はじめに
こんにちは、フューチャーでアルバイトをしている平野です。
今回は「モデル・データの監視」について、なぜ監視が必要なのか、監視するべき項目は何か、監視するにはどのようなツールがあるのかについてご紹介します。
注意点として、今回のブログでのツールの紹介は、「各ツールでどのようなことができるのか」について書いているので、各ツールの使い方などは各公式サイトなどをご参照ください。
Vertex AI Model MonitoringとEvidently AIについては、Vertex AI Model MonitoringとEvidently AIで運用中のモデル・データを監視する【Input Metrics編】で具体的な使い方まで解説しているため、ご覧いただけると幸いです。
なぜ監視するのか
モデルの学習が完了し、そのモデルを本番環境にデプロイし、運用が開始されればそれでミッション完了といえるのでしょうか? 答えはNOです。なぜなら、モデルが本番環境で期待通り稼働するか分からないからです。
例えば、学習データと本番データが大きく乖離している場合、モデルの予測は大きく外れてしまう可能性があります。また、現実世界は時々刻々と変化します。そのため、運用開始時には想定通りの本番データが得られていたのに、徐々に学習データと乖離していくことも考えられます。
この場合、運用開始時には期待通りに稼働していたのに、時間が経つにつれてモデルの精度が低下していくことになります。定期的にモデルを再学習させることによってこの状況を回避することもできますが、モデルの再学習には時間やコストがかかるため、再学習の回数は可能な限り少なく抑えたい所です。
そこで、本番環境でモデルが期待通りに稼働しているかを監視する必要が出てきます。本番環境での入力データやモデルのパフォーマンスを監視し、入力データが学習データと大きく乖離した場合やモデルの精度が大きく低下した場合にモデルを更新することで、モデルを常に期待通りに稼働させつつ、再学習のコストを下げることができます。
監視する項目
監視すべき項目はモデルに求める精度や運用状況によって変わるとは思いますが、ここでは一般的に監視する必要があると考えられる項目を紹介します。
- Software Metrics
リソースの使用率やデータ量、データの更新頻度などです。リソースの使用率が100%に近い場合、リソースのスケールを考える必要があります。また、そもそもMLシステムが正しく稼働できているかを確認するため、システムログも監視する必要があります。項目 説明 リソース使用率 メモリ・CPU・GPUなどのハードウェアリソースの使用率 リクエスト数 予測リクエストの頻度など レスポンスタイム 予測リクエストから予測を返すまでの時間やその平均など 更新頻度 データが定期的に入ってくるか データ量 更新時に想定通りの量のデータが入ってきているか - Input Metrics
モデルのパフォーマンスを監視するためには次に紹介するOutput metricsを監視することが重要なのですが、本番環境では入力データに対する正解データがすぐには手に入らない場合が多くあります。そこで入力データを監視することで間接的にモデル精度の低下を検出します。項目 説明 欠損値 欠損値が含まれているかや欠損値の割合など 値が範囲内か 正の値が来るべきところに負の値が来ているなど columnが増減していないか アップデートなどで入力形式が変わっていないかなど 統計量が範囲内か 平均、分散などの統計量が期待する範囲内に収まっているか ドリフト 入力データの分布が時間とともに変化していないか スキュー 学習データの分布と本番環境でのデータの分布に乖離がないか 外れ値 平均から標準偏差の3倍以上離れているなど 列同士の相関 学習データでの相関と本番環境のデータでの相関に違いがみられないかなど - Output Metrics
正解データが手に入る場合にはモデルの予測の正解率を監視することで、精度の低下を検出できます。また、入力と出力の関係(特徴量寄与率)や予測の偏りなども監視することで、より正確にモデルの再学習のタイミングを計ることができます。項目 説明 モデル精度 Accuracy、Precision、ROC AUCなど 予測の偏り 歪度、尖度など。学習時と本番環境時で予測の分布に変化がある場合には、学習データセットが本番環境でのデータをうまく再現できていない可能性がある。 特徴量寄与率 入出力の相関やShapleyなど。特徴量寄与率が時間経過とともに変化している場合には、精度が低下している可能性がある。 ビジネス指標 CTRやCVRなど
ツールの紹介
Great Expectations
概要
Great Expectationsは、ユーザー独自のデータ品質テストの作成、テストの実行、テスト結果の可視化を可能とするOSS Pythonライブラリです。用意されているテストが豊富でデータの品質チェックに特化していることが特徴です(用意されているテスト一覧)。
監視できる項目例
- Input Metrics
欠損値、各値が範囲内か、columnの増減、統計値が範囲内か、データドリフト/スキュー、外れ値など
詳細
データの品質テスト(テストのことをexpectation)、エラーの文章化(html形式でどのテストをパスし、どのテストでエラーを起こしたかが見れる)、プロファイリング(統計量の計算)が可能となっています。
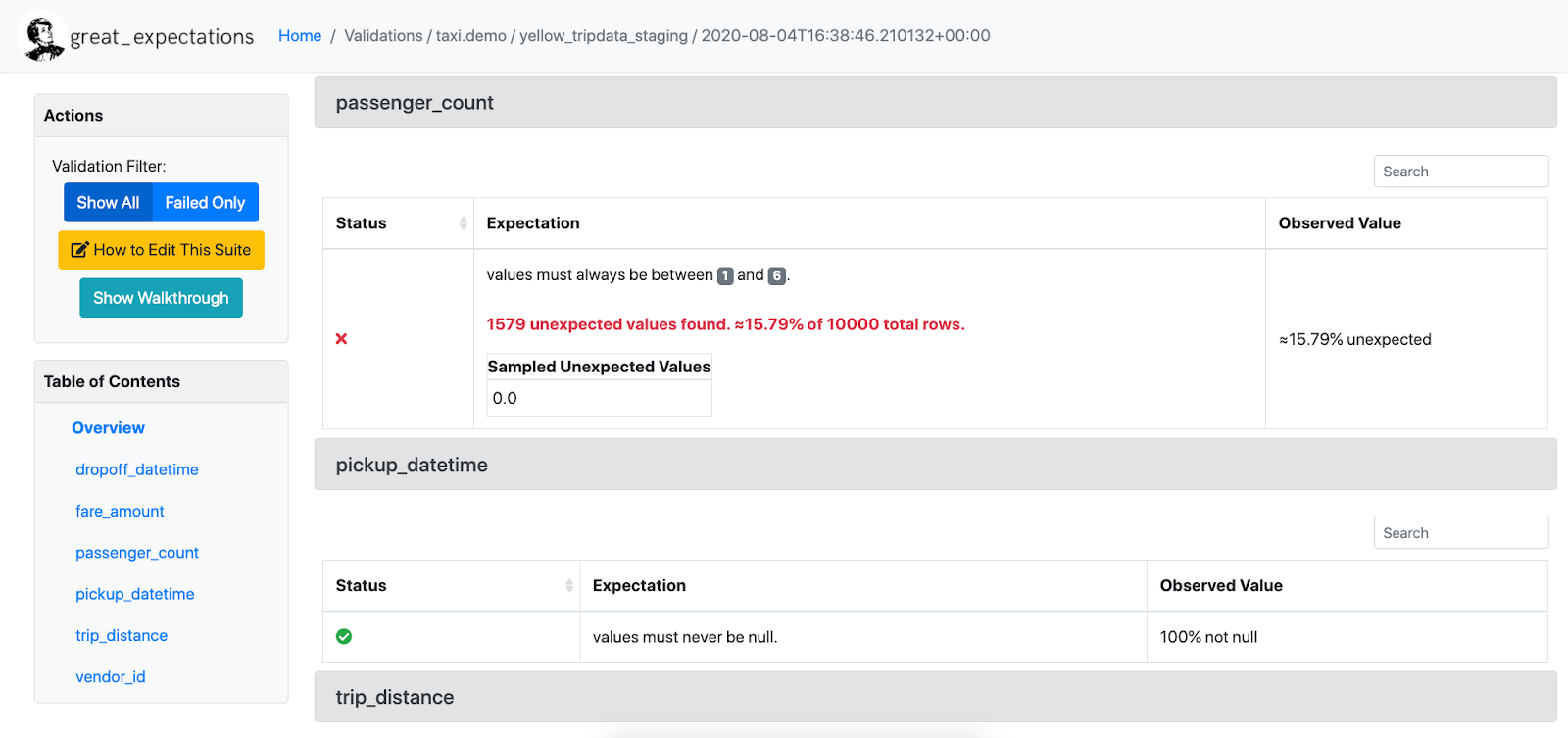
※Great Expectations 公式Docsより画像引用
懸念点としては、モデル精度の監視や特徴量寄与率などのOutput Metricsについては監視ができないと思われます。また、テストの定期的な実行やリアルタイム監視などもGreat Expectations単体では難しいと思われます。
whylogs
概要
whylogsは、データベースに保存されているデータに対してスキーマチェック、ドリフト/スキュー検出、解析を可能とするOSS Pythonライブラリです。テーブルデータやテキストデータ以外に画像や埋め込み表現も扱うことができるのが特徴です。
監視できる項目例
- Input Metrics
欠損値、各値が範囲内か、統計値が範囲内か、データドリフト/スキューなど
詳細
データの統計値の計算、条件を満たしているかのテスト、分布の可視化、別データセットとの比較が可能です。profileと呼ばれる統計値のセット(カスタマイズ可能)を作成し、それをもとに可視化や条件を満たすかのテストを行うという流れになります。また、有償のWhyLabsと組み合わせれば、データの自動監視も可能となります。
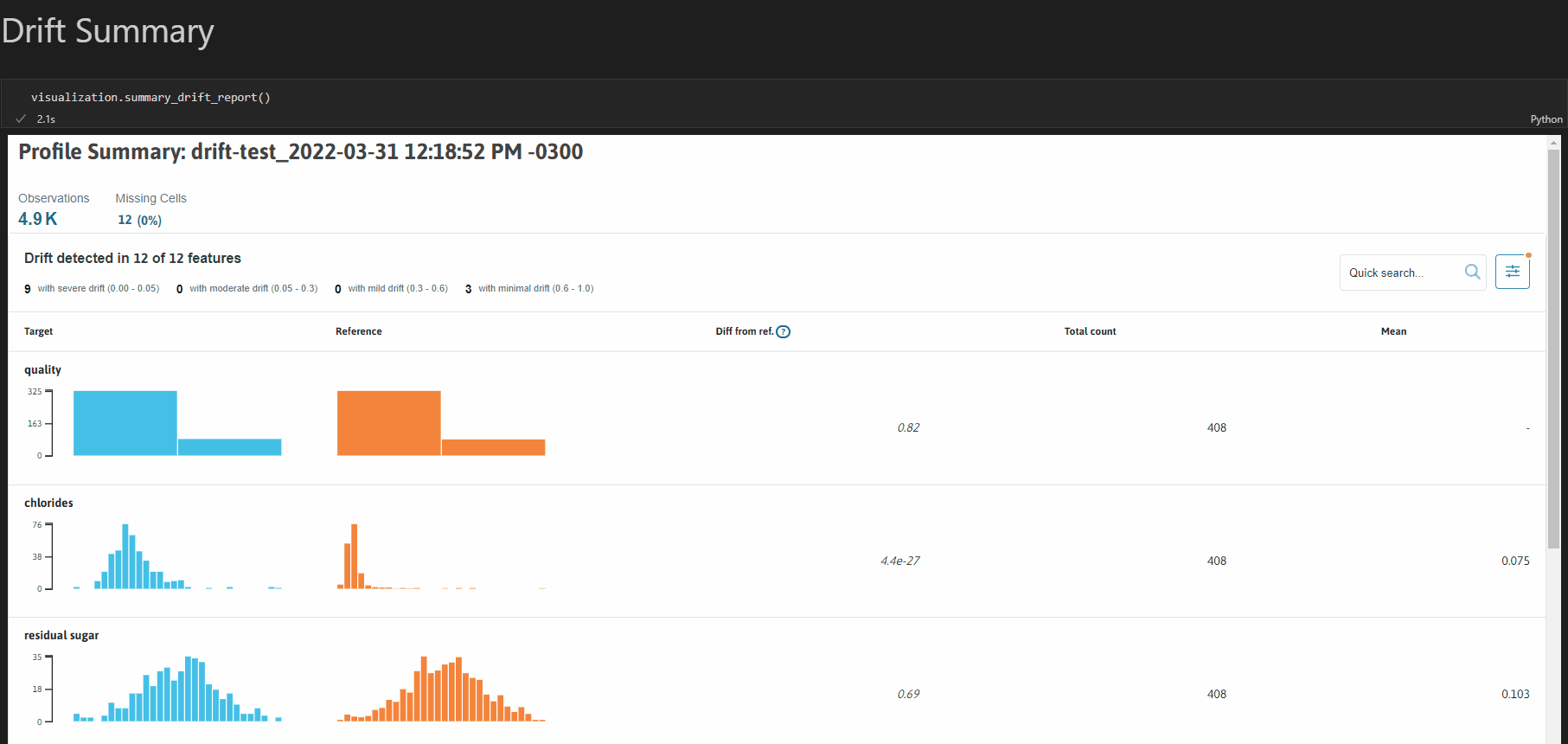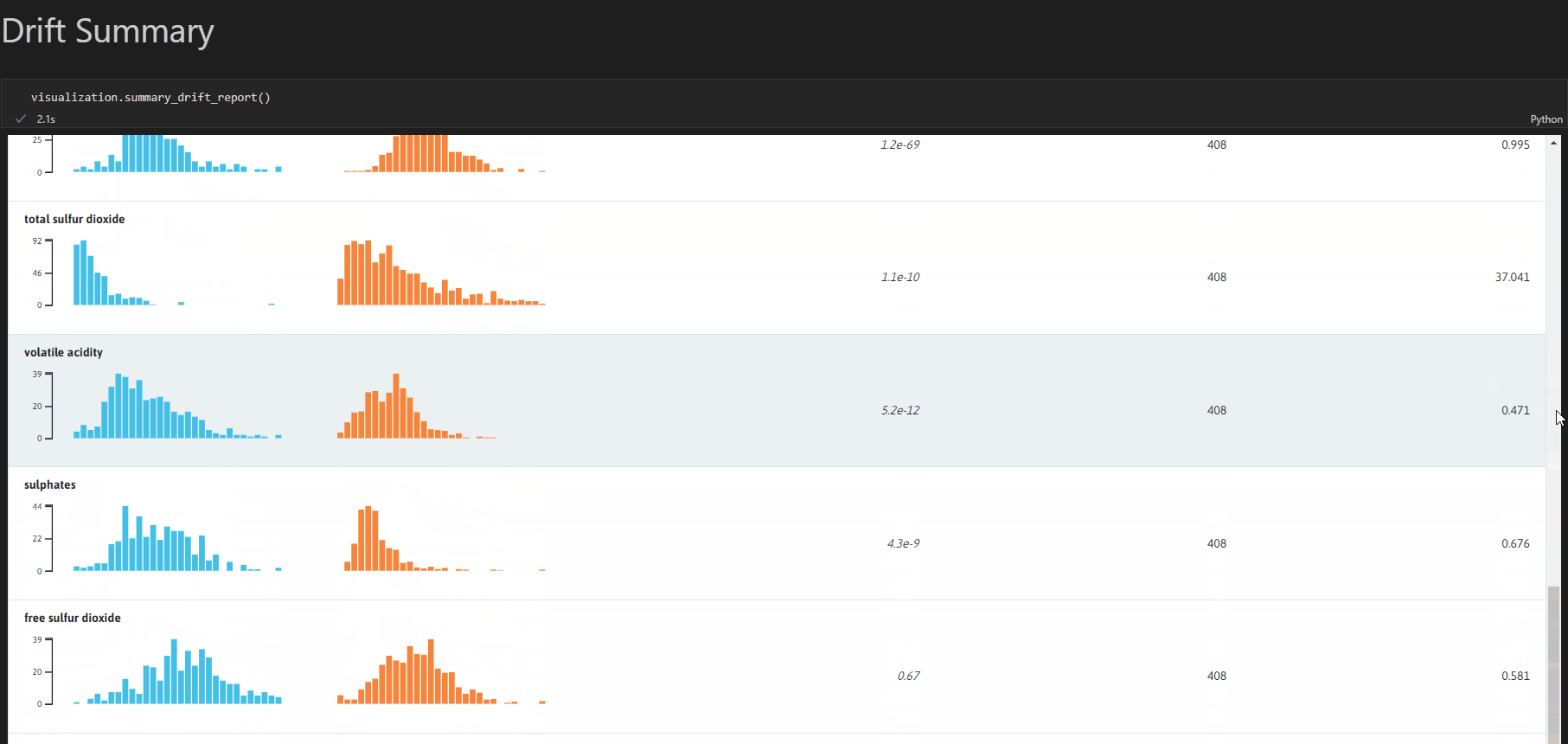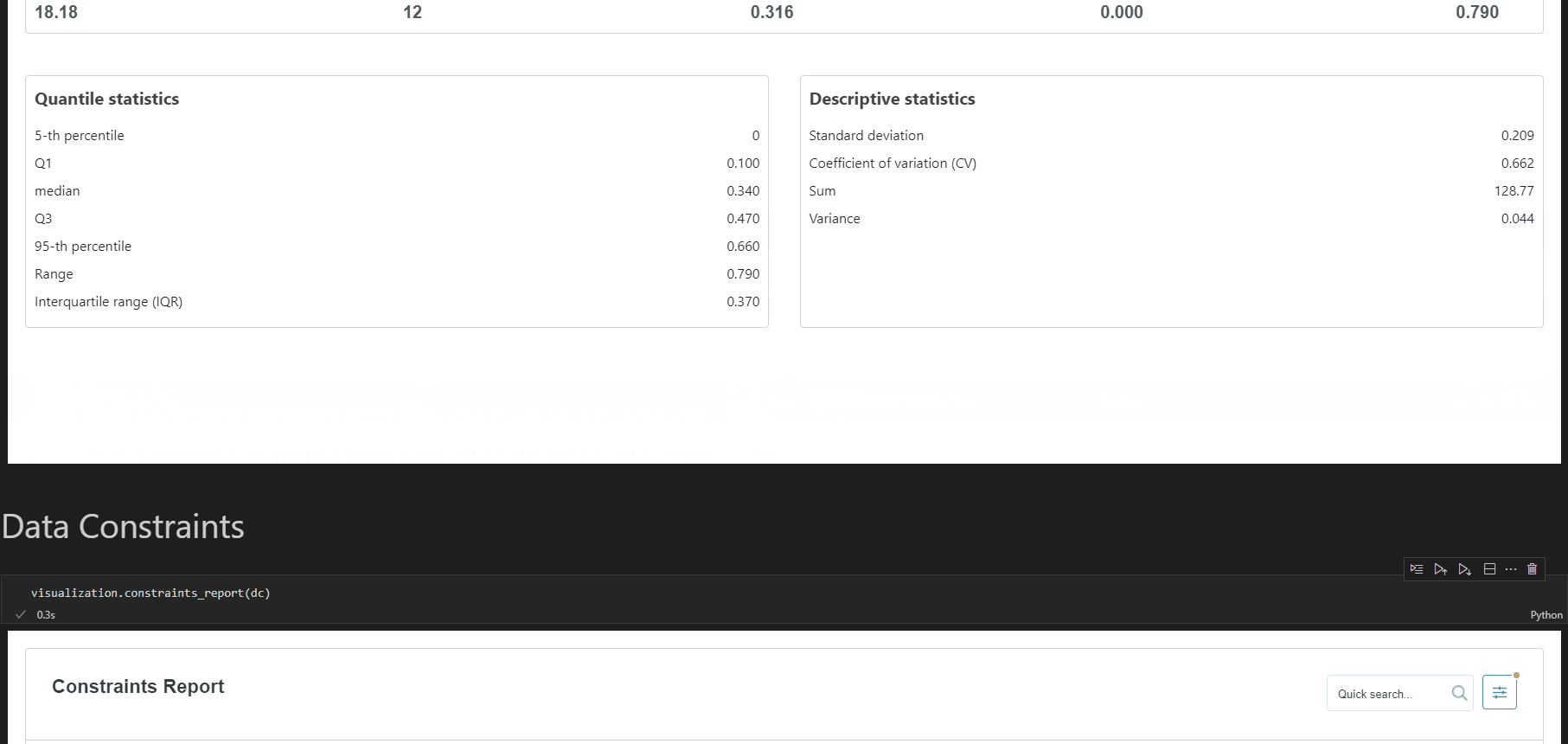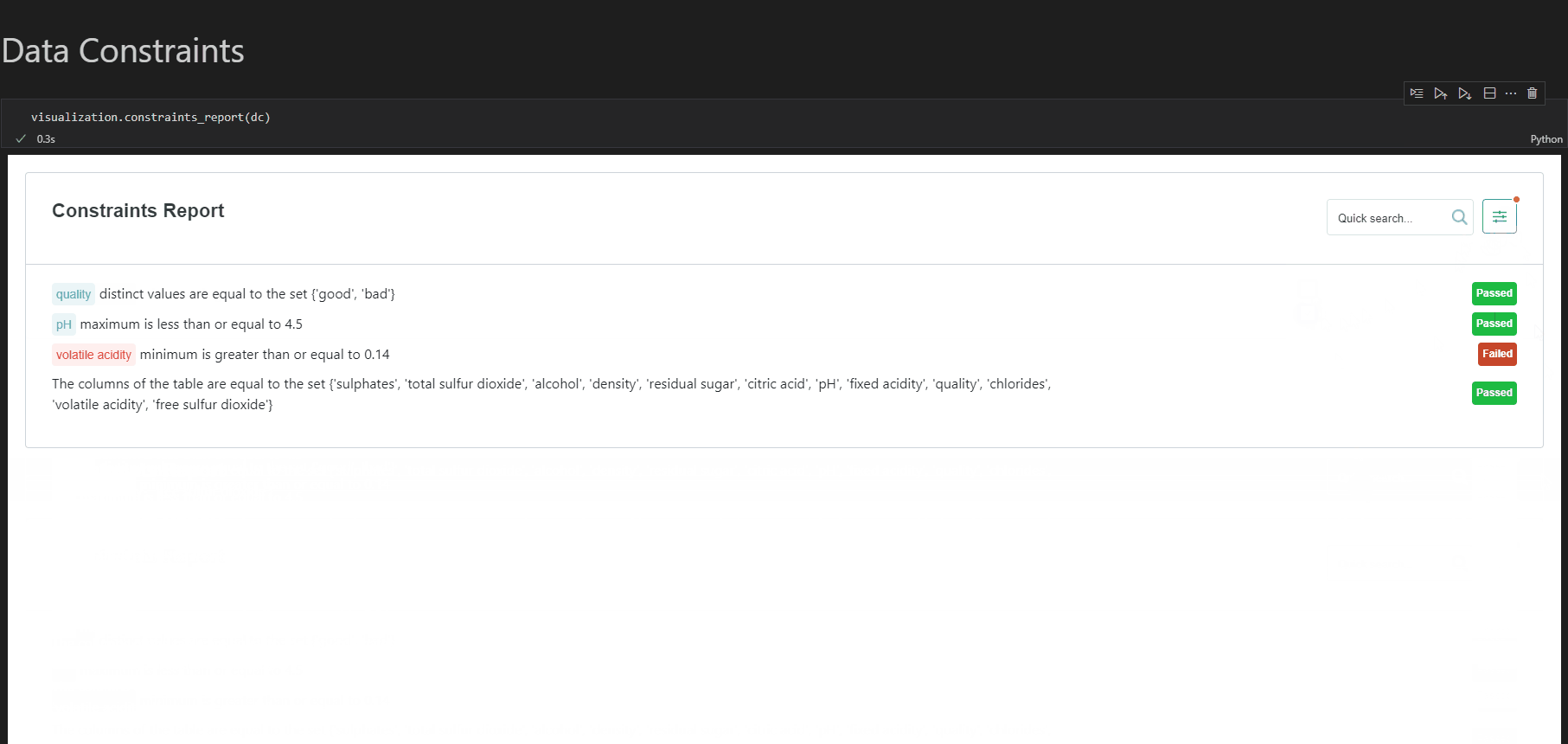
※whylogs GitHubより画像引用
懸念点としては、WhyLabsを用いない場合には、Notebookを使うことでしか可視化ができないと思われます。また、profileを保存できるのですが、現状ではローカル、AWS S3、WhyLabsへ保存する機能しか提供されていない点も懸念点となり得そうです。
Alibi Detect
概要
Alibi Detectは、モデルの学習に用いたデータセットや本番データをDetectorに学習させ、Detectorに外れ値、Adversarial Example、ドリフト検出をさせるOSS Pythonライブラリです。用意されているアルゴリズムが多く、複数のアルゴリズムを併用して検出精度を上げたい場合などに有用です。また、機械学習モデルを用いて監視するため、単純な統計量からは検出できないような異常を検出したい場合などにも使えそうです。
監視できる項目例
- Input Metrics
データドリフト/スキュー、外れ値など
詳細
バックエンドにPyTorch、TensorFlowが使われており、機械学習のモデルを使って外れ値、Adversarial Example、データドリフトを検出できます。また、公式のドキュメントにサンプルが豊富に用意されているため、使いやすさは高そうです。
一方で、機械学習モデルを使った検出方法となるため、検出精度と速度のトレードオフや、学習に用いるデータセットの質によって精度が変化することが考えられます。また、Pythonライブラリであるため、他に紹介しているツールのような、GUIやコマンドですぐに監視を始めるといったことはできず、しっかりとコードを書く必要があります(コード例)。またPythonを実行して初めて検出結果が得られるため、定期実行やリアルタイム監視といったことはAlibi Detect単体では難しく、これらを行いたい場合には別のツールと併用する必要があると思われます。
Monte Carlo
概要
Monte Carloは、データベースに接続することで、自動でデータベースの異常検知、通知を行い、また原因解明のためのツールを提供するプラットフォームです。機械学習を利用してデータを解析してくれるので、ユーザー側で詳細な設定やコーディングをせずとも、データの監視が可能です。
監視できる項目例
- Software Metrics
データ量、更新頻度など - Input Metrics
欠損値、columnの増減、データドリフト/スキュー、外れ値など
詳細
利用を開始した時点で、データの更新頻度、データ量(どの程度追加/削除/更新されたか)、スキーマが自動でチェックされます。そのほか、こちらに記載されている項目の監視も追加で行うことができます。また、ユーザーが独自の設定を行うことも可能で、SQLでルールを設定することで特定の条件でのデータを監視したり、APIやSDKで監視を設定したりできます。
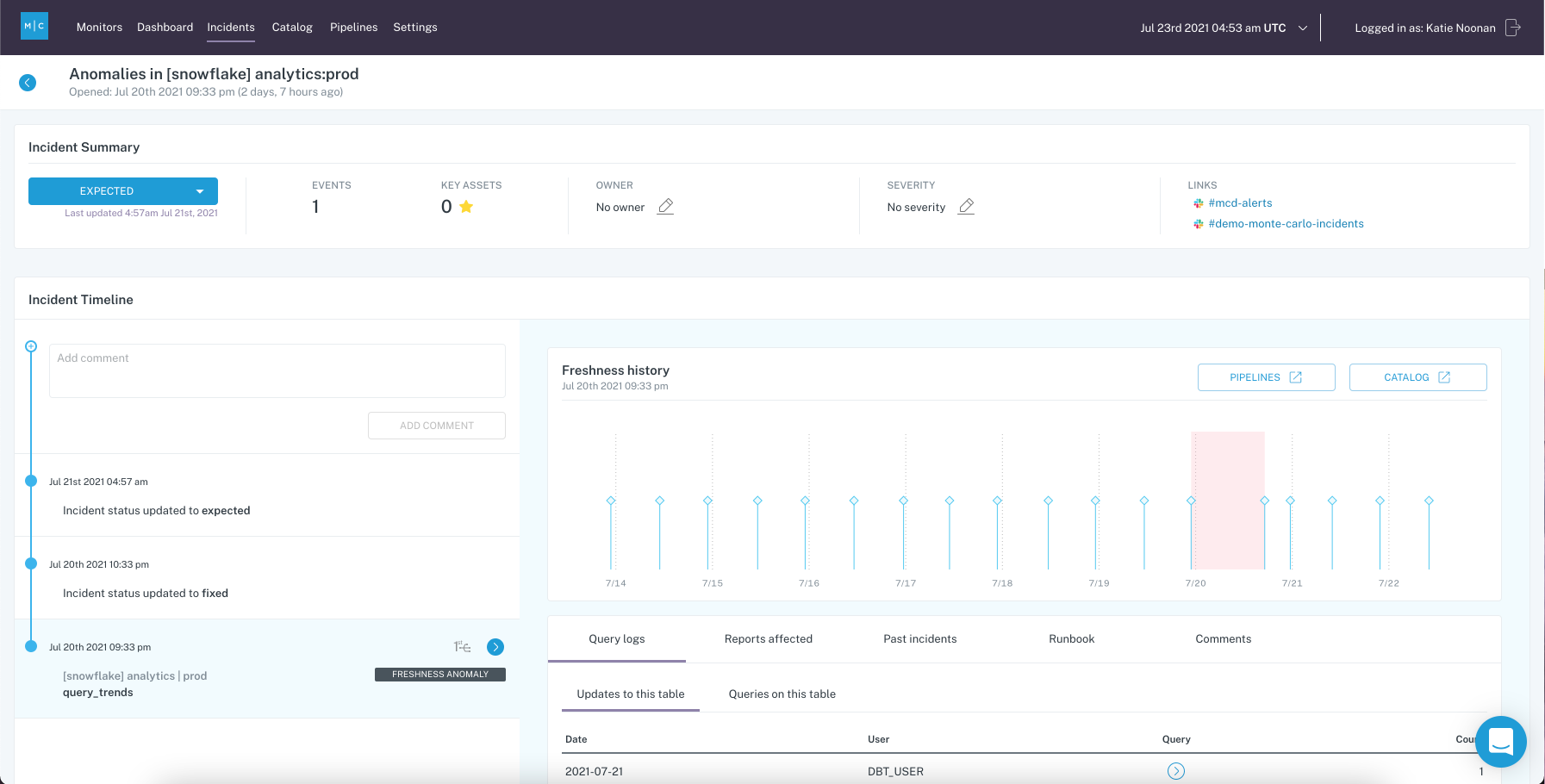
※Monte Carlo 公式Docsより画像引用
懸念点としては、Great Expectationsと同様にOutput Metricsについては監視できないと思われます。Intput Metricsについての監視で十分な場合にMonte Carloは使えるかと思います。
Evidently AI
概要
Evidently AIは50以上の用意されたテスト(スキーマチェックからドリフト/スキュー検出まで)からテストセットを作成、作成したテストセットでデータを検証、検証結果の可視化、本番環境のモデルのリアルタイム監視を可能とするOSS Pythonライブラリです。OSSでありながら、データの品質チェック、ドリフト/スキュー検出、可視化、リアルタイム監視が可能となっています。

※Evidently AI 公式Docsより画像引用
監視できる項目例
- Input Metrics
欠損値、各値が範囲内か、columnの増減、統計値が範囲内か、データドリフト/スキュー、相関係数など - Output Metrics
モデル精度、特徴量寄与率など
詳細
TestとReportの2つがあり、Testでは条件を設定することでデータがその条件を満たしているかのチェックができます。Testは50以上のものが用意されており、それらを組み合わせたり、プリセットを利用できます。notebookで実行することでテスト結果を可視化できます。
Reportではデータの統計値や分布、ドリフト、モデルのパフォーマンスを可視化できます。結果はHTML形式、json形式、Pythonの辞書型で出力可能で、HTML形式の場合、ダッシュボード上からGUIでいろいろと操作することが可能です。また、Grafana dashboardを使って本番環境で稼働しているモデルを監視することもできます。
ただし、HTML形式の場合、インタラクティブな処理に対応するために、全データを取り込んでおく必要があり、大規模なデータセットの場合、ロードに時間がかかってしまうようです。
HTML reports may take time to load. This is because they store some of the data inside the HTML to generate the interactive plots. The exact limitation depends on your infrastructure (e.g., memory).
Citadel AI
概要
Citadel AIは、モデル開発のサポート(モデルの診断レポート、検証、弱点の原因解明と改善)を行うCitadel Lensと、本番環境での監視(モニタリング、異常入力のフィルタリング、モデルの判断根拠の可視化)を行ってくれるCitadel Radarの2つの機能を提供しています。
モデル開発から本番環境までを1つのサービスでカバーできます。
監視できる項目例
- Input Metrics
欠損値、データドリフト/スキュー、外れ値など - Output Metrics
特徴量寄与率など
詳細
- Citadel Lens
モデル開発時やPoCにおいて、モデルのテストを行い、モデルの即時診断レポートを生成してくれます。数値データを扱うモデルや画像を扱うモデルなど様々なモデでき、ができ、バージョンの異なるモデルの性能比較や原因分析が可能です。

※Citadel AIの公式ページより動画引用
- Citadel Radar
本番環境のデータを常時モニタリングすることで、データドリフトやスキューをリアルタイムに検知してくれます。また、入出力データをテストし、不正データや異常値、Adversarial Attackなどをブロックしたり、タグ付けしたりなども可能です。特徴量寄与率や反実仮想分析などでモデルの判断根拠の可視化も可能となっています。

※Citadel AIの公式ページより動画引用
懸念点としては、製品であるため、検証するためにはフォームの登録かEmailでの連絡が必要そうな点です。
TensorFlow Data Validation
概要
Tensorflow Data Validationは学習データ/本番データの統計量計算、スキーマチェック、ドリフト/スキューの検知を可能とするOSS Pythonライブラリです。内部でApache Beamが使われているため、データ量に応じてスケーリングが可能で、大量のデータに対して監視したい場合や監視したいデータの量が変化する可能性がある場合に使えそうです。
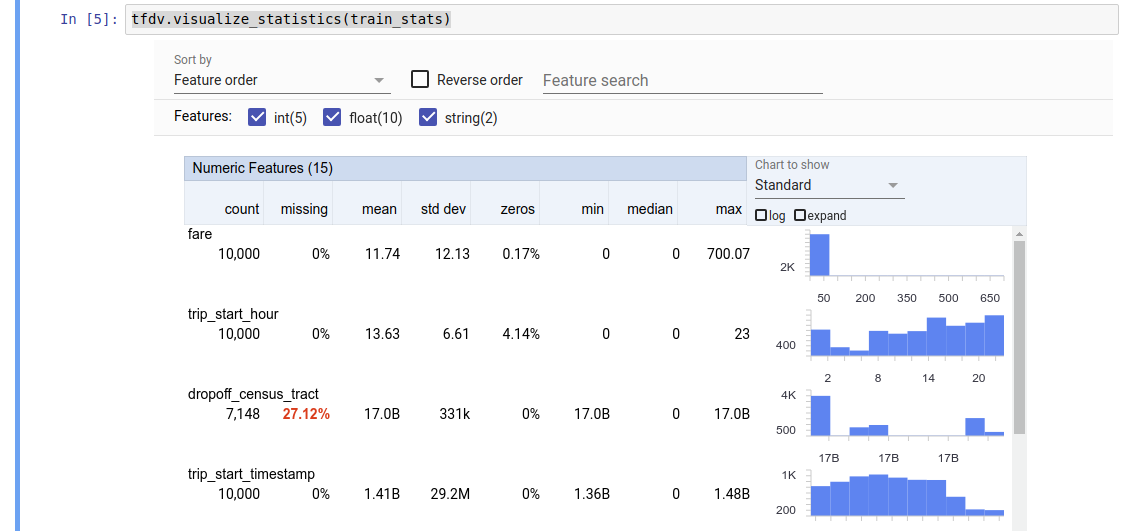
Tensorflowデータ検証を開始するより画像引用
監視できる項目例
- Input Metrics
欠損値、各値が範囲内か、columnの増減、統計値が範囲内か、データドリフト/スキュー、外れ値など - Output Metrics
モデル精度など
詳細
統計量の計算、データのスキーマチェック、ドリフト・スキュー検出、可視化/比較などが可能です。
学習データをもとに統計量のベースライン、各特徴量の型(スキーマ)を推論してくれ、本番データをそれらと比較することでドリフト・スキュー検出、型チェックを行います。スキーマは学習データから自動で作成されますが、変更することも可能です。また、MLパイプラインの中にTensorFlow Data Validationの機能を組み込むことが可能で、例えば、データ生成パイプラインの最後に統計計算を付け加えることなどができます。
懸念点としては、利用のためにはApache BeamとApache Arrowが必要で、スケーリングの利点を活かそうと思うと、少々コーディングが必要となってしまう点がありそうです。こちらはTensorFlow Data ValidationをGCPで利用する場合の例ですが、GUIからスケーリングの設定や監視項目の変更などはできず、コードを変更する必要がありそうです。
Vertex AI Model Monitoring
概要
Vertex AI Model MonitoringはGCPのサービスであるVertex AIの機能の1つで、コードを書くことなく、モデルの予測入力データをモニタリングし、特徴量のスキューとドリフトをモニタリングするための機能です。GCPでMLシステムを運用している場合に、最も手軽に導入できる監視システムです。

※Google Could Blog: Monitor models for training-serving skew with Vertex AIより画像引用
監視できる項目例
- Input Metrics
データドリフト/スキューなど - Output Metrics
モデル精度、特徴量寄与率など
詳細
本番環境の入力データをサンプリングしてベースライン(トレーニングデータや直近の本番環境入力データ)と比較し、閾値を超えるとスキューやドリフトとみなします。
また、Vertex AIの別の機能であるVertex Explainable AIと組み合わせることで特徴アトリビューション(上でいう特徴量寄与率)を監視できます。
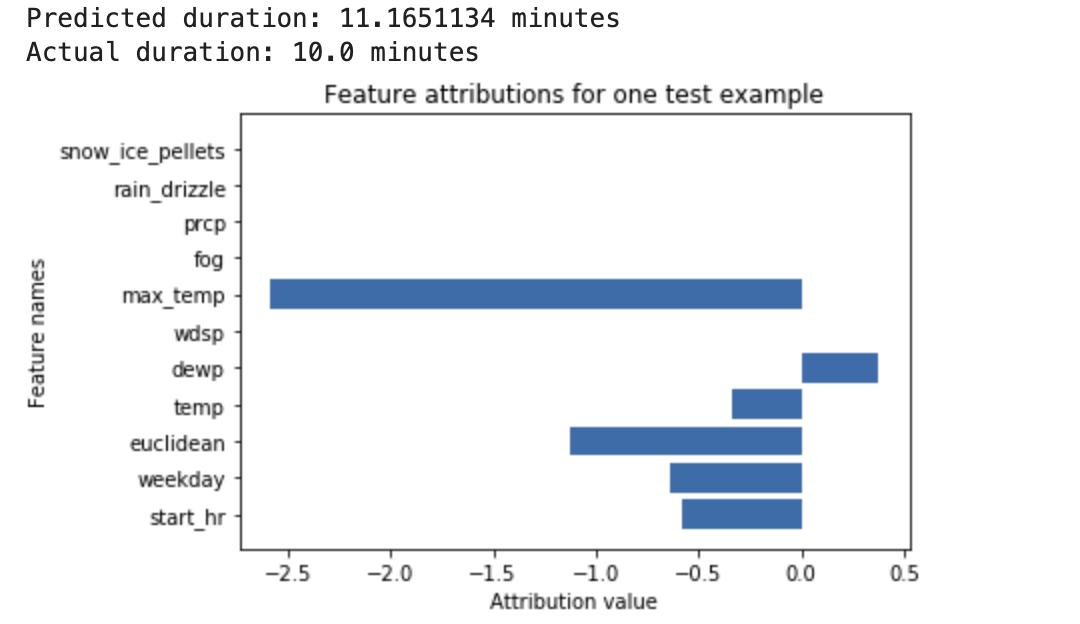
※Vertex Explainable AI の概要より画像引用
また、Model Registoryの機能では、MAE, MAPE, RMSEなどといったモデル精度を監視できます。
一方で、モニタリングのカスタマイズ性(例えば、ドリフト検出のアルゴリズムを変えるなど)は低く、現状では検出の閾値を変える程度しかできなさそうです。通知の機能も現状ではメール通知、Cloud Loggingのアラートだけのようで、単独ではSlackへの通知などは難しそうです。
しかし、Google Cloud Blogに以下のような記述があったため、今後はメール通知やCloud Loggingのアラート以外の通知やドリフト/スキュー検出をトリガーにモデルの再学習を自動でスタートさせることも可能になるかもしれません。
When skew is detected for a feature, an alert is sent via email. (More ways of receiving alerts will be added in the near future, including mechanisms to trigger a model retraining pipeline).
Amazon SageMaker
概要
Amazon SageMakerはAWSのサービスで、MLシステムの監視の機能として以下の2つを提供しています。AWSでMLシステムを運用している場合に、最も手軽に導入できる監視システムです。
監視できる項目例
- Input Metrics
欠損値、各値が範囲内か、データドリフト/スキューなど - Output Metrics
特徴量寄与率、予測の偏りなど
詳細
- SageMaker Model Monitor
コードを書くことなく、予測入力データの品質チェック、入力データおよびモデル出力の分析、ドリフト/スキューの検出が可能となっています。監視のタイミングはスケジュールでき、定期的に監視ジョブを走らせることができます。異常を検知すれば通知、モデルの再トレーニングやデータの監査などの修正アクションを実行できます。各データはAmazon SageMaker Studioで可視化できますし、そのほか、Tensorboard、Amazon QuickSight、Tableau などの他の可視化ツールも使うことができます。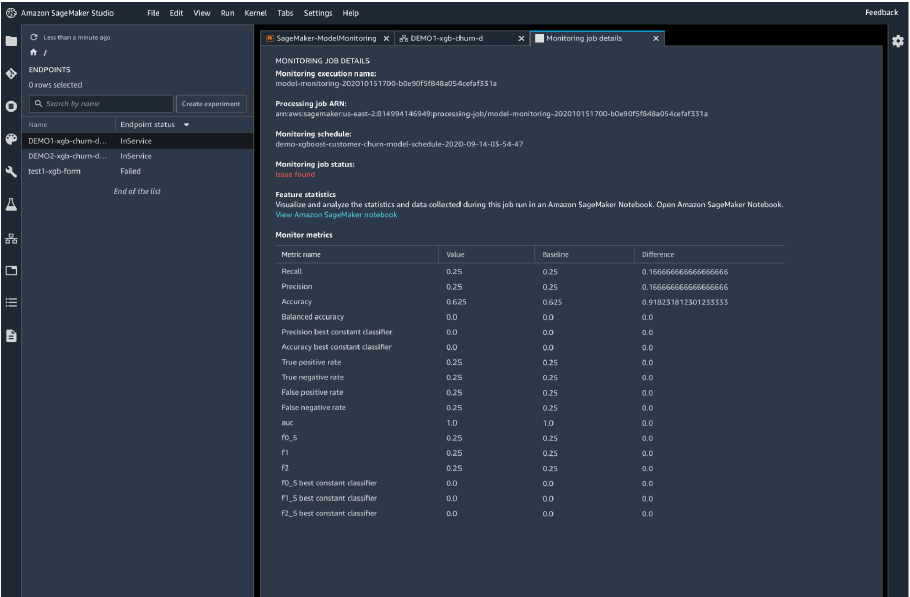 ※Amazon SageMaker Model Monitor より画像引用
※Amazon SageMaker Model Monitor より画像引用 - SageMaker Clarify
データのバイアス(特定の年齢層のデータが少ないなど)やモデルのバイアス(あるグループに対して他のグループよりも否定的な結果を出すことが多いなど)の特定・確認や特徴量寄与率のリアルタイムな監視などが可能となっています。こちらもAmazon SageMaker Studioと組み合わせることで各データを見やすい形でまとめることができます。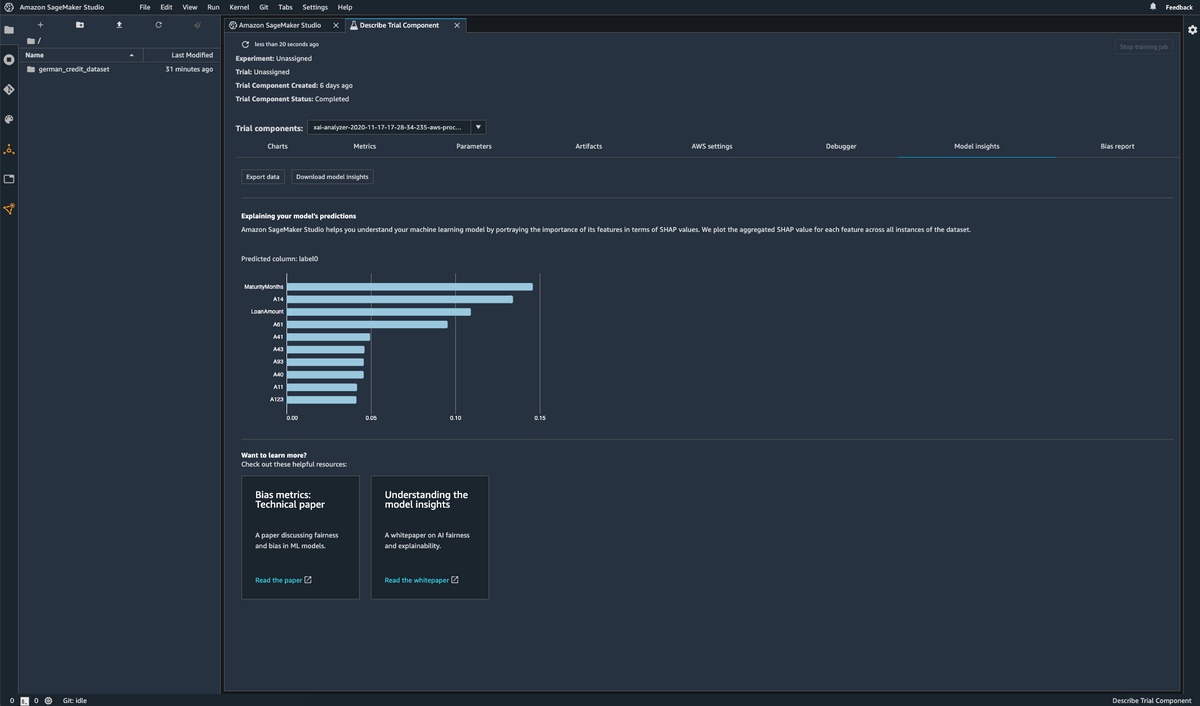 ※Amazon SageMaker Clarify より画像引用
※Amazon SageMaker Clarify より画像引用
参考
| ツール名 | リンク集 |
|---|---|
| Great Expectations | 公式サイト・Docs・GitHub |
| whylogs | 公式サイト・Docs・GitHub |
| Alibi Detect | Docs・GitHub |
| Monte Carlo | 公式サイト・Docs |
| Evidently AI | 公式サイト・Docs・GitHub |
| Citadel AI | 公式サイト |
| TensorFlow Data Validation | Docs・GitHub |
| Vertex AI Model Monitoring | Docs |
| Amazon SageMaker | 公式サイト |
各課題に対するおすすめツール
ここでは、いくつかの例を想定して、その場合におけるツールの組わせの例を紹介します。
まずクイックに監視を開始したい場合
GCPやAWSのクラウドサービスを用いてMLシステムを運用している場合には、まずは各クラウドサービスに用意されている監視サービス(Vertex AI Model MonitoringやAmazon SageMakerなど)を利用するのが簡単です。この場合にはGUIから利用を開始できるため、コーディングの必要もなく、素早く監視を開始できます。その上で足りない部分を他のツールで補っていく形が良いかと思います。
例えば、GCPでMLシステムを運用している場合にInput Metricsを監視したいとなれば、Great ExpectationsやMonte Carloなどを追加で使うことでInput Metricsについても監視できるようになります。
OSSのツールのみで監視を済ませたい場合には、Evidently AIが良いかと思います。Evidently AI単体で、Input Metrics、Output Metricsの監視が可能で、プリセットも用意されているため、監視を容易に開始できます。可視化やリアルタイム監視にも対応しているため、監視の結果も簡単に把握できます。
監視の設定を細かく指定・作り込みたい場合
Great Expectations、whylogs、Evidently AI、TensorFlow Data Validationなどが良いかと思います。
Input Metricsのみの監視で十分な場合には、Great Expectationsやwhylogsがおすすめです。どちらもテストが豊富に用意されており、また、独自のテストを作成することも可能なため、カスタマイズ性は高いかと思います。
Apache Beam等でパイプラインを組んでいる場合には、TensorFlow Data Validationが良いかと思います。TensorFlow Data Validationはパイプラインの中に組み込むことができるため、パイプラインの中間データの監視や監視結果に応じてパイプライン処理を分岐させるといった使い方が考えられます。
Evidently AIは上の「手っ取り早く監視を開始したい場合」でもおすすめしましたが、独自のテストやメトリクスの作成や、ドリフト検知の手法をカスタマイズすることなども可能なため、監視設定を細かく設定したい場合にも十分用いることができます。
おわりに
今回は、モデル・データ監視について、監視の必要性、監視項目、ツールの紹介をしました。
各ツールの使い方については説明できていませんが、Vertex AI Model MonitoringおよびEvidently AIは、Vertex AI Model MonitoringとEvidently AIで運用中のモデル・データを監視する【Input Metrics編】で解説されています。
ご参考になれば幸いです。