この記事は前編の続きです。この記事では、作成したフォーマッタの実装について説明します。
作成したフォーマッタの処理の流れ
前編でも示しましたが、今回作成したフォーマッタの処理の流れを再度示します。
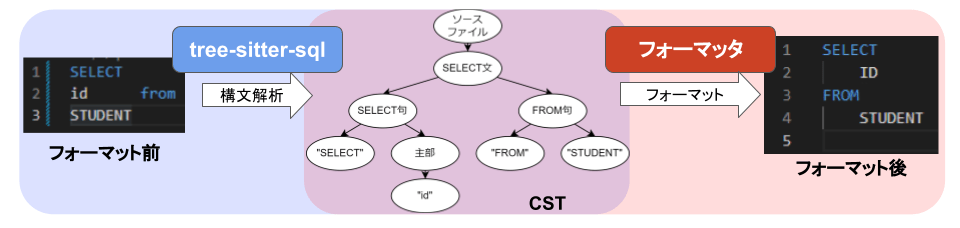
使用した技術
フォーマッタの実装にはRustを使用し、構文解析にはtree-sitter-sqlを使用しました。
Rust

高速で、かつwasm-packなどのライブラリを用いてWebAssembly化できることから、様々なプラットフォームで動作するため、Rustを採用しました。
tree-sitter-sql
tree-sitterで出力されたSQLパーサです。tree-sitterとは作成した文法ファイルからパーサを自動生成するパーサジェネレータの1つです。一般的なパーサライブラリは抽象構文木(AST)を出力するのに対して、tree-sitter-sqlは具象構文木(CST)を出力します。ASTが意味のない情報(例: コメントや多重括弧など)を保持しないのに対して、CSTはそのような情報も保持します。
今回作成するフォーマッタではコメントや括弧の情報を使用したいため、CSTを出力できるtree-sitter-sqlを採用しました。
フォーマット用の構造体の作成
行末に現れるコメントの取得や縦揃えの機能を実現するために、tree-sitter-sqlから得られたCSTをそのまま使用するのではなく、CSTのノードをDFS(深さ優先探索)で辿り、フォーマット用の構造体を用いて再構成しました。
次のような構造体を定義しています。
// 文 |
実装した構造体について、一部抜粋して説明します。
Clause構造体
// 句 |
Clause構造体は句(e.g., SELECT句、FROM句)に対応した構造体です。現状対応している構文に現れる句は、いずれも以下のような構造をしています。
Keyword |
e.g., SELECT句
SELECT /* キーワード */ |
そのため、フィールドにはキーワードと本体(Body)を保持させています。
詳細は割愛しますが、Bodyに後述するAlignedExprを複数保持させることで、複数行の式の縦揃えを実現しています。
AlignedExpr構造体
// エイリアス式、演算式、行末コメントを含む式 |
AlignedExpr構造体は、現状揃えたいAS句や比較演算子、行末コメントを含む式に対応しています。
例えば、以下のSQLを考えてみます。
SELECT |
今回作成したフォーマッタでは、このようにASと行末のコメントの位置を縦揃えする必要がありました。そこで、揃える対象となるASや=などの比較演算子、行末のコメントを持つ行(式)をAlignedExpr構造体で表現しています。AlignedExpr構造体は、左辺(lhs)、演算子(op)、右辺(rhs)と行末コメント(trailing_comment)をフィールドに保持しています。
上の例の学籍番号の行は、左辺がSTD.ID、演算子がAS、右辺がSTD_ID、そして行末コメントが-- 学籍番号であるようなAlignedExprのインスタンスです。
フォーマットを行う際には、左辺や右辺の長さを参照して縦揃えを実現しています。具体的な縦揃えの方法は後述します。
コメントノードの処理
コメントの情報はCST上に保持されますが、直感的でない位置に現れてしまう場合があります。そのため、それに対応する処理を行います。例として以下のようなSQL文を考えます。
SELECT |
SELECT |
これらのSQLをtree-sitter-sqlでパースすると、どちらも以下のようなCSTが構築されます。
.png)
これは、パース時にコメントの位置等を考慮しておらず、コメントの意味まで解釈できないためです。
下のSQLはこの木構造で問題ありませんが、上のSQLでは、GRADEとその末尾コメントである-- 成績がまとまっていたほうが直感的です。そこで、私たちのフォーマッタではCSTを走査する段階で、行末コメントとその行の式を対応付けています。
これからその対応付けの方法について説明します。例として以下のSQLを考えます。
SELECT |
このSQL文をtree-sitter-sqlでパースすると、以下のようなCSTが出力されます。
.png)
出力されたCSTではGRADEのコメントである-- 成績がファイルノードの子ノードになってしまっています。パーサーではコメントの意味まで解釈できないため、このような直感的でない木構造になってしまうことがあります。
この離れた位置にある2つのノードを同じAlignedExpr構造体に格納する方法について説明します。
まずCST上のGRADEノードまで深さ優先探索順に辿ります。
.png)
GRADEノードを辿り終わった時点での自作構造体は以下のようになります。
.png)
この状態で次のノードへ辿ると、コメントノードが出現します。
_2.png)
コメントノードが出現した時点の自作構造体を参照し、自作構造体の一番最後の子とコメントが同じ行であればtrailing_commentにコメントを追加します。今回の例ではGRADEを左辺として持っているaligned_exprに-- 成績を追加します。
.png)
レンダリング時の処理
先述したように構文木を再構築し、最後にレンダリングをして整形されたSQL文を出力します。このときにインデントの調整や縦揃えのためにタブ文字を適切な数挿入します。
挿入するタブ文字の計算について説明します。例えば以下のようなSQLで、タブ幅4の場合を考えます。
FROM |
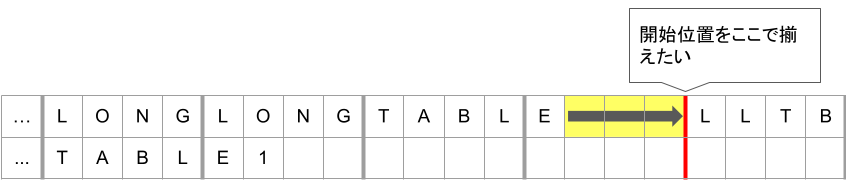
テーブル名を左辺、エイリアスを右辺として説明します。
上の行の左辺(LONGLONGTABLE)は13文字で、これにタブを1つ加えた16文字の位置から右辺(LLTB)が開始します。上の行の右辺の開始位置、すなわち16文字の位置に下の行の右辺(TB1)の開始位置が合わさるようにタブ文字を挿入します。
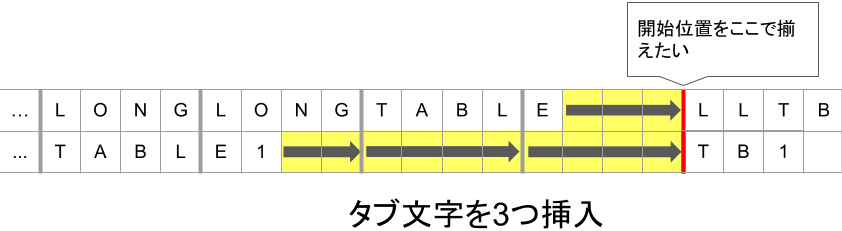
下の行の左辺(TABLE1)は6文字であるため、今回の例ではタブ文字を3つ挿入することで右辺の位置が揃います。
このように、合わせたい部分における最長の左辺の長さを利用して、以下の式で各行で挿入するタブ文字の数を計算します。求めた数タブ文字を挿入することで縦揃えを実現できます。
(左辺のタブ長) = ((文字列の長さ) / TAB_SIZE) + 1(挿入するタブ文字の数) = ((左辺のタブ長最大値) - (合わせたい行の左辺のタブ長))
同様の処理を行うことで、コメント、演算子も縦揃えをできます。
感想
最後に本インターンの感想です。
インターンの感想 (川渕)
今回のインターンでは齋藤さんとペアで設計~開発を行っていたため、お互いが何を考えているかを詳細に把握する必要がありました。また、毎日のミーティングで受け入れ先のプロジェクトの方に成果報告をする場面では、自分の頭の中を説明する難しさを改めて実感しました。このようなことから、相手にわかりやすく伝えることの難しさと大切さを実感したので、これから意識して伝える力を向上させたいと思いました。
今回のインターンは4週間あり、始まる前は長いと感じていましたが、いざ始まってみると毎日充実しており、あっという間に過ぎてしまいました。受け入れ先のプロジェクトの方をはじめとしたFUTUREの方が楽しく成長できるように工夫していただいたからだと思います。4週間本当に楽しかったです! ありがとうございました!
インターンの感想 (齋藤)
私(齋藤)は研究で構文解析を扱っており、その経験が生かせると考えて本インターンシップに参加しました。実際の業務の中では、使用する構文解析ソフトウェアの選定や構文解析結果を利用したフォーマッタの開発など、構文解析に関する知識が生かせる業務が多くありました。
このようなニッチな技術・分野は直接ビジネスにかかわってくるとは限りませんが、業務改善などの点でビジネスを支える重要な技術であるということを実感できました。
他にもチーム開発の経験が得られたり、フューチャーの社風を肌で感じることができ、様々なことを学ばせていただきました。4週間本当にありがとうございました!
さいごに
今回はフォーマッタの作成を行いました。タスク外でも他のプロジェクトの参加者とのコミュ会やディナー等たくさんのイベントを開いていただきました。
受け入れてくれたコアテクの皆さん、HRの皆さん、Engineer Camp2022に参加していたインターン生の皆さんに感謝します。
4週間本当にありがとうございました!