はじめに
初めまして、2022年中途入社でTIG所属の岸下です。
本記事はFlutter連載の5記事目になり、FlutterとTensorFlow Liteを使ったモバイル画像識別について執筆させて頂きます。
TensorFlow Liteとは
近年ではご存じの方も多くなってきたかと思いますが、TensorFlowはGoogle社が開発を行っているディープラーニングを行うためのフレームワークの一種です。
TensorFlowを使えば、
- 画像識別
- 物体検出
- 姿勢推定
- …
などのAI処理を手軽に行うことができます。
ただ、TensorFlowそのままだと計算コストが非常に高く、リアルタイムで推論を行うにはGPUが必須となってきます。そこで、TensorFlowにはTensorFlow Lite(TFLite)と呼ばれるエッジデバイス・モバイル向けのフレームワークが公開されております。
TFLiteはCPU上で演算を行うことに特化しており、スマホなどのモバイル端末上でもほぼリアルタイム(CPU次第)でAI処理を行うことが可能となります。
なぜTFLiteだとCPU上で演算可能なのか
主にTFLiteでは量子化されたAIモデルを推論に用います。
AIモデルの中身では入力された特徴量に対して重み付け演算して、その結果を伝搬するためのネットワークが構築されております。この演算の際に本来であれば32bitの浮動小数点精度(float32)が用いられるのですが、それを8bitまで精度を落とすことで高速化を狙います。
これをint8量子化と呼び、TFLiteには他にもfloat16量子化や重み量子化などのオプションが存在します。簡単に言えば予測精度を若干犠牲にして、推論速度を高めようというのがモデルの量子化になります(もちろん、量子化によって精度がガタ落ちするパターンもあります)。
詳しくは、TensorFlow Lite 8ビット量子化の仕様を読まれるとわかりやすいと思います。
FlutterとTFLiteを用いてホットドッグ識別器を作ってみる
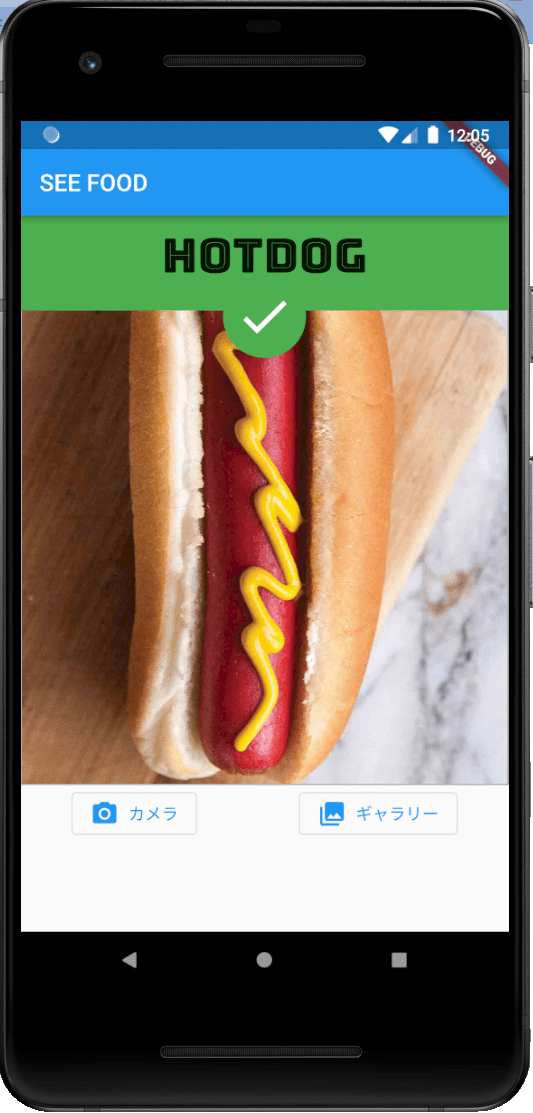
前置きはここまでにして、早速本題へ入っていきましょう!
元ネタは海外ドラマのシリコンバレーです。
ぜひドラマも見てみてください。
モデルの準備
モデルはPythonを使って学習し、量子化しました。
モデルの学習は転移学習と微調整を参考に学習しています。
モデルの量子化はトレーニング後の量子化を参考にpbモデルから.tfliteへint8量子化を行っています。
assetsファイルの準備
Flutterのプロジェクトファイルにassetsディレクトリを作って、tfliteファイルを入れましょう。pubspec.yamlの変更も忘れずに。
name: tflite_img_recognition |
使用ライブラリ
- tflite_flutter^0.9.0
- TFLiteの演算処理を担ってくれます。
- tflite_flutter_helper^0.3.1
- TFLiteモデルに入力するための画像前処理など便利ツール詰め合わせです。
- image_picker^0.8.4+10
- カメラやフォトライブラリから画像を取得するために使います。
- google_fonts^2.3.1
- UIにそれっぽいフォントが欲しかったので使いました。
tflite_flutterの注意点
tflite_flutterを使用する前にTFliteの動的ライブラリをワークフォルダにインストールする必要があります。
Initial setup : Add dynamic libraries to your app
使用PCがLinuxであればinstall.sh、Windowsであればinstall.batを↑のpub.devページからダウンロードして、Flutterのプロジェクトフォルダに置いてください。置いた後、コマンドラインからsh install.shやinsatall.batを入力してファイルの実行を行ってください。あとはよしなにやってくれます。
画像識別クラス(classifier.dart)
画像を識別するためのClassifierクラスを作っていきます。
重要そうな部分だけ解説を入れていきます。
全体コードはこちらから参考にしてください。
変数の宣言
// 推論エンジン |
まずは推論に使われる変数の宣言を行っています。
中身はコード内のコメントの通りで、注意する点としては
- コンストラクタ内で後から変数の初期化を行うため
lateを指定 - 出力結果の格納用に
TensorBufferを用意する必要
などがあります。
他にもNormalizeOpは正規化オプションで、入力画像の正規化に使われます。
ちなみにNormalizeOpに入力する値はNormalizeOp(mean, stddev)になっています。平均と標準偏差ですね。
コンストラクタ、モデルのロード
/* コンストラクタ */ |
コンストラクタ内ではmodelName、labelName、labelsLengthを受け取り、変数の初期化を行います。
また、モデルのロードを行います。
loadModelでは.tflite形式の重みファイルをロードします。ロードを待つために非同期のawaitが指定されていますね。
また、ロードしたモデルから_inputShapeなどの入力・出力サイズとデータの型(intやfloatなど)の情報を取得します。
今回は入力画像サイズが160×160で、int8量子化されたモデルを使うので型はuint8になります。
また、出力を格納する_outputBufferもここで出力サイズと型を指定します。
画像の前処理と推論
/* 画像の前処理 */ |
ここでは画像の前処理と推論処理を行います。
AIモデルの中では、画像の色合いや配色パターンの特徴から「この画像はホットドッグ」、もしくは「そうではない」の判断を下します。
そこで特徴を際立たせたり、無意味な特徴をかき消したりするなどの前処理を行うことによって推論の精度を高めることができます。
また、入力できる画像のサイズが決まっていたり、TensorImageの型で画像を入力する必要があったりするので、入力画像サイズを変更したり、Image型をTensorImage型でキャストしたりする必要があります。そのための前処理となります。前処理が行われた画像は推論エンジンへ入力されて、_outputBufferへ結果が入力されます。
_outputBufferへは画像がホットドッグかどうかの確率が0~1(1だったらホットドッグで、0だったらホットドッグではない)の値で入力されています。
推論エンジンをDestroyする場合は、close()でいけます。
画面の構築と画像の取得(main.dart, index_scree.dart, image_input.dart)
画像を取得するためのimage_input.dartと画面を作っていきます。
重要そうな部分だけ解説を入れていきます。
画面の全体コードはこちらから参考にしてください。
画像の取得とinitState
// 取得した画像ファイル |
画像を取得するためのImagePickerや推論を行うためのClassiferを事前に変数として定義しておきます。
また、image_pickerを使って画像の取得を行います。
カメラで画像を撮るのも、ギャラリーから取得するのもsourceが違うだけで処理は同じです。setStateで_storedImageにFileを代入し、この段階でpredict()を呼び出して推論を行います。predict()は後ほど説明します。
また、initState()内でClassifierのコンストラクタを呼び出し、初期化します。
推論
/* 推論処理 */ |
ここでは、入力された画像に対して_classifierを用いて推論を行います。
入力画像はImage型なので、デコードを行います。ここで_storedImageはnull許容型として定義しているため、!をつけることでnullではないことを明記します。推論結果からはconfidence(確信度)を取り出します。
今回の場合だと、0.5をしきい値としてホットドッグかそうではないかを判断しています。学習に使った画像数が数十枚なので、かなりガバガバです笑。
ホットドッグであれば、isPredictedをtrueにして、resultTextにはHotdogを入れます。そうでなければ逆となります。
これでインタラクティブに推論できるように構築できました。レイアウトは適当なので、色々変えてみてもいいかもしれません。
推論してみる
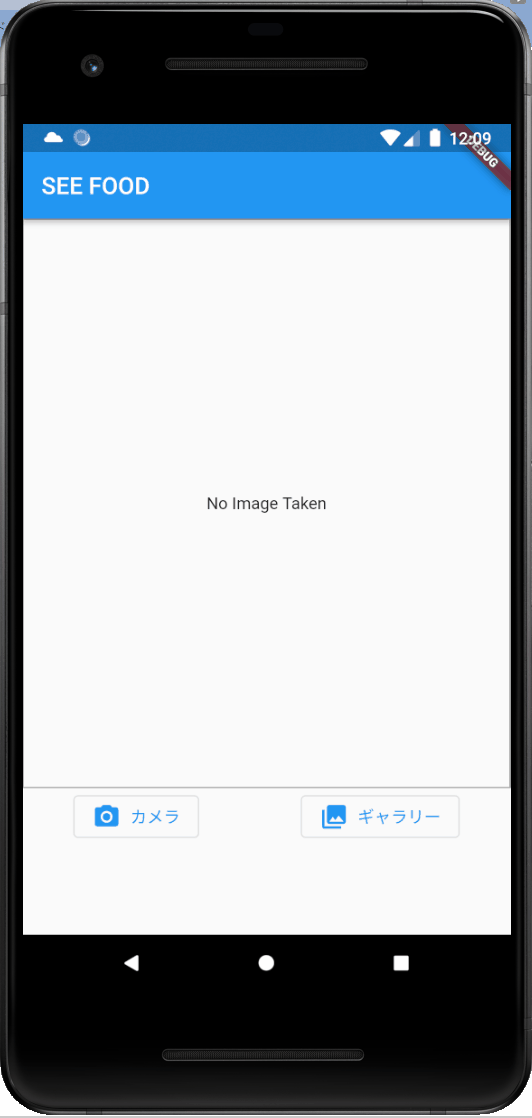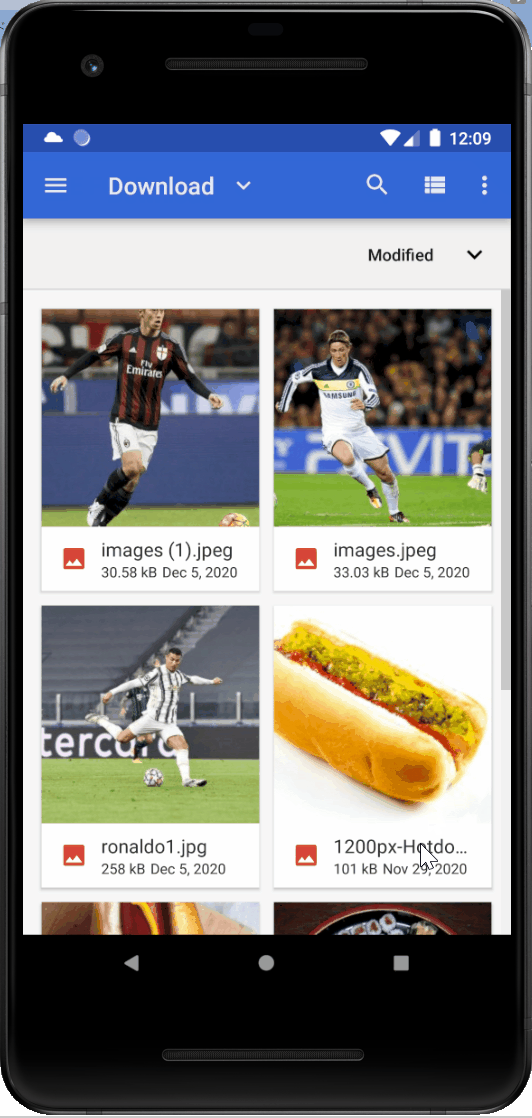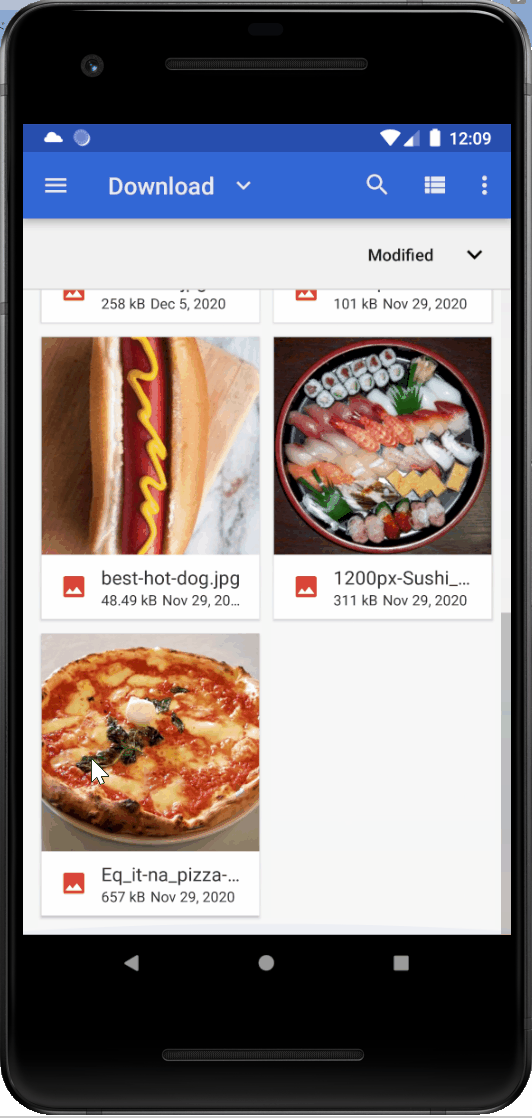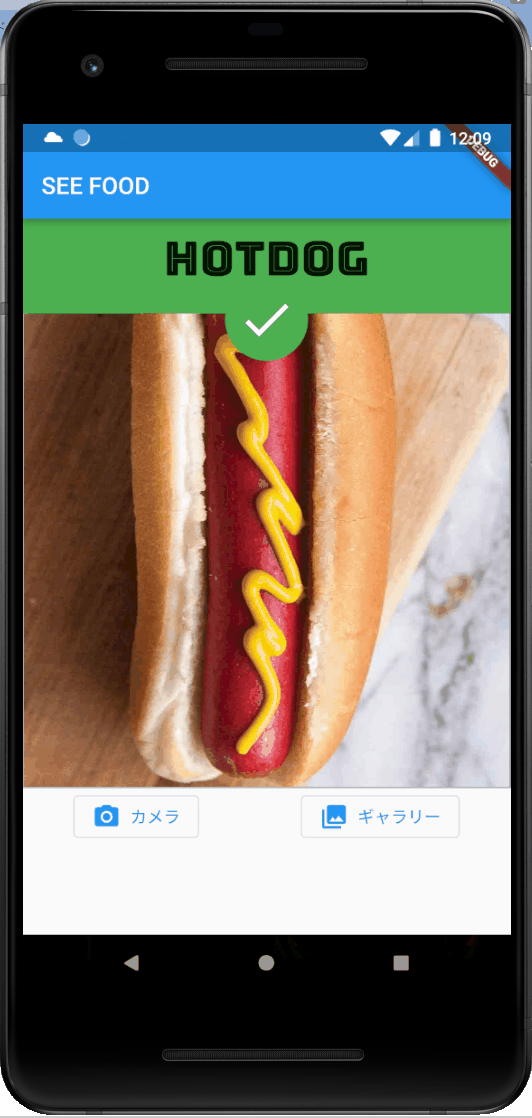
お! うまくホットドッグを識別できていますね!
推論処理自体は大体80~90msで結構スムーズに動いてそうです!
原作通りいけば、これで僕にもベンチャーキャピタルから話が…
おわりに
TFLiteを使えばFlutterでもDeepLearningができます!
今回は2クラス分類でしたが、多クラス分類であればライブラリ側が公開しているデモが参考になりそうですね。
ただ、多クラス分類になると後処理(confidenceが高い配列を抽出する、confidenceからラベルを選択するなど)が追加されるのでそこだけ注意です。
flutter_tfliteを使いましたが、まだver.1.0がリリースされていないので業務で使うには少し怖いかもですね🙄
というか、TFLiteもFlutterもGoogle謹製なので早くFlutter向けTFLite公式版を出してほしいところです🤔
また、null safetyが実装されたFlutter2.0リリース後のFlutterは初だったのでlateの存在や、変数宣言時の初期化等にかなり四苦八苦してしまいました…
機会があれば、次はFlutterでの物体検出や姿勢推定についてやってみたいと思います!
今回使用したコードはこちら:https://github.com/bigface0202/Hotdog_or_NotHotdog