
はじめに
はじめまして、フューチャーのインターン”Engineer Camp”に参加した平野と申します。
今回のインターンでは、Google Cloud Platform (GCP)のサービスとして提供されているDataflowについて調査し、その仕組みや使い方についてこの技術ブログにまとめることに取り組みました。
フューチャーのインターンについてはこちらをご覧ください!
今回の記事は前編・後編に分かれており
- 前編:
- Dataflowの概要
- Apache Beamの概要・内部的な仕組み
- Apache Beamのコードの書き方
- 後編:
- Dataflowを使う上での事前準備と基本的な使い方
- GPUを使う上での事前準備と基本的な使い方
- Pub/Sub・BigQueryとの連携例
という構成になっています。後編も公開しています。
Dataflowとは
Dataflowは様々なデータの分散処理を簡単に実現できるプラットフォームです。
大規模なデータを処理したいけれど、十分な計算資源がない場合やそのためのインフラの構築・管理が面倒な場合には、Dataflowは有効な選択肢の1つです。Dataflowではそのような環境構築が不要で、後述するApache Beamでデータ処理の流れを記述すれば、データの分散処理を実行できます。
また、Dataflowにはオートスケーリングという機能が備わっており、データ処理の重さに応じて自動で最適な計算リソースを割り当ててくれます。さらにDataflowはGCPのサービスなので、他のGCPサービス(Cloud Strage, Cloud Pub/Sub, BigQueryなど)との連携がしやすくなっています。
Dataflowの活用事例は多く、例えばメルペイさんはさまざまなマイクロサービスで必要とされる典型的なデータ処理にDataflow Templateを活用されています。1
また、SUBARUさんでは学習データにアノテーションを付与する処理にDataflowを利用されています。2
「学習用の画像データにアノテーション データを付与して TFRecord を生成する前処理が、日を追うごとに増えていき、これまでのやり方だと並列でやっても丸一日以上かかってしまうようになってしまいました。そこで、これを
Apache Beam を使って Cloud Dataflow で処理するようにしています。結果、データを流すと数百CPU くらいまで一気にオートスケールして、だいたい 30 分くらいで終わるようになりました」(大久保氏)
Dataflowでは、データ処理パイプラインの中に機械学習モデルの推論を組み込むことも可能で、ストリーム処理と組み合わせるとリアルタイム推論もできるようになります。今回はそのようなMLシステムへの応用を見据えて基本から整理しました。
Apache Beamとは
Dataflow上で実行するデータ処理の内容はApache Beamを用いて記述します。
Apache Beam自体は、データ処理パイプラインを定義・実行するソフトウェア開発キット (SDK) で、OSSなので誰でも利用できます。Dataflow以外にもFlink, Nemo, Spark, AWS KDAなどの環境(Runnerという)で動かすことができ、Go, Java, Pythonといった様々なプログラミング言語で利用できます。
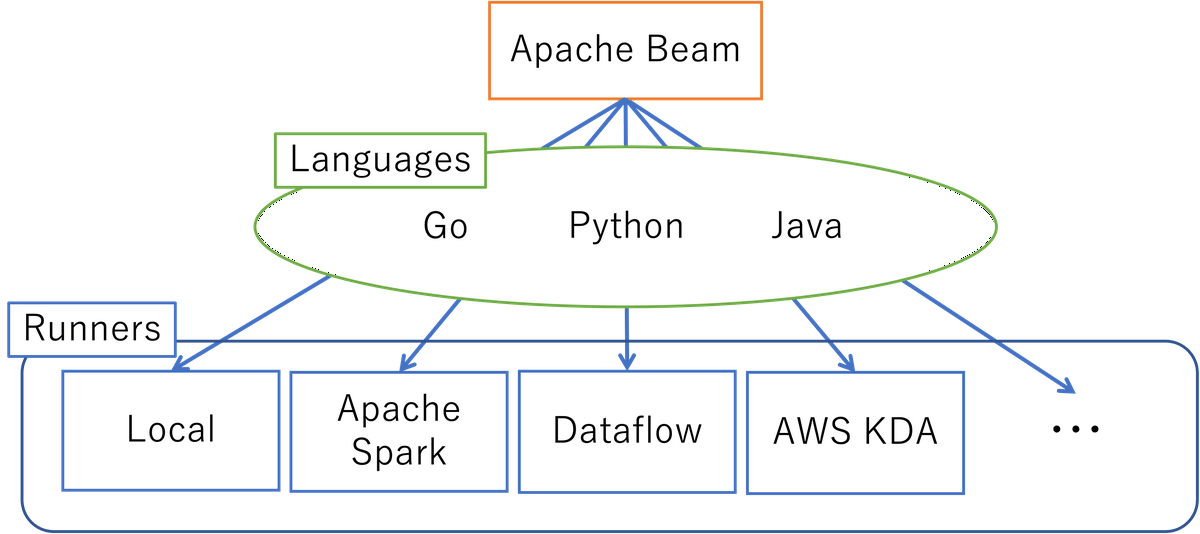
Apache Beamの特徴としては、パイプライン処理を実行するWorkerの確保、各Workerへのデータの割り当てなどはRunnerが自動で行なってくれるという点があります。そのため、コードを書く際にはパイプライン処理の流れだけに注力すればよく、大規模なデータの分散処理を簡単に実行できます。
また、バッチ処理・ストリーム処理の両方のデータ処理を同じようなコードで記述できるというのも大きな特徴の1つで、バッチ処理⇄ストリーム処理の切り替えが簡単にできます。ちなみにBeamという名前は B atch + st eam から来ています。
Apache Beamの構成要素
Apache Beamでは以下の図のような構成となっています。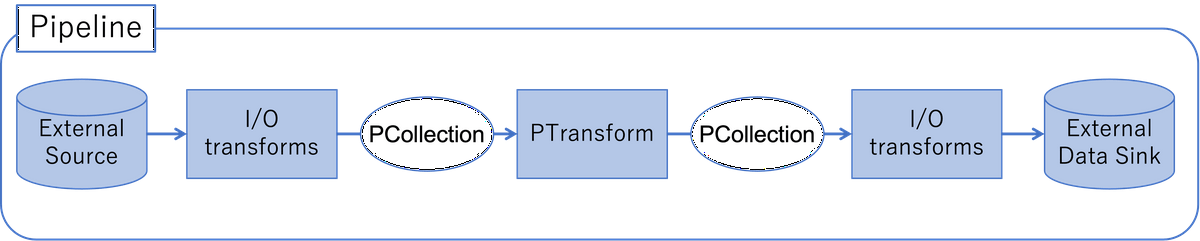
- Pipeline:
データ処理タスク全体(入力データの読み取り→データの処理→データの書き出し)をカプセル化したもの。 - PCollection:
パイプラインを流れるデータ。パイプラインの最初は外部ソースからデータを読み出して、PCollectionにすることから始まる。 - PTransfrom:
パイプライン内の個々のデータ処理オペレーション。PTransformの入出力はPCollection。 - I/O transforms:
外部ソースからのデータの読み取り、外部ソースへのデータの書き出しを行う際に用いるPTransform。
Apache Beamの仕組み
ここでは、Apache Beamがどのようにして分散処理を行っているのかについて、公式ドキュメントの内容をもとに説明します。
以下の説明で用いている図は公式ドキュメントから引用しています。
Transform並列化の仕組み
- Runnerは入力されたPCollectionをいくつかのBundleに分ける。
- 各BundleをWorkerが並列に処理する。
いくつのBundleに分割するかはRunnerが決定します。以下の図では9つのelementからなるPCollectionを2つのBundleに分割しています。

ParDo1を実行する際に、各BundleはWorkerに渡され、並列に実行されます。

PCollectionに含まれるelementよりも小さく分割することはできないため、Bundle数の最大はPCollectionのelement数です。

※Splittable ParDoを使えば、1つのelementを複数のBundleで処理できるらしい。この機能は開発中とのこと。
Transform間に従属関係がある場合の挙動
以下の例では、入力に対してParDo1を適用した後に、ParDo2を適用します。
図ではBundle AにParDo1を適用した出力がBundle C、Bundle BにParDo1を適用した出力がBundle Dとなっています。

RunnerがParDo1を適用前と後でBundleの再構成を行わない場合、各Bundleは同じWorkerでParDo1とParDo2を適用されます。

こうすることで、Worker間の通信を省くことができ、他のWorkerの処理を待つ必要がなくなります。
1つのTransformに失敗した場合の挙動
Bundle内のあるelementの処理に失敗した場合、そのelementが属するBundle全体に対して処理を再度実行する必要があります。
ただし、処理を実行するWorkerは変わってもよく、以下の例ではWorker2が処理に失敗したBundleをWorker1が引き受けています。

従属関係にあるTransformに失敗した場合の挙動
2つのTransform間に従属関係があり、後続のTransformの処理に失敗した場合、Bundleは再度最初からTransformを適用される必要があります。

このような挙動となっている理由は、Transform間のelementを保持しておくとメモリを圧迫してしまうため?公式DocにはPersistence costを節約するためとあった。ラージスケールなデータを処理することを念頭においた設計となっている?
Apache Beamのコードの書き方
Apache Beamでは、以下のような流れでコードを書いていきます。
- Pipelineの生成と実行オプションの設定(ここでRunnerも指定)
- I/O transformsを用いて最初のPCollectionの生成。外部ソースからデータを取ってきたり、コード内で定義してもOK
- PTransformの適用
- PTransform適用後のPCollectionを外部ソースへ書き込み
- RunnerでPipelineを実行
上記の流れで実装したサンプルコードが以下になります。以下の例ではinput.txtの各行の文字数をoutput.txtに出力するコードです。
import apache_beam as beam |
例えば、以下のようなinput.txtに対して、上のコードを実行すると
Hello World! |
以下のようなoutput.txtが生成されます。
12 |
Apache Beamのパイプライン処理はLinuxコマンドのパイプライン処理と同じように
Pipeline | PTransform1 | PTransform2 | ... |
と記述します。Pipelineのインスタンスがパイプラインのスタートとなります。
また、パイプライン内の各Transformにはラベルが割り振られ、コード中で明示的にラベルを与えなかった場合には、そのTransform自体がラベルとなります。
パイプライン内に同一のラベルを持つTransformが存在してしまうと、エラーとなってしまうため注意です。
p |
パイプラインの分岐・合流
Apache Beamは一直線のパイプラインだけでなく、分岐や合流を含む複雑なパイプラインを構成できます。
パイプラインを分岐させたい場合には、分岐の直前までを変数に代入することで、その変数をスタートとしてパイプラインの分岐させることができます。
import apache_beam as beam |
この場合、パイプラインのグラフは次のようになります。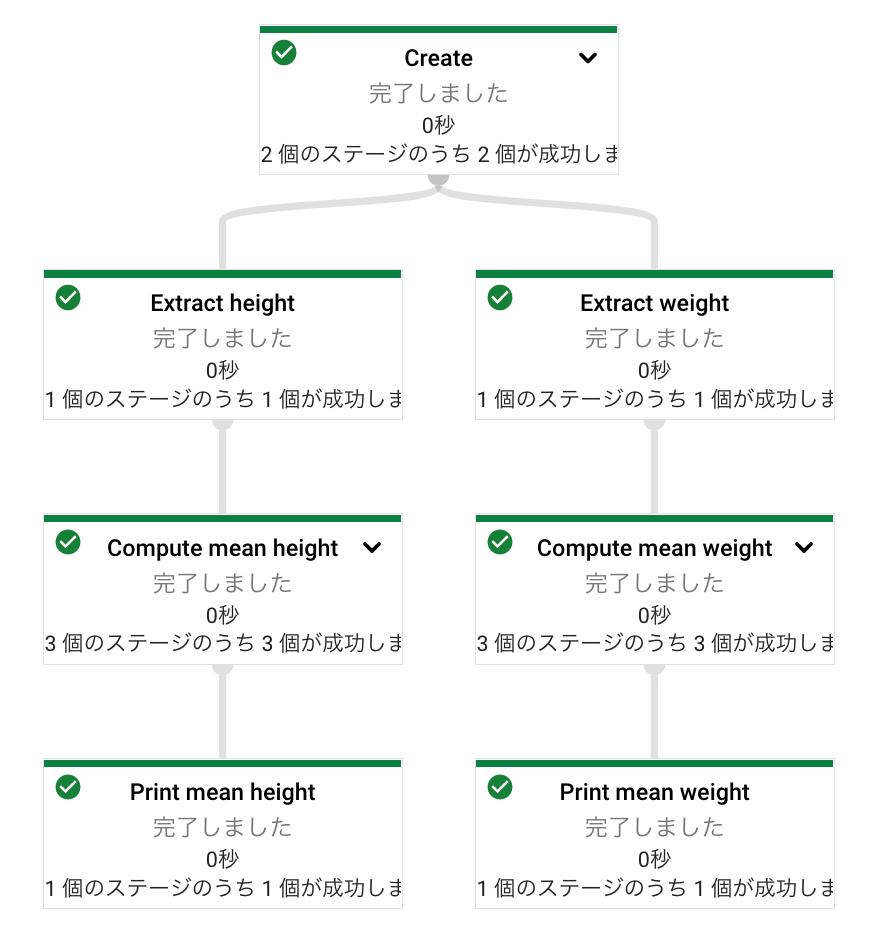
また、合流させたい場合には、beam.Flatten()を使うことで、分岐したパイプラインを合流させることができます。上の分岐のコードではターミナルへの出力を別々にやっていましたが、下の例ではheight_averageとweight_averageを合流させて、ターミナルへの出力を一括化しています。
import apache_beam as beam |
この場合、パイプラインのグラフは次のようになります。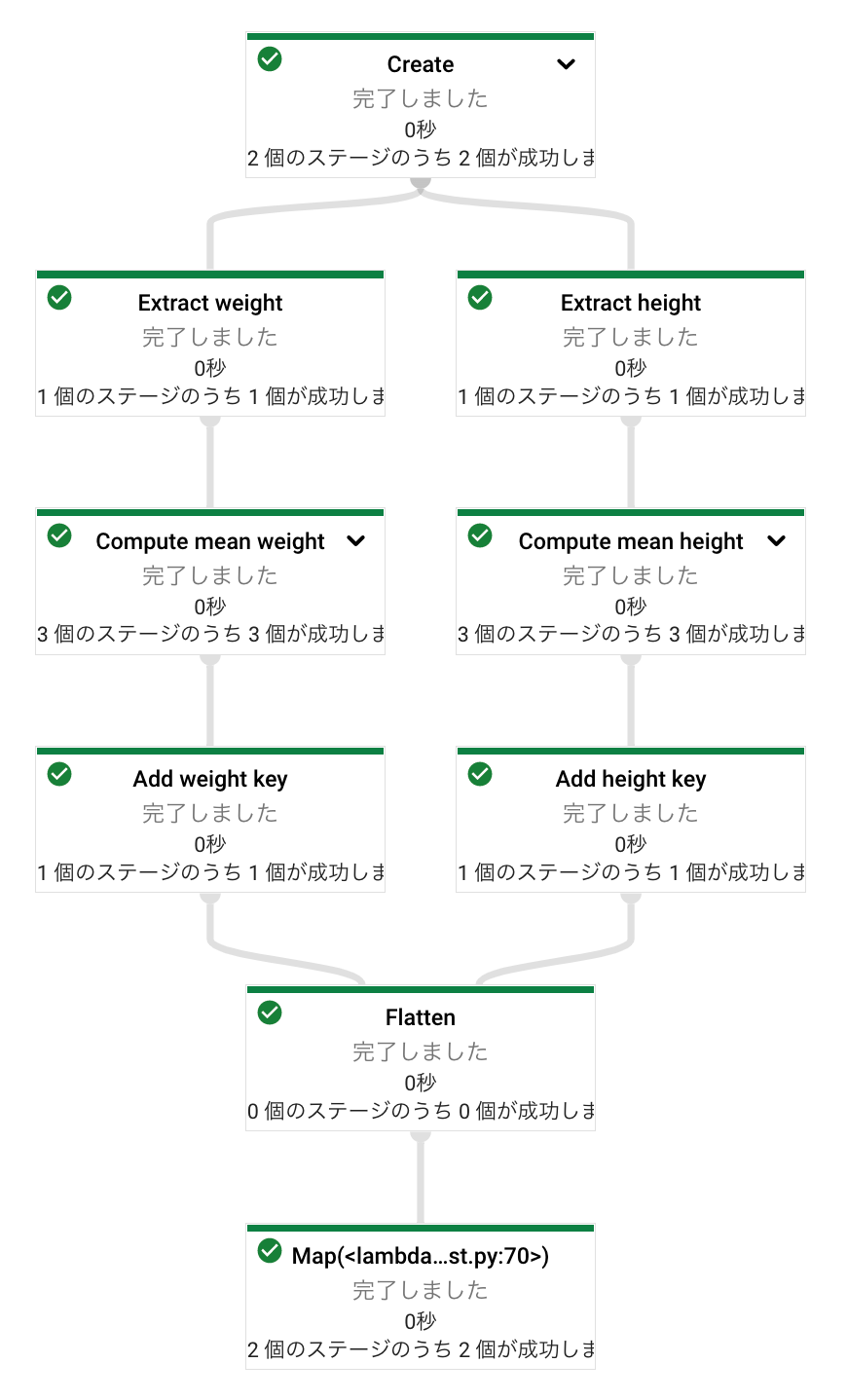
最後に
ここまでお読みいただきありがとうございます。稚拙な文章で読みづらい箇所が多々あったかと思います。よければ後編もお読みいただければと思います。
参考
- Apache Beam (Dataflow) 実践入門【Python】
- How Beam executes a pipeline (公式ドキュメント)
- Python を使用して Dataflow パイプラインを作成する
アイキャッチはPaul BrennanによるPixabayからの画像です。