こんにちは、Strategic AI Group(SAIG)の田中、上野です。
少し前にNeurIPSという学会に参加して来たことをご報告しましたが、今回はNeurIPSで気になった論文をいくつか紹介したいと思います。
画像認識・生成
まずは、上野からは画像認識・生成に関する下記2つの研究を取り上げます。
This Looks Like That: Deep Learning for Interpretable Image Recognition
Chaofan Chen(※1), Oscar Li(※1), Daniel Tao(※1), Alina Barnett(※1), Cynthia Rudin(※1), Jonathan K. Su(※2)
※1: Duku University
※2: MIT Lincoln Laboratory
HYPE: A Benchmark for Human eYe Perceptual Evaluation of Generative Models
Sharon Zhou(※1), Mitchell Gordon(※1), Ranjay Krishna(※1), Austin Narcomey(※1), Li F. Fei-Fei(※1), Michael Bernstein(※1)
※1: Stanford University
1つ目はCNNの解釈性に関する研究で、2つ目は生成モデルの評価方法に関する研究です。
それぞれ、関連する研究を取り上げながら紹介します。
CNNの解釈性に関する研究
Deep Learningの威力を世に知らしめた出来事の1つは、2012年のILSVRCという画像認識に関するコンペティションでした。2012年以降、画像認識の精度がどんどん向上し、ついには人間のレベルに匹敵するまでになりました。
画像認識では、Convolutional Neural Network(CNN)と呼ばれる技術が用いられますが、非線形な演算を何層にも渡って繰り返すため、CNNが画像のどこに着目して分類をしているかといった解釈が非常に難しくなってしまいます。
CNNの着目領域を可視化した初期の研究が、Class Activation Mapping(CAM) [1]です。
CAMでは、下図のようにGlobal Average Poolingをする直前のfeature mapに分類層の結合重みを使った線形和によって、CNNの判断根拠を可視化します。
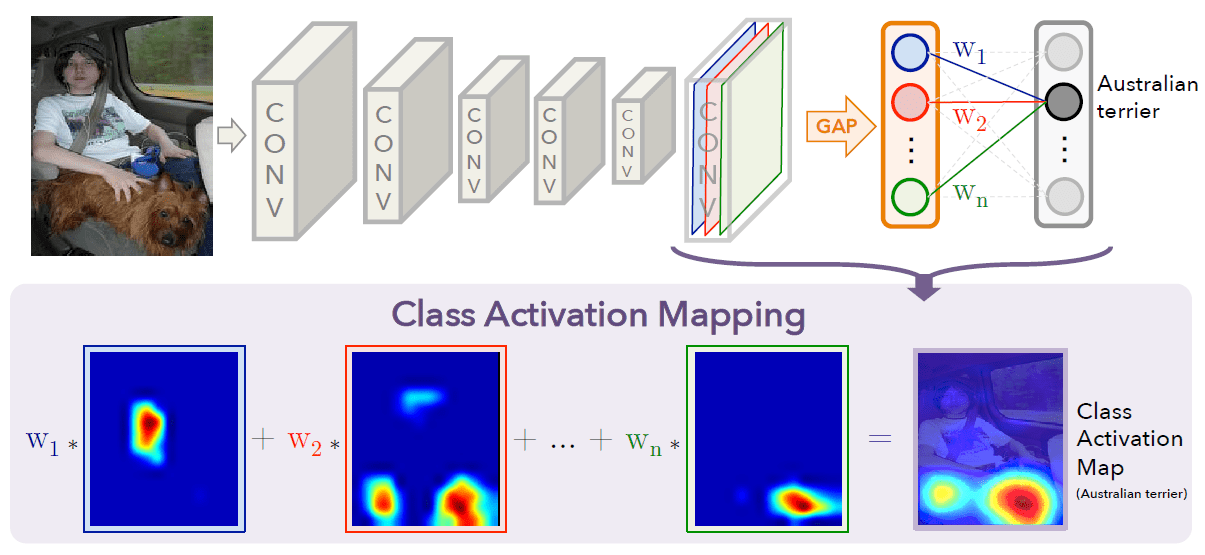
[1]のFigure2より引用
CAMは、conv feature maps → global average pooling → softmax layer という構成である必要がありましたが、Grad-CAM [2]では、勾配を用いてfeature mapの重み付けをすることで、ネットワーク構成の制約がなくなりました。
また、Attention Branch Network [3]では、Activation mapをAttentionに使う方法が提案されています。
Attention Branch Networkは、中部大学の研究グループが提案したこともあり、今夏に参加した日本の学会MIRUではよく見かけました。
NeurIPSでは、porototypical part network(ProtoPNet) [4]という手法が提案されました。ProtoPNetでは、Prototype layerによって、入力画像中のどの領域が、学習データのどの部分と類似しているかまでを判断できます。
その結果、単に着目領域が可視化されるだけではなく、画像の部分ごとの判断根拠を組み合わせた、より詳細な推論の解釈を可能にします。
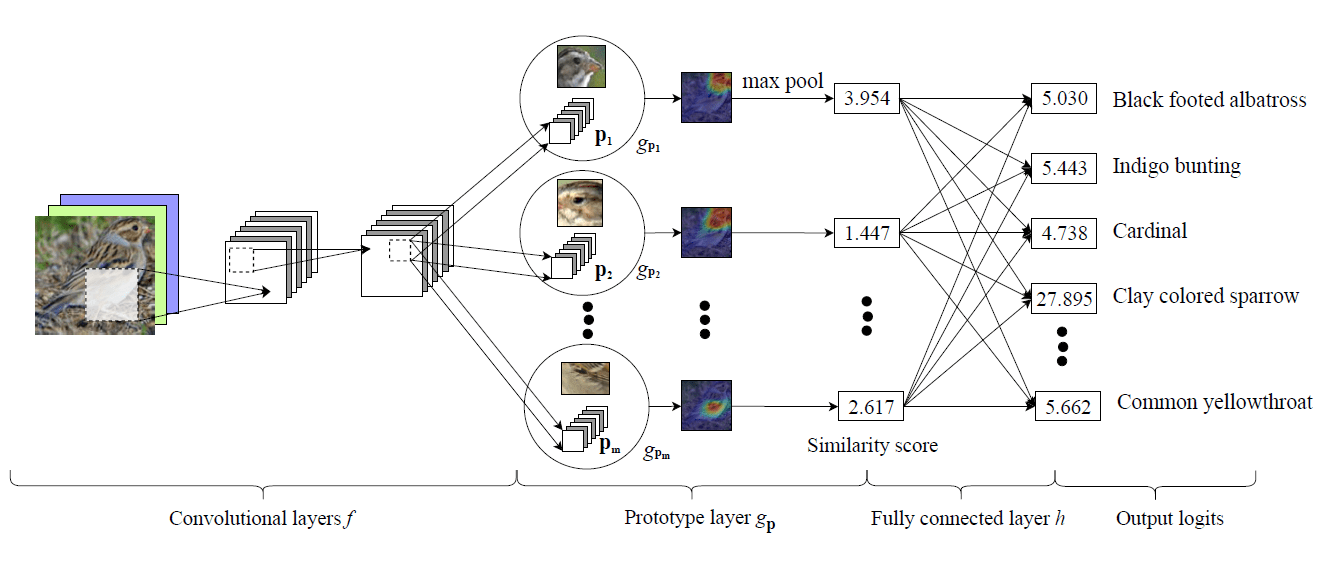
[4]のFigure2より引用
NeurIPS最終日に行われたMedical Imaging meets NeurIPSというワークショップでは、CAMを医療画像へ適用した事例がポスター発表でありました。
HR-CAM [5]では、最後のfeature mapだけではなく、中間層のfeature mapも用いることで、より鮮明に判断根拠を可視化します。
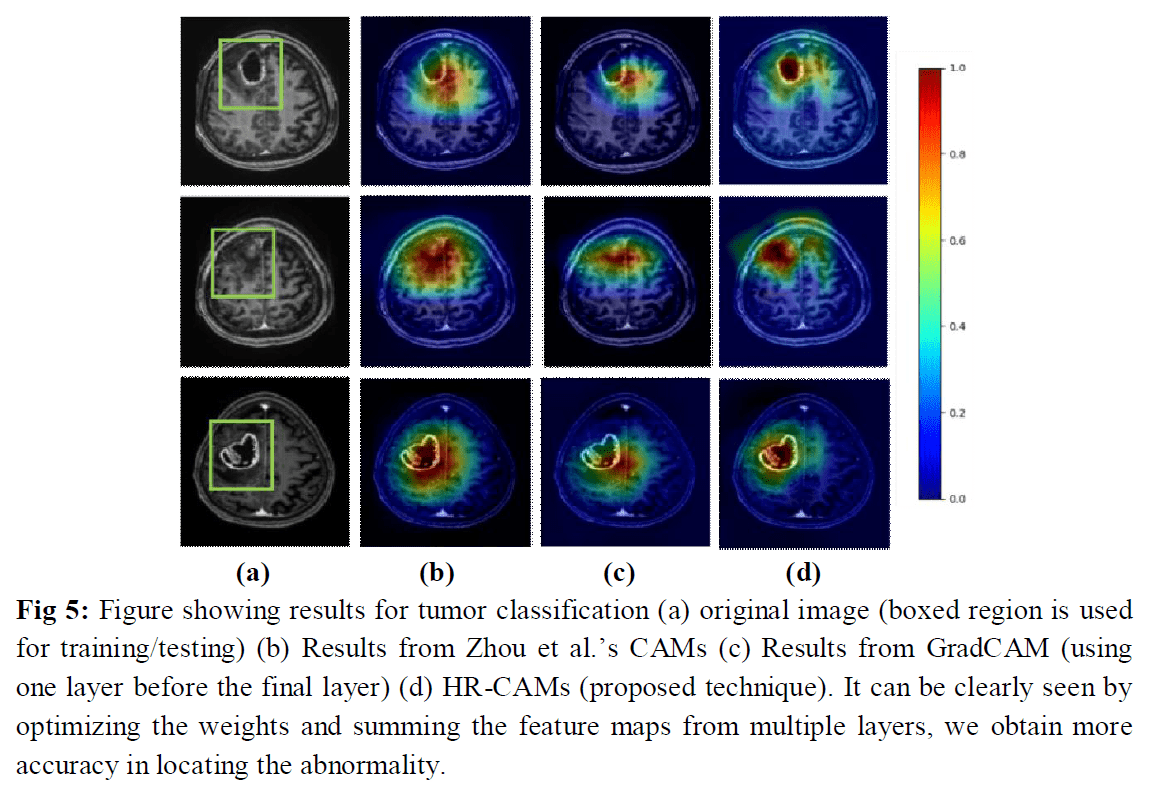 [5]のFigure5より引用
[5]のFigure5より引用
また、初日のEXPOでは、Googleが”Interpretability - Now What?”というタイトルで解釈性に関する発表をしていました。
そこでは、Testing with Concept Activation Vectors(TCAV) [6]という手法が紹介されました。
TCAVは上記までの手法の流れとは少し異なり、概念的な重要度を抽出する方法を取っています。
画像認識の分野に限らず、解釈性に関する研究は近年、注目を高めている分野の1つです。
- [1] B.Zhou, et al., Learning Deep Features for Discriminative Localization, 2016.
- [2] R.R.Selvaraju, et al., Grad-CAM: Visual Explanations from Deep Networks via Gradient-based Localization, 2017.
- [3] H.Fukui, et al., Attention Branch Network: Learning of Attention Mechanism for Visual Explanation, 2018.
- [4] C.Chen, et al., This Looks Like That: Deep Learning for Interpretable Image Recognition, 2019.
- [5] S.Shinde, et al., HR-CAM: Precise Localization of pathology using multi-level learning in CNNs, 2019.
- [6] B.Kim, et al., Interpretability Beyond Feature Attribution: Quantitative Testing with Concept Activation Vectors (TCAV), 2018.
生成モデルの評価方法に関する研究
近年、Generative Adversarial Network(GAN)をはじめとした深層生成モデルは目覚ましい発展を遂げ、本物と見間違える程きれいな画像を生成できるようになってきました。
しかし、生成された画像のクオリティを適切に評価することは、それほど簡単なことではありません。
よく使われる指標は、Inception Score [7]とFréchet Inception Distance [8] です。
Inception Scoreは、次式で計算されます。
p(y|x)は、ImageNetで学習済みのInception Modelで生成された画像を予測したときのラベルの分布、p(y)は予測ラベルの周辺分布であり、それらの分布間の距離をKullback–Leibler divergenceで測っています。
生成される画像が、識別が容易で、かつ、バリエーションが豊富であるほど、スコアが高くなるように設計されています。
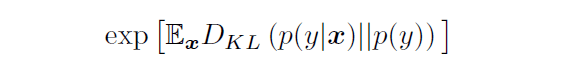
もう1つのFréchet Inception Distanceでは、実画像と生成画像でのInception Modelから得られる特徴ベクトルの距離を次式で測ります。
m_w, C_wは実画像から得られる特徴ベクトルの平均と共分散行列、m, Cは生成画像から得られる特徴ベクトルの平均と共分散行列であり、それぞれ多変量正規分布に従うと仮定し、Fréchet距離で分布間の距離を測ります。
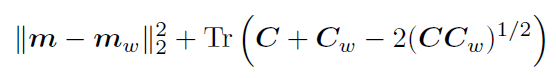
どちらの手法も、画像の「本物らしさ」をどのようにスコアするかや、ImageNetでの学習済みモデルに依存してしまっていることなどが課題としてあげられます。
NeurIPSでは、HYPE [9]というクラウドソーシングを利用して人の目で評価する手法が提案されました。
Amazon Mechanical Turkを利用したクラウドソーシングにより、実画像と生成画像の分類を人の目で行います。
論文では、心理物理学に基づいて評価者への画像の提示時間を制御する方法と、コストを抑えるために時間の制限を設けない方法の2つの手法が提案されています。
次図のように、HYPEのスコアによってモデルの善し悪しが判断できるような結果が得られています。
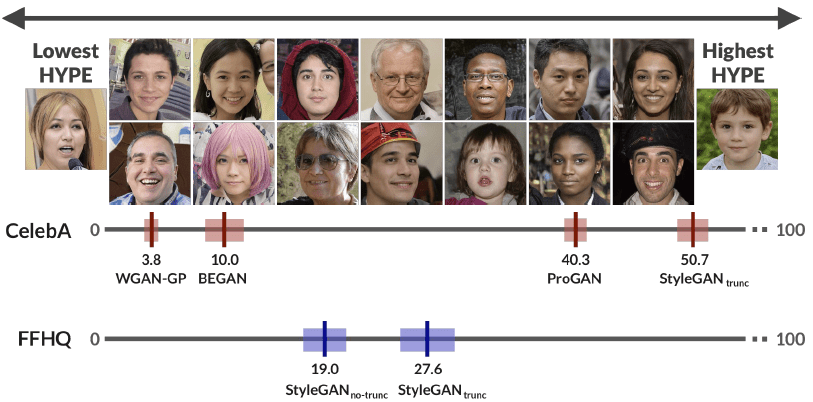
[9]のFigure1,Figure2より引用
HYPEを試すためには、https://hype.stanford.edu/ からAWSのS3の情報を送ると、$60 ~ $100 程度の値段でスコアが得られるようです。
NeurIPSは理論よりの研究が多いなかで、少し変わり種の発表に感じました。
- [7] T.salimans, et al., Improved Techniques for Training GANs, 2016.
- [8] M.Heusel, et al., GANs Trained by a Two Time-Scale Update Rule Converge to a Local Nash Equilibrium, 2017.
- [9] S.Zhou, et al., HYPE: A Benchmark for Human eYe Perceptual Evaluation of Generative Models, 2019.
言語・認知理解
続いて田中から言語理解や認知機能に関する研究を紹介します。
SuperGLUE: A Stickier Benchmark for General-Purpose Language Understanding Systems
Alex Wang(※1), Yada Pruksachatkun(※1), Nikita Nangia(※1), Amanpreet Singh(※2), Julian Michael(※3), Felix Hill(※4), Omer Levy(※2), Samuel R. Bowman(※1)
※1: New York University
※2: Facebook AI Research
※3: University of Washington
※4: DeepMind
GLUEを置き換える、言語理解タスク・転移学習のベンチマークに関する研究です。
GLUEベンチマークでは、システムの評価結果がヒトの評価結果を超えましたが、依然としてシステムの評価を行うために頑健な、単一の評価基準が必要です。
そこで、多くの学習データ/ジャンル/難易度をカバーした8つの言語理解タスク用ベンチマーク、SuperGLUEを提案しました。
新たな評価タスクとして、coreference resolutionとQAを追加し、トレーニングデータが比較的少ないタスクに重点を置いた設計になっています。リーダーボードや、詳細な分析を行うためのデータセットはGLUE同様に提供されています。
SuperGLUEはこちらのリンクから使用できます。
From voxels to pixels and back: Self-supervision in natural-image reconstruction from fMRI
Roman Beliy(※1), Guy Gaziv(※1), Assaf Hoogi(※1), Francesca Strappini(※1), Tal Golan(※2), Michal Irani(※1)
※1: The Weizmann Institute of Science
※2: Columbia University
fMRIからのNatural Image Reconstructionタスク(ヒトが何かしらの画像を思い浮かべている/見ている際にMRIで脳の活動を記録、脳のMRIデータから、思い浮かべていた/見ていた画像を再構築するタスク)において、fMRIデータと正解の画像ペアのデータ数が少なく、学習が十分にできない問題があり、単純に教師あり学習を行っても十分な精度がでない課題があります。
そこで、コーパス外の50000件の画像データと、正解ラベルの付いていないテスト用fMRIデータをそれぞれ用いて、事前にencoder-decoderを学習する方法を提案しました。結果として、state-of-the-art、もしくはそれに匹敵する精度を達成しました。
最後に
NeurIPSは、EXPOからWorkshopまで入れると1週間ほどありました。
そこでは、多くの研究発表があり、ここでは取り上げきれないほど、おもしろい研究がたくさんありました。
みなさんもぜひ、興味のある分野を調べてみてください。