夏の自由研究ブログ連載2022 の10本目です。
はじめに
TIG 岸下です。業務でGKE(Google Kubernetes Engine)を利用することがあるのですが、Kubernetesの挙動や仕組みなど如何せん理解が難しいです。
そこで今回は、自分の手でイチからKubernetesを構築することで勉強しようと思ったのが本記事のモチベーションです。
ちょうど自宅にRaspberry Piが3台あったのでRaspberry Piでクラスタを構築していこうと思います。基本的には以下の記事を参考に設定を行っていき、自分の理解を深めるために解説を挟みながら書いていこうと思います。
参考:RaspberryPi 4 にUbuntu20.04 をインストールして、Kubernetes を構築してコンテナを動かす
今回Kubernetes構築するにあたって用意したもの
- Raspberry Pi3 Model B(メモリ1GB)
- Raspberry Pi4 Model B(メモリ4GB)
- Raspberry Pi4 Model B(メモリ8GB)
- SDカード(64GB)x 3
- 5ポートスイッチングハブ(BUFFALO LSW6-GT-5EPL/NBK)
- LANケーブル x 4(CATはバラバラ)
- キーボード
- マウス
各種Raspberry Piの電源はコンセントから取っています。
ラズパイの設定
- 3台共通のものと、3台それぞれで設定する内容があるので注意して下さい。
OS
- OS: Ubuntu 20.04LTS(3台共通)
Raspberry Pi Imagerを使うと簡単にSDカードへOSを焼くことが出来ます。
SDカード3枚全てにUbuntu 20.04LTSを焼きます。
Kubernetesのバージョン
- v1.25.0
初期設定(3台共通)
ラズパイにOSをインストールしたSDカードを差し込み、パッケージを最新版にしておきます。
sudo apt update |
ネットワーク周り
物理的な構成図
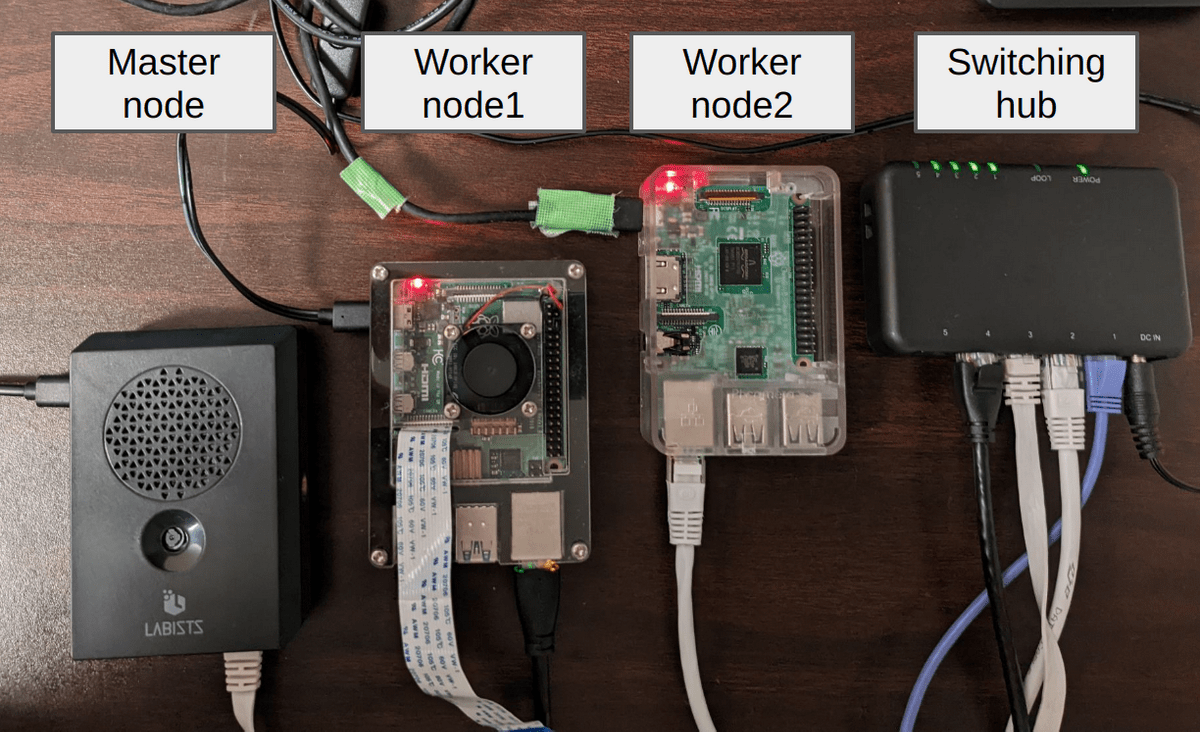
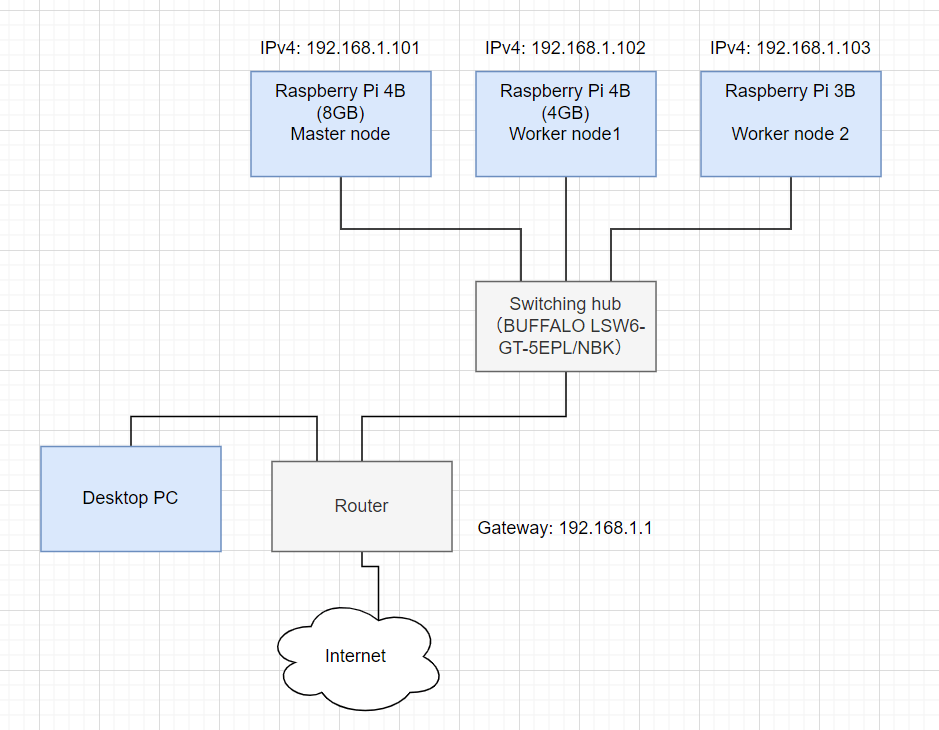
※Desktop PCはラズパイ達とSSHするために繋いでいます。Kubernetesの構成には必要ありません。
| ラズパイ | 役割 | IPアドレス |
|---|---|---|
| ラズパイ4B(8GB) | マスター | 192.168.1.101 |
| ラズパイ4B(4GB) | ワーカー(1) | 192.168.1.102 |
| ラズパイ3B | ワーカー(2) | 192.168.1.103 |
で構成しております。
ネットワークの設定(ラズパイ3台それぞれで)
上記のIPアドレスを各ラズパイに割り振って固定化します。
以下のファイルを作成します。
sudo vi /etc/netplan/99-network.yaml |
network: |
作成したら、適用します。
sudo netplan apply |
SSHの設定(デスクトップPC)
IPアドレスの固定化が完了したので、ここからはSSHで操作を行うようにします。
※SSHは利用しなくても設定できますが、3台分のラズパイのディスプレイを切り替える作業のストレスが無くなります。
VSCodeのRemote SSHを用意
デスクトップPCにてVSCodeをインストールして、「拡張機能」からRemote - SSHをインストールしてください。

SSH構成ファイルを用意
VSCodeウィンドウ左下の「><」をクリックして、「SSH構成ファイルを開く」からconfigを開いて以下のように設定して保存します。
Host rpi4_8 |
- Host名も好きに変更して頂いて構いません。
- IPアドレスは自宅の環境に合わせて適宜変更して下さい。
- User名を変更している場合も適宜変更して下さい。
各ラズパイに接続する
VSCodeウィンドウ左下の「><」をクリックして、「ホストに接続する」からホスト名を選んで接続します。
初回は接続キーの登録が行われるため、キーが表示されたら「続行」を押し、あとはログイン用のパスワードを入力すると接続できます。
複数台同時に接続できるので、3画面分用意しておけばデスクトップPC側からラズパイの操作が可能となります。
ホスト名の変更(ラズパイ3台それぞれ)
ここからはまたラズパイの操作となります。
以下のホスト名を割り振っていきましょう。
| ラズパイ | 役割 | ホスト名 |
|---|---|---|
| ラズパイ4B(8GB) | マスター | mas01.example.com |
| ラズパイ4B(4GB) | ワーカー(1) | work01.example.com |
| ラズパイ3B | ワーカー(2) | work02.example.com |
sudo hostnamectl set-hostname mas.example.com # 各々のラズパイでhostnameは変える |
/etc/hostsの設定(ラズパイ3台共通)
ホスト名とIPアドレスを対応させるために、etc/hostsに以下の内容を追記します。
sudo vi /etc/hosts |
# ... |
これによって、ネットワークの名前解決ができるようになります。
余談
以下はKubernetesの設定とは関係のない話なので余談ですが、ターミナル上で
ssh work01.example.com |
と打てば、192.168.1.102に接続できます。
これはDNS(Domain Name Service)でも同じことが行われています。
DNSについては、ぜひTIG西田さんのNW入門を読んでみてください。ハンズオン形式でわかりやすいと思います。
IPv6の停止(ラズパイ3台共通)
IPv6は今回利用しないので停止します。sysctl.confをvimで開きます。
sudo vi /etc/sysctl.conf |
下記設定を最後の方へ追記します。
設定を1にすることで停止となります。
#... |
余談
また余談ですが、最近はKubernetesでIPv4/IPv6デュアルスタックが利用できるそうです。
参考:IPv4/IPv6デュアルスタック
IPv4/IPv6デュアルスタックを利用するとIPv4とIPv6のアドレスの両方をPod及びServiceに指定できるようになります。
なるほど、わからんという感じです。
IPv6自体はIPv4アドレスの枯渇問題を解決するためのプロトコルで、他にもIPv4に対する不満の多くを一挙に解消しようとしています(マスタリングTCP/IP入門編 P.171)。
デュアルスタック機能によって、お互いは仕様の異なるプロトコルスタックですが共存させる仕組みで、やはりどちらのプロトコルも使えるのが美味しいポイントとなるのでしょうか。利用する機会があればまた調べて見ようと思います。
timezone, keymapの変更(ラズパイ3台共通)
タイムゾーンを日本に、keymapを日本語にします。
# タイムゾーンの変更 |
Kubernetes周り
ここからKubernetes周りの設定を行っていきます。
基本はkubeadmの設定に沿っていきます。
iptablesがnftablesバックエンドを使用しないようにする(ラズパイ3台共通)
nftablesバックエンドは現在のkubeadmパッケージと互換性がありません。(ファイアウォールルールが重複し、kube-proxyを破壊するためです。)
だそうです。
# レガシーバイナリをインストール |
参考:kubernetes: iptablesがnftablesバックエンドを使用しないようにする
Dockerのインストール(ラズパイ3台共通)
参考:Install Docker Engine on Ubuntu
ターミナルにて以下のコマンドでインストールします。
sudo apt-get -y install \ |
dockerをroot権限無しで実行するためにdockerグループへユーザーを割り当てます。
sudo adduser ubuntu docker |
グループ割当を適用するために、一度ログオフ or 再起動をしましょう。
Dockerのバージョンを確認します。
docker version |
dockerの動作確認にhello-worldコンテナを使います。
docker run hello-world |
kubeadm、kubelet、kubectlのインストール(ラズパイ3台共通)
参考:kubeadm、kubelet、kubectlのインストール
以下のコマンドでインストールします。
sudo apt-get update && sudo apt-get install -y apt-transport-https curl |
そもそもこのkubeadm、kubelet、kubectlは何に使われるのでしょうか?
kubeadm
参考:Kubeadm
- Kubeadmは
kube initやkubeadm joinといったコマンドを提供するために作られたツールである。 - 最低限実行可能なKubernetesクラスタを立ち上げるために必要なアクションを実行する。
- Kubeadmの設計上、クラスタの立ち上げのみにフォーカスを当てており、マシンへのプロビジョニングまでは考えていない。
- 同様に、Kubernetesダッシュボードのような種々の便利なアドオンをインストールしたり、モニタリング、クラウド固有のアドオンもスコープ外である。
- 理想的には全てのデプロイのベースとしてkubeadmを使うことで、適合するクラスタの作成が容易になる。
クラスタの立ち上げまではkubeadmが面倒見てくれて、残りのツールとか設定は各々よしなにやりましょうという感じでしょうか。
kubelet
参考:kubelet
kubeletを理解する前に、クラスターの全体像をまず理解する必要がありそうです。
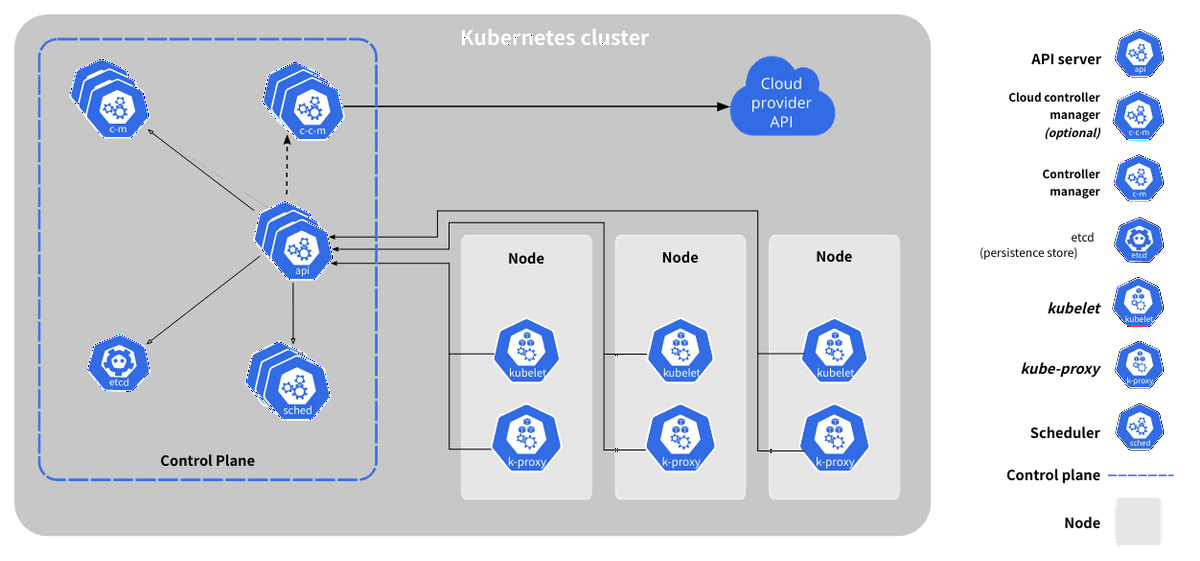
画像引用先: Kubernetesのコンポーネント
グレーの箇所はクラスターになり、先程紹介したKubeadmによって提供されます。
- Control Plane(マスターノード)に対してNode(ワーカーノード)がぶら下がる。
- 今回で言えば、マスターノードであるラズパイ
master01にワーカーノードであるworker01、worker02がぶら下がる。
- 今回で言えば、マスターノードであるラズパイ
- マスターノードはワーカーノードとPodを管理する。
- ワーカーノードはアプリケーションのコンポーネントであるPodをホストする
- Podは1つ以上のコンテナのグループを持ち、Kubernetesにデプロイできる最小単位になる
- 種々のアプリケーションはPodの中のコンテナ上で動作
で、kubeletですが図を見ると各ワーカーノードの中にkubeletが存在し、ワーカーノードの中で使われることがわかります。どこで使われるかがわかったところでkubeletの機能についてまとめていきます。
- kubeletは、各ノード上で実行される主要な”ノードエージェント”
- ”エージェント”なので各ノードの中での仲介者で、Podの起動・管理を行う
- kubeletは、PodSpecの観点から動作する
- PodSpecはPodに関する様々な情報(例えばコンテナの名前やimage)を載せたYAML or JSONファイル
- PodSpec通りにコンテナが実行・動作されているかを確認することでPodを管理する
kubeletは各Pod内の管理・仲介者と考えておくとよさそうです。
kubectl
参考:kubectlの概要
kubectlはKubernetesクラスターを制御するためのコマンドラインインタフェース(CLI)です。ターミナルからKubernetesクラスターを制御するのに使われます。
cgroupでmemoryの有効化(ラズパイ3台共通)
Kubernetesを利用する際に、cgroupのmemoryを有効化する必要があります。
はて、cgroupとは何なんでしょうか。
Kubernetes内でのcgroup
参考:Linuxカーネルのコンテナ機能[2] ─cgroupとは?(その1)
参考:Kubernetes で cgroup がどう利用されているか
cgroupはControle Groupの略で、プロセスをグループ化して、そのグループ内に存在するプロセスに対して共通の管理を行うために使われます。例としては、ホストOSが持つCPUやメモリなどのリソースに対して、グループごとに制限をかけることができます。
kubeletの説明の中でPodSpecの話が出てきました。PodSpecのファイルではPod内のコンテナに関する情報を書くわけですが、この中でCPUやメモリの量も制限する(resourcesのlimits)ことが可能です。正にここでcgroupが使われていて、ラズパイの計算リソースに対して、例えば計算リソースをそこまで必要としないPodに対しては制限をすることで、ラズパイのリソースを無駄に食い潰さないようにできます。
有効化の設定
さて、cgroupのメモリーを有効化していきます。
以下のコマンドで確認すると、初期では無効化(末尾が0)されています。
cat /proc/cgroups | grep memory |
boot/firmware/cmdline.txtを開き、cgroup_enable=cpuset cgroup_memory=1 cgroup_enable=memoryを追記します。
sudo vi /boot/firmware/cmdline.txt |
elevator=deadline net.ifnames=0 console=serial0,115200 dwc_otg.lpm_enable=0 console=tty1 root=LABEL=writable rootfstype=ext4 rootwait fixrtc quiet splash cgroup_enable=cpuset cgroup_memory=1 cgroup_enable=memory |
※改行はありません。既に書かれている文の末尾にスペースを空けて追記する形となります。
変更を適用するために再起動します。
sudo reboot |
memoryが有効化されていることを確認します。
cat /proc/cgroups | grep memory |
Kubernetesクラスターの作成
コントロールプレーンノードの初期化(マスターノードのラズパイのみ)
先程も出てきましたが、コントロールプレーンノード=マスターノードです。
マスターノードにて操作を行っていきます。
sudo kubeadm init --apiserver-advertise-address=192.168.1.101 --pod-network-cidr=10.244.0.0/16 |
apiserver-advertise-address- このオプションを利用して明示的にAPIサーバーのadvertise addressを設定します。
- 明示的に指定しない場合はデフォルトゲートウェイに関連付けられたネットワークインタフェースを使用して設定されます。
pod-network-cidr- Flannelを使用する場合、こちらを指定する必要があります。
- Flannelはノード間をつなぐネットワークに仮想的なトンネルを構成することで、クラスター内のPod同士の通信を実現しています。
/16と広めに設定します(GitHub - flannel-io/flannel)。
初期化後、kubeadm join 192.168.1.101:6443 --token ...という出力が出たら、どこかのテキストエディタにコピーしておきます。
このコマンドはワーカーノードを追加する際に利用します。
もしinit時にcontainer runtime is not runningというエラーが出た場合
参考:Kubeadm unknown service runtime.v1alpha2.RuntimeService #4581
上記ページにエラーについて載っており、内容を読むと以下のように書いております。
In the config.toml file installed by package containerd.io there is the line disabled_plugins = [“cri”] that am guessing creating the issue.
パッケージcontainerd.ioからconfig.tomlをインストールした際に今回のエラーを引き起こす行があるようです(確証ではないみたい?)。
解決方法はマスターノードにて以下のコマンドを実行し、configファイルを削除します。
そして、containerdを再実行します。
# configファイルを削除 |
環境変数と入力補完の設定(マスターノードのラズパイのみ)
kubectlをroot以外のユーザーでも実行できるようにするために、以下の設定を行っていきます。
# ホームディレクトリに.kubeディレクトリを作成 |
Flannelの設定(マスターノードのラズパイのみ)
先程もちょろっと説明しましたが、Flannelはノードを跨いでコンテナ同士が通信できるようにするPodネットワークアドオンになります。
コンテナにはIPアドレスが付与されるのですが、Internal IPなのでそのままだとノードを跨いでコンテナ間で通信できません。これを解決するために、Flannelによってノード間をつなぐネットワークに仮想的なトンネル(オーバーレイネットワーク)を構成することで、Kubernetesクラスター内のPod同士の通信(Podネットワーク)を実現しています。
参考:Kubernetes完全ガイド 3.3.3 Flannel
kubectl apply -f https://raw.githubusercontent.com/flannel-io/flannel/master/Documentation/kube-flannel.yml |
flannelが動作しているか確認します。
kubectl get pods -n kube-flannel |
ロードバランサーのインストール(マスターノードのラズパイのみ)
こちらを参考にして作っているので、同様にMetalLBをインストールします。
MetalLB, bare metal load-balancer for Kubernetesを参考にインストールします。
kubectl apply -f https://raw.githubusercontent.com/metallb/metallb/v0.13.5/config/manifests/metallb-native.yaml |
起動の確認を行います。
kubectl get pod -n metallb-system |
ワーカーノードをクラスタにジョイン
先程、テキストエディタにコピーしておいたコマンドを実行します。
※sudo忘れに注意
sudo kubeadm join 192.168.1.101:6443 --token y2grpy.nbvcyr1em9o5aigj --discovery-token-ca-cert-hash sha256:3e9ef8910b95e0a366041c1e156b7cbd6802df4c857cd53ad59bbba631749983 |
ちゃんとワーカーノードがジョインされたか確認してみましょう。
kubectl get nodes |
ROLESがデフォルトになっているので変更します。
# work01 |
これでクラスタの完成です。遂に我が家にKubernetesがやって来ました。
もしコピー&ペーストを忘れた場合
以下のコマンドで発行したトークンを確認することが出来ます。
kubeadm token list |
有効期限が切れてしまった場合は以下のコマンドで再発行します。
sudo kubeadm token create |
CA証明書のhashも必要なので、以下のコマンドで出力させます。
openssl x509 -pubkey -in /etc/kubernetes/pki/ca.crt | openssl rsa -pubin -outform der 2>/dev/null | openssl dgst -sha256 -hex | sed 's/^.* //' |
Kubernetesでコンテナを動かす
yamlファイルの作成とapply
Dockerが動作しているホストのHostnameを表示するNginxコンテナをお借りして、Metal-LBででロードバランシングします。
yamlはこちらを参考にさせて頂いております。
MetalLB v0.13以降はConfigMapでの設定が廃止され、Custom Resource Definitions(CRD)での設定が推奨になったようで、MetalLBの部分だけv0.13に適合するように書き換えます。
apiVersion: v1 |
参考:
以下のコマンドでリソースを作成します。
# リソースの作成 |
動作確認
色々確認していきましょう。
# ポッドの確認 |
ちゃんと2つ立ち上がってます🙌
サービスを見ることでロードバランサーの外部IPを取得し、アクセスしてみましょう。
kubectl get svc -n nginx-prod |
アクセスするたびに接続先が変わっていることから、ロードバランシングされていることが見受けられます。
同じネットワーク内につながっているPCであれば、ブラウザから上記アドレスへアクセスすることも可能です。
可用性を体感する
こちらの記事同様、ワーカーを物理的に落としても外部IPへアクセスできることを確認します。
ワーカーノード(1)に接続されたLANケーブルを抜いてアクセスしてみます。
curl 192.168.1.210:8080/index.sh |
次に、ワーカーノード(1)を繋ぎ直し、ワーカーノード(2)に接続されたLANケーブルを抜いてアクセスしてみます。
(ワーカーノード(1)を繋いでから接続できるようになるまで少し時間がかかります)。
curl 192.168.1.210:8080/index.sh |
このように、どちらかのワーカーが落ちても外部IPアドレスにアクセスでき、可用性を体感できました。
ロードバランサー自体はアクセス先を2つのワーカーに振り分けることで負荷を分散させる役割を持っていますが、このようにアクセス可能なワーカーのみに振り分けることも可能です。
最後に2つのワーカーノードの接続を外してみます。
curl 192.168.1.210:8080/index.sh |
当然ですが、アクセスできないことが確認できます。
再起動してみる
クラスターを止めずに全ノード再起動して、再度確認してみます。
# nodeの状態を確認する |
このように、ラズパイ自体を再起動してもまたクラスタが立ち上がっていることが確認できます。
まとめ
ラズパイを使ってKubernetesのクラスタを作成し、ロードバランシング・可用性を体感できました。クラウド上でゴニョゴニョ行われていることに対して、物理的な構成から作ってみることで解像度が上がった気がします。また、Kubernetes周りで使われている技術(cgroup, kubeadm, kubelet, flannel, …)について調べながら進めることで、Kubernetesに対して理解が進みました。
今回、コンテナの構成に関しては自分で作らなかったので、次はWebアプリでも作ってデプロイしてみたいと思います。