1. はじめに
こんにちは、フューチャーでアルバイトをしている板野です。
今回は、データ/モデル監視ツールであるVertex AI Model MonitoringとEvidently AIを利用し、両者を様々な観点で検証していきたいと思います。
Vertex AIのAutoMLで作成した回帰モデルの監視を想定し、ユースケースを交えて両者をそれぞれ検証していきます。オープンデータを用いてモデルを学習させ、それに対して監視設定をして運用を試してみたので、その一連の手順と検証結果を記載します。
データ/モデル監視の基本については、以前に投稿された記事:MLシステムにおけるモデル・データの監視(概要編)をご参照ください。
2. 監視の必要性
データ/モデルを監視するモチベーションとして、例えば以下のような事項が挙げられます。
- 刻々と変わる世界の中で、モデルが期待通りに動作し続けるようにしたい
- モデルが出す結果の精度の変化にいち早く気づきたい
- 定期的にモデルの更新が必要だと思うがそのタイミングが分からない
※モデルとは、機械学習システムにおいて、訓練データを用いて訓練したAIモデルのことを指します。
3. 今回想定するユースケース
上記の監視の必要性に対するソリューション例を示すため、具体的なユースケースを想定します。
今回は、天気や気温等の特徴からその日のシェアバイク利用数を予測する回帰モデルを構築することを想定します。
3.1. 監視の背景
シェアバイク屋さんは精度の高い利用数予測モデルを導入し、業務の効率化に役立てたいと考えています。
しかし、季節やトレンドの時季的な変化は必ず訪れるため、同じモデルを使い続けていると精度は低下していきます。また、機能や仕様の変更でデータの形式が変わり、モデルが役に立たなくなることもあります。
このようにモデルの精度を低下させる要因は様々あります。
そこで、モデルを監視することにより精度の低下を防ぐソリューションを考えます。
3.2. 監視項目
では、一体何を監視すれば良いのでしょうか。
監視の対象は様々ありますが、大きく以下の2つに分かれます。
- Output Metrics
- 出力データに関する監視
- 例)精度・特徴量寄与率・予測の偏り等
- Input Metrics
- 入力データに関する監視
- 例)データドリフト・外れ値・データ数の極端な低下等
精度の低下を直接監視するにはOutput Metricsを見れば良いのですが、モデルの予測結果を評価するための正解データが必要な場合があります。実運用では正解データが手に入るまでにはラグがあるので、Output Metricsではモデルの精度低下に気づくのが遅れる恐れがあります。
一方、Input Metricsはモデルに入力されるデータに異常や傾向の変化が無いかを確認し、間接的にモデルの精度低下を監視します。この場合、モデルの出力や正解データを待たずとも精度低下の予兆に気づくことができます。
今回はInput Metricsを監視するツールを検証し、AI運用にどのように役に立つのか検証していきます。
Output Metricsについては、本記事を読んだ上で、こちらの記事:[Vertex AI Model MonitoringとEvidently AIで運用中のモデル・データを監視する【Output Metrics編】(※2023.4.13公開予定)]をご覧ください。
補足:データドリフトとは?
データドリフトとは、主に「データの傾向が時間の経過とともに変化すること」を表します。訓練データと推論データの性質が違い、本番で良い精度が発揮できない場合や、最初は良い精度でもデータの性質変化により徐々に精度が下がっていく場合があります。
4. 事前準備: データ準備・モデル構築
監視ツールを比較検証するための事前準備として、Vertex AIのAutoMLを使用して回帰モデルを作成します。
※本章はAI監視とは関係ありません。既にVertex AIでモデルのエンドポイントを作成している場合はこの章を飛ばすことができます。
4.1. 使用するデータセット
データセットはBike Sharing Datasetを利用します。
このデータセットには2011年と2012年のシェアバイク利用データが入っており、以下のファイルが含まれています。
day.csv: 日ごとのシェアバイク利用者数が記録されている(全731行)hour.csv: 時間ごとのシェアバイク利用者数が記録されている(全17379行)
day.csvではデータ数が少ないので、hour.csvを使うことにします。
データの内容は以下のようになっています(最初の5行のみ表示)

主な説明変数として、気温(tmp), 湿度(hum), 風速(windspeed)等があります。目的変数はその時間のシェアバイク利用数(cnt)です。
今回は2011年分のデータのみで学習し、2012年のデータを入れたときの挙動を確かめます。
hour.csvには2011~2012年のデータがまとめて入っているので以下のように分割したcsvファイルを手作業で作成します。
- hour-2011.csv: 2011年の時間毎シェアバイク利用者数(全8645行)
- hour-2012.csv: 2012年の時間毎シェアバイク利用者数(全8734行)
更に、月毎に特徴量の分布も変わってくるため、推論に使う2012年のデータについては以下のように月毎に分けたデータも作成しておきました。
- hour-2012-01.csv: 2012年1月の時間毎シェアバイク利用者数(全741行)
- hour-2012-02.csv: 2012年2月の時間毎シェアバイク利用者数(全692行)
︙
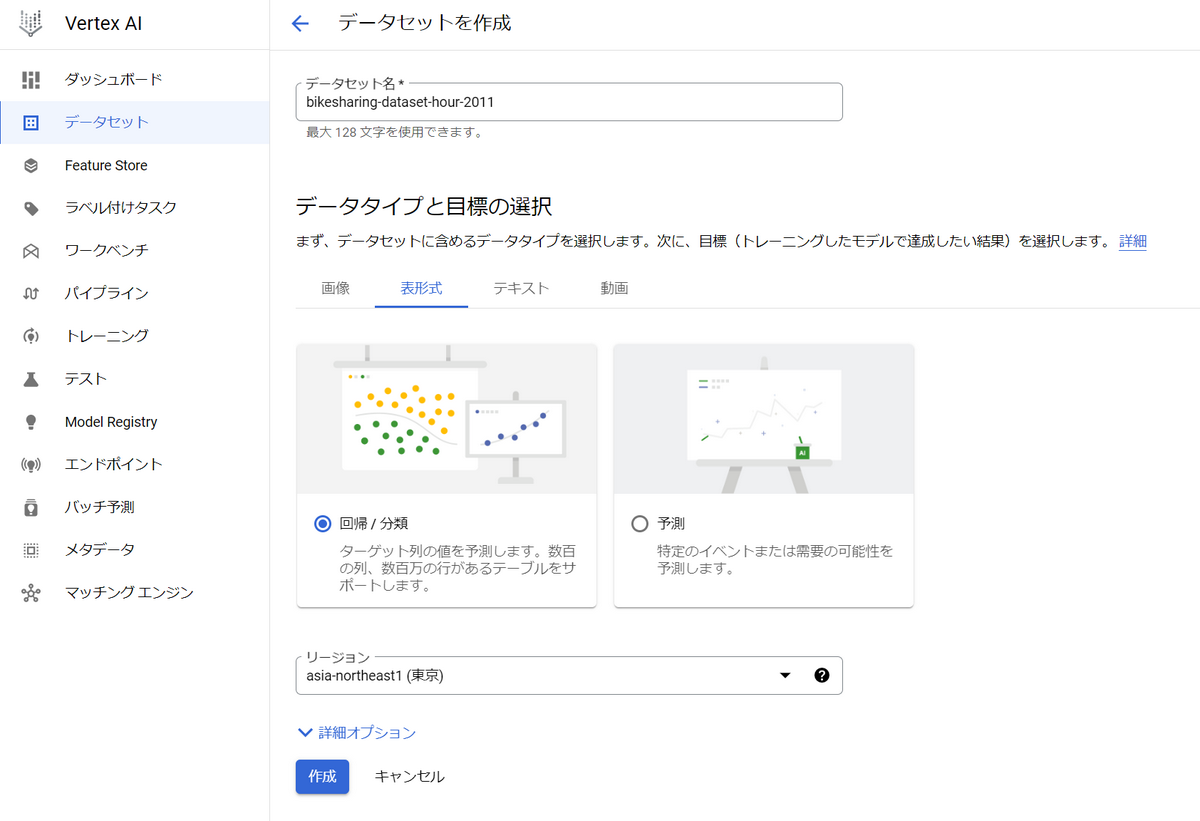
4.2. Vertex AIのデータセットを作成する
AutoMLで学習するためにはデータセットを作成する必要があります。
左メニューの「データセット」から作成できます。
次に、いずれかの方法でCSVファイルをアップロードします。
BigQueryのデータをそのままデータセットにすることもできます。
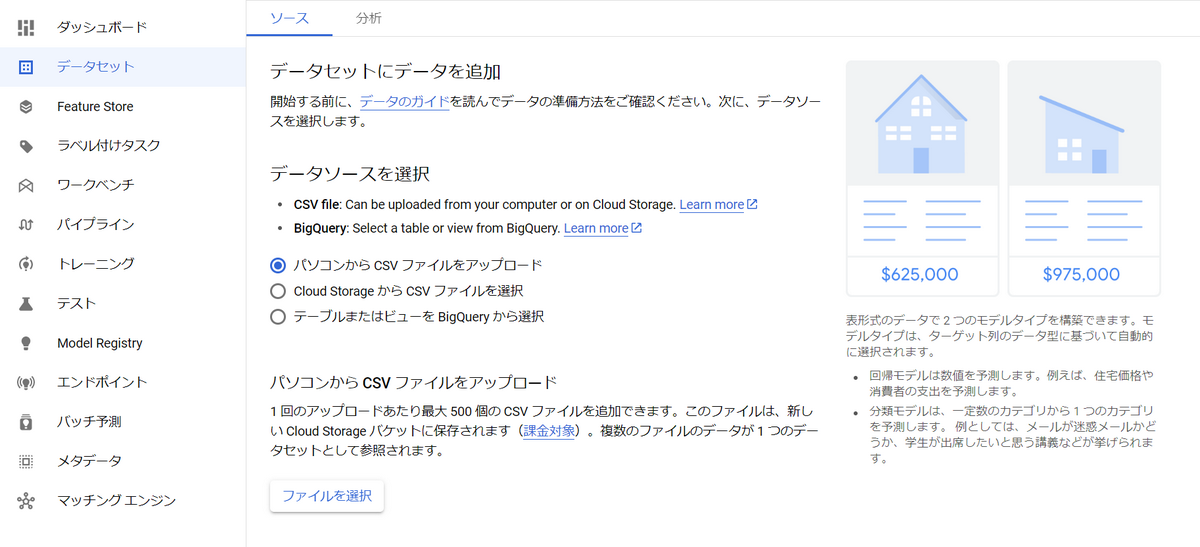
これでVertex AIのデータセット作成は完了です。
4.3. AutoMLでモデルの学習を行う
作成したデータセット(2011年の時間毎シェアバイク利用者数のデータ)で学習を行います。
左メニューの「トレーニング」からAutoMLでの学習設定ができます。
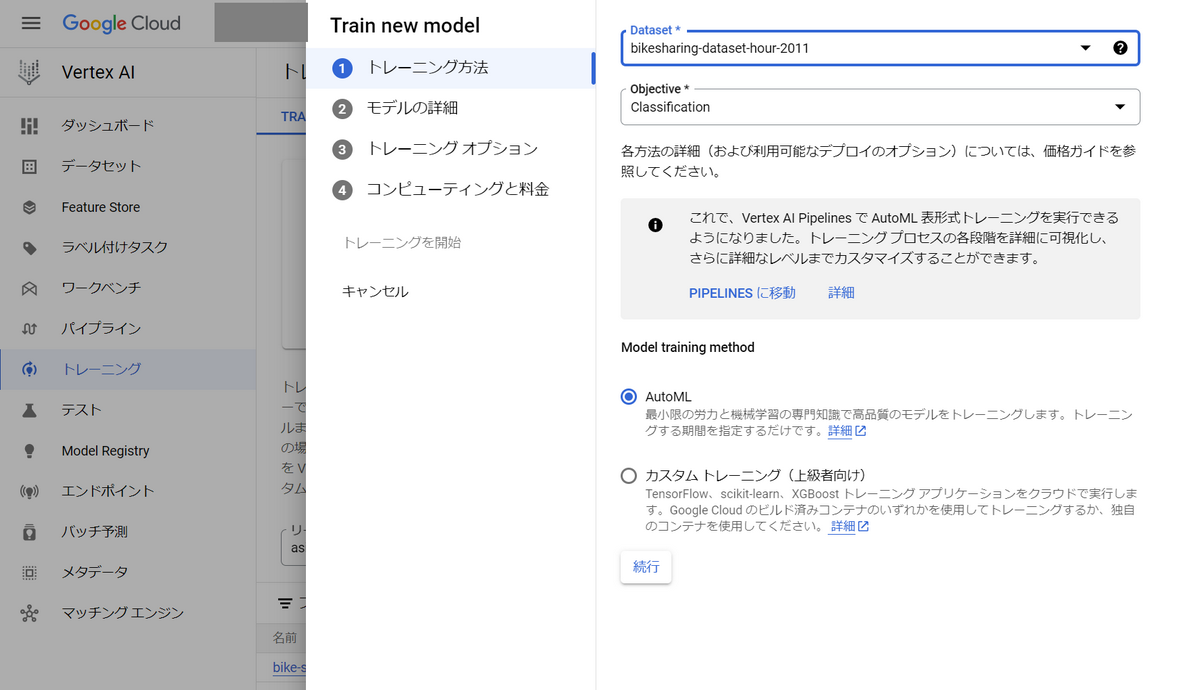
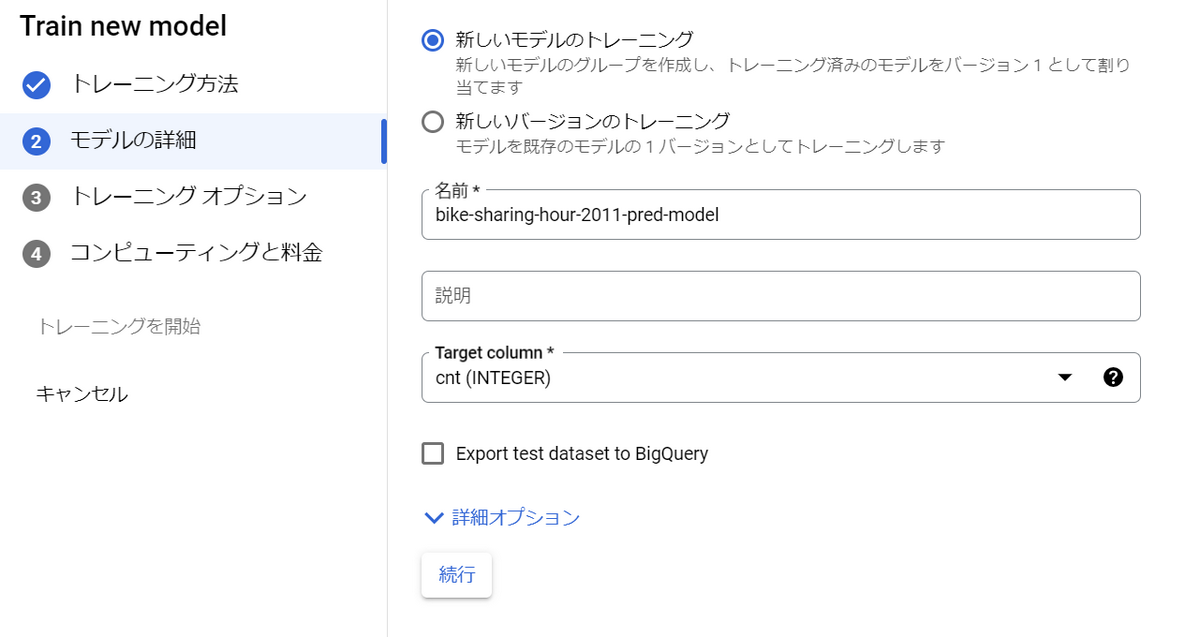
モデルの名前は適宜設定し、Target columnにはcnt(INTEGER)を選択します。
目的変数はシェアバイク利用数(cnt)だからです。
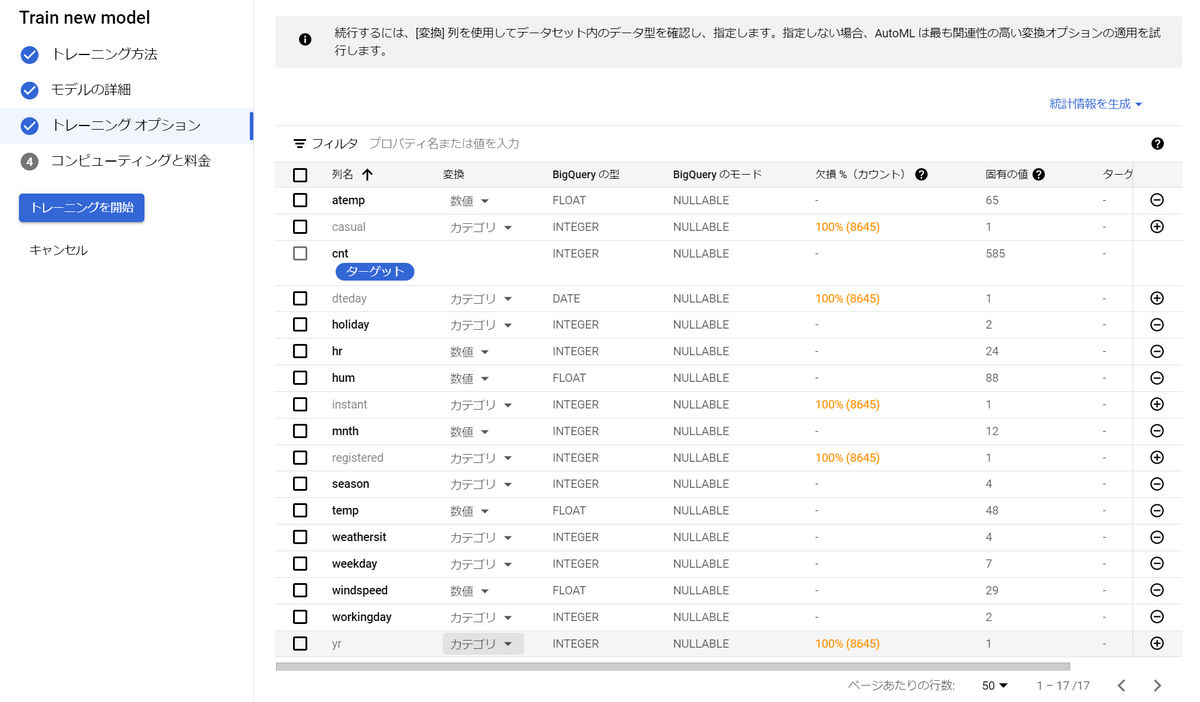
AutoMLでは学習に使う特徴量(説明変数)を選択するといった前処理のようなことができます。
今回入手したデータセットには必要のない特徴量もあるため、この画面で特徴量選択しておきます。
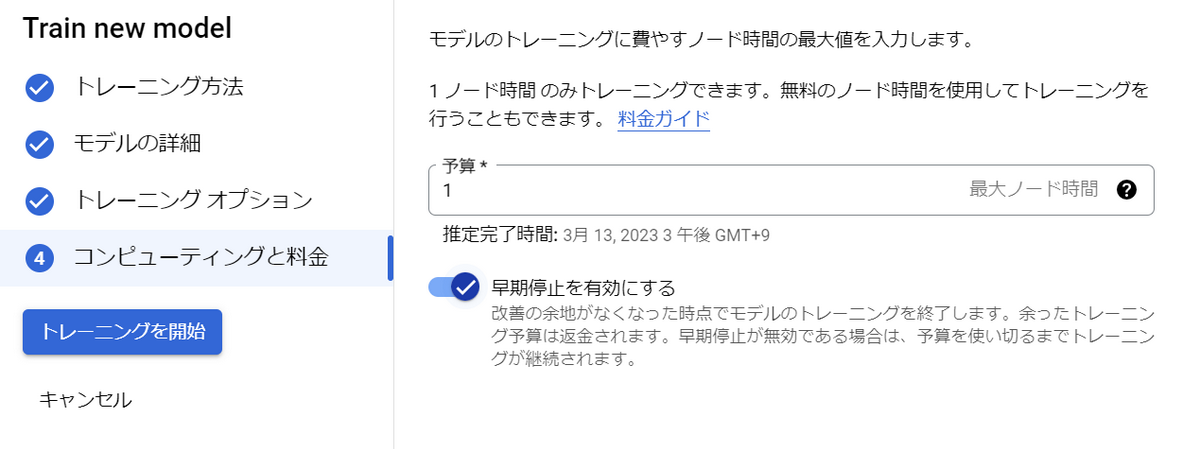
最後に、トレーニングに費やす予算を設定します。
Vertex AIではこの予算の単位には「トレーニング時間」というものが使われています。
1トレーニング時間当たり2000~3000円掛かります(参考)
約2時間程で学習が完了し、モデルが完成します。
4.4. エンドポイントの作成
モデルは完成しましたが、そのモデルを使って予測を行う窓口(エンドポイント)を作成する必要があります。
左メニューの「エンドポイント」よりエンドポイントを作成できます。
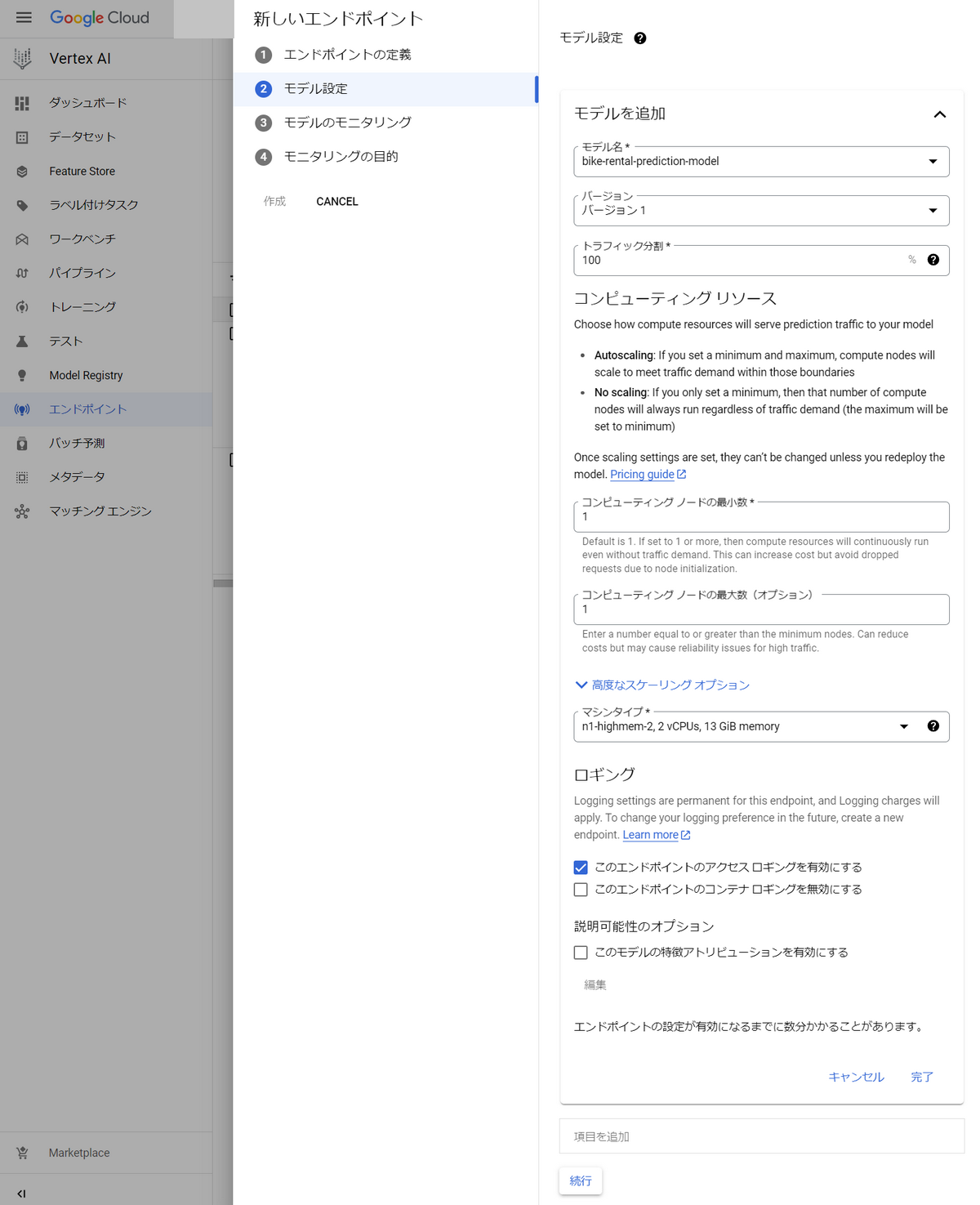
モデルの設定は以下の通りにします。
エンドポイントを設定すると、オンライン予測のリクエストを受け付けるので、マシンを常時起動し続けることになります(課金されます!!)。
従って、まずは最も低スペックのマシンタイプを選択することをお勧めします。
モデルのモニタリングは後で設定できるので、事前準備中の今は設定しません。
「作成」を押すと、10分程待てばエンドポイントが作成されます。
こちらのPythonソースコードを参考にし、試しにエンドポイントにリクエストを投げてみます。
※リクエストの投げ方については割愛

上画像のように予測結果が辞書型(REST API経由でリクエストしたらJSON型)で返ってきます。
※モデルを実運用している現場ではこのような予測リクエストを大量に投げることになります。
これで事前準備は完了です。
5. Vertex AI Model Monitoringでの監視
Vertex AI Model Monitoringは、AutoML等で訓練したモデルの監視をVertex AI内で完結できるサービスです。
コンソール画面から監視設定ができ、ノーコードで実現できることが特徴です。
Vertex AI自体にバージョンの概念はありませんが、2023/3/29時点の操作画面となります。
5.1. 監視できること
Vertex AIではInput Metricsとしてトレーニング / サービング スキューと予測ドリフトを検出できます。
Vertex AIでは二者を以下のように定義しています(公式サイト)
- トレーニング / サービング スキュー(スキュー)
- 訓練データと推論データ間で特徴の分布が異なること
- 訓練データの特徴の分布情報が必要
- 予測ドリフト(ドリフト)
- 推論データの特徴の分布が時間の経過とともに変化すること
- 訓練データの特徴の分布情報は不要
公式サイトによると、分布間の距離は以下のアルゴリズムにより計算されます。
カテゴリ特徴の場合、距離スコアはチェビシェフ距離を使用して計算されます。
数値特徴の場合、距離スコアはジェンセン・シャノン ダイバージェンスを使用して計算されます。
5.2. 監視設定と監視結果
5.2.1. スキューを監視する
トレーニング / サービングスキューを監視するために、エンドポイントの設定を変更します。
「このエンドポイントのモデルのモニタリングを有効にする」をオンにして設定していきます。以下は設定項目です。
- モニタリング間隔
- モニタリングを実行する時間間隔
- 短いほど計算リソースを使うため、あまりデータの変化に敏感にならなくて良い場合は長めに設定
- 今回は検証のため、かなり短めの1時間に設定
- モニタリング データ時間
- モニタリングを実行するタイミングからどの程度リクエストを遡るか
- 例えば1時間に設定すると、モニタリングを実行する1時間前からのリクエストデータを収集し、特徴量分布の計算等を行い、訓練データと比較してスキューがあるか調べる。
- 予測リクエストの履歴は自動でBigQueryに保存されているため、このような機能が実現できているようです。
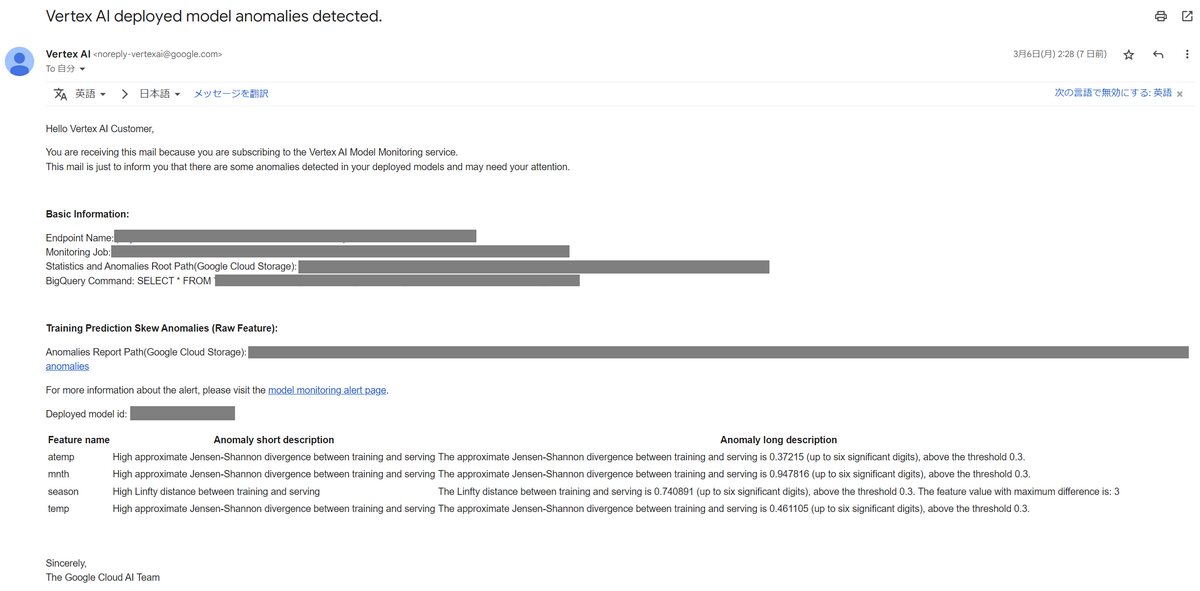
- 通知メール
- スキューを検出した際にアラートを出すメールアドレスを複数指定できる
- Slack等への通知はできない
- サンプリングレート
- 「モニタリング データ時間」の間に溜まった予測リクエスト履歴のうち何パーセントを特徴量分布の計算に利用するか
- 大量の予測リクエストが来る環境下では低めに設定
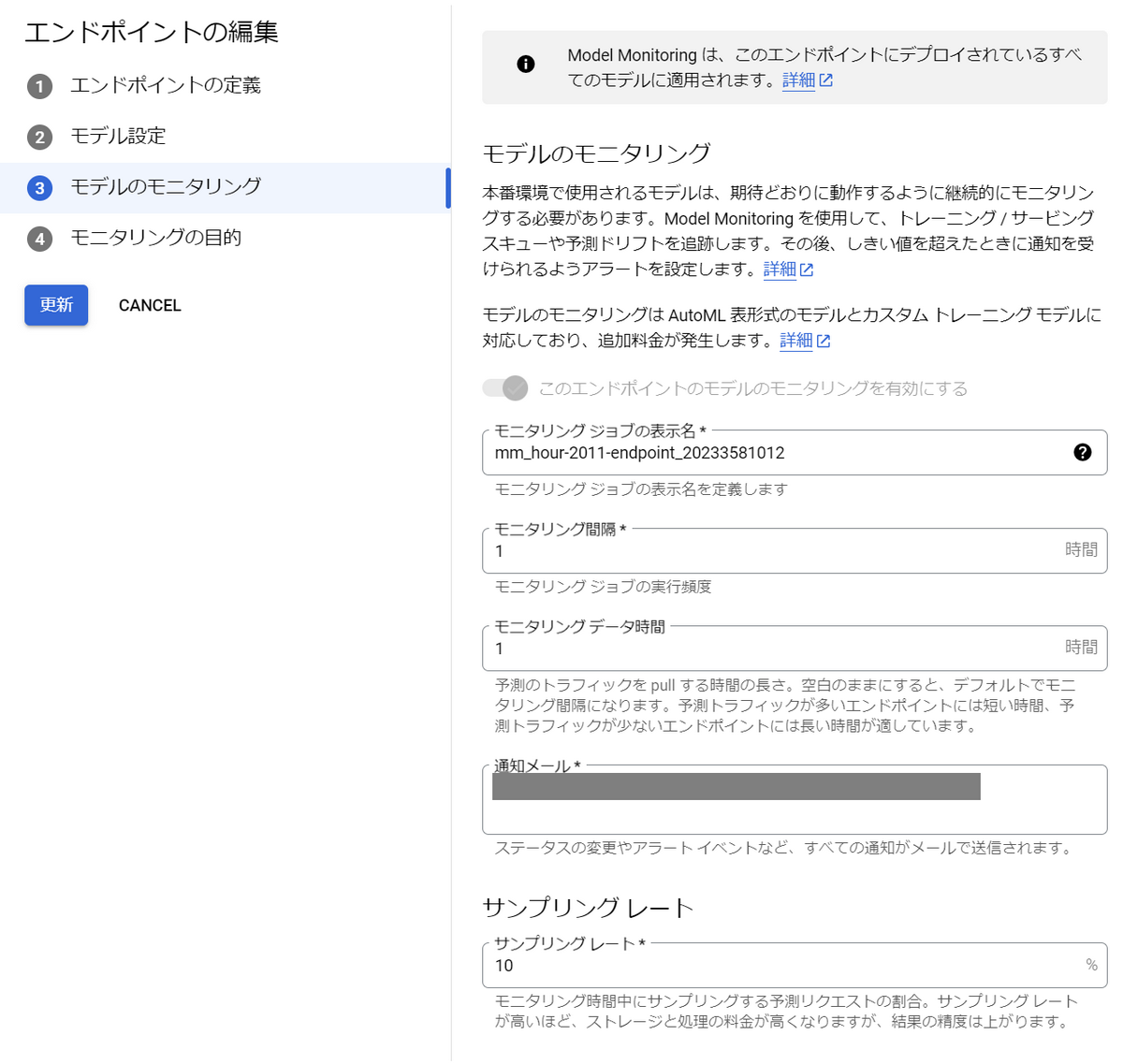
モニタリングの目的は「トレーニング サービングスキューの検出」を選択します。
トレーニング データソースにはモデルの訓練に使用したデータを選択します。
Cloud Strage上のCSVファイル、BigQueryテーブル、Vertex AIデータセットの中から選べます。
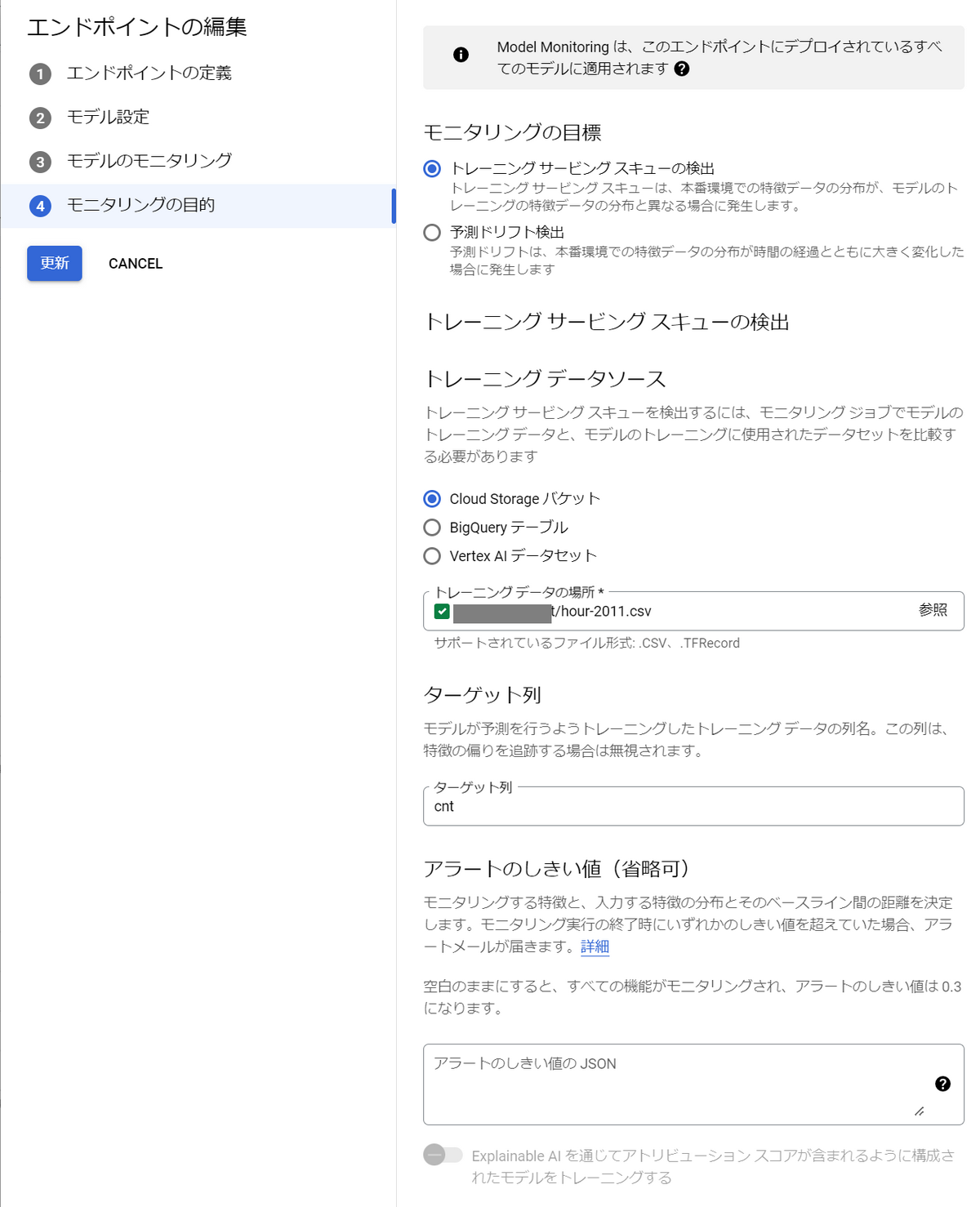
「更新」をクリックすると、モニタリングが有効になります。
試しに、1時間ごとに2012年のひと月分のデータを予測リクエストとして投げてみました。
すると、いくつかアラートが発生したようです。
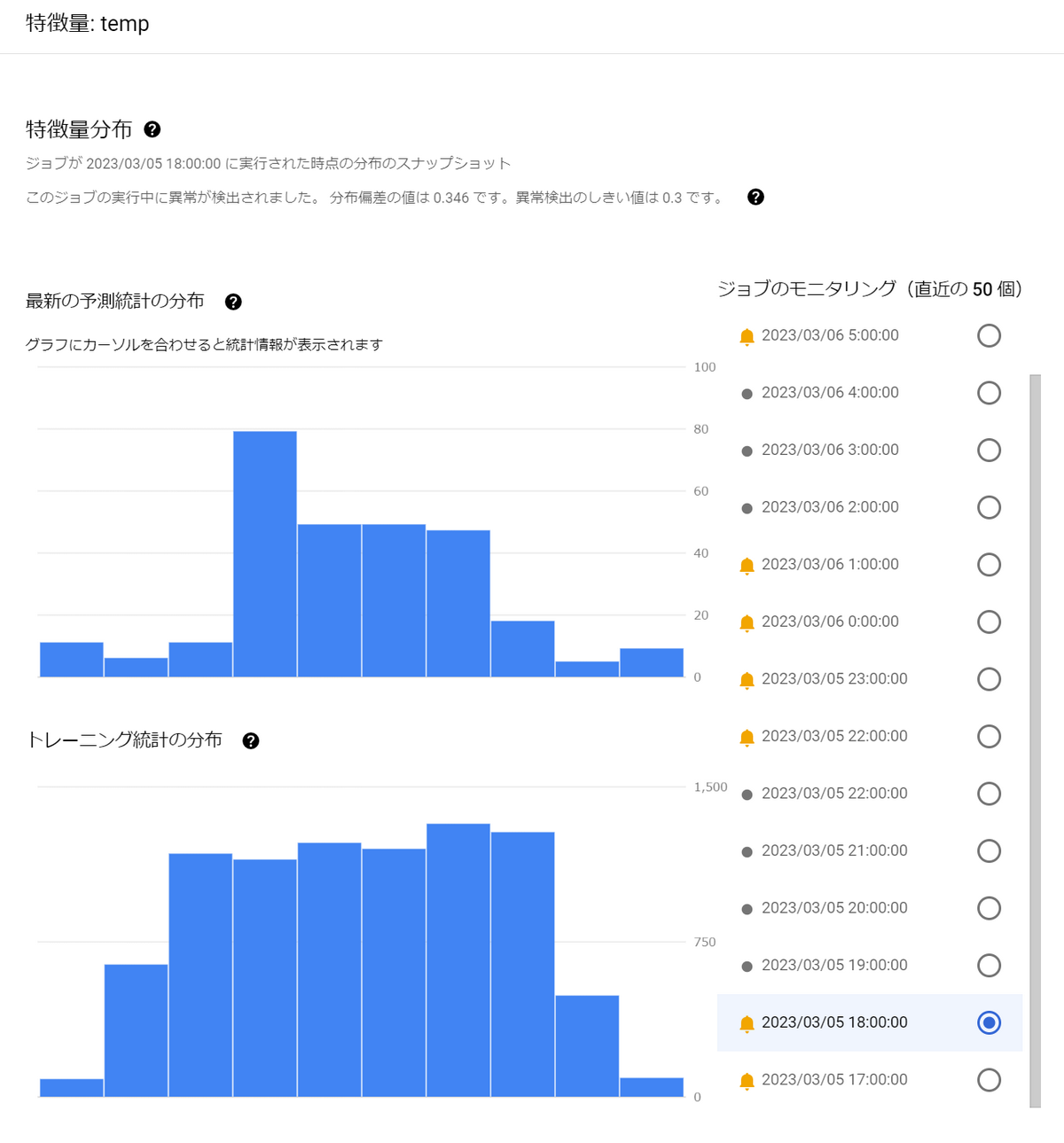
訓練データ分布との距離が大きく開いているため、アラートが発生しています。
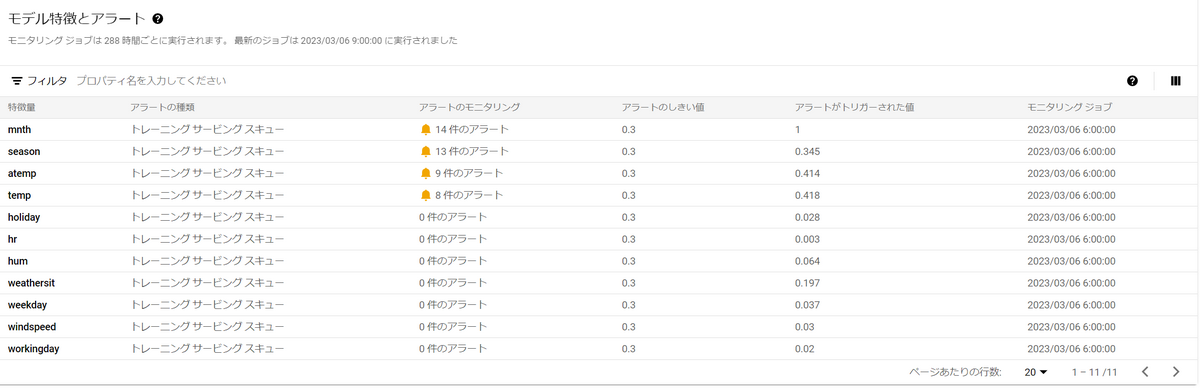
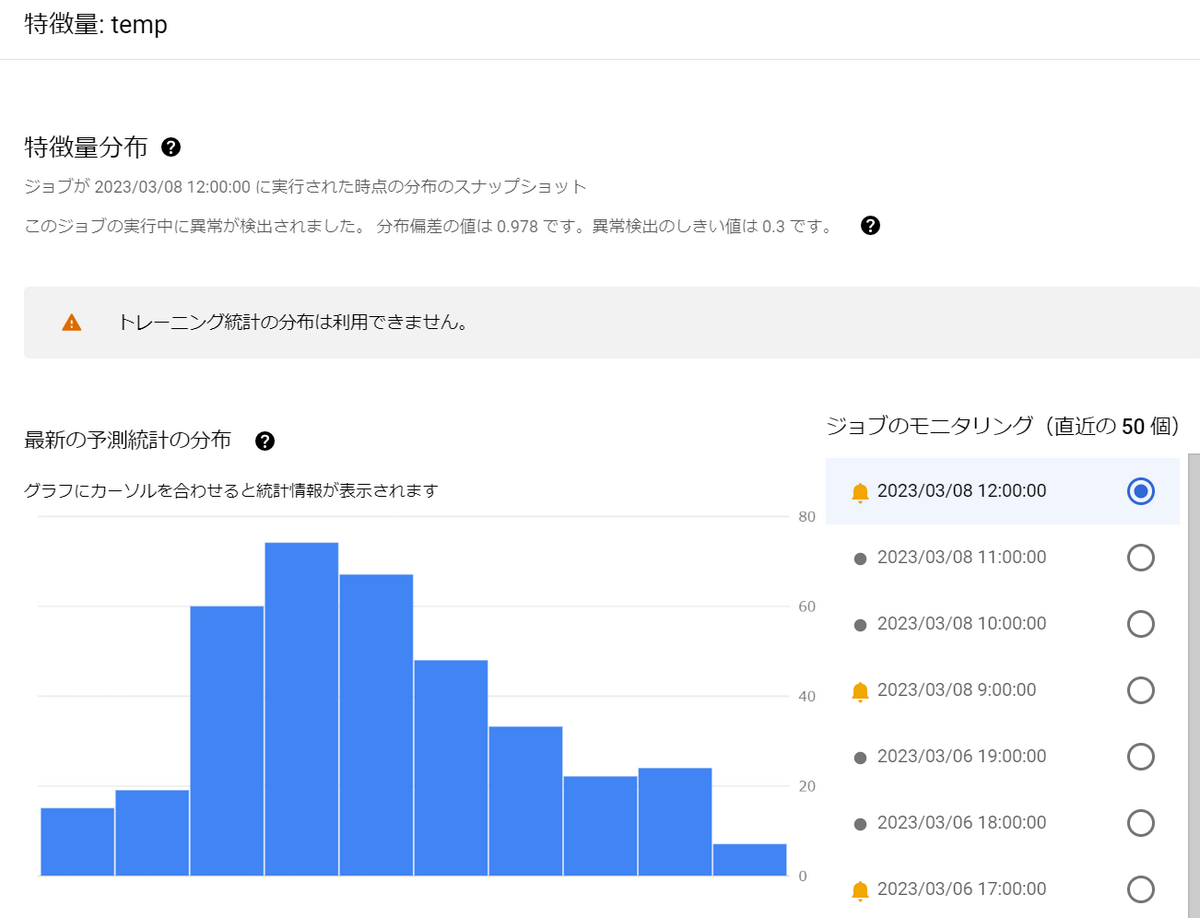
特徴量のうち、temp(気温)をクリックしてみると、分布を可視化できます。
以下は2011年の1~12月の気温の分布(訓練データ)と、2012年のとあるひと月の分布(推論データ)が違っていることを表しています。
※今回はこのようにスキューが起こるように意図的にデータの与え方を工夫しています。
アラートが発生すると以下のようなメールが届きます。
5.2.2. ドリフトを監視する
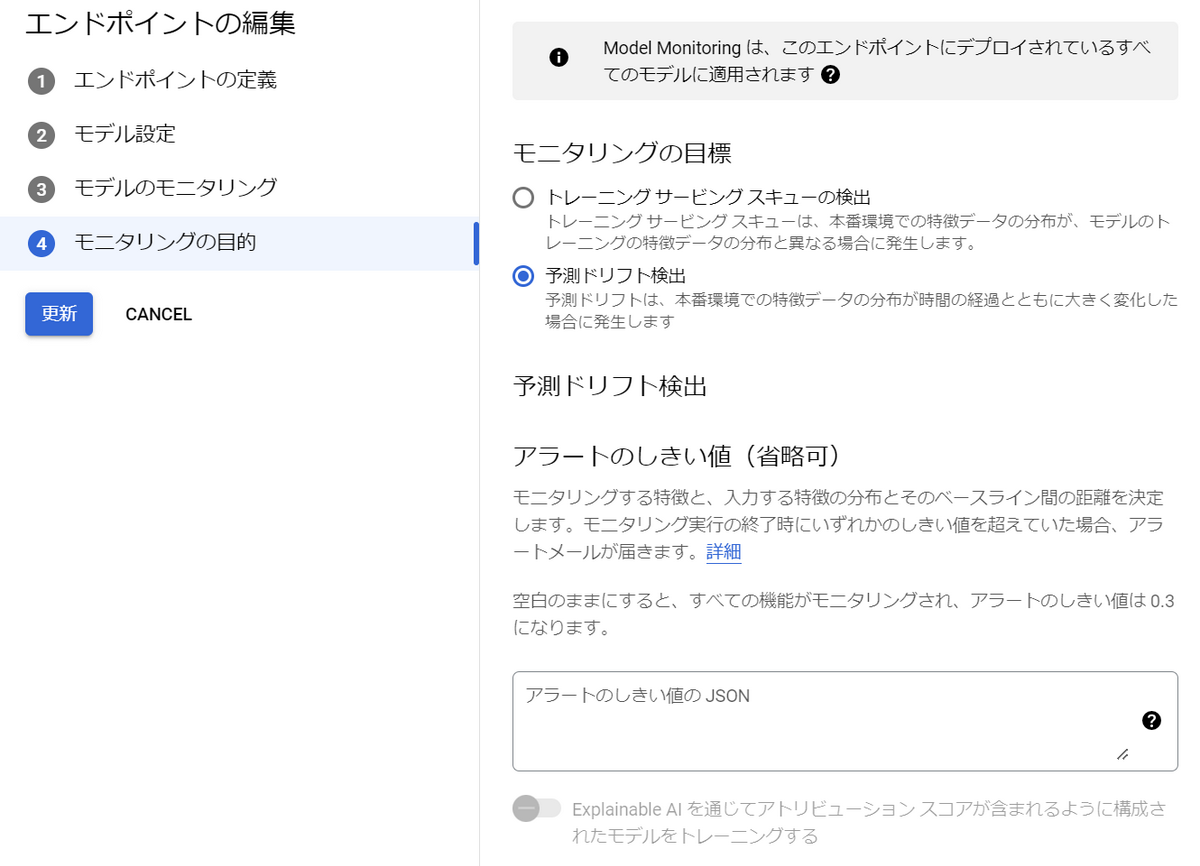
予測ドリフトを監視するために、エンドポイントの設定を変更します。
といっても、5.2. トレーニング / サービング スキューを監視するで行った設定とほぼ同じです。
モニタリングの目的で「予測ドリフト検出」を選択して「更新」ボタンを押すだけです。
※比較用の訓練データを指定する必要はありません。
先程と同様、1時間ごとに2012年のひと月分のデータを予測リクエストとして投げてみました。
すると以下画像のようにアラートが確認できます。
1時間前にリクエストされたデータの分布との距離が大きく開いているため、アラートが発生しています。
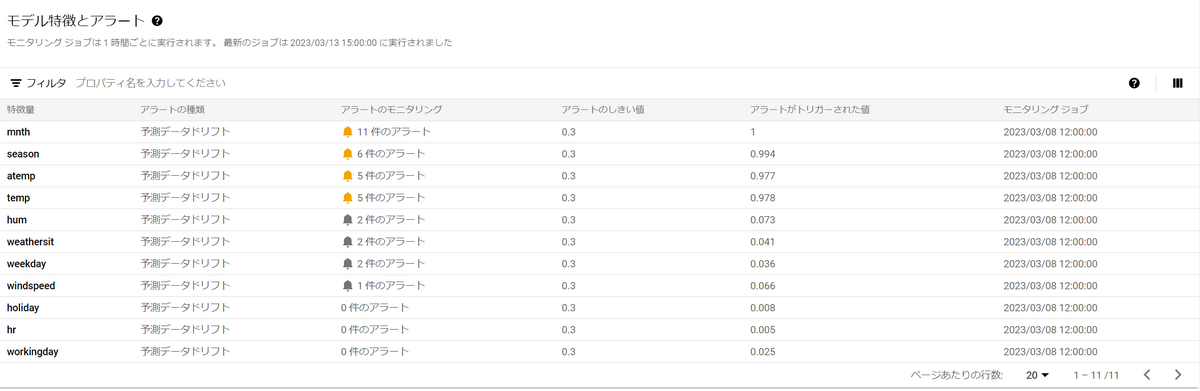
スキュー検出と同様に、特徴量のうちtemp(気温)をクリックすると、分布を可視化できます。
ただし、予測ドリフト検出の場合は比較対象は訓練データではなく、以前の推論データとなります。
このため、トレーニング統計の分布は表示されていません。
右側にモニタリングが実施された時間が表示されており、クリックすることで各時間の分布を表示できます。
5.3. コスト
監視設定はVertex AIのコンソール画面から設定できるので、実装コストはほぼ必要ないと言ってもいいでしょう。
また、モニタリングも自動で定期的に行ってくれるため、運用コストも必要ありません。
ただし、Vertex AI Model Monitoringを使用するには以下の金銭的コストが発生します(引用元)
大規模なデータを扱う時には金銭的コストに注意が必要です。
- Vertex AI Model Monitoring を使用すると、以下に対して課金されます。
- BigQuery テーブルに記録されたトレーニング データと予測データを含め、分析するすべてのデータに対して 1 GB あたり $3.50。
- アトリビューション モニタリングが有効にされている場合、BigQuery Monitoring や Batch Explain など、Model Monitoring で使用する他の Google Cloud プロダクトに対する課金。
6. Evidently AIでの監視
Evidently AIはオープンソースのPythonライブラリで、ML監視に関わるあらゆる機能を提供してくれます。
監視の結果はHTMLファイルやJSONファイルで確認できます。
Input Metricsだけでなく、Output Metricsの監視まで支援してくれる機能もありますが、
今回はInput Metricsに限定して紹介します。
Evidently AIのバージョンは0.2.6を使用しています。
6.1. 監視できること
Evidently AIでの監視はVertex AI Model Monitoringのようにノーコードで実現することはできませんが、
以下のような、より多くの項目を監視できます。
- ドリフト
- スキュー
- 欠損値
- 外れ値
- 値が正常な範囲内か
- 列の不足は無いか
- 列(特徴量)同士の相関
Evidently AIには大きく以下の2種類の機能があります。
両者とも監視項目としては似ていますが、その結果の扱い方に違いがあります。
- Report
- データの品質調査の結果を可視化できる
- データの傾向を分析したいときにデータ活用ができる
- 例)ドリフト検出にて特徴量分布を可視化して傾向を分析する
- Test
- データ品質の異常をテストできる
- 予め基準を定めておき、それを満たすか否か自動で判別したいときに活用
- 例)ドリフト検出にて自動で異常を検知してアラートを発する
6.2. 監視設定と監視結果
6.2.1. Evidently AIのインストール
まずはpipコマンドでEvidently AIをインストールします。
pip install evidently
また、Notebook上で使用する場合は次の2つのコマンドを打つとセル出力から直接結果を表示できるようになります。
※Notebookを使用しない場合はHTMLファイルを出力することになります。
jupyter nbextension install --sys-prefix --symlink --overwrite --py evidently |
6.2.2. データの準備
Evidently AIを使うのに大きな準備は必要ありません。
Input Metricsの監視では2つの異なるデータセット間の分布を調べるため、2つのデータを用意するだけです。
Evidently AIはPandasのDataFrame形式でデータを渡す必要があります。したがって、DataFrameで読み取れる形式のデータならどのようなデータソースでも大丈夫です。ただし、大規模データを扱う際は処理に時間やリソースを要する可能性があります。
CSVファイルならそのまま読み取るだけ、BigQueryならAPIを使ってDataFrameとして読み込むこともできます。
ここでは、2012年1月分と2月分の時間毎シェアバイク利用者数のデータを利用しました。
6.2.3. Reportを使う
公式のBasic Exampleを参考に、以下のコードを作成し、Notebook上で実行してみました。
import pandas as pd |
すると、以下のように各特徴量の分布が可視化されたものが出力されます。
一度に複数の特徴量分布の差を比較できる、分かりやすいレポートです。分布間の距離計算アルゴリズムは、データの数や種類に応じて適切なものを自動で選択しているようです(公式の解説)
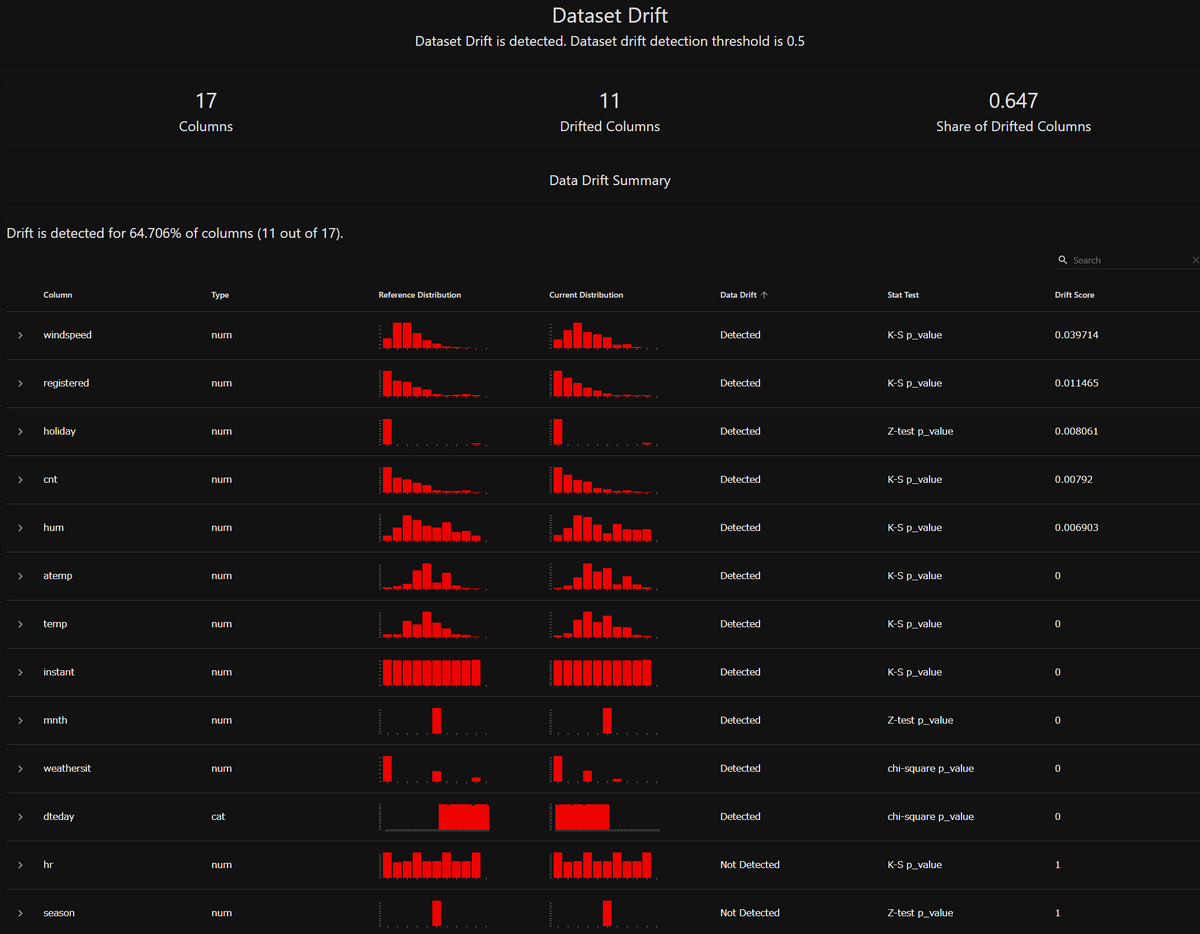
今回は、ソースコードの[★1]の部分にDataDriftPreset()を入れてレポートを出力しました。DataDriftPreset()は、データのドリフトを検出するためのプリセットであり、これをReportで出力しました。
Evidently AIではこのようなプリセットが複数用意されてあります。
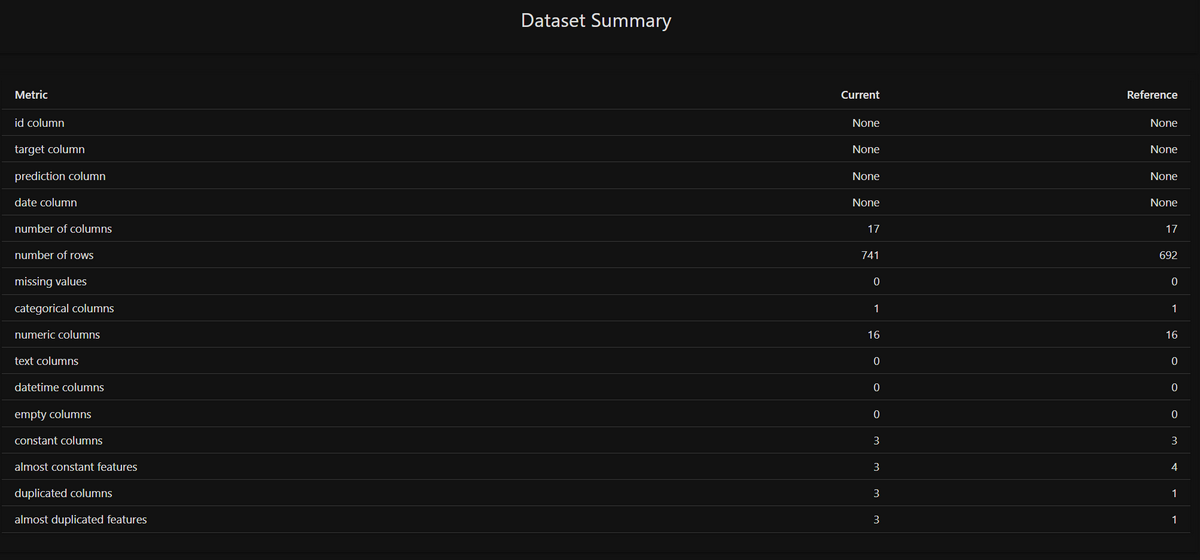
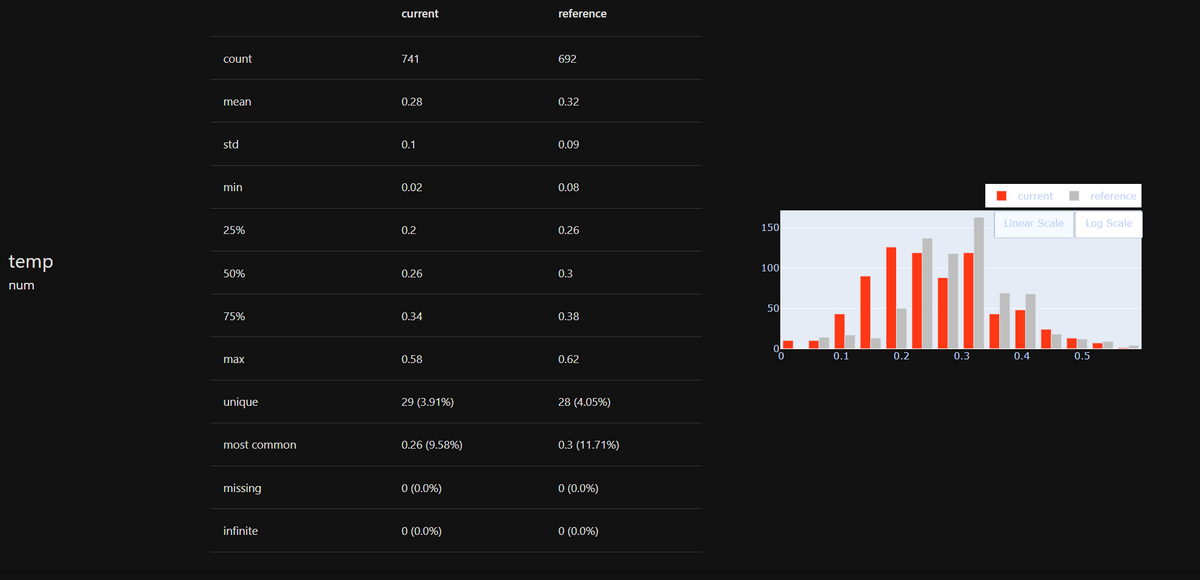
試しに、DataDriftPreset()をDataQualityPreset()に書き換えてみると、次のようなレポートが得られます。
データの統計的情報が可視化されていることが分かります。
他に用意されているプリセットなど、詳しくは公式ドキュメントをご覧ください。
6.2.4. Testを使う
6.2.3. Reportを使ってみると似ていますが、以下のコードを作成し、実行してみました。
import pandas as pd |
すると、以下のようなテスト結果が返ってきます。
今回は53個のテスト項目があり、そのうち42件が合格、11件が不合格だったようです。
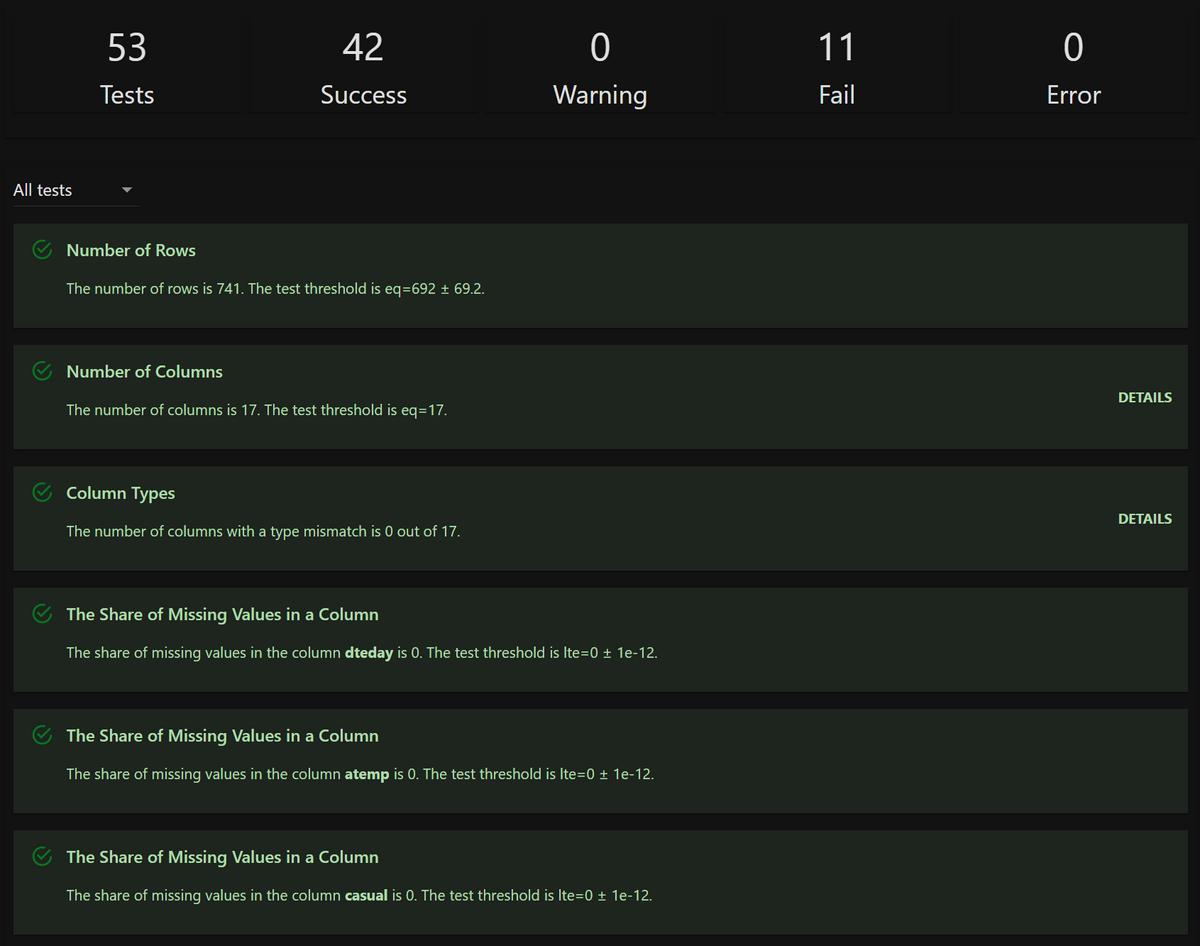
Share of Out-of-Range Values(範囲外の値が含まれる割合が一定値を超えていた)という理由で不合格でした。
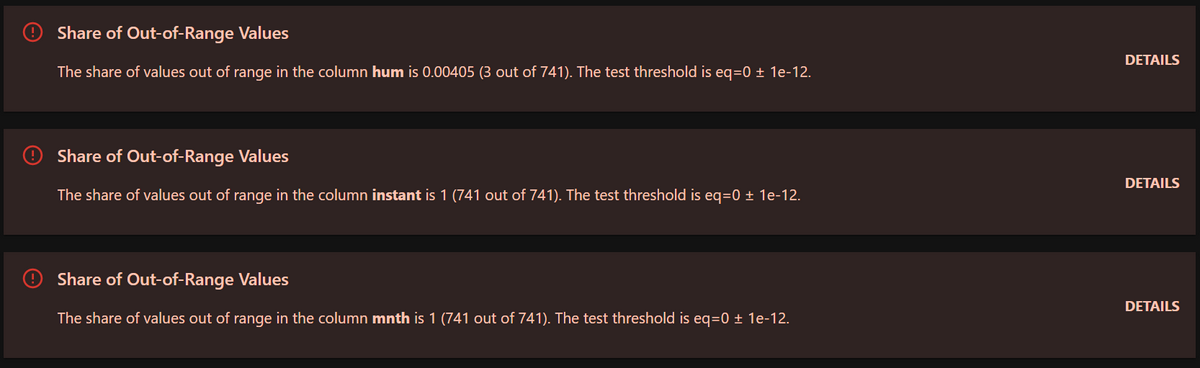
今回は[★2]でDataStabilityTestPreset()を指定しただけで、「完全お任せでテストして!」と言っているようなものなのでいくつか不合格が出てきました。もちろん、使用状況に合わせて合格と不合格の閾値などはカスタマイズできます。
また、今回はHTMLファイル(or Notebookのセル出力)でTestの結果を表示しましたが、結果をJSONファイルとして出力することもできます。
JSONファイルはソースコードで処理しやすいのでアラート通知の仕方や通知先は自由自在です。
詳しくは公式ドキュメントをご覧ください。
6.3. コスト
Evidently AIは、クラウドやオンプレミスの環境での自己運用型Pythonライブラリで、OSSとして提供されます。
このため、ソフトウェアを利用するライセンス料は発生しません。Evidently AIにかかる金銭的コストは、定期的にモニタリングジョブを動かすマシンの料金です。
Evidently AIは、Vertex AI Model Monitoringのようにノーコードで実現することはできません。簡素ではありますが、Pythonコードを書く実装コスト、及び定期的にモニタリングを実行する仕組み(運用コスト)が必要です。
7. まとめ
本記事では、Vertex AIのAutoMLで学習したモデルを監視することを前提に、
AI監視ツールである、Vertex AI Model Monitoring及びEvidently AIを具体的に利用し、その使用感を検証しました。
以下に両者の特徴をまとめました。
| 比較ポイント | Vertex AI Model Monitoring | Evidently AI |
|---|---|---|
| 監視項目の範囲 | スキュー/ドリフトのみ | スキュー/ドリフトに加え、データ品質まで |
| 実装コスト | ノーコードで実現可能 | Pythonコードを書く |
| 運用コスト | 設定するだけでほぼ掛からない | モニタリングを定期的に実行する仕組みの構築が必要 |
| 金銭的コスト | 1 GB のデータあたり $3.50の課金 | モニタリングジョブを動かすマシンの料金 |
| アラートの拡張性 | メール通知のみ | JSON形式を読み取って通知をカスタマイズ |
| 大規模データの注意点 | 金銭的コストの増加 | 処理の遅れ・マシンのリソース不足 |
両者とも機械学習モデルのパフォーマンスを監視するためのプラットフォームですが、Vertex AI Model MonitoringはGoogle Cloud上で提供されるマネージドサービスの一部であり、Googleが提供する機械学習インフラストラクチャの一部です。
一方、Evidently AIは、クラウドやオンプレミスの環境で自己運用型のOSSとして提供されます。
Vertex AI Model Monitoringは、ドリフト/スキューを監視できますが、Evidently AIは、ドリフト/スキューだけでなく、入力データの品質等、より広範な指標を監視できます。
Vertex AI Model Monitoringよりも幅広い項目を監視したいと思う場合、Evidently AIを検討することをおすすめします。