はじめに
こんにちは、TIGの関と申します。GCP連載2021第8弾です。
今回技術ブログに初参加させていただきます。テーマは、2021年2月24日に公開されたGKE Autopilotです。
この記事は、Kubernetesに触ったことがない方でもわかるように、最も簡単な構成で試してみました。
Kubernetesを触ったことがない方にもみていただけるとありがたく思います。
KubernetesとGKEのおさらい
まずは、GKEとKubernetesについて簡単に導入をしたいと思います。
Kubernetesとは?
Kubernetesはコンテナオーケストレーションのためのツールで、数百〜数千といった膨大な数のコンテナを管理、協調させることができます。
1つ以上のマシンを組み合わせたクラスタを構成し、それを単位とした分散システムとして動作します。論理的には”コントロールプレーン”と”ワーカーノード”という2つの構成要素からなります。
デプロイされたコンテナが動作するのはワーカーノード上です。そして、ワーカーノードは複数のマシンで構成できます。このため、ノードの構成を工夫すれば、比較的簡単にコンテナが動作しているマシンを分散させることができ、サービスとしての信頼性や実行効率を上げることができます。
地理的に分散させれば、データセンターレベル障害に対しても耐性を持たせることも可能です。
Kubernetesへのデプロイは、1つ以上のコンテナをひとまとめにしたPodと呼ばれる単位で行われます。
なので、「複数のコンテナで1つのサービスとして動作させたい」といったニーズにも答えることができます。
基本的に、Kubernetesにのせるサービスの開発者は、Podの構成は自分たちで考えることになります。
GKEとは?
GKE(Google Kubernetes Engine)とは、GoogleがGCPのプロダクトの1つとして提供しているKubernetesのマネージドサービスです。
これまでのGKEは上記で説明したコントロールプレーンについて、Googleが管理してくれていました。
利用者は、ワーカノードの構成を考えてクラスタを作成することで、コントロールプレーンの管理をすることなくKubernetesを利用できます。
GKE Autopilot

さて、ここからが本題です。
GKE Autopilotとは?
GKE AutopilotはGKEの新しい運用モードです。
これまでのGKEとの大きな違いは、Googleがワーカーノードの基本的な管理を担ってくれるということです。
これまでは、ワーカーノードの管理は基本的に利用者側で行う必要がありました。ワーカーノードの管理では次に示すような様々なことを考える必要があります。それなり運用コストがあり、Kubernetesの利点を最大限に得るには構成を十分に練る必要がありました。
- 用意するインスタンスのグレードは?
- どれくらいの数のインスタンスを用意するか?
- どのPodをどのノードにのせて、どのノードにのせるべきではないのか?
- インスタンスの利用効率を上げるための最適な構成は?
- 利用者が複数のチームに分かれている場合の利用ルールは?
Autopilotを使うことで、Googleがワーカーノードの管理、最適化を行ってくれるためこれらの考慮が不要になります。
利用者はインフラであるノードの構成をほとんど意識せずに「Podをどのように構成するか」という、より高レイヤーの問題に集中できるようになります。アプリ開発者としては嬉しいですね。
デプロイされたPodに割り当てるリソースは、Podの仕様と負荷をに基づきAutopilotが自動でプロビジョニング、スケーリングしてくれます。また、料金計算、SLAはPod単位で行われます。
その他の詳細情報については、公式ドキュメントが詳しいのでそちらを参照してください。
GKE Autopilotを触ってみる
公式でもチュートリアルがありますが、今回は初心者向けにもう少し簡単な構成を試してみようと思います。
Kuberntesを触ったことがない方でも、なんとなく雰囲気は掴めるはずです。
クラスタの作成
クラスタを作りましょう。Autopilotの設定はクラスタを作る際に行えます。
新機能ですし、ここではGUIでどのように設定できるのかをみていきましょう。
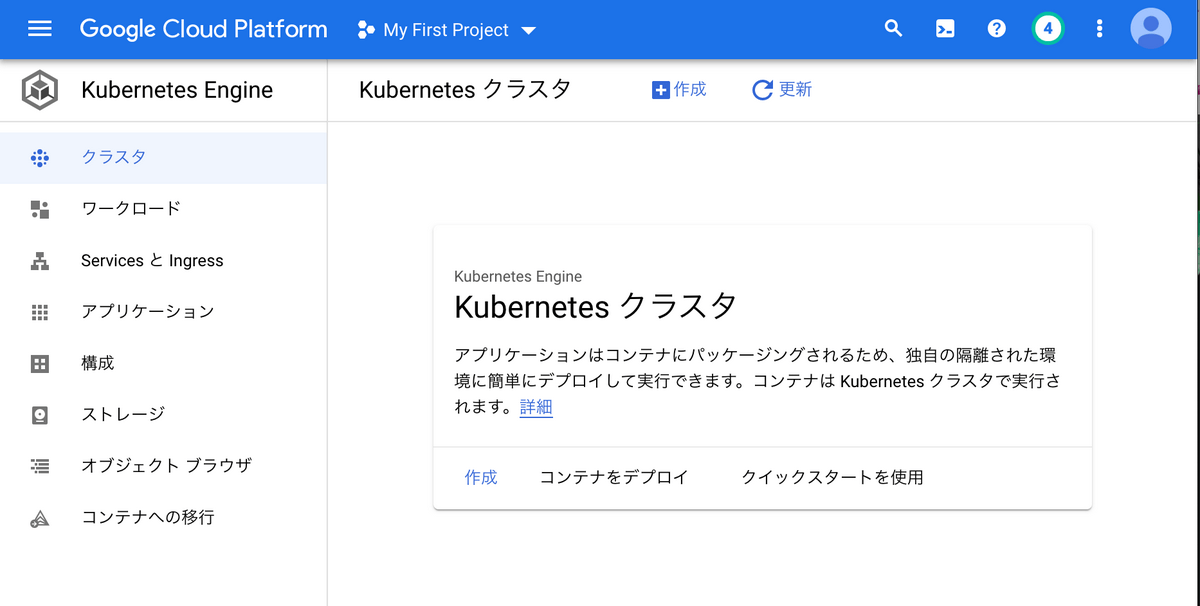 作成を押します。
ポップアップが出て、モードを選択できるようになっていました。
もちろん、Autopilotを選択します。
作成を押します。
ポップアップが出て、モードを選択できるようになっていました。
もちろん、Autopilotを選択します。
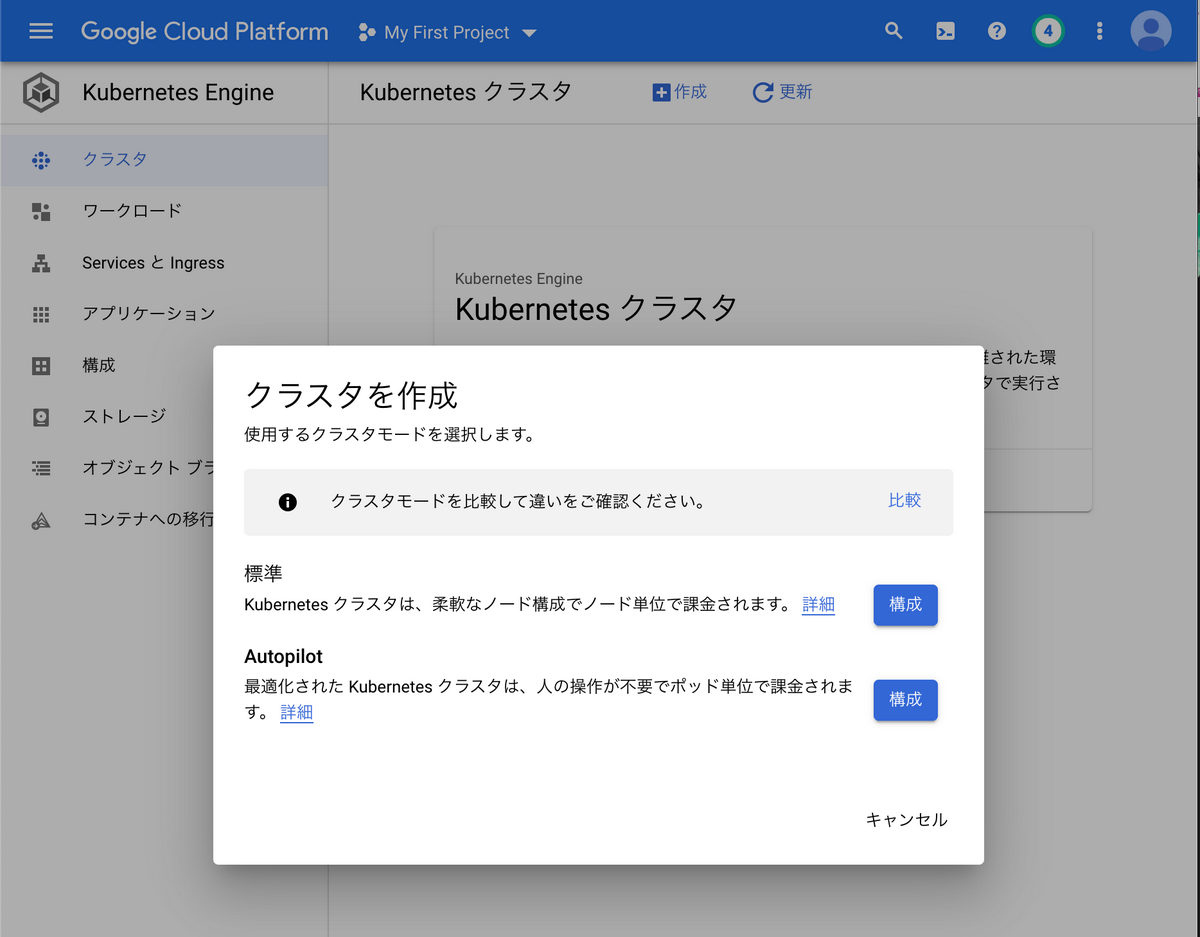
ネットワーキングオプションなど、選択項目もありますが、今回はひとまず触るのが目的なため、デフォルトのまま変更しないことにします。
画面下方の”コマンドライン”のリンクを押すとgcloudコマンドを表示可能です。記録を残したりするのに使えそう。
作成を押します。クラスタの作成が始まります。
5min以上待つ必要があります。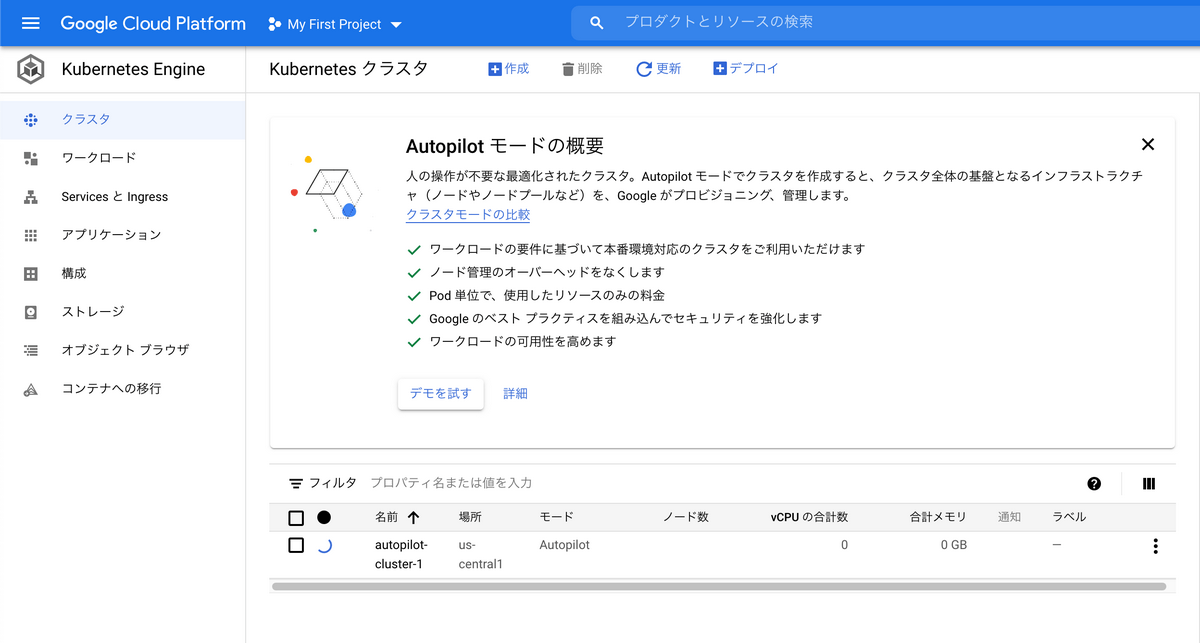
gcloudコマンドを導入する
公式ドキュメントに沿って導入しましょう。
この記事ではクラスタの情報を取得することだけに使うため、出番少なめです。
kubectlコマンドを導入する
macでHomebrewを使っているならコマンド一発です。
brew install kubectl |
Kubernetes公式のインストール方法はこちら
kubectlにクラスタの情報を読み込ませる
Kubernetesの操作はkubectlコマンドで行います。
そのためには、kubectlコマンドにどのクラスタを対象にするのか教えてあげる必要があります。
まずは、gcloudコマンドでログインします。gcloud auth loginだとエラーが出たので、その表示に従い下記のコマンドを実行。
画面の指示に従いログイン完了まで行います。
gcloud auth login --no-launch-browser |
GCPのコンソール に戻ります。
こちらの”接続”を選択します。
コマンドが表示されるので、それをターミナルに貼り付けて実行します。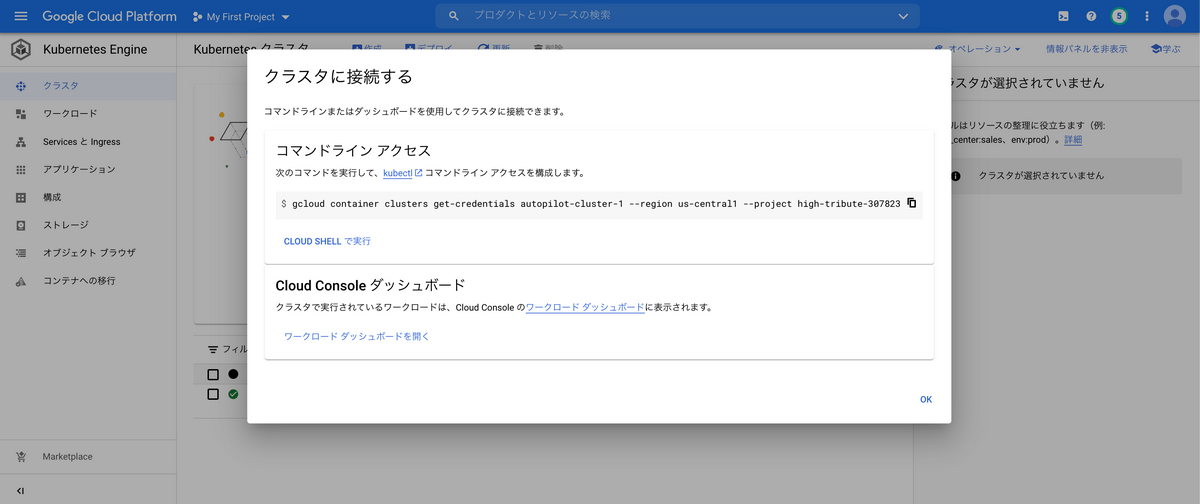
今回の場合、こんな感じ。実行すると、kubectlコマンドの対象クラスタがこのクラスタに切り替わってくれます。
gcloud container clusters get-credentials autopilot-cluster-1 --region us-central1 --project high-tribute-307823 |
クラスタの情報をみてみる
ひとまず、nodeの情報でもみてみましょう。
node1つが1つのVMであり、これまでのGKEだとGCEインスタンスを作成してノードとして利用していました。
nodeの情報をみるにはkubectl get nodeコマンドを使います。-o wideすると詳細情報含めて表示してくれます。
kubectl get node -o wide |
実行結果
Autopilotでは利用者側で管理することはないですが、nodeの情報を取得するのは通常通りできるようです。
NAME STATUS ROLES AGE VERSION INTERNAL-IP EXTERNAL-IP OS-IMAGE KERNEL-VERSION CONTAINER-RUNTIME |
Depoloymentを作成してみる
さて、ようやくですが、Pod(コンテナ)をデプロイしてみましょう。
今回はnginxを用いたPodをデプロイしてみます。
Kubernetesを実運用する際には、マニフェストファイルと呼ばれるファイルにリソースの情報を書き、それをもとにkubectlコマンドでクラスタにリソースを作成する流れになります。実運用に沿った形で、マニフェストを作成して、それを適用していきましょう。
まずはマニフェストファイルの作成です。自身の内部にデータを保持しないステートレスアプリケーションの場合、Deploymentリソースを使います。
下記のファイルを作成し、deployment.yamlというファイル名で保存します。
こちらはKubernetesの公式から拝借しています。
apiVersion: apps/v1 |
軽く説明をしておきます。.spec.template.specに書かれているのがPodの仕様です。nginxのコンテナが1つだけの構成ですね。80番ポートでlistenしています。containersと書かれているのは、1つのPodに複数のコンテナを含めることができるからです。同一Podのコンテナはlocalhost内で通信できます。今回は特に使わないですがPod内で通信する時に必要なマメ知識です。
.spec.replicasの”3”は、「Podを3つデプロイする」という意味です。Podの冗長性を持たせるために通常は複数個にします。負荷分散や対障害性を持たせることができます。
次に、マニフェストファイルをもとに、Kubernetesリソースを作成します。kubectl applyコマンドを使います。kubectl createコマンドもありますが、マニフェストを更新した時などで想定外の挙動をすることがあるのでこちらが推奨です。
# -f {path} で対象のマニフェストを指定する。 |
さて、Podが起動していることを確認しましょう。
GCPコンソールで、サイドメニューのワークロードを選択するとみれます。
エラーになっていますね、、、
あれこれ試しているうちに、ワーカーノードのリソースが小さくなってしまったのかもしれません。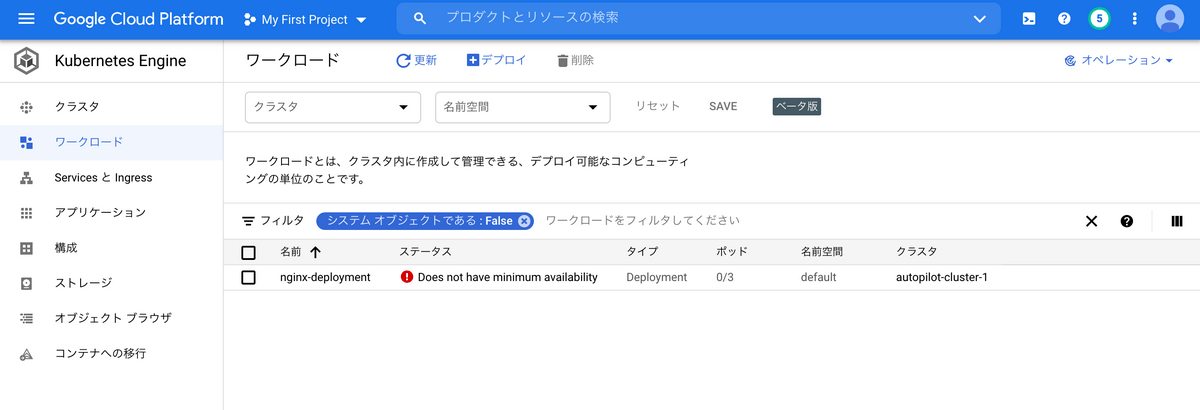
しばらく待ってみましょう。
しばらくして、「nodeどうなっているんだろう?」という疑問が湧いてきました。
おもむろにkubectl get nodeします。なんと、nodeが増えていました。
自動でリソースを拡充してくれているようです。これは期待できる。。。
NAME STATUS ROLES AGE VERSION INTERNAL-IP EXTERNAL-IP OS-IMAGE KERNEL-VERSION CONTAINER-RUNTIME |
少し待ったところ、、、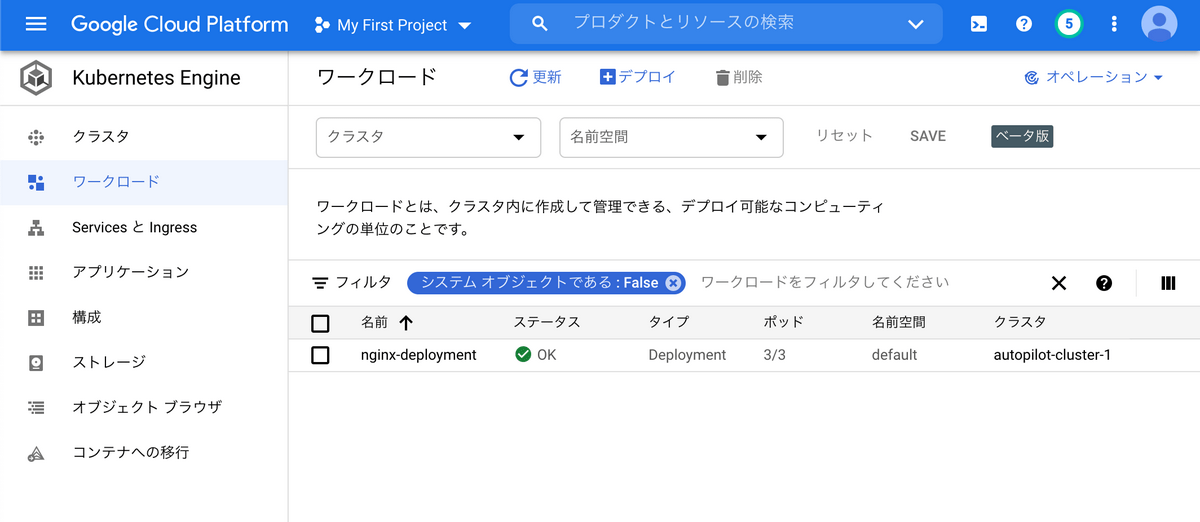
できました!!!リソース作成成功です!!!
ちなみに、kubectl get podコマンドでもPodの情報をみることができます。
kubectl get pod |
実行結果
NAME READY STATUS RESTARTS AGE |
LoadBalancer Serviceを作成してみる。
Podを作っただけだといまいち実感が沸かないという方のために、外部からアクセスできるようにしてみます。
LoadBalancer Serviceリソースを作ることで、GCPのロードバランサーを構成し、それ経由で外部からのアクセスを受け付けることができます。
まずはマニフェストファイルを作成します。service.yamlという名前で保存します。
apiVersion: v1 |
こちらも軽く説明しておきます。.spec.portsでポートの設定をします。targetPortがコンテナがlistenしているポート番号、portはロードバランサがlistenするポート番号です。.spec.selectorでどのPodに対してルーティングするかを指定します。deployment.yamlで指定したlabelのapp: nginxを指定しています。
次に、マニフェストファイルをもとに、kubectlコマンドでリソースを作成します。
kubectl apply -f service.yaml |
作成されたサービスの情報をみてみましょう。
kubectl get service |
実行結果
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE |
EXTERNAL-IPと書かれているのが、LoadBalancerのIPです。
LoadBalancer Serviceを作成すると、コントロールプレーンでそれを認識し、GCPのロードバランサを自動で作成してくれます。これはAutopilot限定の機能ではなく、これまでも可能だった機能です。
ロードバランサができていることをGCPコンソールで確認してみましょう。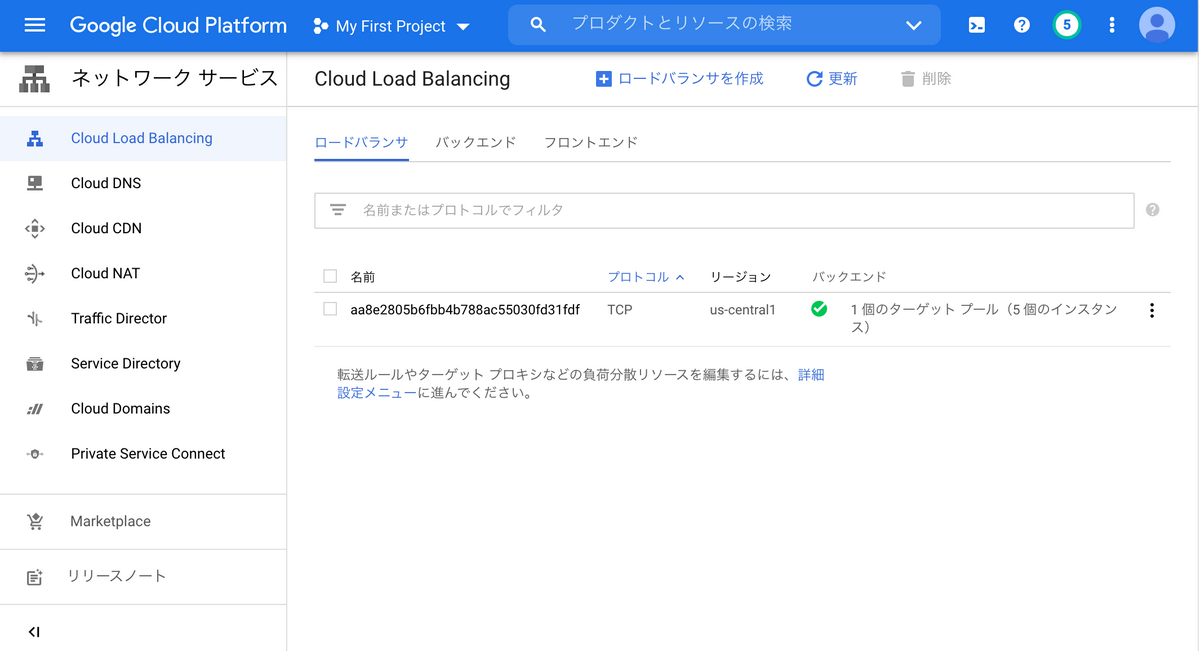
いかにも自動生成な名前でロードバランサが作成されているのがわかります。
さて、先ほどのEXTERNAL-IPにブラウザからアクセスしてみましょう。
もちろん、インターネットオーバーでのアクセスです。
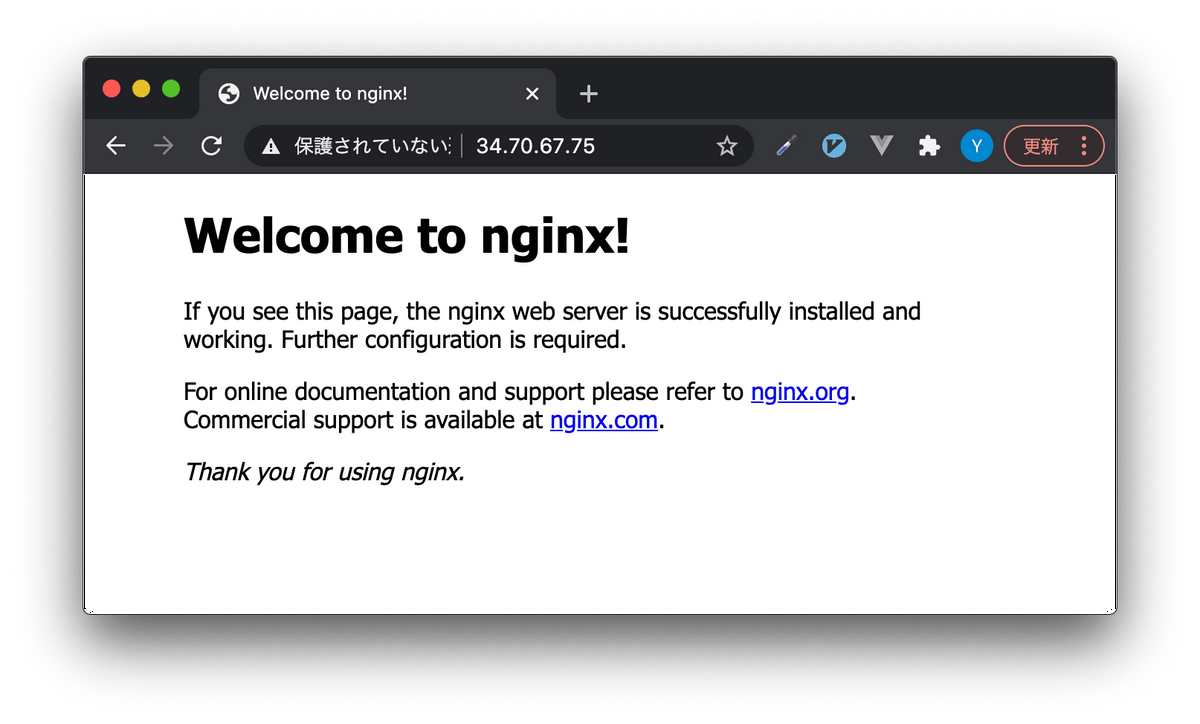
できました!!!
リソースの削除
ここからはお片付けです。
次のようにして、kubectl deleteコマンドで削除できます。特に、LoadBalancer Serviceの削除をサボると自動生成されたLoadBalancerが削除されないままになるので注意が必要です。
kubectl delete -f deployment.yaml |
クラスタを破棄します
クラスタの再構成がなされるので、完了まで待ちましょう。
次のように、削除を選択し、しばらく待てばクラスタが削除できます。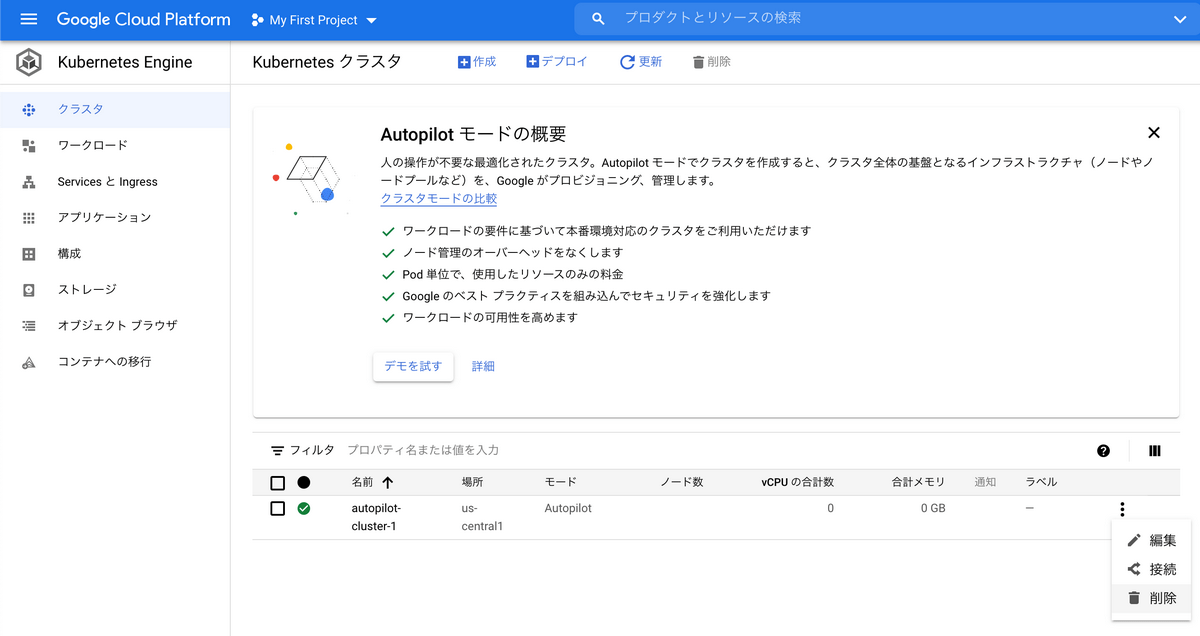
おまけ
これ以外にも、作成するPodの数を増やしてみたり、公式チュートリアルをやったり、いろいろ触ってみました。
リソースが足りなくなると、新しくNodeを確保して、ちょっと待つとPodがスケジューリングされる様子をみることができ、まさしく”Autopilot”という名にふさわしい挙動でした。
感想
公式の説明通り、ノードの設定を特にせずとも使え、一度作ったあとの使い方には大きな差がなく普通に使いやすいと感じました。
シンプルに、ワーカーノードのことを一切考えなくて良くなるのは魅力です。
インフラの最適化を自動でやってくれるので、リソースとしてのノードの過不足を気にせずにマニフェストに集中できるので、ワーカーノードの運用の難しさやそれに伴う導入障壁を感じているのであれば、恩恵を受けられると思います。
さて、明日は越島さんのAnthosの話についていくための最低限の知識をまとめてみたです。お楽しみに!