こんにちは! SAIGの金子です。
普段はフューチャーのAIグループで開発を行っている他、nadareというハンドルネームでデータ分析コンペティションに参加しています。
自然言語処理でよく使われるWord2VecやTransformerをログデータやテーブルデータの予測・分析に活用するためのオレオレベースラインを紹介します。
対象読者
- 既にWord2VecやTransformerについて知識があり、その上自身で改造を行いたい人
- レコメンド・検索技術に興味のある人
はじめに
昨今、ECサイトの閲覧・購入履歴の分析やワクチンの開発といった自然言語以外の分野でも、それぞれの商品やアミノ酸を単語とみなして埋め込み表現を獲得するWord2VecやBERTのような自然言語処理由来の技術が活用されています。
これらの分析にはgensimのようなよく整備されたライブラリが活用されますが、それらは自然言語処理を対象に作られているため以下のようにデータの特徴をつかみきれないことがあります。
- 各トークンのidしか与えられないため、トークンに結びついた情報を考慮できない
- 例: 商品の購入・閲覧履歴について、商品のカテゴリ情報や購入時のセール情報、レビューや閲覧時間のようなユーザーからのフィードバックを入れられない
- BERTを用いようとした場合、自然言語と異なりトークン間の双方向の順序情報を考慮する必要のないケースがある
- 例: 実店舗のレシートを分析する際、商品の順番は店員のスキャンした順番以上の情報を持たない
- Word2Vecを用いようとした場合、各トークン同士の相互作用を考慮できない。
そこで、テーブルデータの為にWord2VecとBERTの中間くらいの拡張性の高いベースラインを作成しました。コードはTensorFlowで実装していて、Kaggleのriiidコンペのデータをもとにnotebookで用意しているため、誰でも簡単に追実験が可能です。
riiidコンペについて
riiidコンペはTOEICの問題集のアプリを使うユーザーが過去に解いた問題から、次に解く問題についての正解率を予測するコンペです。問題は13000問、ユーザーは40万人分のデータがあり、それぞれ問題とユーザーについて適切に特徴量を作成する必要がありました。このコンペではWord2VecやTransformerを用いてそれぞれのIDについての埋め込み表現を学習する解法が多く存在しました。
今回のコードはその時の私のモデルをブラッシュアップしたものになります。
事前学習タスクについて
今回はこのriiidコンペのデータから教師無しでユーザーや問題の特徴を作成するために次のようなタスクを設定しました。
- ユーザーが過去に解いたN問の情報から、次に解く問題のidを予測する。
これはレコメンドのタスクであるため、過去にアドベントカレンダーで紹介したTensorFlow Recommendersの実装を参考にしてモデルを構築しました。
実装
recommender with transformer for embedding
コード解説
モデル概要
TensorFlow Recommendersのretrievalタスクを参考に、ユーザーの履歴から作成したクエリベクトル(X)と問題の情報から作成したアイテムベクトル(y)の内積によって両者の親和性を表現するモデルを作成しました。
訓練時はバッチサイズNに対してNxNの対角行列の正解ラベルを作成し、同じレコードから作成されたクエリとアイテムの組み合わせを1、それ以外を0としてcategorical crossentropyを最小化します。(正例:負例=1:N-1になるようネガティブサンプリングをしているという見方もできます。)予測時は推薦対象のアイテムベクトルを全て事前計算しておき、クエリベクトルとアイテムベクトルの内積を全計算して推薦対象のアイテムをリランキングします。
前処理
ユーザーがどの問題を解いてどの回答をしたかを配列で管理するための処理をしています。
content_idが問題番号に対応していて、それぞれ最大で4つの選択肢を持つため、
Sampler
訓練データを作成するクラスです。
今回はユーザーの履歴からランダムでこれまでに解いた問題(X)と次に解く問題(y)を返します。データはユーザーによってtrainとtestに分割し、trainではユーザーごとの履歴の長さに応じた比率で、testではすべてのユーザーから1回ずつサンプリングして学習・評価を行います。
Tokenizer
受け取ったchoice_idを指定の次元のembeddingに変換するクラスです。
今回の例では問題のidしか入れていませんが、このTokenizerの部分を作りこむことで様々なコンテキストを入れることができます。
Encoder
self-attentionを行うクラスです。
入力に対しlstmとself-attentionを交互に繰り返します。このself-attentionを計算する際に、自身と過去の情報を参照しないようにmaskを作っています。また、今回はqueryはノルムで正規化、keyとvalueは恒等関数で変換しています。
TopModel
今回の次に解く問題を予測するタスクの為のクラスです。
この部分を分離しておくことで、今回学習させた重みをTopModelの部分を挿げ替えることで転移学習・フ.0ァインチューニングに用いることができます。
Model
上記のtokenizer, Encoder, TopModelをまとめるためのクラスです。
ここにまとめておくことで、学習時にapply_gradientが楽にできるようになります。また、今回はbatch sizeをN倍すると予測の出力が
結果
事前学習
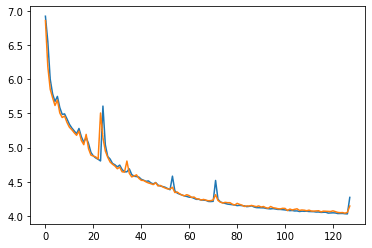
データをユーザーのIDによって訓練:テスト=9:1に分けて学習した際のcategorical crossentropyが以下の通りです。
Tesla T4インスタンスで128epochの学習に1hかかりました。
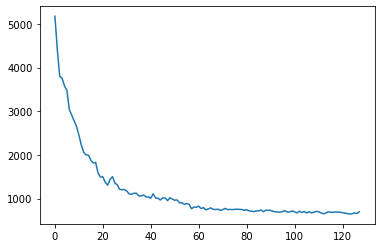
次に解く問題について予測しその問題が何番目に出現したかについて計測したところ、64epoch目では訓練中に存在しないユーザーに対し13000問の問題からおおよそ700番目くらいの精度で推薦できました。
得られたembeddingの可視化です。まずは問題のベクトルの可視化ですが、umapで次元圧縮し可視化したところTOEICのpartごとに綺麗に分離していることが分かります。
notebookには適当に問題番号を選び、その問題を解くときのユーザーのembeddingをその問題に正解したかの二色で色付けしてplotしています。ただ、あまりうまく分離はできていないようです。
得られたembeddingの図についてはnotebookを参考にしてください。
ファインチューニング
得られたembeddingやmodelのweightを固定化した上で、実際にriiidコンペのタスクである次に与えられた問題に対して正解できたかを予測するタスクの学習を行いました。Word2Vecとの比較を行ったところ、今回のモデルではWord2Vecの方が事前学習した重みとしては良い結果を出しました。
応用例
今回はユーザーの問題を解いた履歴という入手しやすいimplicitなデータを用いて推薦/事前学習を行いました。
今回のモデルではuser_idに関する情報を変数に用いていないため、訓練データに存在しないユーザーについても予測が可能です。また、今回は問題のidのみを考慮しましたが、カテゴリ、自然言語、画像情報などのデータの拡張を意識しているため、作りこめば更なる精度が見込めると思います。これらは推薦タスクにおけるユーザー/アイテムのコールドスタート問題に効果的に対応できます。
得られたembeddingやTransformerの重みは他のモデルの学習にファインチューニングして活用できます。特に、Encoderの出力の平均をとったものはユーザーの履歴間の時系列や相互作用を考慮しているため、個々のembeddingの平均をとるよりも効果的になると予想できます。(今回はWord2Vecに負けてしまいましたが…)
今回のモデルは時系列情報を考慮した上でlstmやmaskを作成していましたが、順序情報が不要な場合はSamplerやEncoderを改造して余分な計算を省くことができます。実際に今回のベースラインをatmaCup#10のようなコンペで無理やり使った際は、コードの実装は二時間くらいで容易にできました。
おわりに
今回のベースライン作成にはデータ分析コンペでの戦いやライバルの皆さんとの議論の経験が活きました。これからもデータ分析コンペなどを通じて技術を磨き、還元していければと思います。