こんにちは、フューチャーアーキテクト2017年4月入社、TIG(Technology Innovation Group)所属の竹林です。
大学では主にIoTの研究をしており、趣味で作ったArduinoベースのIoTラジコンカーを入社前にフューチャーのLT大会で発表したりしていました。
研修終了後のOJTではフューチャーの社内インフラ構築・運用に関する業務を担当・経験し、現在はQA(Quality Assurance)チームとして、フューチャーにおける各プロジェクト成果物の品質保証全般に関わるツールの改善業務やサポート業務などを主に行っております。
概要
作ったもの
- AIコンシェルジュのあいちゃんがパワーアップして帰ってきました!
- 新たに「チケットレコメンド業務」をこなしてもらえるようになりました
- 何が出来るのか
- 社内ヘルプデスクで使われているチケット管理OSS「Redmine」に起票された問い合わせチケットの内容と過去の同様事例チケットを自動検索します
- 検索結果として得られた類似度の高いチケット(以下、類似チケット)を、関連チケットへの紐付けによりユーザに提供します
デモ
手順1. 社内問い合わせ窓口のRedmineにチケットを起票
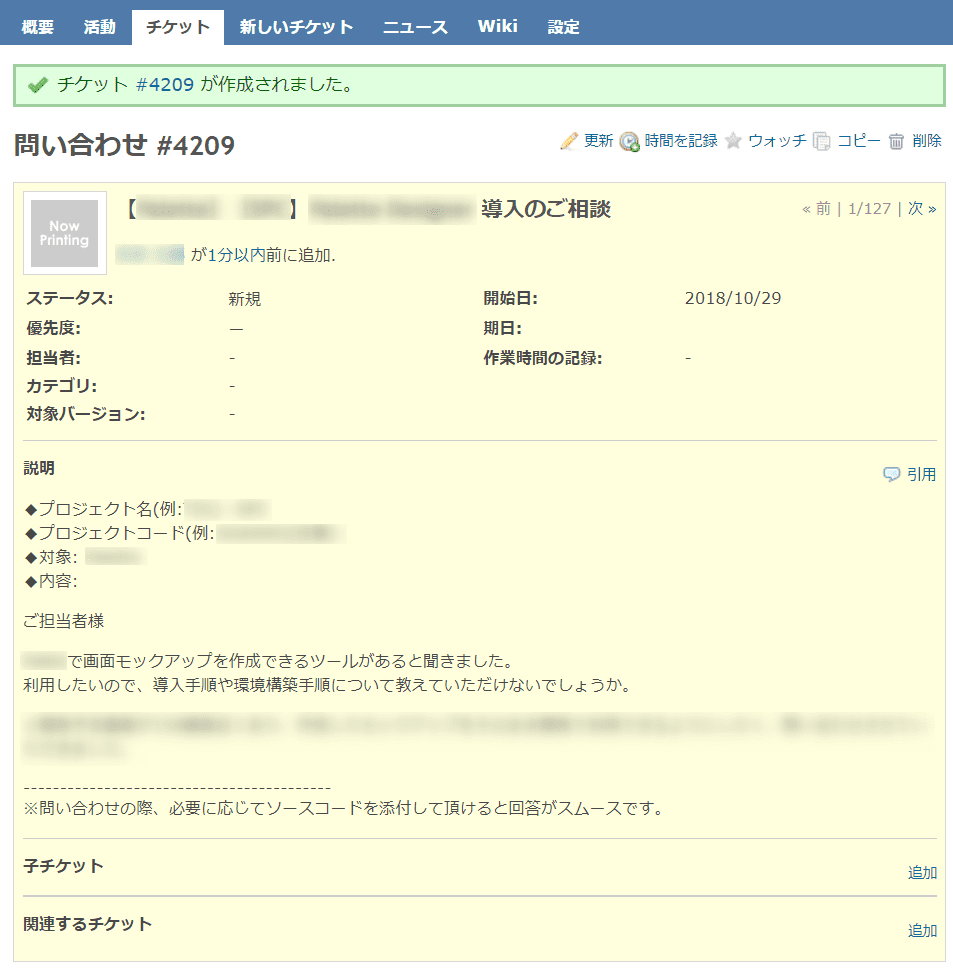
手順2. 起票してから10~20秒後、画面をリロードする
- 類似チケットが自動で紐付けられます!
- 紐付けられたチケットの順番は類似度の高い順でソート済み
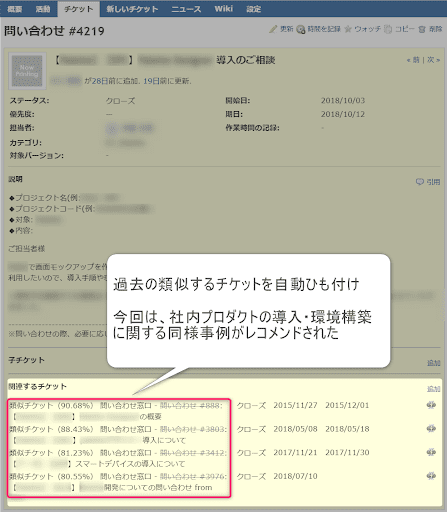
メリットはなにか
本システムを使うことにより、起票者(質問者)と回答者の双方が過去の回答チケットを検索する手間を省略できます。
- チケットクローズまでの回答コストを削減
- 削減により生まれた時間をメインタスクに割り当て、生産性を向上できる
背景
フューチャーでは社内問い合わせのみならず、各プロジェクトの管理としてRedmineを活用していますが、改善要望の声が上がっていました。
- 「過去チケットの検索に時間が掛かるので、何とかしてほしい」
- 「障害発生時に、過去の同様の事例を参照できる仕組みがほしい」 などなど…
フューチャーでは、RedmineでのAI活用実績として既に、萩原さんによるチケットカテゴリ振り分けシステムがあります。
今回、AI活用の次なるステップとして「全文検索アルゴリズム」技術に注目し、これがチケット検索の改善に活かせるのではないかと考え開発に踏み切りました。
システムについて
使用したソフトウェア・ライブラリ
- チケットレコメンドのアルゴリズムはPythonで実装しました。
- Redmineチケット分類・スコア化
- Python (3.5.2)
mecab-python3(0.7)scikit-learn(0.19.0)gensim(3.1.0)- Flask (0.12.2)
- Elasticsearch (5.6.10)
- Python (3.5.2)
- ジョブ管理
- Jenkins (2.60.3)
- Redmineチケット分類・スコア化
システム構成図
システムは大きく分けて、既存システムの「Redmine」グループと、今回新規構築する「チケットレコメンド」の2つのグループから構成されます。(下図点線枠部分)
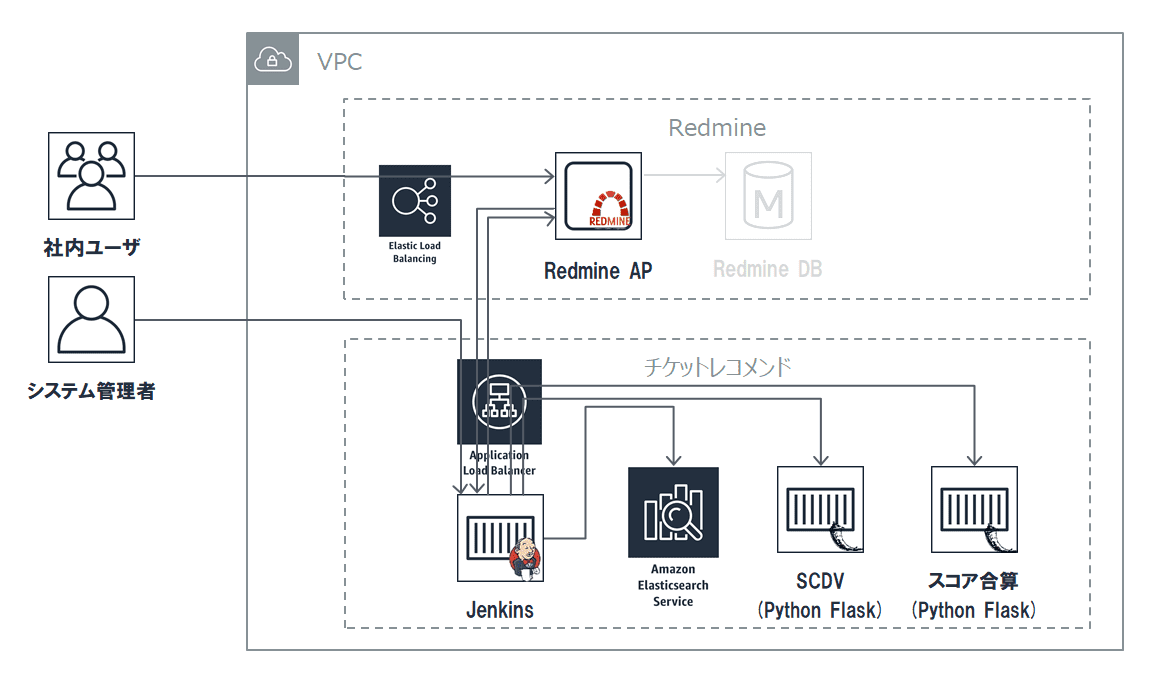
「Redmine」グループでは、既に構築済みのRedmine APに向けて新たにRedmine拡張プラグインを開発・実装を実施しました。
拡張プラグインに実装した機能は以下の2つです。
- 関連チケットへ「類似チケット」の表示・追加機能
- Redmine Plugin Hookを用いたチケット起票時でのJenkinsジョブキック&類似チケットの自動付与機能
チケットレコメンドグループ内のサーバは、ES(Elasticsearch)を除きすべてECS(ElasticContainerService)として新規構築しました。
ESは、AWSマネージドのElasticsearchServiceを使用し、保守・運用コストを抑えることにしました。
- 補足: ECSの起動タイプについて
- ECSの起動タイプは「Fargate」と「EC2」の2種類から選べるが、今回はEC2を利用
- Dockerイメージは社内のプライベートリポジトリで管理する必要があり、その場合だとEC2しか選択できない
- Fargate起動タイプは、AWS ECR又はDocker Hubリポジトリのみをサポートのため利用不可のため。
- 参照: https://docs.aws.amazon.com/ja_jp/AmazonECS/latest/developerguide/task_definition_parameters.html#standard_container_definition_params
チケットレコメンドグループは、更に細かく分けると「ジョブ管理」「レコメンドAPIサーバ群」の2つから構成されます(下図オレンジ色枠線部分)
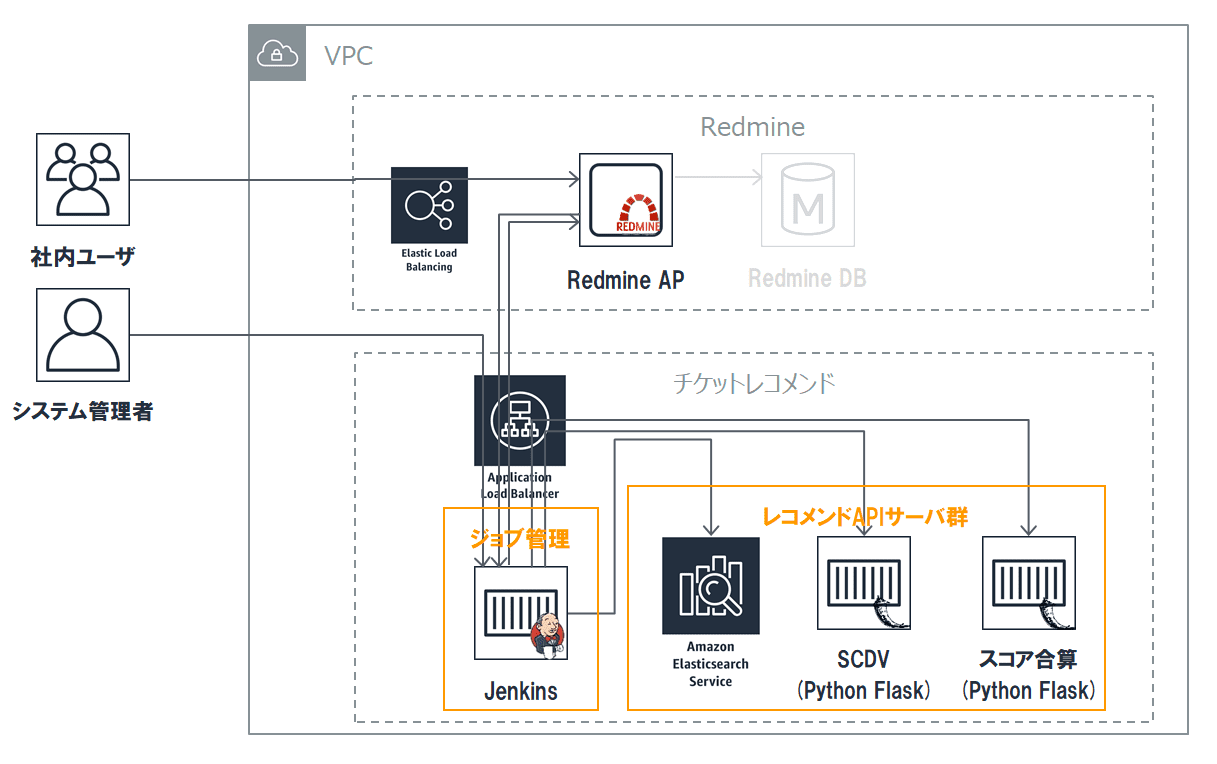
ジョブ管理の仕組みとして、Jenkinsを使用しました。Jenkinsでは、RedmineからWebhookとして飛んでくるリアルタイムジョブ、日次実行ジョブなどを管理します。
レコメンドAPIサーバ群では、入力として検索対象チケット本文を受け取り、出力として類似チケットの番号とスコアのセットを返します。
Redmine,ECS→ECS間のHTTPS/HTTP通信を実現するため、ALB(Application Load Balancer)において以下の振り分けルール設定を行っています。
- パスパターンが
/jenkins/*→ ECSのJenkinsサーバにリクエスト転送 - パスパターンが
/flask-scdv/*→ ECSのSCDVサーバにリクエスト転送 - パスパターンが
/flask-score/*→ ECSのスコア合算サーバにリクエスト転送
検索アルゴリズムについて
※本セクションは、SAIG小池さんにより執筆していただきました。
検索アルゴリズムは、「類似文書検索」と「キーワード検索」のハイブリッド手法を用いることにより、より精度を向上させる試みを行いました。
類似文書検索は、機械学習のトップカンファレンス 1 で発表されたSCDV(sparse Composite Document Vector)と呼ばれるEmbedding手法を用い、キーワード検索は現在有力とされているBM25を用いました。
本システムのもっとも肝な部分は、SCDV(文書検索)×BM25(キーワード検索)のハイブリッドアルゴリズムを実装した点にあります。詳細は下記で説明します。
SCDVについて
SCDVの概要
SCDV(Sparse Composite Document Vectors)とは、簡単にいってしまえば文書(本ブログではチケット)をベクトルに変換する技術です。
文書をベクトル化することによって、各文書の類似度を測ることができます。また、ベクトルに変換することにより、分類問題やクラスタリングなどさまざまなタスクに応用することができます。
文書のベクトル化手法は多く提案されていますが、個人的に分類タスクにてかなり精度が良い印象でした。
SCDVのアルゴリズムについてはここでは詳しくは述べませんが、論文は非常にわかりやすいので、参考にしてもらえればと思います。
SCDVの選定理由
みなさん今流行りのword2vecはご存知でしょうか。
word2vevは現在自然言語処理分野において最も注目されている技術の1つで、言葉通り単語をベクトルに変換する技術のことです。
word2vecの良い点は、教師なし学習で類似単語を獲得できる点にあります。
つまり、「PC」と「コンピューター」といった単語ベクトルの類似度は大きくなり、「PC」と「鉛筆」といった単語ベクトルの類似度は小さくなります。
w2vでは、表現が揺れていても(例、「PC」と「コンピューター」)、似たような単語ベクトルの獲得が可能です。
さて、前置きが長くなりましたが、SCDVを用いるメリットを説明します。
SCDVはword2vecを元に文書ベクトルを獲得します。したがって、上記のword2vecの表現の揺れが吸収でき、なおかつ文書同士の類似度を測ることができるのがSCDVのメリットと言えるでしょう。
選定理由としては、このような単語の揺れを吸収できる点・個人的に精度が良い印象だったという2点から、SCDVを選定しました。
BM25について
BM25の概要
BM25 2は、キーワード検索アルゴリズムの1種です。
キーワード検索といっても、単純にキーワードで引っかかった文書を提示するようなものではなく、各キーワードに重みを付けて、**キーワードと文書のマッチ度をスコア化できます。
BM25は、キーワード検索においてかなりの威力を発揮しています。
今回はElastic Search(ES)にBM25が実装されていたので、ESを使えば簡単に利用できます。
BM25の選定理由
キーワード検索のアルゴリズムは多くあります。その中で、BM25をなぜ選んだかというと、実験の結果BM25が最も検索精度がよかったのが理由です。多くのキーワード検索アルゴリズムを試し、ハイパーパラメーターがあるものはグリッドサーチ的なことを行った結果、BM25が最も高精度でした。
SCDV×BM25のハイブリッド
さて、チケット検索の具体的なアルゴリズムについて話していきたいと思います。
SCDVを用いて全チケットをベクトル化します。クエリーとなるチケットをq、任意のチケットをpとおくと、SCDVによるチケットp,q間の類似度はSCDVscore(p,q)で表すことができます。
BM25ではチケットqの文書を形態素解析(単語に分解)し、ストップワーズの除去(「て」「に」「を」「は」等多く頻出するが意味のない単語)を行ったあとに残ったWordをキーワードとして突っ込みます。
そうすると、チケットp,qの類似度としてBM25score(q,p)が算出できます。
SCDVscore(q,p)は、単純にコサイン類似度としました。
この2つのスコアに対して正規化を行い、重みwをかけ、線形和をとり最終的なスコアとして算出します。
$$Score(q,p) = BM25score(p,q) + w * SCDVscore(p,q)$$
ここでのwは、どちらの重みを重視するかといったパラメーターで、教師あり学習を用いて決定します。
つまり、あらかじめ検索チケットと見つかってほしいチケットのデータセットを用意しておき、それに従って最適なwを見つけることをしています。今回は損失関数を定義するまでもないので、wの最適化にはバイナリーサーチを用いて、ある程度最適なwの更新にとどめています。
上記式は、BM25とSCDVの「おいしいところ取り」をしたい意図があります。
BM25とSCDVでは、検索結果に見つかってほしいチケットに差が生じました。
上記式では、適切な重みwを選ぶことにより、同じチケットでもSCDVでは見つかっているのに、BM25では見つけられないチケットが存在するような場合も検索できるようになりました。まさに「おいしいところ取り」です😁
本アルゴリズムでのチケット検索実験の結果、最もよかったBM25の最高精度を8%上回る結果となりました。
システムの解説
システムの流れについて
ここからは、システムの処理の流れに沿って、本システムの解説を行います。
まず、本システムの処理フローについて説明します。
- (夜間処理)RedmineチケットをES(Elasticsearch)に格納する
- (夜間処理)SCDVモデルを最新化する
- (日中処理)Redmine拡張プラグインが、チケット起票タイミングでJenkinsをキック
- (日中処理)SCDVモデル・ESのスコアをマージし、類似チケット候補のフィルターを実行
- (日中処理)類似チケットセットをRedmine関連チケットに紐付ける
処理フロー1~5を図で示すと以下のようになります。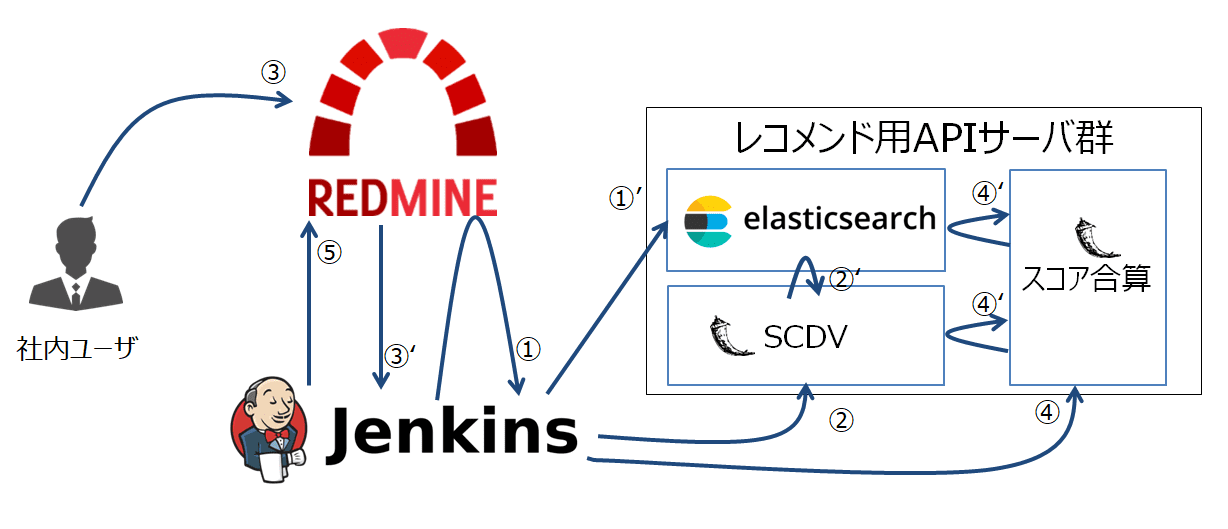
以下、個々のフローの解説になります。
1. (夜間処理)RedmineチケットをES(Elasticsearch)に格納する
まずは、類似チケットを検索するためのインデックスやモデルの最新化処理について説明します。
平日夜間(3:00)に、Jenkinsの定期実行機能をトリガとしてESインデックス内ドキュメント(※)の更新処理を実施するところからスタートします。
※インデックス: RDBにおける「テーブル」に相当。今回は、RedmineプロジェクトのIdentifier(識別子,RedmineサーバURLの/projects/XXXXのXXXX部分に相当)をインデックス名として使用
※ドキュメント: RDBにおける「レコード」に相当
まずはRedmine Issues APIより対象Redmineプロジェクトの全量チケットを取得します(下図(1))。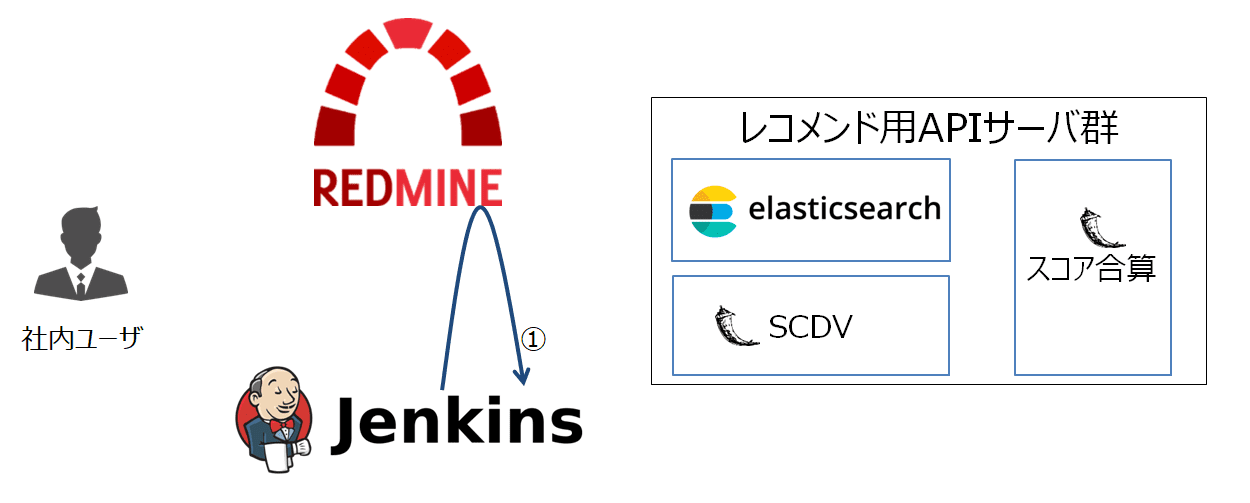
ポイントとして、Issues APIでは一度に取得可能なチケット数は100までとなっています。
ですので、「総チケット数/100回分のリクエストを送信し、レスポンスのJSONデータをマージし保存する」ための実装をする必要があります。
続いて、取得できたチケット全量をESに送信し、ドキュメントとして格納します(下図(1)’)。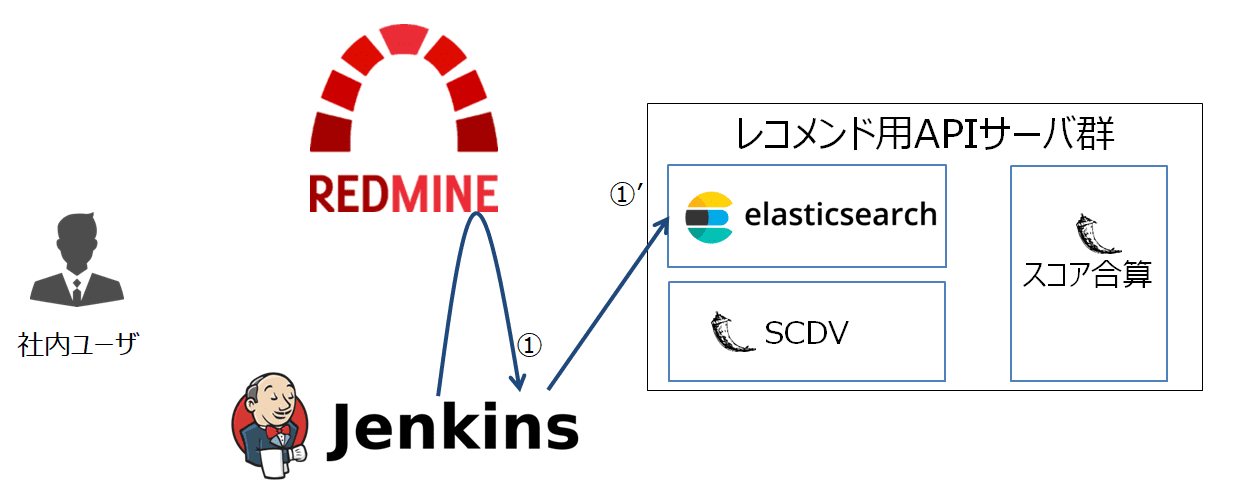
先程得たJSON形式のチケットデータを、Elasticsearch Bulk APIのフォーマットへと変換後、バルクインサートを実行します。
変換前のJSONフォーマットと変換後のバルクインサート用データバイナリのイメージは以下のとおりです。
{ |
{ "index" : {"_id": "1" } } |
上記のバルクインサート用データへ変換したら、まずは既存のESドキュメントを一度消去します。
curl -X POST "${ELASTICSEARCH_URL}/${REDMINE_PROJECT_IDENTIFIER}/issues/_delete_by_query" |
続いて、以下のようにESに向けてバルクインサートを実行します。
curl -X POST "${ELASTICSEARCH_URL}/${REDMINE_PROJECT_IDENTIFIER}/issues/_bulk" --data-binary @ target/${REDMINE_PROJECT_IDENTIFIER}.dat |
2. (夜間処理)SCDVモデルを最新化する
続いて、SCDVモデルの更新を行います。(下図(2))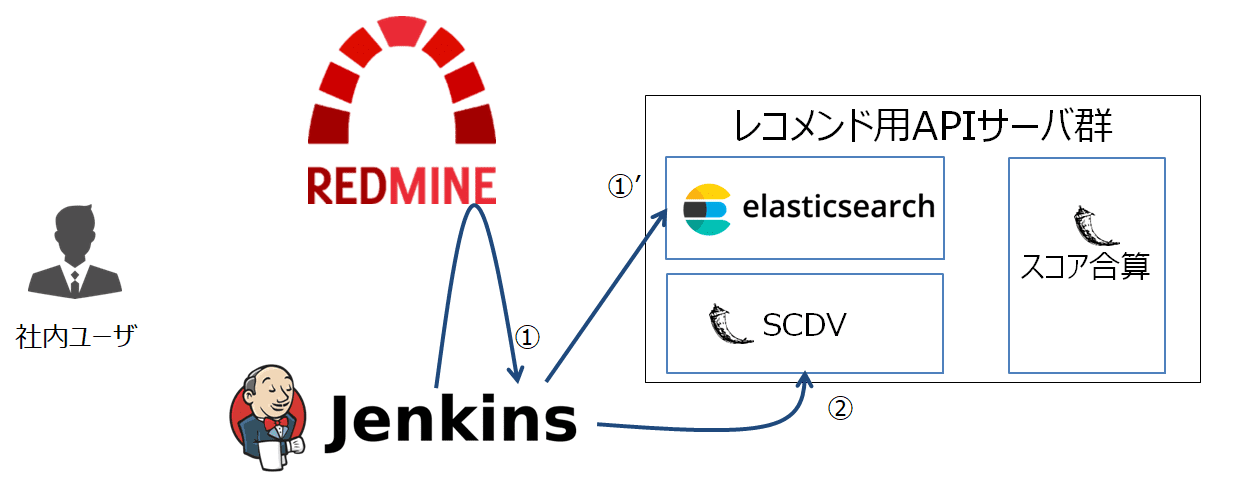
SCDVサーバはFlaskによるAPIサーバとして稼働しており、下記のURLにPOSTリクエストを送信することで、SCDVモデルの更新が可能となる仕組みです。
- リクエストURL:
http://[SCDVサーバのアドレス]/flask-scdv/v1/model/{redmine_project_identifier}
SCDVサーバがリクエストを受信すると、ESからチケット取得・モデルの最新化を実行します。(下図(2)’)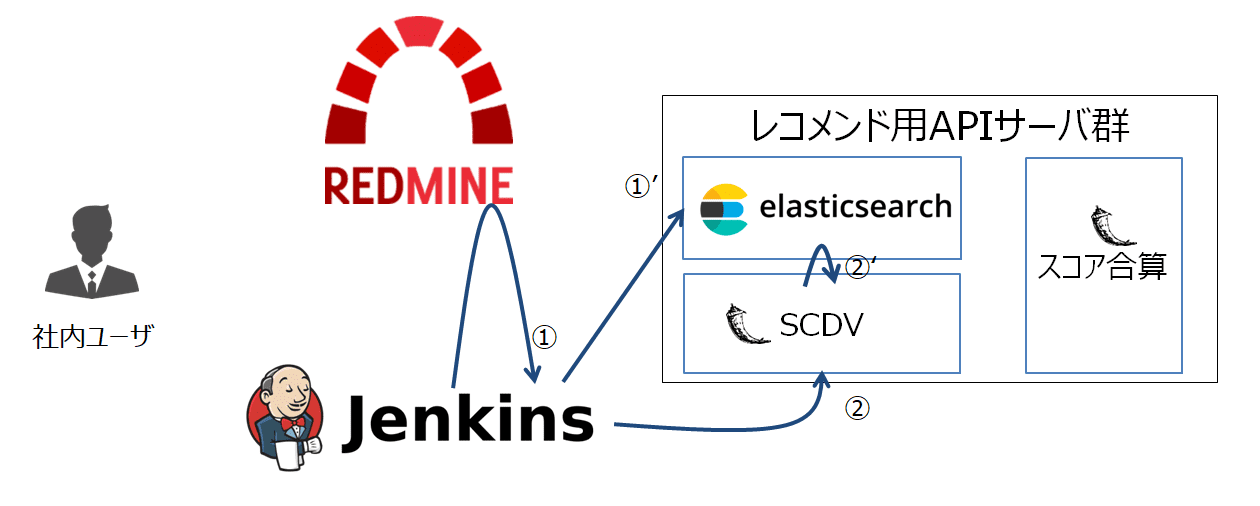
SCDVはPythonを用いて実装していますが、こちらのソースコードの解説はボリュームが多めとなるため今回の記事では割愛とさせていただきます。
これで、夜間処理としての各種モデル最新化のための処理が完了しました。
3. (日中処理)Redmine拡張プラグインが、チケット起票タイミングでJenkinsをキック
ここからは、ユーザが起票したチケットに対し類似チケットの付与をするまでの処理の解説となります。
まず、ユーザが問い合わせチケットを起票したタイミングでJenkinsのジョブを自動実行する仕組みを見てみましょう。
本レコメンドシステム用に実装したRedmine拡張プラグインにより、ユーザのチケット起票のタイミング(下図(3))でJenkinsへのキックを可能とします(下図(3)’)。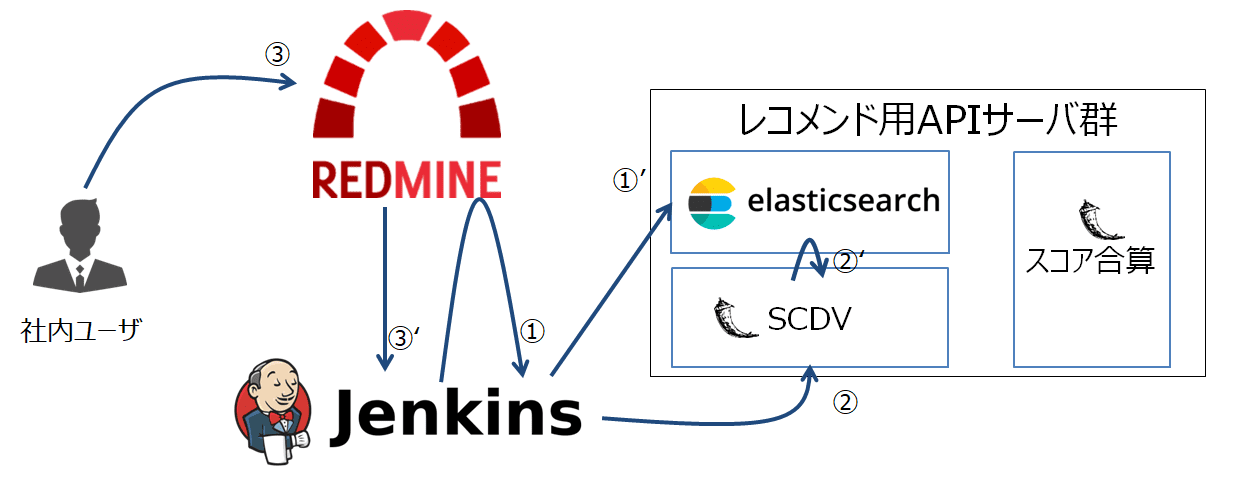
こちらの仕組みの詳細は、過去の萩原さんの記事を併せて参照下さい。
4. (日中処理)SCDVモデル・Elasticsearchのスコアをマージし、類似チケット候補のフィルターを実行
続いて、Redmineよりチケット起票の通知を受け取ったJenkinsがスコア合算サーバに向けてリクエストを送信します。(下図(4))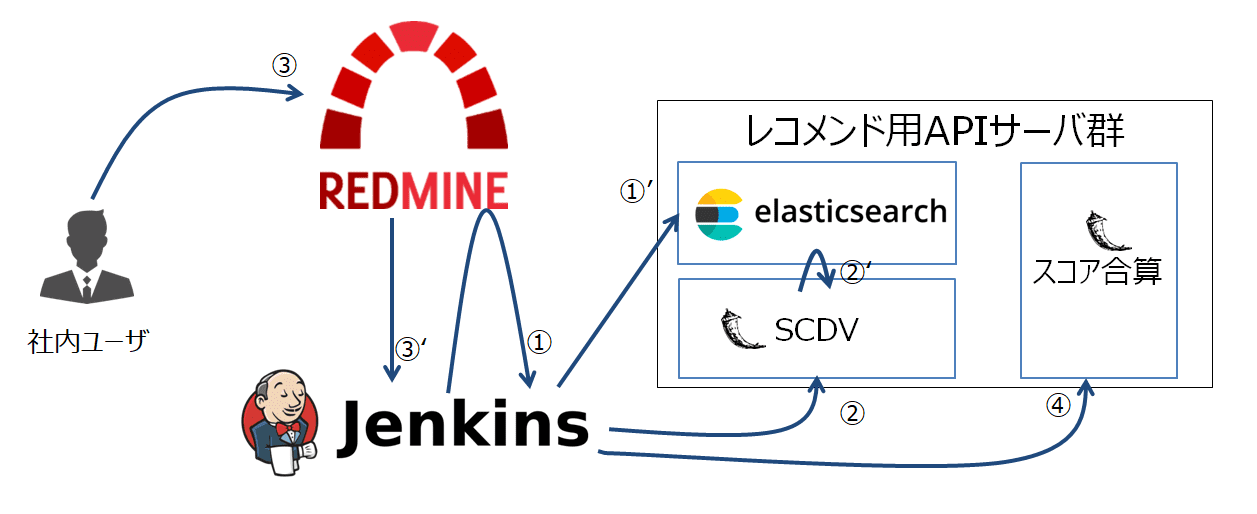
スコア合算サーバもSCDVサーバと同様、FlaskによるAPIサーバとして稼働しています。以下のようなPOSTリクエストを送信することで、レンスポンスとしてレコメンドチケットセットを得ることが出来ます。
- リクエストURL:
http://[スコア合算サーバのアドレス]/flask-score/v1/recommended_issue/{redmine_project_identifier}/{issue_id} - リクエストボディ: 下記JSON参照
{ |
{ |
スコア合算サーバでは、SCDV及びESより得たチケットセット・スコアを合算し(下図(4)’)、合算結果をレスポンスとして返却します。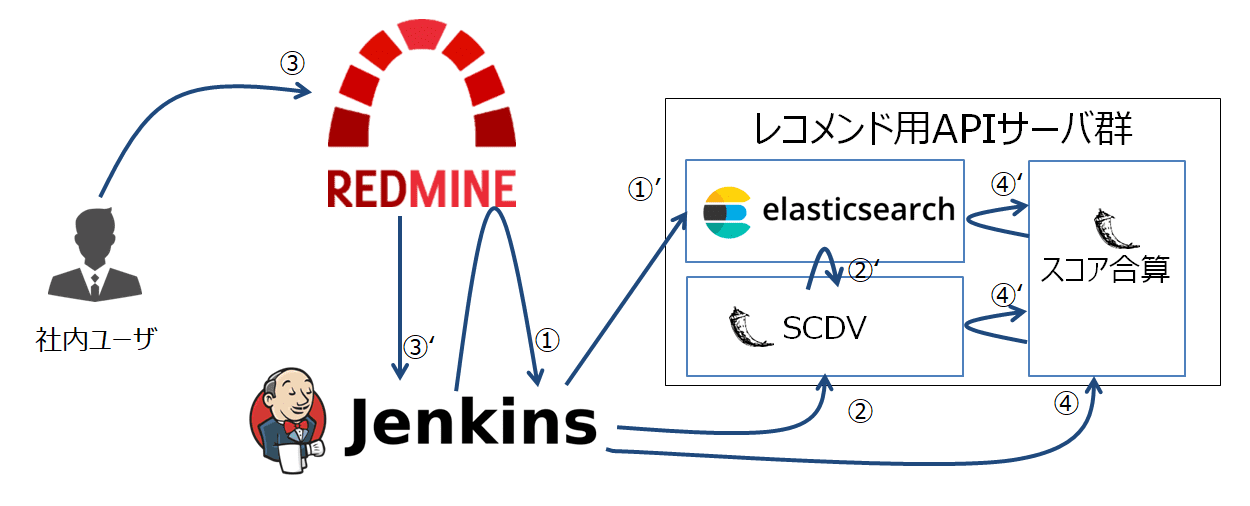
SCDVとESのスコアのマージ方法ですが、片方のスコアを正規化した上で、お互いのスコアを合算させるという方式を取りました。
まずは、SCDVとESのスコアの仕様について比較してみましょう。
- SCDV
- 最小値は0、最大値は1
- スコアの例: 0.9198
- ES(Elasticsearch)
- 最小値は0、最大値は不定
- スコアの例: 613.9819
ESの最大値が不定となっていることが分かります。このため、ここではES側のスコアを正規化した上でSCDVのスコアと合算させるようにしました。
具体的には、ESスコアを1~0の範囲となるようESスコアの最大値ESmaxと重み値wを使って正規化をした上で、1~0の値の範囲を取るSCDVのスコアとマージし、更にスコア順で再ソートを実行します(下図参照)。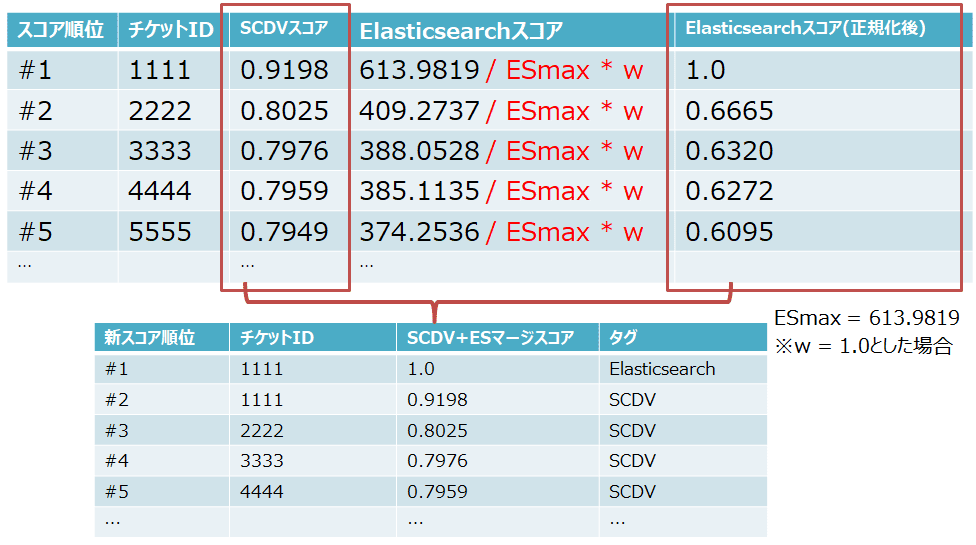
上図の例でチケットID=1111が重複して2回出ているように、ESとSCDVのスコアを合算するためチケットの重複が発生します。
このため実際のプログラムでは、スコアの合算後にチケット重複分を取り除く処理を入れてから、レスポンスとしてチケットIDの一覧を返すようにしています。
5. (日中処理)類似チケットセットをRedmine関連チケットに紐付ける
最後に、受け取ったレコメンドチケットセットをRedmine Issue Relations APIに向けて送信すれば紐付けが完了します。(下図(5))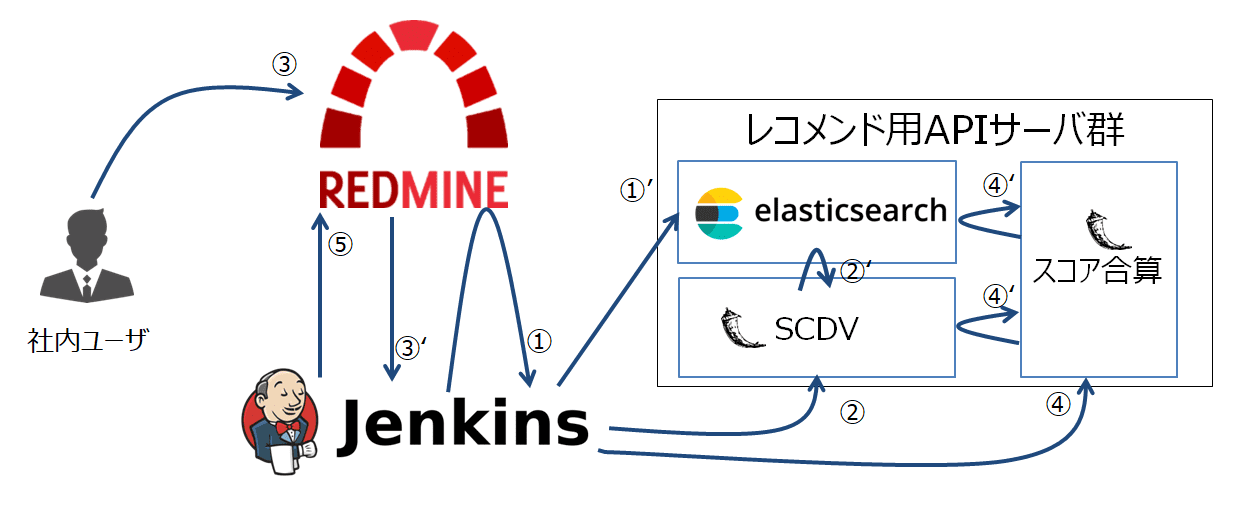
今回は起票された1チケットにつき、スコアの高い順に4件(件数固定)の類似チケットの紐付けを行うようにします。
Issue Relations APIは1リクエストに付き1件の関連チケット紐付けを行いますので、リクエストを4回、紐付け先IDを変えながら送信します。
送信するPOSTリクエストは、以下のようになります。
- リクエストURL:
https://[Redmineサーバのアドレス]/redmine/issues/XX/relations.json - リクエストボディ: 下記JSON参照
{ |
上記リクエストボディには、relation_type: recommendsという独自の関連チケットタイプを用いております。
こちらについて、relation_type: recommendsを含むリクエスト送信デフォルト環境のRedmineに向けて実行すると、下記のようにバリデーションエラーが発生してしまいます。
{ |
そのため、relation_type: recommendsをバリデータに許可してもらうためにモンキーパッチを作る必要があります。
関連チケットのモデルはapp/models/issue_relation.rbで管理しているため、こちらのソースコードで定義されたvalidatorに対するモンキーパッチを当てることで対応しました。
工夫ポイント: Docker+ECSを使ってサービスのコンテナ化を実現
EC2などを使ってOS上に直接Pythonプログラムを載せるのではなく、機能単位でFlask APIサーバ化&Dockerイメージ化をしました。
これにより、AWS ECSの使用が可能となり、多くの恩恵を受けることが出来ました。
- ST環境、本番環境の構築コストが大幅に削減
- やることは「DockerイメージのPush」「タスク定義の作成」「サービス定義の作成」「クラスタの作成」のみ
- ST環境、本番環境の運用コストも大幅に削減
- アップデート作業も「DockerイメージのPush」「タスク定義の更新」「サービス定義の更新」の3ステップで完了
- スケールアップやスケールアウトもECSのWebコンソール画面から操作可能
結果と今後の展望
導入した結果
- 類似チケットの精度について
- 運用・保守フェーズを担当する1プロジェクトにご協力頂き、「チケットに紐付けられた類似チケットが参考になるか?」をPJメンバーの皆様に見てもらいました。
- サンプリング対象: 26チケット
- チケットで扱う内容: クライアントからの問い合わせ、サーバメンテナンス・障害連絡など(定常業務・非定常業務の双方含む)
- 結果
- 26件中、22件(84.6%)のチケットに対して「いずれか1つ以上存在の類似チケットが参考になった」との回答をいただきました。
- 運用・保守フェーズを担当する1プロジェクトにご協力頂き、「チケットに紐付けられた類似チケットが参考になるか?」をPJメンバーの皆様に見てもらいました。
- システムの応答時間について
- 類似チケットの探索時間は、検索対象チケット数に比例して増加します。
- チケット起票から類似チケットがRedmineに紐づくまでの時間は、対象チケット4000件のRedmineプロジェクトにおいて平均9.39秒という結果でした。
感想
- 想像以上にいい精度が出てよかった
- 開発着手前は、参考になる類似チケットが含まれるのはせいぜい5割程度と見積もっていましたが、予想以上の結果(8割超)を得ることが出来ました。
- 少人数・短期間で、簡単に構築できた
- 設計・開発は私一人がメインで、レビューやAI技術に関するアドバイスとしてTIG(Technology Innovation Group)・SAIG(Strategic AI Group)の先輩方にご協力をいただきました。
- ECSを用いることで、サーバ管理がかなり楽になりました。
- DockerイメージとECSタスク定義さえ作れば、EC2のような初期構築作業が一切不要
- メモリリソース不足等でサーバダウンの際は自動で再起動してくれる
- 紙とペンを使った、手書きのアウトプットの有用性に気付かされた
- システムの設計段階においてサーバ構成やデータ処理の流れを考える必要がありましたが、うまくイメージがまとまらず、今までのように「頭の中で考えて、イメージが固まってからパワポ等で作る」だけでは通用しないことが分かりました。
- そこで、ノートをアウトプットの土台とし「まずは頭に浮かんだ個々のイメージをノートに吐き出す」→「出来上がった全体像を俯瞰して、おかしい部分を修正する」という作業に落とし込むことで、スムーズに設計作業を進めることが出来ました。
苦労したところ・ハマりポイント
- AWS ElasticsearchServiceでは一度に送信できるバルクインサートのサイズに制限あり
- 1度のPOSTで挿入できるデータ量は10MB(※)まで ※インスタンスタイプにより異なる
- 参考: https://docs.aws.amazon.com/ja_jp/elasticsearch-service/latest/developerguide/aes-limits.html#network-limits
- およそ1000件以上のチケットを纏めて格納しようとするとエラーとなってしまう
- この仕様を後から知ったため、バルク分割のためのスクリプトを追加で開発することになってしまった💦
- 1度のPOSTで挿入できるデータ量は10MB(※)まで ※インスタンスタイプにより異なる
- Elasticsearchの最新版(6系)では、インデックス内の複数タイプ使用が不可
- 参考: https://dev.classmethod.jp/server-side/elasticsearch/elasticsearch-6-breaking-changes/
- 開発時点では5系をベースとしていた&6系の変更点を洗い出せていなかったため、5系依存のプログラムを作ってしまった
- 「Elasticsearchのインデックス内タイプ」と「RedmineのプロジェクトID(プロジェクト識別子)」を紐付ける仕様としたため、そのままでは6系アップグレードが不可能になってしまった
- AWS ECS環境でメモリリソース不足によるコンテナ強制終了が頻発
- 開発環境(ローカルマシン)から検証環境(AWS)へ移行後、メモリリソース不足によるコンテナ強制終了が頻発した
- 開発機環境における検証段階で、APIサーバ単位・合計の消費メモリのチェックをすべきだった
- APIサーバごとのメモリ使用量調査など、追加検証が幾つか必要になった
- EC2サーバの台数を増やすことで対処できた
- ただし、今もSCDVモデルの書き出し処理の最中で強制終了されることがあり、要改善
- 開発環境(ローカルマシン)から検証環境(AWS)へ移行後、メモリリソース不足によるコンテナ強制終了が頻発した
今後の展望
今回のシステムは「チケット起票時」に注目したものでしたが、
今後はチケットをわざわざ起票せずともシステムを使えるよう、以下のUI機能実装を考えています。
- チケット起票画面で、フォーム入力状況からリアルタイムにレコメンド結果を表示するインクリメンタルサーチ機能
- 対話形式であいちゃんBotと会話することによりリアルタイムにレコメンド結果を得られるチャットボット機能
また、システム面においてはレコメンドシステムのサーバレス化のため、JenkinsをAWS Lambdaに置き換えることを予定しております。
スペシャルサンクス
- フューチャーSAIG(Strategic AI Group)所属の小池さん
レコメンド機能の設計・開発のアドバイスに加え、本記事のアルゴリズム解説の執筆担当をしていただきました!
ありがとうございます。
おわりに
PythonライブラリやAWSのクラウド資源を活用することにより、
AIを活用したレコメンドシステムを少人数・短期間で構築&デプロイできました。
各種機械学習ライブラリやクラウド資源、Web上のナレッジベースの普及により、AIを使ったシステム開発・構築のハードルはかなり下がっているな、と私自身も実感しました。
皆さんの身近な環境に、「このシステムは使いづらい」「検索などの定常作業を取り除きたい」といった”悩みの種”はありませんか?
チケット管理システムなどの社内で眠ったままの豊富なリソースとAI技術とを結びつけることで、多くの人に恩恵を与えるシステムを作り上げることが出来ますよ!
是非、チャレンジしてみて下さい💪
- 1.EMNLP2017 ↩
- 2.okapi BM25(https://ja.wikipedia.org/wiki/Okapi_BM25) ↩