はじめに
みなさんこんにちは。SAIG(Strategic AI Group)の小池です。
前回のNIPS2017 LT報告以来の登場となります。
今回は、2018年6月5日(火)〜6月8日(金)に行われました人工知能学会(JSAI2018)にSAIGで参加して来ましたので、ご報告を致します。フューチャーでは、プラチナスポンサーとしてのブース出展・口頭発表・セッション聴講を行ってまいりました。

場所は鹿児島県城山ホテル鹿児島にて開催されました。鹿児島空港から鹿児島中央駅までバスで1時間くらい、鹿児島中央駅から城山ホテル鹿児島まで30分程かかりました。会場は山の上にあり移動が大変でしたが、景観が良く、高級感溢れるホテルでした。
口頭発表
SAIGの貞光九月がAI応用-産業応用(3)にて、「半教師有りグラフニューラルネットワークを用いたCRUD関係に基づくシステム移行単位の最適化」と題して発表してまいりました。
口頭発表の内容
大規模なシステムが、社会的あるいは工学的観点で旧式化した際、システムの最新化が必要となります。例えば銀行のシステムが銀行の合併により改修が必要となるといった事例が代表的です。旧システムを無計画に改修していては、効率も悪く、むしろ前よりパフォーマンスを悪化することさえあるでしょう。そこで、どのようなサブセットでシステムを移行すべきか、という「移行単位」を人手で設計します。この際用いるのがCRUD表です。CRUD表とは、図1のように、システム内の機能とテーブルの参照関係を表で表したものです。CRUD表を見ることで、例えば1つのテーブルをcreateする機能と、削除する機能は、同じ移行単位とすべき、といった方針が見いだせます。
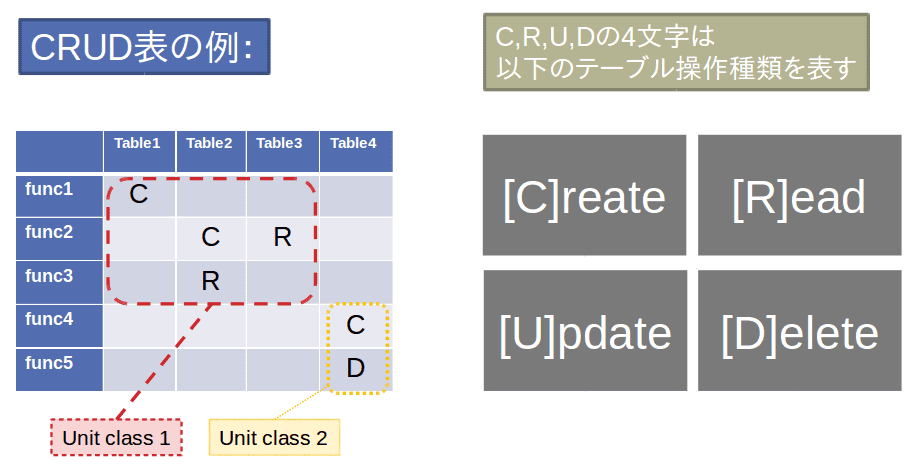 図1 CRUD表の例
図1 CRUD表の例
本研究ではこのCRUD表から自動的に移行単位を推定することを試みています。CRUD表がグラフに対する隣接行列と解釈できることに着目し、半教師あり学習に基づくグラフノードの分類法を用います。具体的にはDiffusion Convolutional Neural Networkを用い、機能とテーブルのファイル配置情報、いわゆるファイルパスを、CRUDグラフと統合して用います。さらにファイルパスの木構造の特性を活かすことができるPoincarē Embeddingsを併用することで、従来法に比べ、人手の移行単位に最も近い結果を得ています(図2)。
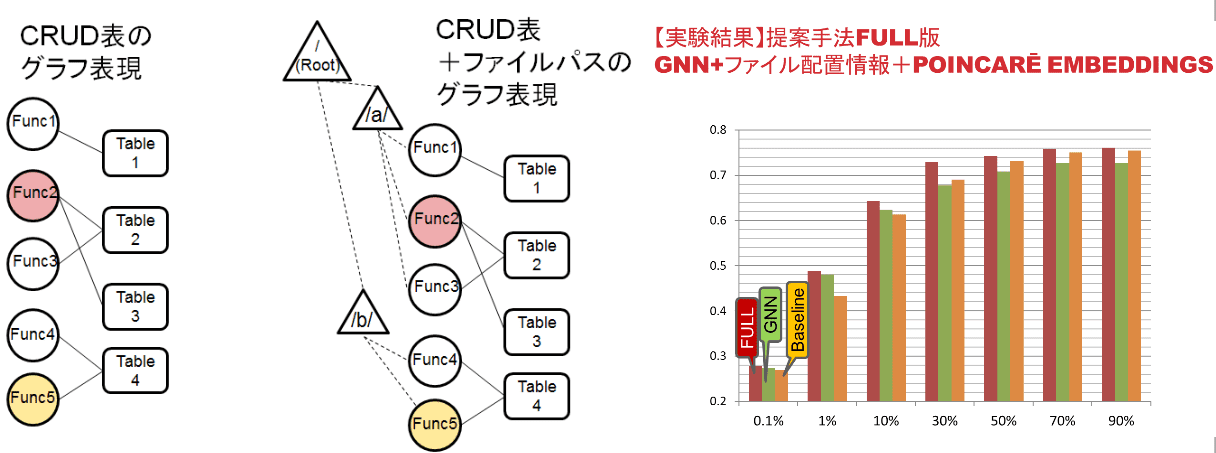
図2 CRUD情報とファイルパスの統合イメージおよびその手法の実験結果
企業ブース
企業ブースでは、FutureにおけるAI案件の実績を展示いたしました。多くの学生さん、企業の方に来ていただき、大変盛り上がりました。Futureオリジナル清涼タブレットを配っていたのですが、3日を通して払底するなど多くの方に来ていただきました。

セッション聴講
口頭発表やインタラクティブセッションに参加してきました。その中でも、面白かったと思うものを紹介したいと思います。(以下の要約には、SAIGメンバーである貞光、藤田、勝村の3名にお手伝いいただきました)
近年言語処理において、word2vecのような分散表現が注目されています。分散表現は文書のクラスタリングや検索タスクにおいて、強力に働きます。一般的なword2vecにおける獲得手法は、3層のニューラルネットを用いて第1層の重み(W in)を学習させて利用します。一方で本研究では、第2層の重み(w out)も共起情報量があることからw in, w out両方を用いるべきだと主張しています。W in W outの両ベクトルの平均をとって単語ベクトルとすることで、分類タスクにおいて従来のw2vよりも精度が上がることを示しています。
実店舗での購買を把握する手法として、アンケートを用いた市場調査や、家計簿アプリのレシートスキャン等の利用が試みられてきましたが、これらは回答の偏りや調査対象者の負担という課題があります。
本研究では、(1)大手スーパーマーケットチェーンT社のID-POSデータ、(2)T社各店舗、および競合と想定される近隣の複数店舗に設定したジオフェンス(※)内への消費者の出入情報をマッチングさせる方法を提案しています。
※地域を特定の距離で区切った仮想の区画のこと。消費者が特定の複数のアプリケーションを利用した際にバックグラウンドで取得される位置情報が一般的であるが、GPSに基づく正確な位置情報ではなく、ジオフェンス内への侵入・退出を記録する方法を採用しています。
ユーザ離脱予測に関する既存研究ではユーザ属性情報や行動データなどの特徴量を機械学習のモデルに読み込ませ、将来の一定期間における離脱を予想するものであり、Random ForestやSVMなど様々な手法が使われています。一方で深層学習を用いたユーザ離脱予測に関する研究は多くありません。本研究で、はユーザの離脱予測モデルに時系列相関を取り込むためにLSTMを採用し、既存手法であるRandom Forestと時系列性を考慮しない中間層が4層のMLPとの比較し、既存手法より提案手法が精度が高いことを示しました。
Deep Learningによって目覚ましい発展を遂げた研究内容の1つに超解像が挙げられます。
超解像に関して様々なモデルが提案される中、人間にとっての見た目を評価するMOStestingにおいて他の超解像手法を凌ぐ性能を発揮しているものが、SRGAN[Leding 16]です。しかしSRGANは元画像のjpgノイズや撮影の際に生じたブレを修復できない問題や撮影対象「らしい」テクスチャが生成されない問題があります。本研究では料理画像を対象にこれらの問題に対して、解きたい問題に応じた適切なデータセットを構築するといった基本的なアイデアに基づき定性的・定量的な実験を実施した。SRGANに対しノイズを加えた低解像度画像の作成やドメイン毎にデータを分割してモデルを作成・比較することで、性能が向上することを確認しています。
任意の特徴を持つ化学分子を設計する際、近年SMILESと呼ばれる文字列表現を元に、VAEを用いる手法が提案されています。(Gomez-Bombarelli 2018) しかしSMILESとVAEを組み合わせた時の欠点として、出力された文字列が分子グラフの要件を満たさないという課題がありました。著者らは独自に、常に原子価を保持するという条件を担保する分子ハイパーグラフ構造(HRG)を定義し、今後VAEを組み合わせることで分子設計が容易になると主張しています。
工業的に有用なタンパク質の耐熱性を向上させることを目的に、タンパク質を構成する数百のアミノ酸の1つを別のアミノ酸(全20種類)に置換する方法がありますが、実際にどのアミノ酸を変化させると効果があるのか予測が難しいといった課題があります。
本研究では、アミノ酸配列全体に関する情報を十分に含む特徴量として、Byte Pair Encoding(BPE) Seq2Seqモデルに、既知の特徴量(実験条件やアミノ酸の性質など)を組み合わせたものを提案し、既存法より高い精度で耐熱性変化を予測できることを示しています。
CADの手順操作ログから、決定木を使ってベテランのスキルを検知するという内容。
JSAIではこのように、ある程度枯れた技術を産業応用していく、という発表が多くありましたが、本研究は研究課題が明確かつ、有益な効果が得られた、ということがとても分かりやすく示されていました。
おわりに
JSAI2018では、多くの収穫があり非常に有益だったと思います。
知識もさることながら、優秀な研究者・エンジニアの方との出会いや企業さんとの出会いもありました。
今後も学会やイベントに参加していきますので、見かけた際には気軽にお声をかけてくださればと思います。
以上小池でした。