はじめに
みなさんこんにちは😃
Strategic AI Group (SAIG)の水本です。
2019年9月27日、28日にフューチャーにて、第15回テキストアナリティクス・シンポジウムが開催され、SAIGから貞光、田中と私が講演を行いましたので、そちらを紹介したいと思います。
また、少し前のことになりますが2019年7月28日〜8月2日にイタリアのフィレンツェで開催された自然言語処理分野の国際会議に参加して、ワークショップですが前職の研究成果を発表してきましたので、合わせて報告したいと思います。
第15回テキストアナリティクス・シンポジウム開催報告
9月27日、28日にフューチャーのオフィスでシンポジウムが開催されました! 自然言語処理の研究会はいくつかあるのですが、その中でも産業界の方の参加が多いテキストアナリティクス・シンポジウムをフューチャーで開催できるということで楽しみにしていました。
また、フューチャー開催ということもあり、SAIGチームからも3件の講演を行いました!
シンポジウムでは、2日間でおよそ130名の参加者にお集まりいただき、活発な議論が交わされていました。
プログラムはこちら↓↓
http://www.ieice.org/~nlc/tm15a.html
フューチャーからは、以下3件の講演を行いました。
- 特別講演「人工知能によるプロフェッショナルの理解に向けて~ 言語・音声・画像・グラフ処理を活用した社会実装 ~」 貞光
- 依頼講演「ICLR2019参加報告」 貞光、田中
- 依頼講演「ACL2019参加報告」 水本
特別講演
特別講演では、従来語られることの多かったBPOやギグ・エコノミーに関するAIの取り組みではなく、高い専門性が要求される、プロフェッショナルの仕事に関するAIの取り組みに焦点を当ててお話ししました。
このような各領域の深ーい話は普段あまり触れる機会がありませんので、多くの方に興味を持っていただけたと思います。なお、本講演に関連するプレスリリースを本blogの末尾にリンクしておきますので、よろしければ是非ご覧ください。

ICLR参加報告
前半はICLR2019の統計と言語以外に関する研究に注目した紹介となっています。PDFを中まで解析して組織毎に採択数をカウントしているのが頑張りポイントです(自動処理のため、数え間違い等についてはご容赦ください!)
後半は、田中から自然言語処理に関連する論文を2本紹介しました。最終日の午前中にNLP系の発表が多くありました。ACLなどと比較しマルチモーダルな研究が多かったです!

ACL参加報告
シンポジウム内で参加報告が2件あったため、私の方は研究内容の紹介よりも、会議の概要に力を入れた発表内容になっています。シンポジウム中の発表では時間の関係上1件しか論文を紹介できませんでしたが、スライドの方には2件とも載せていますので、シンポジウム参加者の方でも興味があればぜひご覧ください。

ICLRに関しては、すでにフューチャーブログで参加報告を書いているので軽めですが、ACLの方はせっかくなのでもう少し紹介したいと思います。
ACL2019参加報告
概要
ACL (Annual Meeting of the Association for Computational Linguistics)は、自然言語処理分野のトップ国際会議で、今年で57回目の開催となりました。
バッソ要塞という要塞内での開催でした。

外は要塞っぽい雰囲気でしたが、中に入ってしまうと現代的な会議施設でした笑
イタリアということで、ピザやパスタは本場の味という感じで美味しかったです。また、フィレンツェの街並みもきれいで見応えがありました〜。
オープニングで主催者の方も強調していましたが、今年のACLは非常に大規模なものでした。参加者の数が3180人 (2018年は1322人)、論文投稿数が2905件 (2018年は1544件)、発表件数が660件 (2018年が384件)と昨年に比べ2倍程度の規模になっています。
ACLトレンドとしてここ3年の論文タイトルで特徴的なものを調べた結果、2017年・2018年はneural、learningという単語が特徴的なのに対して、2019年はsummarizationやunsupervised、generationといった単語が特徴的になっており変化が見られ面白いです。
個人的に今回のACLでホットだと思った分野は以下の4つでした。
- Bias
- Health
- Evaluation
- Interpretability
それぞれセッションが独立であったりワークショップがあったりと盛り上がってるテーマでした。Biasは性別や人種など最近世界全体で話題に上がることも多く、自然言語処理でもそのあたり注意した方が良いということで研究が盛んになってきた感じです。Healthに関してもカルテの電子化なども進んできたりしてることもあり、言語処理でサポートしたいという動きが出てきているように思います。Evaluationは多様な表現を生成できるようになったた生成系タスク(翻訳、要約など)をちゃんと評価したいということで注目が集まっているように思います。Interpretabilityは画像や機械学習分野の会議でも盛んに研究されていますが、言語処理でも機械の判断根拠を知るための方法について注目が集まっています。
参加報告の論文紹介ではこの中から”Health”、”Evaluation”に関する以下の2本の論文を紹介しました(スライドは↑↑)。
- Extracting Symptoms and their Status from Clinical Conversations
- HighRES: Highlight-based Reference-less Evaluation of Summarization
実際の医者と患者の会話から症状や状態を抜き出す論文と、要約の評価をリファレンス(正解)を使うのではなく元記事の方の重要単語を使って要約文を評価するといった論文で、新しい方向性ということで紹介しました。
BEA2019ワークショップ
前職理研AIPでの研究をACLのワークショップの1つ”14th Workshop on Innovative Use of NLP for Building Educational Applications“ (BEA2019)で発表してきましたのでそちらも簡単に紹介します。
BEA2019は自然言語処理の教育分野への応用についてのワークショップで、文法誤り訂正・自動採点について多く研究発表がされています。”Duolingo”、”Grammarly”、”ETS”などの教育分野で有名な分野がスポンサーになっており、自然言語処理の教育応用分野では最大規模のワークショップです。ACLで参加者や投稿数が増えているという話をしましたが、BEA2019も投稿数が80件程度あり、採択率は約40%とワークショップとしては難しいと言える採択率でした。
さて、発表した研究ですが、”Analytic Score Prediction and Justification Identification in Automated Short Answer Scoring“というもので、短答式問題の自動採点に関する研究です。
短答式の問題で日本人に馴染みが深いのは、入試問題でよくある長文読解の記述式問題だと思います。従来の短答式問題の自動採点では、1つの解答に対して1つの点数(全体点)を予測するタスクとして扱っていましたが、本研究では1つの解答に対して複数の点数(項目点)を予測するタスクを新しく提案しました。下の図で”holistic score”となっているのが従来の全体点、”analytic score”となっているのが本研究で新しく扱う項目点です。全体点は項目点の足し算になっており、図の例では減点があるため、3+2-1=4になります。
項目点は採点基準を元に決められます。項目の数などは問題ごとに異なります。加えて新しいタスクとして、項目点の根拠になる箇所(justification cue)を推定するタスクも提案しました。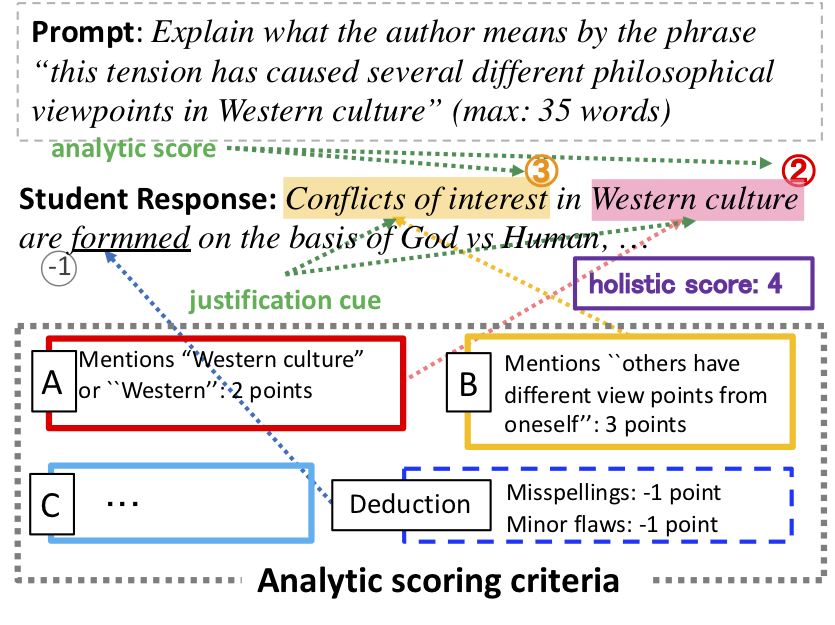
本研究の貢献は、
- 2つの新しいタスクの提案、2. 新タスクのためのデータセットの構築、3. 新タスクのための手法の提案の3つです。
手法としては工夫した点は、
- 項目点だけでなく全体点を使って項目点の推定を学習可能
- 教師ありアテンションを使うことで、項目点推定性能、根拠の推定性能を向上させる
などがあります。
詳しく知りたい人はぜひ論文を読んでもらえればと思います!
短答式問題の自動採点は、記述式問題が大学入試の共通試験に導入されるなど、ホットな分野になってきているので、今後ますます色々と研究され発展していく分野の1つだと思います。
おわりに
いかがでしたでしょうか😃
SAIGチームでは国際会議にも積極的に参加し、最先端の技術の情報収集も怠らずに行っています。また、このような参加報告も力を入れて行っていますので、これからのSAIGにもご期待くださいー。