はじめに
みなさん、こんにちは。
Strategic AI Group(通称 : SAIG)の岩田です。
今回は以前に社内開催されたNIPS2017のLT大会につづきICLR2018の社内LT大会の模様を紹介いたします!
ICLRとは
- International Conference on Learning Representations の略
- 2013年度に初開催されたカンファレンスで、今年で6回目
- 2018年本大会ページはこちら
- 表現学習という意味では採択される内容も広めです。ざっと投稿された表題に目を通しましたが、やはり研究内容としてHOTであるadversarial(敵対的な)に関連する研究は多かったように見受けられました。
社内勉強会の様子
SAIGグループに閉じた開催ではなく、社内で興味のあるメンバーを募って実施しています。
開催時間帯としては、一番メンバーの集まりやすいお昼時に開催です!


実演も交えた形で初学習者にもわかりやすい内容になっていました。
(プレゼンへのこだわりは、たとえLTスタイルだとしてもFutureらしさがあります)。
論文の選択
Conference Track の「Oral Papers」「Poster Papers」から各々が興味あるものを選択し、披露しました。
私個人としては分散表現に興味があるので、関連するテーマを選択しています。
LTの内容
簡単にではありますが、それぞれの発表内容を記載します!
1. Diffusion Convolutional Recurrent Neural Network: Data-Driven Traffic Forecasting
- 発表者:貞光
手法(HOW):
従来の時系列予測問題に対しては、ARIMAモデルやカルマンフィルタ等が用いられていますが、交通量のネットワーク自体がグラフの性質を持つため、グラフをより適切に扱える方法が要求されます。
加えて問題となるのがエッジ重みの非対称性です。ホリデーシーズン等を思い浮かべるとわかりやすいと思いますが、上り線と下り線でまったく交通量が異なりますよね。そのため、同じエッジであっても、エッジの方向によって重みが異なる非対称性を扱う必要が生じます(図1参照)
近年では、グラフをニューラルネットワークで扱うための手法が多く提案されており、その手法は大きく2種類に大別できます。
1つ目はグラフスペクトル情報を用いた系で、Graph Convolutional Network (GCN) [Bruna+2014] が代表的です。[Yu+2017]は、GCNに対し系列データを扱えるように拡張しましたが、無向グラフしか扱えないという問題があり、交通量のようなエッジ重みの非対称性には対応できませんでした。
2つ目は明示的にグラフスペクトル情報を用いない手法で、 Diffusion CNN (DCNN) が代表的です。
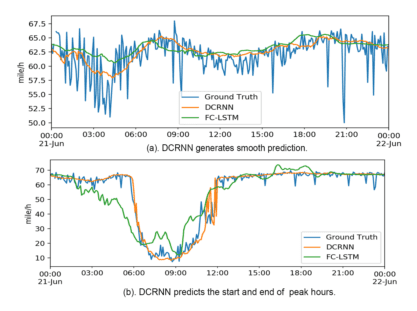
著者らはDCNNを時系列変化に適応させたDCRNNを提案し、交通量予測を高精度に実現しました。
実験の結果、ARIMAやFull Connected LSTMに比べ大幅な予測精度改善を実現しています(図2参照)。
また、コードは以下のGitHubで公開されていますので興味のある方は是非試してみてください。
https://github.com/liyaguang/DCRNN
図1
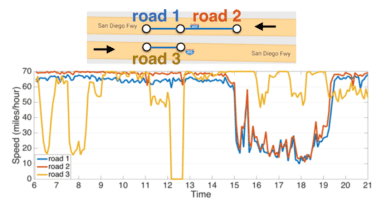
図2
[Bruno2014] Joan Bruna, Wojciech Zaremba, Arthur Szlam, and Yann LeCun. Spectral networks and locally connected networks on graphs. In ICLR, 2014
[Yu2017] Bing Yu, Haoteng Yin, and Zhanxing Zhu. Spatio-temporal graph convolutional neural network: A deep learning framework for traffic forecasting. arXiv preprint arXiv:1709.04875, 2017a
2. A New Method of Region Embedding for Text Classification
- 発表者:岩田
手法(HOW):
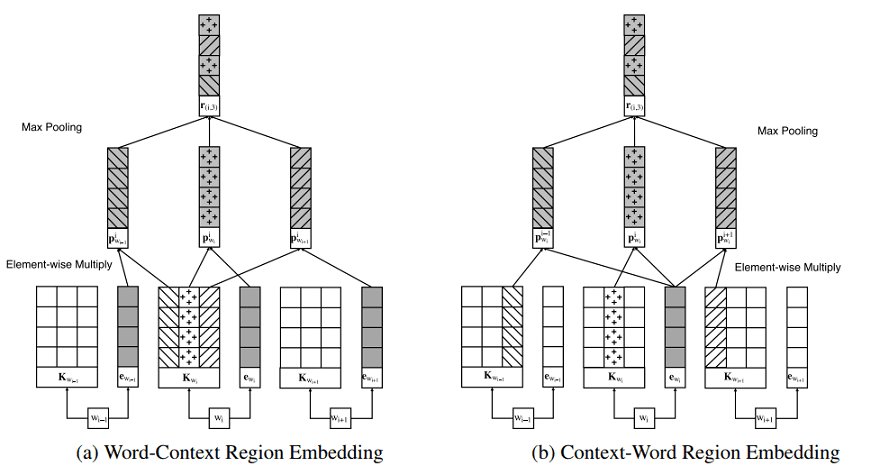
小単位での語順表現を取得する際にCNN等の手法を使わずに、Local Context Unitを用いてembeddingを表現する手法です。文章に対して適用されるregion(範囲)を決めて、取得できた文字列を通常のembedding結果 (e) に対してアダマール積算をします。
(例:The food is not very good in this hotel.という文章があった場合、中心語:not、region:2とすると
food is not very good が取得されます、これが今回でいうところの Local Context Unit (K) になります)
その積算結果 P を各コンテキスト毎に抽出し、Max pooling層を通して、最大値となるものを抽出します
(アーキテクチャとしては下図参照)その結果を用いて、課題の分類問題に当てはめていくというのが大枠になります。
精度としては、8つのデータセットに対して6つが最高精度を収めたという記載があり、Local Context Unitを用いた結果、より語彙の重要性を表現できた、係り受けを明確にできたため正しいsentimentを取得できたという結果になっています。
3. Don’t Decay the Learning Rate, Increase the Batch Size
- 発表者:小池
手法(HOW):
分散学習の際に、精度を落とさずに学習を早く行う手法を示しています。以前からImageNetのような大量のデータを学習するには時間がかかることが言われていました。理論的にはバッチサイズを大きくすれば学習が早く終わりますが、バッチサイズが大きいと精度の面でなかなか学習がうまくいかないことが以前から問題となっていました。
一般的なDeep Learningの学習では、学習が進むにつれLearning rateを小さくしていきますよね。ただしこれの手法は時間が非常にかかります。
本論文では、学習段階で学習率を小さくする代わりにバッチサイズを途中で増していくと学習がうまくいくことを主張しています。これの何が良いかというと、バッチサイズを大きくできる=早く学習ができるというメリットがあります。論文では、数値実験で学習率を減衰させた場合とバッチサイズを増やした場合を比較しており、両者ともに精度面では有意な差がないことを示しています。なお、数値実験ではWide ResNetでCIFAR10の学習を行っています。
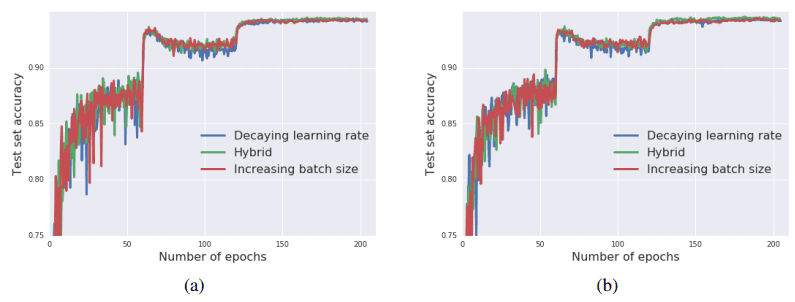
4. Learning Deep Mean Field Games for Modeling Large Population Behavior
- 発表者:西森
手法(HOW):
Collective Behavior(集団行動)中でも人口分布をモデル化し、その時間的発展を予測する手法です。
具体的な方法としては、Mean Field Game(以下MFG)のコスト関数(=報酬関数)を逆強化学習によってデータから学習する手法を提案したものになります。
MFGはコスト関数をヒューリスティックに定める必要があります。しかし、現実の集合行動に対してコスト関数を設計するのは困難なため、これらの実験はトイプロブレム(現実には役に立たない範囲)に留まっていました。
しかし、MFGをマルコフ決定過程(以下、MDP)として表すことでベルマン最適方程式を用いたシングルエージェントの強化学習で解くことができたという論文になります。
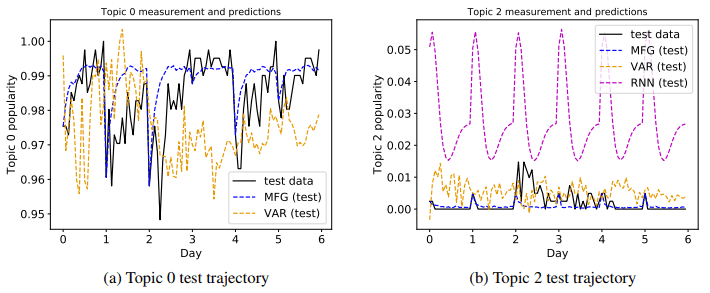
実験として、Twitterの人気トピック予測を行い、既存手法であるVAR,RNNよりも高い精度を示すことを確認しています(下図参照)。また、図(a)より、提案手法では「人気のトピックが、朝から夜にかけて人気になっていく」という特徴をとらえることができています。
5. Towards Neural Phrase-based Machine Translation
- 発表者:平賀
手法(HOW):
attentionを使わずに、ニューラルネットワークを用いた機械翻訳手法です。
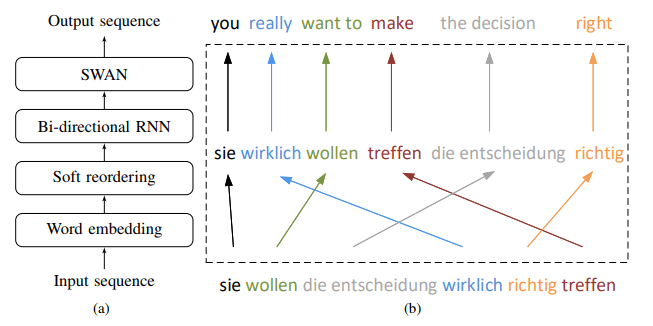
Sleep-WAke Networks (以下SWAN) にsoft reorderingを適用させた Neural Phrase-based Machine Translation (以下NPMT) の提案になります。
NPMTの構造としては、下図のようになります。input (ドイツ語) をoutput (英語) に翻訳する際に、最初のポイントとしてはsoft reorderingの実施になります。
SWANはinputとoutputの繋がりが単調である必要があるため、単語ごとにマッピングを行いinとoutで一致度が高い順に、語を並び替える作業を実施します。その結果をBi-directional RNNに適用し、得られた結果の集合を次ステップであるSWANに適用し、最終的な翻訳結果の出力となります。
実験結果としては、既存手法としてattentionを使ったsequence-to-sequenceモデルと比較したときに
BLEU評価で精度向上が見られました。
6. Learning how to explain neural networks: PatternNet and PatternAttribution
- 発表者:明官
手法(HOW):
ニューラルネットワークを用いた出力結果は「どうやってその結果を導いた」のかという根拠が不明確です。
(つまりブラックボックスである)本論文はその根拠を推定する新しい手法となります。
従来手法としては、重みとして表現される W を分析するということが考えられます。つまり、ネットワークとしてどのようなところに特徴があるのかをポイントで探ったり、出力層から追いかけて各層の出力と重みから貢献度はどの程度なのかを識別したりと W に関する様々な手法があります。
しかし、重みを分析しても結局は出力に寄与する値を導けないという内容を本論文では主張しています。というのも、本質的に W はノイズを消すように更新されるものであるということからです。
本手法では、まず始めにノイズ削減に着目します。ノイズを最小にする操作に注目することでどのような操作がクリティカルなのかを見極めます。またその操作が線形的な場合に限らず活性化関数である ReLU のような場合でも、パターン分け(ReLUの場合 x > 0 の場合とそれ以外の2パターン)を考慮することで対応が可能であることを示しています。
本提案手である Pattern Net and Pattern Attribution を用いた結果を下図になります。
従来手法に対して、人が理解できる表現抽出が可能になっていることが理解できます。

7. A Neural Representation of Sketch Drawings
- 発表者:石橋
手法(HOW):
本研究は人が作成したスケッチをインプットとして、特定のクラスの手書き風スケッチをアウトプットする取り組みです。データセットとして、オンラインで提供されている、スケッチ認識サービスQuickDrawから得られた75クラス各7万枚のスケッチを利用しています。
研究の特徴としては、スケッチのデータが画像ではなく、(Δx,Δy,p1,p2,p3)で表される点のリストSで構成されている点が挙げられます。Δx,Δyは前の点からの移動、 p1,p2,p3はペンの状態(接触しているか、終わりか)を表すパラメータとなっており、画像というよりも書き順に近いデータを保持していることがわかります。
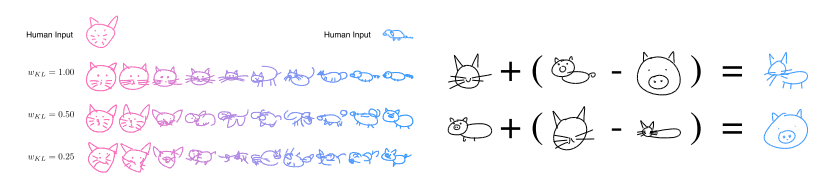
このような点のリストSを入力として、Sequence-to-Sequence Variational Autoencoderモデルを用いた学習を行い、Sketch-RNNを作成しています(猫や豚のクラスに近づけて手書き風スケッチが出力されている)

また、特定のクラスの手書き風スケッチをアウトプットするだけではなく、2クラスの補間を行うスケッチや、スケッチの加減算も可能となります。
おわりに
今回も前回のNIPSと同様に、非常に学びのある勉強会となりました。
少し宣伝となりますが、フューチャーのSAIGチームでは、プロジェクトに所属しながらも自分の興味のある領域を常にインプットし、ビジネスにつなげる思いを持つメンバーが揃っています。
Futureでの働き方に興味がある方は是非こちらを参照してみてください。
エントリーお待ちしてます!