本記事は「地図・GIS・位置特定に関する連載」二日目の記事です。昨日の「郵便番号・住所・緯度経度の体系について」の記事も、今回の記事とは直接つながってはいませんが、参考になる部分もあるのでぜひご覧ください。
はじめに
こんにちは、Strategic AI Group所属の金子です。普段は推薦に関連する実装やデータ分析を行っています。
先日Kaggleで開催された「Foursquare - Location Matching」コンペ(以下4sqコンペ)に社外の知人共にチームで参加し、1083チーム中7位をとりました(初の金メダルでKaggle Competitions Masterになりました! )
本記事では参加記として以下の内容を紹介します。
- 4sqコンペ概要
- 解法のサマリ
- 解法の詳細
- テクニック集
- リーク問題について
- 謝辞
4sqコンペ概要
タスク概要
Foursquareは位置を共有するSNS等を提供する企業です。現在はあるPOI(Points-of-Interest, 同じ地図上の特定のポイント)について口コミ等を検索する「Foursquare」アプリや、あるPOIにチェックインし、それをシェアすることに特化した「Swarm」アプリなどを公開しています。これらに登録されているPOIはユーザーによって登録されます。
4sqコンペではFoursquareの持つPOIとそれに関連するデータが提供されました。そして、このデータに対し一定の実行環境内で同じPOIのIDをもつ行同士のマッチングを時間内に行うコードを提出することが求められました。
データとしては以下の情報が欠損値を含む状態で渡されました。
- 名称(name)
- 住所(country, state, city, address)
- 緯度経度(latitude, longitude)
- カテゴリ(categories, 1つのレコードに0~複数個紐づく)
- URLや電話番号、郵便番号
下記の表は私がつくったデータの見本です。「フューチャー株式会社」・「Future Corporation」・「フューチャー」はすべて同じPOIですが、欠損や表記ゆれを含んだ状態でデータセットの中に散在しています。訓練データは約110万件、テストデータは約60万件あり、テストデータではPOIが隠された状態で渡されていました。提出は各行のIDに対して同じPOIであるIDを連結したmatchesの出力を求められました。
評価はmatchesに対し (正解のラベルと予測ラベルの積集合の数) / (正解のラベルと予測ラベルの和集合の数) で求められるIoUの平均で計算されました。
この問題が解けると何がうれしいか
今回のコンペのデータは意図的にノイズを加えたデータで、実務のデータとは異なるようでした。しかし、名前や住所・商品名の表記ゆれというのは至る所で発生する問題で、今回のコンペで用いられた手法は実務でこのようなゆれと向き合うにあたって有用であると考えられます。
解法のサマリ
前回紹介したH&Mコンペでもそうでしたが、600,000 x 600,000 の組み合わせについてすべて正確に評価することは難しいです。
そこで、今回は以下の3つのパートで予測を行いました。
- 全候補から大まかに候補を絞り込むretrieval part
- 二点間のペアに対して正確な予測を行うpredict part
- ペアをグラフとして扱い後処理で精度を上げるpostprocess part
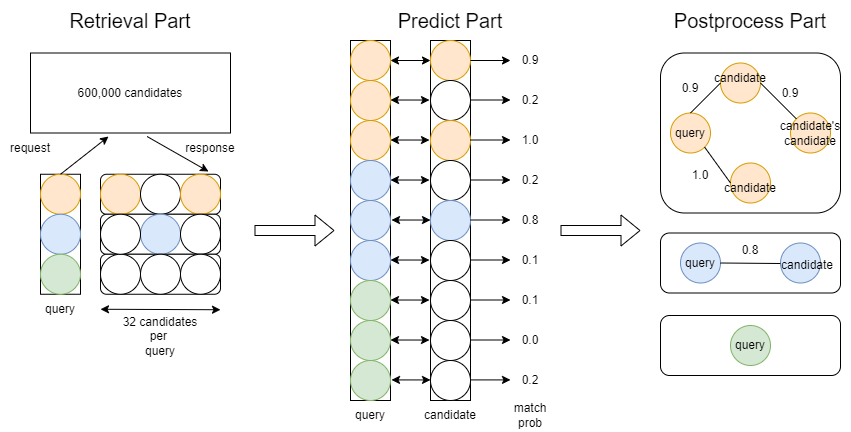
解法の詳細
上記の3つのパートに各データの前処理について加え、前処理から順に説明していきます。
前処理パート
前処理では機械学習モデルがデータを解釈しやすいよう、データをカテゴリ変数とembeddingに変換することを目的にしました。
そのために、NNが扱いやすいような形に自然言語を処理し、欠損値を埋め、無数にあるカテゴリを学習できる種類にまで減らすこと意識しました。
自然言語の前処理
文字の正規化
nameについてはたくさんの言語が混じっており、かつ日本語・中国語・タイ語のような分かち書きが必要な言語も多く混じっていました。そこでname, addressについては、文字単位で比較する用、単語同士で比較する用、NNに入れる用の三種類に向けた前処理を行いました。
「大崎一丁目2-2 アートヴィレッジ大崎セントラルタワー」であれば
| 処理番号 | 処理の目的 | 処理内容 |
|---|---|---|
| 1 | 文字単位の比較用 | Unicode正規化 |
| 2 | 単語同士の比較用 | 1.に対し分かち書きの実施、小文字化・カタカナ化、数字を表す単語の数字化(e.g. 一丁目→1丁目)、一部記号の除去 |
| 3 | NNへの入力用 | 2.に対し正規表現で[0-9a-z& ]のみが残るようローマ字化 |
の三種類の処理を行い、
| 処理番号 | 処理結果 |
|---|---|
| 1 | 大崎一丁目2-2 アートヴィレッジ大崎セントラルタワー |
| 2 | オオサキ 1 チョウメ 2 - 2 アート ヴィレッジ オオサキ セントラル タワー |
| 3 | oosaki 1 choume 2 2 aato virejji oosaki sentoraru tawaa |
となるように変換しました。
addressの欠損値の補完
addressについては3.についてのみ、NNモデルに入れるため欠損値の補完を行いました。
具体的には全レコードについて、addressがNaNでないものからhaversine距離で近傍3か所のaddressを連結して、embedding学習用の前処理としました。
地名のカテゴリ変数化と前処理
city, state, countryはカテゴリ変数として扱うことにしました。countryは欠損値を”NAN”で埋めたうえでカテゴリ変数化、cityとstateについては出現回数上位約2000を代表として平均の緯度経度を計算し、欠損値、もしくは上位2000以外のcityとstateを上位2000との近傍で埋めました。
また、cities1000という1000人以上の人口がいる市を集めたデータセットを用いて緯度経度から地名を求め、geo_nameという名前のカテゴリ変数にしました。これもまた出現数上位2000のどれかに割り振られるよう調整を行いました。
categoriesの前処理
categoriesは1つの列にカンマ区切りで複数のカテゴリが入っていました。そこでカンマ区切りで分割し、RaggedTensorとして扱いました。また、categoriesに何も入っていない場合は”nan”のカテゴリで補完しました。後述のカテゴリ予測モデルを作った後は”nan”の行に予測を行い、カテゴリを1つ追加しました。
URL/Phoneの正規化
URLについてはurllibでネットワーク上の位置を示す部分抽出しました。
電話番号は国際通話用の+81等が付いた形式とそうでない形式が混じっていたため、phonenumbersを用いて正規化を行い統一しました。
embeddingの作成
サブワードへの分割
3で処理したローマ字についてSentencePieceでサブワード分割を学習しました。サブワードは単語をさらに分割したもので、例えば「競プロer」という未知の単語が出てきた際、「競プロ」をする「er」なんだなと解釈できるようになります。単語をすべて[0-9a-z& ]の範囲にしたのもsentence pieceで使える語彙をより有意義なものにするためです。nameとaddressについてそれぞれ32000のサブワードで表すようSentencePieceを別々に学習しました。
embeddingの学習
学習にはname, address, categoriesと、カテゴリ変数にしたcountry, city, state, geo_nameを用い以下の3つのタスクを行いました。
- 同じname内の単語の共起情報からembeddingを学習するSkip-Gramベースのタスク
- categories以外からcategoriesを予測するmetric learningタスク
- それぞれのembeddingをConvMixerのように混ぜてmix embeddingとし、SimCSEで自己教師あり対照学習を行うタスク
1.と3.のタスクについてはバッチ内の他サンプルを負例とするのほかに、距離の近さを辺の重みとしたrandom walkによるnegative hard samplingによって、難易度の高い負例をサンプルごとに用意しました。これによりembeddingの質が大きく向上しました。
なお、1のSkip-Gramタスクの学習はコンペ中W2V & haversine NN baseline[Training/Inference]というノートブックで公開しています。
embeddingの評価
embeddingの評価としてデータごとに近傍を取得し、precision@16 (≒ maxIoU)を計算して評価を行いました。
ベースラインとしてUniversal Sentence Encoderでのコサイン類似度の近傍と、haversine距離の近傍を用意しました。
| 近傍の取得方法 | precision@16 | precision@32 |
|---|---|---|
| USE name embedding | 0.7582 | 0.7879 |
| haversine distance | 0.8946 | 0.9160 |
でしたが、上記の3つのタスクを解くことにより以下のようなembeddingを得られました。
| 近傍の取得方法 | precision@16 | precision@32 |
|---|---|---|
| name embedding | 0.7738 | 0.8061 |
| address embedding | 0.8690 | 0.8811 |
| mix embedding | 0.8997 | 0.9120 |
nameに関しては、Universal Sentence Encoderよりも高いprecisionで、非常に質の高いembeddingを作成できました。
K-means++ & Word Tour
embeddingをLightGBMのようなGBDTが解釈しやすい形にするため、球面K-means++とWord Tourを組み合わせた手法で1次元に落とし込みました。Word Tourはembedding間の距離を元に巡回セールスマン問題(TSP)を解き、その順番でembeddingを並び替えるという手法で、これにより1次元上で距離の近い位置に似たembeddingが並ぶようになります。
これは決定木系の分割手法と相性がよく、Food101のデータセットでの検証を行った際はPCAでの圧縮よりもはるかに高パフォーマンスに次元を圧縮できました。また、Food101のラベルについてWord Tourを実施すると、ラベルは以下のように並ぶため、決定木との相性の良さがわかると思います。
eggs_benedict |
巡回セールスマン問題はNP困難な問題であるのですが、私はこれに対し、K-means++で頂点数を減らしたうえでOR-Toolsを用いることで手軽な実装で現実的な時間内にTSPの近似解を求めました。また、K-meansについてはcategoriesやnamesのembeddingだけでなくlatitudeとlongitudeでもK-means++を行いTSPで並び替えました。city, state, geo_nameなどのカテゴリもCountEncodingの他にhaversine距離に基づいてTSPを計算し並び替えを行いました。
K-means系の特徴量としては、Word Tourで並べなおしたK-meansのクラスタラベルと、各クラスタ中心までの距離をデータに紐づけました。
retrieval パート
概要
retrieval パートではGPU上で全組み合わせの計算ができる高速で簡単な手法で、取りこぼしが無いようモデルを構築しました。
候補生成
作成したembeddingやhaversine距離を元に1つのサンプルにつき32の候補を作成しLightGBMでの学習・予測に用いました。
候補生成は以下の5つの方法を用いました。これらはTensorFlowを用いてGPU上で計算を行ったので、全組み合わせについて愚直に計算できました。
| 番号 | 処理の種類 | 取得数 |
|---|---|---|
| 1 | 二点間のlatitude, longitudeから計算するhaversine距離による近傍 | 4 |
| 2 | haversine距離とembeddingのコサイン類似度を用いた重回帰による近傍 | 12 |
| 3 | nameの単語単位での一致度による近傍 | 4 |
| 4 | nameの文字単位での一致度による近傍 | 8 |
| 5 | nameのembeddingのコサイン類似度による近傍 | 4 |
haversine距離とembeddingのコサイン類似度を用いた重回帰による近傍
2についてはhaversine距離の対数と各embeddingのコサイン類似度から重回帰を行いました。重回帰の学習はロジスティック回帰で行うよりも、正例がより高いスコアになるようランク学習を行うことでよりよい重回帰の係数を得ることができました。
Bag of Words一致度による近傍
3, 4については単語単位、文字単位でのBag of Wordベクトルを作成し、コサイン類似度・precision・recallをもとめました。
precision・recallについては「フューチャー株式会社」をクエリ、「フューチャー」をターゲットとして文字単位で比較した際、
共通部分は「フューチャー」なので、以下のようになります。
- 文字単位でのprecisionは len(フューチャー) / len(フューチャー株式会社)で0.6、
- 文字単位でのrecallは len(フューチャー) / len(フューチャー)で1.0
このような手法を用いたのは、POIのペアとして「〇〇コンビニ」と「〇〇コンビニ XXX店」のような組み合わせを多く見たからです。
Bag of Wordsベクトルをl2正規化した際のコサイン類似度と、precision, recallの大きい順に候補を取得し、同率の場合は重回帰のスコアで並べなおして上位を取得しました。
候補生成の精度
この5つの手法で非対称な候補生成を行った結果、
| 近傍の取得方法 | maxIoU(≒precision@32) |
|---|---|
| retrievalのみ | 0.9778 |
| retrieval+postprocess | 0.9935 |
まで高めることができました。
predict パート
概要
predict パートでは、ある地点(query)とその候補(candidate)の1:1の間の特徴量を追加し、LightGBMで二値分類を行いました。
今回のデータはPOIのペアを持たないデータも多く、False Positiveが悪影響を与えやすかったので、それらを防ぐ工夫も検討しました。
特徴量生成
query, candidateのそれぞれのカテゴリとword tourの一次元の距離
IDごとにそれぞれのカテゴリやクラスタを計算し、queryとcandidateの両方のIDとマージしました。
また、Word Tourで求めたクラスタラベルについては1次元上での距離を計算しました。
name, addressについてのゲシュタルトマッチング、レーベンシュタイン距離、ジャロ・ウィンクラー距離
これらは文字列の類似度を計算する古典的な手法で、Python内蔵のdifflibや、Levenshteinといったライブラリで計算できます。CPUでの計算なので時間はかかりますが、有効な特徴量であったため、3種類の方法で加工したname, addressとname, addressの数字部分だけを抽出したものをこれらの手法で類似度を計算しました。
name, addressについてのROUGE-N, ROUGE-L
ROUGEは文章要約タスクの良しあしを測るのにつかわれることが多い手法で、文章同士について一定の分割をした後、共通部分のprecision, recall, F値を計算します。ROUGE-NはN-gram、ROUGE-LはLCSを用いてROUGEを計算します。前者はTensorFlowのRaggedTensorを活用、後者はtensorflow-textにあるrouge_l関数を用いてGPU上で高速に計算しました。
学習・予測
学習データ
学習はLightGBMを用い、特徴量の評価時はpidで分割した5foldでの計算、提出時は全データを用いてiteration数を決め打ちで学習を行いました。
sample weight
sample weightは他のPOIのペアをすべて当てられたうえで予測を間違えたときのIoUの損失をweightとしました。これは、前述のとおりTrue NegativeよりもFalse Positiveの方がスコアに対する悪影響が大きいからです。weightは正例で平均して0.8、負例で1.0になりました。
dev_data_df["weight"] = np.where(dev_data_df["label"], |
LightGBMのハイパーパラメータ
LightGBMの基本的なハイパーパラメータはnum_leavesが2^12が最適で、学習率は0.1と高く、2000iterationsまで学習を行いました。これでもpidで分割したバリデーションデータでのAUCが上昇し続けました。
細かいパラメータとして、”max_bin_by_feature”を設定しました。LightGBMは学習の前に連続値をヒストグラムに変換し、最大でも255のbinにしてしまうのでそれ以上のカテゴリ数があると押しつぶされてしまいます。そこで、K-meansのラベルとcategoriesのラベルは255より大きな値になるように一部のカテゴリのmax_binを緩和するよう設定しました。”bin_construct_sample_cnt”は初期のヒストグラムを作るときのパラメータで、これを小さくすると精度が少し下がる代わりに学習前のヒストグラム構築におけるメモリと時間を節約できます。学習環境によってこれを変更しました。すべてのパラメータは以下の通りです。
lgb_params = { |
予測
予測は500iterationのモデルを用いた時点で予測時に合計1時間以上かかることが分かったため、cumlのForestInferenceを活用しGPU上での予測を行いました。これにより100倍近くの高速化がされ、2000, 3000iterationのモデルを用いても実行時間内に予測を終えられました。LightGBMはfloat64で境界値やleaf valueを持つ一方、ForestInferenceはfloat32で計算を行うので若干の精度低下はあるものの、それ以上の高速化の恩恵を受けたため採用しました。
Postprocess パート
Postpeocessパートでは、グラフとして予測されたペアをつなげることで拾いこぼしを拾って精度を上げました。
概要
ペア同士の予測値を出した後は、一定の閾値を元にUnionFindで頂点同士を連結しグラフを構築しました。
各グラフに対して、NetworkXを用い、媒介中心性を元にした辺の排除を行った後、頂点間の距離が2以内の頂点のみを予測のペアとして出力を行いました。
テクニック集
メモリ増加のテクニック
Kaggleにコードを提出する際、実行には以下の2つの環境を選べます。
- 4CPU 16GBRAM 9時間以内
- 2CPU 13GBRAM 1GPU 16GBRAM 9時間以内
今回のコンペにとってはメモリが少なく、OOMを起こしやすい実行環境でした。
そこで私は以下の2つの工夫をしました。
- 予測は10000行単位で特徴量生成→予測の流れで行う。
- BoWの行列はTensorFlowのRaggedTensorやSparseTensorに変換し、embeddingと一緒にGPU RAMに配置する。
embeddingをGPUに配置することで実質29GBのメモリを使えることになり余裕のある推論ができました。
高速化のテクニック
また、embeddingのコサイン類似度やROUGEの計算はGPUで行い、lgbmの推論もForestInferenceによるGPUでの推論を活用することで高速化できました。これのおかげで提出から結果が出るまでの時間はおよそ5時間で、4時間の余裕がありました。これを有効活用できなかったのは残念ですが、余裕をもって特徴量生成に集中できました。
各言語処理のテクニック
中国語の分かち書きにはzh_segmentation、タイ語の分かち書き・ローマ字変換にはPyThaiNLPを用いました。特にPyThaiNLPは機能とドキュメントが充実しており、タイ語の処理にはとても使いやすいなと感じました。
日本語の分かち書き・読み方の取得・ローマ字化はSudachiとPyKakasiを用いていて、特にSudachiについては日本語の表記ゆれの正規化まで取得できたのは利点でした。また、今回のタスクではSentencePieceの学習とSudachiのA mode(UniDic単位相当)の分割が相性良かったです。
試したが効かなかったもの
- Universal Sentence Encoderを用いたembedding特徴量の追加(LBが悪くなった)
- Sentencepieceについてname, addressを同時に学習(precisionが下がった)
- name, address embeddingへの畳み込みの追加(precisionが下がり、かつ遅くなった)
- city, stateなどあまり質の高くないembeddingへのWord Tour(意味のある並びを得られなかった)
- Word Tourがうまくいくかはembeddingの質に大きく左右されます。
- 転置インデックスを用いた候補生成(Pure Python実装だと遅かった)
- LightGBMのTensorFlow実装(ForestInferenceを使う方がはるかに効率的だった)
リーク問題について
今回のコンペは参加者が推論を行うコードを提出すると、参加者が直接見ることのできないtestデータで評価を行われPublicとPrivateのリーダーボードが更新されました。しかし、コンペ終了後運営のミスによってtestデータの67%がtrainデータと一致していた可能性が参加者から指摘されました。(trainデータのnameと緯度経度が完全一致するレコードについてLB上で検証が行われました。)7/19時点で全提出について重複を排除したデータについて再評価が行われ、一部のチームに追加の賞金が支払われることが決まりました。
このリークにより金圏付近までの解法の良しあしの比較が困難になってしまいました。ただ、リークがあったにしろ上位の解法は納得のできるもので、私自身も自身の解法は他にも活用できる自信を持っています。このリークによって上位の解法の価値がなくなったわけではないことについて、理解が広まればいいなと考えています。
謝辞
今回のコンペはtakapyさん、Shotaさん、visionさん、Kurutonさんと一緒に参加しました。チームで協力してディスカッションやコードの整備、励ましあいを行ったおかげで、今回金メダルを獲得できたと思っています。まずはチームメンバーに強く感謝したいと思っています。
また、今回の解法に用いた技術やライブラリ、例えばSentencepieceやOR-Toolsは会社の勉強会等で教わり、SimCSEやWord Tourは日本語の勉強会で発表されたものを聞いて理解を深めていました。自分も積極的に発表を続け恩返しをしたいと思っています。
最後に、今回のコンペで一緒に戦い、ディスカッションを行ってくれたライバルたちにも感謝を込めて、本記事の終わりとさせていただきます。
連載の次の記事は 澁川さんのRedisのジオメトリ機能です。お楽しみに!
リンク
- 7th place solution(discussion): コンペ終了後に投稿したdiscussion、解法について質問があればこちらのdiscussionへどうぞ
- 7th place solution inference(inference notebook): コンペで提出を行った推論用notebook
- Let’s discuss how to correspond to the name and address of each language!: 各言語ごとの自然言語の前処理についてより詳しく説明したdiscussion
- W2V & haversine NN baseline[Training/Inference]: コンペ中に公開したsentencepieceを用いた候補生成のnotebook
- word tour experiment: word tourをFood101で実験したnotebook