はじめに
こんにちは、TIGの原木です。
SLOconfという、Nobl9社が主催する、サービスレベル目標(SLO)に特化したカンファレンスがあります。今までオンラインでやってきたのですが、3回目になる今回、初めてオフラインで開催&世界各地でローカルなコミュニティイベントを同時開催する運びになりました。
日本ではGoogleJapanさんが手を挙げて、Googleの渋谷オフィスで2023/5/13日に、SLOconf Tokyo 2023として開催されました。
SLOに関する興味深い話を数多く視聴できたので、イベントレポートとして記録に残したいと存じます。
当日のセッションリスト
| No | タイトル | スピーカー |
|---|---|---|
| 1 | How I learned to stop worrying and love burn rates | Ashley Chen |
| 2 | スタディサプリにおける SLI/SLO の継続的改善 | @chaspy_ |
| 3 | SLOを満たせなくなったら | Shunji Kawabata |
| 4 | LuupにおけるSLOの物語 | @gr1m0h |
他、DatadogのToby BurressさんによるWhat we mean by 'Mean' (平均が意味するものは? )のパブリックビューイングも予定されていましたが、時間の関係でなくなりました。
SLOconf 2023 - How I learned to stop worrying and love burn rates
動画: https://www.youtube.com/watch?v=ra0cCmEVKS8
話された内容
DataDogのSLOチームで働いているAshley Chenさんに、閾値からバーンレートにインシデントの検知方法を変えた場合にどのようなメリットがあるのかお話いただきました。
運用監視通知システムのロジックを、「閾値を使ったシンプルな通知システム(Simple Threshold alert)」から「バーンレートを用いた通知システム(Burn Rate alert)」に置き換えてみたら…
- インシデントの検知対象は変わるのだろうか?
- paging数(システムから運用者への警告/通知数)に変化はあるのだろうか?
…ということについて、6か月にわたって実際のサービスメトリクスに基づいて両方のタイプのアラートをトリガーすることで実験したそうです。
バーンレートとは、SREのエラーバジェット(障害に対してどこまで許容していいかという予算)の消化率を表したものです。一般にはバーンレートが高い場合、障害によるユーザーへの影響が大きいことを示します。
その実験結果として、
- インシデントの種類によってバーンレートアラートの発火は変わる
- インシデントの種類は4種類に分類できる
- 既知のインシデント
- 既知のインシデントとは、アラートを受け取ったとき、既に上流で別のシステムが既にインシデントを認知、対応中であるようなケースのこと
- 依存関係にある周辺システムへのスケールアップの要求
- 不明
- フレイキーページ(Flaky Page)
- フレイキーページとはアラート後、数分して勝手に復旧するようなケース
- 既知のインシデント
- インシデントの種類は4種類に分類できる
- 既知のインシデントの場合はバーンレートは高くなるが、それ以外のケースはそれほどでもない
- 手動アクションの介入が最も必要なのは既知のインシデントの場合である
結果として「閾値を使ったシンプルな通知システム」と比較して、「バーンレートを用いた通知システム」ではユーザーのページ数を42ページも減らすことができると実験結果で得られました。
ページ(Page)とは、運用監視の文脈ではシステムからエンジニアやオペレーターへの警告または通知を指します。○○ページ減ったというのは、つまり運用者への警告数を減らせたことを意味します。
携帯電話が普及するより前、ポケベルという小型無線通信機が良く使われていました。英語名をPagerといいます。現代でも業務用として急患などの緊急通知で病院にいない医者の呼び出しをする等の用途で現役らしいです。IT業界ではSaaSのPagerDuty等にその名残があります。
感想
Flaky(フレイキー)という馴染みがあまりない用語を知ったのは、Jenkinsの作者である川口さんがソフトウェアのテストで「Flaky test」について解説した下記の記事でした。
https://www.publickey1.jp/blog/22/itjenkinsdevops_days_tokyo_2022_1.html
この記事には、フレイキーテストという、原因ははっきりしないのにたまに失敗するテストケースに振り回される開発者が出てきます。
これは何もテストだけに限った話ではなく、運用の場でも同様な事象が起こります。現代のサービスを支えるシステムは、Kubernetesに代表されるようにある程度のレジリエンシーを備えており、一瞬エラーイベントが発火しても数分したら回復していることも少なくありません。後述するセッション「SLOを満たせなくなったら」でもShunji Kawabataさんが強調していましたが、そのような一過性のイベントで開発者を呼び出した場合、呼び出された人には今しかかっている仕事を切り替えなくてはならない認知負荷を与えます。
もちろん、エラーイベントを生じさせているのは潜在的なバグである可能性が十分にあります。しかし、そのバグは、今しかかっている機能開発を止めてまで障害解決と対策に全力でリソースを入れなくちゃいけないものなのか、それともエラーバジェットの範囲内だといったんエラーイベントを許容できるレベルなのか。
そのバランスを保つために、開発者には適切なレベルでエラー通知を送るための材料として非常に説得力がある内容でした。
スタディサプリにおけるSLI/SLOによる継続的な改善(をこれからやっていくぞという話)
スライド資料: https://speakerdeck.com/chaspy/slo-at-studysapuri
話された内容
小学生から大学生までの学習を支援するサービス「スタディサプリ」でアプリケーション開発を行っているChaspyさんに、今関わっている「スタディサプリ 中学講座」にSLI/SLOで運用してみた苦い体験談について語っていただきました。
「スタディサプリ 中学講座」は2022年2月にリリースされました。順調にサービスは稼働し、リリース時に設定したSLI/SLOのモニタリング項目も遠い記憶となった一年後….ある時、SLO Alertが一度も鳴ったことがないという衝撃的な事実が発覚しました。
APMサービスであるSentryのExceptionAlertは飛んでいました。つまり、アプリケーションエラーが今まで起きたことが一度もないわけではありません。それなのに、SLO Alertは鳴ってないのはどうしてだろう? その理由について深堀してみたら数々の不具合が見つかりました。
最終的にはSLI/SLOに関して下記の見直しを実施しました。
- サービス間通信で利用していたGraphQLでエラーが生じた場合にhttpステータスを明示的に5xxで返すようにする
- マイクロサービス間のメトリクスを取得するためだけに入れていたプロキシサーバーのEnvoyをやめて、代わりにDatadog APM metricsを導入
- Datadog APM metricsに合わせた、メトリクスの取得方法やSLOの算出方法の変更
- エラーイベント発生時の対応のドキュメント化
感想
今回SLOconfを主催したNobl9のAlex Hidalgoさんが書いた「Implementing Service Level Objectives」(サービスレベル目標の実装)という書籍があります。
SLOの実装というタイトルの通り、SLOに関する実践情報がこれでもかと詰まった本ですが、その中でも好きなところが、第3部「SLOの文化」第14章「SLO Evolution(SLOの進化)」です。
サービスは時間経過に伴い様々な要因で変化し、当然、その際にSLOも変えていかなければなりません。SLI/SLOは定期的に見直さなくてはいけないねという話は、運用監視に携わる方ならよく聞く話だと思うのですが、ではどういったイベントが発生したらSLOを変えていかなければならないんだろうっていうことに踏み込んで説明した資料は少ないと思います。本誌を読んだとき、生命保険を見直すライフイベントに関するノウハウ本を読んでいるような錯覚を覚えました。
僭越ながら本書の日本語訳がもっと早く出ていればChaspyさんも…と思わずにはいられません。
本講演について、技術的には、Datadog APM metricsの”癖”に関して運用した知見に関する話が興味深く、実際に運用してフィードバックを得る良さを学びました。
Datadogのメトリクスの1つに、httpリクエストのエラー件数をカウントする trace.http.request.errors という指標があります。名前からこれで十分な気がしますが、実際は4xxのみカウントする(5xxは該当しない)指標でした…という登壇者の説明に、視聴者から「え、そうなの?」という反応が見て取れて面白かったです。
統合ログ管理ツールであるSplunkでエンジニアとして働いているKazunori Otaniさんが、こういう意図ではないか? とSlackで補足されていましたので引用します。
Client - Serverの通信で、両者にAPMエージェントがセットアップされているとして、
- 4xxの場合はClient側でエラーとして、Server側ではエラーとしてカウントしない
- 5xxの場合は、Server側でエラーとして、Client側ではエラーとしてカウントしない
みたいな世界観なのかなと思いましたーが、これでうまく行かないことも多いので、難しい
Otelエージェント(注: OpenTelemetryのこと)では、Server側として、4xx, 5xx両方ともerror扱いとしてるはずですね
SLOを満たせなくなったら
資料非公開
話された内容
Google Cloudの大規模ユーザー向けに、信頼性向上やパフォーマンスチューニング等の支援業務を行っているShunji Kawabataさんからは、「SLOを満たせなくなったら」というタイトルで、主にインシデント管理に関して語っていただきました。
SLOを満たせない状況の大半は、インシデント、つまり予期しない問題や障害が発生することに起因します。したがって、インシデントについての正確な理解や予防措置、対策をしっかり行えば、SLOを満たせない状況を回避できます。
そもそも、SLOに対するインシデントの影響が小さくなったことはどのように判断すれば良いでしょうか?
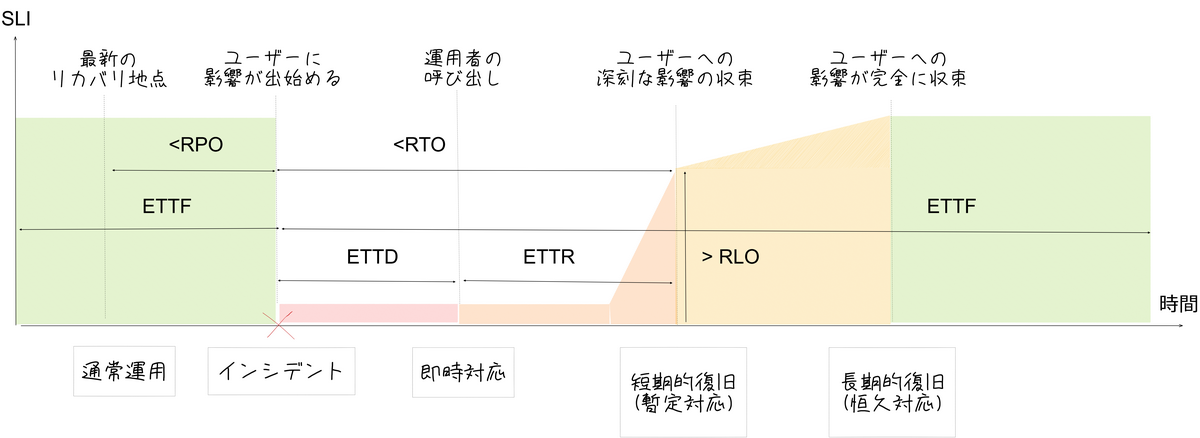
上記の図はインシデントとSLOの関係について説明したものです。インシデントの発生によるSLIの減少を最小限に抑えるためには、横軸が時間、縦軸がSLIを表すこの図の面積を小さくする必要があります。つまり、時間軸(横軸)とSLI軸(縦軸)のいずれかを縮小する必要があります。
時間軸については、「問題の検出時間」(ETTD: Estimated Time to Detect)と「問題の回復時間」(ETTR: Estimated Time to Recovery)を短縮することが求められます。一方、SLI軸では、「影響を受けたユーザー数」や「エラーの発生率」などのインパクトを最小限に抑えることが重要です。
また、インシデントの発生頻度を管理することも重要で、これは「次の障害発生までの時間」(ETTF: Extended Time to Fail)を長くすることで達成可能です。
これらの4つの要素を適切にコントロールするためにはどうすればいいでしょうか?
- 問題の検出時間(ETTD)を短くする
- 監視業務の自動化が鍵
- 運用者が日常的に見ている情報を文書化することでアラートポリシーやプログラムの材料とする
- よくやる対処策は自動化し、なるべく人手を要らないようにする
- 運用者の呼び出しは、人間にコンテキストスイッチを要求する負荷の高い行為なので最終手段とする
- 復旧時間を(ETTR)を短くする
- 統制とプレビューが鍵
- Googleはフラットな組織だが、インシデント対応に関しては完全なボトムアップ型の組織アプローチであるインシデントコマンドシステムを採用し、対応している
- 参考: GoogleCloudドキュメント「データ インシデント対応プロセス」
- インシデントを未然に防ぎ、ETTFを長くする
- 事後対応としてポストモーテムを実施する
- Googleではインシデントの7割はシステムの変更時に発生しているのでカナリアリリースやプログレッシブロールアウト(段階的なデプロイ作業)といったリリース戦略を実行する
- 参考: GoogleCloudドキュメント「カナリア デプロイ戦略を使用する」
- 事前準備をしっかり行う
- インシデント対応ポリシーを策定する
- コミュニケーションチャンネルを用意する
- 作業時間のリミットと引継ぎ方法を事前に検討することで、インシデント発生時に対応者が長時間拘束されることを防ぐ
- インシデント対応ポリシーを策定する
- 暫定復旧の基準点を決める
- SLOと同じ指標にしてしまうと往々にして困ることがあるので、長期的復旧とは指標を別にする
講演者から、極端な例だけど…と、データセンター火災とSLOの関係について、閑話休題的に説明があったのですが、非常にインパクトがありました。
先月、パリのGoogleCloudデータセンターの1つ、europe-west9 リージョンが豪雨に見舞われました。多大な雨量が地下室のバッテリー室に流れ込んだ結果、火災が発生し、現状でも完全には回復には至っていません。
https://www.theregister.com/2023/05/10/google_cloud_paris_outage_persists/
上記のようなまれによくある事態が発生すると、顧客にはリージョンのお引越しをお願いすることになります。ですが、リージョンを移動した後でも移動前と全く同じ環境かというと、細かい差異が出てくることもあるそうです。
この状況下ではいつまでもSLOを満たせず、暫定対応から中長期的な改善対応(データセンターの再建等)へのシフトチェンジを行えません。
したがって、暫定復旧と長期的復旧の指標は別にした方がよいでしょう、との結論でした。
- ポストモーテムを行い、失敗を学習、修正し、次に繋げる
- インシデントを解決した後はポストモーテム(振り返り)を実施し、その内容を共有する
- 共有作業を単なる公開処刑としないためには、心理的安全性の確保が欠かせない
- 心理的バイアスがあることを認知し、改善していくことで、失敗を学習、修正し、次につなげる行動は生まれる
- 参考: 「 サイトリライアビリティワークブック ―SREの実践方法」第10章 ポストモーテムの文化:失敗からの学び
- リスク分析を行う
「発生確率・影響度マトリックス」は、人間が正しくリスク判断できない恐れがあるのでお勧めしていない
代わりに「Net Error Budget Impact」という指標を使ってリスク評価する
この計算式に紐づいて CRE Risk Analysis Template でリスク分析をすると客観的な数値を計算できる
Net Error Budget Impactの計算式
リスク分析表の一例
- 年間停止時間が長い項目ほどリスクが高いことを示します。
| No | リスク | ETTD 問題の検出時間 |
ETTR 問題の回復時間 |
Implact 影響を与えたユーザーの割合 |
ETTF 次の障害発生までの時間 |
年間停止時間 左の4数値に基づいて計算した値 |
|---|---|---|---|---|---|---|
| 1 | 設定ミスでノード数をへらしてしまい、これによる過負荷でリクエストを取りこぼす | 30分 | 120分 | 20% | 120日 | 91時間 |
| 2 | 新しいリリースが半分のリクエストにエラーを引き起こすが、慣れていないロールバック手順のために復旧に時間がかかる | 5分 | 120分 | 50% | 180日 | 127時間 |
| 3 | 誤ってデータベースを削除してしまい、バックアップから復旧する | 5分 | 510分 | 100% | 1460日 | 129時間 |
| 4 | クラウドプロバイダーのゾーン障害で、全体の3分の1のリクエストを取りこぼす。該当ゾーンを外し、他のゾーンにノードを追加するが、キャパシティ不足でデプロイできない。 | 5分 | 960分 | 33% | 365日 | 319時間 |
感想
- SLOの脅威となるものはなにか? SLIとインシデントの時系列図を使って指標を可視化する
- 心理的安全性を確保することで、インシデントを次の改善につなげていく
- 人間が正しく評価することが苦手なリスク分析をSLIの指標を使ってリスク分析する
大きく三点にわたって話された内容は、Google流のSREポリシーが肌感覚でわかる非常に面白い講演でした。
個人的には、特に最後の「Net Error Budget Impact」を用いてリスク分析を行うあたりが、関心を引きました。ETTF(次の障害発生までの時間)が分類によってはどうにもなるので難しいところではありますが、こういった用途にも使えるのかと新鮮な驚きがありました。
この内容についてさらに深堀したいなと思ったところでググったところ、ニフティのテックブログで、本講演のリスク分析のテンプレートファイルについて詳細な解説記事が上がっていました。この場を借りて、ご紹介させていただきます。
関連リンク: 「SRE的なリスク分析手法を試してみた」
LuupにおけるSLOの物語
スライド資料: https://speakerdeck.com/grimoh/luupniokeruslonowu-yu
話された内容
電動キックボードや自転車などのシェアリング事業を展開するLuupで、SREとして働いているぐりもお。さんに「LuupにおけるSLOの物語」というタイトルで、Luupで実践しているSLO運用について語っていただきました。
- アジェンダ
- Luup SREチーム
- どんなことをしてるか
- どんなチームとコラボレーションしてるか
- LuupにおけるSLO
- CUJ、CMC
- SLO
- LuupにおけるSLO運用
- SLO定期見直し
- SLO違反対応
- BurnRateAlert対応
- Luup Case Study: Unlock
- Enabling SRE活動
- Luup SREチームの今後について
- Luup SREチーム
資料をご一読していただければ、講演内容の概要は分かると思うので、個別の概要については説明せず、感想にて自分が重要だと感じたことをピックアップしていく形を取りたいと思います。
感想
SLIについて
SLOの設定にあたり、どのような指標(SLI)を取るか。これはビジネスや提供するサービスによって大きく異なり、他社を参考に簡単に正解が見えてくるものではありません。
Luupさんには自分も上京した時にはよくお世話になっておりますが、電動キックボードや自転車など実機を扱うという点で、難易度の高い問題が更に複雑になったかと存じます。
たとえば、利用しようと思ったらスマホアプリで操作してQRコードを開いてリモートで鍵を解除してもらって…と一連のイベントが発生します。
この一連の流れの中で、Luup社はいったい何を計測すれば顧客体験の改善につながると判断したか?
そのスタンスを表現したのが、次のスライドでした。

通常のSREの文脈でよく使われるCUJ(Critical User Journey)を用いつつも、Luup独自のCMC(Critical Machine Communication)という計測対象を独自に定義し、CUJ(人)とCMC(マシン)の両側面からSLIを策定したそうです。
こういうポリシー策定って地味ですが重要な観点だと思います。さらに、そういった定義が必要になるということから逆説的にビジネスドメインが見えてくるのが面白いですね。
LuupにおけるSLO運用について
全体を通して、サイトリライアビリティワークブックにある内容を手堅くやっているなという印象でしたが、特にSLO見直しのケーススタディとして取り上げられていた「Unlock Availability SLO違反」の事例は、共感度が高かったです。
Luupの電動キックボードや自転車を利用するためには、スマホアプリを使って遠隔操作でロックを解除する必要があります。この遠隔操作の可用性に関するサービスレベル目標を定めたものが「Unlock Availability SLO」ですが、見直した結果、エラーバジェットに影響を及ぼしている2つの要因が分かったそうです。

特に後者のような、実機が絡み、リトライによって自動的に解決されるような問題は、なかなか適切なSLOの設定が難しいところです。「How I learned to stop worrying and love burn rates」でもフレイキーページとして説明されていたエラーイベントですね。
しかし、鍵が解除できないと実機を借りられず、少なくとも一人のユーザーの顧客体験を大きく損なってしまうので、こういうイベントはなるべく避けたいし、解消したいものです。顧客体験と開発リソースの狭間で、IoTデバイス特有のSLO運用の難しさがよくわかった事例でした。
最後に
昨年、OpenSLOに関する記事を書きました。1
https://future-architect.github.io/articles/20220518a/
あれから一年後、同じNobl9社を通してSLOconfというイベントに参加でき、貴重な経験になりました。特に、講演中の周りの反応…ざわめきだったり、どこでスライド資料の写真を撮っていたのか後ろの方に座っていたのでよくわかったのですが、こうしたところに改めてオフラインイベントの良さを感じました。イベントを開催した関係各社様にお礼申し上げます。
最後に2つばかり宣伝をさせてください。
この記事の途中で触れた、Nobl9のAlex Hidalgoさんが書いた「Implementing Service Level Objectives」(サービスレベル目標の実装)という書籍ですが、7月に「SLO サービスレベル目標(仮タイトル)」という名前で日本語訳が出版されるそうです。
https://twitter.com/shotaTsuge/status/1658408285803008000?s=20
また、SRE向けのテックカンファレンス、SRE NEXT 2023が今年も開催されるそうです。9月下旬を予定しているとのことなので、気長に待ちましょう。
https://twitter.com/ymotongpoo/status/1658448191346589697?s=20
どちらも楽しみですね。
- 1.OpenSLOは今回SLOconfを主催したNobl9社のメンバーが中心となって策定した、SLOを定義するためのオープンな仕様です...実はブログを書いてからほとんど動きがなくなってしまい、ちょっと残念ではあります ↩