
1. 初めに
DBにおける処理はSQLによって記述しますが、データの取得するために具体的にどのような内部処理を行うかという点までは記述しません。
ここでいう内部処理とは「SQLの書き換え」「インデックスの使用」「結合アルゴリズムの選択」などがDBMSのオプティマイザによって選択されて実施されることを指します。
SQLのパフォーマンスを見るにあたっては上記の内部処理について正しく理解する必要があります。
本Blogでは、重要なアルゴリズムであるにもかかわらず、まとまった情報が少ないSQL実行時におけるブルームフィルタ(Bloom Filter)についてOracleをもとに紹介を行います。
Bloom Filterは結合処理を効率化するために、結合の前段階で利用される技術になります。
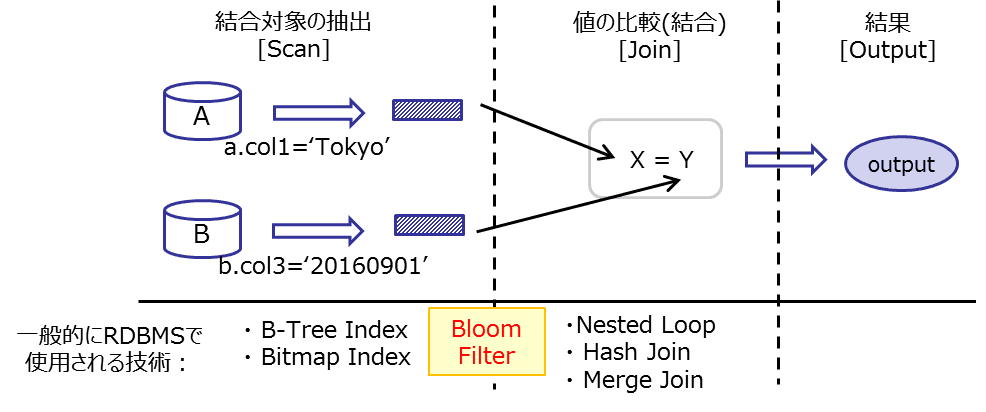
公式なドキュメントとしては以下になります。
Oracle Database SQLチューニング・ガイド 12cリリース1(12.1) 結合の最適化 ブルーム・フィルタ
2. Bloom Filterとは
Bloom Filterの概要は他サイトを参照してください。
ポイントとしては以下になります。
- ある集合データからBloom Filterを作成した場合、Bloom Filterを利用してその集合の中にデータが含まれているかどうかを判定できる
- その判定は100%正しくなく、「存在する」判定されたが実際は「存在しない」という誤検知を含む
- これを 偽陽性[false positive] と呼びます
- Bloom Filterは非常に小さいサイズとなることから、「インメモリで保持が可能」「別の処理(プロセス)にフィルタを渡すことが可能」というメリットがある
3. サンプルスキーマ
今回の説明は、Oracleのサンプルスキーマを用いて説明を行います。
説明に必要なカラム以外は省略しています。
Oracle Database Sample Schemas
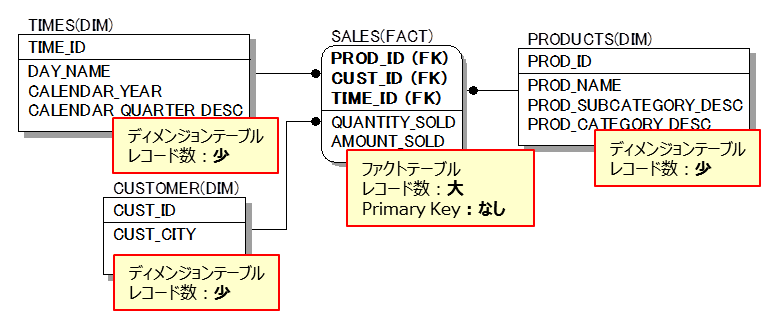
DWHにおけるスタースキーマ構成となっています。
- SALES表がファクト(OLPTでいうトランザクション表)
- TIME表、CUSTOMOER表、PRODUCTION表がディメンジョン(OLTPでいうマスタ表)
- レコード数はファクト表が非常に多く、ディメンジョン表はそれほど多くはない
実場面ではSALES表にはBitmap Indexを作成する例も多いのですが、今回は無しの状態で議論を進めます。
4. SQL実行時のBloom Filter
SQL実行時におけるBloom Filterは「テーブル結合(Join)」で利用されます。
また、「結合操作はハッシュ結合(Hash-Join)であること」という大前提があります。
その理由はハッシュテーブルを作成するタイミングでBloom Filterを同時に作成するからです(ハッシュ結合についてはここなど参考にどうぞ)
4-1. Bloom Filterを使わない場合のハッシュ結合
サンプルスキーマにおけるハッシュ結合の具体的なフローは以下のようになります。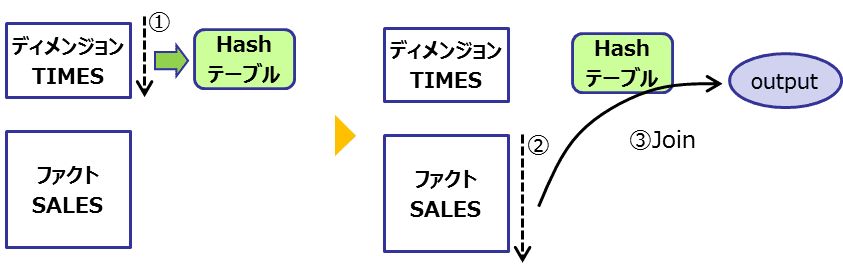
- ディメンジョン表(TIMES)を全スキャンしてハッシュテーブルを作成
- ファクト表(SALES)を全スキャン
- ハッシュテーブルを確認して結合できるかを判断する(値の比較)
4-2. Bloom Filterを用いた場合のハッシュ結合
これが、Bloom Filterを使うと以下のようになります。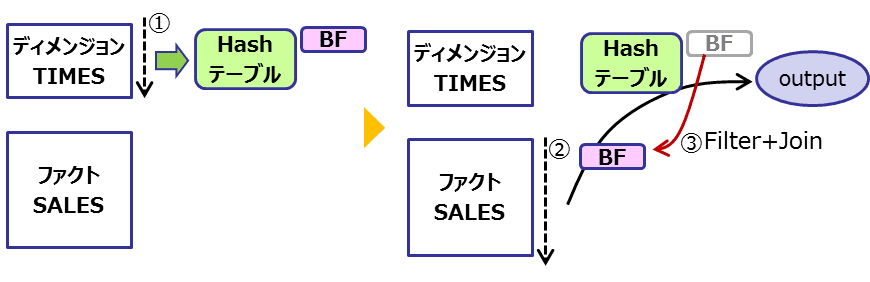
- ディメンジョン表(TIMES)を全スキャンしてハッシュテーブルとBloom Filterを作成
- このBloom FilterをチェックするとTIMESに該当レコードが含まれているかが判断できます
- ファクト表(SALES)を全スキャン
- Bloom FilterをチェックしFilterを通過(TIMESに該当レコードがあると判断した)したレコードについてハッシュテーブルで結合を実施
- このフローにより結合操作の対象をフィルタできるのが分かります
Bloom Filterには偽陽性を含むため、Bloom Filterを通過するレコードは実際には必要のないレコードも含まれてしまいます。このレコードについてはハッシュテーブルの確認をした際に結合対象なしと判断されて除外されます。
4-3. Bloom Filterを用いた複数テーブルの結合
さらに、複数のテーブル結合の場合以下のようになります。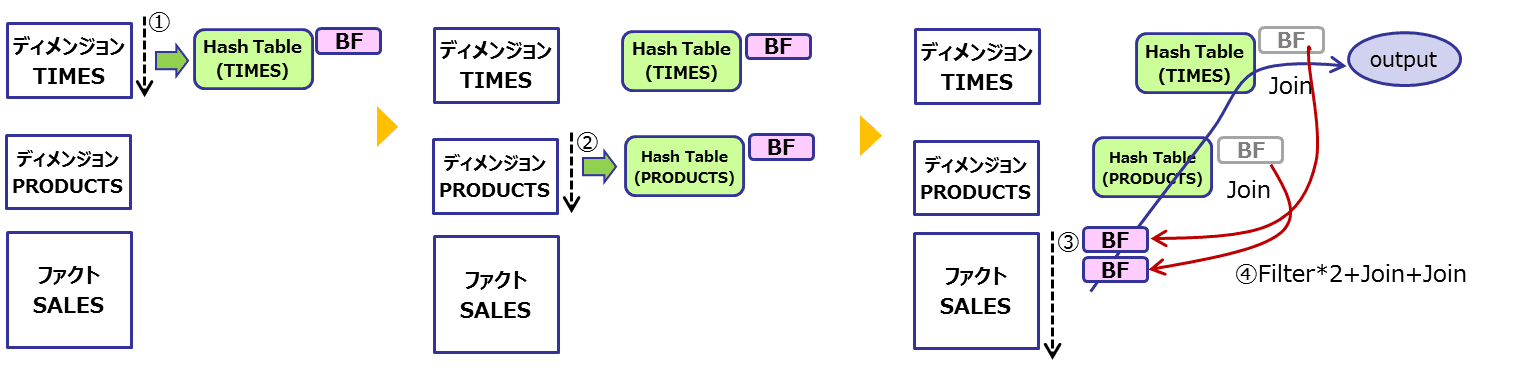
- ディメンジョン表(TIMES)を全スキャンしてハッシュテーブルとBloom Filterを作成
- ディメンジョン表(PRODUCTS)を全スキャンしてハッシュテーブルとBloom Filterを作成
- ファクト表(SALES)を全スキャン
- 2つのBloom FilterをチェックしてFilterしたレコードに対してハッシュ結合を2回(PRODUCTS、TIMESの順番に)実施
- 結合前に2つのBloom Filterを組み合わせてチェック(双方のフィルタを通過する必要がある)しているので、ハッシュ結合の対象データをいきなり減らすことができます
この挙動をサンプルスキーマ(スタースキーマ)で実際に利用するSQLをベースに説明します。
スタースキーマにおける複数テーブルを結合するSQL
SELECT |
例として各テーブルは以下の条件でデータが存在すると仮定します。
- SALESテーブルに全レコードが100万件存在する
- TIMES.CALENDAR_YEAR=’2001’に該当するレコードが10万件存在する
- PRODUCTS.PROD_CATEGORY=’Photo’に該当するレコードが1000件存在する
という場合、Bloom Filterを利用することで(4)の結合は1000レコードに減らすことができます。
100万レコードが1000レコードになる。Excelent!!
と、ここまで書くと非常に素晴らしい機能のように見えます。
しかし残念ながら、DWHにおいて最も負荷の高い(3)ファクト表の全スキャンについては何も変わっていないためパフォーマンス上の効果は限定的なのです。
4-4. SQL実行時のBloom Filterまとめ
まとめると、SQL実行時におけるBloom Filterの利用について以下のことが言えます。
- テーブル結合(Join)時に結合対象のデータを減らす効果はあるが、ファクト表のスキャン量は変わらないため普通に使うと効果は限定的
- ファクト表のスキャンサイズを減らすことが出来れば効果は出そう
この「普通に使うと効果は限定的」という条件があるため「パーティション表」「パラレルクエリ」においてBloom Filterは利用されます(後述)が、非パラレルクエリでは効果が無いため利用されません。
5. OracleにおけるBloom Filterの利用
ここまでを踏まえて、Oracleにおいてどのように利用されているか見ていきます。
Oracle Database SQLチューニング・ガイド 12cリリース1(12.1) 結合の最適化 ブルーム・フィルタでは以下の4つにおいて利用されるとあります。
- 5-1. パーティションテーブル結合
- 不要なパーティションのアクセスを排除(パーティションプルーニング)するために利用
- 5-2. パラレルクエリ
- パラレルクエリ実行時のスレーブプロセス間で転送されるデータ量を低減させるために利用
- 5-3. Exadataにおけるストレージサーバ(セルサーバ)からDBサーバに転送されるデータ量を低減させるために利用
- 5-4. サーバの結果キャッシュにデータが存在するかどうかをチェックするため
(5-4)についてはSQL実行の利用ではないのでここでは除外します。
5-1. パーティションテーブル結合におけるBloom Filter
Bloom Filterの原則「テーブル結合(Join)時に結合対象のデータを減らす効果はあるが、ファクト表のスキャン量は変わらないため普通に使うと効果は限定的」を前提に、ファクト表がパーティションならパーティション単位でデータを減らせる可能性があるので適用しようというコンセプトです。
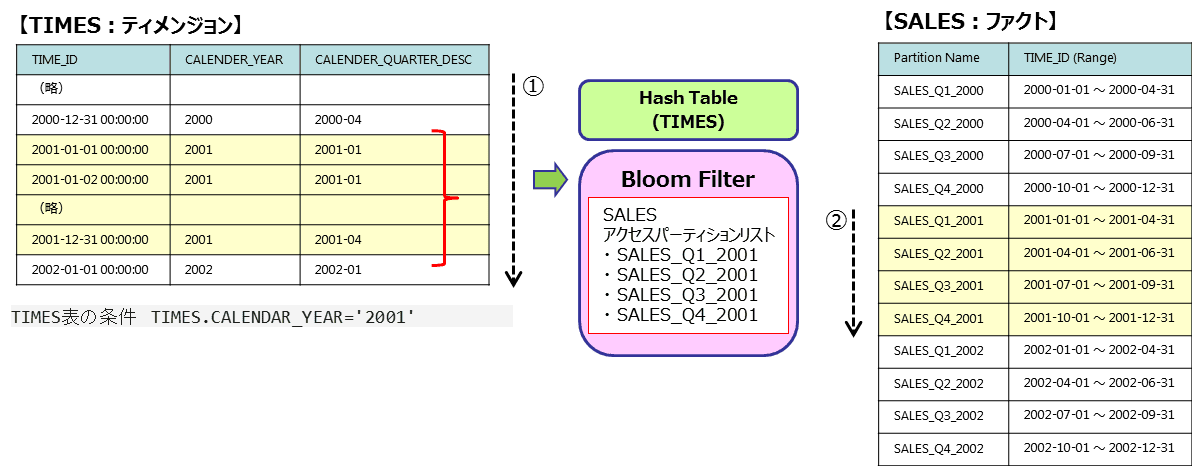
- (1)ディメンジョン表(TIMES)を全スキャンしてCALENDER_YEAR=’2001’に合致するデータでハッシュテーブルとBloom Filterを作成。ディクショナリよりSALES表のパーティション定義を取得して、結合対象データが存在するパーティションのリストをBloom Filterとして保持しています。
- (SALESのパーティションキーはTIME_IDでTIMES.CALENDER_YEARから導出可能です)
- (2)Bloom Filterを利用してファクト表(SALES)の必要なパーティションのみをスキャンして結合を実施します。
具体的にSQLの実行計画(プラン)を見ていきます。
**Tips: **
- SQLに
gather_plan_statisticsヒントを入れて実行した場合、SQL実行時の統計が記録されます。- 実行後に
dbms_xplan.display_cursorを利用することで記録された内容を確認することができます。- A-Rowsを見ると、SQL実行中にアクセスした行数が分かります。
- [参考URL]
パーティションテーブルでBloom_Filter利用するSQLを実行します。
SELECT /*+ gather_plan_statistics */ |
続いて、実行計画を確認します。
select * from table(dbms_xplan.display_cursor(null,null,'ALLSTATS ALL')); |
最後に、パーティション内のデータ件数を確認します。
select to_char(a.TIME_ID,'YYYY') time_id_year,count(*) |
実行計画のLINE#3(id=3の部分) 「PART JOIN FILTER CREATE」でフィルタ(BF000)を作成
LINE#6 BF000を利用してアクセスパーティション範囲を特定しているのが分かります。
アクセスした行数は259Kレコードで、SALESの2001年のデータとレコード数が一致しています。
例ではSALESのパーションキーに対応していたので、Bloom Filterの効果がはっきりとわかりましたが、条件によってはパーティションの特定が出来ずにフィルタ効果がないこともあり得ます(たとえば、TIMES.CALENDAR_YEAR between ‘1995’ and ‘2000’ という条件の場合、SALESの全データが必要になるためパーティションフィルタによる効果はゼロです)
パーティションのフィルタ効果が出るかは条件によりますが、Bloom Filterによるパフォーマンス上の副作用もないので、ディメンジョン表とファクト表がパーティションキーで結合される場合ほぼ間違いなく実行計画に登場します。
このSQLの実行操作についてはBloom Filterの特徴を活用していないためBloom Filter操作の1つとすることにあまりしっくりきません。むしろ「PARTION RANGE JOIN-FILTER」という名称の方が理解しやすいのではと感じます。
5-2. パラレルクエリにおけるBloom Filter
Bloom Filterの原則「 テーブル結合(Join)時に結合対象のデータを減らす効果はあるが、ファクト表のスキャン量は変わらないため普通に使うと効果は限定的」を前提に、パラレルプロセス間のデータ転送量を減らすときに適用しようというコンセプトです。
- パラレルクエリとは、クエリ実行を複数のプロセスで並列化実行する機能です。
- 詳細はこちらを参照してください。
実行計画の確認
具体的にSQLの実行計画(プラン)を見ていきます。
**Tips: **
今回はSQLの実行計画だけを参照するため、explain plan forをSQLの前につけることで実行計画の作成を行なった後、dbms_xplan.displayを実行することでSQL実行計画の表示を行っています。
パラレルクエリでBloom_Filterを利用するSQLを実行します。
explain plan for |
続いて、実行計画を確認します。
select * from table(dbms_xplan.display(null, null, 'ALL allstats last outline')); |
図示すると以下のような流れになっているのがわかります。
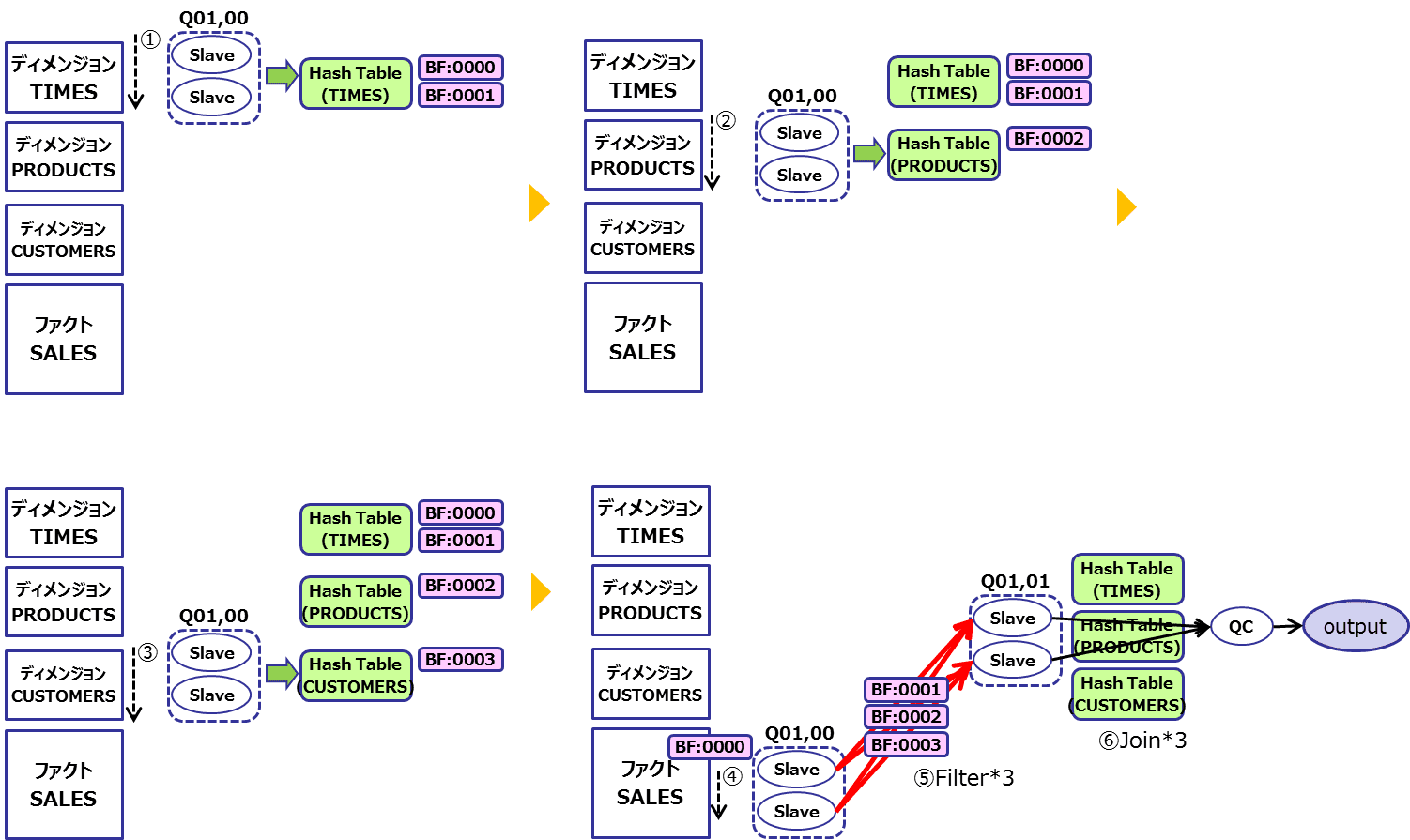
- TIMES表をスレーブプロセス群(Q01,00)はパラレルスキャンしてハッシュテーブルとBloom Filterを作成。この時、パーティションフィルタ用(BF0000)と、パラレルプロセス用(BF0001)の2つを作成
- PRODUCTS表をスレーブプロセス群(Q01,00)はパラレルスキャンしてハッシュテーブルとBloom Filter(BF0002)を作成
- CUSTOMERS表をスレーブプロセス群(Q01,00)はパラレルスキャンしてハッシュテーブルとBloom Filter(BF0003)を作成
- SALES表に対してBF0000を利用して必要なパーティションのみスレーブプロセス群(Q01,00)はパラレルスキャン
- スレーブプロセス群(Q01,00)は3つのBloom Filter(BF0001,BF0002,BF0003)を利用して、転送するデータを削減して、別のスレーブプロセス群(Q01,01)に転送
- スレーブプロセス群(Q01,01)はハッシュテーブルを利用してパラレル結合を実施して結果をQCプロセスに転送
ここでのポイントは(5)において転送データの削減を行っているところにあります。
実行計画でのLINE#21を見ると、3つのBloom Filter(BF0000,BF0001,BF0002)を同時に利用してデータを絞り込んでいるのが分かります。
filter(SYS_OP_BLOOM_FILTER_LIST(SYS_OP_BLOOM_FILTER(:BF0003,"SALES"."CUST_ID"),SYS_OP_BLOOM_FILTER(:BF0002,"SALES"."PROD_ID"),SYS_OP_BLOOM_FILTER(:BF0001,"SALES"."TIME_ID")))
Bloom Filterの効果計測
次に、Bloom Filterの有り無しでSQLの実行計画とI/Oがどのように変化するか見てみます。
まずはBloom Filterを利用しない場合の実行計画を確認します。
**Tips: **
- Bloom Filterを使用しないヒント句として
no_px_join_filter(テーブル名)があります。- これを使用することで指定テーブルに対してBloom Filterは作成されなくなります。
パラレルクエリ:Bloom_Filterなし※データは整形済み
(使用したヒント:SQL本文は省略) |
続いて、Bloom Filterを利用する場合の実行計画を確認します。
変更したのはヒント句のみです。
パラレルクエリ:Bloom_Filterあり※データは整形済み
|
Bloom Filterありとなしの実行計画を見てみると、実際にアクセスしたレコード数(A-Rows)は1/3000になっていますが、読み込みデーブロック数(query)はそれほど変わっていないため、実行時間(elapsed)も劇的には変わっていません。
| # | 実際にアクセスしたレコード数(A-Rows) | 読み込みデーブロック数(query) | 実行時間(elapsed) |
|---|---|---|---|
| Bloom Filterなし | 4,150,688 | 13,482(6909+6573) | 0.4 |
| Bloom Filterあり | 1,328 | 10,346(5620+4726) | 0.23 |
一見パフォーマンスに効果がありそうだけど、実際はいまいちの効果です。結合対象レコードは減らせるのですが、そもそもファクト表をスキャンするサイズは変わらないからです。
過度の期待は禁物です。
5-3. ExadataのストレージサーバにおけるBloom Filter
これは「パラレルクエリにおけるBloom Filter」のコンセプトをExadata のストレージサーバ(セルサーバ)とDBサーバに適用するというコンセプトになります。
処理の流れは、パラレルクエリの時と考え方は同じです。パラレルプロセスがストレージサーバに置き換えて考えます。
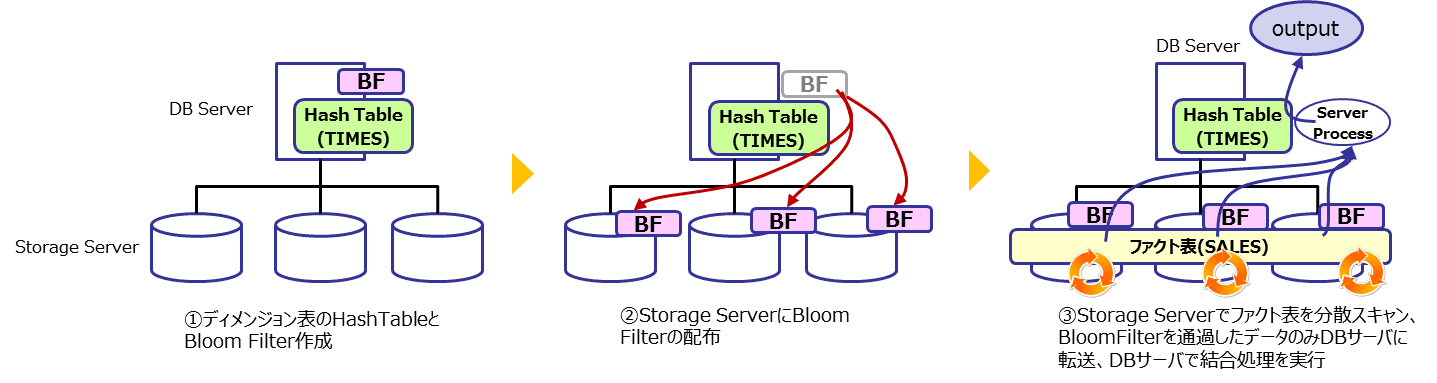
- ディメンジョン表(TIMES)をスキャンしてハッシュテーブルとBloom Filterを作成
- Bloom Filterをストレージサーバに転送する
- ストレージサーバ側でファクト表(SALES)をスキャンしBloom Filterを通過したデータのみをDBサーバに転送
ExadataでのBloom_Filter例
(使用したヒント:SQL本文は省略) |
LINE#17がストレージサーバでのBloom Filterの適用を示します。
storage(SYS_OP_BLOOM_FILTER_LIST(SYS_OP_BLOOM_FILTER(:BF0003,"SALES"."CUST_ID"),SYS_OP_BLOOM_FILTER(:BF0002," SALES"."PROD_ID"),SYS_OP_BLOOM_FILTER(:BF0001,"SALES"."TIME_ID")))
さらに、Exadataの持つStorage IndexとBloom FilterデータのMin/Max値を利用してさらにデータを絞り込無ことが可能です。これによりBloom FilterによるデータSCAN処理効果が得られます。
Storage Indexは、ストレージサーバにおいて、あるデータの格納単位における列データのmin/maxを保持することで、そのデータ格納単位を読み込む必要があるかを判断できるExadata特有の機能です。
Oracle Exadata Storage Server Software User’s Guide “Improved Join Performance Using Storage Index”
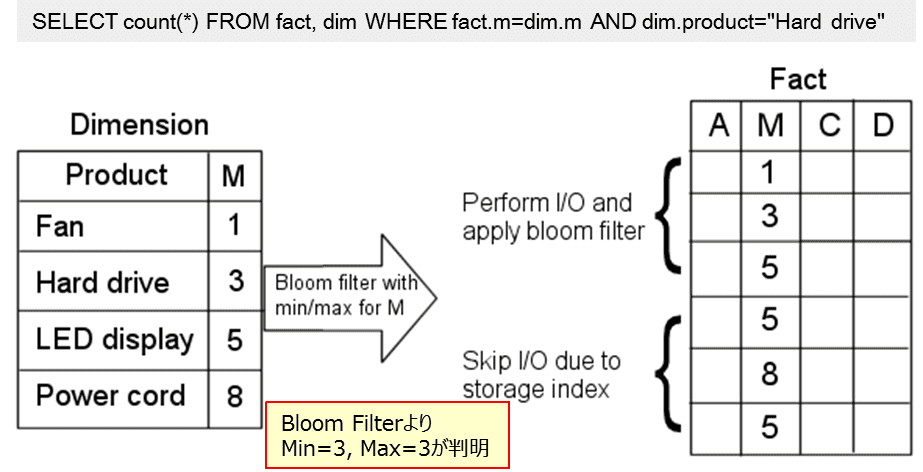
例では、min=3,max=3という値でStorage Indexを利用してファクト表のSCANサイズを削減しています。min=3, max=100という幅広い値である場合はStorage Indexの効果は得られないため、この効果はデータ内容に依存したものとなります。
データ内容に依存はするけど、ファクト表のSCANサイズを減らすことができる」ここ重要なポイントです。
5-4. In-Memory機能におけるBloom Filter
ここまで見ていきましたがBloom Filterはたしかに効果はあるのだけど、画期的というほどでもないのが実情でした。具体的にはマニュアルには記載されていないのですが、In-Memory機能がある場合は事情が変わります。
ここでの図は全てOracle Database In-Memory詳細編 検索処理の詳細より引用しています。
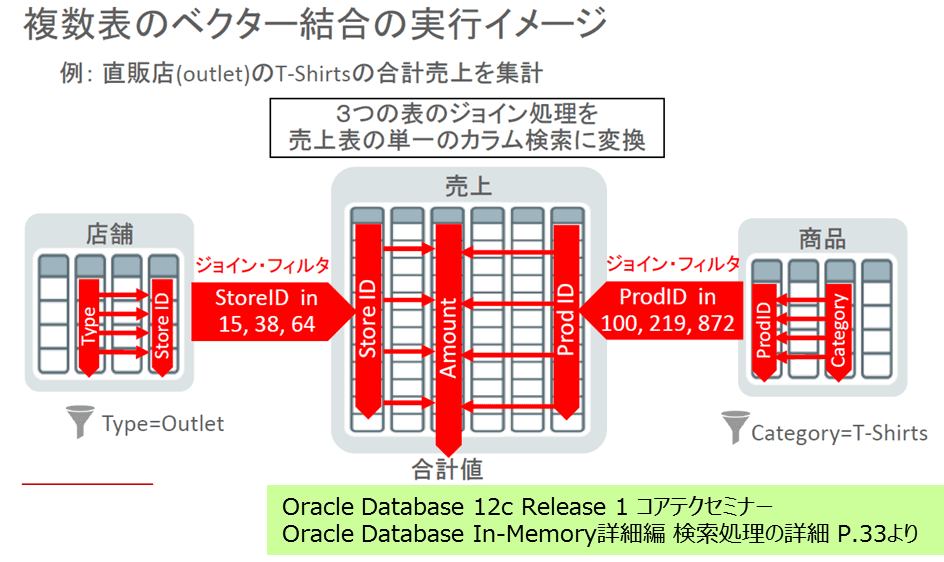
この絵の例で結果取得までの流れは以下の通りです(パラレルクエリーでのみ動作します)
- 「店舗」表でBloom Filter(図ではジョンフィルタと書かれています)を作成
- 「商品」表でBloom Filter作成
- 「売上」表をスキャン(具体的には謎ですが、列指向なので列ごとにアクセスしているのではないかと推測します。StoreID列でフィルタに該当するものを調査→Prod ID列でフィルタに該当するものを調査→StoraID列、Prod ID列の双方で必要なAmount列という流れでアクセスしていると思われます)
- 「商品」表でHash結合
- 「店舗」表とHash結合
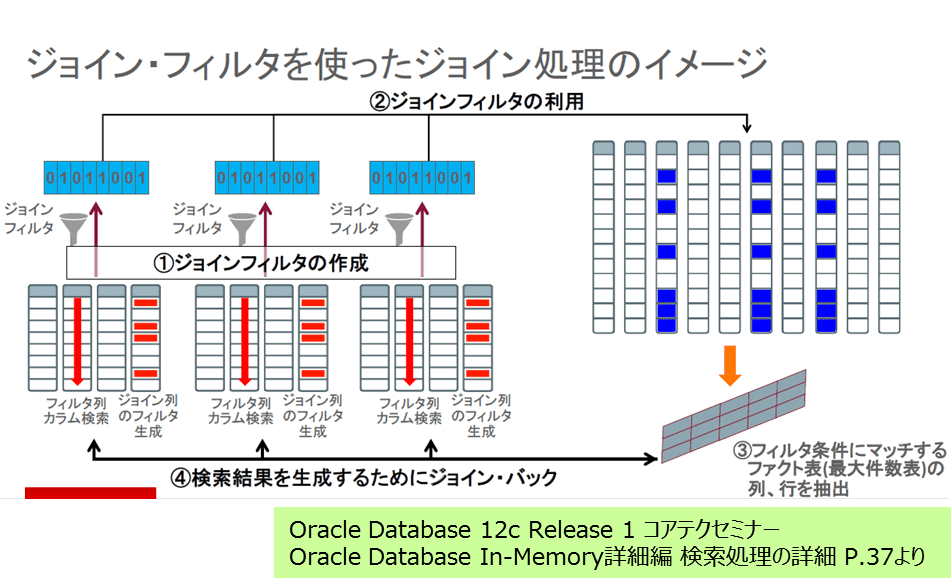
もう少し具体的なイメージ図は上記のとおりです。
(3)「フィルタ条件にマッチするファクト表(最大件数表)の列、行を抽出」の効率化がポイントです。ここではIn-Memoryの備える以下の機能が利用されます。
- 列指向による必要な列のみアクセス
- カラムデータ保持単位(IMCU)に設定されているインメモリ・ストレージ索引(ExadataのStorage Indexと同じです)
- SIMD(Single Instruction Multiple Data)による効果的な値の比較
これらのすべてが利用されることで結合処理が非常に高速で実行可能となります。
6. OracleにおけるBloom Filterの利用のまとめ
ここまでの話をまとめると、以下のようになります。
| # | Bloom Filter適用シーン | Filter効果 | ファクト表SCAN処理 低減効果 | 効果 |
|---|---|---|---|---|
| 5-1 | パーティション表結合 | パーティションの選択 | なし | 効果小 |
| 5-2 | パラレルクエリ | スレーブプロセス間転送サイズ | なし | 効果小 |
| 5-3 | Exadataストレージサーバ | ストレージサーバからの転送 | Storage Indexの利用 | 効果中 |
| 5-4 | In-Memory | スレーブ プロセス間転送サイズ | 列指向型データ保持、In-Memory Strage Index、SIMDの利用 | 効果大 |
Bloom Filterが利用される(5-1)(5-2)(5-3)(5-4)のすべてにおいて、Filter効果(結合対象データの削減)は確かに有効ではあるのですが、パフォーマンス重要なファクト表のSCAN処理の低減効果があるのは(5-3)(5-4)についてとなります。パフォーマンスという点では(5-3)(5-4)の場面で大きな効果が見込めます。
(5-3)はExadataの機能、(5-4)はOracle In-Memoryオプションによる機能ということで、通常のEnterprise Editionにおいては利用できないのは残念です。
7. 終わりに
Bloom Filterについて詳しく見ていく中で、Filter自体の効果よりファクト表のSCANサイズを減らすことがパフォーマンス上に効果を与えることが有効であることがわかりました(ある意味当たり前の結論ですが)。この視点で見てみると(Exadataについては特殊なのでおいておくと)Oracle In-Memoryについては本質的には列指向データ保持による効果と言えます(Oracle In-MemoryはOLTPにも対応しているのでメモリを利用していますが、分析用であればインメモリである必要はないので列指向であることが重要と言えます)
また、データが大規模になるほどBloom Filterの「Bloom Filterは非常に小さいサイズとなることから、「インメモリで保持が可能」「別の処理(プロセス)にフィルタを渡すことが可能」という効果が重要になってきます。そのため、分散DB(シャーディング機能による複数のサーバにおけるデータを分散保持)においてExadataと同じくサーバ間でBloom Filterを渡すことで処理を効率よく結合処理を分散させることができると言えます。
Bloom Filterアルゴリズムは「列指向型データベース」「分散DB」に有効であることから今後も利用が広がると予測されます。
8. さらなる終わりに
Oracleのマニュアルは読み物としても質が高いためバージョンアップが行われた際は、Oracleに携わることの多いエンジニアの方はぜひ読み込むことをお勧めします。
12c(12.1)のリリースが行われた際に、SQLチューニングについて新しいドキュメントが追加されました。従来「パフォーマンスチューニングガイド」の一部を独立させて、内容を充実させてドキュメントにしたものです。上級者にとっても新しい発見があると思います。
- Oracle 12c R1のドキュメント > Oracle Database SQLチューニング・ガイド 12cリリース1(12.1)