はじめに
こんにちは、Strategic AI Group所属の金子です。普段は推薦に関連する実装やデータ分析を行っています。
先日Kaggleで開催されたH&M Personalized Fashion Recommendationsコンペに単独で参加し、2952チーム中46位をとりました。
今回の参加記では以下の内容を紹介します。
- H&Mコンペ概要
- H&Mコンペの難しいところ
- 解法のサマリ
- 解放の工夫
- 次に取り組みたいこと
- 感想
H&Mコンペ概要
本コンペはH&Mのオンライン・オフラインの行動履歴をもとに、次にユーザーが購買する商品をレコメンドするコンペティションでした。提供されたデータの期間は2018-09-20~2020-09-22の約二年間で、このデータをもとに2020/9/23~2020/09/29のユーザーの行動を予測しました。予測対象のユーザーは約137万人のユーザーで、これらのユーザーに対し予測対象の商品(=article)は約10万点の中から12点を選び、MAP@12で評価しました。データの種類をユーザー、アイテム、インタラクションの3つに分類すると、それぞれ以下のようなデータがありました。
- ユーザー: 年齢、ハッシュ化された住所、会員登録の状況
- アイテム: 商品のカテゴリ、色・模様、商品の説明文(英語)、商品画像
- インタラクション: 日付、オンラインかオフラインか
H&Mコンペの難しいところ
今回のコンペで難しかった点について、レコメンド一般的な課題、このコンペ特有の課題の順に説明していきます。
レコメンド一般的な問題
レコメンド一般的な課題として、暗黙的(=implicit)なデータであること、大量のデータを高速にさばく必要があること、コールドスタートに対応する必要があることがあります。
implicit なデータ
implicitなデータとは、ユーザーから明示的(=explicit)なフィードバックが与えられていないデータです。それぞれ例を挙げるなら、explicitは星の数やいいねなどユーザーの反応がついている状態、implicitはユーザーが見たという情報だけがあるような状態です。explicitなデータではユーザーの好みが数値化されているので、これを直接予測し評価できますが、implicitなデータではユーザーが何かしらの行動を起こしたということが分かるのみで、実際にユーザーが気に入ったかどうかは分からないという問題があります。また、ユーザーが行動を起こさなかったデータはない場合が多く、閲覧・購入したデータを二値分類の正例にするのであれば、負例は上手く生成する必要があるのも問題です。
大量の商品xユーザー、履歴データ。
今回のコンペは137万人のユーザーに対し、10万の商品の候補からレコメンドを行う必要がありました。また、履歴については2年間で約3000万件あり、これをうまく処理することが求められました。レコメンドはリアルタイムに予測を行う場合と、バッチ形式でまとめて予測するものがありますが、今回のコンペでは後者で時間もマシンリソースも無限でした。ただ、それでも全組み合わせを愚直に評価するのは難しく工夫が求められました。
コールドスタート問題
コールドスタートは履歴の少ないユーザー・アイテムに対して上手く予測ができない問題です。レコメンドは主にユーザーの行動履歴もとに予測を行う協調フィルタリング形式と、アイテム自身のカテゴリや画像といった情報を活用するコンテンツベースの手法に分類されます。前者の協調フィルタリングのアルゴリズムは大量にデータがあるアイテムやユーザーには上手く作用しますが、まだ履歴の少ないユーザーや新しく登録されたばかり・マイナーなアイテムには上手く予測できないという問題があります。
コンペ特有の課題
コンペ特有の課題として、ユーザーの行動が散発的であること、繰り返しの購入パターンが強すぎることがありました。
散発的な履歴
ユーザーの履歴を確認したところ、前回の履歴から数か月空いていることが多く、履歴があったのは似たようなズボン数種類だけ、と一部の種類のカテゴリにのみ行動があったケースが多くみられました。これはユーザーの気持ちになって考えると、ある程度買いたい種類の服を決めてからオンラインのサイトを見て欲しいものだけ買うケースが多かったからではないかと考えています。
繰り返し購入の多さ
また、今回のコンペでは繰り返し商品を購入するパターンが強い傾向が見られました。例えば書籍などの推薦では一度購入した商品を再度推薦する意味はないのですが、今回のH&Mでは同じ商品やその色違いを購入するケースが多くみられました。この点は自身が普段服をオンラインで買うときはサイズを間違えてもダメージの少ない靴下やシャツ等の消耗品ばかり買っているので予測はできていました。ただ、想像以上にスコアに対する比率が高く、以前購入した商品の再購入をとらえるのがコンペのカギとなっていました。
解法のサマリ
今回私はこの問題に対し、候補を高速に絞り込むretrievalステージと精度よく予測を行うrankingステージの二段階で予測を行うtwo-tower modelを構築しました。解法についてはkaggleのdiscussionにも投稿したので、ここではサマリで割愛させていただきます。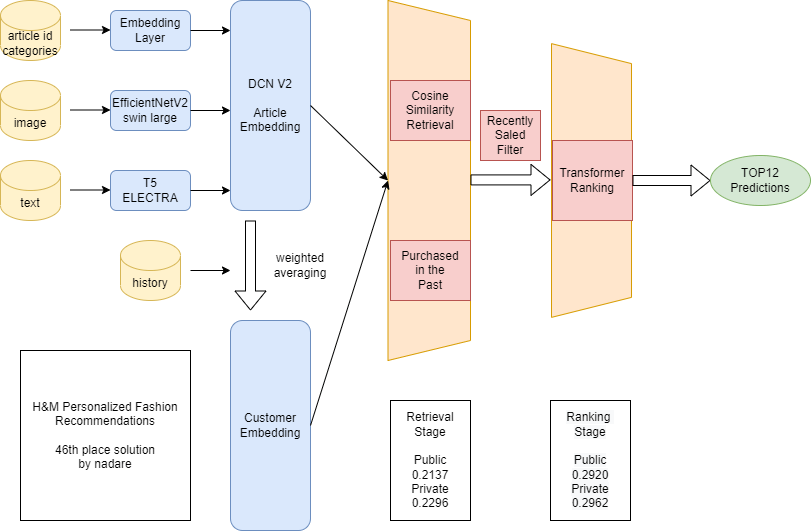
Retrieval Stage
Retrieval Stageではarticleの画像や自然言語、カテゴリといった情報を、articleの性質を表すベクトル(=embedding)に変換し、ユーザーの行動履歴で学習を行う協調フィルタリングとコンテンツベースのハイブリッド手法を実装しました。ユーザーの行動履歴はこのembeddingの平均とし、ユーザーと候補のアイテムのembeddingの類似度を内積計算で計算することで、ユーザーの行動履歴に近い商品を高速に絞り込みました。検索対象のアイテムはユーザーが過去に購入したことのあるアイテムと、直近90日で履歴の数が多かったトップ20000のアイテムのうち、過去一週間で1回以上購入されている販売終了になっていないものに絞ることで実行速度と精度を上げました。
Ranking Stage
Ranking Stageではユーザーの行動履歴とRetrival Stageで絞り込んだ商品の組み合わせについて、それぞれBERT等に用いられるattentionという技術を用いてより正確に相性を判定し精度を高めました。
この2つを組み合わせることで130万人のユーザーに対する予測をRTX3090でわずか20分のうちに予測し全体で46位に入ることができました。
解法の工夫
今回の課題で有効だった工夫について三点紹介します。
Gumbel-Max Trickを用いた効率的Negative Hard Sampling
二値問題のモデルを学習させる際、負例はある程度難しいものを選ぶと良いことが知られています。例えば[gensimのWord2Vec](https://radimrehurek.com/gensim/models/word2vec.html#gensim.models.word2vec.Word2Vec)では単語の出現確率のα(通常は3/4)乗で負例をサンプリングします。
今回のデータでは予測日と対象のユーザーの年齢が分かっていました。そこでバッチごとにユーザーの年齢(10歳区切り)と予測日を統一し、予測する日から直近1週間における予測対象の年齢層の購入数top10000の割合からItem2Vec用の負例をサンプリングしました。
サンプリングの方法はGumbel-Max-Trickという手法を用いました。これはカテゴリカル分布から重複のない組み合わせをサンプリングする手法です。日ごと年齢層ごとにtop10000のarticleのIDと出現確率を入れた配列を用意し、それを用いて計算を行いました。
今回のItem2Vecの学習では負例の量と質が非常に重要でした。Word2Vecの負例の数は通常5~15付近ですが、今回のモデルでは負例の数を最大4096まで増やしました。負例の数を変えて学習させたところ、負例が4096個の時がLB0.020付近で、1024個の時がLB0.010付近、それより少なく質の低い負例ではあまり効率的に学習ができませんでした。
ApproxNDCGLossベースによるランク学習
Ranking StageにおけるTransformerの学習ではApproxNDCGLossベースのランク学習が有効でした。通常の二値分類ではユーザーが購入したかどうかをそれぞれ別々に計算するPointwiseの学習を行いますが、ApproxNDCGLossを用いた学習では1つの予測対象につき複数個のarticleを予測し、その順番を最適化するlistwiseな学習を行います。ApproxNDCGLossの実装は、予測値の差をsigmoid関数にかけることで微分可能な順位を計算し、その順位を用いてnDCGLossを計算します。私はこれをもとにnDCGの重み付けの部分を代わりに正例の順位差で計算するように改造しました。これが効いた原因は今回の予測は難しく、例えば128個サンプリングしても正例は平均して32位付近に予測されるので、nDCGによる重みづけが上手くいかず、代わりに順位差をそのまま使った方がよかったからだと推測しています。
配列長を意識したattention計算の効率化
計算時間短縮のための工夫としてattentionの計算を大幅に高速化しました。通常のattentionではクエリの長さとターゲットの長さの積の計算量で行列計算を行います。ただ、行動履歴のようなデータは大抵が一桁二桁の長さで、ヘビーユーザーのみ三桁四桁の長さである場合が多いです。ただ、精度のためにヘビーユーザーに合わせた行列の大きさで計算を行うとかなり無駄な計算を行って非効率的になってしまいます。
そこで、クエリとターゲットの配列を一定の長さで分割し、計算を行うペアのみ部分的に計算を行うようにtf.tensor_scatter_nd系のメソッドを使ってTransformer Layerを設計することで、時間・空間計算量を大幅に削減しました。また、予測時は行動履歴の少ない順にユーザーを並べ、行動履歴の少ないユーザーの時はバッチサイズを大きくすることでさらに予測時間を短縮しました。
次に取り組みたいこと
今回のコンペのテーマでは取り組めませんでしたが、検討すると面白いと思うテーマについて個人的に述べていきたいと思います。
セレンディピティの検討
今回のコンペは繰り返しの購入を当てることが有効で、それにうまく取り組めたチームが上位になっていました。一方で実際のレコメンドではユーザーにとって自明なレコメンドより、ユーザーにとって有用でかつ意外なアイテムを推薦することが重要な場合もあります。(セレンディピティといいます)実際には今回のH&Mコンペのような指標のみではなく、本当に改善したい指標(ユーザーの満足度・売上)につながる指標も検討が必要と考えています。
ユーザー・アイテムセグメンテーションと分析
今回はItem2Vecを推薦に用いましたが、ここで得られたベクトル(=embedding)を分析することで似たようなアイテム・ユーザーの傾向を分析できます。embeddingを用いた分析の例は過去に医薬品副作用データベースから医薬品同士の関係を学習・評価・可視化するやembeddingを用いた分析・検索・推薦の技術で紹介しましたが、これらの手法を用いることでレコメンドモデルから新たな示唆を得られる可能性があります。
テーマ別推薦・検索との融合
今回のコンペではユーザーに対して全アイテムの中からレコメンドを行っていました。実際にレコメンドを適用するとしたらサイトのトップページ、もしくはメルマガやアプリのプッシュ通知のような例が考えられます。しかしこのようなレコメンドから購入するというケースは少なく、ユーザーはキーワードで検索・もしくはカテゴリのページで探しながら商品を購入すると考えられます。
私は趣味でいろいろなECサイトのUIを眺めるのですが、カテゴリ・検索後の部分までパーソナライズできているサイトは少ないです。(ウィンドウを見て評価するショッピングをしています。)レコメンドは一方的に出して終わりではなく、ユーザーに気づきを与え、そこから興味を深堀りできるようインタラクティブに設計していくのがキモだと思っています。全商品からだけでなく、カテゴリ別のページや検索結果にもパーソナライズされたレコメンドを適用できるモデルの検討は実用上重要なテーマである。
感想
今回のコンペは画像・自然言語・カテゴリの詰まったログデータによるレコメンドコンペということで非常にワクワクしながら挑戦しました。ただ、今回のコンペはユーザーの購入間隔がばらばらかつ同じ商品の繰り返しの購入傾向が強いという性質からか画像や自然言語を用いたNNがあまり効かないタスクでした。私はEnd2EndのNNで勝つことにこだわったため、NNを用いた解法の中では非常に高いスコアを出せたものの、順位としては46位ともっと上を目指せたのになという後悔が残りました。このコンペからは良いレコメンドには人のロジックとMLのアルゴリズムを上手く融合させることのできる設計が必要と学びました。それを実現するための仕組みを引き続き研究していきたいと思います。