Update on tr_part tgt (cost=0.83..115.84 rows=4 width=44) Update on tr_part_p_1809_01 tgt_1 Update on tr_part_p_1809_02 tgt_2 Update on tr_part_p_1809_03 tgt_3 Update on tr_part_p_9912_31 tgt_4 -> Nested Loop (cost=0.83..28.01 rows=1 width=38) Join Filter: ((a.related_key = b.key) AND (a.target_date = b.part_date)) -> Nested Loop (cost=0.42..26.34 rows=1 width=32) -> Seq Scan on wk_input a (cost=0.00..1.03 rows=3 width=16) -> Index Scan using pk_tr_part_p_1809_01 on tr_part_p_1809_01 tgt_1 (cost=0.42..8.44 rows=1 width=16) Index Cond: ((part_date = a.target_date) AND (key = a.related_key)) -> Append (cost=0.42..1.61 rows=4 width=26) -> Index Scan using pk_tr_part_p_1809_01 on tr_part_p_1809_01 b (cost=0.42..0.48 rows=1 width=26) Index Cond: ((part_date = tgt_1.part_date) AND (key = tgt_1.key)) -> Index Scan using pk_tr_part_p_1809_02 on tr_part_p_1809_02 b_1 (cost=0.42..0.48 rows=1 width=26) Index Cond: ((part_date = tgt_1.part_date) AND (key = tgt_1.key)) -> Index Scan using pk_tr_part_p_1809_03 on tr_part_p_1809_03 b_2 (cost=0.42..0.48 rows=1 width=26) Index Cond: ((part_date = tgt_1.part_date) AND (key = tgt_1.key)) -> Index Scan using pk_tr_part_p_9912_31 on tr_part_p_9912_31 b_3 (cost=0.15..0.17 rows=1 width=78) Index Cond: ((part_date = tgt_1.part_date) AND (key = tgt_1.key)) -> Nested Loop (cost=0.83..28.01 rows=1 width=38) Join Filter: ((a.related_key = b.key) AND (a.target_date = b.part_date)) -> Nested Loop (cost=0.42..26.34 rows=1 width=32) -> Seq Scan on wk_input a (cost=0.00..1.03 rows=3 width=16) -> Index Scan using pk_tr_part_p_1809_02 on tr_part_p_1809_02 tgt_2 (cost=0.42..8.44 rows=1 width=16) Index Cond: ((part_date = a.target_date) AND (key = a.related_key)) -> Append (cost=0.42..1.61 rows=4 width=26) -> Index Scan using pk_tr_part_p_1809_01 on tr_part_p_1809_01 b (cost=0.42..0.48 rows=1 width=26) Index Cond: ((part_date = tgt_2.part_date) AND (key = tgt_2.key)) -> Index Scan using pk_tr_part_p_1809_02 on tr_part_p_1809_02 b_1 (cost=0.42..0.48 rows=1 width=26) Index Cond: ((part_date = tgt_2.part_date) AND (key = tgt_2.key)) -> Index Scan using pk_tr_part_p_1809_03 on tr_part_p_1809_03 b_2 (cost=0.42..0.48 rows=1 width=26) Index Cond: ((part_date = tgt_2.part_date) AND (key = tgt_2.key)) -> Index Scan using pk_tr_part_p_9912_31 on tr_part_p_9912_31 b_3 (cost=0.15..0.17 rows=1 width=78) Index Cond: ((part_date = tgt_2.part_date) AND (key = tgt_2.key)) -> Nested Loop (cost=0.83..28.01 rows=1 width=38) Join Filter: ((a.related_key = b.key) AND (a.target_date = b.part_date)) -> Nested Loop (cost=0.42..26.34 rows=1 width=32) -> Seq Scan on wk_input a (cost=0.00..1.03 rows=3 width=16) -> Index Scan using pk_tr_part_p_1809_03 on tr_part_p_1809_03 tgt_3 (cost=0.42..8.44 rows=1 width=16) Index Cond: ((part_date = a.target_date) AND (key = a.related_key)) -> Append (cost=0.42..1.61 rows=4 width=26) -> Index Scan using pk_tr_part_p_1809_01 on tr_part_p_1809_01 b (cost=0.42..0.48 rows=1 width=26) Index Cond: ((part_date = tgt_3.part_date) AND (key = tgt_3.key)) -> Index Scan using pk_tr_part_p_1809_02 on tr_part_p_1809_02 b_1 (cost=0.42..0.48 rows=1 width=26) Index Cond: ((part_date = tgt_3.part_date) AND (key = tgt_3.key)) -> Index Scan using pk_tr_part_p_1809_03 on tr_part_p_1809_03 b_2 (cost=0.42..0.48 rows=1 width=26) Index Cond: ((part_date = tgt_3.part_date) AND (key = tgt_3.key)) -> Index Scan using pk_tr_part_p_9912_31 on tr_part_p_9912_31 b_3 (cost=0.15..0.17 rows=1 width=78) Index Cond: ((part_date = tgt_3.part_date) AND (key = tgt_3.key)) -> Nested Loop (cost=0.57..31.81 rows=1 width=64) Join Filter: ((a.related_key = b.key) AND (a.target_date = b.part_date)) -> Nested Loop (cost=0.15..17.55 rows=1 width=58) -> Seq Scan on wk_input a (cost=0.00..1.03 rows=3 width=16) -> Index Scan using pk_tr_part_p_9912_31 on tr_part_p_9912_31 tgt_4 (cost=0.15..5.50 rows=1 width=42) Index Cond: ((part_date = a.target_date) AND (key = a.related_key)) -> Append (cost=0.42..14.20 rows=4 width=26) -> Index Scan using pk_tr_part_p_1809_01 on tr_part_p_1809_01 b (cost=0.42..4.65 rows=1 width=26) Index Cond: ((part_date = tgt_4.part_date) AND (key = tgt_4.key)) -> Index Scan using pk_tr_part_p_1809_02 on tr_part_p_1809_02 b_1 (cost=0.42..4.66 rows=1 width=26) Index Cond: ((part_date = tgt_4.part_date) AND (key = tgt_4.key)) -> Index Scan using pk_tr_part_p_1809_03 on tr_part_p_1809_03 b_2 (cost=0.42..4.66 rows=1 width=26) Index Cond: ((part_date = tgt_4.part_date) AND (key = tgt_4.key)) -> Index Scan using pk_tr_part_p_9912_31 on tr_part_p_9912_31 b_3 (cost=0.15..0.22 rows=1 width=78) Index Cond: ((part_date = tgt_4.part_date) AND (key = tgt_4.key))
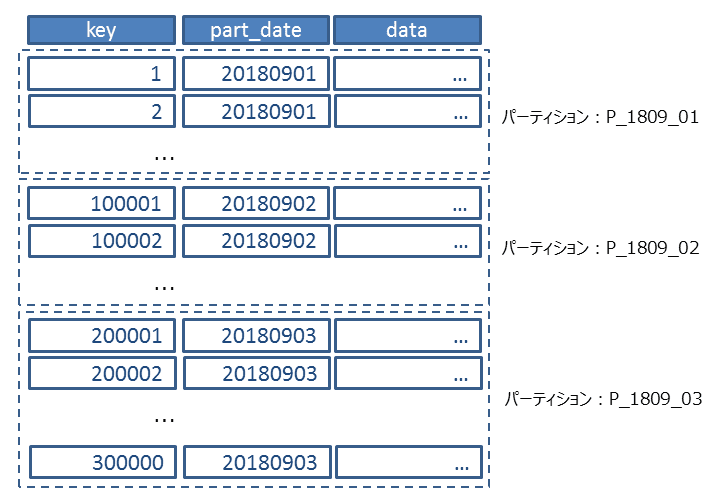
--drop table tr_part; CREATE TABLE tr_part( part_date date , key numeric , data numeric ) partitionbyrange(part_date); --パーティション作成 create table tr_part_p_1809_01 partitionof tr_part forvaluesfrom ( MINVALUE ) to ('20180902'); alter table tr_part_p_1809_01 add constraint pk_tr_part_p_1809_01 primary key(ymd,key);
create table tr_part_p_1809_02 partitionof tr_part forvaluesfrom ( '20180902' ) to ('20180903'); alter table tr_part_p_1809_02 add constraint pk_tr_part_p_1809_02 primary key(ymd,key);
create table tr_part_p_1809_03 partitionof tr_part forvaluesfrom ( '20180903' ) to ('20180904'); alter table tr_part_p_1809_03 add constraint pk_tr_part_p_1809_03 primary key(ymd,key);
create table tr_part_p_9912_31 partitionof tr_part forvaluesfrom ( '20180904' ) to ('99991231'); alter table tr_part_p_9912_31 add constraint pk_tr_part_p_9912_31 primary key(ymd,key);
insert into tr_part select'20180901',generate_series,round(generate_series * random() *100) from generate_series(1,100000); insert into tr_part select'20180902',generate_series,round(generate_series * random() *100) from generate_series(100001,200000); insert into tr_part select'20180903',generate_series,round(generate_series * random() *100) from generate_series(200001,300000); analyze tr_part;
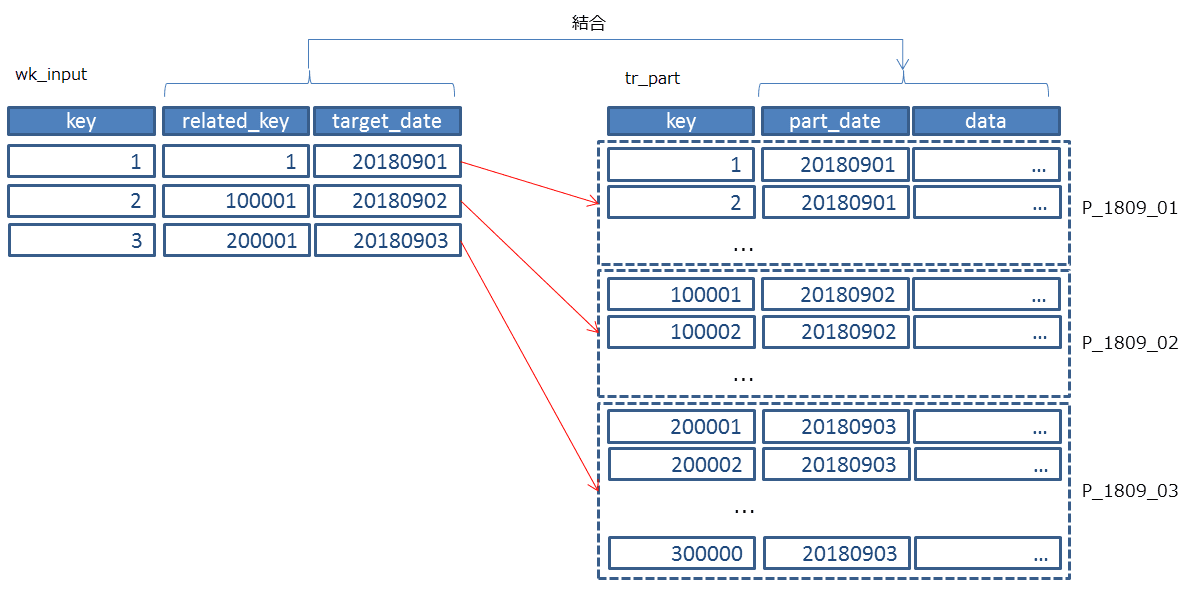
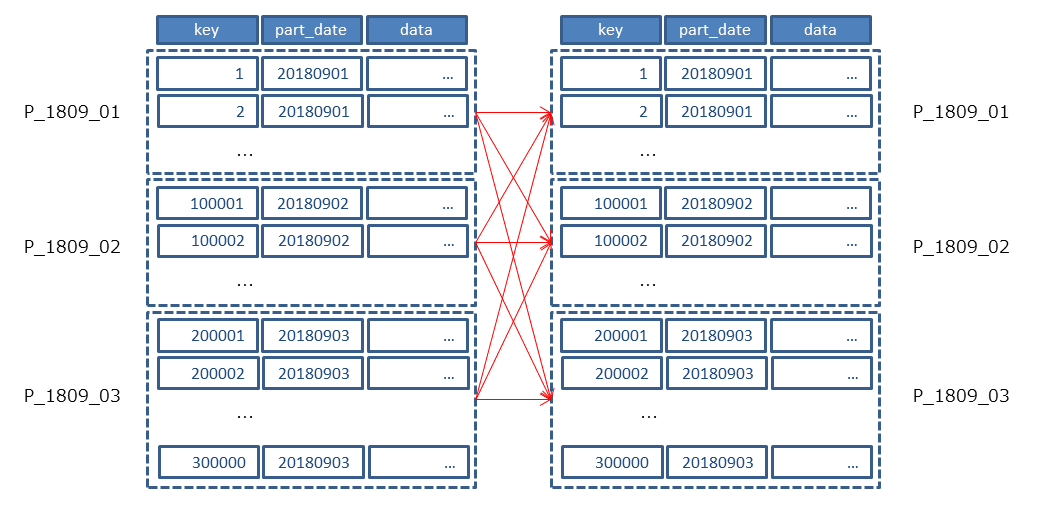
update tr_part tgt set data = b.data *0.8 from wk_input a , tr_part b where1=1 and a.related_key = b.key and a.target_date = b.part_date and b.key = tgt.key and b.part_date = tgt.part_date ;
冒頭の実行計画の先頭部分を抜き出して以下に貼り付けました。
Update on tr_part tgt (cost=0.83..115.84 rows=4 width=44) Update on tr_part_p_1809_01 tgt_1 Update on tr_part_p_1809_02 tgt_2 Update on tr_part_p_1809_03 tgt_3 Update on tr_part_p_9912_31 tgt_4 -> Nested Loop (cost=0.83..28.01 rows=1 width=38) Join Filter: ((a.related_key = b.key) AND (a.target_date = b.part_date)) -> Nested Loop (cost=0.42..26.34 rows=1 width=32) -> Seq Scan on wk_input a (cost=0.00..1.03 rows=3 width=16) -> Index Scan using pk_tr_part_p_1809_01 on tr_part_p_1809_01★ tgt_1 (cost=0.42..8.44 rows=1 width=16) Index Cond: ((part_date = a.target_date) AND (key = a.related_key)) -> Append (cost=0.42..1.61 rows=4 width=26) -> Index Scan using pk_tr_part_p_1809_01 on tr_part_p_1809_01● b (cost=0.42..0.48 rows=1 width=26) Index Cond: ((part_date = tgt_1.part_date) AND (key = tgt_1.key)) -> Index Scan using pk_tr_part_p_1809_02 on tr_part_p_1809_02● b_1 (cost=0.42..0.48 rows=1 width=26) Index Cond: ((part_date = tgt_1.part_date) AND (key = tgt_1.key)) -> Index Scan using pk_tr_part_p_1809_03 on tr_part_p_1809_03● b_2 (cost=0.42..0.48 rows=1 width=26) Index Cond: ((part_date = tgt_1.part_date) AND (key = tgt_1.key)) -> Index Scan using pk_tr_part_p_9912_31 on tr_part_p_9912_31● b_3 (cost=0.15..0.17 rows=1 width=78) Index Cond: ((part_date = tgt_1.part_date) AND (key = tgt_1.key)) ...省略
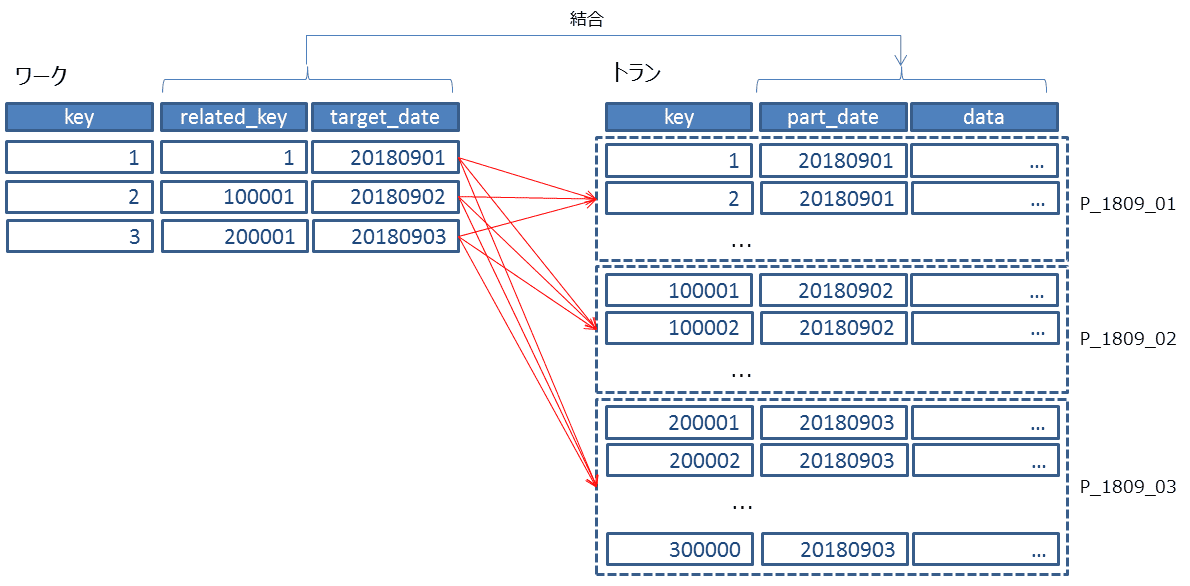
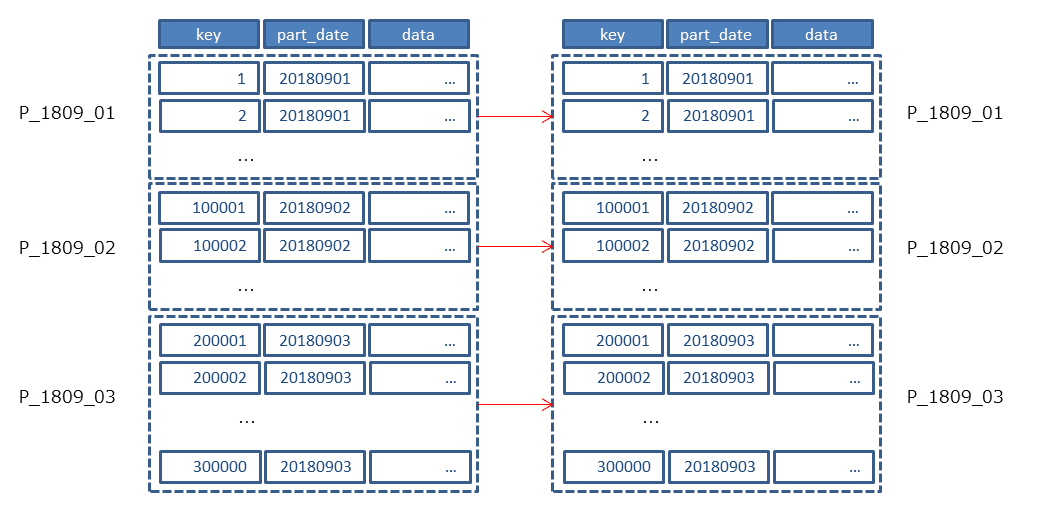
PostgreSQLのこのような動作に起因して性能劣化が見られる場合は、ユーザからアクセスすべきパーティションを教えてあげる必要があります。 つまり、この例ではアクセス対象のパーティションはwk_inputに保持されているtarget_dateの値で決まっています。 そのため、select distinct target_date from wk_iputのように一度target_dateの一覧を抽出します。 そのうえで、以下のようにパーティションキーのpart_dateの値を以下のクエリの/*あらかじめ取得した値*/のところで指定してループ実行します。
update tr_part tgt set data = b.data *0.8 from wk_input a , tr_part b where1=1 and a.related_key = b.key and a.target_date = b.part_date and b.key = tgt.key and b.part_date = tgt.part_date and b.part_date =/*あらかじめ取得した値*/ ;