はじめに
フューチャー棚井龍之介です。
本ブログでは、サーバレス連載の第1日目として、「Kinesis+Lambda構成」でのメトリクス監視について取り上げます。
データ流入量が徐々に増加する見込みのとき、各リソースのどのメトリクスを重点チェックすべきか。また、メトリクスがリソースの制限にぶつかった場合やアラート検知された場合にどのような対応アクションを取るべきか。KinesisやLambdaのリソース監視設定から得た知見を、本ブログに整理しました。
そもそもの「サーバレスって、何が便利なんだっけ?」から整理したい方は、AWS公式のグラレコ解説記事をご覧ください。
今回のサーバレス構成
「Amazon Kinesis Data Streamでデータを受け、AWS Lambdaがコンシュームする構成」を本ブログで想定する環境とします。
AWS本家の形で考えるサーバレス設計でも「流入データの連続処理」として取り上げられおり、サーバレスという用語に馴染みのないエンジニアにもよく知られたデータフロー構成ではないでしょうか。
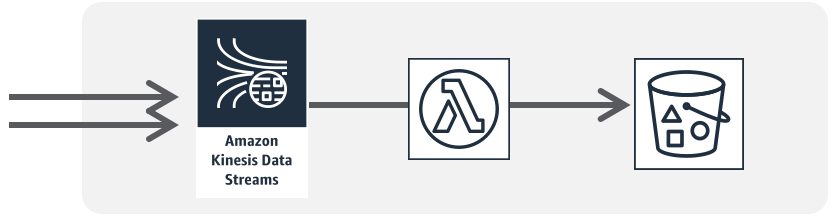
大量データの受信にはKinesisを使い、受信データのコンピュートはLambdaでやりくりする。この構成はシンプルで分かりやすく、かつ、各リソースをスケールしやすいため、データ連携やデータ保存などのあらゆるケースに応用が効く、ベーシックなインフラ構成だと思います。
どちらもフルマネージドサービスなため、管理運用コストはほとんとかからないのですが、こと「データ流入量がどんどん増える場合」にはその限りではありません。後続で説明するCloudWatchのメトリクス監視を設定し、通知やアラートを受けた場合にはリソースの拡張・スケーリング対応が必要となります。
リソース監視の基本
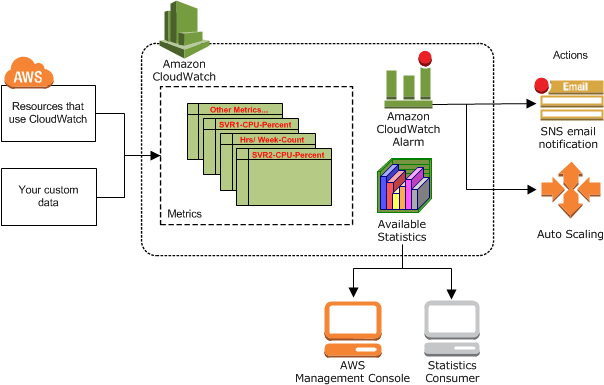
AWSリソースの監視には、CloudWatchを活用します。
Amazon CloudWatchを利用することにより、AWSリソースサービスの利用状況や、各サービスの出力する情報をモニタリングできます。
各リソースの出力する情報は「メトリクス(Metrics)」としてAWSサービス内に集約されています。CloudWatchに追加設定を入れることで「このメトリクスが急上昇した場合には、社員にメールで通知して」や「あのメトリクスが80%を上回ったら、自動でリソースを増強して」などを登録し、緊急時のシステム対応に備えることができます。
EC2やRDSの運用経験があれば、メトリクス監視は「当たり前に実施すべき」と言われても違和感は無いと思います。
しかし、システムの運用経験が「エンジニアになってこのかた、サーバレスのみ」だと、「フルマネージドサービスなのだから、メトリクスの監視設定はいらないよね。エラー監視は当然だとしても、リソース増強は全て自動でしょ」と勘違いしてしまうケースが見受けられます。
サーバレス構成だとしてもメトリクス監視は必須であり、それを怠ってしまうと「知らないうちに、システムの動きがおかしくなっている」状況になります。
筆者自身の経験では、Lambdaの代表的なメトリクス IteratorAge の監視が漏れたことにより「リアルタイム処理と謳っているが、実際のデータ連携には〇〇時間要する」というケースがありました。サービスの非機能要件を担保するためにも、メトリクス監視は徹底すべきです。
監視メトリクス
Kinesis+Lambda構成の場合、最低でも以下のメトリクスには監視・アラート通知設定を入れましょう。
| # | AWSサービス名 | メトリクス名 | 説明 |
|— |—————————- |———————————— |—————————————————————————|
| 1 | AWS Lambda | Errors | 関数エラーが発生した呼び出しの数 |
| 2 | AWS Lambda | Throttling | スロットリングされた呼び出しのリクエスト数 |
| 3 | AWS Lambda | Duration | 関数コードがイベントの処理に費やす時間 |
| 4 | AWS Lambda | ConcurrentExecutions | イベントを処理している関数インスタンスの数 |
| 5 | AWS Lambda | IteratorAge | あるデータをKinesisが受信してから、そのデータをLambdaに送信するまでの時間 |
| 6 | Amazon Kinesis Date Stream | ReadProvisionedThroughputExceeded | データ取得要求が、Kinesisのスループット上限に達して調整が行われた |
| 7 | Amazon Kinesis Date Stream | WriteProvisionedThroughputExceeded | データ書き込みが、Kinesisのスループット上限に達して失敗した |
| 8 | Amazon Kinesis Date Stream | GetRecords.IteratorAgeMilliseconds | Kinesisにレコードが滞在した時間 |
| 9 | Amazon Kinesis Date Stream | GetRecords.Success | Kinesisから正しく取得されたレコードの数 |
これらのメトリクス監視を入れることで、Kinesis, Lambdaサーバレスリソースの「フルマネージドではない部分」までにも目が行き届くようになります。
アラート通知が届いたら
メトリクス監視を入れることで、リソースの負荷上昇をアラートで検知できるようになります。
基本的には「ボトルネックの特定 → 解決/緩和アクションの実施 → 継続監視 → アラートの未再発を確認し対応クローズ or 原因の再調査」の対応フローとなります。
エラーが発生した場合や、データが全く届かないケースであれば、原因の切り分けは容易だと思います。
しかし、「処理遅延」のような処理時間が徐々に長くなっているケースでは、関数内部ロジックの修正やリソースの増強が必要になります。
代表的なアクションとしては
- Lambda
- アプリケーションの内部ロジックを見直す
- 別リソースとの接続時間を調べる
- 詳細調査のためにログ出力を追加する
- メモリを増強する
- 同時実行数の上限緩和を申請する
- 並列化系数を増やす
- アプリケーションの内部ロジックを見直す
- Kinesis
- シャード数を増やす
- データ保存期間を延長する
などが考えられます。
いずれにしても「ボトルネックの特定」が最優先であり、原因に対してピンポイントで対処すべきです。
アラート通知時に慌てないためにも、CloudWatchのコンソール画面に日頃から慣れておくことも大事です。
おわりに
サーバレス構成でのメトリクス監視について、入門的な内容として、Kinesis+Lambda構成にフォーカスして説明しました。フルマネージドサービスは基本的に「ほったらかし」でも大きな問題は発生しませんが、徐々に負荷が高まるケースでは「気づいたら、大変なことになっていた」という笑えない状況が発生しがちです。
面倒な作業はAWS側に任せられるとしても、最終的なサービス稼働監視は「利用者側の責務」と意識して、メトリクスの監視設定は必ず入れるようにしましょう。
サーバレス連載の第1日目でした。次は真野さんの「15分の壁を超えるLambda分散実行術」です
参照記事
- サーバーレスって何が便利なの ? AWS でサーバーレスを構築するためのサービスをグラレコで解説
- 形で考えるサーバーレス設計
- モニタリング (monitoring)
- Amazon CloudWatch の仕組み
- サーバーレスアプリケーションレンズ - AWS Well-Architected フレームワーク
- AWS Lambda 関数メトリクスの使用
- Amazon CloudWatch を使用した Amazon Kinesis Data Streams サービスのモニタリング
- Kinesis, Lambdaのボトルネック解析時の考慮点
- Kinesis Data Streams で IteratorAgeMilliseconds の値が増え続けるのはなぜですか?