
はじめに
はじめまして、フューチャーのインターン”Engineer Camp”に参加した平野と申します。
今回のインターンでは、Google Cloud Platform (GCP)のサービスとして提供されているDataflowについて調査し、その仕組みや使い方についてこの技術ブログにまとめることに取り組みました。
フューチャーのインターンについてはこちらをご覧ください!
今回の記事は前編・後編に分かれており
- 前編:
- Dataflowの概要
- Apache Beamの概要・内部的な仕組み
- Apache Beamのコードの書き方
- 後編:
- Dataflowを使う上での事前準備と基本的な使い方
- GPUを使う上での事前準備と基本的な使い方
- Pub/Sub・BigQueryとの連携例
という構成になっています。前編はこちら。
Datflowの事前準備と基本的な使い方
Dataflowを使うための事前準備からパイプライン実行までの一連の流れについて説明します。以下の手順で進めます。
- APIの有効化
- IAMの設定
- Apache Beam SDKのインストール
- Cloud Storageバケットの作成
- Dataflow上でパイプラインを実行
なお、以降の
- Dataflowの使用例(GPUなしver.)
- DataflowでGPUを使う際の事前準備と基本的な使い方
- Dataflowの使用例(GPUありver.)
- 他のGCPサービスとの連携とストリーミング処理
では、ここで説明するAPIの有効化、IAMの設定、Cloud Storageバケットの作成ができている前提で話を進めています。
APIの有効化
Compute Engine API, Dataflow API, Cloud Storage APIとその他必要な(連携させたい)APIを有効化します。APIの有効化はコンソール画面上部にある検索窓から有効化したいAPIを検索すれば簡単に有効化できます。
IAMの設定
APIを有効化するとIAMにCompute Engine default service accountという名前のアカウントが追加されているはずです。
Dataflowを利用するにはそのサービスアカウントにDataflowワーカー、Dataflow管理者、Storageオブジェクト管理者のロールを追加して保存します。以下の画像のようになっていればOKです。
なお、ロールを付与するには、resourcemanager.projects.setIamPolicyの権限を持っている必要があります。持っていない場合はプロジェクトの管理者に権限を付与してもらうか、サービスアカウントへのロールの付与を代わりにやってもらってください。
Apache Beam SDKのインストール
続いて、ローカル環境(今回はCloud Shell)にApache Beam SDKをインストールします。2022/08/30現在、Apache Beam SDKでサポートされているPythonのバージョンは3.8までです。一方、Cloud ShellにデフォルトでインストールされているPythonのバージョンは3.9ですので、pyenv等を用いてPython3.8を実行する仮想環境を作成してください。その後、作成した仮想環境にApache Beamをインストールします。Dataflow(GCP)上で実行するには追加パッケージをインストールする必要があるので、以下のコマンドでインストールしてください。
pip3 install apache-beam[gcp] |
Cloud Storageバケットの作成
Dataflowでパイプライン処理を行う場合、一時ファイルや出力ファイルを保存するためにCloud Storageのバケットを作成する必要があります。
バケットの作成はコンソール画面から作成する方法とPythonから作成する方法があります。
コンソール画面からは以下のように作成できます。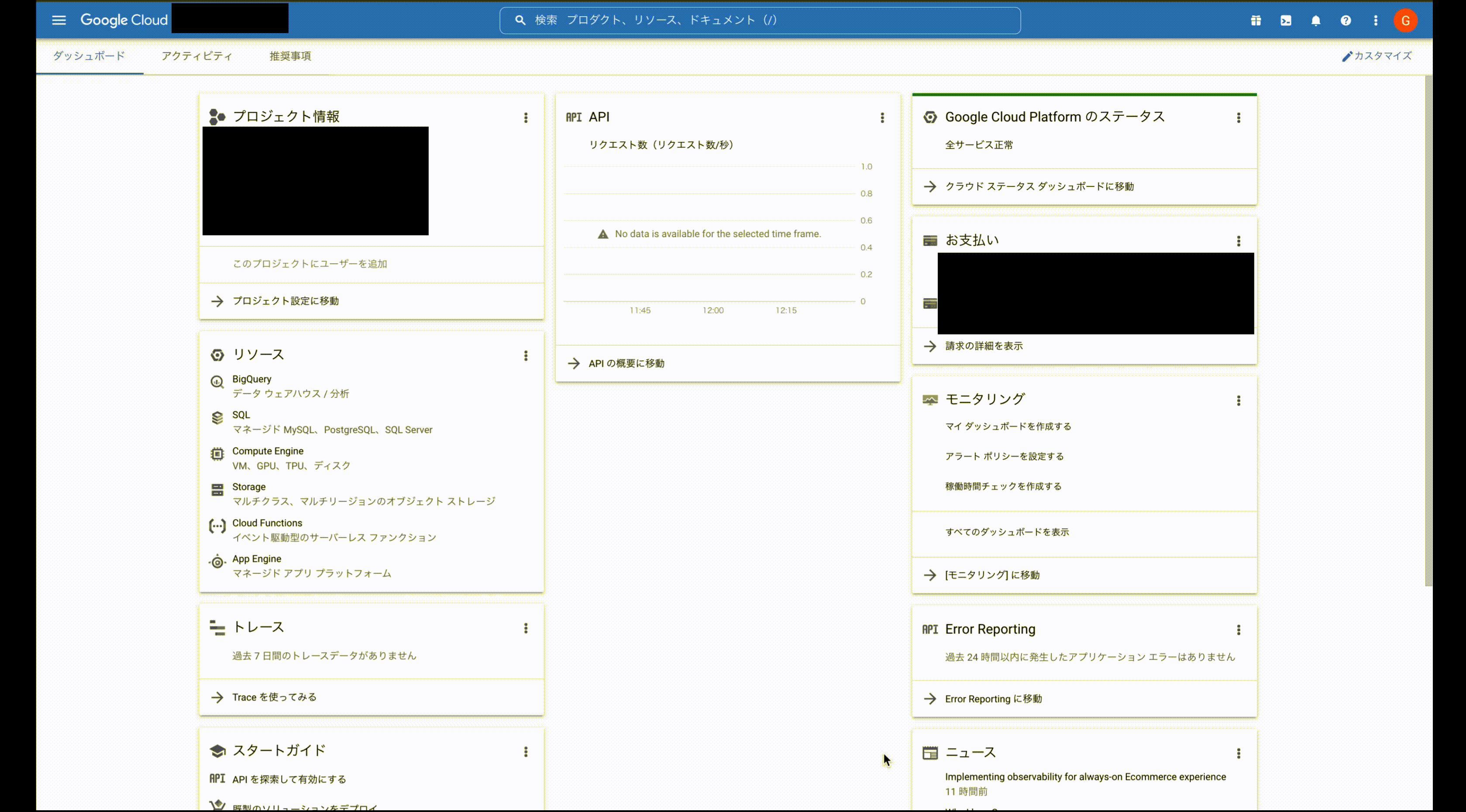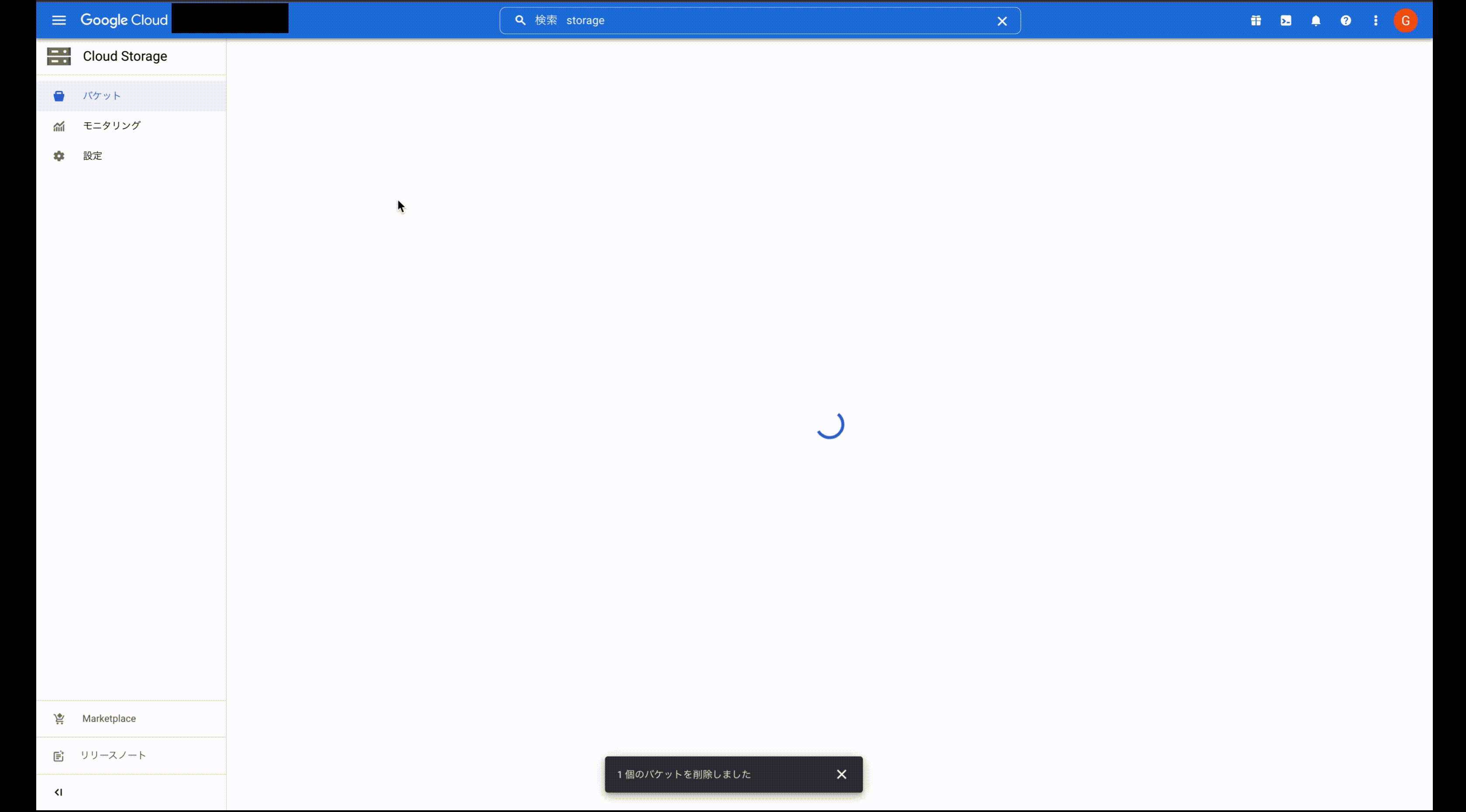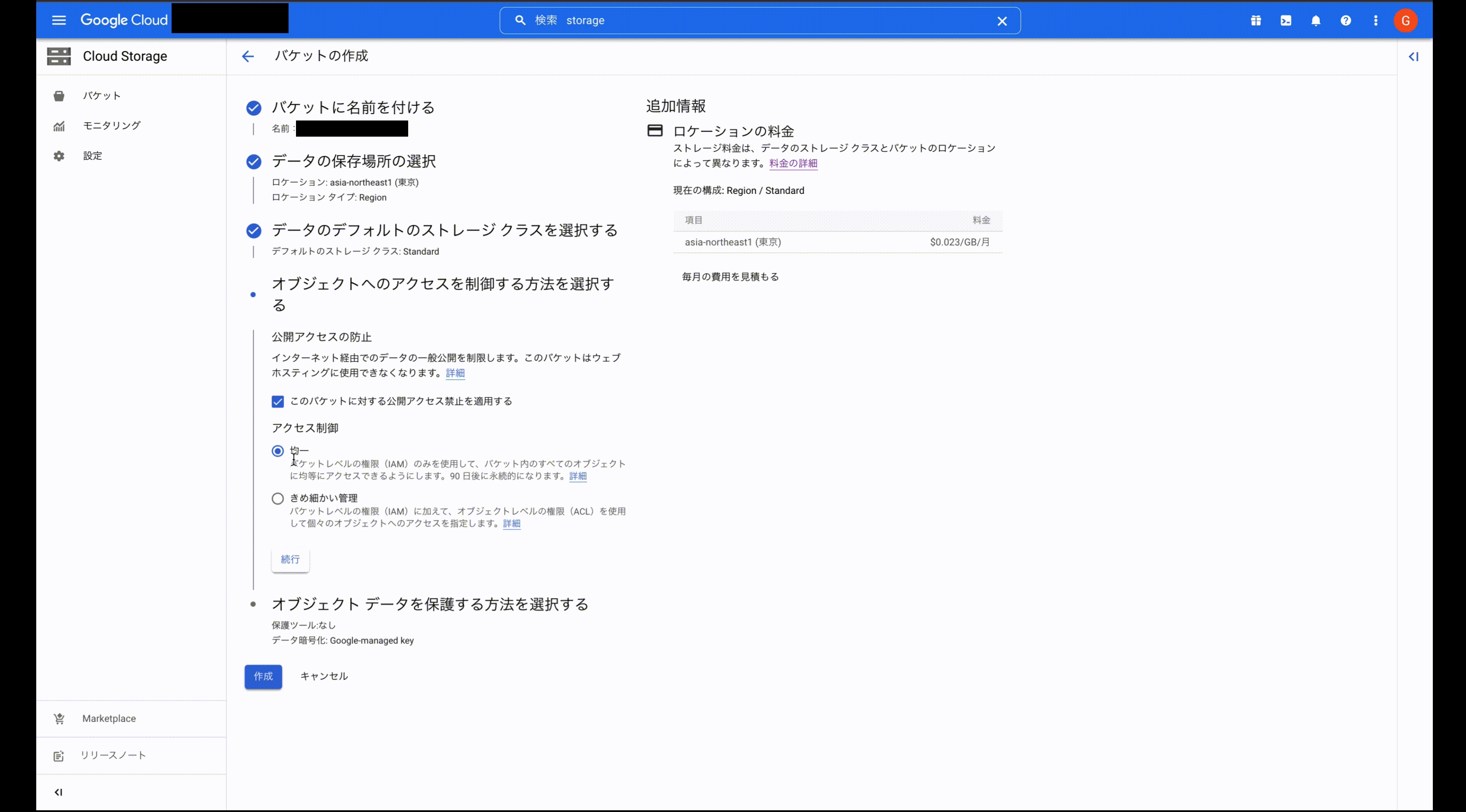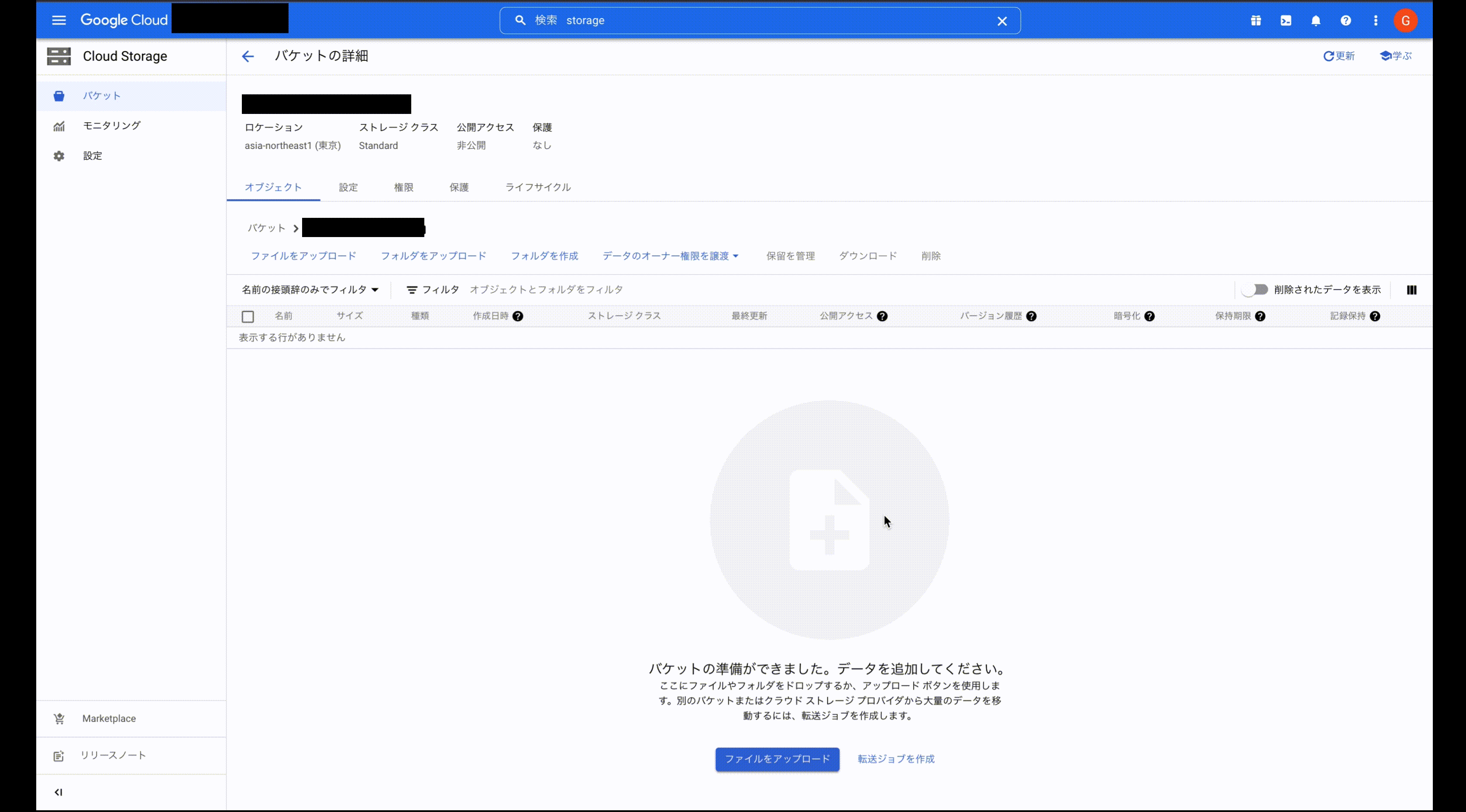
Pythonからバケットを作成する際は以下のコードを参考にしてください(pip3 install google-cloud-storageが必要です)。
from google.cloud import storage |
Dataflow上でパイプラインを実行
続いて、Dataflow上でパイプラインを実行していきます。Dataflow上でパイプラインを実行するにはいくつかのオプションを指定する必要があります(主にGCP関連)。ここでは、それらのオプションの説明とオプションの渡し方について説明します。
Dataflowでパイプラインを実行するためには以下のようなオプションを指定する必要があります。
| オプション名 | 説明 |
|---|---|
| runner | Dataflowで動かす場合にはDataflowRunnerを指定。ローカルで動かす場合にはDirectRunner。 |
| project | プロジェクトID。指定しないとエラーが返ってくる。 |
| job_name | 実行するジョブの名前。Dataflowのジョブのところにジョブの一覧が表示されるが、その際にどのジョブかを見分ける際に使える。指定しなければ勝手に名前をつけてくれるが、パッと見で判断しづらい。 |
| temp_location | 一時ファイルを保存するためのGCSのパス(gs://からスタートするパス)。指定しなければstaging_locationのパスが使用される。 |
| staging_location | ローカルファイルをステージングするためのGCSのパス。指定しなければtemp_locationのパスが使用される。temp_locationかstaging_locationのどちらかは指定しなければならない。 |
| region | Dataflowジョブをデプロイするリージョンエンドポイント。デフォルトではus-central1。 |
ここでは動かすのに必要な(とりあえずこのへんを渡しておけば動く)オプションを紹介していますので、その他のオプションについては公式ドキュメントを参照してください。
実行する際には以下のように--<オプション名> 値の形式で指定することでオプションを渡すことができます。
python {ソースコードまでのpath} \ |
Dataflowの使用例(GPUなしver.)
ここでは、scikit-learnのモデルの推論をDataflow上で行う例を扱っていきます。今回はIrisデータセットで学習したモデルの重みパラメータ(SVC_iris.pkl2)が既に手元にあるという想定で、そのモデルの推論(学習時と同じIrisデータセットを使用)をDataflow上で行っていきます。以下のような手順で進めていきます。
- ソースコードの準備
- Cloud ShellでPythonの環境構築
- パイプラインの実行
なお、APIの有効化、IAMの設定、Cloud Storageバケットの作成がお済みでない方はまずそちらから始めてください。
ソースコードの準備
今回実行したいソースコード(ファイル名:runinference_sklearn.py)です。モデルの重みパラメータまでのパスは{ソースコードがあるディレクトリ}/models/sklearn_models/SVC_iris.pkl2です。
import logging |
Cloud ShellでPythonの環境構築
次にCloud ShellのPython環境を構築していきます。
まず、Python 3.8の環境を準備します。ターミナル上で
pyenv install 3.8.13 |
を実行し、Python 3.8をインストールします。その後、
pyenv virtualenv 3.8.13 dataflow |
を実行してPython 3.8.13がインストールされた仮想環境(ここではdataflow)をアクティベートします。
続いて、必要なパッケージをインストールしていきます。
pip3 install apache-beam[gcp] google-gcloud-storage |
パイプラインの実行
必要なパッケージのインストールが終わったら、最後にパイプラインを実行していきます。以下のコマンドを実行するとDataflow上でパイプライン処理が動き始めます。{プロジェクトID}、{ジョブの名前}、{バケットの名前}は適宜変更してください。
python runinference_sklearn.py \ |
結果
推論結果はCloud Storageのバケットのoutput.txtに出力されます。今回の例では以下のような結果が得られました。
PredictionResult(example=array([5.1, 3.4, 1.5, 0.2]), inference=0) |
DataflowでGPUを使う際の事前準備と基本的な使い方
DataflowでGPUを使用したい場合(例えば機械学習モデルの推論など)には、Dockerと組み合わせることでGPUを使用できます。
基本的な流れはDatflowの事前準備と基本的な使い方と同じです。違いはDockerイメージの準備とパイプラインに追加で渡すオプションが増えることくらいです。ここでは
- Dockerイメージの準備
- GPU使用時のオプション
について説明します。なお、APIの有効化、IAMの設定、Cloud Storageバケットの作成がお済みでない方はまずそちらから始めてください。
Dockerイメージの準備
DataflowでGPUを使用するには、Apache Beamが扱える、かつ、必要なGPUライブラリが入ったDockerイメージを用意する必要があります。ありがたいことにPyTorch用の最小イメージやTensorFlow用の最小イメージのためのsampleが既に用意されているので、特に理由がなければこちらを利用するのが楽かと思います。
PyTorchを使用する場合にはPyTorch用の最小イメージからファイルをダウンロード後、
gcloud builds submit --config build.yaml |
で、DockerイメージをContainer Registryに保存します(デフォルトでのイメージ名はsamples/dataflow/pytorch-gpu:latest)。
なお、私の環境では、Pythonのバージョンが3.8ではパイプライン実行の際にエラー(TypeError: code() takes at most 15 arguments (16 given))が発生してしまっていたため、Pythonのバージョンを3.7に落としました。具体的には以下のように変更することでエラーは発生しなくなりました。
pyenvでPython 3.7の環境を用意
ターミナル上でpyenv install 3.7.13
を実行し、Python 3.7をインストールします。その後、
pyenv virtualenv 3.7.13 dataflow_gpu
pyenv activate dataflow_gpuを実行してPython 3.7.13がインストールされた仮想環境(ここでは
dataflow_gpu)をアクティベートします。
続いて、Apache Beamをインストールしていきます。pip3 install apache-beam[gcp]
Dockerfileを以下のように変更
FROM pytorch/pytorch:1.9.1-cuda11.1-cudnn8-runtime
WORKDIR /pipeline
COPY requirements.txt .
COPY *.py ./
RUN apt-get update \
&& apt-get install -y --no-install-recommends g++ \
&& apt-get install -y curl \ # この行を追加
python3.7 \ # この行を追加
python3-distutils \ # この行を追加
&& rm -rf /var/lib/apt/lists/* \
# Install the pipeline requirements and check that there are no conflicts.
# Since the image already has all the dependencies installed,
# there's no need to run with the --requirements_file option.
&& pip install --no-cache-dir --upgrade pip \
&& pip install --no-cache-dir -r requirements.txt \
&& pip check
# Set the entrypoint to Apache Beam SDK worker launcher.
COPY --from=apache/beam_python3.8_sdk:2.38.0 /opt/apache/beam /opt/apache/beam
ENTRYPOINT [ "/opt/apache/beam/boot" ]
GPU使用時のオプション
DataflowでGPUを使用する際には、実行時に以下のようなオプションを追加で指定する必要があります。
| オプション名 | 説明 |
|---|---|
| sdk_container_image | 使用するコンテナイメージの名前。 |
| disk_size_gb | 各ワーカー VM のブートディスクのサイズ |
| experiments | Dataflow Runner v2を使用するかやGPUのタイプ・個数、Nvidiaドライバをインストールするかを指定する際に使用。具体的な使い方は下の例を参照。 |
experimentsオプションに関しては次のように指定します。下の例のように複数個に分けて指定してもOKです。
--experiments "worker_accelerator=type:nvidia-tesla-t4;count:1;install-nvidia-driver" \ |
Dataflowの使用例(GPUありver.)
ここでは、PyTorchのモデルの推論をDataflow上で行う例を扱っていきます。今回はMNISTデータセットで学習したモデルの重みパラメータ(mnist_epoch_10.pth)が既に手元にあるという想定で、そのモデルの推論(MNISTのテスト用データセットを使用)をDataflow上で行っていきます。以下のような手順で進めていきます。
- ソースコードの準備
- Dockerコンテナイメージの作成
- Cloud ShellでPythonの環境構築
- パイプラインの実行
なお、APIの有効化、IAMの設定、Cloud Storageバケットの作成がお済みでない方はまずそちらから始めてください。
ソースコードの準備
今回実行したいソースコード(ファイル名:runinference_pytorch.py)です。
import logging |
モデルの構造を定義したコード(ファイル名:pytorch_MNIST.py)です。
from torch import nn |
これらのソースコードはCloud Shellの同一のディレクトリに置いてください。また、モデルの重みパラメータまでのパスは{ソースコードがあるディレクトリ}/models/pytorch_models/mnist_epoch_10.pthです。
Dockerコンテナイメージの作成
続いて、Dockerイメージを準備していきます。PyTorch用の最小イメージからファイルをダウンロード後、それらのファイルをソースコードと同一のディレクトリに置きます。続いてDockerfileを以下のように変更します。
FROM pytorch/pytorch:1.9.1-cuda11.1-cudnn8-runtime |
その後、コンテナイメージをContainer Registryに保存するために以下のコマンドを実行します。
gcloud builds submit --config build.yaml |
コンテナイメージ名はsamples/dataflow/pytorch-gpu:latestで保存されます。
Cloud ShellでPythonの環境構築
次にCloud ShellのPython環境を構築していきます。
まず、Python 3.7の環境を準備します。ターミナル上で
pyenv install 3.7.13 |
を実行し、Python 3.7をインストールします。その後、
pyenv virtualenv 3.7.13 dataflow_gpu |
を実行してPython 3.7.13がインストールされた仮想環境(ここではdataflow_gpu)をアクティベートします。
続いて、必要なパッケージをインストールしていきます。
pip3 install apache-beam[gcp] google-gcloud-storage |
パイプラインの実行
必要なパッケージのインストールが終わったら、最後にパイプラインを実行していきます。
以下のコマンドを実行するとDataflow上でパイプライン処理が動き始めます。{プロジェクトID}、{ジョブの名前}、{バケットの名前}は適宜変更してください。
python runinference_pytorch.py \ |
結果
推論結果はCloud Storageのバケットのoutput.txtに出力されます。今回の例では以下のような結果が得られました。
tensor([ -8.2468, -2.1803, -9.8459, 1.3747, 2.4845, -5.6996, -18.9429, |
他のGCPサービスとの連携とストリーミング処理
最後に、Pub/Subからリアルタイムにデータを取得→Dataflowでデータ処理→結果をBigQueryに書き出す例を紹介します。
今回はIrisデータセットの各サンプルを10秒間隔でPub/SubにPublishし、Dataflowの使用例(GPUなしver.)で行ったscikit-learnモデルを用いた推論をストリーミング処理でDataflow上で行い、その結果をBigQueryに書き出します。今回もIrisデータセットで学習したモデルの重みパラメータ(SVC_iris.pkl2)が既に手元にあるという想定で、以下のような手順で進めていきます。
- ソースコードの準備
- Pub/Sub・BigQueryの準備
- パイプラインの実行
なお、APIの有効化、IAMの設定、Cloud Storageバケットの作成がお済みでない方はまずそちらから始めてください。
ソースコードの準備
今回実行したいソースコード(ファイル名:predict_iris_dataflow_pubsub2bq.py)です。
モデルの重みパラメータまでのパスは{ソースコードがあるディレクトリ}/models/sklearn_models/SVC_iris.pkl2です。
import json |
また、Irisデータセットの各サンプルを10秒間隔でPub/SubにPublishにするためのコード(ファイル名:publish_iris_local2pubsub.py)です。
import argparse |
Pub/Sub・BigQueryの準備
まず、Pub/Subのトピック作成から始めていきます。Pub/Subのページ上部にある「トピックを作成」から、トピックIDを設定してトピックを作成します。そのほかの設定に関しては今回はデフォルトのままで大丈夫です。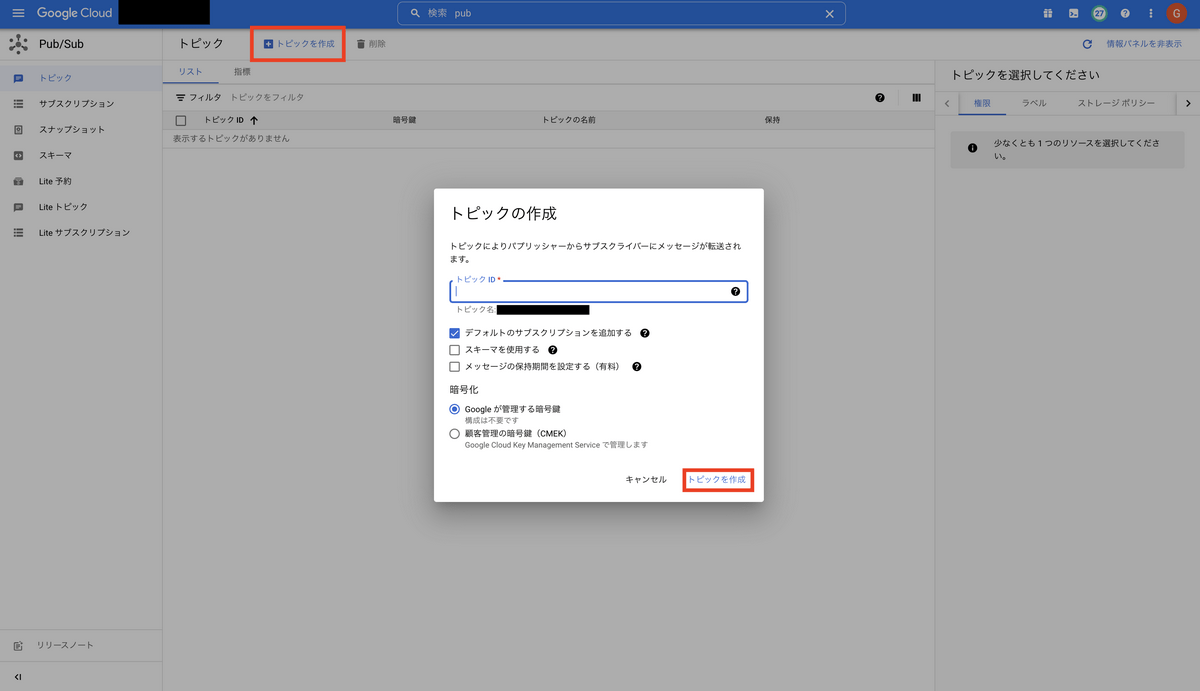
続いて、BigQueryのデータセット・テーブルの作成に入ります。BigQueryのデータセット・テーブルは以下のようにして作成できます。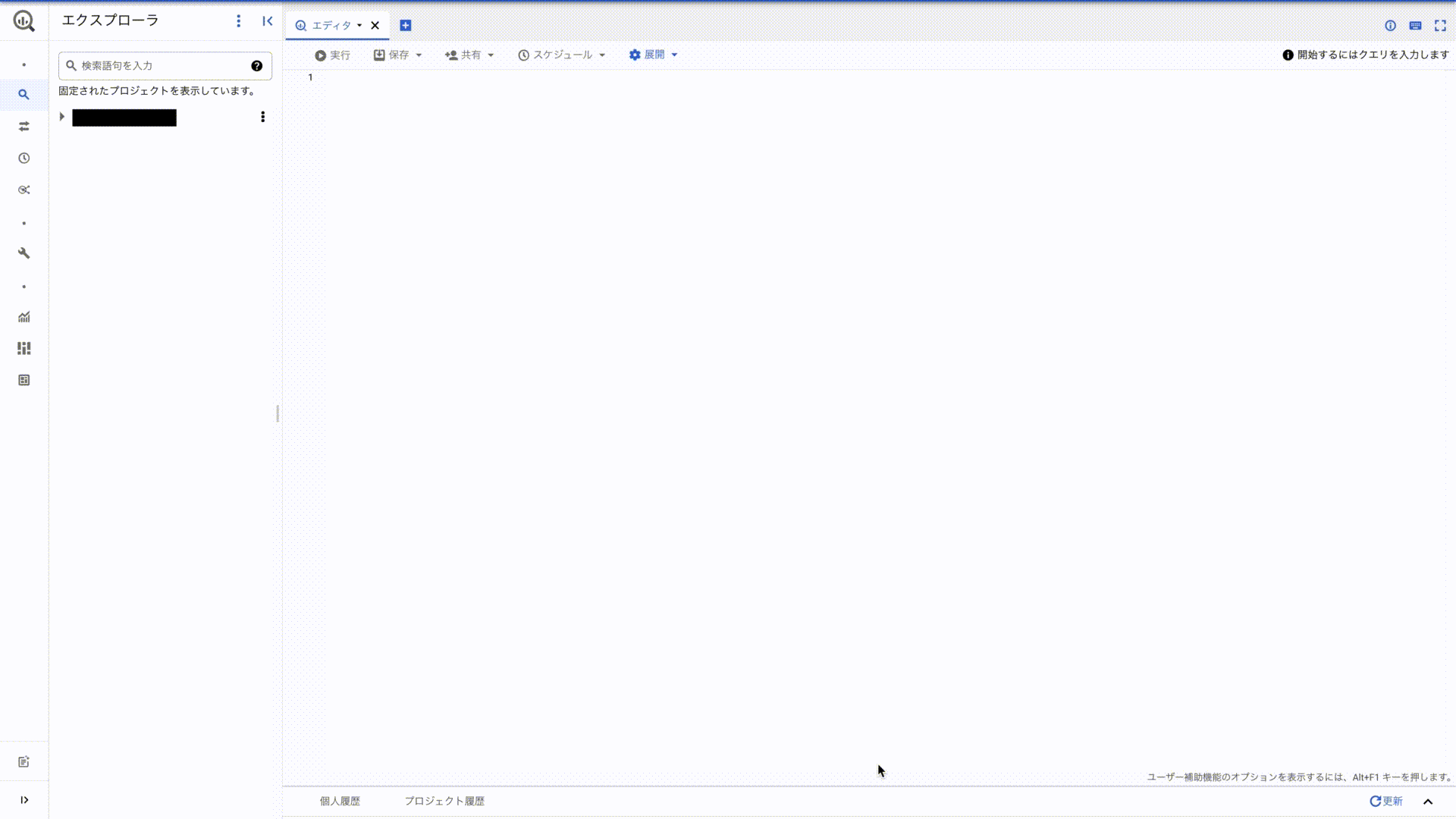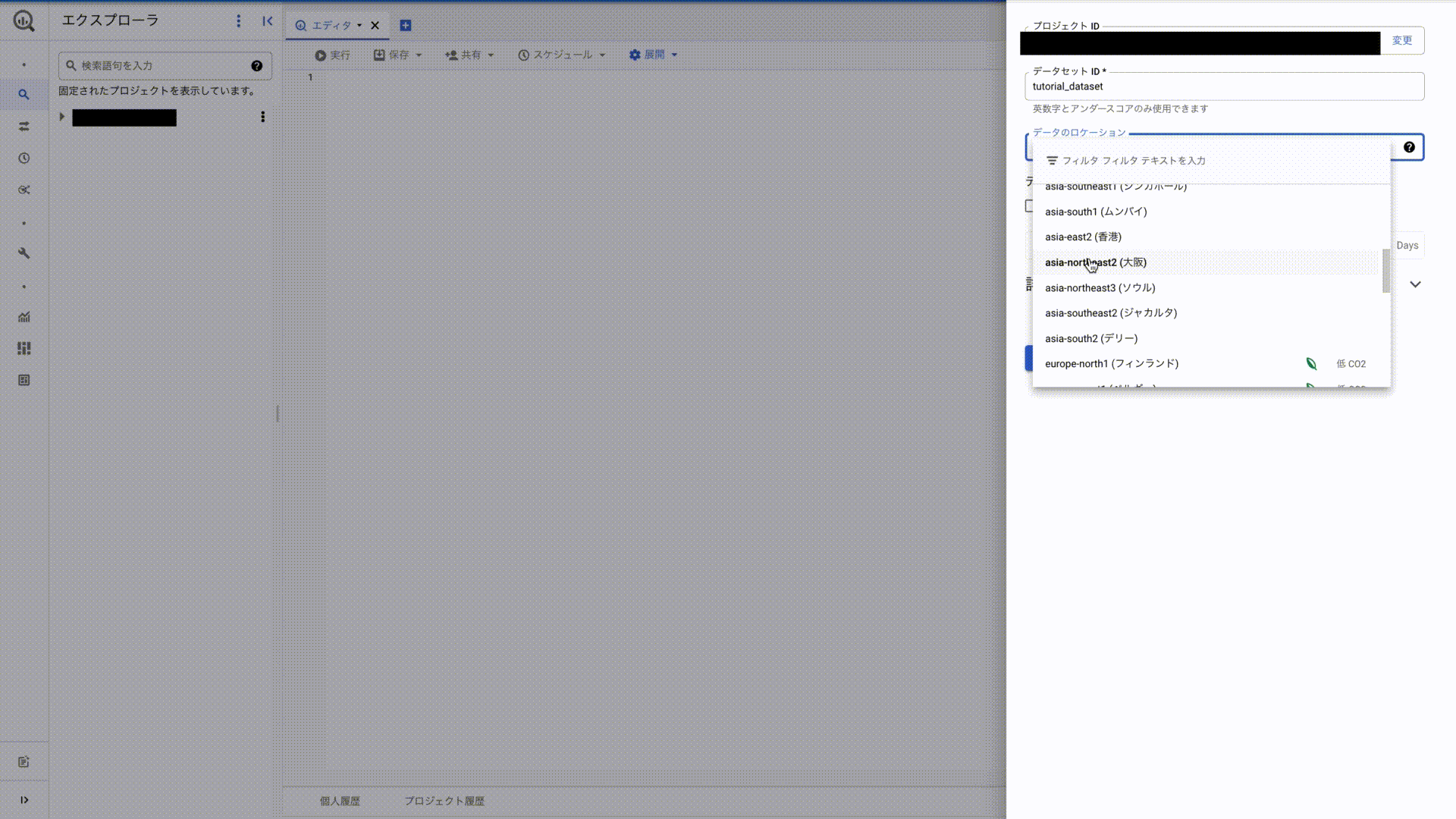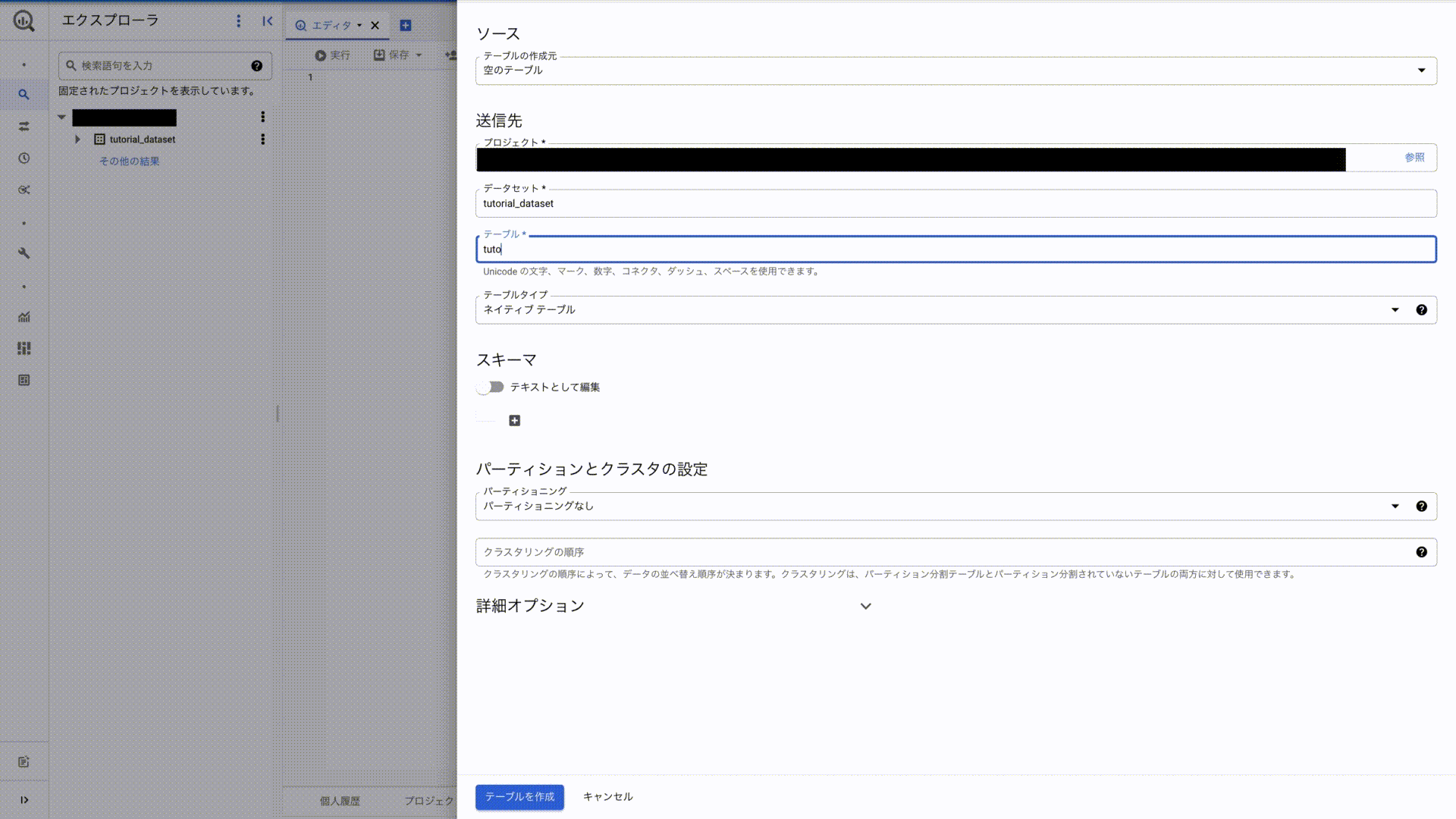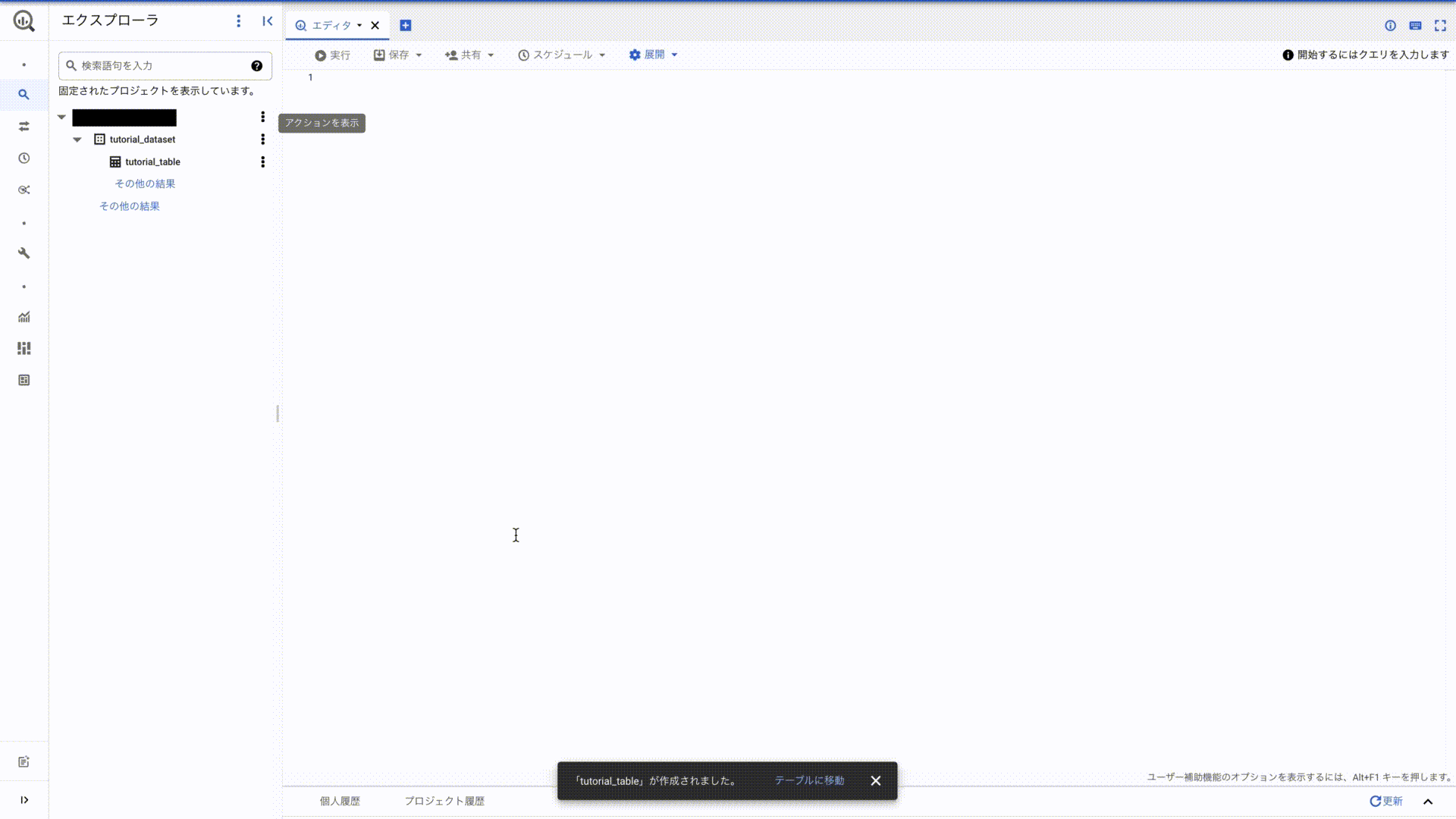
なお、今回使用しているスキーマは以下の通りです。
[ |
パイプラインの実行
続いて、パイプラインの実行に移ります。以下のコマンドを実行するとパイプラインが動き始めます。{プロジェクトID}、{ジョブの名前}、{バケットの名前}、{テーブルの名前}、{データセットの名前}、{トピックの名前}は適宜変更してください。今回はRunnerおよびストリーミング処理のオプションはコード内で記述しているためコマンドライン引数から渡す必要はありません。ストリーミング処理をコマンドラインから有効化したい場合は、--streamingを加えるとできます。
python predict_iris_dataflow_pubsub2bq.py \ |
これでパイプラインが実行されます。
パイプラインのジョブが動き始めたら、以下のコマンドで、Irisデータセットの各サンプルをPublishしていきます。なお、PythonファイルからPub/SubにPublishする際にはサービスアカウントキー作成する必要があります。IAMと管理→サービスアカウントからサービスアカウントキーを含むjsonファイルを作成し
export GOOGLE_APPLICATION_CREDENTIALS="{jsonファイルまでのpath}" |
で、PythonファイルからPub/SubにPublishできるようになります。それが終わったら
python publish_iris_local2pubsub.py \ |
を実行して、Pub/Subに10秒間隔でデータを送ります。
結果
BigQueryの画面からクエリを実行して結果を確認します。クエリは下図の赤枠の部分を順にクリックして
開いたエディタに
SELECT * FROM `{プロジェクトID}.{データセットの名前}.{テーブルの名前}` LIMIT 1000 |
を入力して実行します。
今回の例では以下のような結果が得られました。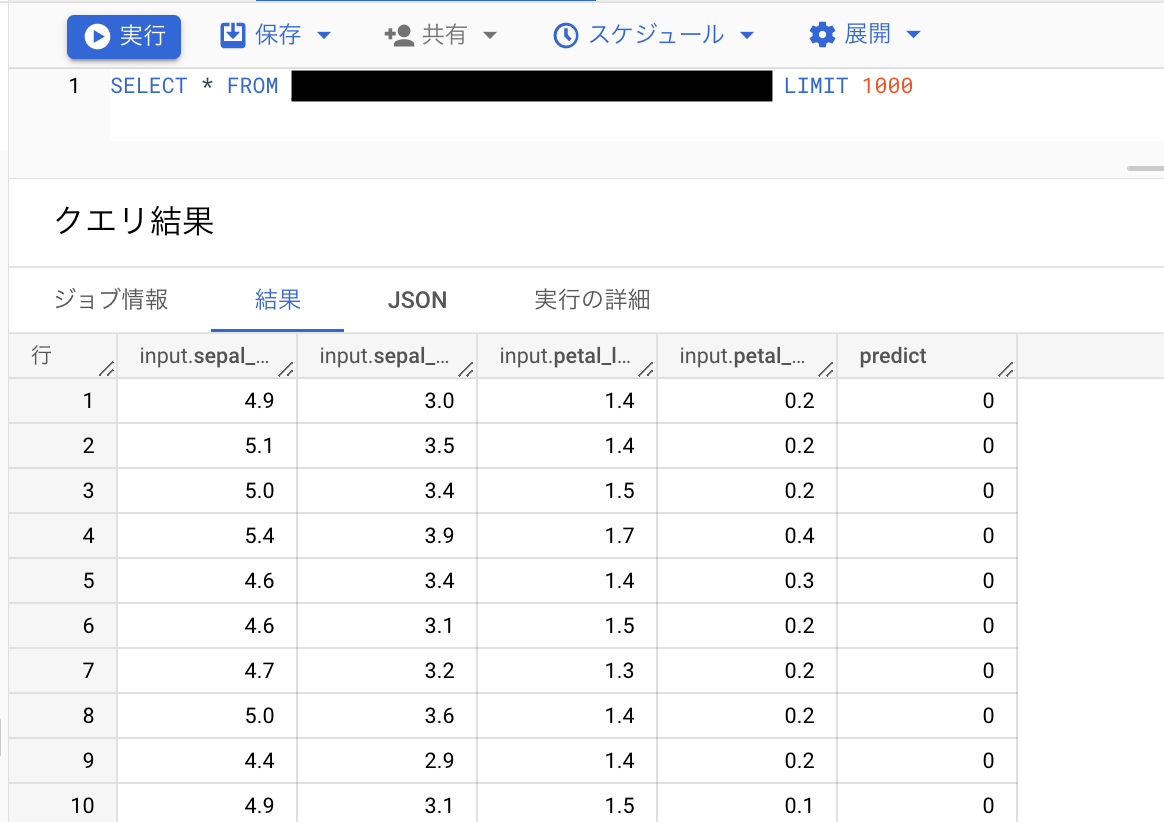
最後に
今回のインターンで扱わせていただいたDataflowは、なかなか個人で扱う機会がない一方で、ビジネスの場面ではとても需要のあるサービスです。そのようなものを扱う機会を頂けたことは今回のインターンに参加してよかったと思えることの1つです。また、私は今まで技術ブログを書いた経験がなかったため、今回のインターンで、学んだことを言語化しまとめることの難しさを知ることができました。
そのほかにも、インターンではSAIG(フューチャーのAIチーム)の進捗報告会に参加させていただき、さまざまなプロジェクトの存在、各プロジェクトの進め方、各プロジェクトの難しさなど実際の仕事の現場を体験できました。また、インターンのイベントの一環である社員の方にインタビューをさせていただき、そこでは専門分野の勉強の進め方、AIのトレンドのキャッチアップのやり方を教えていただきました。
今回のインターンでは本当に多くのことを学ばせていただきました。受け入れ先プロジェクトの方々やフューチャーHRの皆さん、本当にありがとうございました!
参考
- Apache Beam (Dataflow) 実践入門【Python】
- How Beam executes a pipeline (公式ドキュメント)
- Python を使用して Dataflow パイプラインを作成する
- GPUの使用
アイキャッチはPaul BrennanによるPixabayからの画像です。