ | ❌️条件文で制御 | |
| タスクのスキップ | ❌️ | ❌️条件文で制御(UIから一時スキップは可能) | |
| その他 | QoS | ✅️At Least Once | ✅️At Least once |
| コード管理 | ✅️JSON/YAML | ✅️Python |
推奨は以下。
- 保守運用体制への引き継ぎがあり、JP1などの製品がすでに導入されているのであれば、既存製品の利用を第一に検討する
- 構築対象の領域が、ジョブが少なく依存関係も存在しない場合、AWSの場合はStep Functions や Airflow の導入を検討する
- 原則、Airflowを推奨するが、複雑なタスク間の依存関係がなく、コスト要件が厳しい場合は、Step Functionsの利用も検討する
ワークフローが存在しない場合(AWS)
システム特性によっては、ワークフローの「概要」節で求められるようなタスク定義が不要な場合がある。例えば、1日1回、あるタスクが起動できればよく、タスク間の依存関係(フロー)が存在しないケースである。このような場合は、AWSではEventBridge Schedulerで ECS(ecs run task) などを呼ぶという軽量な手法もある。このようなケースでは、Airflowのようなワークフローエンジンは牛刀かもしれず、EventBridgeから直接ECSを呼び出すか、Step Functionsを経由させるといった軽量な手法が採用されることが多い。
| # | (1)EventBridge Scheduler | (2)Step Functions |
|---|---|---|
| 説明 | スケジューラからECSやLambdaを呼び出す形式 | スケジューラからStep Functionsのステートマシンを呼び出し、内部的にECSやLambdaを呼び出す形式 |
| 構築コスト | ✅️最小限の構成となる | ❌️余計なインフラリソースが増える |
| クラウド費用 | ✅️最小限の構成となるため | ⚠️Step Functionsのコストは安いとはいえ、追加費用が発生する |
| 拡張性 | ⚠️Step Functionsでラップする必要 | ✅️後々、依存関係が追加される場合には便利 |
| リラン操作 | ✅️スケジューラ経由のリランは不可。ECSやLambdaの画面から再実行する | ✅️Step Functionsのステートマシン(タスク)を再実行する |
推奨は以下。
- 現時点で、依存関係が存在しない場合、(1)を利用する
- アプリ終了後に通知を飛ばしたいといった要件程度であれば、アプリ側でロジックを追加すればよい
- まだ発生していない拡張要件への備え、早すぎる最適化であるため
- 将来的な、依存したタスクの追加が判明している場合は、(2)を採用する
- 後で切り替えることも現実的な作業量で可能だが、面倒には違いないため
- (1)、(2)の構成が混在することは許容する(ハイブリッド型)
- リランの操作方法が、ジョブごとに異なってしまうが、運用マニュアルでカバーすること
- そもそもが、ジョブ数が少なくシンプルという前提があるため
- もし、大多数が単発ジョブしか存在しないが、数が多く運用の一貫性を図りたい場合は、(2)に統一する方式を取る
ジョブ間パラメータ動的連携(AWS)
あるジョブで動的に生成したパラメータを、後続のジョブに連携したい場合がある。Lambdaの同期呼び出しの場合は直接戻り値を取得できるが、ecs run task の場合は非同期呼び出しのため、DBやオブジェクトストレージを経由するなどの工夫が必要である。この時、ワークフローの重複起動を考慮すると、ワークフロー実行毎に一意のID(リクエストIDやトランザクションIDと呼ぶ場合もある。以降はトランザクションIDと呼ぶ)を生成し、ワークフローの各ジョブで共有する必要がある。
トランザクションIDの発行と共有について、以下の設計パターンが考えられる。
| # | (1)アプリ制御 | (2)ワークフローエンジン制御 |
|---|---|---|
| 説明 | できる限りアプリケーションで制御する方法。トランザクションIDの採番や、ジョブ実行時に利用すべきトランザクションIDの特定をアプリケーションで行う。特定したトランザクションIDを元に、DBやオブジェクトストレージなどを検索し、パラメータを取得する。リランや重複起動への対処など考慮点が多数ある | ワークフローエンジン上で検索用のトランザクションIDを発行し、各ジョブに連携する。各ジョブはトランザクションIDをキーにパラメータ連携する。Airflowでは dag_run.run_id を用いるか、UUID発行 & XComの利用を利用 |
| 開発コスト | ❌️アプリ側の考慮点が多く、枯れるまで一定の動作実績が必要な場合が多い。フレームワーク化が必要なことが多い | ✅️Airflowなどでは一般的な設計 |
| 品質 | ⚠️独自実装部分が多く複雑である | ✅️各アプリロジックはシンプルに抑えられる |
| 運用性 | ⚠️独自の設計方針に従う。学習コスト高 | ✅️より一般的な運用方針に従う。ナレッジの転用が可能 |
| 移植性 | ✅️アプリに閉じて設計が可能。移植しやすい | ❌️ワークフローエンジンに依存する |
推奨は以下。
- 原則、(2)を採用する
- ワークフローエンジンへの依存度は高くなるが、アプリ側に寄せると開発コストが高くなるため
- ワークフローエンジンにこういった機能を寄せることは、特殊ではないため
動的なワークフロー
ワークフローの定義を動的に組み替えたい場合がある。例えば、あるジョブの実行結果に応じて、後続のジョブの実行数が可変になるような場合がある。AirflowやStep Functions の場合は、それぞれ expand() や Map ステートで対応できる。アプリケーション側での制御も不可能ではないが、フロー制御がアプリケーションとワークフローエンジンの2箇所で行うことになり、複雑になる傾向がある。
| # | (1)アプリ制御 | (2)ワークフローエンジン制御 |
|---|---|---|
| 説明 | ジョブ呼び出しを、ラップするようなアプリケーションを作成し、その実行基盤上で次に呼び出すジョブを制御する方法。ワークフローエンジン経由ではないジョブ呼び出しが追加される | ワークフローエンジン側の機能で対応する |
| 開発コスト | ❌️アプリ側の考慮点が多く、枯れるまで一定の動作実績が必要な場合が多い。フレームワーク化が必要なことが多い | ✅️Airflowなどでは一般的な設計 |
| 品質 | ❌️独自実装部分が多く複雑である | ✅️各アプリロジックはシンプルに抑えられる |
| 運用性 | ❌️運用の一貫性がなくなる | ✅️より一般的な運用方針に従う。ナレッジの転用が可能。エンジン側が提供するビューアなどで実行結果を確認可能 |
| 移植性 | ✅️アプリに閉じて設計が可能。移植しやすい | ❌️ワークフローエンジンに依存する |
推奨は以下。
- ワークフローエンジンの機能を用いて制御する
- もし、ワークフローエンジン上で不可である場合は、アプリ制御する(しかない)
ワークフローエンジン導入パターン
ワークフローエンジンをどこに構築し、だれが運用するか、運用ルールが作成済みか確認する必要がある。大きな考慮ポイントとして、ワークフローエンジンをシステムで専用・共用を決める必要がある。
| # | 占有 | 共有 |
|---|---|---|
| 説明 | 1システムで1ワークフローエンジンを用意するパターン | 複数のシステムで共用するパターン |
| 利用コスト | ❌️JP1のようにライセンスが必要な場合、調達コストが上がる❌️サーバ利用運用がそれぞれ必要 | ✅️ライセンス数を抑えることができる ✅️サーバ数を抑えることができる |
| 構築コスト | ✅️各チームで自律的に利用可能 | ⚠️他チームと共用するためルールが厳しくなる傾向がある ⚠️権限管理などの設計、運用ルールが必要 |
| セキュリティ | ✅️システム単位で権限分離 | ❌️他チームのワークフローが参照できてしまうことや、誤操作の懸念 |
| 分離性 | ✅️システムごとに分離 | ❌️ノイジーネイバーの懸念 |
推奨は以下。
- 組織のシステム化方針などで、「共有」が決まっている場合は従う(運用ルールはどのようになっているか確認する)
- 「共有」が決まっていないが、「JP1」などのプロダクトを利用する必要がある場合は、「占有」方式を採用できないかを第一に検討する。コスト(ライセンス)などの都合で難しい場合は、運用ルールの整備を並行させる
- 利用するワークフローエンジンが、AirflowやStep Functionsの場合は、「専用」で構築する
環境ごとにワークフローエンジンを構築すべきか
デプロイメント環境ごとにクラウドアカウントは分離すべきである。
AirflowやStep Functionsを採用した場合は、権限などの観点からもデプロイメント環境ごとにワークフローエンジンを構築することが望ましい。
ワークフロー設計
主な設計観点として以下の項目がある。
- ワークフロー命名規則
- ネスト階層数
- フロー間の依存設定
ワークフロー命名規則
ワークフローの命名は保守運用性に直結する。dag1 や task1 といった連番ではなく、 目的や役割が明確な命名をすべきである。ワークフローエンジンはワークフローエンジン導入パターン 章の通り、システムごとに構築する前提であればシステム名などのプレフィックス・サフィックスは付与する必要はない。
推奨は以下。
- 表示名:
- 日本語にしても良い
- ID:
calc_order など
✅️発注量計算するワークフローの命名
calc_order❌️不適切なワークフローの命名
dev_myproject_calc_order_v1ネスト設計
ワークフローは、AirflowではTaskのグループ化・JP1ではジョブネットを用いることでネストさせることで抽象的に管理ができる。
全体のタスク数の規模や複雑度に大きく依存するが、一般的にネストを深くしすぎると、運用時の操作性が複雑になる点や、過度な抽象化で具体的に何を行っているかの把握が難しくなるというトレードオフが存在する。
推奨は以下。
- 原則、最大のネスト数を3階層に抑える(※基準となる数値はチームごとに決めて良い)
- ワークフローはできる限りフラットに管理し、見通しが悪くなってきた場合でネスト化を検討する
- ネスト化は、処理レイヤー(例えばファイル受信、加工・ファイル送信など)や、機能分類など、関連性がある場合に用いる(良い命名ができる場合にのみ留める)
- リランのしやすさを考慮して、ネストの設計を考慮する
- 例えば、処理レイヤー(ファイル受信など)単位でネスト化すると、リランは全ファイル種別を再取り込みする、という意味合いが生まれる
- あるファイル種別のみリランしたいことを考えると、処理レイヤーではなく機能分類の方が、ネスト化として望ましい可能性がある
- ネスト化させる場合、レベル感が同一のタスクのみとする(例えば、特定のタスクのみ際立って実行時間が長い場合は、分離することを検討する)
以下の場合はネストしたワークフローは作成しない。
- 全体のタスク数が20未満と少ない場合(※基準となる数値はチームごとに決めて良い)
- ネスト対象のタスク数が、2以下である場合(※基準となる数値はチームごとに決めて良い)
- ネストしたタスクの集合を示す、良い命名ができない場合
| ✅️例: 機能分類でネスト化 | ❌️例: 関連性の高いが処理レイヤーでネスト化 | ❌️例: レベル感が不揃いのネスト化 |
|---|---|---|
| 関連度の高いタスクを集約し視認性を上げ、リランはファイル種別単位で行うことを想定 | 関連度の高いタスクを集約し視認性を上げているが、リランのユースケースとして、全ファイル種別をやり直すことは考えにくい | マスタ取り込みに改廃処理が存在し名称と不一致。サマリ作成にMVIEWリフレッシュがありレベル感が不一致。受注予測と発注量を束ねた名称の抽象度が高すぎる |
 | 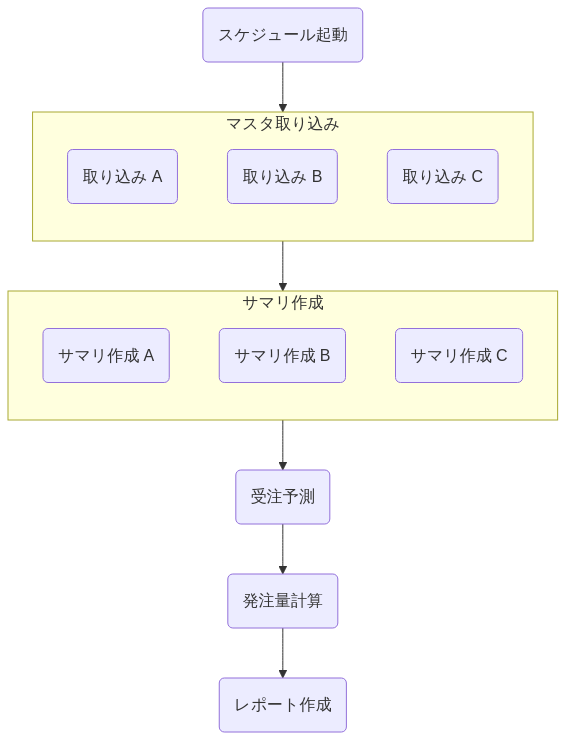 |  |
フロー間の依存関係
フローAが終了後に、フローBを呼び出したい場合がある。結合度が高い場合はA、Bを統合するということも考えられるが、業務的な区切りを表現したいなど、分離させたまま管理したい場合も多い。この時、フロー同士の依存関係をどのように表現、管理するかいくつかの方式が考えられる。
| # | (1)ワークフローエンジンのイベント通知 | (2)外部データストア経由 |
|---|---|---|
| 説明 | 上流のフローの完了を下流のフローが監視するか、上流のフローの最後に下流のフローの起動を呼び出す方式 | DAG間で直接依存関係を持たせず、データストア(S3, GCS, DBなど)を介してデータを連携する方式 |
| 例 | Airflowでは ExternalTaskSensor や TriggerDagRunOperator、JP1ではイベント送信が該当 | オブジェクトストレージへのputイベントなどが該当 |
| 視認性 | ✅️ワークフローエンジン側のビューアなどで依存関係が表示され便利 | ❌️ビューア上は依存関係が表示されない |
| 柔軟性 | ⚠️連携対象のフローを明示的に指定する必要があるため、結合度が上がる | ✅️各DAGは独立性を高くしてデプロイが可能である |
| 運用性 | ✅️リランや手動実行などの運用は通常の差が無い | ⚠️リランはデータストアへの操作が必要になり、運用難易度が上がる。ただしリラン用のタスクを作成すれば緩和可能 |
| 保守対象 | ✅️インフラ対象としては最小限 | ❌️外部データストアのインフラ管理対象が増える |
推奨は以下。
- 原則、(1)を採用する
- Airflowであれば実装コストが低い(外部データストアを経由させるほうが、手数が増える)
- (1)を採用し、上流のフローから下流のフローを明示的に呼び出す場合は、ネストの深いところではなく浅い層から呼び出す
- 依存関係を明示的にし、視認性を上げるため
バッチコントローラ
バッチコントローラとは本ガイドライン独自の用語である。これを利用すると、ワークフローエンジンからバッチ処理を呼び出す際に、バッチコントローラを経由して、コンピューティングリソースを起動する構成を取ることができる。この時、透過的な計算資源の呼び出し・流量制御・リトライ・タスクの終了判定などを責務として持つことも多い。これにより、ワークフローエンジンの責務を小さくし、バッチ呼び出しの統制を効かせることができる。
【バッチコントローライメージ】
バッチコントローラの導入の是非について、観点を下表でまとめる。
| # | (1)バッチコントローラあり構成 | (2)バッチコントローラレス構成 |
|---|---|---|
| 説明 | バッチ処理を実行するためのコンピューティングリソースの呼び出しを、バッチコントローラ経由で行う構成。バッチコントローラは任意の言語で実装できるため、技術スタックを揃えたい場合には有利 | ワークフローエンジンから直接、コンピューティングエンジンを呼び出す方式。SDKをワークフローエンジン側にインストールする必要がある。AirflowであればPythonでの実装量が増える傾向がある |
| 開発生産性 | ⚠️バッチコントローラ側に定義情報の登録が必要となることが多く、ワークフローエンジンのフロー定義以外の設定が必要 | ✅️フロー定義は一箇所になる |
| 開発難易度 | ✅️バッチコントローラにバッチ呼び出しを集約可 | ⚠️各ワークフロー定義にて、振り分けやリトライなどの制御を入れる必要がある。Airflowでは関数化などで緩和可能 |
| 運用性 | ⚠️バッチコントローラ分、障害ポイントが増える | ✅️必要最小限の構成 |
| 費用 | ❌️バッチコントローラ分のリソースが追加で必要。バッチコントローラがSPOFにならないように冗長構成を取ることや、バッチコントローラはDBを必要となることが多い | ✅️必要最小限の構成 |
推奨は以下。
- 原則、(2)の方式を採用する
- Airflowであれば、コンピューティングの呼び出しやリランなどの制御が比較的容易
- レイヤーを減らすことで、管理対象を減らすことができる
バッチ実行モデル(AWS)
バッチの実行基盤は、AWSであれば以下3つから選定されることが多い。
| # | (1)スタンドアローンタスク | (2)ファンクション呼び出し | (3)Web API呼び出し |
|---|---|---|---|
| 分類 | ワンショット | ワンショット | 常駐サーバ |
| 説明 | バッチ処理用のプロセスを起動させる方式。ここではコンテナアプリを動かすことを想定 | バッチ処理をサーバレスのファンクションで呼び出す方式。スタンドアローンタスクに近い | バッチ処理をWeb APIサーバ上で動かす方式 |
| AWSでの例 | ecs run task | lambda invoke | ECS上のWeb APIを呼び出し |
| 実行時間制限 | ✅️無限(非同期のため) | ❌️15分 | ⚠️ALBのアイドルタイムアウトの場合60分 |
| 起動のオーバーヘッド | ❌️数秒程度(FargateかつVPC内の場合は1分程度見ておくと良い) | ⚠️数百ms程度 | ✅️常駐モデルでは無視できる程度。コールドスタートの場合は数秒程度 |
| GPU利用 | ⚠️Fargeteの場合は利用不可。EC2モードの場合は可能 | ❌️利用不可 | ⚠️Fargeteの場合は利用不可。EC2モードの場合は可能だが、GPU資源の取り合いが懸念 |
| 費用モデル | ✅️利用分のみ | ✅️利用分のみ | ✅️オートスケーリングでゼロにできる |
| RI | ✅️Savings Plans | ✅️Savings Plans | ✅️Savings Plans |
| 終了判定 | ⚠️非同期実行のため ecs describe tasks で判定(API呼び出し数に制限あり) | ✅️同期呼び出しが可能(戻り値も取得可能) | ✅️リクエスト/リプライの同期呼び出し |
| 分離性 | ✅️リソースの独立性は高い | ✅️リソースの独立性は高い | ⚠️サーバリソースを共有している |
| リスク | ❓️東京リージョンでは時間帯によってリソースを確保できない可能性がある。EC2起動で緩和可能 | ❓️東京リージョンでは時間帯によってリソース確保ができないユーザーが出たという噂があった | ❓️東京リージョンでは時間帯によってスケールアウトするためのリソースを確保できない可能性がある。最小設定で緩和可能 |
それぞれ、実行モデルが異なるため、システム特性によって使い分ける必要がある。
推奨は以下。
- Airflow上で直接ビジネスロジックを動かすことは、スケーラビリティの観点から、原則禁止とし、(1)~(3)のモデルから選択する
- バッチ処理の実行時間が分単位(3分以上など)の場合は、(1)を推奨する
- 実行時間の制限が無いため、初期以降やリカバリーなどで定常運用より大きいデータサイズでもタイムアウトせずに実行できる点が良い
- 終了判定を行うためのAPIの利用数制限があるため、大規模システムでは回避するための実装が必要になるかもしれないので注意する
- バッチ処理の実行時間が3分未満やバッチウィンドウが秒単位とシビアな場合でかつ、実行頻度が高い場合は(3)を検討する
- スタンドアローンタスクの起動オーバーヘッドを許容できない場合
- 実行時間の制約が60分はバッチ処理では超えることが多々あるため、呼び出しの粒度は予め入力データを分割するなどで工夫する
- (2)はできる限り選択しない
- マイクロバッチなど、起動間隔が1分以下など短い場合に有効
- とにかくコストを抑えたいといった特殊な場合に有効
GPU利用について
機械学習のトレーニングにはSageMakerを利用することも検討する。より大規模でリソース効率を高めたい場合は、AWS Batchを利用する考えもある。
I/Fファイル取り込み
I/Fファイルとはシステム間のデータ連携で利用されるCSVなどのファイルのことを指し、それを自システムに取り込むバッチ処理の設計について説明する。I/Fはオブジェクトストレージを共有して行われるとする。本ガイドラインでは、オブジェクトストレージは自システム側のクラウドアカウント上で構築されるとし、連携システム側が書き込みする前提とする。なお、このファイル取り込み処理を本ガイドラインでは、「受信」と呼ぶ。
いくつかの観点で分類分けはできるが、連携頻度軸で大別すると、以下の2種類が存在する。
- 随時(連携先システムの何かしらの業務イベントが発生の都度連携)
- 定時(1日N回、決められた時間帯に連携)
随時連携
随時連携の場合は、取り込みタイミングは以下の2方式がある。
| # | (1)イベント起動 | (2)ポーリング |
|---|---|---|
| 説明 | オブジェクトストレージの書き込みイベントを元に、受信タスクを起動する | N分間隔でオブジェクトストレージに未処理ファイルが存在しないか監視する方式 |
| 鮮度 | ✅️イベント駆動で処理できるため低遅延(通常、数秒以内にイベントが配信される)にできる | ❌️最大でポーリング間隔分、遅延が発生 |
| インフラ要素 | ⚠️書き込みイベントを取得用のキュー、ワークフロー呼び出しの仕組みが必要 | ✅️ワークフローエンジンからポーリングが可能 |
| 開発難易度 | ❌️イベントの順序制御などの考慮が必要。異常発生時に以降のファイル取り込みを停止させるといった制御が必要な場合は特に面倒 | ✅️順序性は担保しやすい。キューイングの連携が無いため難易度が低い |
| 運用性 | ✅️リラン可能 | ✅️リラン可能 |
推奨は以下。
- 取り込みまでの遅延が許容できる場合は、構成がシンプルとなる(2)を採用することで開発難易度を下げることができる
- なるべく遅延を減らしたい要件の場合のみ(1)を採用する
AWS S3のputイベントの信頼性
かつて、S3のイベント通知は欠損する可能性があるとされ、ポーリング処理と合せ技の必要な時代があった(どうせポーリングが必要であるため、リアルタイム性が求めなければポーリングに寄せることもあった)。
現在はドキュメント上もAt Least Onceであると強調されているため、イベント通知に依存した作りで問題ないと考えられる。
定時連携
定時連携とは、決められた時刻にI/Fファイルが連携される取り決めの場合のことを指す。
随時連携と異なり、本来連携されるはずであったI/Fファイルが定刻になっても未連携だった場合に、対向システムに問い合わせる必要があるため未着チェックが必要である。そのため、下表に示す通り、(1)の手段は採用しにくく、(2)と組み合わせる必要がある。(1)のメリットは低遅延だが、そもそも定時連携の時点でそれが優先されることは少なく、(2)を採用することが多い。本ガイドラインでも②を前提とする。
| # | (1)イベント起動 | (2)定時起動 |
|---|---|---|
| 説明 | オブジェクトストレージの書き込みイベントを元に、受信タスクを起動する | I/Fファイル連携の門限後の、定められた時間にスケジュール起動する方式 |
| 機能要件 | ❌️未着チェックの実装が行いにくく、定時起動との組み合わせが必要 | ✅️未着チェックを行いやすい |
| 鮮度 | ❓️遅延は少ないが、そもそも定時連携の時点で遅延が発生しうるため、イベント起動するメリットは少ないはずである | ⚠️I/Fファイル到着後、定時起動までの間隔の遅延が発生。一定間隔ポーリングさせるなどで緩和可能 |
| 誤送信時の制御 | ❌️対向システムが誤った時間帯に連携してきたファイルは、むしろ取り込みをしないほうが良い場面がある。イベント起動にしてしまうと、こうした制御が逆に面倒である | ✅️決められた時間に存在するファイルのみに対象を絞ることができる |
主な注意点を上げる。
- 未着チェックの関係上、連携したいデータがゼロ件であったとしても空ファイルを連携する仕様となるよう、対向システムと調整する
- もし、不可能な場合は未着チェックを諦める事になる(システム間のデータ連携が予期せぬ不具合で停止しても、検知が遅れる(対向システム側の監視に委ねられる)ことを許容する必要がある)
- 対向システムと未着チェック検知時の運用ルールを詰める
- 問い合わせ先の確認後、手動で送信してもらう取り決めにするなど
- 未着チェックには少し余裕を持たせる場合がある
- 20時に連携予定のファイルだったとしても5分到着を待つ場合もある。例えばなるべく早く取り込みたいが、対向システム側のデータ処理量が大きい場合に多少遅延する場合である。この場合は、定刻から5分間は1分ごとにオブジェクトストレージをポーリングするなどでリトライし、それでも未着だった場合に、エラーログを出し監視通知すると良い
- いちいち、システムで通知を出すと運用が大変であるため、自動化できる運用はアプリケーションロジックに組み込んでも良い
その他の考慮点
その他、I/Fファイル連携には以下のような考慮点がある。
- I/F連携ファイルのオブジェクトキー命名規則
- 差分連携/全件連携(洗替)
- 親子ファイルの待ち合わせ
- 取り込み完了した場合に、オブジェクトを移動させるかどうか
- All or Nothing か 部分取り込みを許容するか
- 入力ファイルのバリデーション
- 巨大なファイルの場合にチューニング
- ファイル連携以外を採用すべきケース
- 前回分の未処理ファイルが存在した場合の考慮
上記は「I/F連携ガイドライン」に記載予定である。
定時起動ジョブ
定時起動ジョブとは、1日1回、週に1回、月に1回など定められた日時で起動するジョブのことである。
推奨は以下。
- 起動時間は、可能であれば業務時間帯に設定すると、運用性が高い
- あくまで可能であればだが、いつでも実行して良いジョブであれば、ユーザーが少ないとはいえ夜間帯に実行すると、システム運用が大変である
- 業務のクリティカル度にも寄るが、実行時間の自由度が高い場合、運用観点では通常の業務時間帯(9-17時など)に起動させたほうが、何か合ったときのリカバリー体制が取れやすく、運用者フレンドリーである(※通常、夜間帯は頭が働かないため)
- 起動時間は、バッチウィンドウとリカバリー用のバッファでバランスを取る
- 例えば、10分程度で終わるジョブを、17時までにジョブを実行させなければならない場合、16:45分起動にすると異常終了した際のリカバリーは不可能になる。そのため、門限を遵守する場合は、最低でも16:30に起動しておきたい(できれば16時起動にしておきたい)
- 業務調整が難しい場合は、16時起動のジョブ(大部分のデータを処理)と、16:45起動ジョブ(16時以降に蓄積したデータを処理)の2つに分割するなどの考慮ができないか検討する
- 月次に1回など周期が大きい場合は、週次など間隔を狭めてアプリケーション側で空振りさせて、動作確認しやすくする
- ジョブが正しく起動するかの確認に便利である
- ワークフローエンジン上でスキップ判定をすると、テスト性が良くないためアプリケーション側でスキップすることを推奨する
- 処理対象がゼロ件の場合の挙動を定義する
- スキップで良い場合、INFOログでその旨を出力する。結合テスト時などで、出力先のDBテーブルに書き込みがゼロ件だった場合に、調査したいことは意外と多いため、切り分け可能な材料を提供すると良い
- ゼロ件がありえない場合は、エラーログ出力+通知を出す
- 同一時間帯に起動時間が集中しないように、微妙にずらす
- システムタイムチャート(※後述)から、定時起動ジョブの起動時間が集中しすぎると、DB負荷高騰などが考えられる。そのため、各ジョブの起動時間・実行時間・バッチウィンドウを考慮して、集中しないようにする
- 例えば数分程度、起動時間をずらすのもありである
サイクルジョブ
サイクルジョブとは定時起動ジョブの一種であるが、10分など比較的短い間隔で起動するジョブのことを指す。
以下の注意点が存在する。
- 重複起動の制御(前回起動したジョブが残ったまま、次のジョブを起動しないようにするかどうか)
- 重複起動を許容しない場合、前回ジョブ終了後にすぐ次のジョブを起動させるかどうか
- すぐに次のジョブを起動させた場合、その次はそこから10分後にするかどうか
- ジョブが異常終了した場合に、次回起動を許可するかどうかを、設計で定義する必要がある
- 起動タイミングで受け持つ対象が決まっているような場合には、異常終了したジョブをリカバリーしてから次のジョブを動かす必要があることも考えられる
推奨は以下の通り。
- 利用する業務日付について日替わり 章を確認し、サイクルジョブ独自で日付管理するかどうかの要否を決めること
- 重複起動について
- 重複起動を許容しない(追い抜きさせない)
- 次のジョブは、起動中のジョブが終了済みかつ、予め指定したスケジュールを満たした場合に起動する
- スケジュールはジョブ実行でずらさないことで、運用をシンプルにする
- 異常終了時の次回起動
- 前回異常終了しても、次回はそのまま次のジョブを起動すれば良い設計にすると運用が楽である(リラン操作が不要になるため)
- もし、前回異常終了のまま、次のジョブ起動を許容しない場合は、アプリケーション側でも判定ロジックを追加する
- 誤って手動や設定ミスで実行してしまった場合に、フェイルセーフさせると安心・安全である
- エラーになったら次回ジョブ起動を止めないとならない場合は、以下のようなフロー制御が考えられる
【1hごとに起動するサイクルジョブで、エラー発生時に次回ジョブを必ず停止する必要がある場合の設定例】
(1)時起動ジョブ
↓
(2)時起動ジョブ
↓
(3)時起動ジョブ
↓
(4)時起動ジョブ
↓
(5)時起動ジョブ
↓
(6)時起動ジョブ
↓
(7)時起動ジョブ
↓
(8)時起動ジョブ
↓
(9)時起動ジョブ
↓
(10)時起動ジョブ
↓
(11)時起動ジョブ
↓
(12)時起動ジョブ
↓
(13)時起動ジョブ
↓
(14)時起動ジョブ
↓
(15)時起動ジョブ
↓
(16)時起動ジョブ
↓
(17)時起動ジョブ
↓
(18)時起動ジョブ
↓
(19)時起動ジョブ
↓
(20)時起動ジョブ
↓
(21)時起動ジョブ
↓
(22)時起動ジョブ
↓
(23)時起動ジョブ
↓
(24)時起動ジョブ※上記のように1hごとに起動するジョブを、愚直に24個用意する(前ジョブが正常終了+指定された起動時間になった)という条件とすることで、必ず前のジョブが正常終了しないと、後続のジョブは起動されない
非同期タスク
非同期タスクとは、タスクの終了を待たず呼び出された後はバックグラウンドで実行されるタスクである。マイクロサービスアーキテクチャやイベント駆動型アーキテクチャの普及に伴い、こうした非同期ジョブの活用も広がってきており、キューイング(AWSにおけるSQS)などを経由して呼び出される場合や、サーバレスでスタンドアローンタスクを非同期呼び出しされる場合が該当する。バッチ処理の実行も非同期で呼び出される場合がある。
参考
実行環境についてはバッチ実行モデル の章に記載がある。本章では非同期の呼び出し方についての方針をまとめる。
画面操作による非同期ジョブ呼び出し
重い処理を非同期化することで、ユーザーの待機時間を短くしてUXを上げることができる。例えば、帳票作成処理・アップロードファイルの取り込み(エンコーディングなど)を非同期化することがある。
参考
処理方式や注意点は、 Web API設計ガイドライン > 非同期 に記載している。
ワークフローエンジンから非同期ジョブ呼び出し
ワークフローエンジンからキューイングサービスの利用有無に関わらず、非同期タスクを呼び出すことは多々ある。AWSの ecs run task はそもそも非同期呼び出しであり、終了の判定には ecs describe tasks などを用いてポーリング監視するか、アプリケーションレベルで終了イベントを何かしらの手法でコールバックする必要がある。
| # | (1)ポーリング | (2)コールバック | (3)イベント通知 |
|---|---|---|---|
| 図 |  | 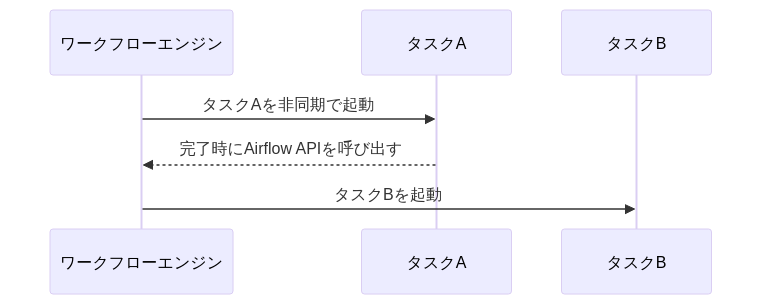 | 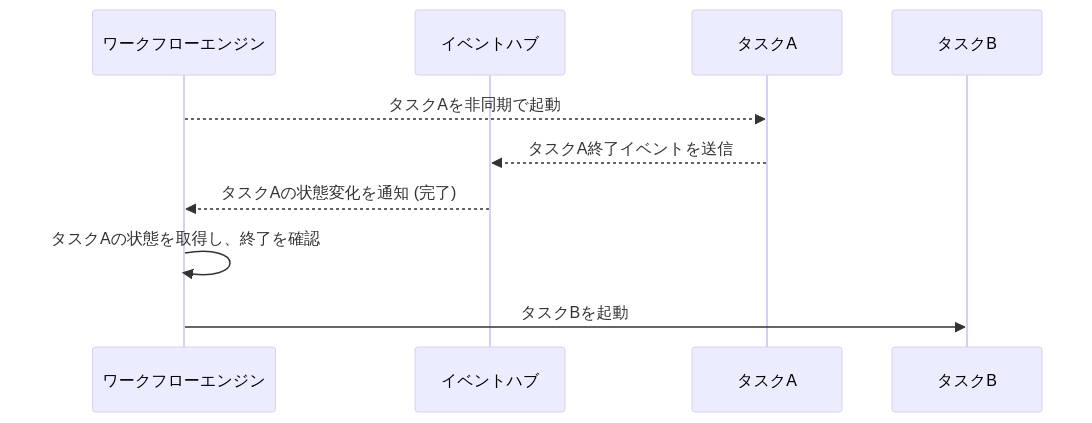 |
| 説明 | ワークフローエンジン側からみて、非同期タスクの状態をポーリングして監視する手法 | アプリケーション側から、ワークフローエンジンのREST APIを呼び出し、次のタスクを呼び出す手法。REST APIの代わりにキューイングシステムを経由して、ファンションなどからREST APIを呼び出す構成もコールバックの一種とする | タスク終了を何かしらイベント連携サービス(AWSの場合はEventBridge)が取得できる場合、イベントの変化をワークフローエンジンが受信し、それによって終了を把握する方法 |
| 即時性 | ❌️ポーリング分遅延があり | ✅️随時連携が可能 | ✅️随時連携が可能 |
| 信頼性 | ⚠️タスクが突如、異常終了した場合にワークフローエンジン側からの検知が難しい | ❌️タスク異常終了時の検知および、コールバックの到達保証など障害ポイントが多い | ✅️イベントハブへの連携が、クラウドベンダー側の責務であれば確実性が高い |
| 制限 | ⚠️ecs describe tasks の場合は、API呼び出しのレート制限があるため、大規模システムでは採用しにくい。回避策としてアプリケーション側にオブジェクトストレージやDBにレコードを登録し、それをポーリングするという方式が考えられる | ✅️なし | ✅️なし。ecs describe tasks の呼び出し回数は削減できる |
| 結合度 | ⚠️オブジェクトストレージに状態を保存すると、外部サービスとの依存性が増える。ネイティブの状態取得サービスのみを利用する場合、結合度は下がる | ⚠️コールバック呼び出し分、ワークフローエンジンと各タスクの結合度が増す | ⚠️イベントハブの連携分、ロックイン度が高まる |
| セキュリティ | ✅️なし | ❌️ワークフローエンジン側のREST APIを呼び出し可能とするネットワーク設計/権限設計が必要 | ✅️なし |
| リソース | ⚠️ポーリング中にリソースを占有してしまう懸念がある。tipに記載した緩和策がある | ✅️なし | ⚠️イベント受信待機でリソースを占有してしまう懸念がある。tipに記載した緩和策がある |
推奨は以下。
- 原則、(1)の方式を採用する
- バッチ処理である以上、一定の遅延は許容されることが多いため
- よりシンプルな構成が可能であるため
- もし、机上計算でAPI呼び出し数がネックになる場合は、(3)の導入を検討する
Airflowについてリソース占有の緩和策について
MWAAでのリソース管理:Deferrable Operatorsによるワーカースロット解放の実践 - Qiita が参考になる。
あるジョブから非同期ジョブ呼び出し
あるジョブ(同期/非同期を問わない)から非同期ジョブを呼び出すと、ワークフローエンジンからの制御が行いにくい(リランなどの運用も特殊になる)。そのため原則、非推奨とする。代替として、ワークフローエンジン側からの呼び出しに変えられないか検討する。
あるジョブから同期ジョブ呼び出し
あるジョブ(同期/非同期を問わない)からの同期ジョブ呼び出しは、DBトランザクションが分離するため実質的に2相コミットとなる。エラー時のハンドリングやリカバリーが難しくなることが多いため(※同期ジョブ側を冪等にすることで緩和は可能)、原則、非推奨とする。代替として、ワークフローエンジン側からの呼び出しに変えるか、同期ジョブのロジックをライブラリ化し関数呼び出しにできないか検討する。
日替わり
業務日付
業務日付とは、特定の業務において一定のルールに基づく変わり目を持つ日付であり、多くの場合で暦日とは異なる日替わりタイミングを持つ。例えば、暦日上N+1日の夜間にN日分の集計処理をする場合、バッチ機能が参照する日付を暦日ではなく業務日付とすることで、バッチ機能の起動タイミングに関わらず処理対象データを特定させることができる。
TIP
暦日を直接参照するパターンでN+1日にN日分の処理を行う場合、暦日-1日という指定をどこかで行う必要がある。この場合は起動タイミングをN日に変更しようとすると改修が必要になってしまう。
動作イメージとして、一連の夜間バッチが完了した後、業務日付切り替え機能からN+1日に更新することで業務日付を切り替える(DBであれば業務日付の値をUPDATEする)。
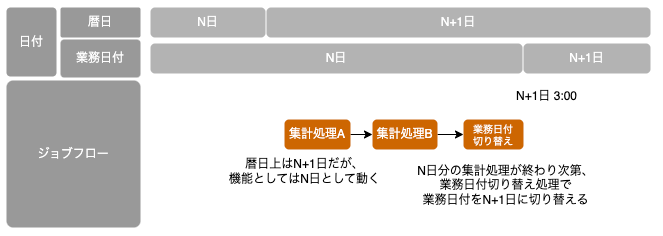
本ガイドラインでは業務日付として呼称するが、文脈によっては必ずしも「業務」範疇で使用する日付である必要はなく、バッチ日付と呼称する場合もある。
業務日付の管理場所
業務日付の管理場所について、システムグローバルに参照できるのであればオブジェクトストレージ、RDB、KVS、DWH等いずれの方法でも問題は発生しないが、本ガイドラインではRDBで管理する前提とする。SQLの扱いやすさから通常、DBテーブルに保持することが多いため。
業務日付管理パターン
業務日付管理のパターンとして、暦日を直接参照する最も簡単なパターンから、機能ごとに業務日付を切り替える複雑な管理パターンまで考えられる。
暦日(システム日付を使用)
最も簡単なパターンとして、システム日付を使用して暦日を参照する方式がある。起動タイミングと処理対象データのズレが考えられない簡易なシステムであれば、あえて業務日付を管理しなくて良いケースも考えられる。
原則、この方式は非推奨とする。ジョブのリカバリーのため、翌日に前日のデータを処理したいといったことが難しくなるため。
万が一採用する場合は、テストや後々の仕様変更に備え、参照日付を変更できるよう日付取得関数は共通化する。システムテストやリランのため、環境変数(例えば BIZ_YMD があればそれを利用するといった)仕組みを予め備えておくと良い。
オンラインとバッチで分離するパターン
オンライン機能とバッチで参照する日付をコントロールしたい場合、業務日付マスタのPKとして業務日付区分を定義するパターンが考えられる。オンライン機能は暦日と同様の日替わりタイミングとし、バッチ機能は一連のジョブフローが完了した後で業務日付を切り替える。オンラインは開局させ業務継続させたいが、一部のバッチだけは翌日の日中時間帯にリランさせるといった運用が可能となるため、通常、分離して管理することが望ましい。
また派生パターンとして、オンライン機能ではシステム日付を使用、バッチ機能のみ業務日付マスタを参照するパターンも考えられる(下図に示す)。どういったタイミングで締めになるかが不透明であれば、両方とも業務日付マスタとして管理すべきだが、オンライン側が暦日と同じにして良い場合は以下のようなパターンも選択可能である。
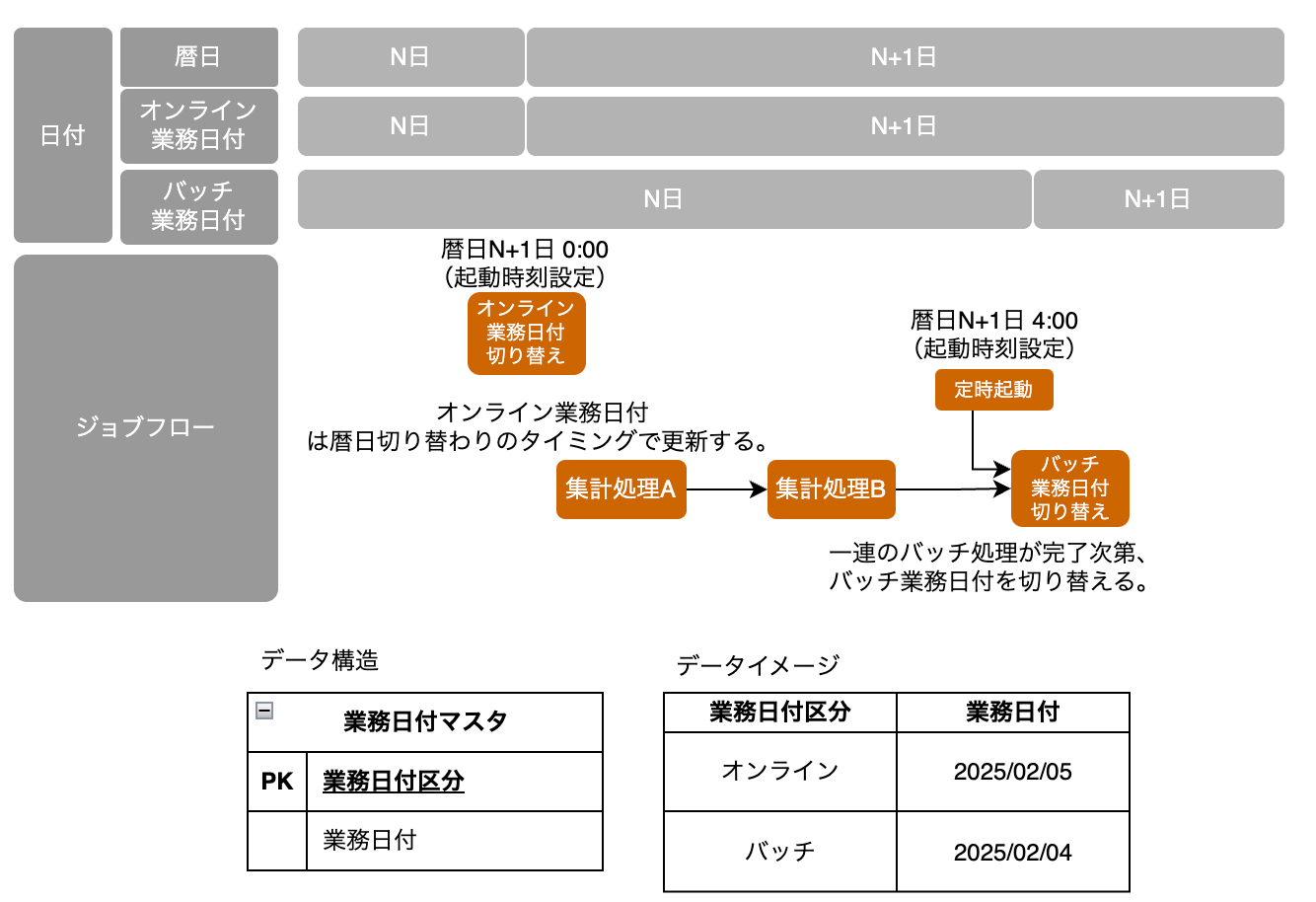
オンライン業務日付更新ジョブの起動方式として、起動に時間がかかる実行モデルを採用する場合、意図した更新タイミングから数分遅延し得る点に注意する。
例えばECSスタンドアローンタスク(ecs run task)で業務日付を更新する場合、タスク起動指示から実際に処理が開始されるまでは数分のラグが発生する。その分を予見して数分前に起動したとしても、数秒の誤差は発生してしまう。この遅延を許容できない場合はシステム日付を使用するか、Web API等の遅延が少ない処理方式を採用すると良い。
機能グループ毎に分離するパターン
さらに詳細に業務日付を管理したいパターンとして、機能グループ(たとえばサブシステムなど)を定義し、グループ毎に業務日付を切り替えるケースも考えられる。
例として、以下3種類が存在する場合を考える。
- 暦日通りの日替わりタイミングを持つ業務日付を参照するオンライン機能
- 処理遅延などに備え、業務日付切り替えを遅らせたい深夜集計バッチ機能
- 暦日とは別タイミングで業務日付を遅延無く切り替えたいサイクルバッチ機能
- 深夜集計バッチとサイクルバッチには依存関係が無いものとする
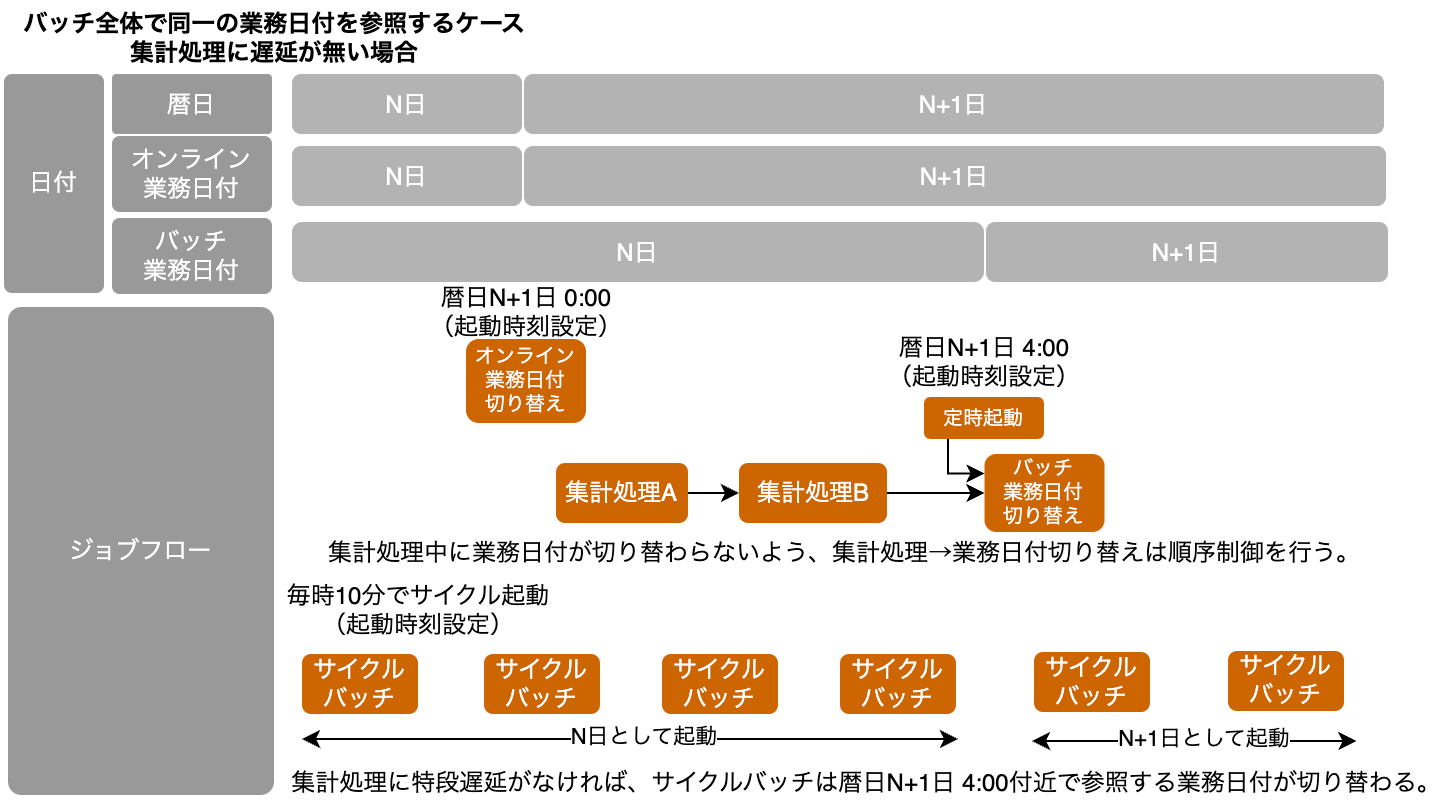
まず、バッチ全体で同一の業務日付を参照するケースを考える(悪い例である)。
- 集計処理→業務日付切り替えのジョブは順序制御、業務日付切り替えジョブには起動時刻設定を行い、合流設定とする。このケースではAM4:00に時刻設定する
- 順序制御をすることで、集計処理が遅延したとしても途中で業務日付が切り替わるようなことは無くなる
- また、起動時刻を設定することで、想定より早く集計処理が完了した場合でも、意図したタイミングで業務日付が切り替わる
- サイクルバッチは集計処理と同様の業務日付を参照しており、集計処理に遅延がない場合はAM4:00に参照する業務日付が次の日付に切り替わる
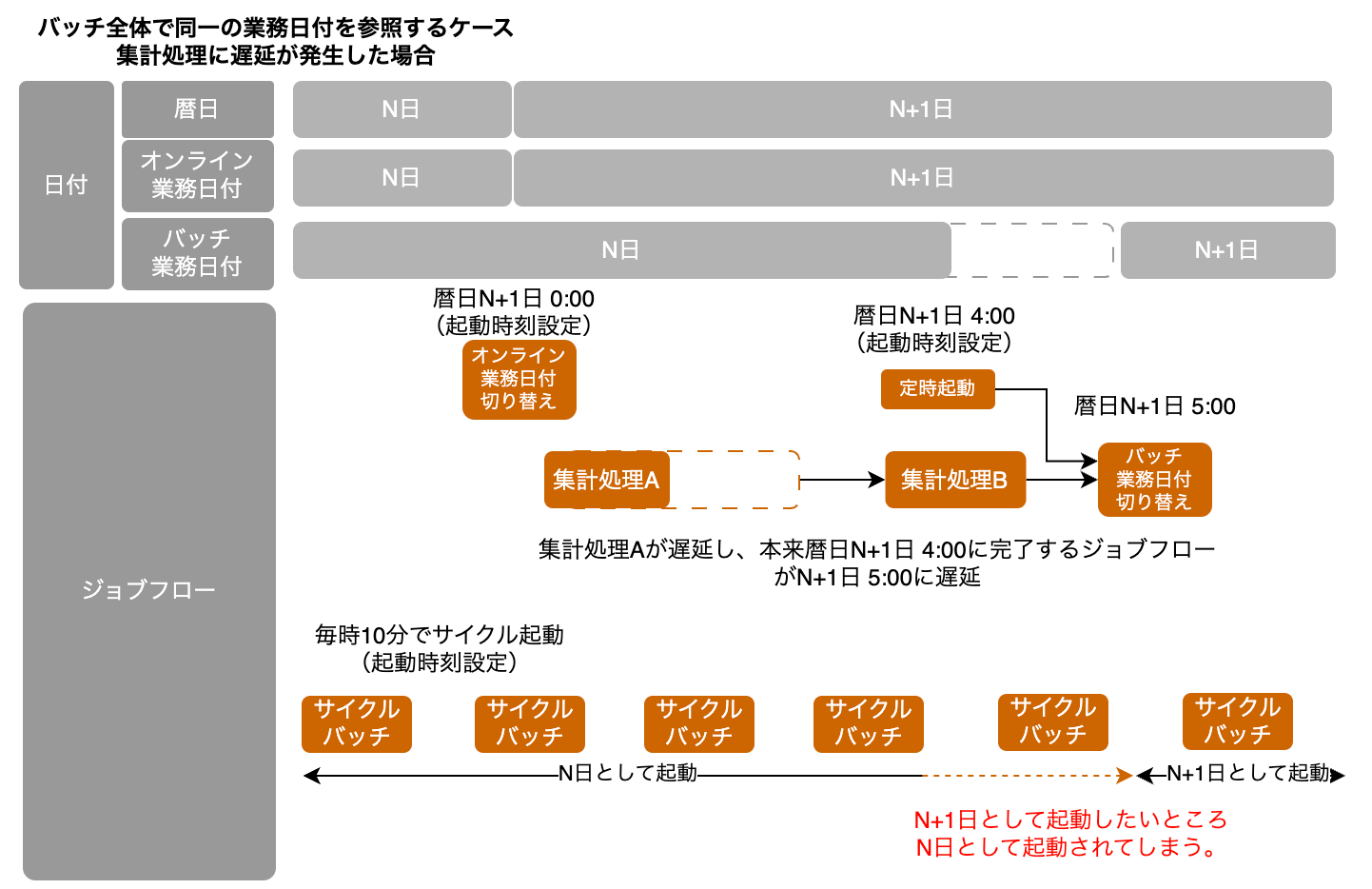
一方で、集計処理が遅延してしまった場合、AM4:00付近で起動するサイクルバッチはN+1日として起動するべきところ、N日として起動されてしまうことになる。
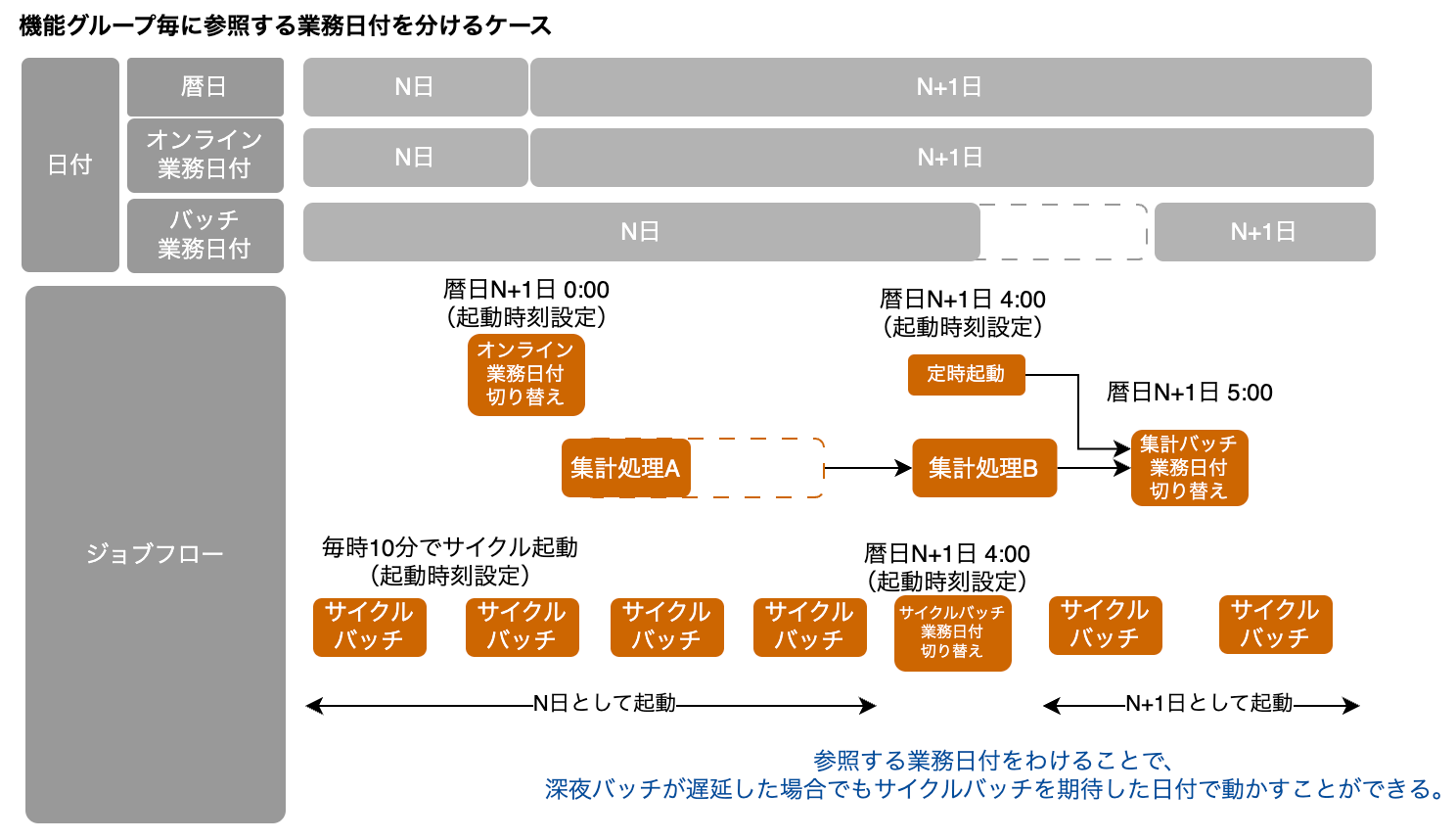
この問題を解消するパターンとして、機能グループ毎に業務日付を定義するパターン(良い例である)が考えられる。
- 集計バッチとサイクルバッチで業務日付を分け、サイクルバッチ業務日付はAM4:00に切り替わるようジョブ設定を行う
- それぞれの業務日付が独立することで、ジョブ遅延による影響を受けない構成にできる
 |  |
なお、このケースでも一部の業務日付をシステム日付とするなどの派生パターンを考える事もできる。適宜使い分けること。
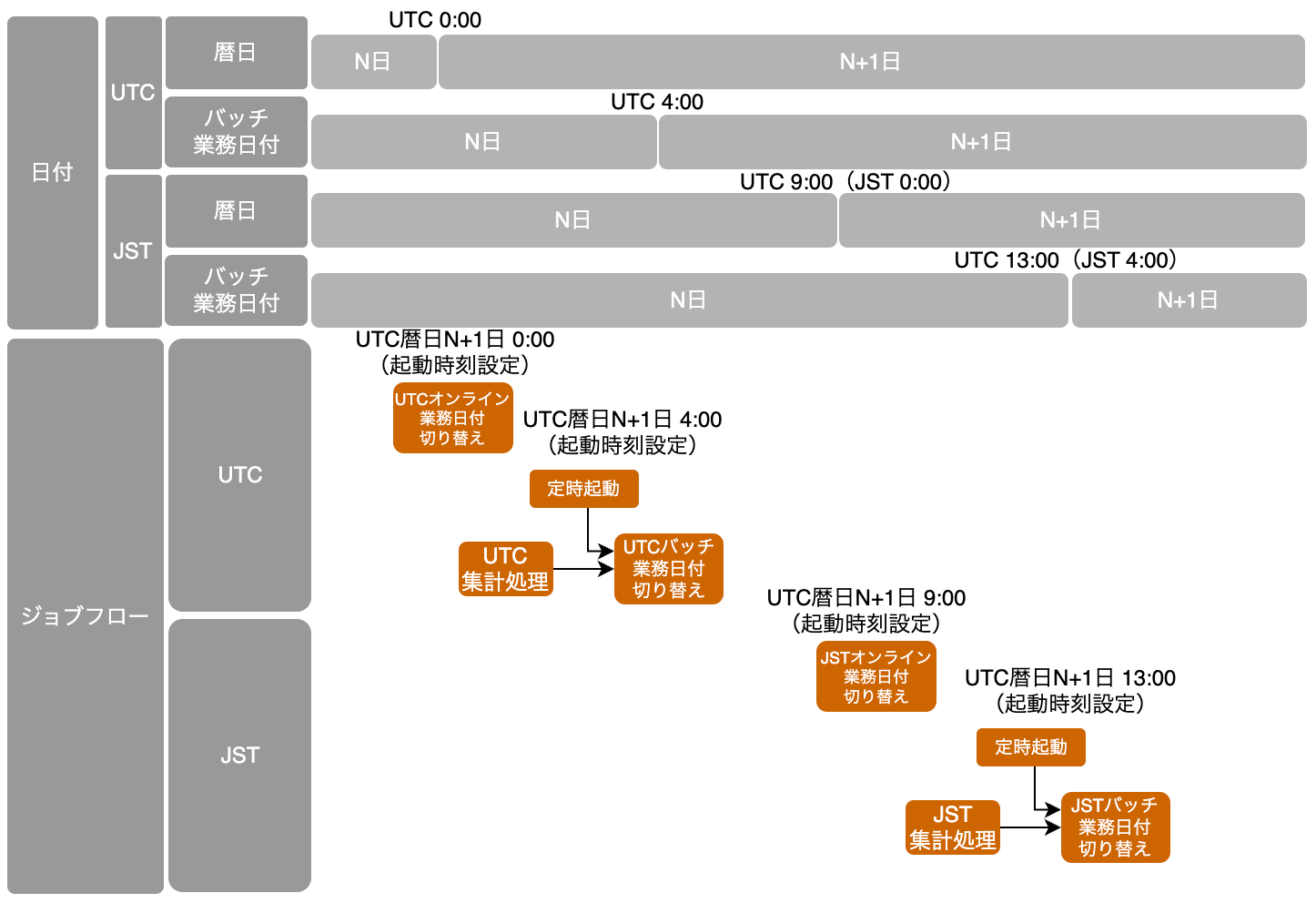
タイムゾーン毎に分離するパターン
2つ以上のタイムゾーンを扱う場合、タイムゾーン別の業務日付管理を検討する必要がある。
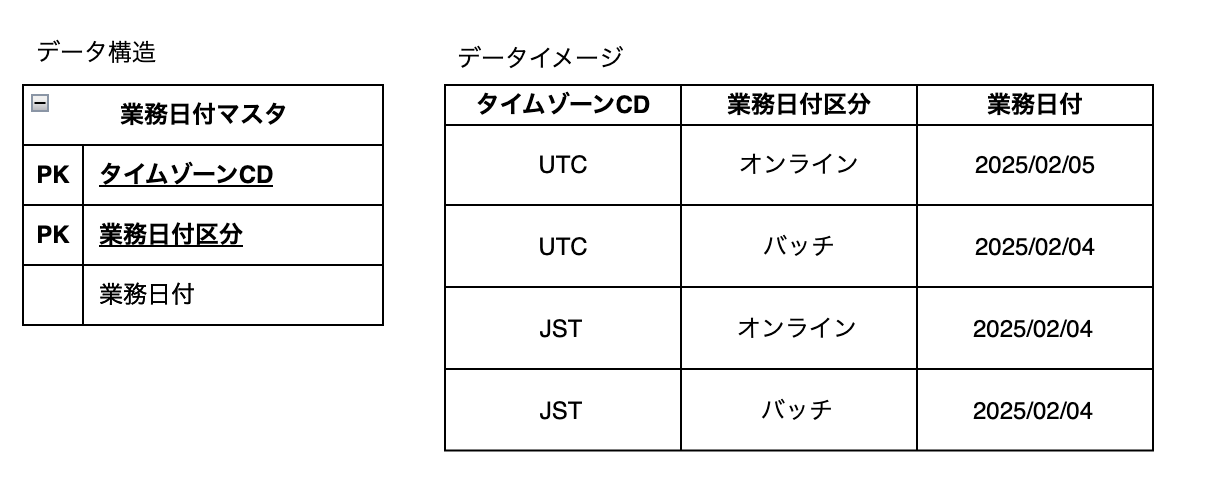
RDBを業務日付の管理場所とする場合は、PKにタイムゾーンを追加することで業務日付を分割できる。前述した機能グループ毎の業務日付分割が必要な場合は、さらにPKに機能グループIDを追加することで、更に詳細な業務日付制御ができる。ただし、業務日付の取り扱いが複雑になりすぎるとアプリケーション品質に影響する可能性が増加するため、必要最低限度の制御とするよう留意する。
【管理イメージの例(記載簡略化のためオンライン業務日付=暦日として記載する)】
 |  |
オンラインとの排他制御
オンライン中に実行されるバッチ処理を「オンライン中バッチ」(※現場によっては「オン中バッチ」とも呼ぶ)と定義する。
2C/2Bのアプリは画面の閉局が通常は存在しないため、定期メンテナンス時間で実行されるジョブ以外は、全てオンライン中バッチとも言える。例えば、以下のようなユースケースが存在する。
- ユーザーが商品在庫を手動で調整している最中にバッチ処理で自動在庫補充が行われる
- ECでユーザーから注文が入ったタイミングでちょうど商品在庫の自動発注のバッチが動いた
- 従業員のロール変更を登録している最中に、バッチ処理でリストが更新される
バッチ起動のトリガーは例えば、例えば以下が考えられる。
- システムI/Fファイルを日中オンライン開局中に受信し、テーブルを更新するバッチが起動
- ユーザーが一括取り込みファイル(数千~数万件程度)をアップロードし、一括で更新するバッチが起動
- WMS(倉庫管理システム)への発送配送指示の締め時間になった
オンライン中バッチのうち、考慮が必要なケースを下表で記載する。
| 項目 | 1.通常バッチ | 2.オンライン中バッチA | 3.オンライン中バッチB | 4.オンライン中バッチC |
|---|---|---|---|---|
| 条件: 同一時間帯に起動 | ー | ✔ | ✔ | ✔ |
| 条件: 同一テーブル更新 | ー | ー | ✔ | ✔ |
| 条件: 同一カラム更新 | ー | ー | ー | ✔ |
| 排他制御の要否 | 不要 | 不要 | 4と同様にするか、lock_noの更新無しでレコードを更新する。バッチ同士の多重起動は別で制御するか冪等な作りとする | 個別検討が必要(※後述) |
3については、排他制御をシンプルにするためテーブルを分割するのも手である(例えば、バッチはテーブルロック、オンラインは行ロックなど排他制御の粒度が異なる場合は、区別したほうが業務効率を上げることができる可能性がある)。
4の対応方法としては大別すると以下2つがある。
| # | 1.バッチの起動スケジュール調整 | 2.排他制御を加える |
|---|---|---|
| 説明 | 業務システムであれば閉局中にできないか検討する。2C/2Bアプリであればメンテナンス期間にバッチを実行できないか検討する。 | オンライン側とバッチ側の排他制御を加える |
| UX/業務効率性 | ❌️業務遂行時間への制約が生じる可能性や、バッチ処理実行で得られるはずだったユーザビリティやデータ鮮度が犠牲になってしまう | ✅️適切な排他制御を加えることで、整合性を守りつつ業務効率を上げることができる |
| 対応工数 | ✅️システム的な対応は最小限にできる | ❌️状況に適した排他制御方針を設計、テストする必要がある |
1が難しい場合は、2の対応を検討する。次のような対応案がある。
| 1.常にバッチで上書き | 2.部分更新+NGリスト表示 | |
|---|---|---|
| 説明 | バッチは操作するユーザーが当然いないため、バッチでの更新を常に優先して、後勝ちで更新する。場合によっては起動時にテーブルロックを取得し、悲観ロックする | バッチ起動時にロックが取れなかった、あるいはバッチ起動時刻より最終更新時刻が新しい場合はスキップする |
| Pro | ✅️実装がシンプル | ✅️ユーザー入力がバッチ競合で登録できない点は救済可能 ✅️競合が無いレコードに対しての処理は遂行できる |
| Cons | ❌️ユーザーの入力情報がバッチ競合で登録不可になる可能性 ❌️更新内容がバッチで知らず知らずのうち上書きされるおそれがあり、それらの通知やリカバリーの有無などの設計や業務調整が必要となる可能性 | ❌️スキップした一覧を表示する画面の準備や、業務運用が必要 |
それぞれ詳細を説明する。
常にバッチで上書き
オンライン側の更新フローでは悲観ロック (SELECT FOR UPDATE) をしてもらう。ロックが競合した場合は、常にバッチが勝つように、画面側はNO WAITを指定する。バッチ側は一定期間(例えば数分)WAITするようにする。待ち時間はバッチウィンドウを加味して決定する。
バッチ処理でオンライン処理と同じデータを編集する場合は、更新前にSELECT FOR UPDATEを取り、かつ画面側でも方式2とすることで、バッチ実行中のオンライン変更を禁止(待たせる)ことができる。
PostgreSQLにおいてデフォルトではロック取得のタイムアウトは無限であるため、オンライン側ではNO WAIT(ないしは数秒のタイムアウト)、バッチ側ではオンライン側の処理タイムアウトより長い時間まで待機させると良い。これにより、バッチ実行前にたまたまオンラインで変更があったとしても、楽観的ロックによる失敗をリトライする実装無しでバッチ処理を継続させることができる(※バッチの書き込みを常に優先させて良い場合)。
ロックをバッチ・オンラインのどちらで取得したかでケース1・ケース2のような排他制御となる。
| ケース1: バッチがロックを先取り | ケース2: オンラインがロックを先取り |
|---|---|
 | 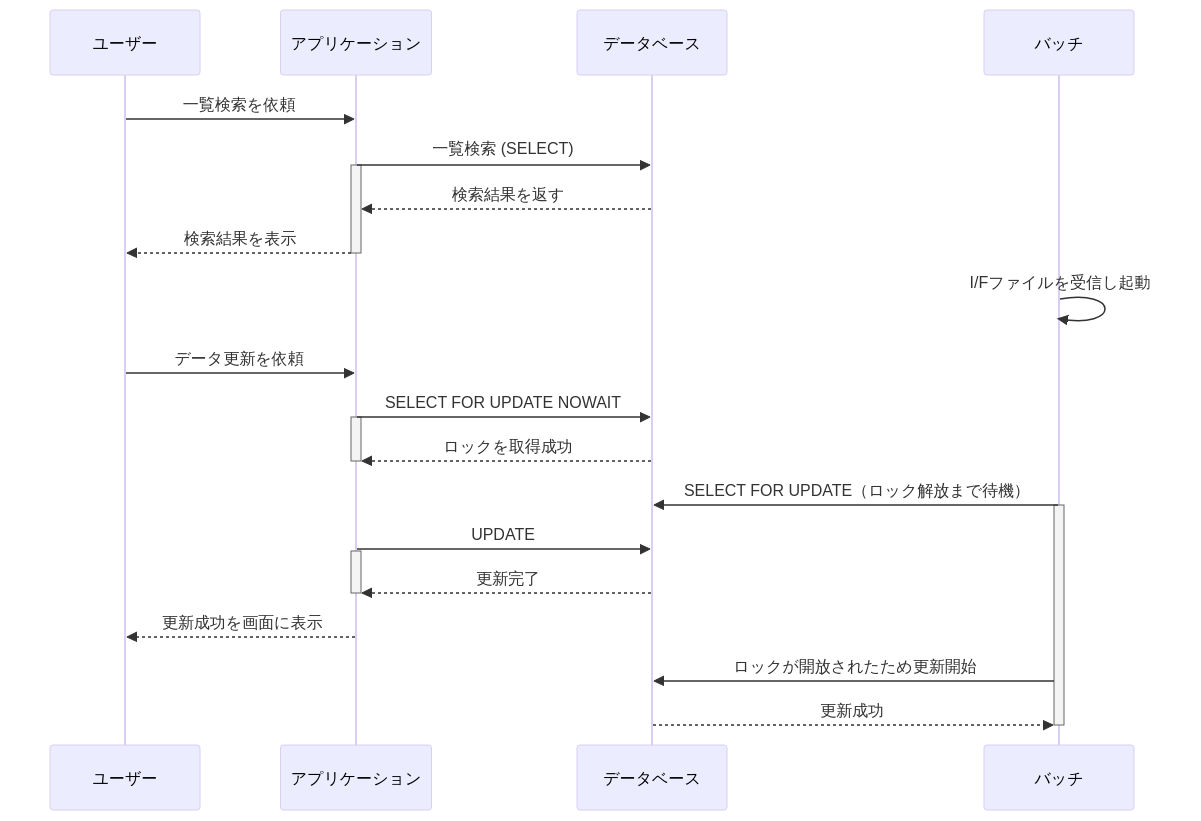 |
ケース1に該当すると、ユーザーは入力したフォーム内容が無効化されるため、発生頻度の想定や再入力支援(入力値をLocal Storageなどに記録しておくなど)を検討すること。
部分更新+NGリスト表示
オンライン側の更新フローでは悲観ロック (SELECT FOR UPDATE) をしてもらう。ロックが競合した場合は、バッチ側は対象レコードをスキップ (SKIP LOCKED) し、ロックが取れたレコードのみを更新する。このパターンの場合は、ユーザー操作で更新したレコードを、バッチでなるべく上書きしたくない背景が考えられるので、特定の更新日時以降のレコードは一律更新をスキップするなどの合わせ技な要件になることが考えられる。
また、更新が失敗したレコードのリカバリーを諦めるか、復帰業務を追加するか、次回ジョブで救済するかといった判断が必要となる。
参考
図解でなっとく!トラブル知らずのシステム設計 エラー制御・排他制御編 9話にバッチ処理の排他制御が詳しく説明されているため、お勧めである
パラメータ
Twelve-Factor App にも記載されている通り、デプロイメント環境等によって値の変わり得るパラメータやチューニングパラメータはコード上で宣言せず、環境変数としてワークフローエンジンから渡すか、envファイル等で管理することが望ましい。環境変数化しておくと、どの箇所が変更可能であるかより明示的であるため保守運用フレンドリーでもある。また、あるジョブが動いたことによって決まるような動的なパラメータのような存在もあり、これらをどのように受け渡すか手法を統一しておかないと、影響度調査や改修などの運用コストが高くなる。リラン操作を簡易にするためには、ワークフローエンジンからパラメータを上書きできるようにすると便利な場合もある。
このように、ジョブに受け渡すパラメータを、どのような種類であればどこに管理するかという方針を決めておく必要がある。
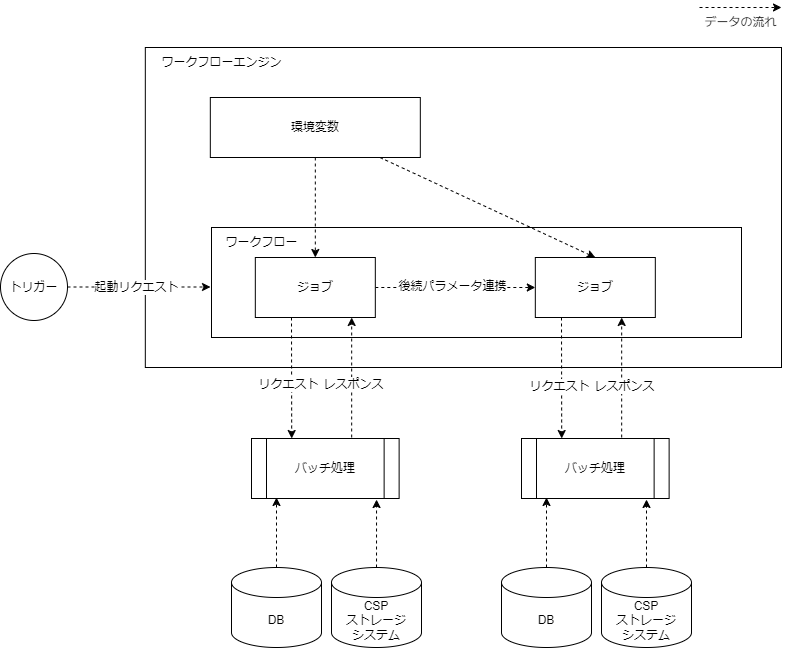
パラメータの管理
パラメータの特性に応じて管理場所の使い分けを行う必要がある。
ワークフロー起動時のパラメータ
外部プログラムや管理画面から実行時にパラメータを受け取る。
- 管理対象
- 実行の度に変動し、ワークフロー全体で利用するパラメータの連携に利用する
- 理由
- リトライ時にパラメータを一部修正して実行可能であるため。
- 時刻といった時間によって変動する情報をワークフロー内で固定して扱うため
- 利用方針
- 外部プログラムとの結合度が高くなることを避けるため、パラメータ数は最小化する
- パラメータ数が動的に変わる場合は、リスト形式でパラメータを渡して全量をバッチ処理に引き渡すような方式を検討する
- 例
- 処理対象日付、処理対象ファイル名
ジョブ間での後続連携
依存関係を持つ上流ジョブからパラメータを受け取る。
- 管理対象
- 後続のジョブの処理対象を特定するキー情報の連携に利用する。
- 理由
- ジョブの結果によって後続ジョブで利用するデータが動的に変動する場合、DBに保存しない一時的な情報及びDBに保存するデータのキー情報を引き渡す必要があるため
- 利用方針
- タスク間での依存度が高くなることを避けるため、ジョブ間で連携するパラメータ数は最小化する
- 例
- 中間ファイル名、中間テーブルのキー情報
ワークフローエンジンの環境変数(AirflowのVariables等)
すべてのワークフローから参照可能な値を指す。
- 管理対象
- 複数のワークフローで共通して利用するパラメータの管理に利用する。
- デプロイメント環境ごとに異なる情報(エンドポイント等)の管理や、デフォルトのリトライ回数やタイムアウト設定の保持、特定の機能を有効化・無効化するためのフラグなど、用途は様々である。
- 理由
- Twelve-Factor Appなど、業界標準の考え方に準拠するため。
- 利用方針
- Git等で変更履歴を管理し、容易にデプロイ可能な環境を構築することを推奨する
- 秘匿情報を含む情報の場合はCSPストレージシステム(AWS Secrets Manager等)の利用を検討する
- 例
- タスク定義のARN、ログレベル
ワークフロー内部定数(AirflowのDAGのparms等)
単一のワークフロー内で利用する静的なパラメータを指す。
- 管理対象
- ワークフローやタスク固有のパラメータの管理に利用する。理由
- ワークフローやタスク固有のパラメータを環境変数等で保持するとワークフロー数の増加に伴い環境変数等が肥大化する恐れがあるため個別定義する
- 利用方針
- パラメータ値を変更する場合にワークフロー定義のデプロイを許容できる程度の変更頻度であるパラメータのみ利用する
- 変更頻度の高いパラメータは環境変数やリクエストパラメータとして管理することを検討する
- 例
- リトライ回数、タイムアウト設定
コード上の定数
アプリケーションのみで利用する定数を指す。当然ながら、パラメータを変更するためにはアプリケーションのリリースが必要となる。
- 管理対象
- アプリケーションの起動中に変更されることはないパラメータの管理に利用する。
- デプロイメント環境でも変化しない、全環境同一で良い値であることを前提とする。
- 理由
- 変更が無い値は環境変数化を無くすことで、管理コストを減らすため。
- 利用方針
- アプリケーションのリリース無しに変更する必要がある値はDBに保持するか、環境変数を利用しワークフローエンジンから受け取る方式とする。
- 例
- 出力ディレクトリ名
DB
アプリケーションから参照可能なパラメータを管理する。DBの値を更新することでアプリケーションのリリースなしにパラメータを変更可能である(ただし、DBのデータパッチは何かしら承認フローを設定することが望ましい)。
- 管理対象
- ユーザー操作やバッチ処理等によって更新されるパラメータの管理に利用する
- 理由
- アプリケーションの操作やバッチ処理によって変動したパラメータを用いてバッチ処理を実行する場合、最新の値を取得する必要がある。この場合はデータ操作の容易性やトランザクション管理の観点からDBの利用を推奨する
- 利用方針
- ワークフローエンジンの負荷・データ整合性・保守性の観点から大量のデータを後続ジョブに引き継ぐ場合は、キー情報のみジョブ間での後続連携を行い、実データは後続ジョブから直接取得する方針とする
- 複数の業務処理から同一のテーブルを参照・更新する場合は、デッドロックやロックの競合による遅延に配慮した設計にする
- 例
- 各種マスタ情報、中間テーブル
CSPストレージシステム(AWS Secrets Manager等)
アプリケーションから参照可能なパラメータを管理する。認証情報の管理にAWS Secrets Managerといったサービスを利用することを想定する。暗号化要件が厳しい場合など、DBでの管理が不可能な場合はパラメータの特性に応じてストレージを使い分ける方針とする。
- 管理対象
- 要件に応じてDB外に保存する情報の管理に利用する
- 理由
- セキュリティや性能、コストといった要件に応じて適切なストレージシステムを選択する必要がある
- 利用方針
- 紐づく情報(認証情報のID、S3のキー等)をDBに保存しアプリケーションから容易に利用できるものとする。
- データの登録・更新時はDBとその他ストレージシステムの2箇所を更新する必要がある。そのため、データの整合性担保に配慮した設計にする
- 例
- クライアントID、クライアントシークレット、画像データ、大規模ファイル
バッチ処理起動時のパラメータの指定
前節の通り、デプロイメント環境別の設定は原則、環境変数を利用することを推奨する。
Amazon ECSを利用する場合、コンテナ起動時には事前に定義したタスク定義と呼ばれるテンプレートを利用し、一部のパラメータを上書きすることで柔軟な実行が可能である。環境変数を上書きすることで、同一イメージを利用するタスク定義を異なる設定値で起動可能である。
- ネットワーク設定
- ロール
- コンピューティングリソースの種類(EC2 or Fargate)
- 実行環境のスペック
- 実行引数
- 環境変数
環境変数以外の値の上書きは下記のようなデメリットが考えられるため、非推奨とする。
- 管理の複雑さ
- どの設定がいつ使用されたのかを把握しづらくなり、設定の追跡や管理が複雑となる。
- IaCでインフラ設定をコード化している場合、インフラでの設定値が実態と乖離する
- 動的に実行環境の種類やスペックを変更できるようにすると、コストの管理が煩雑になる。
- セキュリティリスク
- ロールやネットワーク設定などを動的に変更可能とすることでセキュリティリスクが高まる。
- 実行引数で特定の環境や設定を強制することで、依存するライブラリやパッケージの動作の不正な変更や、特定のセキュリティ対策が無効化される可能性がある。例えば、デバッグモードを有効にするなどの設定は、本番環境では情報露出の原因になり得る。
ジョブ設計
本章ではジョブの実装レベルで留意すべき点をまとめる。
業務日付の利用
日替わり章の通り、利用する日付は業務日付を利用すること。
PostgreSQLの場合、パーティション・プルーニングを有効にするため、SQLのプレースホルダーで明示的に業務日付をバインドする必要があることも多い。そのため、業務日付は共通処理などで簡易に取得可能にしておくと良い。
冪等性
業務日付やパラメータが同一であれば、処理結果が同じであるようにジョブを設計する。それにより、2回以上起動しても問題ないようにする。誤操作の場合もあるし、ワークフローの先頭からリランしたい場合の運用コストを軽減できるためである。
具体的には以下のような実装にする。
- 処理対象のレコードにステータス列を追加し、処理後に完了ステータスに更新する。抽出条件では未処理のみに絞るようにする
- 処理結果の書き込みにはSQLのMerge文相当の動きをさせる(あるいは、最初に今回利用するワークフロー上のトランザクションIDに紐づくレコードをDELETEしてからINSERTする)
冪等というのは、あくまで実行結果を永続化するDBなどのデータストアの状態が、何度実行しても同じ結果になるということを指す。ジョブのアプリケーションそのものの挙動は異なって良い(2回目はスキップして終了という処理にしても、冪等と呼ぶ)。
入力チェック
各バッチ処理において、起動条件を満たすかどうかの入力チェックは必要であるが、対応レベルは濃淡がある。
推奨は以下。
- ジョブ間連携で用いる動的なパラメータや、入力引数
- 連携値の妥当性をチェックする必要がある。例えば、前ジョブの実装不備などで想定外の値が連携された場合は、異常終了させる(Fail Fast)
- 最低でも、単体テストで動作確認する
- ワークフローエンジン上で指定できるもの
- 環境変数
- ビルド、リリース時に決定する環境変数であれば、アプリケーション上で、明示的にチェックする必要はない(正しく値が設定された前提とする)
- リリース後の動作確認で十分であると考えられるため
- アプリロジックとして存在しないため、単体テストは不要
- ただし、ワークフローエンジン上で、環境変数を切り替えるものは入力チェックする
- 入力ファイル
- 「I/F設計ガイドライン(※作成予定)」を参照
- 処理対象データ
- 前ジョブや自システムが作成したトラン、マスタ、中間テーブルを指す
- 基本的に自システム側のデータは正しいという前提でアプリケーションを組むため、ジョブ起動時に積極的なデータ不整合チェックは行わない
- もし、手入力データがロードされることや、データパッチで不整合がすでに混入している場合は、各ジョブではなく別途データクレンジング作業を行い、根本から解決する
- ただし、データ不整合によりテーブル結合落ちが生じると、処理対象が想定外に欠損し業務要件が達成できたか不明瞭で、プログラムとして脆弱である。そのため、対策としてSQLのテーブル結合は原則、外部結合を用いる。もし、データ不整合を検知した場合には、実行時例外で停止または、ERROR/WARNログを出すといった消極的なチェックで運用者にフィードバックして対処する
- 処理結果のデータ
- 自ジョブの実行結果のデータをアプリ上で検証する必要はない
- 単体テストを含めた、テストプロセスで担保すべきである
ログ出力
ログ設計ガイドライン > バッチ実行時のログ出力 参照。
コネクションプール
バッチ実行モデル 章で紹介した、Web APIのような常駐モデルでバッチ処理の実体を動かす場合は、コネクションプールの利用が必須である。逆に、スタンドアローンタスクの場合は、プロセスの寿命がバッチ処理実行と同一であるため、コネクションプールする意味は無い(むしろプール数分、余計なコネクション作成処理負荷をDBに与えるため悪影響がある)。
スタンドアローンタスクの場合は、Amazon RDS Proxy のようなデータベースプロキシを経由させることで、DB負荷を下げることができる。ジョブの同時実行数、DB負荷、クラウド費用などをバランスして導入を検討すること。
なお、Web API呼び出しでもTCPコネクションの再利用が効果的な場合が多い。この場合は、TCP Keep alive も注意して設定する。
性能
バッチインサート
ループ中でN+1クエリにならないように注意する。
SQLを用いたデータ登録時は、基本的にはBatch(Bulk)インサートを用いる。バッチサイズは1000件ごとなどPJごとに固有値を定数(グローバル変数)で管理する。Amazon DynamoDBのようなKVSの場合も、同様のバッチAPIを備えているため、原則利用可能な箇所は全てバッチAPIを利用する。
SQLの場合、バッチUPDATEが連発する場合は、一時表にバッチインサートしてから、MERGE文にした方が早い可能性もある。データ量が多いと分かっている場合は、アーキテクトやDBAと相談の上、検討すること。
Web APIへの要求に対しても、提供されている場合はバッチAPIを利用する。もし提供されていない場合は、1 Web API要求を20msと仮置きして、最大の想定件数をかけ合わせて、バッチウィンドウに収まるか机上検証する。
大量データロード
例えば、PostgreSQLにはCOPYのように、ファイルを高速にテーブルに登録するコマンドが存在する。数百~数千万件オーダーでかつ、バッチウィンドウが厳しい場合は、これらの手法が採用できないか検討する。
バッチ処理の並列化
バッチ処理のプログラム内でWeb API呼び出しする場合、並列化したい場合がある。ただし、処理レコード単位で並列化すると多重度が高くなりすぎ、依存先のWeb APIサーバ負荷が高まりすぎる懸念があるため、4並列までにするといった絞り込みを検討する。
なお、連携先のWeb APIに対して流量制御可能なリバースプロキシを追加設置する案も考えられる。アプリケーション側から外部のWeb APIに向けたリクエスト数を、割り当てた上限を超過するとスロットリングで防ぎ、アプリケーションとしては適切に待機させることで流量調整が可能である。流量調整に対する強制力が強く、アプリケーション側の実装がシンプルになるメリットと、構成要素が追加となる点・インフラ費用が増加するデメリットがあり、両者のバランスを判断して検討する。
なお、DBアクセスをプログラミング内で並列化することは非推奨である。理由として、SQLコネクションが異なるためトランザクションが異なり、ジョブの成功/失敗とDBトランザクションが不一致となることで、リランなどの操作が特殊となり、運用性が下がるためである。
ジョブ並列化
バッチ処理のアプリケーション内で並列化するのではなく、ワークフローエンジンから呼び出すジョブ自体を並列化するという対応方針も考えられる。ジョブを分割するとそれ単位でリラン可能となるため、運用上その方が好ましい場合は、プログラミング内の並列化にこだわりすぎず、ジョブ自体の並列化を検討する。
TIP
Airflowを利用する場合は Pools 機能を用いて同時実行数を制限できる。
省メモリ
入力データが大量データの場合に、全てメモリに抱えるとOOMエラーやOOMキラーによりプロセスが強制終了される懸念がある。
そのため、大量データを扱うバッチ処理では、原則ストリーミング的にデータを扱い、逐次処理する必要がある。
また、場合によっては配列(リスト、Go言語ではスライス)を再利用することで、GCに優しい実装を意識すると良い。
テスト
特にバッチの文脈で特徴的なテスト観点を記載する。なお、一般的なソフトウェアテストの範疇といえる観点(例えば、境界値やカバレッジなど)については省略する。
| テストフェーズ | テスト観点 | 詳細 |
|---|---|---|
| 単体テスト | 全般 | ・ワークフローエンジンでの実装(分岐やロジック)は可能な限り減らす。一般に、ワークフローエンジンの実装はテストコードによるUTが困難なため ・どうしても実装が必要な場合はfunctionとして分離し、テストコードによるUT可能な構成とする |
| 冪等性 | 冪等性を確認するテストケースを必ず追加する | |
| 0件処理 | 特にIF受信機能の場合、0件データを受信した場合のテストケースを必ず追加する | |
| 性能テスト | メトリクス | バッチの処理時間のほか、データベースのRead/WriteIOPs/CPU/メモリは必ず確認する |
| バッチサイズ | 大量件数の処理テストで期待する性能が得られない場合、バッチサイズ(一度にDB書き込みを行う件数)の調整を試みる。DBサイジング次第ではバッチサイズによって書き込み速度が変わる。処理量によってはジョブ実行時間に大きく影響があるため | |
| オンラインピークとの重なり | ロングランテストを行う場合、オンラインでの業務/サービスピークとバッチ実行タイミングが重なった場合に著しく性能が劣化しないか確認する | |
| ウィルススキャンとの重なり | EC2ベースの環境の場合は、ウィルススキャンが実行されたタイミングで著しく性能が劣化しないか確認する | |
| 障害テスト | 未起動検知 | ・AWS等クラウドプラットフォーム側のリソース確保ができてない等で、バッチ自体が起動しないケースが考えられる場合、それを検知できるかどうか ・起動ログをDBに書き込んでおき、定期でそれらを確認するなどが対策として考えられる |
| 遅延検知 | 想定されるバッチウィンドウを超過した場合に通知が必要な場合、遅延検知のテストケースを必ず組み込む | |
| シナリオテスト | 日回しテスト | ・暦通り連続して起動した場合に不整合が発生しないかどうか、日回しテストを行って確認する ・データ改廃や、月次タイミングでしか起動しないバッチはテスト密度が薄くなる傾向にあるので、日回しテストで確実に実行する |
リリース
バッチ処理のリリースについては、B/Gデプロイやカナリアリリースのような段階的なリリースすることはできない。そのため、インプレースデプロイ(一括で資材を置き換える)のみとなる。
推奨は以下。
- リリース周りのプロセスは、Gitブランチフロー規約 を参考に整備する(開発環境、検証環境で動作確認を取ってから、本番環境にデプロイするなど)
- いざというときのために、前回のバージョンに、切り戻せるようにしておく
- もし、影響範囲が大きい重要なジョブを大きく改修した場合は、データバックアップを取っておくと良い
ワークフローで依存関係があるジョブのデプロイ
例えば、A1⇛B1⇛C1 というワークフローで定期的(サイクル的)に実行されるジョブがあるとする。機能改修がありA2、B2、C2に更新したいが、A~Cで利用するワークテーブルの列名変更があり、同期を取ってリリースする必要がある。この場合に、ナイーブにA、B、Cの順番でデプロイすると、A2 の実行結果をB1が処理できないためエラーで落ちてしまう。同様にB2の実行結果はC1が処理できないため、エラーで落ちてしまう。
最も簡易的なリリース方式としては、ワークフローを停止して静止点を確保してデプロイすることである。メンテナンスウィンドウを週に数時間程度、確保してこれを行うことが多い。しかし、リリース頻度によっては無停止が求められる場合がある。また、データ層を意識したリリース手順は作業者の負荷が大きく、作業ミスを誘発しやすい。
このような場合は、以下のルールを守って改修してもらうと良い。
- 後方互換性があるように改修する。例えば、A1⇛B2 や、B1⇛C2がエラーにならないようにする
- リリースは、C、B、Aの順番で行う(下流から行う)
- そのためそれぞれ、B2はA1という古いバージョンのデータを処理できる必要がある
- ERD変更で言えば、列名の削除は行わず、追加のみを許容する
- もし、列を削除する場合は、A2、B2、C2のリリースが終わった、その次のリリースでデータ移行+ERD変更する
もし、B・Cが従来バージョンと全く互換性がない場合は、新しいワークフローバージョンとしてD、Eを追加し、切り替える方法も考えられる。しかし、これはワークフロー自体が追加となり、リリース手順が複雑かつリハなどのコストも高いことから、なるべく避けるように改修してもらうと良い。
A1
\ B1 ⇛ C1(★有効)
\ D1 ⇛ E1(無効)
--- リリースタイミングで切り替え ---
A1
\ B1 ⇛ C1(無効)
\ D1 ⇛ E1(★有効)ドキュメント
バッチ処理がいつ、どのようなタイミングで起動し、それぞれの依存関係を把握し、門限がいつでそれぞれのバッチウィンドウ(バッチ処理を動かしても良い最大の期間)がどれくらいかを把握することは、保守運用の観点で非常に重要である。これを「システムタイムチャート」 「バッチスケジュール表」 「ジョブバーチャート」 などと呼ぶ。本ガイドラインでは「システムタイムチャート」と呼ぶ。
【簡易版: システムタイムチャートの例】
最低限、どのジョブがどのように動くかを記載する。形式は「ガントチャート」 や「バーチャート」で記載する。門限となるイベント(例えば、開局や対向システムへのデータ送信の門限など)を記載すると良い。上図はmermaid.js で記載しているため、ジョブ間の依存関係を線で表現できないが、本来は記載したほうが分かりやすい。draw.io など別の作画ツールの利用も検討すると良い。PlantUMLではガントチャートに依存関係を書けるようである。
こういったシステムタイムチャートは以下のようなユースケースがある。
- あるジョブが失敗した場合、影響を受けるジョブと業務が何か把握して、暫定対応案の検討、エスカレーション、アナウンスを行いたい
- 新規にジョブを追加する場合、どれくらい時間的余力があるか確認したい
推奨は以下。
- ジョブ間に依存関係が発生する場合は、システムタイムチャートを作成しておく
- 必要に応じて、ジョブの依存関係や定時起動などの起動条件を追記する
謝辞
このアーキテクチャガイドラインの作成には多くの方々にご協力いただいた。心より感謝申し上げる。
- 作成者: 真野隼記、本田健悟、宮崎将太、武田大輝、村田靖拓、澁川喜規