はじめに
こんにちは。データサイエンスチームの李(碩)です。
以前、古典的ゲームAIを用いたAlphaGo解説に紹介したAlphaGoの最新バージョンが2017年10月19日に発表されました。
この記事では、最新のAlphaGo、AlphaGo Zero の仕組みについて紹介です。
本文を直接読みたい方はスライドをご覧になってください。
AlphaGo のバージョン
AlphaGo には下記の4つのバージョンがあります。
1. AlphaGo Fan
・2015年10月にヨーロッパの囲碁チャンピオンFanに勝利
2. AlphaGo Lee
・2016年3月に過去世界最強と呼ばれたイ・セドルに勝利
3. AlphaGo Master
・2017年1月、オンラインで世界最強の棋士たちに60:0で勝利
4. AlphaGo Zero
・2017年10月に論文発表
前回の古典的ゲームAIを用いたAlphaGo解説に紹介したAlphaGoのバージョンは「AlphaGo Fan」になります。AlphaGo ZeroはAlphaGo Fanとアーキテクチャレベルから大きく異なります。Fanの場合、2つのディープニューラルネットワーク(DNN)で構成され、その他にも結構複雑なアーキテクチャになっています。しかし、Zeroの場合は1つのDNNだけで、学習プロセスもすごく簡単になりました。簡単になったけど、学習は早く、性能も強力になったのです。
AlphaGo Zeroのすごいポイント
1. 人がプレイしたデータを必要としない
AlphaGo Zeroのすごいところは、以前のAlphaGoと違い、人がプレイしたデータを一切必要としないことです。以前のAlphaGoは、まず人がプレイした数百万の囲碁のデータで学習して、その後に自己対局を通じて強くなる形でした。しかしAlphaGo Zeroは最初から人のプレイデータ無しで、自己対局だけで学習していきます。AIを作る時に一番苦労をするのが、良質のデータを手に入れることです。多くの場合、データを集めるのがすごく大変だったり、データの質がよくなかったり、そもそもデータが無かったりします。AlphaGoはその苦労無しで学習してくれるのです。
2. 手作りインプットの削除
以前のAlphaGoはインプットに囲碁の背景知識が必要なデータを人が手作りして入力してました。しかし、AlphaGo Zeroのインプットは石の配置履歴だけです。つまり、AlphaGo Zeroは囲碁の背景知識が全くない状況で学習を始めるのです。背景知識なしで問題を解決するこの進化により、囲碁でない他の問題でも、AlphaGo Zeroは活用できると予測されています。
3. 圧倒的なパフォーマンス
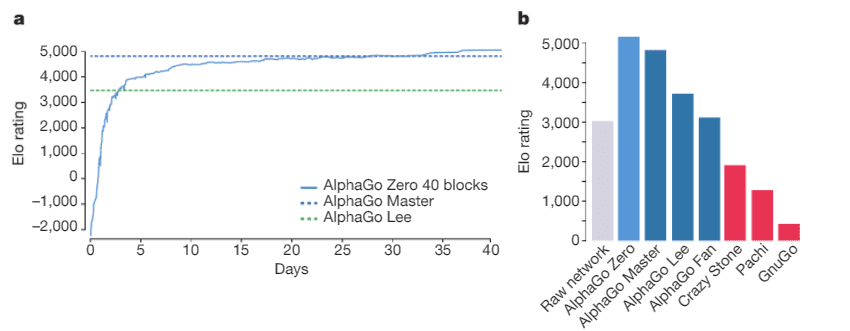 AlphaGo Zeroはアーキテクチャが簡単になったわりにAlphaGo FanやLeeより圧倒的なパフォーマンスを誇ります。学習時間も、計算速度も比べられるものではありません。たった36時間で数か月学習したAlphaGo Leeを超えて、40日でAlphaGo Masterを超える。驚異的なスピードです。
AlphaGo Zeroはアーキテクチャが簡単になったわりにAlphaGo FanやLeeより圧倒的なパフォーマンスを誇ります。学習時間も、計算速度も比べられるものではありません。たった36時間で数か月学習したAlphaGo Leeを超えて、40日でAlphaGo Masterを超える。驚異的なスピードです。
本資料の狙い
本資料ではAlphaGo Zeroの仕組みを分かりやすく解説します。AlphaGo Zeroはどう作られているかが知りたい方はぜひご覧になってください。
本資料の目次
- AlphaGo Zeroを構成する2つのパーツ
- ニューラルネットワーク(DNN)
- モンテカルロ木探索(MCTS)
- AlphaGo Zeroの学習プロセス
- MCTSによる自己対局
- DNNの学習
- 学習前後の性能比較
- AlphaGoの各種バージョン
- AlphaGo Fan vs. AlphaGo Zero
- AlphaGo Zeroの性能評価
- 教師あり学習 vs. 強化学習
- 人の動き予測
- まとめ
- 参照論文
まとめ
AlphaGo Zeroは人のデータを必要としない、そして囲碁の背景知識を全く使わないことで、他の領域でも活用できると思われています。今後、AlphaGo Zeroを元にどんな面白い課題を解決していくのか、すごく楽しみですね!