1. はじめに
こんにちは、フューチャーでアルバイトをしている板野です。
データ/モデル監視ツールであるVertex AI Model MonitoringとEvidently AIを利用して両者を様々な観点で検証していきます。
本記事は、前回の記事:Vertex AI Model MonitoringとEvidently AIで運用中のモデル・データを監視する【Input Metrics編】の続きです。
データ/モデルの監視項目については主にInput MetricsとOutput Metricsがあることを前回の記事でお伝えし、Input Metricsの監視について検証しました。
今回は、Vertex AIとEvidently AIのそれぞれにおけるOutput Metricsの監視について検証します。
※データ/モデル監視の基本については、以前に投稿された記事:MLシステムにおけるモデル・データの監視【概要編】をご参照ください。
2. Output Metricsの監視項目
Output Metricsを監視するにはモデルからの出力が必要となります。
主に以下の項目を監視します。
- (1)モデル精度
- モデルの性能をダイレクトに把握できる指標
- 回帰モデル:決定係数(R^2), 二乗平均平方根誤差(RMSE), 平均絶対誤差(MAE), 等
- 分類モデル:正解率(Accuracy), 適合率(Precision), ROC, AUC, 等
- モデルの性能をダイレクトに把握できる指標
- (2)特徴量寄与率
- 各特徴量がどの程度モデルの予測結果に対してどの程度影響を与えているかを示す指標
- 各説明変数-目的変数間の相関係数, Shapley値, 等
- 特徴量寄与率が変化した場合、モデルの精度に影響を与えることがあるため、監視する
- AIモデルの説明性が必要となるケースも多々ある
- 例)なぜこの薬が処方されたか? 等
- 「説明性の保証」のため、特徴量寄与率が変化していないか監視する
- 各特徴量がどの程度モデルの予測結果に対してどの程度影響を与えているかを示す指標
- (3)予測結果の偏り
- 予測結果の偏りが大きくなってしまうこと
- 例)予測結果の分布が時間とともに大きく変化した等
- 予測結果の偏りが大きくなってしまうこと
「モデル精度」については正解データが必要なため、ユースケースによっては指標が出るまでに遅れがあります。
例えば、人力で正解ラベルを付与しなければならない場合はその分待たなくてはなりません。
3. 前提条件
前回の記事の今回想定するユースケースの部分と合わせてあるので、詳細は割愛しますが、以下の前提条件で検証を行います。
- 天気や気温等の特徴からその日のシェアバイク利用数を予測する回帰モデルを構築している
- Vertex AIのAutoML(表形式)で訓練している
4. Vertex AIでOutput Metricsを監視
Vertex AI自体にバージョンの概念はありませんが、2023/3/29時点の操作画面となります。
4.1. 監視できる項目
Vertex AIでは、以下のような指標を監視できます。
- (1)モデル精度
- MAE:平均絶対値誤差
- MAPE:平均絶対パーセント誤差
- RMSE:二乗平均平方根誤差
- RMSLE:対数平均平方二乗誤差
- R^2:決定係数(説明変数が目的変数をどれくらい説明できるかを示す値)
- (2)特徴量寄与率
- Shapleyのサンプリング近似値(詳細)
4.2. 監視設定と監視結果
4.2.1. 必要なもの
- [★1] 説明変数列(特徴量データの列), 目的変数列(正解データの列)を含むデータ
- Google Cloud Strage上のCSVファイル or BigQuery上のデータ であること
4.2.2. 手順
Moder Registryから作成したモデル・バージョンの詳細画面に行き、「評価を作成」をクリックします。
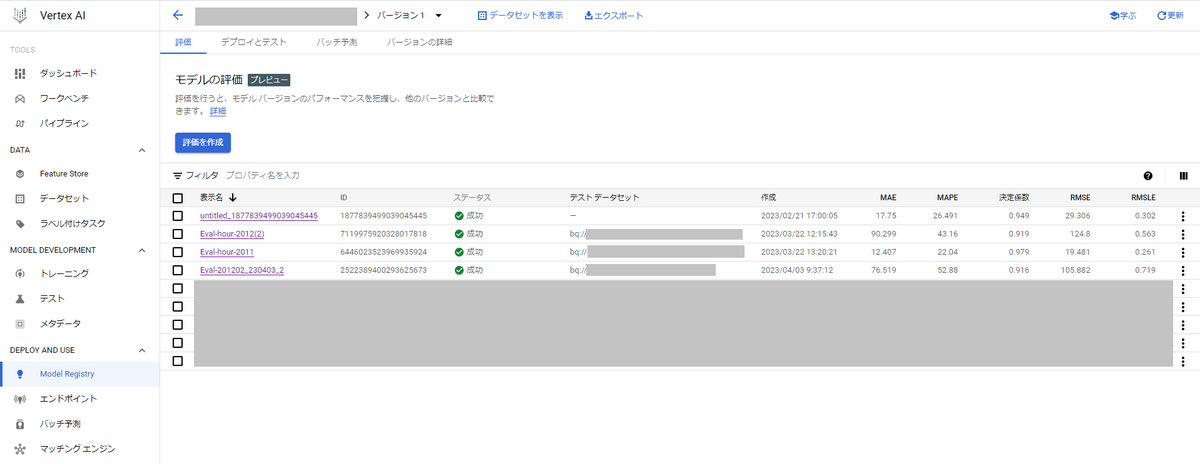
設定項目がいくつか出てくるので、ターゲット列、ソース([★1])、バッチ予測の出力先を指定します。
説明可能性のオプションで、「モデル特徴量の重要度を有効にする」にチェックを入れたら「(2)特徴量寄与率」も監視できます。
今回は、以下の画像のように設定します。
評価を開始すると、内部でバッチ予測ジョブが自動的に開始され、約20分ほどで評価が完了します。
評価や特徴量寄与率計算のための予測(推論)はここで動いています。
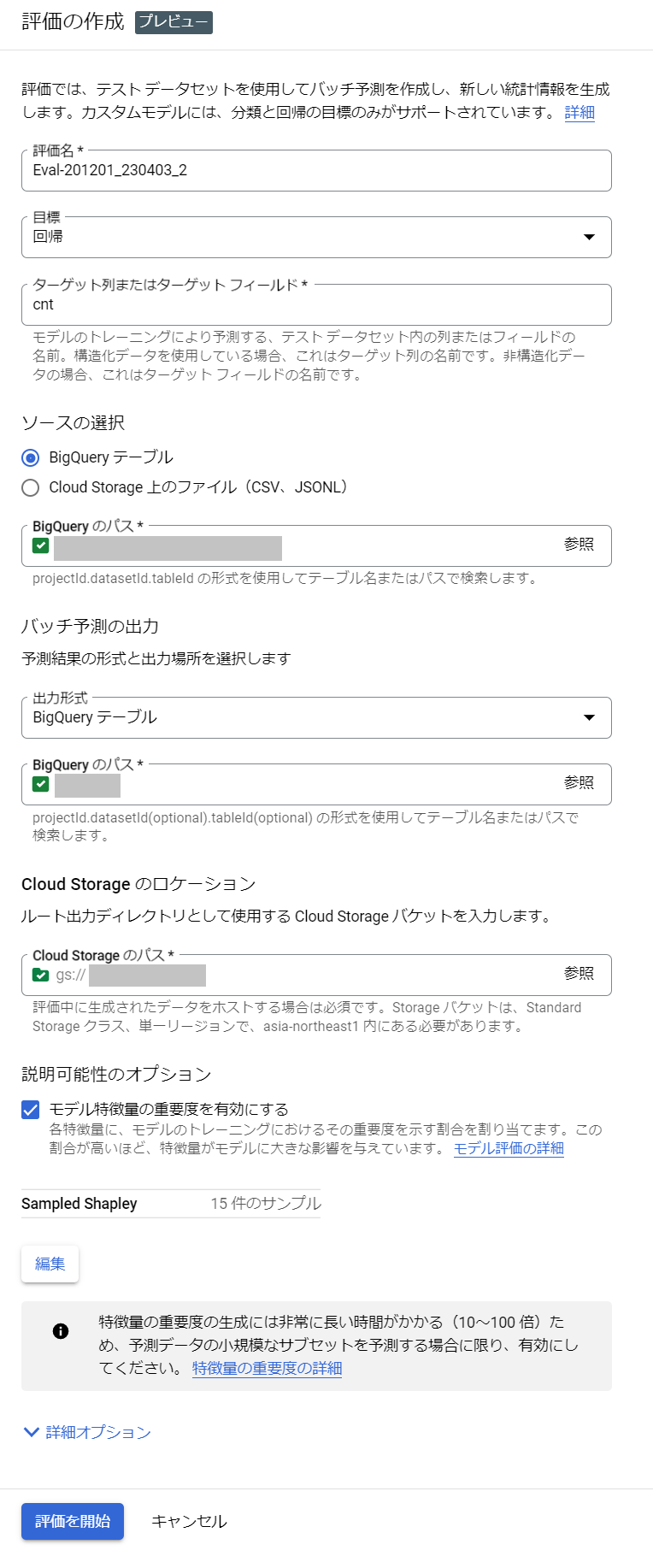
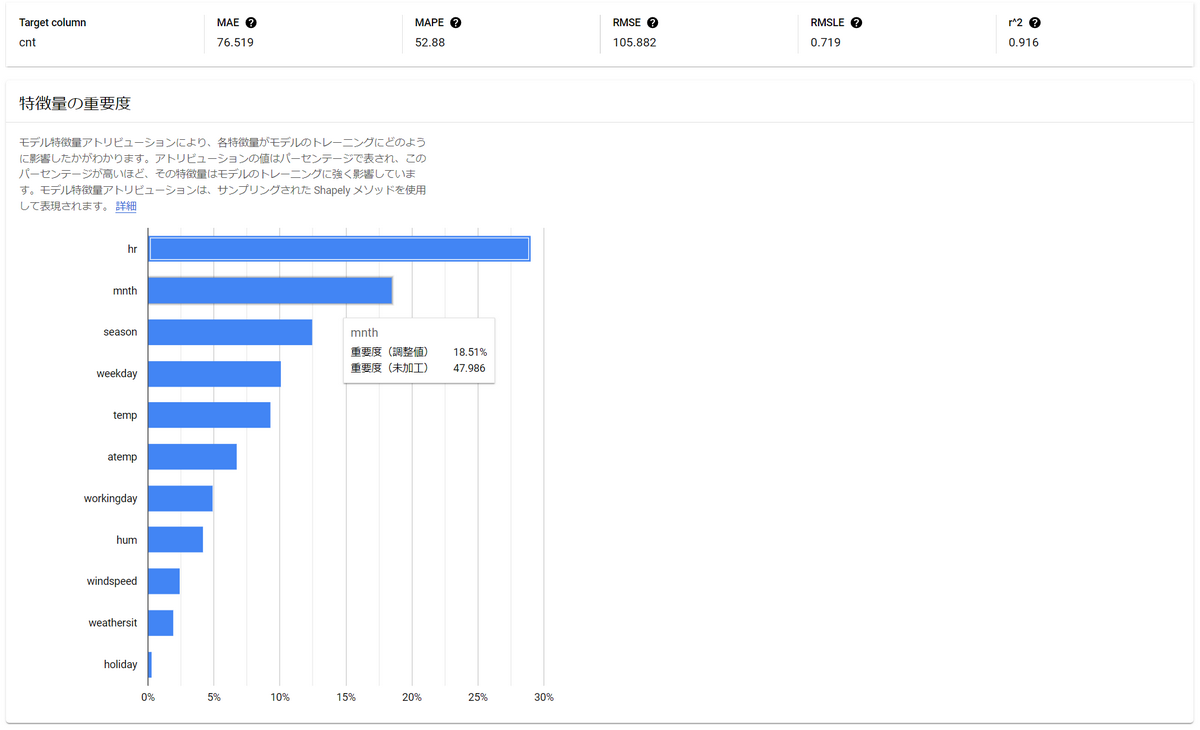
4.2.3. 監視結果
評価の結果は以下のように見ることができます。特徴量の重要度もヒストグラムで確認できます。
4.2.4. 自動化とアラート
今回の記事には含まれていませんが、以上の手順を自動化する場合、Vertex AI APIを利用して自動で定期実行できると考えられます。
Vertex AI自体に、評価結果が悪くなった際のアラート発生機能はありませんが、REST APIの結果を受け取り、前回の評価結果と比較するシステムを構築すればアラートを発生させることも可能と考えられます。
4.3. コスト
- 実装コスト
- 評価を行うこと自体はVertex AIのコンソール画面から設定できるのでほぼ実装コストは掛かりません
- 自動化する場合は、Vertex AI APIを使って処理を実装する必要があります
- 金銭的コスト
- 評価ジョブ自体にどのくらいのノード時間を費やしているか不明ですが、少なくとも評価ジョブに含まれるバッチ予測ジョブにはこちらに示されている費用が掛かると考えられます
- Vertex AI APIを動かすサーバ・関数等のコストが掛かります
5. Evidently AIでOutput Metricsを監視
Evidently AIのバージョンは0.2.6を使用しています。
5.1. 監視できる項目
Evidently AIでは、以下のような指標を監視できます。
- (1)モデル精度
- ME:平均誤差
- MAE:平均絶対値誤差
- MAPE:平均絶対パーセント誤差
- (2)特徴量寄与率
- 各説明変数-目的変数間の相関係数
- (3)予測結果の偏り
- 過去の予測結果と現在の予測結果の分布の違い
また、Evidently AIでは視覚的にモデルの精度変化を把握できるようなグラフも出力できます。
5.2. 監視設定と監視結果
5.2.1 必要なもの
- [★2] 説明変数列(特徴量データの列), 正解データ列(
target), 予測結果データ列(prediction) を含むデータ- DataFrame型として読み取れる形式
- 予測結果データ列はVertex AIで手動でバッチ予測を行い、その結果を新たに
prediction列として追加する - すなわち、予測(推論)処理はこのデータを用意する段階で行う
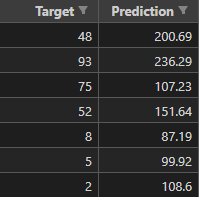
※[★2]について「(2)特徴量寄与率」を算出しなくて良い場合は、以下のように、target列とprediction列があればよい
5.2.2. 手順
Evidently AIのライブラリが入っている環境下で以下のコードを実行する。
備考:
- 過去・現在の2つのデータで評価して結果をを比較したい場合は[★3]と[★4]ように別のCSVファイルを指定する
- 現在の1つのデータのみで評価したい場合は[★5]のメソッドで
reference_data = Noneとする
import pandas as pd |
5.2.3. 監視結果
「(1)モデル精度」として、以下のようにMAE等の基本的な数値指標を出力できます。
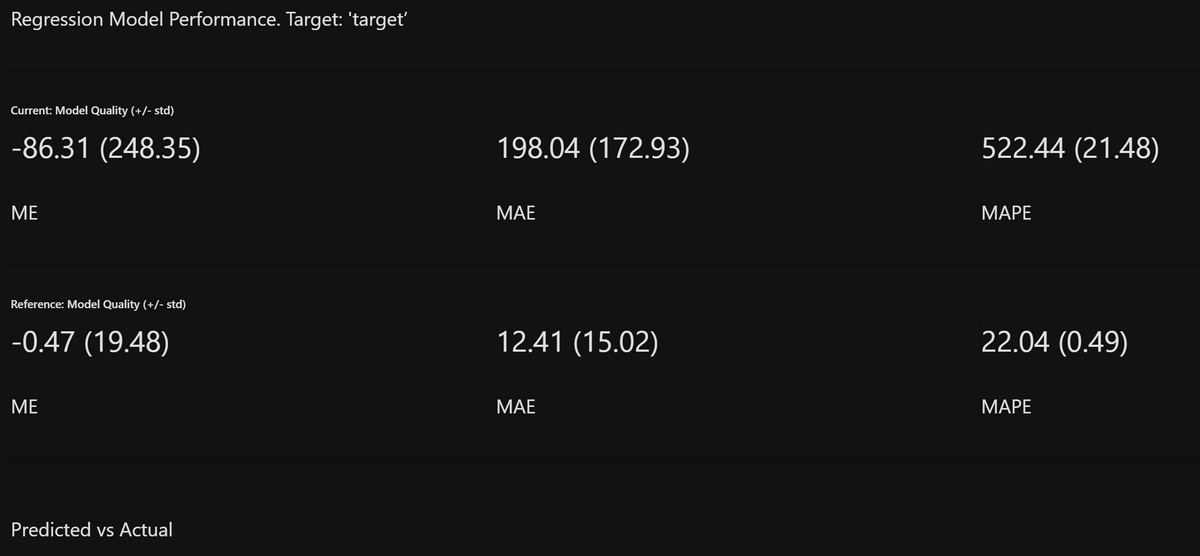
※以降、赤色と灰色のグラフが出てきますが、次のような区別です。
- current(赤色):訓練に使ったものとは違うデータ(評価用データ)をモデルに入力した場合の予測結果
- reference(灰色):訓練に使ったデータをモデルに入力した場合の予測結果
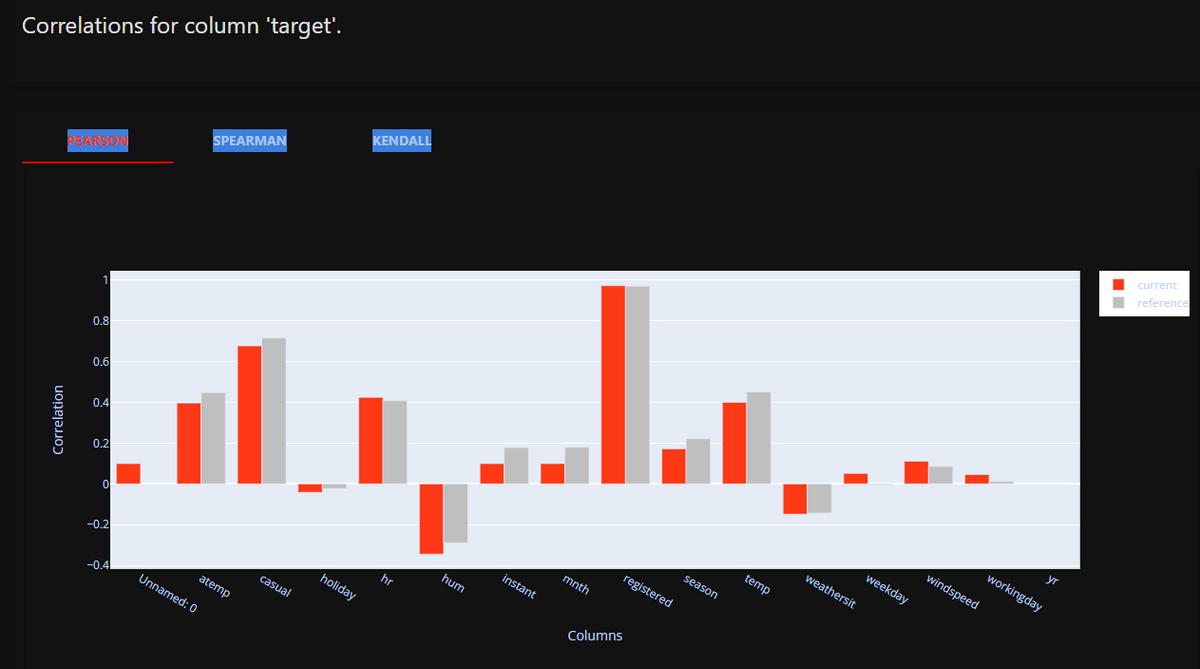
「(2)特徴量寄与率」として、以下のように各説明変数-目的変数(target列)間の相関係数を出力できます。
説明変数-目的変数間の相関係数が大きいほど特徴量寄与率が大きいことを示します。
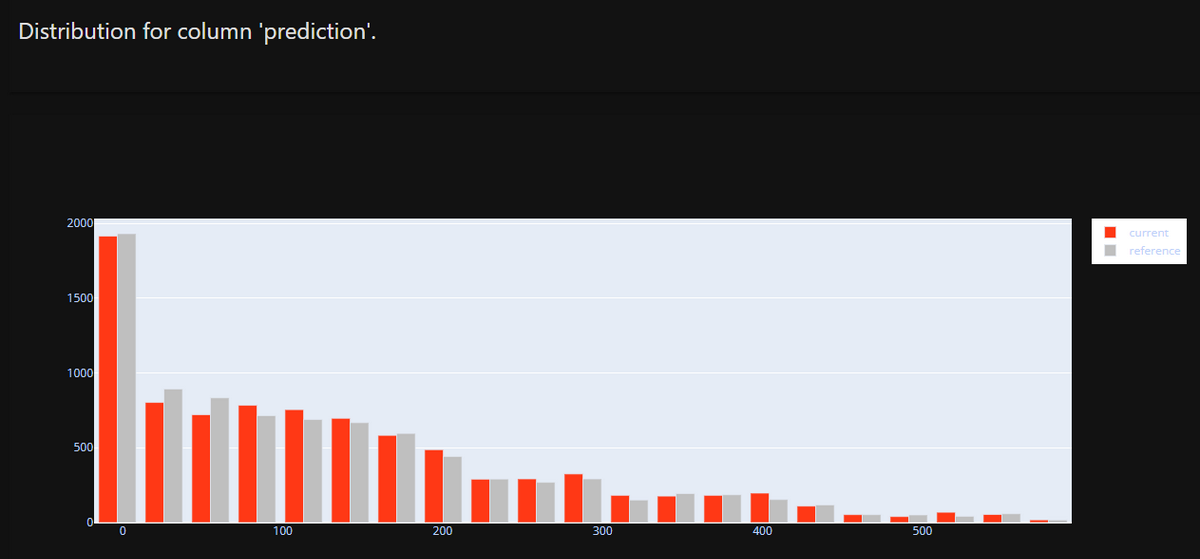
「(3)予測結果の偏り」として、以下のように予測結果の分布表示をできます。
訓練用データに対する予測結果(reference)と評価用データに対する予測結果(current)の分布を表示したものです。
両者の分布を比較することで、予測結果の偏りを監視できます。
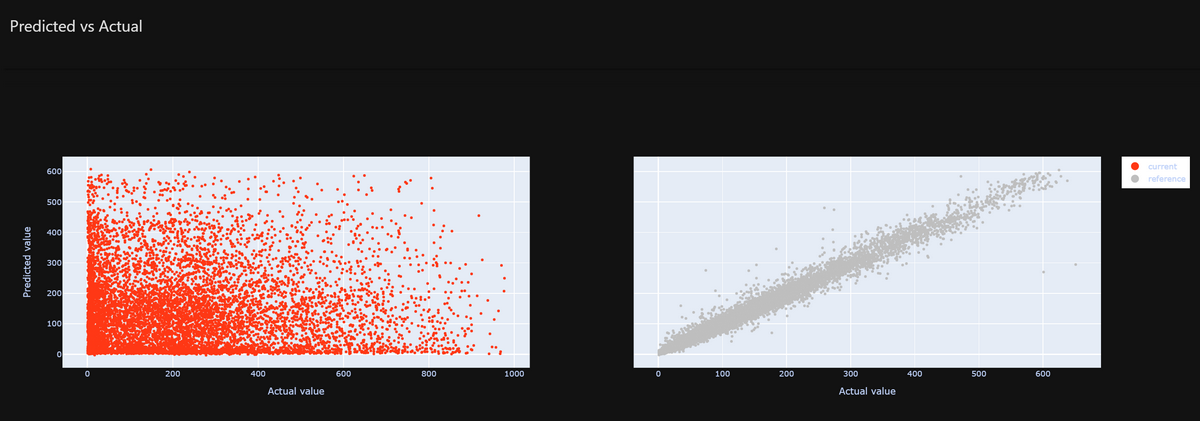
加えて、Evidently AIでは以下のような視覚的出力もできます。
次の画像は、予測結果と正解データの分布表示を表しています。
直線に近い見た目になるほど高精度であることを視覚的に示します。
また、誤差の時間的推移を視覚的に表示することもできます。
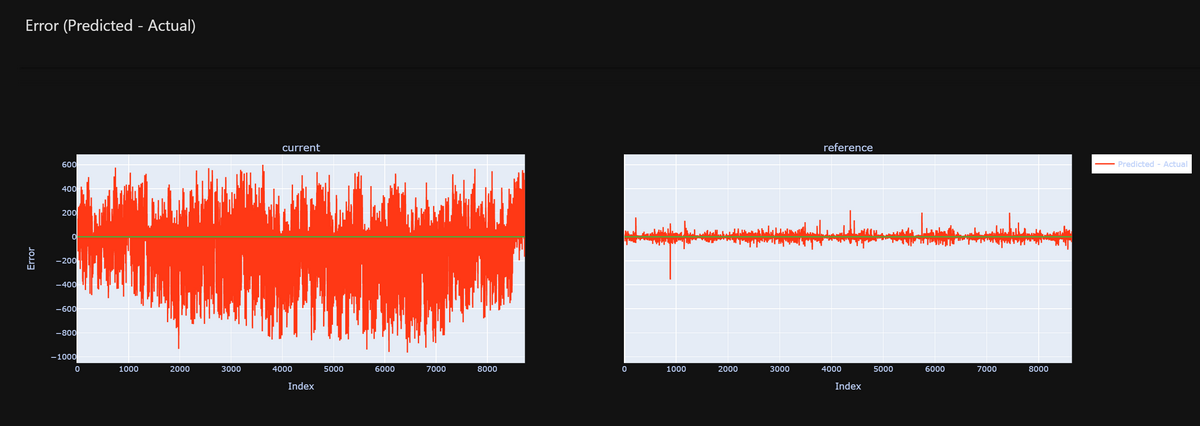
今回出力したグラフは一例ですが、Evidently AIでは他にも様々なグラフを出力できます。
詳しくは公式ドキュメントを参照してください。
5.2.4. 自動化とアラート
以上の手順を自動化するための実装コストは大きいと考えられます。
まず、Vertex AI APIからバッチ予測をリクエストし、その結果をCSVファイル形式等で受け取ります。
受け取ったCSVファイルから、予測結果データ列(prediction)を取り出し、 正解データ列(target)と合わせたテーブルを作成し、Evidently AIに入力します。
アラートについて、Evidently AIのTestの結果はJSON形式で受け取れるため、
その結果を受け取り、前回の評価結果と比較するシステムを構築すればアラートを発生させることが可能と考えられます。
※Evidently AIのTestについては前回の記事に詳細があります。
5.3. コスト
- 実装コスト
- ユースケースに合わせてPythonコードを実装する必要がありますが、コードは単純でドキュメントも分かりやすく、評価自体はローコードで実装可能です
- 自動化する場合、Vertex AI APIを駆使する必要があり、実装コストは大きいです
- 金銭的コスト
- Evidently AIを動かすサーバ・関数等のコストが掛かります
6. まとめ
本記事ではVertex AIとEvidently AIを用いたOutput Metrics監視の検証を行いました。
検証の結果を以下の表にまとめます。様々な観点で両者を比較しているので、ご参考になれば幸いです。
| 比較の観点 | Vertex AI | Evidently AI |
|---|---|---|
| (1)モデル精度 | ◎(5種の評価指標) | 〇(3種の評価指標) |
| (2)特徴量寄与率 | 〇(Shaplay値) | 〇(相関係数) |
| (3)予測の偏り | 機能は提供されていない | 〇 (予測結果の分布を比較) |
| 実装コスト | ノーコードで実装可能 | ローコードで実装可能。一部手作業 |
| 金銭的コスト | VertexAIのバッチ予測 + 評価のコスト | VertexAIのバッチ予測のコストのみ |
| メリット | モデルと連携して特徴量寄与率を算出可能 | 可視化機能が充実している |
| デメリット | 可視化機能が充実していない | 手動でVertex AIのバッチ予測を行う必要がある |