はじめに
2022年12月キャリア入社の大村俊輔です。
強化学習を学びたい人が最初に読む本の感想です。本記事で2本目の投稿となります。

本書を読んだ背景
本書を読む前の、わたしの強化学習の理解状況を最初にお伝えします。
- 機械学習を3つに分類する際の1分野であること
- 教師あり学習(回帰や分類等)
- 教師なし学習(分類等)
- 強化学習(ゲーム等)
- 取り得る状態の数が小さければ全ての状態に対し
- 全探索により厳密解を求める
- ランダムな試行を繰り返し、良さそうな解を求める
…等で対応できるが、取り得る状態の数が大きい(一説では囲碁の取り得る盤面は10の200乗を超える! )ととても対応できないことが問題であった。
- そのようなケースで、状態をニューラルネットワークの形で持つことで、上記問題に上手く対応する手法である
- 私としては、簡単なニューラルネットワークは実装できるので、理論を理解できれば強化学習で遊ぶことくらいはできそう
- ただ、強化学習の理論は難しく、私に合った入門教材も見当たらないので手を出せない
…程度の認識でした。
なお、本書は業務に役立てる知識を得るためではなく、単純に面白そうなので学びました。
本書の特徴
本書は読んで学ぶ本ではなく、次の様な流れで学ぶスタイルであることが特徴です。
- まず人間が簡単なゲームを体験してみる
- サンプルプログラムを使用してプログラムにゲームをさせる
- サンプルプログラムのコードの丁寧な解説を読みながら、自分でもコードを書き替えて理解する
教師あり学習のゼロから作るDeep Learning ―Pythonで学ぶディープラーニングの理論と実装が合う方と相性が良いと思います。
目次
章立ては下記の通りです。
第1章 強化学習の位置づけ
第2章 Pyhtonの環境構築
第3章 教師あり学習
第4章 強化学習の問題設定
第5章 基本のQ学習:tableQ
第6章 ニューラルネットQ学習:netQ
第7章 経験再生を取り入れたQ学習:replayQ、targetQ
第8章 改良と工夫
講座A Visual Studio Codeのインストールと使い方
講座B Pythonの基本
本書の良かった点と注意事項
1章
まずは機械学習における強化学習の立ち位置と、強化学習の歴史について広く浅く簡単に復習できます。
2章
以降のPythonプログラムを実行するための環境構築です。AnacondaではなくMinicondaであったり、少々古めのバージョンのライブラリが指定されていたりと少々変わった環境を求められますが、基本的に書かれた通りに実行すれば良いです。ただ、古いPCで、CPUがAVXに対応していない場合、TensorFlowはこちらのAVX非対応のTensorFlowを使用する等の対応が必要です。
3章
ここから本書の良さが実感できると思います。
内容はまだこの後の章で使用するための教師あり学習で、直線の線形回帰モデルから平均二乗誤差(MSE)、勾配法、ニューラルネットワークを扱います。それぞれ丁寧な解説付きのコードと共に解説があり、結果のグラフ表示と併せて学ぶことで理解が深まります。
特に、パラメータとMSEの関係を等高線グラフや3Dグラフでイメージを持つ工程は習慣化したいですね。
4章
ここから強化学習に入ります。
まずは簡単なゲームを行い、ゲームのイメージを持ちます。
- 横4マスの盤面があり、一番左にロボットがいて、右から1番、もしくは2番目(ゲーム開始時にランダムに決定されます)にクリスタルがあります。
- ロボットは「進む」「拾う」の2種類の動作が可能で、「拾う」は1回のみ実行可能です。
(つまり、クリスタルの上で「拾う」ができれば成功、そうでなければ失敗)

5章
4章の簡単なゲームを解くプログラムを作成します。
各状態からの行動に対する価値(Q値)をまとめたQテーブルを作成します。
また、「ゲーム」そのもののコードについても解説してありますので、ゲームを少し改編して試してみるのも良いかと思います。
6章
ゲームがこれまでより難しくなりました。
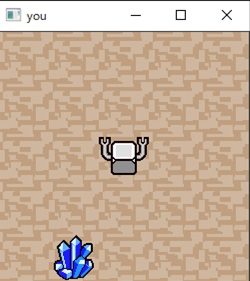
盤面は2次元でロボットは中央、クリスタルは1つで配置はランダム-状態数81
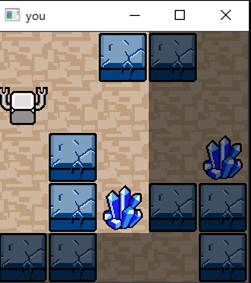
盤面は2次元でロボットの位置はランダム、クリスタルは1つで配置は固定だが壁もある-状態数約150(ロボットから縦横2マス以内は明るく表示、この領域を見えている領域とみなしてプレイ)
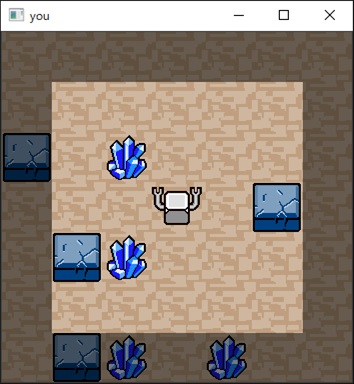
盤面は2次元でロボットの位置は中央、クリスタルと壁は4つずつで配置もランダム-状態数5千万以上(全クリスタルを回収できない盤面は現れない)
1, 2のように状態数が81や約150であればあ5章と同様にQテーブルを作成すれば良いですが、3.のように状態数が5千万を超えてくると、Qテーブルの作成は現実的ではありません。
そこで状態をニューラルネットの形で持つことにします。ここからは、本で内容を理解するというより、プログラムを動かしながら理解することになります。
これだけでも私がゲームをする場合と比べてもあまり遜色ないような気がします・・
7章
6章の3.ですでにそこそこの性能が出ていましたが、ときどきロボットがウロウロしてクリスタルを探しにいけないこともありました。
それを改善するために、なぜそれでプログラムの性能が向上するのかの解説と共に以下の2点を組み込みます。
- 経験再生(Experience Replay)
- ターゲットネットワーク(Target Network)
この時点で、もう私ではプログラムに勝てる気がしません。
高性能な強化学習プログラムが、囲碁や将棋で人間より強くなることを理解できた気がします。
8章
これまでのゲームをより複雑にしたり、組み込んだニューラルネットワークを変更したりと、これまでの学習内容を他のタスクに応用するためのヒントで締めくくられています。
本書では扱わない点
本書一冊で強化学習を何かに応用することは難しいと思います。あくまで強化学習に入門するための本で、応用が目的であれば他の教材で学ぶ必要があると思います。
最後に
強化学習を学びたい人が最初に読む本により、実際にプログラムを動かしながら強化学習の基礎を学ぶことができました。これで他の強化学習の教材で学ぶこともできるようになったと思いますので、これまで手を出せなかった少し難しい本にも挑戦したいと思います。
強化学習以外にも、常に新たな学びにつながる本を探し、その内容を記事にしていきたいと思いますので、その際もお読みいただければ幸いです。