はじめに
こんにちは、2021年新卒入社の SAIG 松崎功也です。Tech Blog 初投稿です。
NVIDIA 社が提供するディープラーニング用の GPGPU ライブラリ「cuDNN」の CUDA API を紹介します。
cuDNN は TensorFlow や Keras で学習や推論を高速化するためのバックエンドとしてよく使われていますが、CUDA API を直接たたいたことがある方は少ないのではないでしょうか?
個人的に作成したアプリケーションで CUDA API を叩く機会があり、社内の技術勉強会で紹介したところ好評だったため、こちらにも寄稿します。
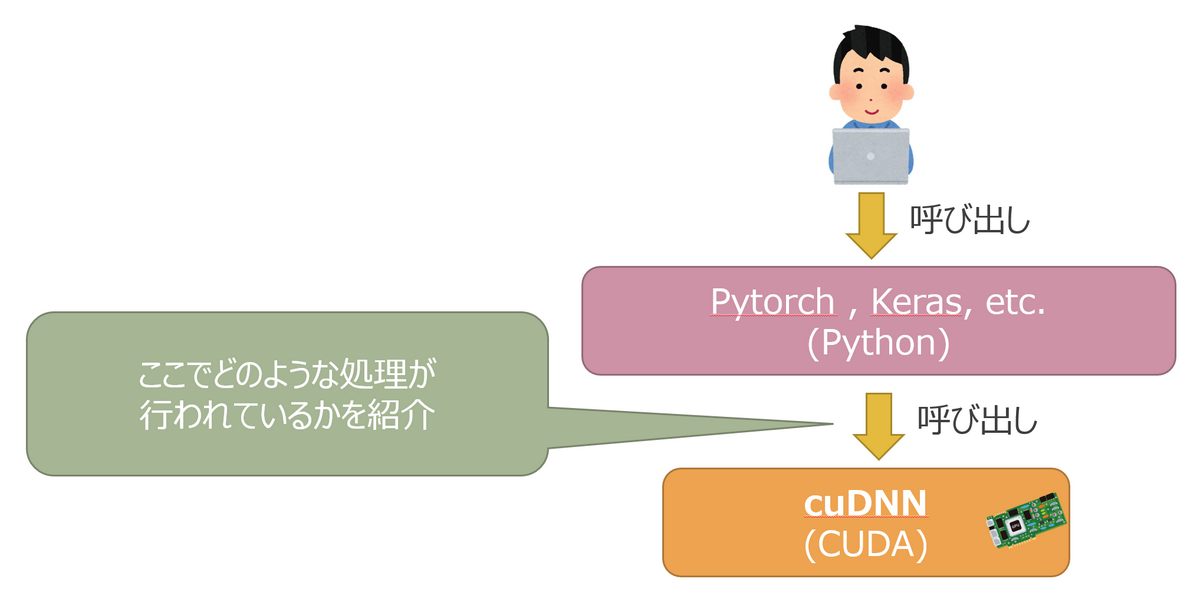
cuDNN を叩くことになったきっかけ
私はレトロゲームを遊ぶことが多いのですが、解像度が低いため 4K ディスプレイだと拡大した際に非常に粗が目立ってしまいます。これをなんとかしたかったのがきっかけです。
最終的には以下の手法で解決することにしました。
- Windows API でゲームウィンドウをキャプチャ
- waifu2x という CNN の超解像モデルでキレイに拡大
- ウィンドウをもう一枚作り、拡大後の画像を表示
この一連のフローをリアルタイムで行います。Python でもできないことはないのですが、今回はパフォーマンスチューニングのしやすさを考慮して CUDA を選択しました。
この記事では、1., 3. の部分の説明は行いません。3. において使用した cuDNN API にのみ焦点を当てて紹介します。
cuDNN で畳込みを行う流れ
流れは以下の通りです。
次の章で、1項目ずつコードと一緒に紹介していきます。なお、コードは正確に書くと量が多くなりすぎるためある程度端折って掲載しています。そのため、単純にコピー&ペーストしてつなげても動きませんのでご了承ください。
- cuDNN ライブラリの初期化
- モデルのフィルタの重みをRAM(ホスト)に読み込む
- RAM(ホスト)に読み込んだフィルタの重みを VRAM へ転送する
- フィルタ記述子(フィルターのサイズなどを定義)の準備
- バイアス記述子の準備
- 畳込み記述子(パディング、ストライドなどを定義)の準備
- 活性化関数の記述子(ReLU, Swish などの係数を含めて定義)の準備
- 畳込みの内部アルゴリズムを設定する
- 拡大したい画像データをRAM(ホスト)→ VRAM へ転送
- 畳込みを行う
1. cuDNN ライブラリの初期化
ライブラリの初期化は以下のように行います。
cuDNN の初期化
cudnnHandle_t cudnn_handle = nullptr;
cudnnCreate(&cudnn_handle);
|
2. モデルのフィルタの重みをRAM(ホスト)に読み込む
今回は JSON 形式で保存されているモデルのフィルタの重みを、picojson で読込みました。
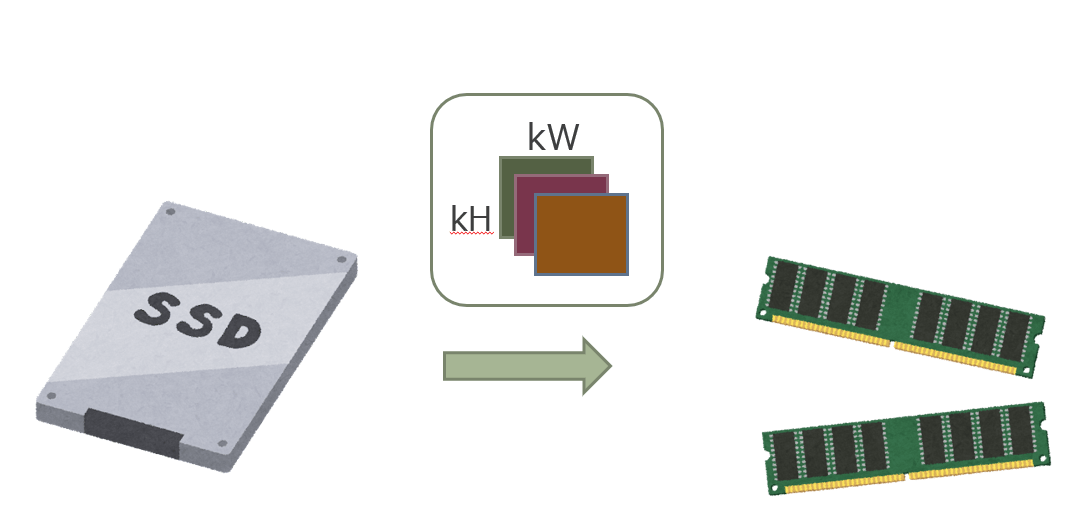
重みの読込み
for (int i = 0; i < layer.nOutputPlane_; i++) {
auto& kernel = kernels[i].get<picojson::array>();
for (int j = 0; j < layer.nInputPlane_; j++) {
auto& mat = kernel[j].get<picojson::array>();
for (int k = 0; k < layer.kH_; k++) {
auto& row = mat[k].get<picojson::array>();
for (int l = 0; l < layer.kW_; l++) {
layer.host_weight_[
i * (layer.nInputPlane_ * layer.kH_ * layer.kW_)
+ j * (layer.kH_ * layer.kW_)
+ k * layer.kW_
+ l
] = row[l].get<double>();
}
}
}
}
|
3. RAM(ホスト)に読み込んだフィルタの重みを VRAM へ転送する
VRAM のメモリを確保して、読み込んだモデルのフィルタを VRAM へ転送します。
メモリ管理はスマートポインタで行っているので、それに合わせたラッパーを自作し使用しています(cuda_memory_allocate)。
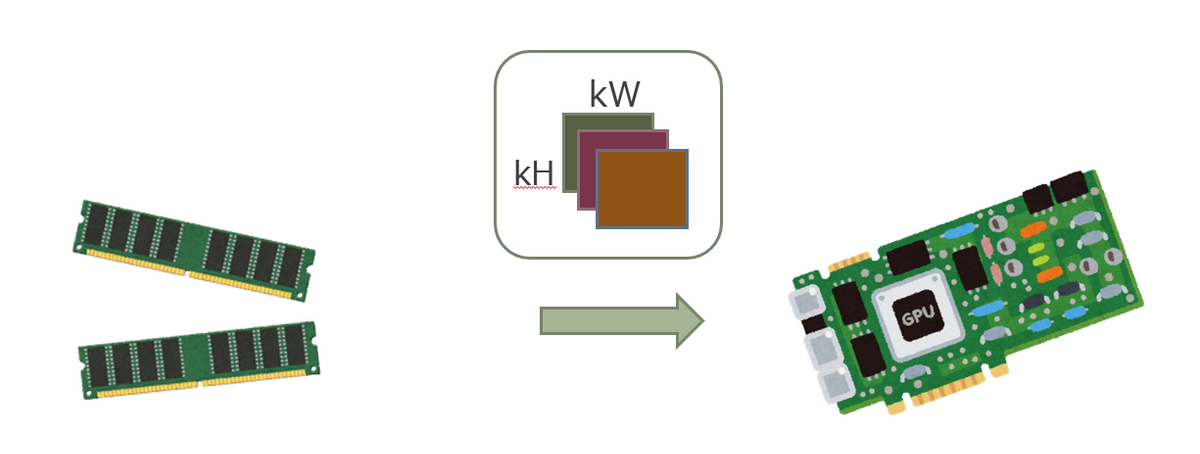
VRAM へ重みを転送する
layer.device_weight_ptr_ = cuda_memory_allocate(sizeof(float) * layer.host_weight_.size());
cudaMemcpy(layer.device_weight_ptr_.get(), layer.host_weight_.data(),
sizeof(float) * layer.host_weight_.size(), cudaMemcpyKind::cudaMemcpyHostToDevice);
|
cuda_memory_allocate(自作のメモリ確保ラッパー)
struct cuda_device_memory_delete {
void operator()(void* ptr) const {
cudaFree(ptr);
}
};
using device_unique_ptr = std::unique_ptr<void, cuda_device_memory_delete>;
device_unique_ptr cuda_memory_allocate(size_t n) {
void* ptr = nullptr;
cudaMalloc(&ptr, n);
return device_unique_ptr(ptr);
}
|
4. フィルタ記述子(フィルターのサイズなどを定義)の準備
フィルタ記述子では、フィルタの枚数やサイズなどを設定します。
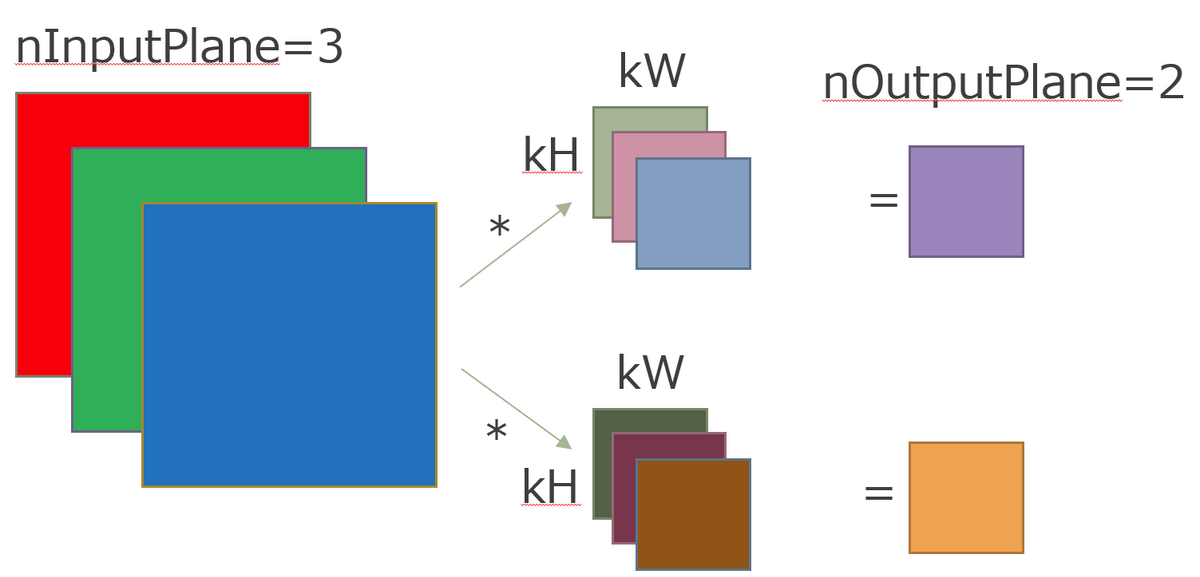
フィルタ記述子の準備
cudnnFilterDescriptor_t temp_filter_desc;
cudnnCreateFilterDescriptor(&temp_filter_desc);
filter_desc_.reset(temp_filter_desc);
cudnnSetFilter4dDescriptor(filter_desc_.get(), CUDNN_DATA_FLOAT, CUDNN_TENSOR_NCHW, nOutputPlane_, nInputPlane_, kH_, kW_);
|
5. バイアス記述子の準備
畳込み処理後に加算するバイアスの準備を行います。バイアスは1次元ベクトルなので、テンソルの記述子を流用します。
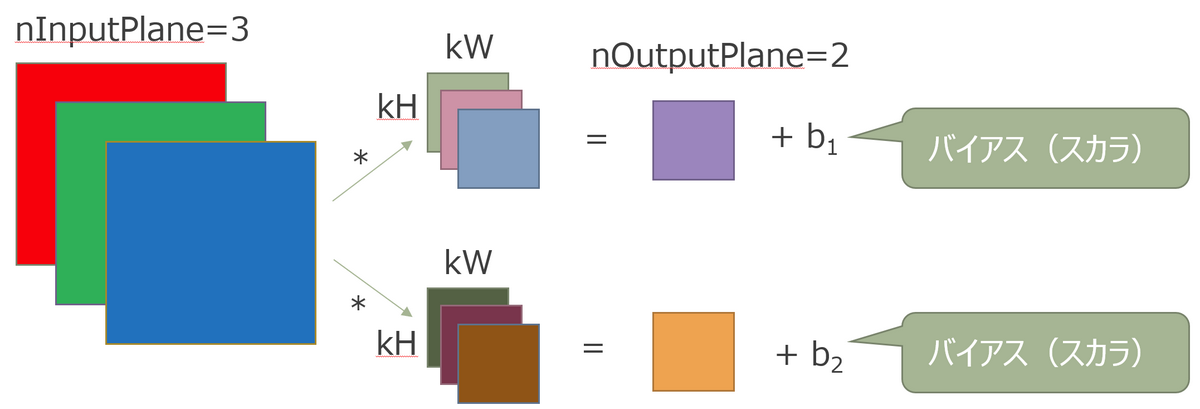
バイアス記述子の準備
cudnnTensorDescriptor_t temp_bias_desc;
(cudnnCreateTensorDescriptor(&temp_bias_desc);
bias_desc_.reset(temp_bias_desc);
cudnnSetTensor4dDescriptor(bias_desc_.get(), CUDNN_TENSOR_NCHW, CUDNN_DATA_FLOAT, 1, nOutputPlane, 1, 1);
|
6. 畳込み記述子(パディング、ストライドなどを定義)の準備
畳込み記述子では、フィルタの動かし方(パディング、ストライド、ディレーションなど)を設定します。
畳込み記述子の準備
cudnnConvolutionDescriptor_t temp_conv_desc;
(cudnnCreateConvolutionDescriptor(&temp_conv_desc);
conv_desc_.reset(temp_conv_desc);
cudnnSetConvolution2dDescriptor(conv_desc_.get(), padH, padW, dH, dW, 1, 1, cudnnConvolutionMode_t::CUDNN_CONVOLUTION, cudnnDataType_t::CUDNN_DATA_FLOAT);
|
7. 活性化関数の記述子の準備
cuDNN ではデフォルトで ReLU や Swish などの活性化関数が準備されています(提供されている活性化関数の一覧)。
ただ、waifu2x で使用されている leakyReLU は cuDNN では提供されていないため、自前で準備する必要があります。
そのため、活性化関数には IDENTITY(何もしない恒等関数)を指定し、CUDA で leakyReLU を実装しました。
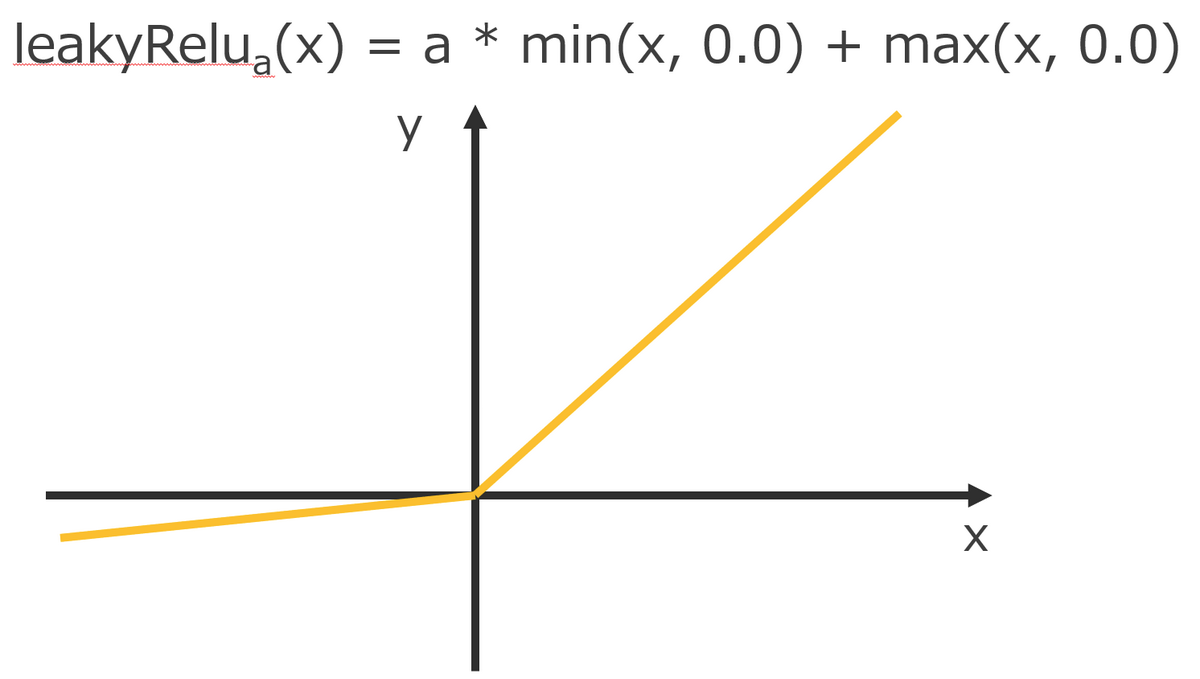
活性化関数の記述子の準備
cudnnActivationDescriptor_t temp_activation_desc;
cudnnCreateActivationDescriptor(&temp_activation_desc);
activation_desc_.reset(temp_activation_desc);
cudnnSetActivationDescriptor(activation_desc_.get(), cudnnActivationMode_t::CUDNN_ACTIVATION_IDENTITY,, cudnnNanPropagation_t::CUDNN_PROPAGATE_NAN, 0.0);
|
leakyReLU.cu__global__ void leakyRelu_(float* vec, int n) {
int i = blockIdx.x * blockDim.x + threadIdx.x;
if (i < n)
vec[i] = 0.1f * fminf(vec[i], 0.f) + fmaxf(vec[i], 0.f);
}
|
8. 畳込みの内部アルゴリズムを設定する
cuDNN では畳込みの内部アルゴリズムがいくつか用意されていて、それぞれメモリ使用量や計算速度にトレードオフがあります(提供されている内部アルゴリズムの一覧)。
これまで設定してきたフィルタ記述子や畳込み記述子の情報を使用して、cuDNN に自動で選択させることもできます。
ただ、同じ記述子を使用した場合でも、実行のたびに自動選択されるアルゴリズムが異なることがありました。そのため、使用するメモリ使用量や処理時間に再現性が欲しい場合は自分で指定するのが吉です。
畳込みの内部アルゴリズムの設定
cudnnFindConvolutionForwardAlgorithm(handle, src, filter_desc_.get(), conv_desc_.get(), dst, 1, &nAlgos, &forward_algo_);
forward_algo_.algo = cudnnConvolutionFwdAlgo_t::CUDNN_CONVOLUTION_FWD_ALGO_IMPLICIT_PRECOMP_GEMM;
cudnnGetConvolutionForwardWorkspaceSize(handle, src, filter_desc_.get(), conv_desc_.get(), dst, forward_algo_.algo, &workspace_size);
|
9. 拡大したい画像データをRAM(ホスト)→ VRAM へ転送
あともう一息です。
拡大したい画像データを VRAM へ転送します。
画像の転送
auto image0 = cuda_memory_allocate(image_size);
cudaMemcpy(image0.get(), image_float.data(), sizeof(float) * image_float.size(), cudaMemcpyKind::cudaMemcpyHostToDevice);
|
10. 畳込みを行う
最後にここまで設定してきた記述子を元に、VRAM へコピーした画像データに畳込み処理を行います。
関数名から分かるように、畳込み、バイアスの加算、活性化関数の適用を一気に行います。
畳込みを行うcudnnConvolutionBiasActivationForward(
handle,
&one, src, src_data,
filter_desc_.get(), device_weight_ptr_.get(),
conv_desc_.get(), forward_algo_.algo,
workspace, workspace_size,
&zero, dst, dst_data,
bias_desc_.get(), device_bias_ptr_.get(),
activation_desc_.get(),
dst, dst_data
);
|
さいごに
cuDNN の CUDA API による畳込みの流れを紹介しました。
普段なかなか見ることのないバックエンド側の API でしたが、興味を持ってもらえるきっかけになればうれしいです。