はじめに
こんにちは。TIG DXチームの村瀬です。
今回はGCP連載企画の9日目です。私個人としてはGCPはほとんど利用したことがないので、せっかくだから面白そうなことを試してみようと思い、画像AIのサービスであるVision APIについて試してみることにしました。
Vision APIとは
Google Cloud の Vision API は REST API や RPC API を使用して強力な事前トレーニング済みの機械学習モデルを提供します。画像にラベルを割り当てることで、事前定義済みの数百万のカテゴリに画像を高速で分類できます。オブジェクトや顔を検出し、印刷テキストや手書き入力を読み取り、有用なメタデータを画像カタログに作成します。
https://cloud.google.com/vision
Google Cloudの公式ページによりますと事前トレーニング済みの機械学習モデルを利用してラベルの割り当てやOCRとしてすぐに利用できるようですね。
機能(検出のタイプ)としては以下のものがあります。
| Feature Type | Description |
|---|---|
| Face detection | 顔の検出 |
| Landmark detection | ランドマークの検出 |
| Logo detection | ロゴの検出 |
| Label detection | ラベル検出 |
| Text detection | 光学式文字認識(OCR) |
| Document text detection (dense text / handwriting) | PDF/TIFF ドキュメント テキスト検出 |
| Image properties | 画像プロパティの検出 |
| Object localization | 複数のオブジェクトを検出する |
| Crop hint detection | クロップヒントの実行 |
| Web entities and pages | ウェブ エンティティおよびページの検出 |
| Explicit content detection (Safe Search) | セーフサーチ プロパティの検出 |
詳細は公式ページを参照ください。
https://cloud.google.com/vision/docs/features-list?hl=ja
料金
無料枠があり、最初の1,000ユニット/月は無料。それを越した場合でも1,000ユニットあたり$1.50。なんと太っ腹!
詳細は公式ページを参照ください。
https://cloud.google.com/vision/pricing?hl=ja
準備
プロジェクト作成
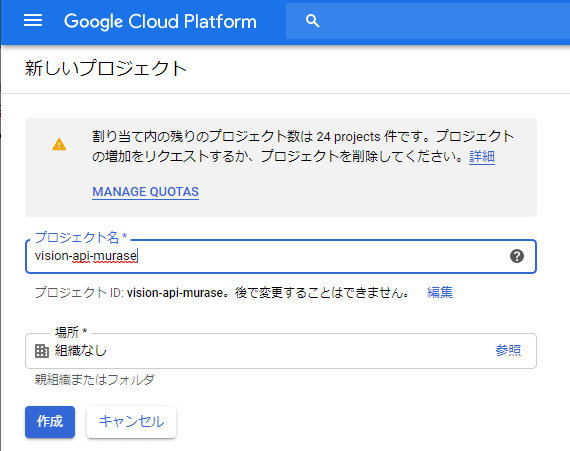
プロジェクト名を入力し作成ボタンをクリック
Cloud Vision APIの有効化

Cloud Vision APIの画面に移動して有効にするボタンをクリック
https://cloud.google.com/vision/docs/before-you-begin
APIキーを作成
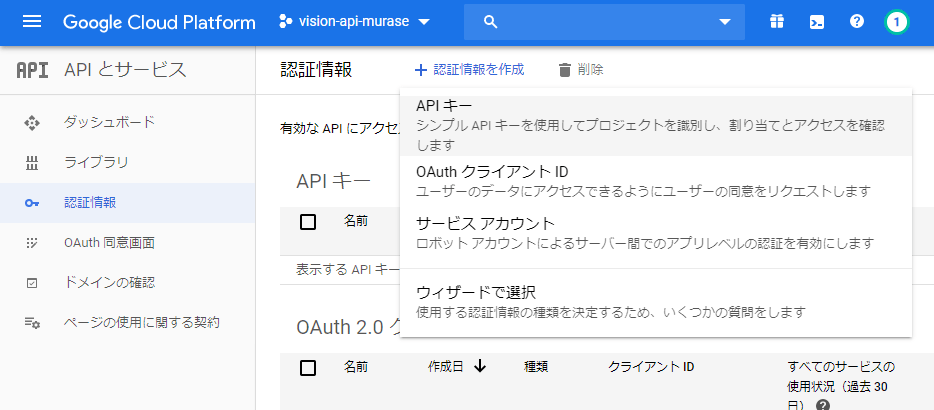
APIとサービスの画面に移動して認証情報を作成からAPIキーを選択してクリック
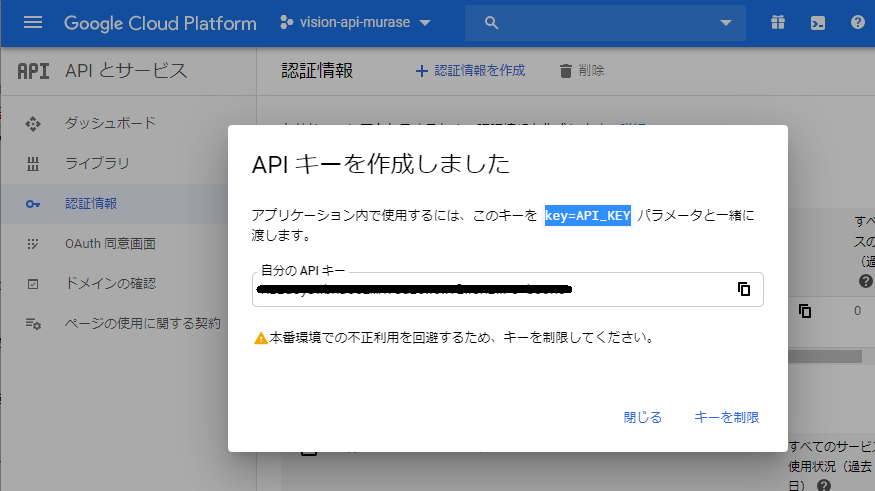
これでAPIキーが作成されました。
後ほどこのAPIキーを利用します。
事前準備はこれで完了です。
APIをコールしてみる
バリエーション豊かな機能がありますが、今回はLabel detection(ラベル検出)とText detection(光学式文字認識(OCR))を試してみます。
Label detection(ラベル検出)
まずは、Label detection。Futureのキャリア採用ページにある、つよつよエンジニア渋川の画像を利用してどのようなラベルが検出がされるか見てみましょう。今回の検証では改めて説明する必要はないと思いますがお手軽万能HTTPアクセスツールcURLを利用します。

keyの項目に先ほど取得したAPIキーを設定します。
curl -H 'Content-Type:application/json' -d '{"requests":[{"image":{"source":{"imageUri":"https://www.future.co.jp/recruit/common/img/member/er_popup_14_pc.jpg"}},"features":[{"type":"LABEL_DETECTION","maxResults":10,"model":"builtin/stable"}],"imageContext":{"languageHints":[]}}]}' https://vision.googleapis.com/v1/images:annotate?key=xxxxxxxxxxx |
リクエストのJSONを整形するとこんな感じ
{ |
レスポンスは以下の通りJSON形式で返却されます。
{ |
descriptionだけ抜き出して整理すると
| description | 日本語 |
|---|---|
| Sitting | 座っている |
| Arm | 腕 |
| Furniture | 家具 |
| White-collar worker | サラリーマン |
| Neck | 首 |
| Smile | ほほえみ |
| Textile | 織物 |
| Photography | 写真撮影 |
| Comfort | 快適さ |
| Couch | ソファー |
当たり前と言えば当たり前なのですが、画像から連想される説明が返却されてます。
サラリーマンが快適にソファーに座っていてほほえんでおり、首や腕、ソファーの繊維も映っていますね。
Text detection(光学式文字認識(OCR))
続いてText detection。渋川のスペックのレーダーチャートを解析してみましょう。

curl -H 'Content-Type:application/json' -d '{"requests":[{"image":{"source":{"imageUri":"https://www.future.co.jp/recruit/common/img/member/chart_14_pc.png"}},"features":[{"type":"TEXT_DETECTION"}]}]}' https://vision.googleapis.com/v1/images:annotate?key=xxxxxxxxxxx |
{ |
解析したテキストを整理すると
| text |
|---|
| コミュケーションカ |
| メイタリティ |
| 画性 |
| 5 |
| 3 |
| 4 |
| 5 |
| インラインスケート |
| メタ学習法オタク度 |
一部の文字はレーダーチャートの線と重なって別の文字として認識されてしまったり、読み込めなかったりしていますが(目的にもよりますが)十分な精度かと思います。
画像AIってすごいですね。
さいごに
機械学習と聞くと利用できるようにするのにトレーニングが必要で、ある種の車輪の再発明に近い作業が必要になり、コストと時間が掛かるものと思っていたのですが、事前トレーニング済みの機械学習モデルが安価にお手軽に利用できてとても便利ですね。様々な検出のタイプがあり、(当たり前ではありますが)適切なタイプを選ぶ必要があるのでそこさえ間違えなければ多種多様なニーズに応えられる素晴らしいAPIかと思います。Vision APIのすばらしさを実感できる検証となりました。
今回は検証目的でプロジェクトを作成したのでプロジェクトを削除して完了です。
GCP連載企画の9日目でした。次は前原さんのCloud Build を知ってみようです。