はじめに
こんにちは、フューチャーでアルバイトをしている平野です。今回は、Vertex AI Pipelinesを利用してみて分かったTipsについて、いくつかピックアップしてまとめました。なお、コードは全てPython・Kubeflowを用いた場合を記載しています。
前提知識
Vertex AI Pipelinesとは、GCP上でMLパイプライン機能を提供するサービスです。サーバーレス方式でMLワークフローをオーケストレートします。
基本的な使い方などについては様々なドキュメントがあるので今回は省略しますが、主には以下の公式ドキュメントを参考にしました。
Vertex AI のドキュメント
公式のドキュメントです。Vertex AIの概要、チュートリアル、コードサンプルなどがまとめられています。
Kubeflowのドキュメント
Vertex AI Pipelinesを使う際に参照することになる、Kubeflowの公式ドキュメントです。こちらもKubeflowの概要からコンポーネントの作成・パイプラインの実行、サンプルなどがまとめてあります。
関連用語
MLOps on GCP 入門 〜Vertex AI Pipelines 実践〜で分かりやすく解説されていたため、参考にさせていただきました。
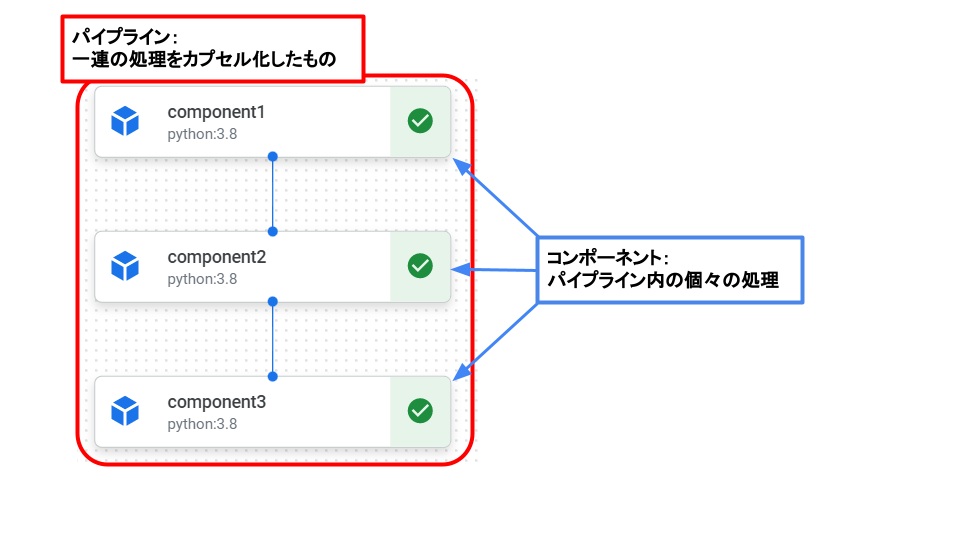
- パイプライン
機械学習の一連の処理をカプセル化したものです。Pythonで定義します。前処理やモデル学習、エンドポイントへのデプロイなどの1つ1つの処理(コンポーネント)の実行順序を記述します。パイプラインを定義する関数には@pipelineデコレータを付けます。パイプラインの内部には「精度がある値を超えたらデプロイする」などの条件分岐を含ませることも可能です。 - コンポーネント
パイプラインで実行する1つ1つの処理のことを指します。例えば、preprocess -> train -> deployを実行するパイプラインの場合、「preprocess」「train」「deploy」がコンポーネントです。コンポーネントを定義する関数には@componentデコレータを付けます。コンポーネントの実装には以下の3つが存在します。
コンポーネントの実装パターン- (1) GCR に push されているDocker imageを使う (詳細は自前のDocker imageを使って実装するには?)。
GCRにpushされているimageのURIを引数として与えることで処理を行う関数が用意されています。 - (2) パイプラインのソースコードに関数ベースで書く (詳細は事前のDocker imageの準備なしでPythonスクリプトのみで実装には?)。
dockerのimageを使わずPythonベースで好きな処理を書くことができるため、簡単な処理を試したい場合などに向いています。 - (3) Google Cloudパイプラインコンポーネントを使う
よく利用される処理についてはGoogle側がすでに用意してくれているため、事前に関数一発で呼び出して実行してくれるものになっています。
- (1) GCR に push されているDocker imageを使う (詳細は自前のDocker imageを使って実装するには?)。
参考
Tips
【基本】パイプラインを実装するには?
おさらいとしてパイプラインの実装方法から始めます。ここではコンポーネントを実装する方法の内、以下2つを紹介します。
(1) 自前のDocker imageを使って実装
(2) 事前のDocker imageの準備なしでPythonスクリプトのみで実装
(1) 自前のDocker imageを使って実装するには?
1. コンポーネントの作成
コンテナ(Dockerfile+src)とコンポーネント定義yamlを用意する
こちらの方法では、コンポーネントごとにDocker imageを用意して、そのDocker imageにコンポーネントの処理の内容を記述したPythonスクリプトを含ませることでコンポーネントを作成します。この方法は、利用するDocker imageのDockerfileやコンポーネントの各種設定を記述したyamlファイルを用意する必要がありますが、ローカルで動かしていたPythonスクリプトをそのままコンポーネント化できます。Docker imageでコンポーネントを作成するために必要なファイルは以下の3つになります。
- Pythonスクリプト:コンポーネントの処理の内容を記述する。
- Dockerfile:Pythonスクリプトの実行に必要なパッケージをインストールする。Pythonスクリプトのコピーも。
- yamlファイル:コンポーネントの入出力、使用するDocker image、Pythonスクリプト実行の際の引数の設定などを記述する。
それぞれのファイルの記述例を以下に示します。
Pythonスクリプトの記述例
import argparse # 必要なパッケージのインポート |
Dockerfileの記述例
FROM python:3.8-slim |
yamlファイルの記述例
name: foo |
2. パイプラインの作成
Pythonでパイプラインを定義する(コンポーネントの依存関係定義など)
コンポーネントの作成が終わったら、続いてそれらのコンポーネントをつなげてパイプラインを作成します。
パイプラインを定義した関数には@pipelineデコレータを付けます。引数にはパイプラインの名前、説明、pipeline_rootを指定できます。pipeline_rootにCloud Storageのバケットを指定することで、指定したバケットに各処理で生成されるアーティファクトを保持しておくことができます。
また、パイプラインをコンパイルするにはcompiler.Compiler().compile関数を使用します。引数にはコンパイルする関数、コンパイル結果を出力するjsonファイルのパスを渡します。
パイプラインの定義、コンパイルを行うPythonスクリプトの例は以下の通りです。
from kfp.v2 import compiler, components, dsl |
パイプラインを定義したファイルを実行すると、パイプライン実行時に必要なjsonファイルがcompiler.Compiler().compile()のpackage_pathに指定したパス(上記の例ではpipeline.json)に生成されます。
(2) 事前のDocker imageの準備なしでPythonスクリプトのみで実装には?
Vertex AI Pipelinesでは、コンポーネントの処理内容をPythonの関数として記述することでPythonスクリプトのみでコンポーネントを作成できます。その一方で関数の定義の仕方には若干の癖があります。コンポーネントの関数はstandaloneである必要があり、以下の要件を満たす必要があります。
- 関数の外で定義された関数や変数を含まない
- 関数内で必要なパッケージ・モジュールは関数内でimportする
- 関数の入出力の型を明記する
この方法でのコンポーネントの作成例を以下に示します。
from kfp.v2 import dsl |
コンポーネントを定義する関数には@componentデコレータを付け、base_image引数でコンポーネントを実行するコンテナイメージを指定、packages_to_install引数にリストで必要なパッケージを指定します。また、create_component_from_funcで関数をラップすることでもコンポーネント化できます(この場合は@componentデコレータは必要ありません)。create_component_from_funcの引数にもbase_image、packages_to_installがあるので、そちらでコンテナイメージ、必要なパッケージを指定できます。
コンポーネントの作成が終わったら、続いてそれらのコンポーネントをつなげてパイプラインを作成します。
パイプラインの定義、コンパイルを行うPythonスクリプトの例は以下の通りです。
from kfp.v2 import compiler, dsl |
参考
コンポーネントの依存関係を制御するには?
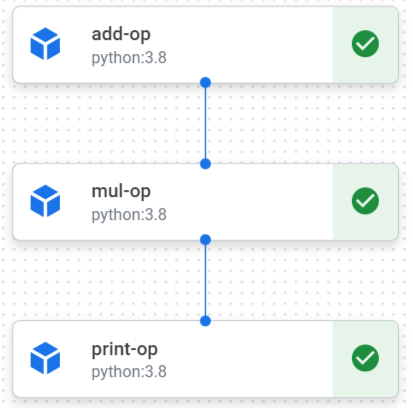
(1)パイプラインの実行順序は基本的にはコンポーネントの入出力の関係から自動的に決定されます。
例えば、以下のようなパイプラインの場合、add_op→mul_op→print_opの順に実行されます。
from kfp.v2 import dsl, compiler |
(2)パイプラインの実行順序を明示的に制御したい場合には、ContainerOp.after関数を使うことで可能です。
|
上のようなコードの場合、以下の図のようなパイプラインとなります。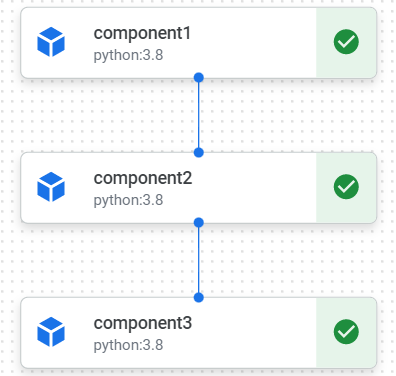
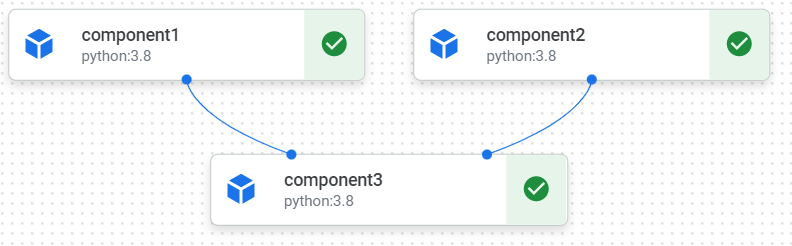
また、after関数は複数のコンポーネントを受け取ることもできます。
|
この場合、以下のようなパイプラインとなります。
参考
パイプラインを起動するには?
パイプラインの起動方法としては、GUIから起動する方法とPythonスクリプトやノートブックから起動する方法があります。GUIから起動する方法については以下の参考のコンソールをご確認ください。
Pythonスクリプトから起動する場合は、以下のようなスクリプトを作成し、実行することでパイプラインを起動できます。ノートブック(Vertex AI Workbenchなど)の場合は、以下のコードを最後のセルで実行することで起動できます。
import google.cloud.aiplatform as aip |
job.submit()のほかにjob.run()も利用でき、両者の違いは、submit()はジョブを投げ終わると終了、run()はジョブを投げた後、パイプラインの状態を定期的に表示してくれます。
参考
各コンポーネントに指定したスペックを割り当てるには?
マシンタイプを指定しない場合にはデフォルトでe2-standard-4(4コアのCPUと16GBのメモリ)が利用されます。コンポーネントのマシンタイプを指定するには、set_cpu_limit、set_memory_limit、add_node_selector_constraint、set_gpu_limitを利用します。マシンタイプを指定するとVertex AI Pipelines側が指定されたスペックに最も近いマシンを自動で割り当てます。
from kfp.v2 import dsl |
また、CustomJob.jobSpec.workerPoolSpecsから指定することもできます。
from kfp.v2 import compiler, components, dsl |
参考
実行結果のキャッシュを利用するには?
Vertex AI Pipelinesでは、パイプライン全体、タスク単位でキャッシュを利用するかどうかを選択できます。パイプライン全体でキャッシュを利用する場合には、コンパイルしたパイプラインを実行する際にenable_cachingをTrueにすることでキャッシュを利用できます。なお、enable_cachingはデフォルトでTrueとなっているのでむしろキャッシュを利用したくない場合にFalseにすることになると思います。
pl = PipelineJob( |
タスク単位でキャッシュを利用する場合は、<task_name>.set_caching_options(True)で利用できます。
|
キャッシュが利用されたかどうかは、パイプラインのGUIから確認できます。キャッシュが利用されている場合にはコンポーネントの右に以下のような矢印マークが付きます。また、ノード情報からもキャッシュ済みかを確認できます。

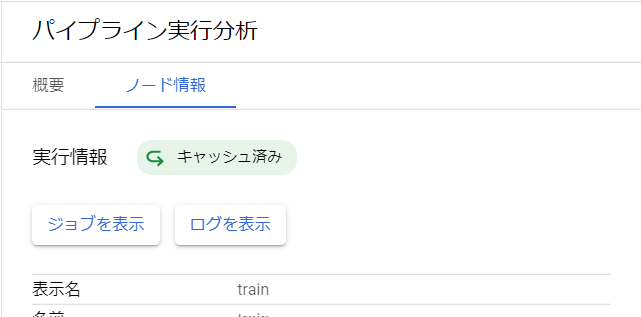
参考
パイプラインを定期実行するには?
パイプラインの定期実行はCloud Schedulerを利用することで可能です。
パイプラインの定期実行までの流れは以下のようになります。
- コンパイルしたパイプラインjsonファイルをGoogle Cloud Storageにアップロード
以下のコマンドでローカルのファイルをバケットにアップロードします。
gsutil cp <ローカルファイルまでのパス> gs://<BUCKET_NAME>/<ファイル名> |
- HTTPリクエストに応じてパイプラインを実行するPythonスクリプトの作成
Cloud FunctionsでHTTPリクエストが送信された場合にパイプラインを実行するコードを作成します。
以下がPythonスクリプトの例です。HTTPリクエストのbodyに、実行するパイプラインのjsonファイルまでのパス、パイプラインに渡すパラメータが含まれているという想定です。
import json |
以下はHTTPリクエストのbodyの内容です。Cloud Schedulerジョブを作成する際に以下の内容を含むjsonファイルを使用します。
{ |
- Cloud Functionsの関数をデプロイ
続いて、HTTPトリガーを使用して関数をデプロイします。
上で作成したPythonスクリプトを含むディレクトリで以下のコマンドを実行します。
gcloud functions deploy python-http-function \ |
- Cloud Schedulerジョブを作成
最後に以下のコマンドでCloud Schedulerジョブを作成します。以下の例では毎日の朝9時にパイプラインが実行されます。
gcloud scheduler jobs create http run-pipeline \ |
参考
- Cloud Scheduler でパイプライン実行をスケジュールする
- Google Cloud CLI を使用して Cloud Functions(第 2 世代)の関数を作成してデプロイする
- cron ジョブを作成して構成する
- gcloud コマンドライン リファレンス
引数を渡すには?
ユーザ→パイプライン、コンポーネント→コンポーネント
パイプライン実行時に引数を渡すには、aiplatform.PipelineJobのparameter_valuesを指定することで可能です。辞書型で変数名と値のペアで渡すことができます。あとはargparseなどを利用すれば、コマンドライン引数からパイプラインのパラメータを入力できます。
import argparse |
コンポーネント間でのデータの受け渡しは、渡すデータが単一データか複数データかで異なります。
単一データの受け渡しの場合、以下のようになります。
from kfp.v2 import dsl |
単一データの場合、関数の出力は<task_name>.outputで渡すことができます。
一方、複数データの受け渡しの場合は、以下のようになります。
from typing import NamedTuple |
複数データを出力する場合は、NamedTupleを用いて属性名を指定して出力し、それらを受け取る際には<task_name>.outputs['<key>']で各データを指定します。
参考
- Understanding how data is passed between components
- Kubeflow Pipelinesにおけるコンポーネント間のデータ受け取り方・渡し方まとめ - その1
- Kubeflow Pipelinesにおけるコンポーネント間のデータ受け取り方・渡し方まとめ - その2
パラメータ・中間データ・モデルを管理するには?
入力パラメータの保存
パイプラインを定義した関数の入力が自動で保存されます。例えばパイプラインを以下のような関数とした場合、learning_rateとmax_depthが「パイプライン実行分析」の「実行パラメータ」や、パイプライン比較の「パラメータ」として表示されます。
また、これらのパラメータはパイプラインのリランの際に、別の値を入力してパイプラインを実行できます。リランの際にはこれらのパラメータしか変更できないため、変更の可能性があるパラメータはすべてパイプラインの関数の引数としておくことをおすすめします。
|

データセット、モデル、指標の保存
データを保存するには、コンポーネントの関数の引数にOutput[<type>]もしくはOutputPath("<type>")型の引数を作ることで可能です。<type>にはDataset、Model、Metrics、Executionが指定できます。
from kfp.v2 import dsl |
また、Dockerベースの場合には、コンポーネントの仕様を定義したyamlファイルのoutputsに記述することでできます。
name: train |
指標については、以下のようにlog_metric(<name>, <value>)を使うことで、のちの比較において「指標」として見ることができます。
from kfp.v2 import dsl |
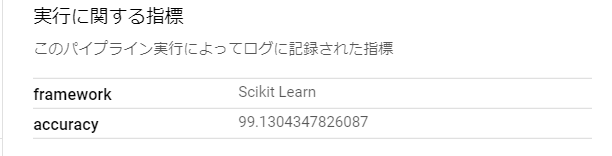 →各データについて、後から確認したくなった場合、Vertex AI Pipelinesでは、どのようなパイプラインの中で生成されたのかをGUIで見ることができます。
→各データについて、後から確認したくなった場合、Vertex AI Pipelinesでは、どのようなパイプラインの中で生成されたのかをGUIで見ることができます。
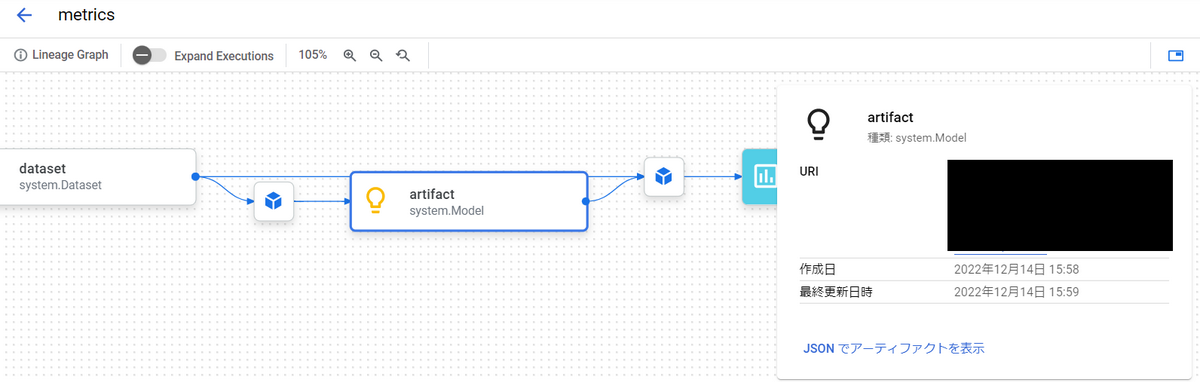
ログを確認するには?
ログはパイプラインのコンポーネントごとに見ることができます。
Vertex AI Pipelinesのコンソールからログを見たいパイプラインを選択し、表示されるパイプラインのグラフからコンポーネントを選択することで、画面下部にコンポーネントのログが表示されます。
ログは標準出力、標準エラー出力に出力されたものがログに表示されます。
処理時間・起動時間(Pythonスクリプト・Docker image)を確認するには?
パイプラインの処理時間や開始時刻、終了時刻はパイプライン一覧のページから確認できます。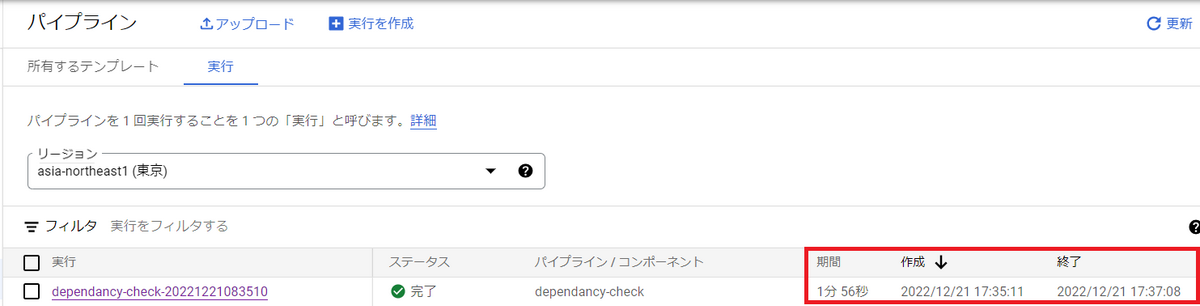
また、パイプラインの詳細のページからは各コンポーネントの処理時間、開始時刻、終了時刻を確認できます。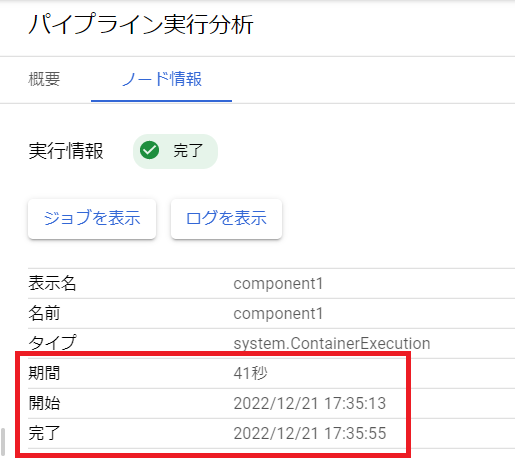
パイプラインのグループ分け・実行結果を比較するには?
Vertex AI Pipelinesでは、パイプライン実行で生じる様々なデータ(入力パラメータ、データセット、モデル、指標、etc)を保存でき、後でそれらを確認したり、複数のパイプラインを比較したりできます。データの保存についてはパラメータ・中間データ・モデルを管理するには?をご覧ください。
パイプラインのグルーピング
パイプラインをのちの比較のためにグルーピングしておきたい場合には、Vertex AI Experimentsが便利です。Vertex AI Experimentsではexperimentを作成してそこにパイプラインを登録できます。experimentの作成は以下のようにしてできます。
import google.cloud.aiplatform as aip |
パイプライン実行時に以下のように作成したexperimentを指定することでパイプラインをexperimentに登録できます。
import google.cloud.aiplatform as aip |
experimentはサイドバーの「テスト」から見ることができます。
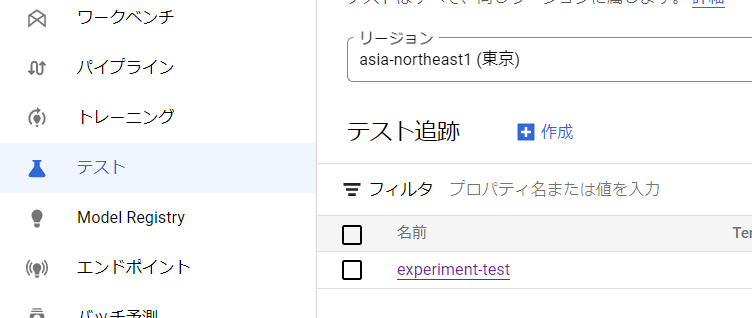
パイプラインの比較
パイプラインを比較する方法はVertex AI PipelinesのGUIから行う方法と、Vertex AI Experimentsから行う方法の2種類あります。
Vertex AI PipelinesのGUIから行う場合は、パイプライン一覧のページから比較したいパイプラインを選択後、比較を押すことで以下の図のような比較が可能です。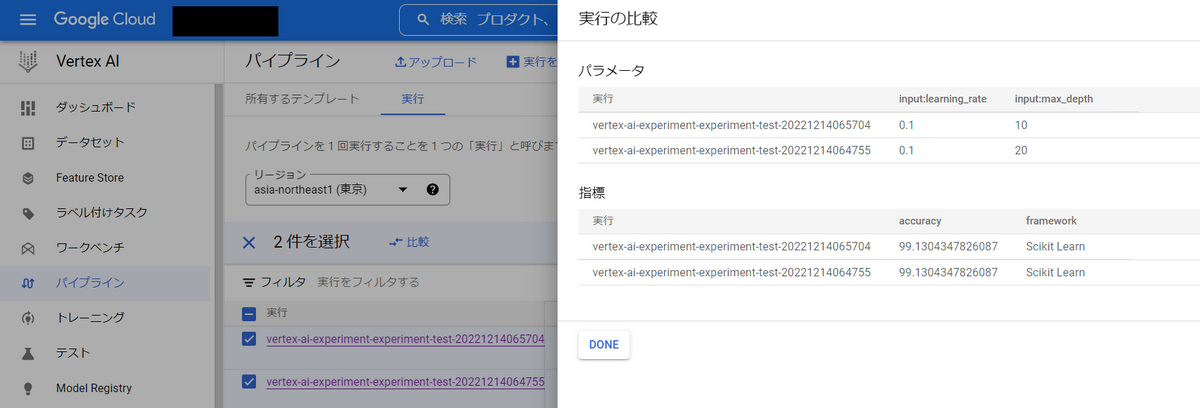
Vertex AI Experimentsから行う場合は、サイドバーの「テスト」から見たいexperimentを選ぶと、以下のように比較ができます。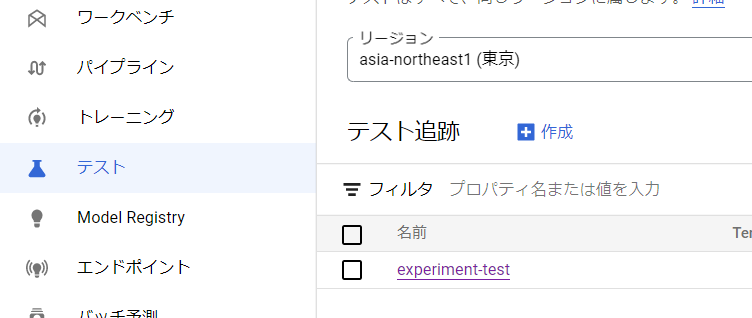
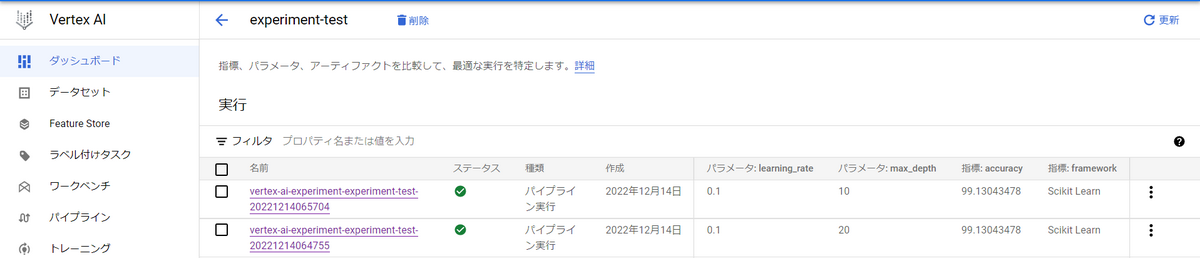
また、Pythonスクリプトでターミナル上から比較することも可能です。以下のスクリプトを実行することで対象のexperiment内のパイプラインを比較できます。
import google.cloud.aiplatform as aip |
以下が実行結果です。![]()
Vertex AI Pipelinesを利用するコストは?
Vertex AI Pipelinesでは、パイプライン実行ごとに0.03ドルかかります(執筆時点)
加えて、コンポーネントによって使用されるCompute Engineリソースやデータの保存に使用されるGoogle Cloudリソースに対しても課金されます。
例として、リージョンにasia-northeast1、コンポーネントのマシンタイプにn1-standard-4を指定してパイプラインを1時間実行した場合は
かかる計算になります。
料金の詳細については、以下の参考のリンク先をご参照ください。
参考
起動時間の目安は?
環境や実行するパイプラインによって起動時間は変わると思いますが、参考までに以下のような簡単なパイプラインで確認してみたところ、約1分後にprintの内容がログに表示されました。
import google.cloud.aiplatform as aip |
ログ![]()
ディレクトリ構成はどうすればよい?
コンポーネント関連のファイルは、例えば以下のような構成が記載されています。
components/<component group>/<component name>/ |
実際にこの構成で管理された公式のサンプルコードがありましたので、詳細はそちらをご参照ください。
参考
テストはどうすればよい?
kubeflowの公式のサンプルでは、unittestを用いたテストの例がありました。
参考
パイプライン実行のためのサービスアカウントは?
Vertex AI Pipelines関連のサービスアカウントは、パイプライン実行の際に指定できるサービスアカウントと、パイプライン実行時に各種リソースにアクセスするためにGoogle側が作成するService agents(gcp-sa-aiplatform-cc.iam.gserviceaccount.comとgcp-sa-aiplatform.iam.gserviceaccount.com)の計3つが存在します。
1つめのパイプライン実行時のサービスアカウントを指定しない場合、Compute Engineのデフォルトのサービスアカウントを使用してパイプラインを実行します。
Compute Engineのデフォルトのサービスアカウントには、プロジェクト編集者のロールがデフォルトで付与されています。そのため、公式のガイドではきめ細かい権限を持つサービスアカウントの作成に関する項目があります。
gcp-sa-aiplatform-cc.iam.gserviceaccount.comとgcp-sa-aiplatform.iam.gserviceaccount.comはVertex AIを利用し始めた段階でGoogle側が自動で作成してくれるため、利用者側が事前に作成する必要はありません。また、パイプライン実行時に指定する必要もありません。
gcp-sa-aiplatform-cc.iam.gserviceaccount.comはカスタムトレーニングコードを実行する際に利用され、gcp-sa-aiplatform.iam.gserviceaccount.comはVertex AI全般の機能を動作させるために利用されるようです。これら2つのアカウントが持つロールについてはこちらをご参照ください。
参考
気を付けるべきクォータ制限は?
Vertex AI Pipelinesでは、パイプラインジョブの同時実行数やタスクの並列実行数に上限が存在します。また、1つのパイプラインジョブで実行できるタスク数、入出力にも上限があります。
| 項目 | 値 |
|---|---|
| パイプライン タスクの並列実行 | 600 |
| 同時実行パイプライン ジョブ | 300 |
| ジョブあたりのパイプライン タスクの数 | 10,000 |
| パイプラインタスクあたりの入力アーティファクトと出力アーティファクト | 100 |
| パイプラインジョブあたりの入力アーティファクトと出力アーティファクト | 10,000 |
参考
おわりに
Vertex AI Pipelinesを利用するにあたって気になりそうなことをまとめました。皆様の一助となれば幸いです。