背景
- 社内ヘルプデスク(Redmine)における管理対応の業務を効率化し、サービスレベルを上げたい
- 現状の課題
- 起票されたチケットの解決にかかる時間が長い
- 原因の1つは、正しい担当者にチケットが割当てられず滞留することがあること
- 処理されないチケットは、カテゴリが正しく設定されていないものが多かった
- 弊社の運用としてカテゴリ単位で専門的な担当者が割り当てられているので、カテゴリを間違うとやり取りが増え、解決までに時間がかかってしまいます
Redmineについては下記を参照下さい
http://redmine.jp/overview/
作ったもの

Redmineにチケットが新規に起票すると、過去のデータから自動的にカテゴリを設定する仕組みをDeepLearningを用いて作成しました。
これにより正しい担当者にチケットが割り当てられ、チケットの平均解決時間の向上を狙います。
この仕組に対して、親しみを持たせたいということで あいちゃん と命名しました。
例えば下記のような動きです(※社内情報に触れそうなところは隠しています)
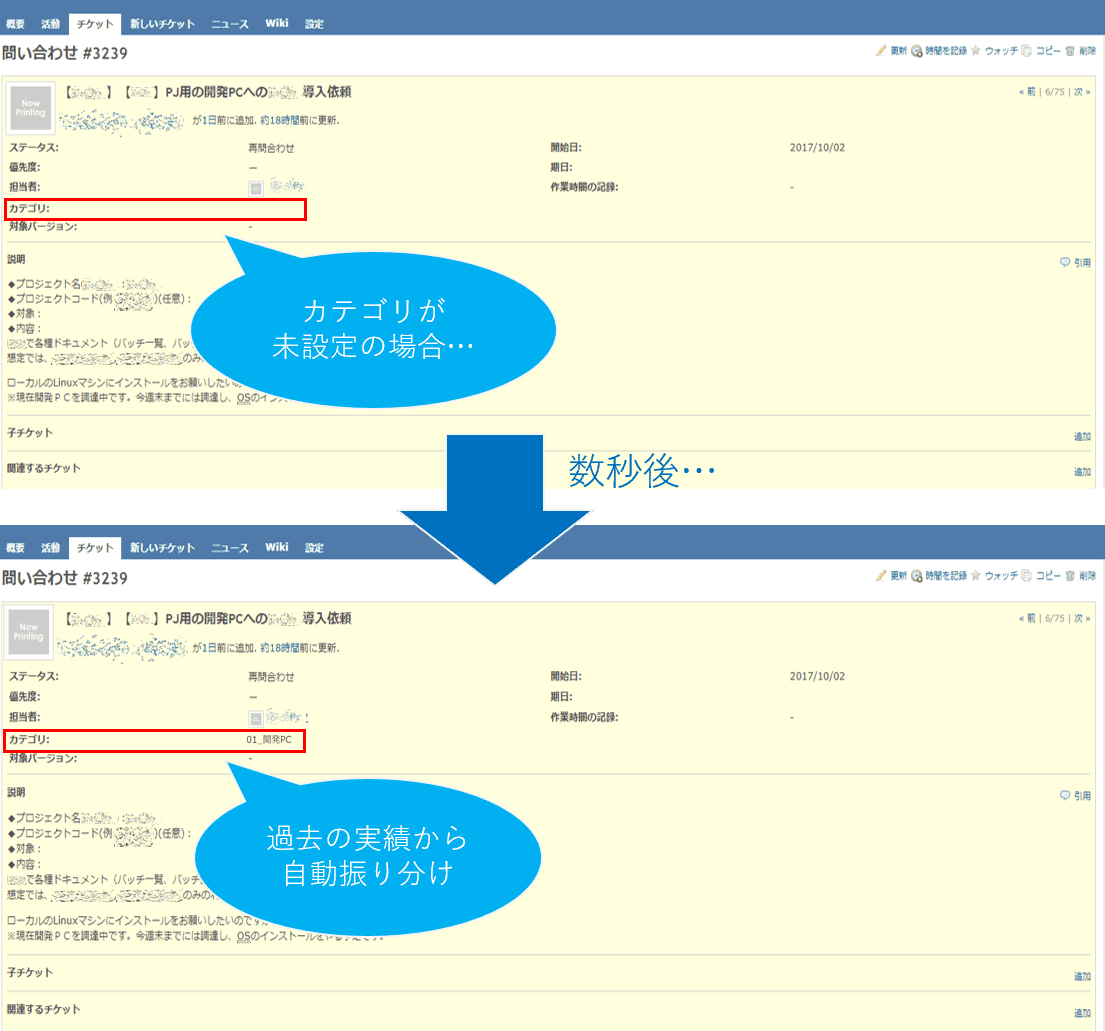
さらに、カテゴリが自動設定されたことに驚かないよう、振り分けた旨のコメントもセットで投稿するようにしました。
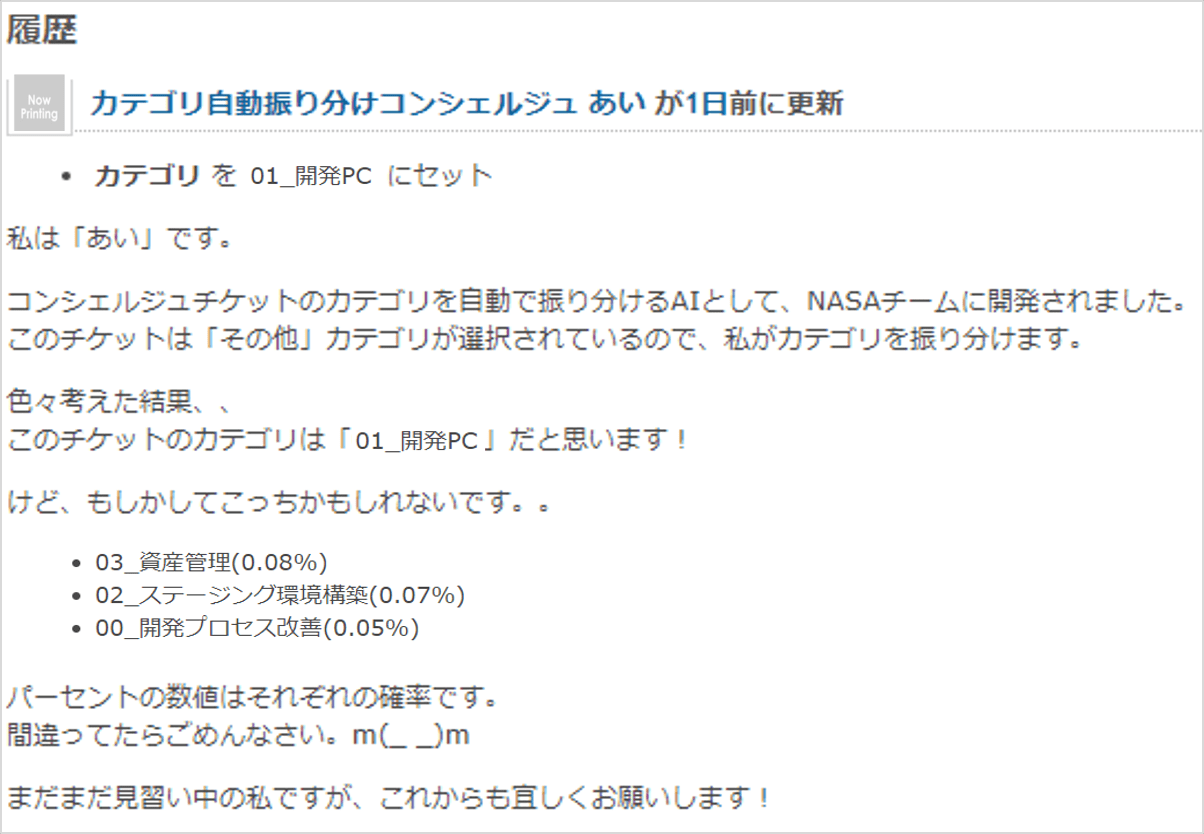
万が一、間違った振り分けをしても許してもらえそうな新人さんキャラクターを演出しています。
今のところクレームは届いていないのですが、彼女の貢献も大きいと思います。
採用技術
- Python パッケージ
conda(4.3.11) # Pythonのパッケージ管理python-redmine(2.0.2)- Keras (2.0.5)
- tensorflow (1.2.0)
- Janome (0.2.8) # 形態素解析
- Ruby パッケージ
- faraday(0.13.0) # HTTP client library
- ジョブ系
- Jenkins (2.7.4)
- ミドル
- Docker (17.03.1-ce)
処理の流れと構成
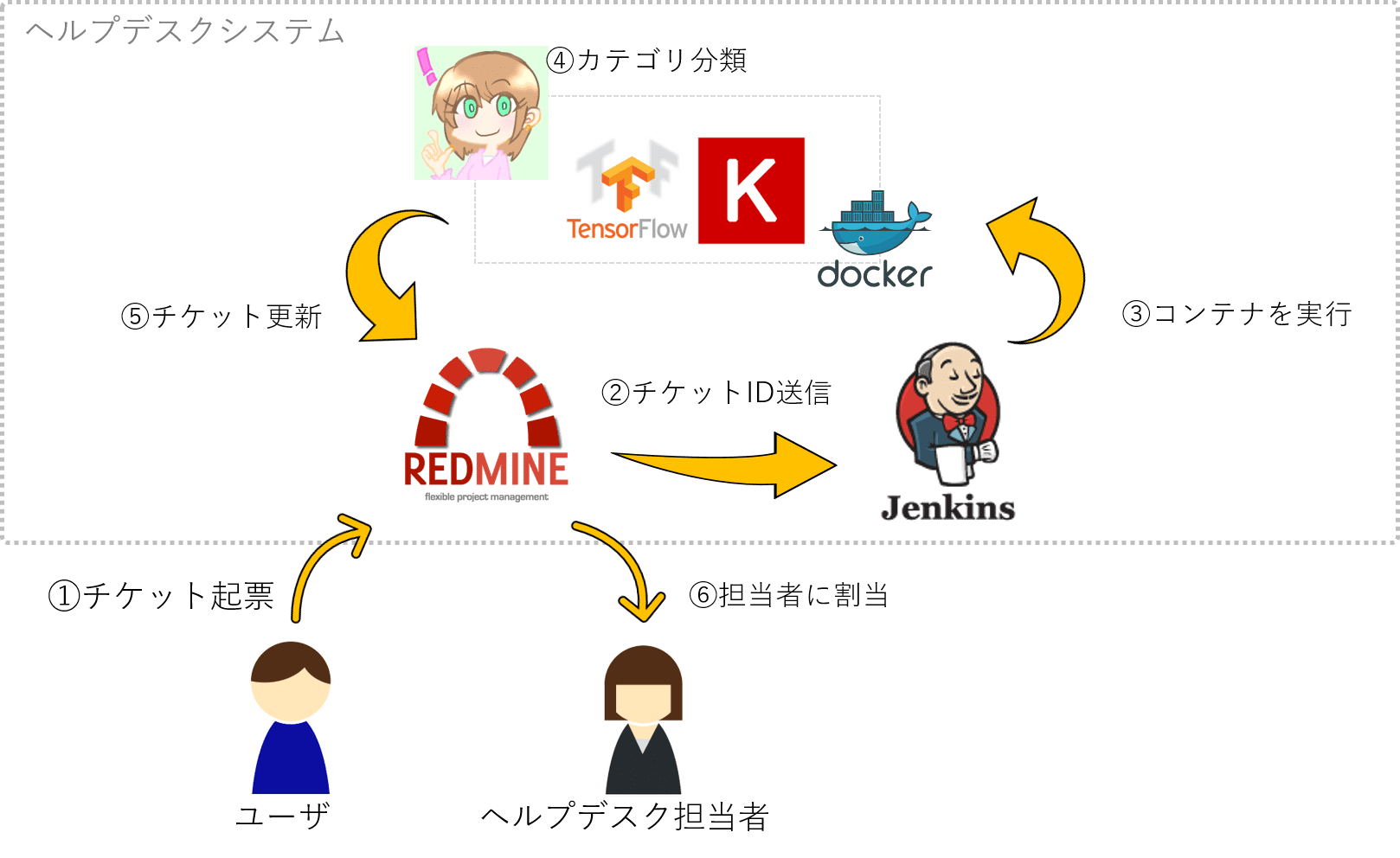
チケットの自動カテゴリ設定の処理フローです。
- Redmineにチケットが起票される
- Redmineのweb hook pluginを使ってJenkinsジョブを呼び出す
- JenkinsはKeras Dockerコンテナを起動
- Kerasでチケットのカテゴリを判定を行う
- カテゴリの判定結果をRedmineのWeb API経由でチケットを更新
- カテゴリに紐付いたヘルプデスク担当者に、Redmine経由で通知がなされる
あいちゃんの実体は、Dockerコンテナ上のKeras(Tensorflow)+ 連携用のRubyスクリプトです。
ユーザからはRedmineのカテゴリが、あいちゃんユーザから更新されたかのように見えます。
あいちゃんを作成
まずは、 あいちゃん のコアとなるAI部分を開発します。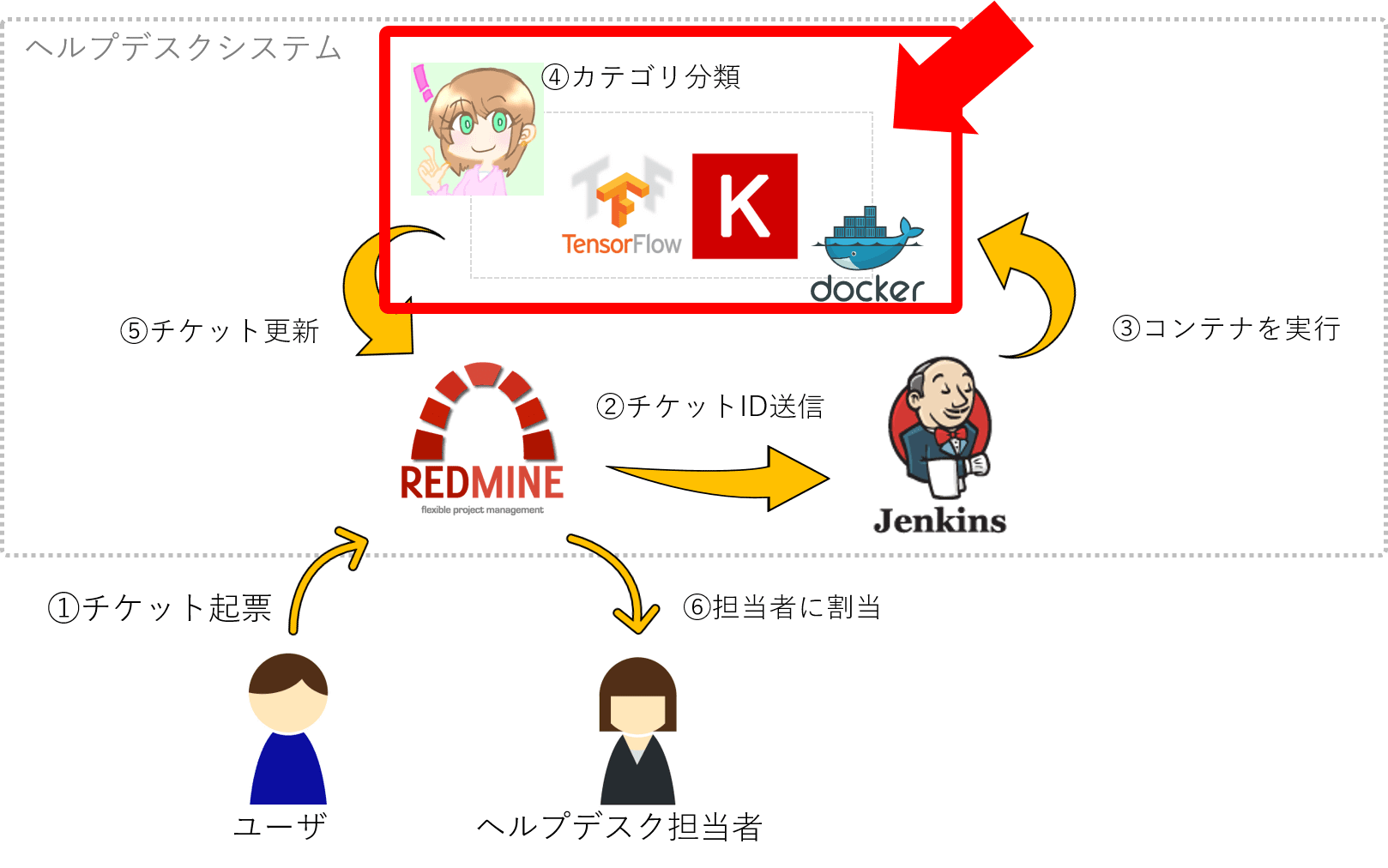
今回はKerasライブラリを使います。
Kerasで学習&判定させるときに必要なフローは以下の1~3です。
- 教師データを準備する
- モデルを用意する
- 学習させる
- 判定させる
1. 教師データの作成
元となるデータは運用中のRedmineが利用するDBに蓄積されている3000件のデータです。
まずは教師データを作成します。
教師データとは、入力データとそれに対応した正解データ(バイナリ)のタプルです。
$$ 教師データ = (X(入力データ), Y(正解データ)) $$
今回は、「チケットの件名」と「チケットの内容」の文字列からカテゴリを出したいので、以下の形式です。
$$ X(入力データ) = チケットの件名 + 内容の文字列 $$ $$ Y(正解データ) = カテゴリ $$
入力データ(X)と正解データ(Y)の作成フローを下図にまとめました。
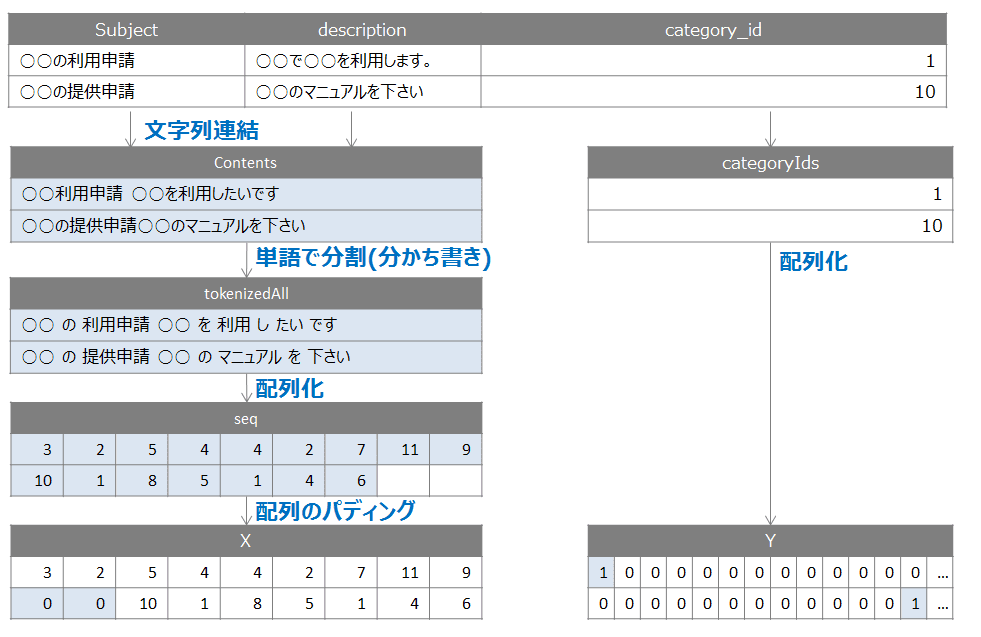
# 題名と本文を結合 |
2. モデルを用意する
CNN、RNN、LSTMで技術検証を行った結果、最も正解率が高かったCNNを採用しました。
CNNを利用した実装は下記のようなイメージになります。
model = Sequential() |
3. modelで学習させる
教師データを設定します。
Kerasを用いると、モデルを作成後、fix function に X(入力データ) , Y(正解データ) , epoch数を渡すだけで学習できます。
※poch数とは、学習をさせる回数です。この回数を増やすと限界はありますが重みづけが最適化されていきます。
model.fit(X, Y, epoch...) |
4. 判定する
学習は終わっているので、あとはX(入力データ)を与えると判定できます!
また、後続で使うRedmine操作用に、結果を加工しておきます。
result = model.predict(predictX) |
Redmineのチケットを更新
続いて、Redmine APIを使って、対象のチケットを更新します。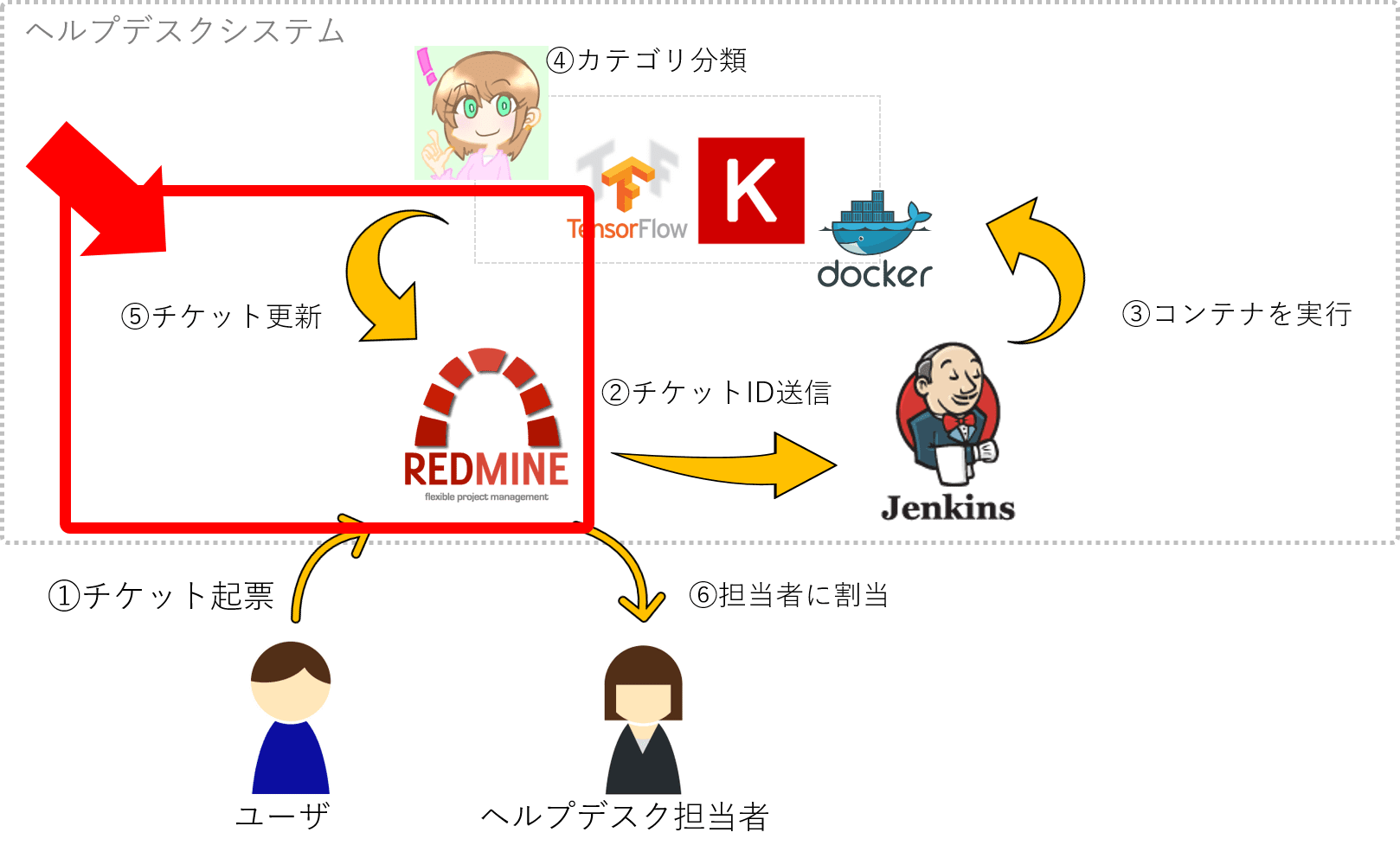
Python-RedmineとAPIキーを使って、対象のチケットを新しいカテゴリIDで更新します。
これをコンテナの最後の処理に差し込めば、Redmineのチケットが更新されます。
from redminelib import Redmine |
以下を参考にしました
- https://python-redmine.com/
- http://www.redmine.org/projects/redmine/wiki/Rest_Issues
- http://qiita.com/mima_ita/items/1a939db423d8ee295c85
Jenkinsジョブの作成
今回はRedmineから直接Kerasコンテナを呼ばずに、間にJenkinsを経由させるアーキテクチャになっています。
そのため、DockerコンテナをキックするJenkinsジョブを作成します。
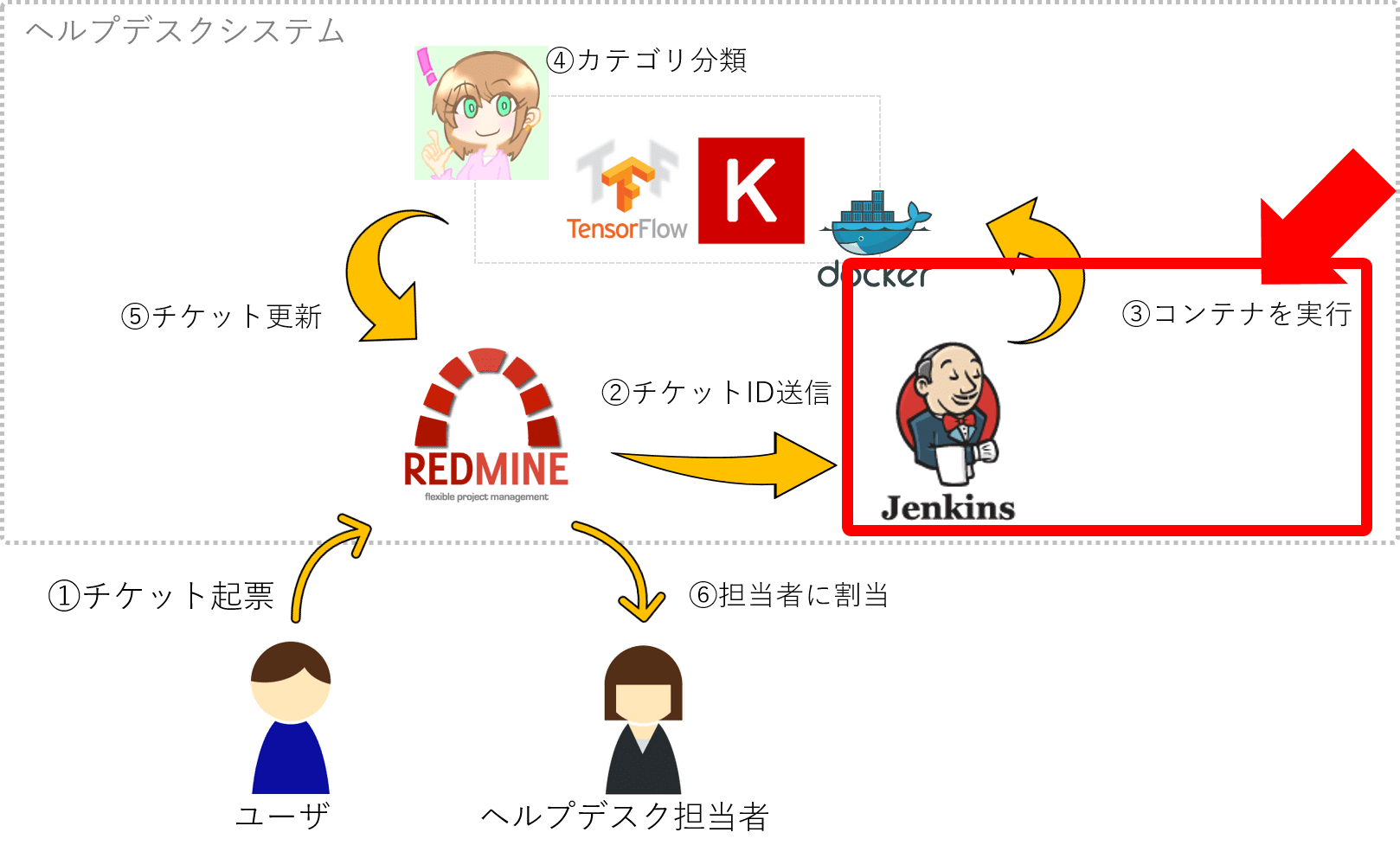
# KerasコンテナがいるジョブサーバにSSHで接続して、コンテナにticket_idを渡します。 |
以下を参考にしました
Redmine Pluginの作成
RedmineとJenkinsを連携させる部分を作ります。
Redmineにチケットが起票されたイベントをトリガーにしてJenkinsジョブを呼び出します。

import faraday |
以下を参考にしました
- https://wiki.jenkins.io/display/JENKINS/Remote+access+API
- https://wiki.jenkins.io/display/JENKINS/Parameterized+Build
まとめ
結果と所感について..。
- 目論見どおり大変だったチケットの再振り分けが減りました
- 実は私もヘルプデスクに担当を持っていますが、チケット対応が以前より楽になったと実感しています
- 意外だったのは、epoch数が10回程度でも思ったよりと正答率が高い(約80%)ということ
- Deep Learning の登場で機械学習の敷居は相当下がっていると感じます。みなさんも是非チャレンジしてみてください!
あいちゃん は今後も大きく育てていきます!
- チケットの担当者振り分け
- カテゴリ毎にだいたい同じような担当者になるので、一緒に入れてしまえるのでは?
- あいちゃんと対話できるようにしたい
- チャット形式でチケット起票における質問にある程度答えてくれると助かるのでは?
フューチャーアーキテクトでは、技術的視点だけでなく、ビジネス視点からも応用先を考え技術検証・現場への導入を行っています。
興味がある方、一緒に働きましょう! ぜひメッセージ下さい。