はじめに
こんにちは、SAIG/MLOpsチームでアルバイトをしている板野・平野です。
今回は、昨今注目されている大規模言語モデル(LLM)の開発においてMLOpsチームがやるべきことを考えるため、まずはLLM開発の流れを調査・整理しました。
本記事はその内容を「LLM開発のフロー」という題目でまとめたものです。LLMを本番運用するときに考慮すべきこと、LLM開発・運用を支援するサービスやツール・LLMシステムの構成例などについては、「LLM開発でMLOpsチームがやるべきこと」と題して別記事でご紹介していますので、ぜひ併せてご覧ください。
ここでのLLM開発とは、「LLM自体の開発」および「LLMを活用したシステム開発」の両方を含みます。また、「LLM自体の開発」は学習フェーズ、「LLMを活用したシステム開発」は推論フェーズ、として記載しています。
本記事ではLLM開発における各フェーズのフローを解説します。
LLM開発のフロー
LLM開発は下図のように、LLM自体の開発(1.モデルを用意する(学習))とLLMを活用したシステム開発(2.モデルの能力を引き出す(推論))の大きく2つのフェーズに分けられます。
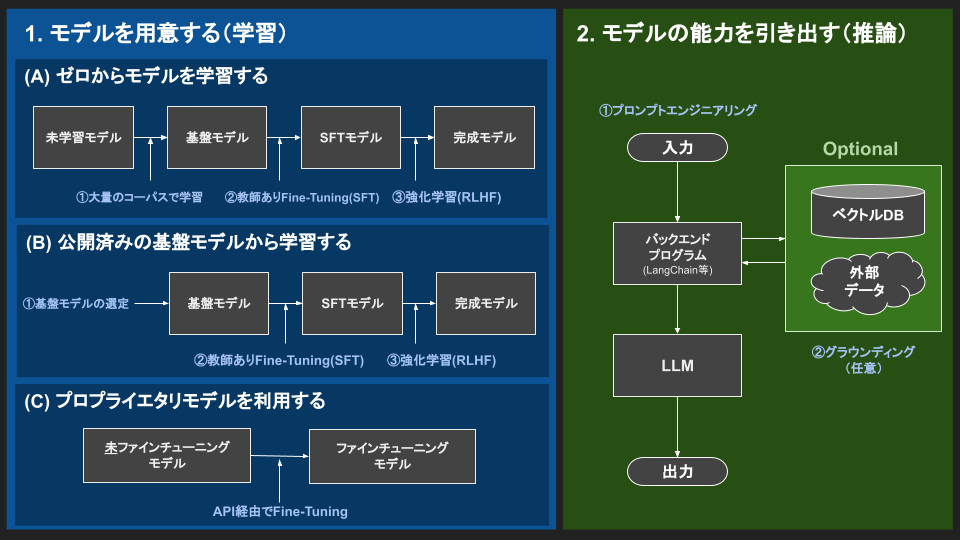
以下、各フェーズについて詳しく解説します。
1. モデルを用意する(学習)
モデルを用意するには、大きく分けて以下の3つの方法があります。
- (A) ゼロからモデルを学習する
- (B) 公開済みの基盤モデルから学習する
- (C) プロプライエタリモデルを利用する
※プロプライエタリモデル:ソースコードや構造等が非公開なモデルのこと。
(例)ChatGPT(GPT-3.5)やGPT-4等
どの方法を用いてLLM開発を行うべきかについては、要件に応じて決定します。
各方法のメリット・デメリットについては下表をご参考ください。
| (A) ゼロからモデルを学習する | (B) 公開済みの基盤モデルから学習する | (C) プロプライエタリモデルを利用する | |
|---|---|---|---|
| メリット | ・モデル構造を自由に選択可能 ・使用した全データセットを把握可能 |
・基盤モデル作成のコスト不要 ・様々な公開基盤モデルを試せる |
・推論リソースの用意が不要 ・汎用的なタスクにおいて高品質 |
| デメリット | ・学習に大量の計算リソースの用意が必要 ・推論リソースの用意が必要 |
・基盤モデルのライセンスに依存 ・推論リソースの用意が必要 |
・オンプレ運用ができない ・モデルが意図しないタイミングで更新される可能性がある |
以下、モデルを用意するための各方法の詳細を解説していきます。
(A) ゼロからモデルを学習する
ChatGPT(GPT-3.5)と学習方法が同じInstructGPTと呼ばれるモデルの学習方法は、論文として公開されており、下図のようなフローで学習されています。
※論文リンクはこちらです。
Training language models to follow instructions with human feedback
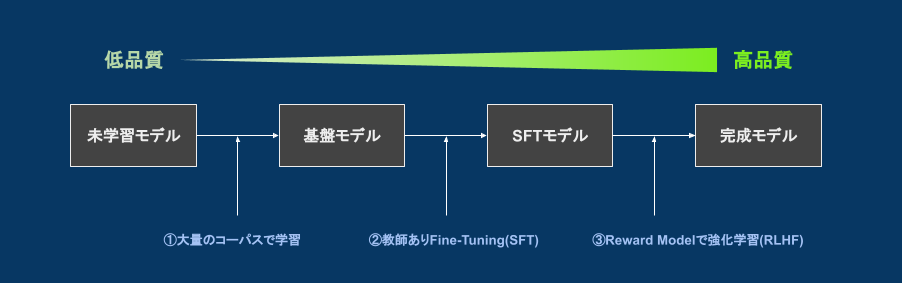
- (1)大量のコーパスで学習
- 未学習モデルに対して大量のコーパス(自然言語の文)で学習を行い、基盤モデルを構築
- 次に来る単語(next-token)を予測するモデルとなるため、それっぽい文章を作成できる
- 基盤モデルは、質問に答えたり対話したりする能力が乏しい
- (2)教師ありファインチューニング(SFT)
- 基盤モデルに対して「指示文・コンテキスト・理想の回答を人力で集めたデータセット」でファインチューニングする
- 人力で集めたデータセットとは、こちらにあるような指示文(instruction)、コンテキスト(input)、理想の回答(output)がセットになったもの
- ファインチューニングして得られるモデルはSFT(Supervised Fine-Tuning)モデルという
- SFTモデルには、質問に答えたり対話したりする等のタスク処理能力がある
- (3)人間のフィードバックによる強化学習(RLHF)
- 人間のフィードバックによる強化学習のことをReinforcement Learning from Human Feedback(RLHF)と呼ぶ
- SFTモデルに対して、文の品質をより向上させるためにRewardモデルを使用して強化学習を行う
- Rewardモデルとは、文章を入力すると、その文章の評価を数値として出力してくれるモデルのこと
- Rewardモデルは人間のフィードバック等を利用して別途作成しなければならない
- SFTモデルと比べ、人間にとってより好ましく流暢な出力が得られるようになる
(1)まで完了すると、プロンプトに続く文を次々と出力するだけのモデルが完成します。
LLM開発に、まずこのプロセスは必須です。この時点ではまだ要約や質疑応答などのタスクに対するファインチューニングが行われていないため、要約や質疑応答等のタスクをさせようとしても返答が不安定です。基盤モデルの学習データで「日本の首都は?東京です。」や「要約してください。"""<要約したい文書>"""。」 のようなinstructionのアノテーションが付いているものは極めて稀で、なにか特定のタスクを解かせるための学習がされていないからです。
(2)まで完了すると、質問に答えたり、対話したりする能力がついたモデルが完成します。この時点で、基本的なタスクを行うのに最低限のことは身についているため、より実用に近づきます。このプロセスは大半のケースで必要だと考えられます。
(3)まで完了すると、人間にとってより好ましい出力ができるモデルが完成します。ここまでするか否かは、要件やモデルに行わせたいタスクによって判断します。
ゼロからモデルを学習する場合に必要な計算リソースの参考値をご紹介します。
GPT-3に似たBLOOMというモデルは1760億のパラメータを持っており、BLOOMの発表記事では、学習に117日掛かり、300万ユーロ(約4.5億円)もの金銭的コストが掛かったと述べられています。
ただし、LLM関連の技術の進歩は早く、学習方法を工夫することで大幅に計算コストを減らしたり、パラメータ数が小さいモデルを使っても高い精度が出せたり等、より時間やコストを抑えられるようになってきています。
(B) 公開済みの基盤モデルから学習する
最近では基盤モデルがオープンソースで公開されるようになってきています。
公開されている基盤モデルを使用すれば、「ゼロからLLMを学習する」の学習フローにおいて大きなコストを要する「(1)大量のコーパスで学習」のプロセスをスキップできます。
公開されている基盤モデルからは、以下のようなフローで追加学習を行います。
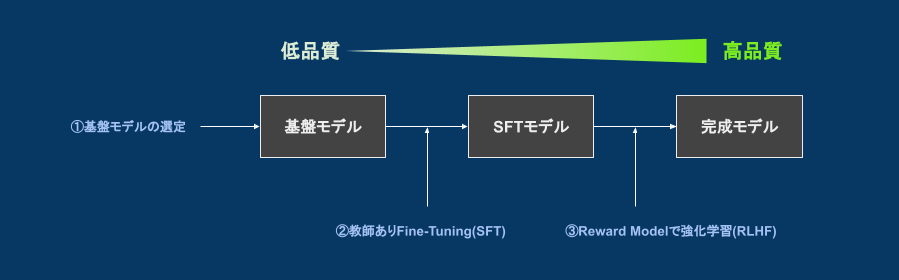
- (1)公開されている基盤モデルの選定
- 商用利用可能なものは、Llama 2 (ラマツー)やrinna, OpenCALMなどがあり様々な選択肢から選択できる
- ※公開済みモデルの中でも、rinna (japanese-gpt-neox-3.6b-instruction-ppo)のようにファインチューニングや強化学習が行われているものもあります
- モデル選定には「公開済みの基盤モデルが学習に用いたデータセット」や「パラメータ数」等を参考にする
- 商用利用可能なものは、Llama 2 (ラマツー)やrinna, OpenCALMなどがあり様々な選択肢から選択できる
- (2)教師ありファインチューニング(SFT)
- ※ (A)ゼロからモデルを学習すると同じ
- (3)人間のフィードバックによる強化学習(RLHF)
- ※ (A)ゼロからモデルを学習すると同じ
公開済みの基盤モデルから学習する場合に必要な計算リソースの参考値をご紹介します。
ゼロから学習する場合と比べ、ファインチューニングから始める場合は効率的なファインチューニング手法(Parameter-Efficient Fine-Tuning: PEFT)が複数あります。
こちらの事例ではLoRAというPEFT手法や8ビット量子化等のメモリ削減手法を適用し、VRAM使用量:23.5GBで1台のGPUでファインチューニングができています。
(C) プロプライエタリモデルを利用する
OpenAI等のAPI経由で公開されているモデルを利用する方法です。
現状、LLMを手軽に用意するにはこの方法が一番です。
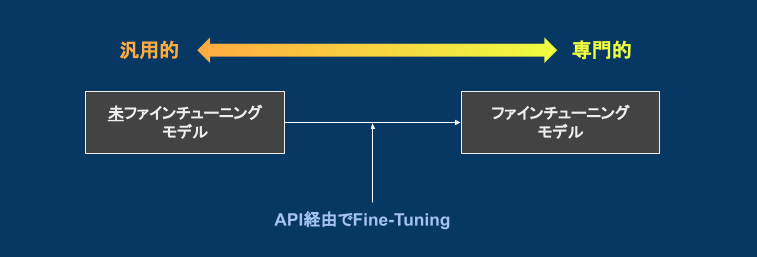
そのまま使うこともできますが、API経由でプロプライエタリモデルをファインチューニングすることもできます。
OpenAIのドキュメントによると、ファインチューニングで以下のような効果が期待できるようです。
- プロンプトで調整するよりも高品質な結果
- プロンプトに収まらない程の多くの例でトレーニング可能
- プロンプトを短くできることによるトークンの節約・レイテンシの減少
2. モデルの能力を引き出す(推論)
続いて、LLMを活用したシステム開発(推論フェーズ)について解説します。
従来のMLモデルは入出力の形式が一定で、分類や予測などの特定のタスクに活用する使い方が主流でした。
一方、LLMは汎用的なモデルであるため、1つのLLMモデルであらゆるタスク(質問応答、要約など)をこなすことができます。
このため、LLMモデルを入手したら、タスクを正しくこなせるように入力(プロンプト)を調節してモデルの能力を最大限引き出す工夫が新たに必要となりました。
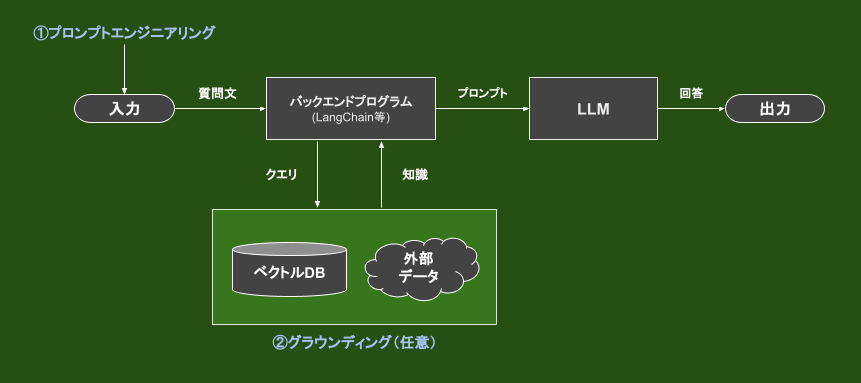
図内のバックエンドプログラムとして挙げられているLangChainとは、モデルの能力を引き出すあらゆる部分を効率化するライブラリで、知識データへの円滑なアクセス等も実装できます。
モデルの能力を最大限引き出す工夫として、大きく以下の2つの要素があります。
- (1)プロンプトエンジニアリング
- LLMへの「聞き方」を工夫することで質問応答や算術推論などのタスク処理能力を向上させる
- プロンプトの中に望ましい答え方のフォーマット等を埋め込んだり、例示したりする
- 望んだ回答が返ってこない確率を減らす
- (2)グラウンディング(任意)
- グラウンディングとは、仮想世界で存在するLLM等のシステムを現実世界と繋げること
- 現実世界にアクセスして情報検索をしたり、コマンドを発生したりする等
- LLM単体が知らないことでも答えられるようにするための知識データを用意する
- 文の要約など、外部知識を要しない質問の場合は不要
- 知識データの情報をプロンプトに付加することでLLMが知らない事も答えられるようになる
- LLMの特徴である、嘘をつくこと(=幻覚:Hallucination)を抑えられる
- 出力の根拠が把握できる
- グラウンディングとは、仮想世界で存在するLLM等のシステムを現実世界と繋げること
(1)プロンプトエンジニアリング
プロンプトエンジニアリングの一例を以下にご紹介します。
- Zero-shotプロンプティング
- モデルに対して事前に情報や例を与えずに直接質問をすること
- 質問例)「次の文をポジティブかネガティブに分類してください」「次の文章を要約してください」「1+1= 」等
- Few-shotプロンプティング
- モデルに対して事前にいくつかの例を提示してから質問すること
- 質問例)「1+1=2, 3+3=6, 4+4= 」「みかん→フルーツ, サッカー→スポーツ, 猫→ 」等
- Chain-of-Thought(CoT)プロンプティング
- モデルに中間的な推論ステップ(思考過程)を介するように促すこと
- 「ステップバイステップで考えてみましょう」の文言を入れるだけで良い結果が得られることがある
- 質問例)「6個のバナナを買いました。それを友達に2つ渡しました。それから3つのバナナを買って1つ食べました。残りは何個ですか? ステップバイステップで考えてみましょう」
他にもプロンプトエンジニアリングやその他の技術は多々あります。興味のある方は、こちらのサイトが参考になります。
(2)グラウンディング(任意)
グラウンディングの一例として、「ベクトルデータベースに知識データを格納しておき、検索クエリから類似のテキストを上位数件分持ってくる」等が挙げられます。
これを実現するための大まかな手順は以下の通りです。
まず、以下の流れでベクトルデータベースを準備します。
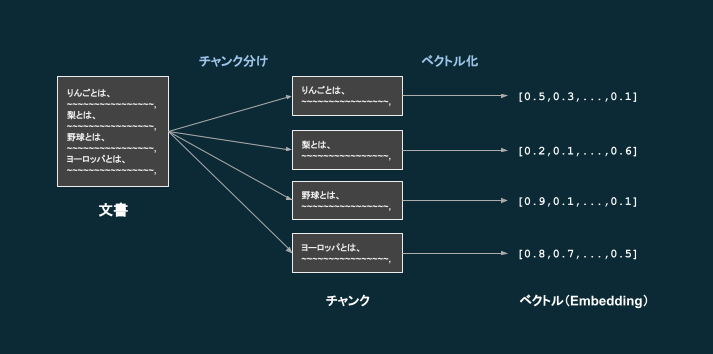
- 文書を用意する(社内QAチャットを作りたい場合は社内文書など)
- 文書が長い場合、チャンク分けをする(短い文書=チャンクに切り分ける)
- テキストをチャンク毎に低次元空間に埋め込む (Embeddingを作成する / ベクトル化する)
- テキストを入力として受け取り、ベクトルを出力してくれる、エンベディングモデルというモデルがある
- そのようなモデルは様々あり、OpenAIのtext-embedding-ada-002が高性能なモデルとして挙げられる
- チャンク毎に、「テキスト」と「ベクトル」の対をベクトルDBとして格納する
ベクトルDBが作成できたら、以下のように利用します。
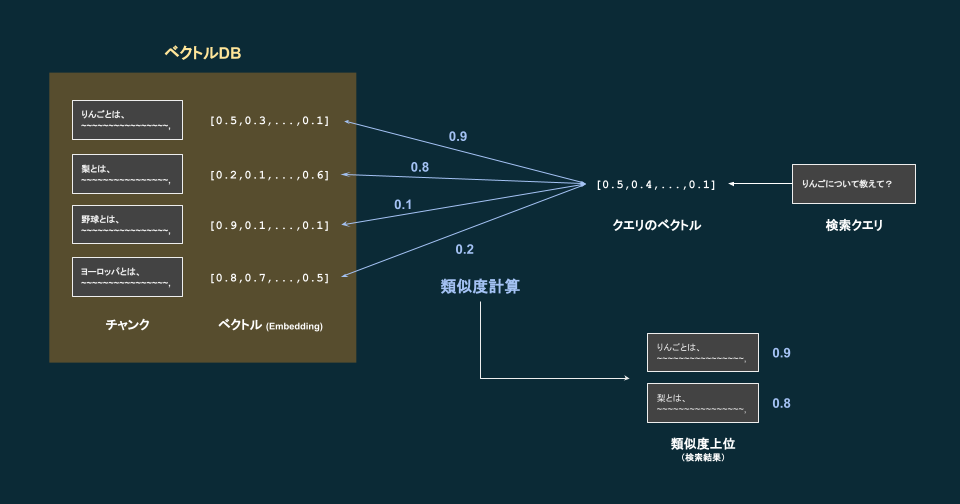
- ユーザーの質問文を元に、LLMが検索クエリを生成する
- ユーザーの質問が単純であれば、その質問をそのままクエリとしてもよい
- 検索クエリのテキストをベクトル化する
- ベクトルDBを作成するときに使用したエンベディングモデルと同じものを利用する
- ベクトルDBに格納されている各ベクトルと、クエリのベクトルとの類似度を計算する
- 類似度が高い上位のテキスト(チャンク)を取り出し、LLMのプロンプトに含める
基本となる考え方は以上ですが、これを簡単に実現できるようにクラウドサービスやライブラリとして提供されているものもあります。
ツール等の詳細は後日、別記事にて解説予定です。
まとめ
本記事では「LLM開発のフロー」と題し、LLM自体の開発およびLLMを活用したシステム開発のフローをご紹介しました。
これからLLM開発を検討している方々やMLOpsに携わっている方々の参考となれば幸いです。
今回ご紹介した「LLM開発のフロー」を前提とした、LLM開発でMLOpsチームがやるべきことについてもぜひ併せてご覧ください。
(2023年9月19日追記)関連して Prompt Flowでプロンプト評価の管理を行う という記事も公開しました。