はじめに
みなさんこんにちは! SAIG(Strategic AI Group)の水本と明官です!
2019年6月4日(火)〜6月7日(金)に開催された人工知能学会全国大会(JSAI2019)にSAIGで参加してきましたので報告します。
フューチャーは2017年からJSAIのプラチナスポンサーとなっており、今年もスポンサーブースの出展、インダストリアルセッションでの発表を行ないました。また、スポンサーブース出展の合間を縫ってセッション聴講も行なってきました。
今年のJSAIは新潟県の朱鷺メッセで開催されました。東京からだと新潟駅まで2時間程度、新潟駅から朱鷺メッセまで20分ほどの比較的参加しやすい立地でした。ありきたりですが、おいしい日本酒とお米が印象的でした(下の写真は参加者交流会で出た日本酒のほんの一部)。
人工知能学会全国大会とは
今年で33回目の開催で人工知能 (AI)の研究発表を行う学会で、機械学習から人工知能の応用の話まで幅広く発表があります。一般口頭発表、インタラクティブセッション(ポスター発表)、テーマに沿った発表を行うオーガナイズドセッションや企画セッション、企業の方が事例紹介などを行うインダストリアルセッションなどがあります。一方で発表会場も15会場程度あり、どの発表を聞きに行くか決めるのも大変なセッション数になっています。SAIGの貞光/水本はこの全国大会の運営委員もやっており、学会中にそちらの仕事も行っておりました。
人工知能学会全国大会はここ数年でさらに規模が拡大してきており、2017年には2,561人であった来場者数は、2018年には2,611人、今回の2019年には2,897人と順調に増加しており発表申し込み件数も750件程あったそうです。スポンサー数も、2017年から55社、68社、90社と増加しました。また、学会としては、量から質への転換を目指しており、査読付きの国際セッションを開催するなど、新しい取り組みに積極的な様子でした。
ブースの紹介
企業ブースでは、FutureでのAI案件実績を展示し、学生さんや企業の方との議論が大変盛り上がりました!
ノベルティとして配布したFutureオリジナルの歯ブラシも大好評でした。
セッション聴講
スポンサーブース出展の合間を縫って聴講した口頭発表、インタラクティブセッション(ポスター発表)から独断と偏見でおもしろいと思ったものを紹介します。
[3Rin2-40] 潜在的な旅行者への宿泊施設の提案(丸山ら)
この研究では、宿泊施設の提案のためにユーザの路線検索の履歴を使います。具体的には路線検索で100km以上の移動がある検索を行なったユーザに対してホテルも情報をメールすると言った本当に単純な方法です。検証では、移動距離が長く、かつ路線検索の指定日時が遠いほどメールによってホテルの予約をするユーザが多くなるといった結果が得られていました。一見当たり前のようですが、様々なサービスを一社で扱っている強みとも言え大変興味深かったです。また、応用的にはホテルだけでなくレストランの提案などとも相互に情報を使うこともできそうなため今後に期待したい発表でした。
[2H4-E-2-03] 潜在的な談話構造を捉えたレビュー文書の教師なしヘッドライン生成(磯沼ら)
今年のJSAIから始まった国際セッションで発表されたものです。教師ありのヘッドライン生成が主流ですが、教師ありでやるにはデータ量も必要でかつドメインも揃えないと難しいといった問題があります。その問題を解決する手段としてこの論文ではヘッドライン生成を教師なしで行う手法を提案しています。談話構造を考えた時に、子の文は親の文に関する追加情報が書かれている、ルートというのは良いサマリーになっているという仮定をおいた手法になっています。つまり、子の文を使って親の文を生成するように学習することで要約になる文を生成しようというアイデアになります。実験の結果、全体の性能では教師あり手法に及ばない結果になっていますが、レビューに含まれる文が多い場合は教師あり手法と同じ程度もしくは上回る性能となっており大変興味深い結果となっています。実際の出力例を見ると、教師あり学習では名詞句のようになっているのですが、教師なしの方ではちゃんとした文になっているのが特徴的です(ヘッドラインとして文になっている必要があるかはわかりませんが)。モチベーションにあるように、ドメインの違うデータで学習した場合の教師ありの結果と比較したらどうなのかというのも気になるところです。この研究は自然言語処理のトップ国際会議でもあるACLに採択されているようなので、そちらも要チェックです。
[2L5-J-9-02] 物語世界間のつながりが一部明示されたメタファー写像セットの構築(松吉ら)
物語文章の自動生成にシミュレーションとメタファー写像を使うといったおもしろい研究です。自動生成のフレームワーク自体は著者らの先行研究 1で提案されたもので、この研究はその自動生成のフレームワークを使ってデータ(メタファー写像セット)を拡張した話になります。ここでシミュレーションは迷路探索であったり、チェスであったりをシミュレートするものです。その状態遷移に基づきメタファー写像にある対応する事象を使って文を生成します。例えば、「チェスで相手のコマを取る」様子を「部屋の物を片付ける」イベントに写像するといった具合です。部屋の片付けだけでなく、チェスや迷路探索を様々なイベントに対応することでいろいろな物語を自動生成可能になります。また、チェスや迷路探索などを組みわせることもでき、フレームワーク自体は簡単ですが、より複雑な物語も生成できます。この研究では、物語を生成する核となるメタファー写像セットの構築をし、チェスと迷路探索によるメタファー写像をそれぞれ100個ずつ作成しました。また、物語世界の呼び出しを行うようなものも実際に作成しました。
[2L5-J-9-03] 機械翻訳における訳語一貫性評価用データセットの構築(阿部ら)
NMTの登場によって流暢な翻訳を生成可能になってきましたが、これまでの機械翻訳の研究では一文単位での翻訳を対象にしていました。そのため文章単位での翻訳を考えた場合に、文脈に応じた訳語選択、代名詞補完、訳語の一貫性といった観点から見ると機械翻訳には課題が残っています。最近になり文脈を使った機械翻訳の研究は行なわれるようになってきましたが、訳語の一貫性といった観点で取り組んでいる研究はありませんでした。そのため一貫性を評価するためのデータセットや適切な評価指標が存在していません。この研究では、機械翻訳による訳語一貫性を評価するための日英/英日翻訳データセット作成に取り組みました。また、実際に実験も行なっており、制約付きデコーディングを使うことで訳語の一貫性の正解率が高くなることを示しました。
[3N4-J-10-03] 深層学習を用いた不動産間取り図のグラフ化と物件検索への応用(山田ら)
不動産の間取り図で類似したものを検索するために、グラフ構造を利用した研究です。先行研究では部屋の物理的近さを用いてグラフを構築していたため、実際に行き来できない部屋同士にもエッジが張られるという問題がありました。そこでこの研究ではドアの位置の情報を使うことで先行研究の問題を解決しました。具体的には、まずドアの位置をルールベースで同定し、ドアで繋がっている部屋(ノード)間にエッジを張るところを限定しグラフを生成します。この手法を使って実際の物件検索に応用した例の成功したものは人が見ても似ていると思えるものでありおもしろいと思いました。
[2Q3-J-2-04] 特徴パターンを用いた機械学習の説明手法(浅野ら)
LIMEは個々の特徴の重要性を測ることはできますが重要な特徴の組み合わせを特定することはできないため、予測に影響を与えた特徴の組み合わせに着目したMP-LIME(Minimal-Patterns-LIME)を提案しています。極小パターンの探索方法としては、特徴の組み合わせ特徴(A,B,C)に対して(A,B),(B,C),(A,C)と特徴数を減らしたパターンを作り、それぞれの特徴パターンを使った分類結果と元の分類結果が変わるまで探索します。特徴数を減らしていき、異なる分類結果になった1つ前の特徴パターンを極小パターンとし、この極小パターンをMP-LIMEにおける判断根拠とします。結果は、recallは若干下がりましたが、Precisionがかなり向上し、実際に予測に用いられた特徴の割合も多くなるという結果でした。LIMEにより判断根拠として出力された画像を再度CNNにかけると、もとの分類結果にならないという問題がありましたが、MP-LIMEだとそれも解消されていました。判断根拠特定手法はかなり多くの方々から注目されており、我々もチャレンジしている分野だったため非常に興味深い発表でした。
[1P2-J-13-05] 新聞記事からの因果関係を考慮したアナリストレポートの自動要約文生成(高嶺ら)
新聞記事からのテキストマイニングによる因果関係を考慮したアナリストレポートの要約文生成手法の研究です。アナリストレポートとは、証券分析の専門家が企業の経営状態や収益力などを分析・調査し、まとめたレポートのことです。アナリストレポートには、アナリストの予想を示す文とその根拠を示す文があり、これら二種類の文と類似する文を新聞記事中からマイニングします。類似度の算出方法として、LDAとSkip-gramにより得られた2種類の分散表現の類似度と金融極性辞書を用いた極性の一致度をそれぞれコサイン類似度を用いて算出しています。評価方法として、文章内で因果関係を抽出できたレポートの件数に対するアナリストの予想の根拠情報の抽出ができたレポートの件数の割合を用いており、この割合が80%を超えていることから提案手法が有用であることを示しました。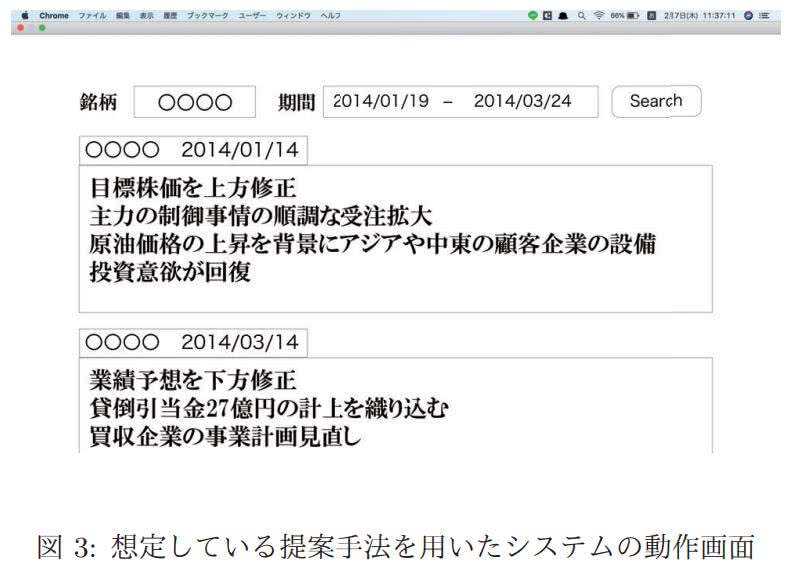
[1H4-J-13-03] 長期短期記憶と心拍変動に基づく睡眠時無呼吸症候群のスクリーニング(岩崎ら)
睡眠時無呼吸症候群(SAS)は、睡眠中に呼吸の停止あるいは呼吸量の減少が頻繁に起こる疾患であり、日中の眠気などの症状を引き起こすほか、心血管系の合併症のリスクを高めます。一方で自覚症状に乏しいケースも存在するため治療に至っていない患者が多いと考えらえています。SASの診断には終夜睡眠ポリグラフ検査 (PSG) が用いられますが、PSGを実施できる施設が少ないことや高額であることが問題でした。そこで本研究では、心拍変動解析とLSTMを組み合わせたスクリーニング手法を提案しており、SAS患者および健常者のデータに対して提案法を適用したところ、感度100%、特異度100%(感度:SASの人のなかで、陽性と判断された割合、特異度:SASではない人のなかで、陰性と判断された割合)でSASのスクリーニングが可能であることが明らかとなりました。適用された手法としては新規性はありませんが、このような医学領域での活用は新鮮でわかりやすく面白い発表でした。
[1L3-J-11-01] HVGH: 高次元時系列データの深層圧縮と教師なし分節化(長野ら)
この研究では教師なしで高次元の時系列データから特徴抽出すると同時に、分節・分類が可能なHierarchical Dirichlet Processes-Variational Autoencoder-Gaussian Process-Hidden Semi-Markov Model (HVGH)を提案しています。HVGHは、HDP-GP-HSMMにVariational Autoencoder(VAE)を導入したモデルであり、VAEにより高次元データを低次元の潜在変数へと圧縮し、その潜在変数の遷移をガウス過程を用いて表現することで、高次元の複雑な時系列データの分節化を可能としています。実験ではCMU Graphics Lab Motion Capture Databaseのモーションキャプチャデータ(チキンダンスと体操動作 1)を入力として分節化を行った結果、複雑な動作も高い精度で分節化が可能であることを示しました。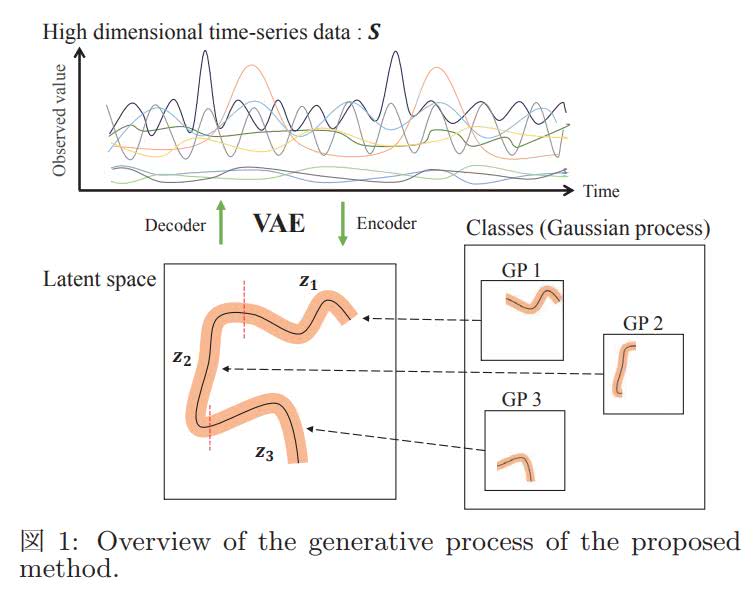
おわりに
いかがでしたでしょか? 👦
二人ともFutureに入って初めての学会でしたが、様々な研究成果を見ることができ良い刺激を受けました。
SAIGでは、週に1回、Future Study Group という勉強会を開催しているので、JSAI2019の研究発表も共有しようと思います!
現在SAIGでは意欲あるメンバーを募集しています。
下記URLから応募できますので、興味のある方は是非!
https://progres12.jposting.net/pgfuture/u/job.phtml?job_code=365
https://progres12.jposting.net/pgfuture/u/job.phtml?job_code=363

▲会場(朱鷺メッセ)から見える景色
以上、水本・明官でした!
- 1.松吉 俊, 内海 彰:メタファー写像に基づく物語文の自動生成, 言語処理学会第 24 回年次大会発表論文集, pp. 1288–1291 (2018) ↩