1. 初めに
こんにちは。Technology Innovation Groupの岸田です。
データベースシステムに対しては、高い信頼性・可用性・安定性が求められることから、データベースとしては、Oracle Database(以降はOracleと記載)やMicrosoft SQL Serverなどの商用製品が採用されてきました。
十数年前より、商用データベースの高いコストに不満を持つ企業において、OSSデータベースに注目が集まってきており、近年では基幹システムにおいてもOSSデータベースが採用されるケースも多くなっています。
このような背景から技術者としてもOSSデータベースのスキルは非常に求められている状況かと思います。
元々高額なライセンス料に加え、仮想基盤における課金体系の問題や2016年のOracle Database Standard Edition Oneの廃止などにより、基盤更改などを契機にOSS検討事例が増えてきました。
また、クラウド基盤を選択肢に入れた場合にも、柔軟にスケールアップが可能なOSSを採用したいという要望もあります。
OSSデータベースで広く採用されているのはPostgreSQLとMySQLがあります。今回は、エンタープライズ領域においてマイグレーション例が多いOracleからPostgreSQLについて、考慮すべき事項について2回にわたり紹介していきます。
2. マイグレーションの流れ
データベースの選定(アセスメント)
単にコスト面に問題を抱えているからといって、安易にOSSデータベースへのマイグレーションを決断することは危険です。そのシステムにおいて提供しているサービスに関して、マイグレーションによって機能要件及び非機能要件を満たせなくなっては元も子もありません。
マイグレーションの検討については、OracleとPostgreSQLの技術的な検討だけでなく、コスト算定(コストメリット)、移行期間やテストなどで多方面での検討が必要となります。この検討については、以下のようにQCDの視点で検討を行う必要があります。
Quality(品質)
「アプリケーション機能面」「システム非機能面」の両面について実現性を検討し、ノックアウト項目が存在しないかを評価します。システムによっては現行システムとのデータ連携や災害対策目的で別サイトへのレプリケーションを実現する必要が出てきます。この時点で抜け漏れが発生してしまわないように、現行の運用面を含めた細かい評価が必要となります。
Cost(コスト)
マイグレーションに関連するコスト評価をおこないます。以下の2点が考えられます。
- マイグレーションに関連する費用:「アプリケーションソース移行」「データベースミドルウェア自体の移行」「データ移行」
- 新基盤での費用:「ソフトウェアライセンス、基盤費用」
Delivery(納期)
マイグレーション実現にむけたスケジュールの評価を行います。基盤更改期限がある場合についはその期間内に実現可能かという評価が必要になります。
これらの検討結果を基にデータベースマイグレーションの判断を行います。
マイグレーション決定後の作業イメージ
データベースのマイグレーションが決定した後は、一例として以下のように進めていきます。
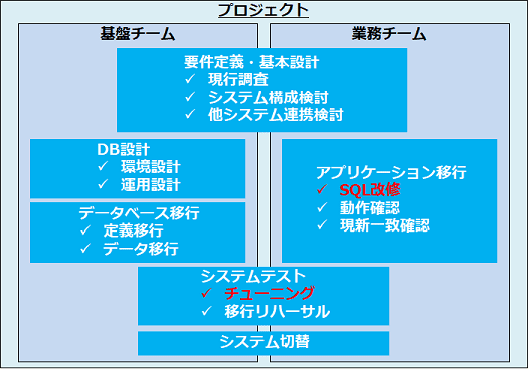
赤字となっている作業については、実装されているアプリケーションにより作業量が大きく変動するものとなります。
データベースのマイグレーションの成功は、現状アプリケーションの正確な把握に直結すると考えておりますので、現状把握については専門技術者を交えてしっかりと実施することをお奨め致します。
3. マイグレーションのポイント
前章にてマイグレーションの流れを説明しましたが、この章では実際にマイグレーションを実施するにあたりポイントとなる点を記載していきます。ポイントとしては以下の3点となります。
- スキーマ移行
- データベースの内部環境(オブジェクト等)の移行
- 2章のDB設計・データベース移行(定義移行)にあたる
- アプリケーション移行
- アプリケーションプログラムの移行。主にSQL改修となる
- データ移行
- データベースに格納されているデータの移行
上記それぞれについてみていきます(今回はデータ移行は紹介まで)
3-1. スキーマ移行(データベースオブジェクト)
2章で記載しましたDB設計フェーズにて方針を設計し、データベース移行フェーズにて実装致します。
Oracleに存在する主なオブジェクトについてPostgreSQLの存在有無は以下の通りです。
| Oracle | PostgreSQL | 備考 |
|---|---|---|
| テーブル | 〇 | |
| インデックス | △ | B-Treeインデックスとパーティションインデックスが存在。逆キーインデックス、ビットマップインデックス等は存在しない。 |
| ビュー | 〇 | |
| マテリアライズド・ビュー | 〇 | |
| シノニム | × | 一部ビューで代替可能。 |
| シーケンス | 〇 | |
| トリガー | 〇 | |
| データベースリンク | × | dblink関数または、FDW(Foreign Data Wrapper) で代替可能。 |
| パッケージ | × | 3-2で記載。 |
| プロシージャ | × | 3-2で記載。 |
| ファンクション | 〇 | |
| 〇:存在 △:一部存在 ×:無し |
インデックスについては一部の種類のインデックスは存在しませんが、インデックス自体は性能要件を満たすために作成されていますので、インデックスの存在自体がマイグレーションに影響を及ぼすことはありません。ただし、マイグレーション後の性能要件を満たすために別の方法を検討する可能性があります。
その他につきましては、代替機能を含めてPostgreSQLにて実装ができると考えております。
ストアド・パッケージ/プロシージャ/ファンクションについては3-2.アプリケーション移行で記載致します。
データ型の変換
テーブルのコンバージョンの際には、データ型を意識する必要があります。OracleとPostgreSQLのデータ型の対応表は以下の通りです。数値型にはいくつかのデータ型が存在しますので、システムとしてルールを定めることをお奨め致します。
| 属性 | Oracleのデータ型 | PostgreSQLのデータ型 | 備考 |
|---|---|---|---|
| 文字列 | CHAR/NCHAR/VARCHAR2/NVARCHAR2 | char/varchar | PostgreSQLの文字型の精度は文字数を意味する |
| CLOB/LONG | text | ||
| 数値 | NUMBER | smallint/bigint/integer/decimal/real/double precision | 精度によってデータ型を選択 |
| 日付 | DATE/TIMESTAMP | timestamp | |
| バイナリ | BLOB/RAW | bytea | |
| その他 | ROWID | oid |
3-2.アプリケーション(SQL)移行
アプリケーションの移行については、同じ製品のバージョンアップをする場合であっても一通りアプリケーションの動作確認(結果の現新一致確認)は実施することが多いと思います。
データベースのマイグレーションの場合は、このアプリケーションの動作確認において結果の不一致による原因究明やアプリケーションの見直しが発生する可能性が高くなることが考えられるため、当初よりアプリケーションの移行作業の作業量を多めに見積もることが大事だと思います。3章で説明したツールなどを利用して自動的なコンバージョンでアプリケーションの改修にかかる時間は削減できますが、アプリケーションの動作確認は必ず実施してください。
アプリケーションの動作確認と同様に重要なのは、性能テストとなります。データベースのマイグレーションでは、データベースの機能の差異がありますので、SQLの処理性能は事前の机上予測が難しいといえます。この性能テストについてもデータベースのバージョンアップ時のテスト作業量よりも多めに見積もっておくことをお奨め致します。
Oracleにて実装されているSQLについて、Oracle独自の記法であったとしてもPostgreSQLにて実装は可能であると考えておりますので、アプリケーション改修によりマイグレーションがNGとなることは無いと思います。
ただし、アプリケーションに依存して、改修作業や改修後の確認テストの作業量が変動していきますので注意が必要です。
アプリケーション移行についての考え方及び対策の一部を以下に紹介していきます。
ストアド・サブプログラム変換
ストアド・サブプログラムは、Oracleでのストアド・パッケージ、ストアド・プロシージャ、ストアド・ファンクションの総称です。
PostgreSQLにはパッケージ及びプロシージャが存在しません。
Oracleのストアド・パッケージ及びストアド・プロシージャはPostgreSQLのファンクションで実装することになります。
プロシージャ、ファンクションの集合体であるパッケージはスキーマで代用します。
まとめると以下のようになります。
| Oracle | PostgreSQL |
|---|---|
| パッケージ | スキーマ |
| プロシージャ | ファンクション |
| ファンクション | ファンクション |
PostgreSQLのファンクションでOracleと大きく異なる部分は、トランザクションの制御となります。PostgreSQLのファンクションは、呼び出し元のトランザクションに依存するため、ファンクション内でCOMMITの発行はできません。つまり、ファンクション内でエラーが発生した場合は、ファンクション内の処理はすべてロールバックします。
参考までに、Oracleでは、PRAGMA AUTONOMOUS_TRANSACTIONを利用して呼び出し元とトランザクションを分離できます。Oracleのストアド・サブプログラム内でトランザクションを分離している場合は、PostgreSQLではロジックを見直す必要があります。
外部結合
Oracle独自の記法としては外部結合が挙げられます。外部結合はSQLにおいて結合条件で対応するレコードが存在しない場合でも優先となるテーブルについてはレコードが除外されない結合方法です。
Oracle 9i以降はSQL標準である[LEFT | RIGHT] OUTER JOINの記述がサポートされるようになり、オラクル社としても同バージョンからOUTER JOINによる記法をマニュアル上でも推奨しています。
とはいえ、Oracleで動かすSQLの外部結合は(+)表記をよく目にします。
主な理由としては以下じゃないかなと思ってます。
- Oracle 8i 以前に作成したSQLが今でも使われている(バージョンアップを繰り返していて改修していない)。
- 以前プロジェクトとして作成していたシステムのSQLコーディング基準書では(+)表記で記載することが基準となっており、現状でも(+)表記自体は利用可能であるため、基準書自体を修正できていない。また、成功したプロジェクトの基準書を横展開している。
- プログラムの改修や新機能導入においても、現行で動作しているSQLを踏襲して作成する。
PostgreSQLにおいて外部結合は当然SQL標準であるOUTER JOINの記載となりますので、データベースマイグレーションの際にはSQLのコンバージョンが必要です。
(+)表記での外部結合をコンバージョンするときに気を付けなければならないのは、リテラル値に対する外部結合の条件がある場合です。
言葉だけでは分かりづらいと思いますので、Oracleで用意されているサンプルスキーマ(SCOTTユーザ)で見ていきます。テーブルはEMP表とDEPT表を使います。デフォルトの状態から少しだけ値を変えているところはあります。
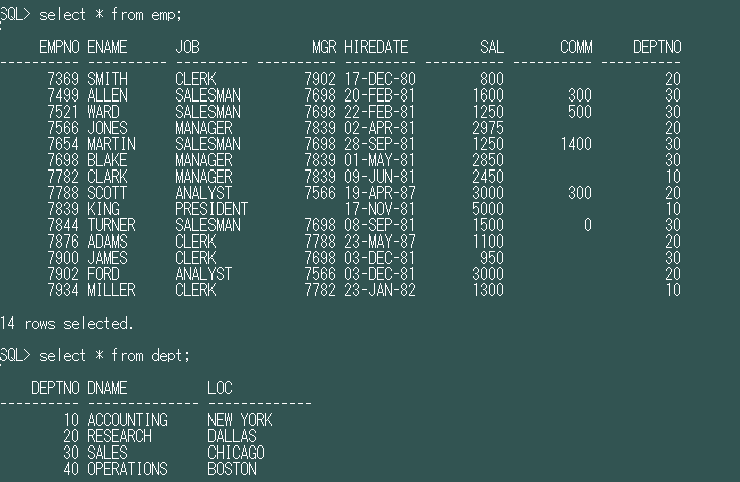
2種類の外部結合表記のSQL文を用意しました。
(1)リテラル条件にも「(+)」を付与したパターン
SELECT d.deptno, d.dname, e.empno, e.ename, e.comm |
(2)リテラル条件には「(+)」を付与しないパターン
SELECT d.deptno, d.dname, e.empno, e.ename, e.comm |
検索結果は以下の通りです。

(1)の場合は結合前にリテラル条件で絞っている、(2)の場合は結合後にリテラル条件で絞っている、ということです。
これをSQL標準であるOUTER JOINで記載すると以下のようになります。OUTER JOINの条件となるか全体の条件となるかの違いがSQL標準の方が分かりやすいですね。
(1)
SELECT d.deptno, d.dname, e.empno, e.ename, e.comm |
(2)
SELECT d.deptno, d.dname, e.empno, e.ename, e.comm |
念のため結果も。
PostgreSQLでも。
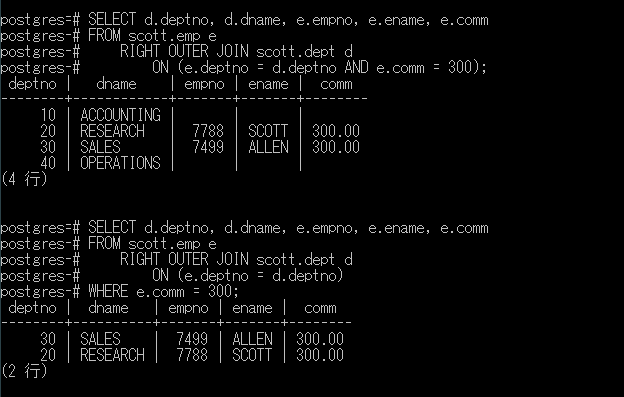
同じですね。
将来のことを考えて、外部結合はSQL標準のOUTER JOINで記述していくことにしましょう。
組み込み関数
組み込み関数はデータベース毎に事前に用意されている関数です。データベース毎に仕様が異なることもありますので、移行の際には注意が必要です。OracleとPostgreSQLの組み込み関数の対比表についてはこちらに詳しく載っておりますので、参考にしてください。
OracleとPostgreSQLの両方で用意されていますが、機能仕様が全く異なる関数としてはDECODEがあります。
OracleではDECODE関数は条件分岐として使われています。構文としては以下です。

PostgreSQLでは、DECODE関数はテキスト表現からバイナリデータを復号する関数となっております。構文としては以下です(formatオプションはbase64/hex/escapeから選択)。

OracleでのDECODE関数はPostgreSQLではcase文に変換します。
SELECT empno, ename, deptno, |
変換後は以下となります。
SELECT empno, ename, deptno, |
DECODEについては以上です。
一部のOracle独自の組み込み関数は、orafceモジュールをインストールすることで、いくつかOracleと同じ関数が実装されます。orafceで実装される関数についてはこちらを参考にしてください。また、AWSのRDSでも事前にOracleからの移行用にモジュール(スキーマ:aws_oracle_ext)が準備されています。
行レベルロック
一般的に業務ロジック上では競合による不整合を回避するため、SELECT ~ FOR UPDATEにより行レベルでロックを取得し、トランザクション中のレコードが他から更新・削除されることを防ぎます。
Oracleにおいては、FOR UPDATE句として[WAIT n|NOWAIT]の記述ができます。どちらも指定しない場合は、行が使用可能になるまで待機した後でSELECT文の結果が戻されます(そんな記載はできませんが、WAIT ∞の指定のような挙動です)。
PostgreSQLでは、WAIT nが存在しないため、WAITと記載するとOracleにおけるWAIT句を未指定とした場合と同様の挙動となります。つまり、OracleにおいてWAIT nが指定されていた場合は、PostgreSQLではSQLにて実装できません。
代替となるかは実行形式によりますが、lock_timeoutのパラメータを指定することでOracleと同じ挙動となる可能性はあります。このパラメータを設定してSELECT ~ FOR UPDATEを発行しすると、該当レコードがロック状態であった場合は設定したパラメータの時間経過するとエラーとなります。lock_timeoutはセッションレベルでの変更も可能ですので、トランザクション開始時にパラメータを設定をしてSQLを実行、トランザクション終了時にパラメータをリセットするという処理仕様とすることもできます。
ヒント句
OracleにおいてSQLの性能問題は実行計画が原因であることが多いのではないでしょうか。確かに、Oracleにおける性能劣化対策としての「ヒント句を記載して実行計画を固定化する」は、統計情報に依存せずにSQLの性能を安定させる最適な解決策なのかもしれません(バージョンアップの時にヒントが無くなったり、オプティマイザの機能向上により性能の良い実行計画が選ばれないというデメリット(?)もあります)。また、システムのSQLコーディング基準でヒント句を記載するといったルールがある場合もあるでしょう。
PostgreSQLではバージョン9.1以降pg_hint_planモジュールをインストールすることでヒント句の記載はできますが、Oracleほど数多くの種類のヒントがあるわけではありません(参考までにヒント句の種類としては、pg_hint_plan 1.1で23個、Oracle 12cR1で332個あります)。
データベースによりオプティマイザが全く異なりますので、データベースをマイグレーションすると実行計画が変化するのは致し方無いと考えております。そこで、ヒント句の記載のあるSQLについては、コンバージョン時には一旦ヒント句を削除して性能を見ることになります。処理性能が思わしくない場合は個別にチューニングの対応を施すことになります。
NULLと空文字
OracleではNULLと空文字は同義で、空文字はNULLとして扱われます。PostgreSQLではNULLと空文字は別物です。従いまして、Oracle上で動作するSQL内で条件句としてWHERE COL is NULLといった記載がある場合は、マイグレーションにより結果が異なってくる可能性があるので注意が必要です。
PostgreSQLでは、NULLの使用を禁止するといった基準を作った方が良いと思います。その場合は、データの移行時にNULLはすべて空文字に変換することは忘れずに!
NULLの四則演算やNULLと文字列の連結については、すべてNULLとなってしまうため、NULLが格納される可能性がある列を取り扱う場合は、必ずCOALESCE関数を使って処理してください(OracleでいうところのNVL関数ですね)。
MERGE文
OracleではMERGE文が利用できますが、PosrgreSQLではMERGE文は存在しません。
PosrgreSQL 9.5からUPSERT文(INSERT ON CONFLICT)が使用可能となります。
こちらもサンプルスキーマ環境で見てみましょう。
empと同じ定義のemp_up表を作成してます。

emp_up表のレコードを見てemp表にレコードが存在した場合はUPDATEをして、emp表にレコードが無ければINSERTをするというMERGE文を作ってみました(今回はSAL列とCOMM列だけをUPDATEしてます)。
MERGE INTO emp e |
実行結果です。
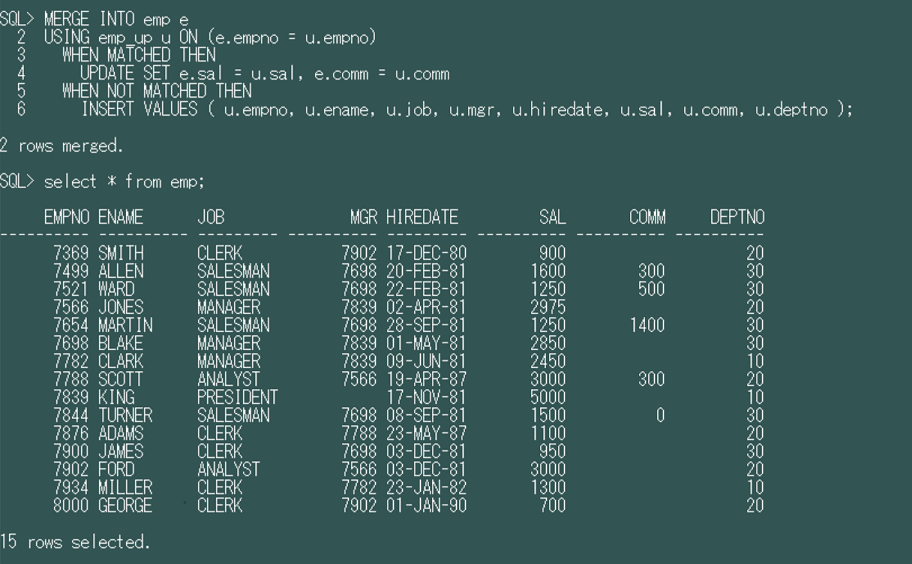
empno:7369のsal列が変更され、empno:8000のレコードが作成されていますね。
これをPostgreSQLで実装すると以下のようになります。
INSERT INTO scott.emp |
実行結果です。
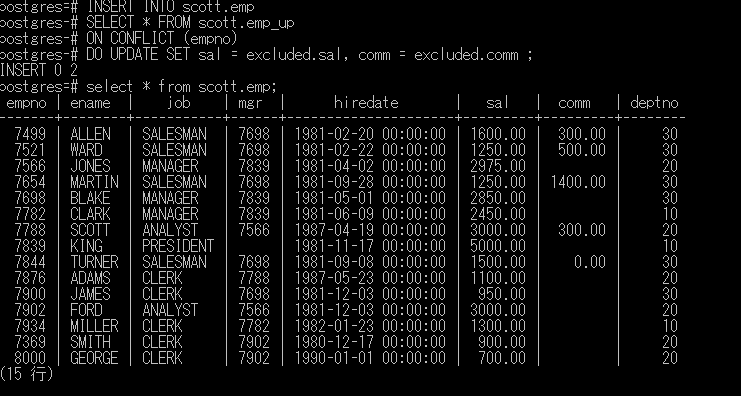
同じ結果となりました。
このUPSERT文ですが、PostgreSQL 9におけるパーティションテーブルに対しては機能しません。理由としては、PostgreSQLのパーティションテーブルは親となるテーブルとパーティション単位の個別テーブルを作成して、親テーブルへのDML発行時にはトリガーにより該当のパーティションテーブルを更新しており、親表に対してINSERT ON CONFLICTを発行したとしてもトリガーとしては該当パーティションテーブルに対してINSERT ON CONFLICTを発行しないからです。
それであれば、トリガー内でのパーティションテーブルに対する構文をINSERT ON CONFLICTとなるように作り直せば良いかというとそうもいきません。それは通常のINSERT文が発行された際もON CONFLICT付きのINSERTとなってしまうからです。
では、パーティションテーブルに対するMERGE文の変換はどうすればよいかというと、PostgreSQL 9.1で導入されたCommon Table Expression(CTE)を使って代替ができます。SQL文としては以下のようになります。
WITH insrt AS (SELECT * FROM scott.emp_up), |
実行結果です。
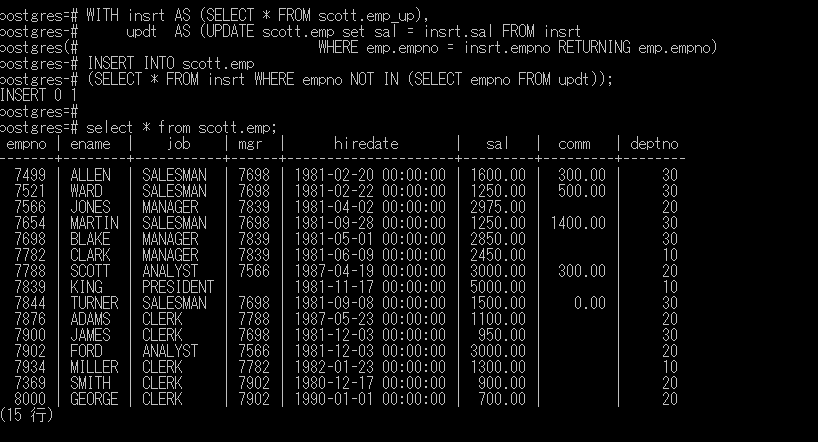
通常テーブルであれば、もちろんUPSERTでもCTEでも結果は一緒ですね。
3-3. データ移行について
データ移行については今回のブログでは詳細な記載は割愛しますが、データ移行もマイグレーションにおいては非常に重要な作業となります。移行時間、キャラクタセットの違いやデータ抽出方法など、移行要件を満たすために様々な検討・設計が必要となります。
データベースの切替時にはデータベースを利用する業務の全面停止が必要にはなりますが、その停止時間を最小限とする要件を持つシステムも多いと思います。その場合は、データの事前移行+切替直前まで常時レプリケーション⇒切替といった方式で業務停止時間を最短とする案もあります。事前移行方法やレプリケーション方式については機会があれば詳しく書こうとは思いますが、検討する事項はたくさんあります。
レプリケーション方式の一例としては、SaaSとして提供されているAWS Database Migration Serviceがあります。こちらのサービスは移行先のデータベースがAWSのPaaSを利用している場合となります。
AWS DMSの詳細はこちらを参照してください。
まとめ
第1回では、データベースマイグレーションの背景や流れと一般的なマイグレーションのポイントとなる点について記載していきました。データベースオブジェクト(スキーマ)、アプリケーション(SQL)について、多くの場合は一定ルールに基づき変更可能であることが分かります。
次回は、一般的に利用されているマイグレーションツールと、実際のアプリケーションにてマイグレーションの評価をおこなった例ついて記載していきたいと思います。