はじめに
はじめまして、TIGの原木です。サービス間通信とIDL(インタフェース記述言語)連載の4本目です。
気が付けば、バージョンの話1ばかりしています。
この記事ではスキーマのバージョン管理と互換性について話します。
“スキーマ”が指し示す言葉と課題
一般的にスキーマのバージョン管理という話が出た場合、次のどちらかを想像する人が多いのではないでしょうか。
- データベースのスキーマ(DB内のデータ構造)の変更をどうやってバージョン管理していくか
- サービス間通信で使用するデータフォーマット(ex. gRPCのprotobuf)をどうやってバージョン管理していくか
データ構造が変わったことによりソフトウェアの改修が発生するとわかった瞬間、この問題に直面して「どうしよう…」と悩まれた経験を持つ方は数知れずいらっしゃるかなと思います。
両者において、スキーマのバージョン管理が課題だと意識するタイミングにさほどの違いはありません。しかし、両者において何を問題として捉えているのか? そして解決に向けたアプローチ方法は? とみると異なるようです。
データベースのスキーマのバージョン管理
データベースのスキーマのバージョン管理といった文脈では、通常、DBマイグレーションツール2がセットで語られます。なぜなら、データベースのスキーマを変更するためにはデータの構造を示す定義情報を変更すると共にその中身であるデータそのものを変えていく必要があるからです。
データ定義の変更には必ず中身のデータ移行(マイグレーション)が伴います。ここに、データベースのスキーマのバージョン管理の課題に繋がる難しさがあります。例を挙げてみました。
- データベースのスキーマの変更管理をどうやって行うか?
- 例: 「カナリーリリース予定の新機能についてテーブルの変更が必要だって聞いて対応した後で、その変更が要らなくなってしまった。切り戻す? 放置する?」
- データベースのスキーマの変更に伴う影響をどうやって正確に見積もるか?
- 例: 「データベースのテーブルのカラムを一部増やす対応を行うって聞いたけど、そのテーブルを参照している他業務システムが結構あるんだよね。影響調査よろしくー」
- スキーマの変更に伴い、データ移行をどうやって行うか?
- 例: 「データベースをダウンタイムゼロで移行しなければならないのだが、自動化できてない。つらい」
「データベースのバージョン管理に困っている」といった話が持ち上がった場合、注意が必要です。データベースのスキーマ変更に伴う業務アプリケーション側の影響を気にされているのか。それともデータベースの更新に伴うデータ移行と運用の重さを気にされているのか。立場上、気にするポイントが全然異なるからです。
前者の業務アプリケーション側の影響に主眼を置いた解決策の1つとして、かつてデータベースとユーザーとの間に抽象化レイヤーを設けることで、データ構造の見た目と実体を自在に切り離すことで解決しようといった試みが繰り返されていました。(“Data Virtualization”等で検索)
しかし、この手法は主流となっておりません。なぜなら、そういった問題がそもそも生じる理由として境界付けられたコンテキストに従った適切なデータ分割を行っていないことが考えられるからです。
ここまでくると、データベースという要素技術ではなく、業務サービスに紐づく組織づくりやシステムアーキテクチャといった俯瞰的な視点から解決せざるを得ません。
この辺りは「ソフトウェアアーキテクチャの基礎」の続編にあたる「Software Architecture: The Hard Parts」にて詳しく説明されています(翻訳待ってます)。
後者の、運用におけるデータベースの影響に着目した解決策についても、ベストといえる解は残念ながらありません。データベースの変更自体は、DBマイグレーションツールにより差分を吸収しつつ移行の自動化が可能ではあります。しかし、システム全体の運用を鑑みた場合、解決策は1つのツールで成しえないからです。
データベースのバージョン管理に困った場合、そのソリューションは結局DBに留まらない話が多いんだとわかったところで、もう1つの課題であるサービス間通信で使用するデータフォーマットのバージョン管理の話に移ります。
データフォーマットのバージョン管理
サービス間通信で使用するデータフォーマットというと固く聞こえますが、要はgRPCで使われているprotobufのスキーマの仕様だったり、OpenAPIで書かれたAPIの仕様書から起こしたJSON Schemaのことです。これらのデータフォーマットにバージョン管理が必要となるユースケースはいったいどういった場面が想定されるでしょうか。
例えば、APIの仕様書が変わったときに生まれそうな課題を想像してみました。
- API仕様書とAPIサーバーレスポンスのギャップをどうやって防ぐか?
- API仕様書の変更に伴い、APIクライアント側の影響をどうやって見積もるか?
これらの課題に対して、それぞれ解決策を検討します。
データスキーマの仕様書と実データのギャップ
ソフトウェアの開発において、仕様書と実装がずれるという事象は決して起きてはなりませんが、現実にはままあることです。そんなギャップを防ぐ手法の1つとして、スキーマファーストデザイン、あるいはコントラクトファーストデザインといわれる開発手法があります。
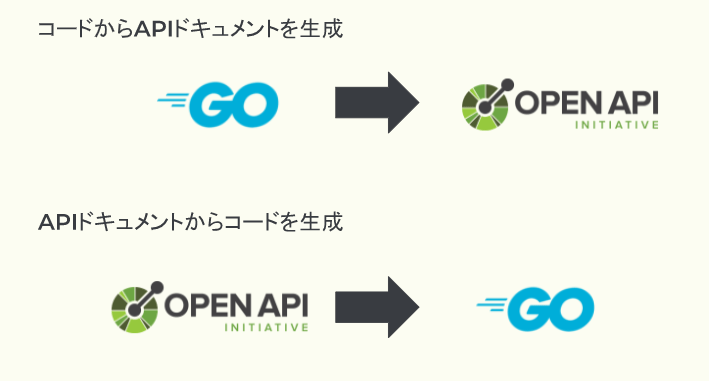
「コードから仕様書を生成」するのではなく、「仕様書からコードを生成」することで、サービス間で交換されるデータの仕様を先に決めて仕様と実装のギャップを防ぎます。
詳細は、多賀さんが話されたGoにおけるAPIドキュメントベースのWeb API開発について登壇しましたにて説明されていますのでご参照ください。
上記のような取り組みを行い、Git上にあるデータスキーマの仕様書と実際に送信されるデータとの間の溝を埋めていっても、データスキーマのバージョン更新に伴う課題はまだまだ解決しません。データベーススキーマでも出てきましたが、スキーマの変更に伴う影響調査です。
データスキーマの変更に振り回されながら
データスキーマの変更を変更する際に、その影響が大きいのはたいていデータの送り手ではなく受け手です。変更したことでどのような影響が出てくるのか?(1)変更したデータスキーマが互換性を持つか(2)その情報を誰がどこで連携するか3、自分はこの辺りを気にしています。
(1)については特にスキーマの進化(Schema evolution)=開発によって変わり続けるスキーマをどうやって変更管理しようかという文脈で検討されることが多い問題です。名著データ指向アプリケーションデザインでも第4章「エンコーディングと進化」にて詳しく取り扱われています。
そもそも、”データ”とは何でしょうか。サービス間通信の文脈では、大きく二種類の扱われ方をしています。
- コンピューターがメモリ内で取り扱うためのデータ構造(インメモリの表現)
- サービス間で情報を交換するためのデータ構造(バイナリデータ)
これら、インメモリの表現とバイナリデータを相互に変換することで、
- 人が読みやすい、直感的にわかるデータとして扱いたいときはインメモリの表現
- 送受信する情報量を圧縮することで、より効率的に情報交換したいときはバイナリデータ
という風に、利用シーンに応じてデータの様態を変えることができます。

このインメモリの表現、メモリ上のデータ構造をスキーマとして記述することで人間にもわかりやすくするために開発されたのが、本ブログの連載テーマであるIDL(インタフェース記述言語: Interface Definition Language)です。普段良く耳にするXMLやJSON Schema、ブログの連載でもたびたび取り上げられたgRPC内で使われているprotobufやcuelang等が代表例です。
これらIDLでスキーマを描画する際に問題となるのが、スキーマの進化に伴う、データスキーマ同士の互換性です。
例えば、あるバージョンのIDLに従って作成したバイナリデータ、また別のバージョンのIDLに従って作成したバイナリデータはどこまで同じなのでしょうか? あるいは、バイナリデータを作成したときとは異なるバージョンのIDLを使ってバイナリデータを人が読める形に戻せるのでしょうか?
IDLの1つ、Apache Avroでは、言語の設計時から互換性を念頭に考えられていました。
例えば、Kafka等のメッセージング駆動によるシステム連携において、Producer(データを流す側)とConsumer(データを受け取る側)でデータを送るケースを考えてみましょう。
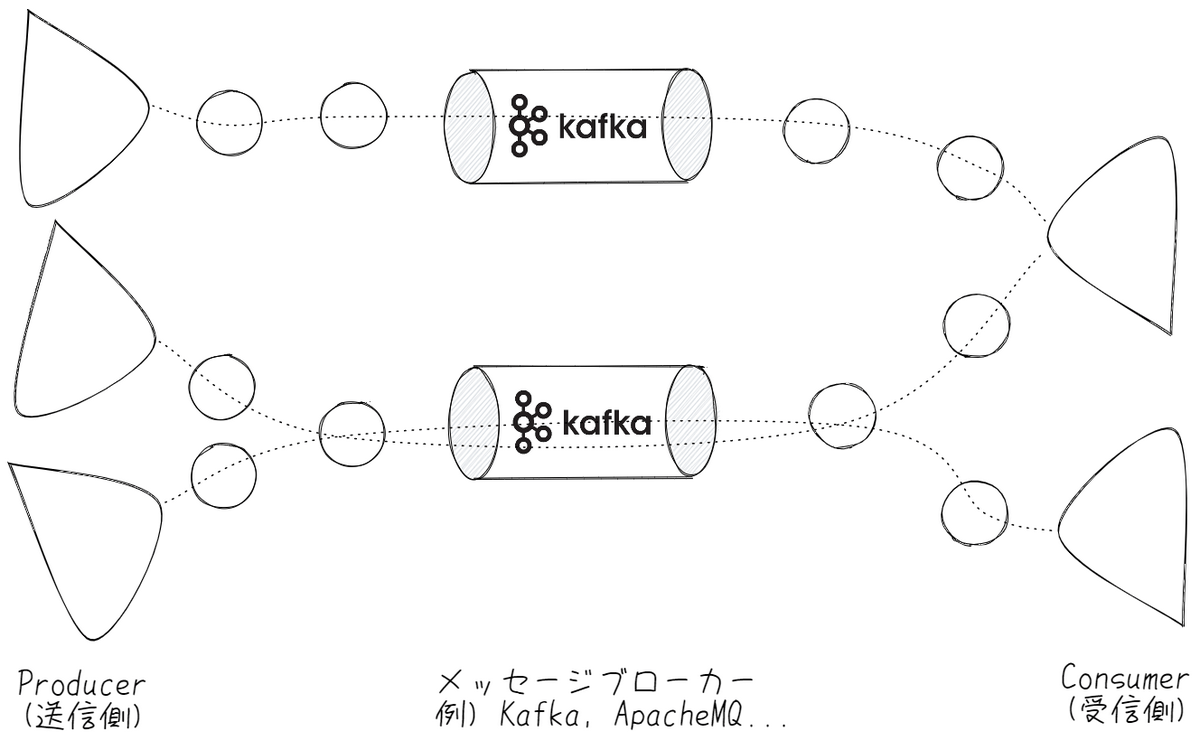
メッセージング駆動アーキテクチャではデータの連携はキューを介して行われており、両者の関係は緩やかにつながっています。ここでProducer側で送信するデータスキーマを変更したときに、逐一Consumer側で対応しないとうまく動かないシステムだったら運用の負担が非常に大きいですよね。そうした課題への回答の1つとして、Apache AvroはIDLの言語仕様として、フィールド値の動的な変更に追随して自動的にマッピングを行いつつ、互換性にも可能な限り応えることができます。
Apache KafkaのManaged ServiceであるConfluentが提供するConfluent Schema Registryにはこの言語仕様を元に互換性の”強度”に基づいてvalidationの処理を変えられるユニークな機能があります。
諸事情により、Confluentの画面は出せないのですが、想像しながら読み進めてください。
参考: https://docs.confluent.io/ja-jp/platform/7.0.1/schema-registry/avro.html
例えば、BACKWARD(後方互換性モード)で、Confluent Schema Registryに次のApache Avroの形式のスキーマ情報を登録してみましょう。後方互換性とは、version1のフォーマットがversion2でも使用できることを意味します。
{ |
しかし、32bitだと値が小さすぎるということで、int型をlong型に変える必要が出てきました。
my_field1の型をint型からlong型に変更して再登録します。
// 中略 |
登録できました。int型のデータはlong型に代入しても問題ないからです。ここでさらに文字列型数字、たとえば先頭が0から始まる値を扱う必要が出てきました。long型をさらにstring型にしてみます。
// 中略 |
エラーになりました。long型とstring型には互換性がないためです。ここで互換性モードを変更し、制限を緩くしてみます。
Compatibility settingsを選択して Backward から Noneに変更して、先ほど失敗したスキーマを入力して、再度登録ボタンを押してみましょう…登録できました。
この状態ではスキーマは以前のバージョンとの互換性が完全にないため、Consumer側(データを受け取る側)はこのスキーマに基づいたメッセージをそのまま受け取ることができません。通常は新規スキーマを切り直すユースケースですが、あえて登録してみました。
互換性の強度に応じた細かいvalidationチェックにより、破壊的な変更を防ぐConfluent Schema Registryの機能紹介でした。
Thema: スキーマのバージョン管理の行く先
スキーマの変更に伴い、破壊的な変更が生じたときに自動的にvalidateする仕組みは、Confluent Schema Registryのような便利機能でなくてもスキーマファーストデザインを採用している開発現場であれば、CI/CDの一部としてチェックする別の機構(E2Eテスト)があると思います。しかし、スキーマの進化が頻繁に行われるような環境下では、validateするだけではなく、次のような仕組みが欲しくなってくるでしょう。
- 既存データをスキーマバージョンによって動的に変更する機能(いわゆるmutate機能)
- ソースコードのリポジトリ管理でよくあるような、スキーマの”変更履歴”を可視化する機能
- マージ操作による違うスキーマ同士の接合機能
このあたりの課題感を解決する仕組みとして、現在開発中のThema - grafana/themaが非常に参考になるでしょう。
Themaはcuelangをベースとした、スキーマを作成するためのフレームワークです。
Themaが目指す姿はずばり 抽象化によるスキーマのバージョン管理 (“schema versioning by abstraction”)です。cuelangで記載した リネージ(系譜) を用いて、スキーマの進化を安全に行える世界を目指しています。
ここから、どうやってcuelangでスキーマのバージョン管理を実現しているのかThemaの詳細について説明しますが、その前に少しだけThemaの開発のモチベーションについて代弁させてください(モチベーションシートが見当たらなかったので)。
Themaは主にGrafanaに所属しているSam Boyer氏によって開発されているOSSです。どうして彼はThemaを開発することにしたのでしょうか?そのモチベーションを辿ると二つのイベントにたどり着きます。2018年にGo言語に入った仕様、そしてGrafanaが直近進めているDashboard as Codeの中で導入されたPrometheus monitoring mixinです。
2018年初頭、Go言語界隈は揺れていました。現在のGo言語のバージョン管理(dep)を続けるのか、それともそれを捨てて新しいバージョン管理とパッケージ管理システム(vgo)を再構築するのか。Russ Cox氏が中心となってまとめられたvgoの検討会にSam Boyer氏もいました。
https://web.archive.org/web/20180222100213/https://sdboyer.io/blog/vgo-and-dep/
vgo、Versioned Goは、Go言語を最近使うようになった方にはまったく馴染みがない言葉だと思います。vgoは検討段階で消えてしまったのでしょうか? 実は、Go1.11に導入する際に名前が変わりました。その名は Go Modules です。
彼がGo言語のバージョニングとパッケージ管理について最も造詣が深い一人であることは言うまでもないでしょう。これは余談ですが、全然異なる文脈でThemaを知った自分はこの人どこかで見たことあるんだけどな...って気持ちで軽く来歴を調べて鳥肌が立ちました。全てはバージョン管理に戻ってくるのです。
そしてもう一つが、Monitoring Mixin にまつわる課題です。近年では従来の運用監視システムの対象者がSREやDevOpsの普及によって開発者にまで広がったこと、マイクロサービスの普及により爆発的に監視対象が増えたことなどから、Observabilityの三つの柱であるメトリクス、トレーシング、ログを横断的に確認できる需要が高まっています。それを支えるための仕組みの一つに、Monitoring Mixinというプロジェクトがあります。
↓こちらの方が詳しく解説されています。
https://kobtea.net/posts/2021/08/29/monitoring-mixins/
Monitoring MixinsはPrometheus rule, Grafana dashboardといった監視設定のPackagingを目指すプロジェクトです。ExporterのMetricsだけではなく、それを使って何を観測し可視化するかという知見を共有するのが目的です。Out-of-the-boxでいい感じのアラート設定とダッシュボードがほしい、そんな需要に答えます。コードはJsonnetとパッケージングツールのjsonnet-bundlerで管理されます。
という、いわば運用監視設定の欲張りセットなのですが、Sam Boyer氏はMonitoring Mixinsのスキーマとして使われるjsonnetの寄せ集めゆえの扱いづらさについて触れて、もっと改善する仕組みを考えていることを過去に仄めかしています。
旧名scuemata、Themaはこうした背景を踏まえた上で誕生しました。
リネージとは、ざっくりいえばスキーマの進化表です。1つのオブジェクトに対する全てのスキーマの履歴を含む、”レンズ”(後述で解説します)でリンクされたシーケンスの順序付きリストを示します。元々familiyって呼んでいましたがリネージに名前を改めました。
リネージの中身( ship.cue )を実際に見てみましょう。
// ship.cue |
このリネージを図示化したものが次の図になります。
.png)
それぞれの役割について説明していきましょう。
まず、リネージには2つのスキーマバージョンがあり、それぞれ Sequence(シーケンス) という単位でグルーピングされています(図の黄色と赤色のエリア)。Sequenceは「スキーマの順序付きリスト」であり、同じSequenceであれば、一つ前のスキーマとの後方互換性を保証します(今回は1つのSequenceに1つのスキーマしかないのでここは検証しません)。
そして、Sequence同士を結ぶ重要な役割として Lens(レンズ) があります。レンズは「あるシーケンスにおける最後のスキーマと、別のシーケンスにおける最初のスキーマとの間の双方向のマッピング」であり、互換性を持たないシーケンスどうしの変換、糊付けのような役割を果たします。リネージをよく見ると、 lens: forward と lens: reverse という役割があり、それぞれレンズを通過した際に、スキーマの変更に合わせてどのようにデータを変換すればいいか記述されています。
ここで忘れてはならないのが Lacuna(ラクーナ、欠落) です。ラクーナは「レンズのマッピングロジックにおけるギャップ、つまり、そのレンズを通過した特定のインスタンスが何らかの意味上の欠落を持つこと」を表します。テーブルのカラムの追加、削除を思い浮かべるのが手っ取り早いのではないでしょうか。リネージではSchema1.0からSchema0.0に変換する際に、secondfieldが消えることを説明しています。
最後にインスタンスです。これはスキーマというテンプレートにしたがって作成されたデータの実体を表しています。
さて、Themaの概念を説明したところで、これをどうやって活用するか説明しましょう。Themaのチュートリアルでは、Theamaを組み込んだGo言語のプログラミングを例にスキーマの進化に合わせて、自動的にインスタンスを変換できる処理を掘り下げて説明しています。
ここではその内容に従ってできることを1つのテストコードにまとめてみました。
https://github.com/hodagi/learning-thema/blob/main/main_test.go#L53-L85
// version0.0のスキーマに従って作成されたJSONデータを読み込み、cuelangデータに変換する |
この処理で重要なのは1.バリデーションチェック、2. スキーマの推測 3. バージョン変換です。これらの処理をリネージに従って行うことで、スキーマの進化に伴ったデータ変換を安全に行うことができます。
振り返り
スキーマのバージョン管理と互換性に関する話をしました。
サービス間通信とIDLというお題からするとデータベースの話は蛇足ではありますが、テーブルをデータ構造とそのIFと見なした時に、スキーマの進化が抱えている問題と同根であると思ったので、説明いたしました。個人的には、データベースにおいて分散データベースという文脈から “コンピューティングとストレージの分離” ってテーマが流行っていますが、この辺が課題解決につながりそうな気がしています。
Themaは絶賛開発中ですが、目指そうとする姿に共感したのでご紹介させていただきました。宜しければ一度触ってみてください。
次は武田さんのOpen API Specification 規約の話です。