こんにちは、TIGの村田です。
本記事では、3月17日に開催された「Future Tech Night #21 Google Cloud: データエンジニア+MLOps」のセッションサマリと補足事項について触れていきます。
当日のセッションは2つありましたが、私の記事では「JSON関数と共に歩む、BigQueryを使った超汎化型データ活用基盤」のセッションについて記載します。「Vertex AIによるフルマネージドなMLOps導入」のセッションについては真鍋さんの記事をお待ち下さい。
スライド&動画
登壇時の資料および動画がそれぞれ以下にアップロードされています。
JSON関数と共に歩む、BigQueryを使った超汎化型データ活用基盤
Future Tech Night #21 Google Cloud: データエンジニア+MLOps
サマリ
セッションでは、ビルIoTデータ蓄積基盤の設計開発をユースケースとしてピックアップし、設計における考慮ポイント等についてお話ししました。
At least onceとの付き合い方
Google CloudでのIoTデータ蓄積基盤を構築する際、「データは最終的にBigQueryに格納する」というケースは多く存在すると思います。
データ格納までの道中でメッセージングサービスを利用することも多く、アーキデザイン時の考慮事項として”QoSとの付き合い方”は欠かせません。
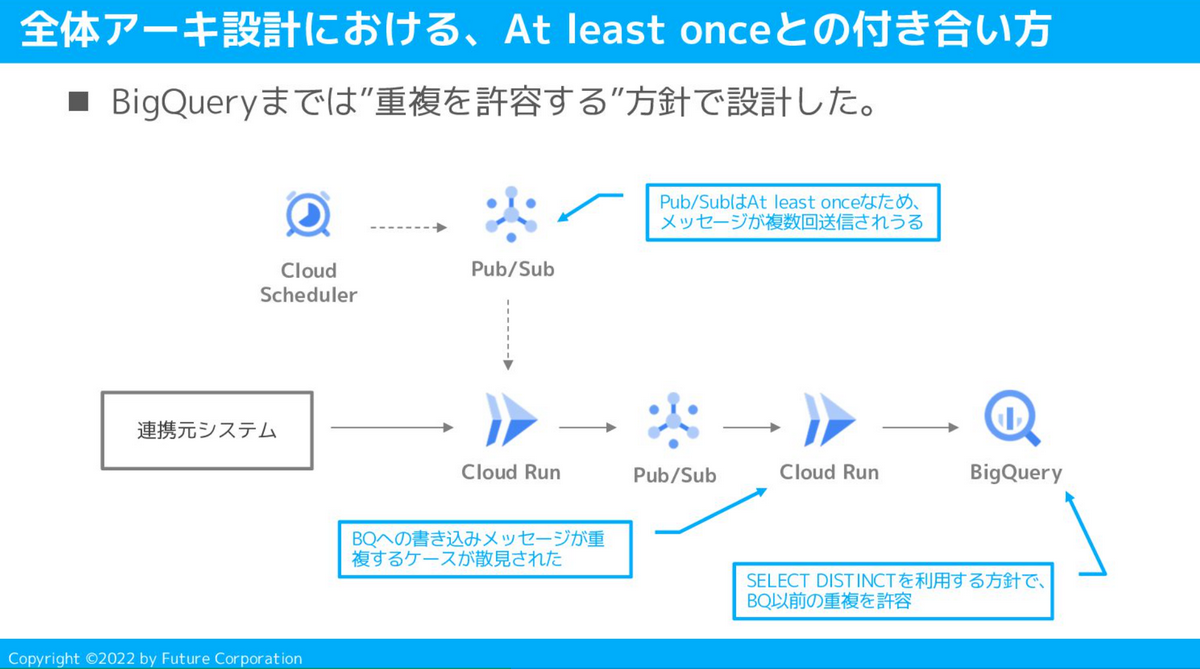
今回のアーキテクチャではPub/Subを採用したのですが、Pub/SubはAt least onceのQoSで動作するため、BigQuery到達までの道中で電文が重複してしまう可能性がありました。
結論としては、BigQueryにてSELECT DISTINCTを利用する方針で、道中の電文重複を許容する形をとりました。
そのため、Cloud Runで行っていたIoT電文の加工は最小限および冪等に設計し、BigQueryでのSELECT DISTINCTにて”同一レコードである”と確実に判定されるよう考慮しました。
BigQueryのカラム構造設計とJSON関数
今回のユースケースでは、データ取得元のデータ構造含めて発展途上かつ今後も頻繁なレイアウト変更が予想されました。そのため、テーブルのカラム構造は極力柔軟な形を目指し設計しました。
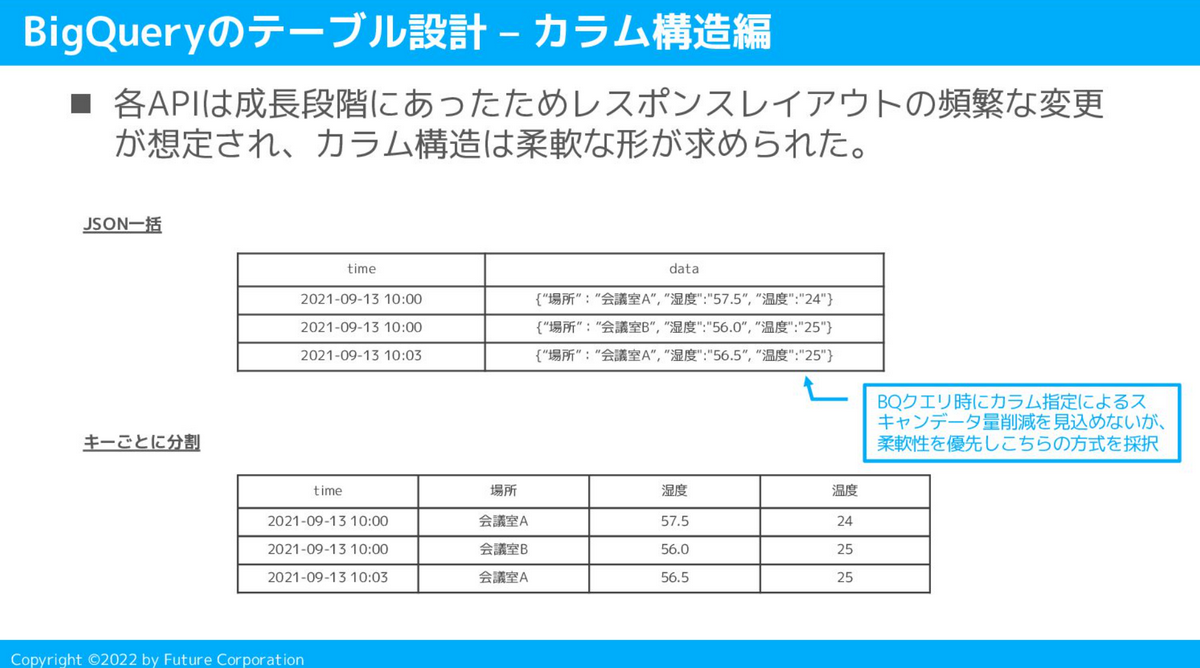
添付資料記載の”JSON一括”方式を最終的には採用しました。カラムをキーごとに分割して格納する形はとらず、受け取ったJSONを丸ごと1カラムに格納しました。
この方式、BigQueryの課金体系を考慮するとベストプラクティスとは言えないのですが、データ量が少ないかつ発展途上である点を考慮して現段階では柔軟な形を採用しました。
BigQueryの課金はスキャンデータ量に応じた従量課金モデルであり、列単位での課金となるため、”JSON一括”方式にした場合不要なデータのバイト数もスキャンされ、課金の対象となります。もしこの方式を採用する場合にはその点に注意する必要があります。
Q&A
Q1. JSON一括方式を採用した際、具体的な性能懸念等はありましたか?
無かったです。
というよりも、データ量が少なかったのでそこまで具体的に「遅い!」となるケースは無かったです。理論上はデータ量が増えてくるとチリツモで性能劣化してくるのではないかなと思います(未検証です)
Q2. 検索キーだけでも固まっていれば、そこを切り出すとコスト削減を見込めるのでは?
おっしゃる通りですね。利活用側の要件が一定見えているのであればそのようなコスト最適化アプローチをとることができたと考えられます。本ケースではデータ蓄積時に利活用側の要件が見えきらず、柔軟な形を採択しました。
まとめ
BigQueryの機能に助けられる形で、クイックスタートに適したデータ活用基盤を簡単に構築できました。JSON関数は非常に便利なのですが、BQのコスト最適化アプローチは念頭に置きつつアーキテクチャデザインおよび処理方式設計を行うことがとても重要だなと感じました。