はじめに
こんにちは、SAIG/MLOpsチームでアルバイトをしている板野・平野です。
今回は「LLM開発のためにMLOpsチームがやるべきこと」というテーマで、従来のMLOpsとの違い・ツール・構成例等について調査・整理しました。
LLMとはLarge Launguage Model(大規模言語モデル)の略であり、ここでのLLM開発とは、「LLM自体の開発」および「LLMを活用したシステム開発」の両方を含むものとします。LLM開発のフローについては以前にLLM開発のフローで詳細を説明しているので、ぜひ併せてご覧ください。
まず、MLOpsとは「機械学習モデルの実装から運用までを円滑に推進するための手法や考え方」のことです。AIの社会実装が増えるに伴い、MLOpsチームを設ける企業も増えてきました。また、最近ではLLMやその関連技術が急速に発達してきており、今後LLMを用いたアプリケーションが開発されていくと考えられます。
LLM自体やLLMを活用したシステムを開発していく場合、MLOpsチームからは「MLOpsチームは何をするべきか?」「既存のMLOpsの枠組みとの違いは?」といった疑問が生じます。
本記事ではこれらの疑問に答えられるよう、LLM自体やLLMを活用したシステムの開発の基本的な部分を踏まえてご説明します。
従来のMLOpsとの違い
まず、LLM開発の特徴を以下に整理します。
- パラメータ数が大きくて大規模(大量の計算リソースが必要)
- 汎用的なモデル
- 自然言語を扱う
- 生成AIである(出力が自然言語である)
- 人間による評価が必要
- モデルの能力を引き出すための工夫が必要
※従来のNLP開発の特徴も一部含む
特定のタスクに対応する小規模なモデルを学習&デプロイするのみであれば既存のMLOpsで対応できましたが、上記の特徴に対応するため、MLOpsチームは新たに「LLMのためのMLOps(LLMOps)」を考えていく必要が出てきました。
LLM開発の全体像
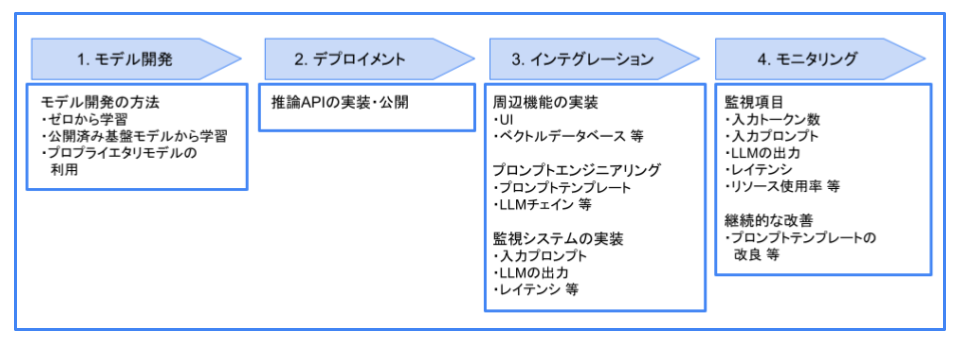
参考: https://note.com/wandb_jp/n/n1aa6d77f33cf
ここでは、LLM開発の全体像を見ていくとともに、各段階において従来のMLOpsと異なる点をご説明していきます。
一般に、ML開発では「モデル開発」→「デプロイメント」→「インテグレーション」→「モニタリング」と進めていきます。LLM開発も同様の流れで開発していくことになるかと思います。
1. モデル開発
以前にLLM開発のフローで紹介した通り、LLM開発は大きく「モデルを用意する(学習)フェーズ」と「モデルの能力を引き出す(推論)フェーズ」に分けられます。モデル開発の段階は「モデルを用意する(学習)フェーズ」に相当します。
「モデルを用意する(学習)フェーズ」では、従来のML開発と同様、データ収集からモデル選定、様々なハイパーパラメータで実験・評価を行い、モデルを開発していきます。
モデルを用意する方法は大きく分けて
- ゼロからモデルを学習する
- 公開済みの基盤モデルから学習する
- プロプライエタリモデルを利用する
の3種類があります。詳細はLLM開発のフローをご参照ください。
モデル開発の段階では、lossの監視やメタデータの保存、各実験のハイパーパラメータの管理などの従来のMLOpsと同様の実験管理を行う必要がありますが、それに加えLLM開発特有の管理も必要となってきます。
モデル開発の段階における従来のMLとLLMの違いとして、まずモデルが巨大であることがあります。そのため、様々な分散学習の手法を利用して効率的に学習を進めていく必要があります。
また、モデルの出力に対し確立された評価手法が存在しないこともあります。そのため現時点では、モデルの出力を人間が評価する必要もあります。したがって複数モデルの出力を効率的に評価・比較できるような仕組みを作る必要があります。
2. デプロイメント
このフェーズでは、開発したLLMをサービス側で使えるようにするためにAPIを実装し、モデルを公開します。
この段階でも、LLMの「モデルが巨大である」という特性から、従来のMLOps以上にリソース管理に注意を払う必要があります。
また、OpenAI等のAPI経由でLLMを利用する場合にはレイテンシやトークン数にも注意を払う必要があります。
3. インテグレーション
このフェーズは、LLM開発のフローにおける「モデルの能力を引き出す(推論)フェーズ」に相当します。
「モデルの能力を引き出す(推論)フェーズ」では、モデル開発の段階で開発したモデルをプロンプトエンジニアリングにより対象タスクに特化させたり、外部データと統合することで学習段階ではモデルが得ていなかった知識を活用して回答を生成できるようになります。こちらも詳細はLLM開発のフローをご参照ください。
また、サービスを提供するための周辺機能(フロントエンドのUIや外部データのデータベース等)を実装・テストし、サービスの提供を開始します。
この段階では、ベクトルデータベース等の構築に加え、サービス開始後の継続的な改善のため、入力プロンプト、チェーンの過程、モデルの出力等を監視できるシステムを構築する必要があります。
4. モニタリング
このフェーズでは、提供を開始したサービスが想定通り稼働しているかを監視し、問題があればサービスのアップデートを行う必要があります。
監視する項目はリソース使用率やデータ量、レイテンシ、モデルの入出力、入力トークン数など多岐にわたります。
LLM開発の課題・検討事項
では、LLM開発に対してMLOpsチームはどのようなことをすれば良いのでしょうか?
MLOpsチームがやるべきことは、以下のような課題や検討事項を解決し、LLM開発を円滑に進めることです。
※課題の一部を羅列
1. モデル開発における課題・検討事項
| 課題 | やるべきこと | サービス・ツール候補 |
|---|---|---|
| LLMの学習では大規模なデータセットを扱う必要がある | 「大量なデータの保管」や「効率良いデータの取り出し」ができるデータ基盤を用意する | [1] クラウド系データレイク |
| LLMの学習では大量のデータを集める必要がある | 「指示文・参考情報・理想の回答を人力で集めたデータセット」を効率良く収集する | [2] Argilla |
| LLMの学習には大量の計算リソースが必要 | 学習時の膨大な計算コストに注意を払う(分散学習の基盤などを用意する) | [3] クラウド学習基盤 |
| LLMの学習は大量の計算リソースを消費するため、必要以上の学習はコストを増加させる | 学習中に「どこで学習を終えるか」を判断するためにプロンプトに対する出力を適宜確認する | [4] MLflow [5] Weights & Biases [6] aim |
| LLMの定量的評価は難しく、人間による評価が必要 | 複数の基盤モデルをファインチューニングする際、各モデルの出力を効率よく比較する | [4] MLflow [5] Weights & Biases [6] aim |
| LLMは汎用的なモデルであるが故、学習時のタスクとダウンストリームのタスクが一致しない | 「学習の評価時に行うタスク」と「推論時に行うタスク」が異なり、推論フェーズで想定通りに動かないという事態を避ける | [2] Argilla [4] MLflow [5] Weights & Biases [6] aim |
| LLMの出力は自然言語であり、評価が難しい | 評価指標を用意する(人間による評価基盤の構築等) | [7] DeepSpeed Chat [8] JGLUE [9] toxic-bert [10] Moderation [11] Prompt Flow |
| 形式的なプロンプト(タスクの説明や出力の形式など)を毎回入力するのは面倒 | プロンプトのテンプレートを作成・管理する | [20] LangChain [21] LlamaIndex [24] Semantic Kernel |
| LLMはプロンプト次第で振る舞いが大きく変わってしまう | タスクに合わせてプロンプトを改良する。タスクが複数ある場合はそれぞれ独立で改良していく | [20] LangChain [21] LlamaIndex |
2. デプロイメントにおける課題・検討事項
| 課題 | やるべきこと | サービス・ツール候補 |
|---|---|---|
| プロプライエタリモデル使用時特有のコスト管理が必要 | プロプライエタリモデル使用の際、コストマネジメントのため、入力トークン数を監視する | [12] Datadog |
| プロプライエタリモデルの場合、レイテンシが発生してしまう | プロプライエタリモデル使用の際、サービス品質保証のため、レイテンシを監視する | [12] Datadog |
3. インテグレーションにおける課題・検討事項
| 課題 | やるべきこと | サービス・ツール候補 |
|---|---|---|
| サービス開始前にテストを行う必要がある | チャット形式のUIを用意してLLMを試験的に試してみる | [13] Dify [14] Fixie [15] Playground |
| LLMの能力を最大限引き出すために、外部データを活用する必要がある | 文書検索のためのベクトルデータベースを構築・運用する | [16] Chroma [17] Elasticsearch [18] Faiss [19] Pinecone |
| LLMの能力を最大限引き出すために、外部データを活用する必要がある | 文書等をベクトルデータベースに保管する | [20] LangChain [21] LlamaIndex [22] Cosmos DB [23] Azure Cache for Redis |
| LLMに会話の流れを理解させる必要がある | チャットの履歴を管理する | [20] LangChain [21] LlamaIndex |
4. モニタリングにおける課題・検討事項
| 課題 | やるべきこと | サービス・ツール候補 |
|---|---|---|
| サービスの継続的な改善 | 過去のプロンプトを保持し、プロンプト改良に繋げる。苦手なプロンプトを見つけたらマークして保持 | [20] LangChain [21] LlamaIndex |
| プロンプトインジェクションへの対策 | 不正な入力プロンプトを監視する | - |
| LLMが不適切な発言をしてしまう可能性がある | LLMの出力を定性的に評価・監視する(正確性、倫理性、バイアス、プライバシー等) | [9] toxic-bert [10] Moderation [25] Guardrails AI |
課題・検討事項をどう解決するか(ツール紹介)
LLMの急速な発達に伴い、上記の課題や検討事項を解決するのに役立つサービスやツールが沢山出てきています。一方で、LLMはまだ新しい技術のため、サービスやツールを使っても解決しない場合やそもそもツールが無い場合もあります。
このような課題はMLOpsチームが独自に工夫して解決していく必要があります。MLOpsチームは、活用できるサービスやツールは活用し、サービス・ツールが無い or 使えない場合の解決策を考えることに注力したいところです。
ここからは、MLOpsの効率的な推進に活用できそうなLLMのためのサービスやツールを紹介し、読者の皆様に役立つことを期待します。LLMのためのサービス・ツールは数多くありますが、以下に課題・検討事項に対応するサービス・ツールの候補を一部抜粋してまとめました。
その他にも多くのツールがあり、こちらが参考になります。以下は表にまとめた各サービス・ツールの詳細です。やや無秩序な羅列となっていますがご紹介します。
[1] クラウド系データレイク
AWSやAzure、GCPなどのクラウドサービスでは、「大量なデータの保管」と「効率良いデータの取り出し」が可能なサービスが提供されています。
- AWS
- データレイク:Amazon S3
- 検索サービス:Amazon Kendra
- Azure
- データレイク:Azure Blob Storage
- 検索サービス:Azure Cognitive Search
- GCP
- データレイク:Google Cloud Storage
- 検索サービス:Vertex AI Matching Engine
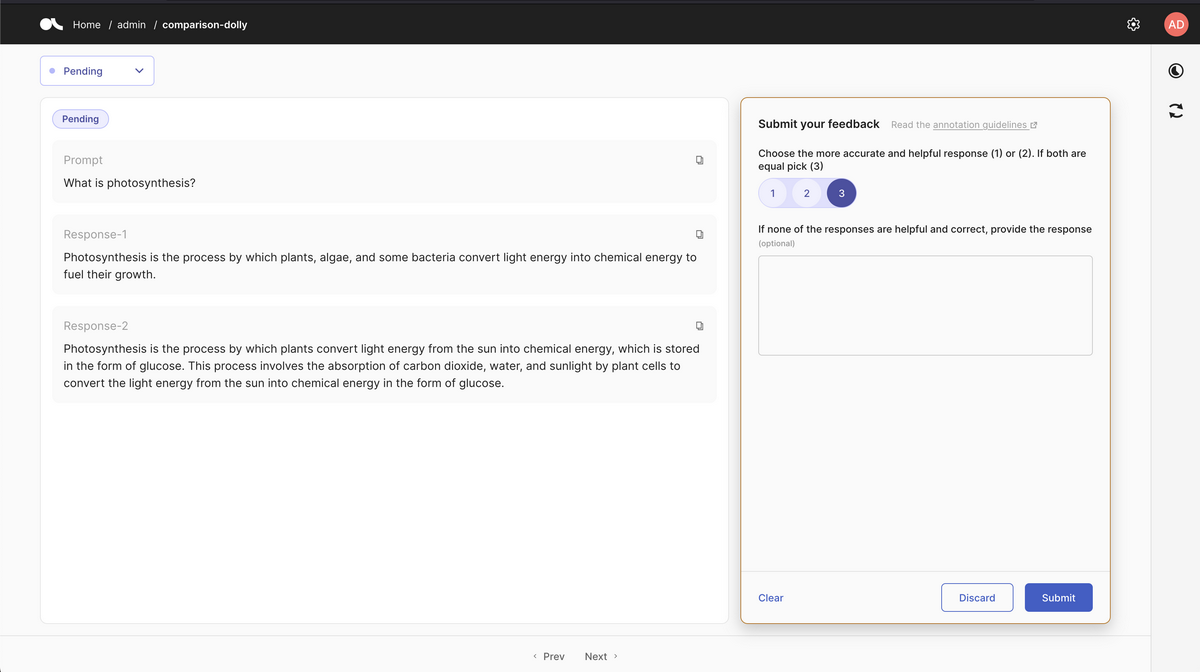
[2] Argilla
Argillaは、RLHF用に「人力で集めるデータの入力・出力の評価」を円滑にするための管理を行ってくれるプラットフォームです。\
例えば、人力で集めるデータとは、こちらにあるような指示文(instruction)、参考情報(input)、理想の回答(output)がセットになったものや、複数のLLMからの出力にランク付けをした結果等です。
このようなデータを収集する際、分かりやすいUIを提供し、集めたデータを管理してくれます。
詳細
[3] クラウド学習基盤
AWSやGCPなどのクラウドサービスでは、LLM開発のための学習基盤が用意されています。
- AWS
- Amazon SageMaker上でLLMの分散学習が可能です(参考)
- GCP
- Azure
- Azure Machine LearningでLLMの学習が可能です(参考)。Prompt Flow(後述)を利用することで、LLM自体の開発を含めたLLMを用いたサービスの開発を行うことができます
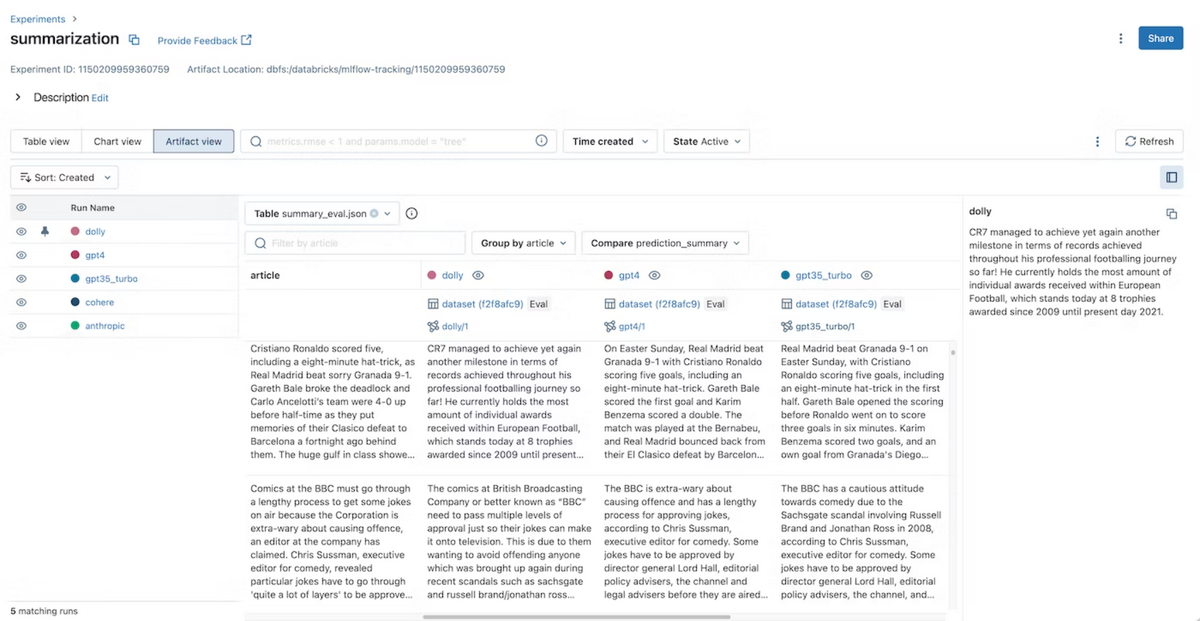
[4] MLflow
MLflowは、従来のMLOpsにおいても広く使われてきたツールですが、MLflowはバージョン2.3からLLMに対応し、
HuggingfaceのトランスフォーマーやLangChainのロギング機能が追加されました。
また、バージョン2.4からはLLMの評価のための機能も追加され、複数のモデルの入力、出力、中間結果を簡単に比較できます。
参考
[5] Weight & Biases
Weight & Biasesも有名なMLOpsツールです。Weight & BiasesではW&B Promptsというツールが提供されています。
LangChainの処理の可視化、各実行における入出力、中間結果の比較、チェーン構造やパラメータの確認が簡単に行えます。
YouTube動画にて、W&B Promptsでどのようなことができるのかが分かりやすく紹介されているのでぜひご覧ください。
[6] aim
aimでは、LLMの学習における各種パラメータやメトリクスのロギング、出力の確認、比較をできます。
LangChainの公式Docsに、Aimを用いたLangChainのトラッキングの例が記載されており、具体的な導入方法も分かりく紹介されています。加えてMLflowと組み合わせて使うことも可能なため、MLflowを現在使われている場合にも、導入を考えることができます。
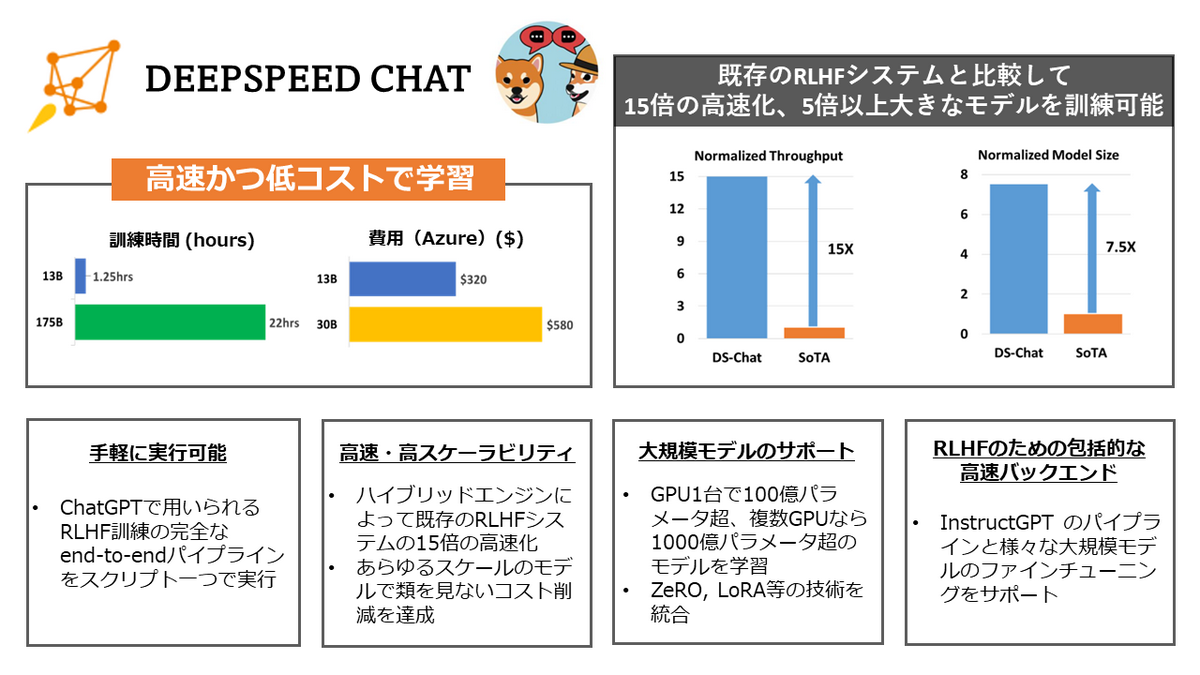
[7] DeepSpeed Chat
DeepSpeed Chatは、人間のフィードバックによる強化学習(RLHF)に必要なパイプラインをサポートするツールです。
通常、RLHFには複雑なパイプラインが必要で、多大なコストと時間が掛かりますが、DeepSpeed Chatを利用すると以下のような恩恵が得られます。
- 簡単なコードで複雑なRLHFのパイプラインを実行できる
- ZeROやLoRAベースの多数のメモリ最適化技術を利用することで計算リソースを大幅に削減できる
詳細
[8] JGLUE
JGLUEは早稲田大学とYahoo! JAPAN研究所によって作成された日本語理解能力を測るためのベンチマークです。文章分類、文ペア分類、質疑応答のタスクの能力を測ることができ、そのためのデータセットも用意されています。
注意点として、JGLUEは一般的な日本語理解能力を測るためのベンチマークであるため、JGLUEのスコアが良いからと言って目的タスクの精度も良いとは言えません。JGLUEのスコアはあくまで参考程度とするべきでしょう。結局、現状では目的タスクの精度を測るには独自でテスト用データセットを作成する必要があるかと思います。
[9] toxic-bert
toxic-bertはコメントの有害レベルの分類や有害なコメントの分類(どのような有害さを持っているか)が可能なモデルです。LLMの出力の監視に利用できます。
複数言語で学習済みのモデルが公開されていますが、日本語での学習済みモデルはないようです。しかし、学習用のコードは公開されているため、データセットを用意すれば日本語に対応したモデルも作成することもできるでしょう。
[10] Moderation
ModerationはOpenAIのAPIを利用する際に、入出力がOpenAIの利用ポリシーに反していないかを監視するために利用できるモデルです(それ以外の目的での利用は禁止されています)。
Moderationでは、ポリシーに反しているかのフラグ(True/False)に加えて、どのカテゴリー(sexual、hate、harassmentなど)で反しているか、各カテゴリーのスコアを返してくれます。
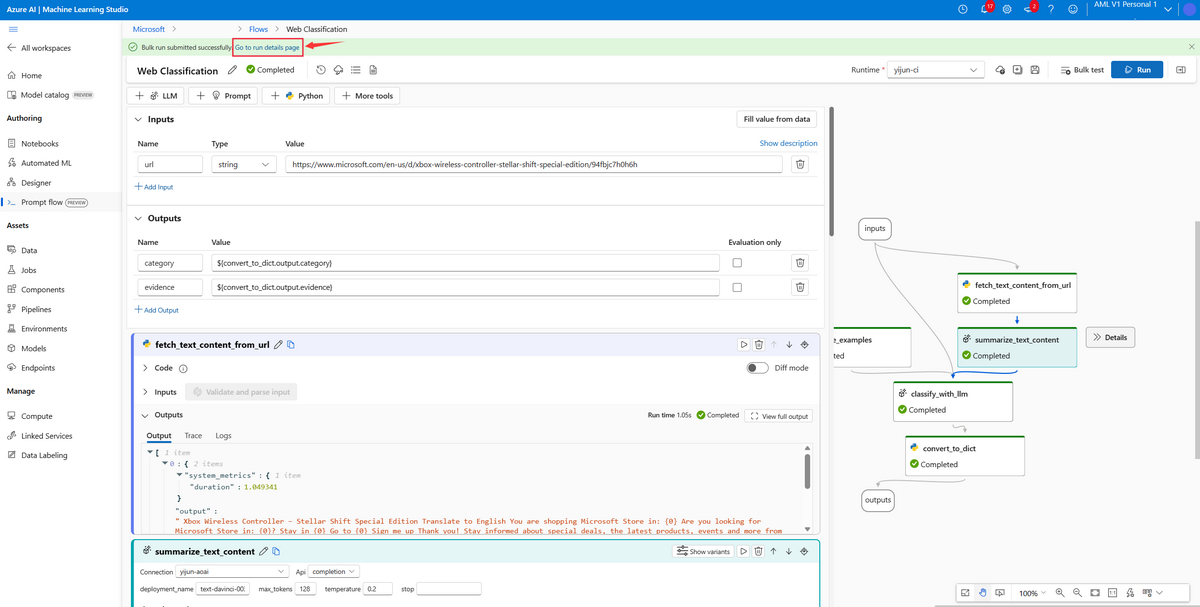
[11] Prompt Flow
Prompt FlowはLLMを用いたアプリケーションの作成・デバッグ・評価・デプロイを行うことができるツールです。作成したフローがグラフで可視化されているため、開発時にはどのようなフローになるのかを簡単に確認できます。また、作成したフローは簡単に評価できます。その後、デプロイまでをPrompt Flowで完結させることができます。
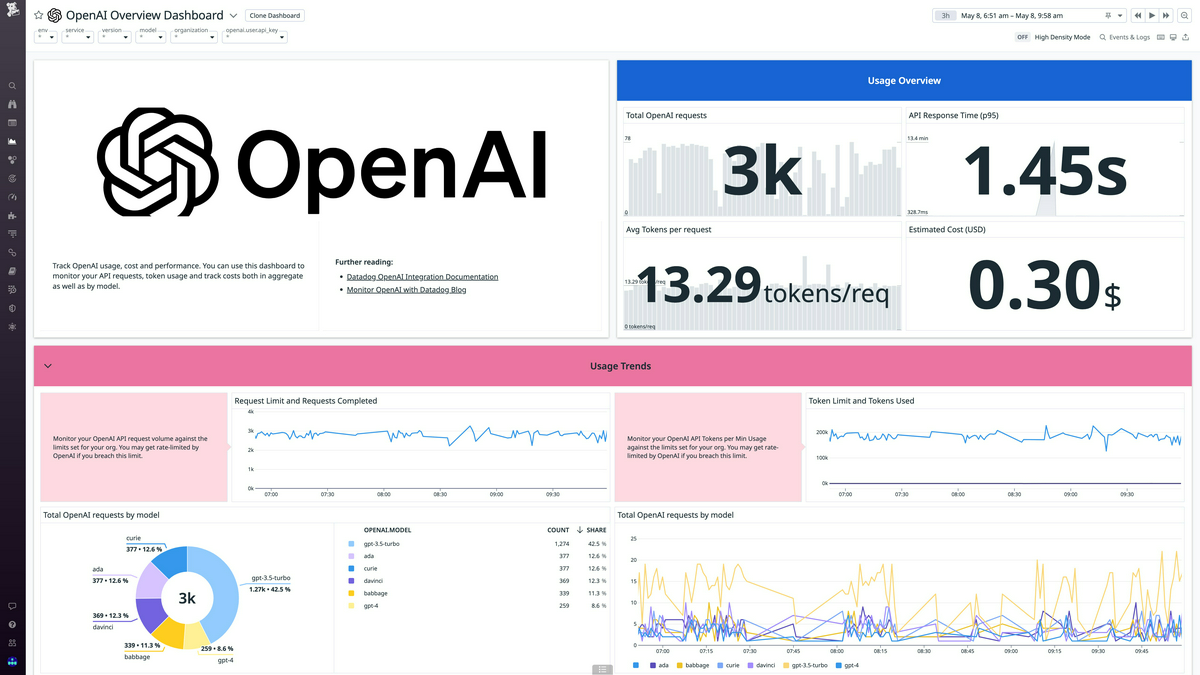
[12] Datadog
Datadogは、SaaS形式で利用できるモニタリングサービスです。
Datadogでは、OpenAI API利用時のトークンの総消費量、リクエストごとのトークンの平均総数、レスポンスタイム、APIのエラー率を監視できます。
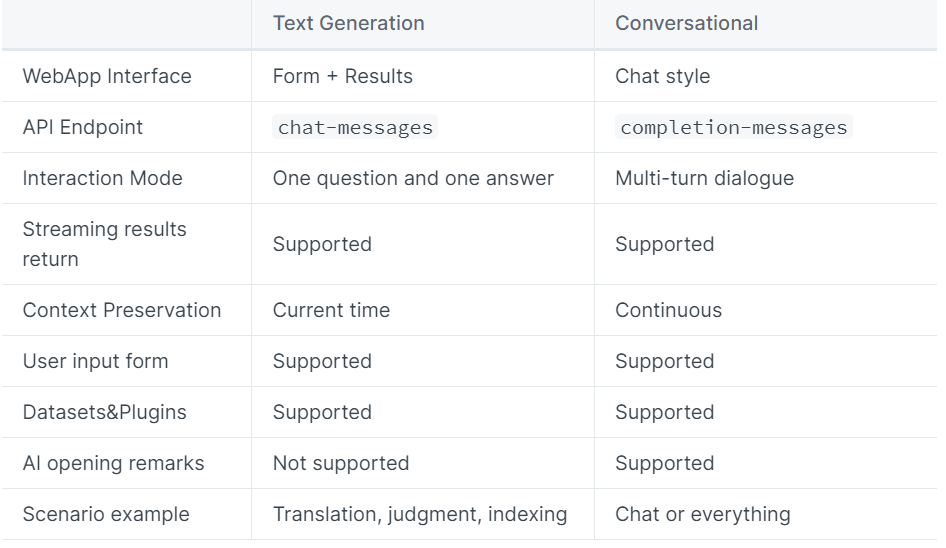
[13] Dify
DifyはLLMを用いたアプリケーションを簡単に作成できるツールです。Difyではテキスト生成型と会話型のアプリケーションを作成できます。
アプリケーションのタイプを決めた後は、プロンプトテンプレートを作成、データセットの読み込み、デバッグ、パラメータ調整等ができます。
また、アプリケーションの公開も行うことができます。
[14] Fixie
Fixieは、LLMを用いたアプリケーションを開発できるプラットフォームです。
Fixieでは、agent registryに登録されているLLMを使用でき、使用するLLMにはOpenAIなどのプロプライエタリモデルや独自にファインチューニングしたモデルなどを選ぶことができます。また、外部データとしてGitHub、Google Calendar、databaseなどを利用できます。
開発したLLMを用いたアプリケーションを作成したい場合や、開発したLLMが期待通りの挙動を示すかどうかのテストなどに利用できるかと思います。
[15] Playground
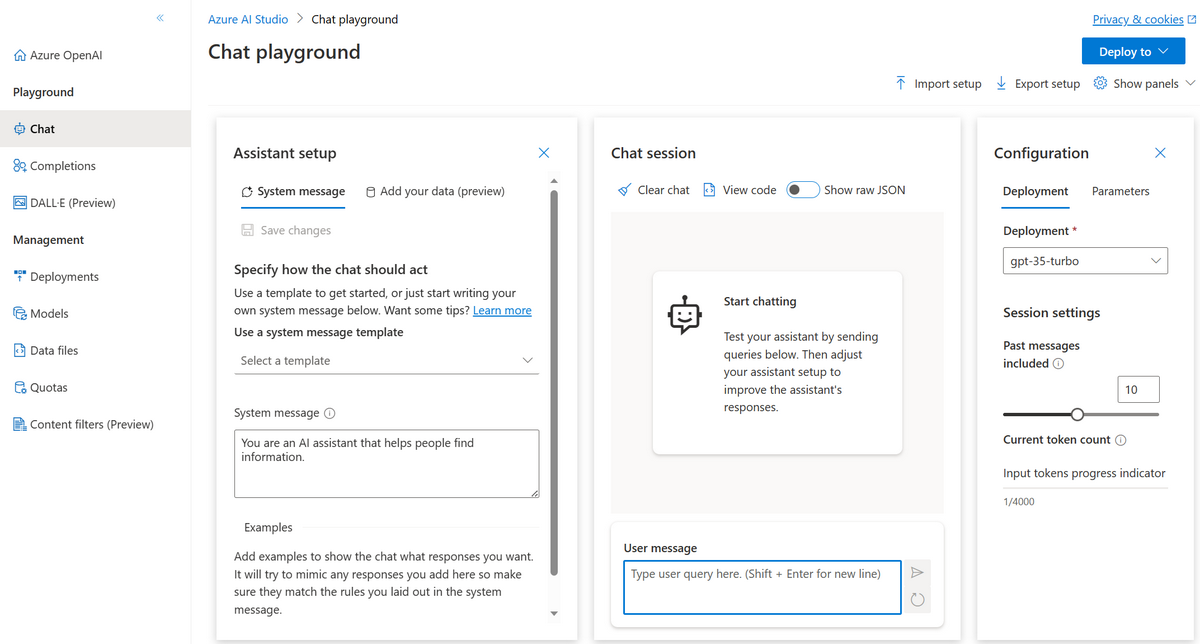
Playgroundは、Azure OpenAI Serviceで利用できる、モデルをインタラクティブに試すことが可能なサービスです。
チャット形式とcompletion形式でモデルを試すことができ、各種設定(システムメッセージ(モデルがどのように振舞うべきかを定義した文)や温度パラメータなど)もその場で変更できます。
[16] Chroma
LlamaIndex等で作成したIndexはどこかに保存しておいて、毎回作成するという手間は省きたいところです。
ChromaはLlamaIndex等で作成したIndexの保存、活用を容易にするためのOSSのベクトルデータベースです。
LangChainやLlamaIndexとの連携をサポートしており(参考)、またデプロイ先としてAWSが利用できます(参考)。
[17] Elasticsearch
ElasticsearchはElastic社が提供する全文検索エンジンです。
大量のデータ量やリクエスト量であってもスケーラブルに分散処理が可能となっています。 バージョン8.0からはNLPを用いたセマンティック検索の機能も追加されました(参考)。
これにより、LLMを活用したシステムにおける外部データの保存先として利用できます。
[18] Faiss
FaissはMetaが作成したOSSのベクトル検索ライブラリです。
テキストのインデックスの作成、検索が可能となっています。
マルチGPUでの検索もサポートされており、高速に類似した文章を検索できます。
[19] Pinecone
Pineconeはフルマネージドなベクトルデータベースです。
商用のサービスとはなりますが、インデックスの作成、検索、保存・管理をこのサービス1つで完了させることができます。また、スケーリングにも対応しているため、大量のリクエストにも高速に対応できます。
[20] LangChain
LLMを拡張し様々なタスクに特化させるための代表的なOSSツールとして、LangChainがあります。
LangChainでは、LLMの呼び出しから、プロンプトの管理、外部データの活用、連続的なタスクの実行などが簡単に実装できます。
詳細
以下にLangChainで提供されている主要な機能を紹介します。| 機能 | 説明 |
|---|---|
| Models | LangChainがサポートしている多くのモデルを同一インタフェースで扱える |
| Prompts | プロンプトの管理、最適化、シリアル化ができる |
| Memory | LLMとのやり取りを保存でき、またそれを用いてLLMに過去のやり取りを踏まえた回答を促すことができる |
| Indexes | LLMに外部データを踏まえた回答をさせるため、外部データのロードやクエリ、更新のためのインタフェースが用意されている |
| Chains | LLMに対して連続的に指示を出すことができる |
| Agents | LLMに次にすべきことの決定、実行、結果の観測を繰り返させ、高レベルの指示に応えさせることができる |
| Callbacks | Chainの過程を記録することができ、アプリケーションのデバッグ・評価をしやすくする |
[21] LlamaIndex
LlamaIndexは、大量の文書等から質問に関連する内容を抽出し、その内容に基づいてLLMに回答させるといったことができます。
この場合、まず大量の文書をベクトル化して保持しておきます。質問文が来たら、ベクトルとの類似度をもとに関連する文章を抽出し、
その内容をプロンプトに含めてLLMに回答させるという流れになります。
LlamaIndexを用いることで、
- 外部データの読み込み
- Indexの作成
- クエリで関連データを抽出
ができるようになります。
[22] Cosmos DB
Cosmos DBは、チャット形式のLLMを用いたアプリケーションにおいて、会話履歴を保存する場合に使うことができます。 Cosmos DBはAzureのフルマネージドなNoSQLデータベースです。
こちらの記事では、実際にCosmos DBを用いてチャットの履歴を保存する例が紹介されていますのでご参照ください。
[23] Azure Cache for Redis
Azure Cache for Redisも会話履歴を保存する際に利用できます。通常はインメモリキャッシュとして使用することが想定されますが、データ永続化の機能を利用することでNoSQLのDBとしても利用できます
(参考)。
[24] Semantic Kernel
Semantic Kernel(SK)は、Microsoftが開発しているOSSのサービスで、LLMと従来のプログラミング言語を簡単に組み合わせることが可能で、LLMをアプリに統合できます。
SKでは、LLMを特定のタスクを実行する関数(Semantic Function)として扱い、従来のプログラミング言語の関数(Native Function)と合わせて、「スキル」という枠組みで扱います。そして、これらのスキルをパイプライン化してまとめることが可能です。
さらにプランナーという機能では、登録されたスキルを使って自動でタスク実行のためのスキルの選択・実行順を考えてくれます。
[25] Guardrails AI
Guardrails AIはLLMの出力に対して、構造検証、型検証、品質検証を行うことができるPythonライブラリです。
Guardrails AIには以下のような出力検証機能があります。
- 生成されたテキストに偏りがないか、生成されたコードにバグがないかなどの意味的な検証を行う
- バリデーションが失敗した場合、修正アクション(LLMに再びプロンプトを入力する等)を実行する
- 構造や型(JSONなど)の検証を行う
LLMシステム構成例
これまで、LLMに対するMLOpsチームの課題ややるべきことを中心に説明しました。ここからは、LLMの具体的なユースケースから理解を深めていただくことを目的として、LLMシステムの構成例を紹介していきます。
本章では、LLMシステムの構成例を「クラウドサービスに依存しない構成例」と「クラウドサービスを用いた構成例」に分けてご紹介します。
いずれの例も、社内文書やWeb上のドキュメント等をチャット形式で検索できるようなシステムの構成例です。
クラウドサービスに依存しない構成例
以下はLLMを用いたチャットによる文書検索システムの構成例です。
特定のクラウドサービスに依存せず、可能な限りOSSで構成する際の構成案を考えてみました。
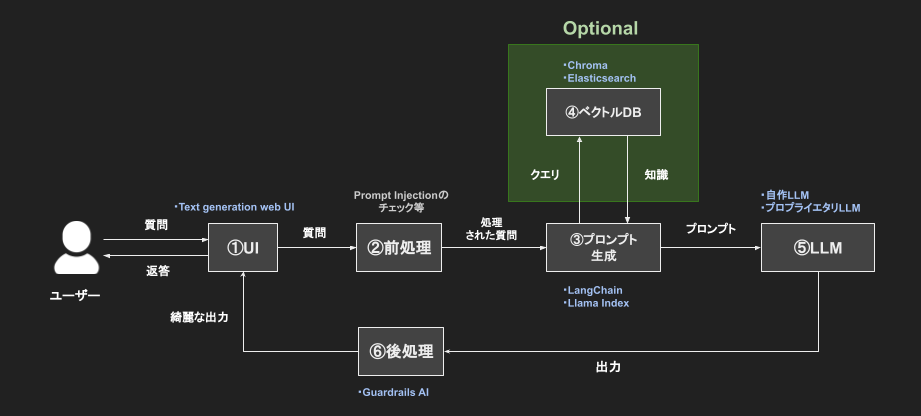
- (1)UI
- ユーザーからの入力をチャット形式で受け付ける
- チャット形式のインタフェースにText generation web UIというツールを利用
- あらゆるLLMに対応しているため、モデルの交換等がスムーズに行える
- (2)前処理
- プロンプトインジェクションという攻撃を防ぐ役割を持つ
- プロンプトインジェクションとは、「LLMに対して特殊な質問をすることで、LLMが持つ機密情報や非公開データを不正に引き出す攻撃」を指す
- ユーザーからの入力を何らかの形でフィルタリングする必要がありますが、確固たる手法は未だ無い
- 現状、前処理部は概念として図示しているが、今後必要になってくると考えられる
- この前処理部分は、プロンプト生成部にまとめても良い
- (3)プロンプト生成
- ここでは入力された質問からプロンプトを生成する
- プロンプト生成のためのライブラリとして、LangChainやLlamaIndexが代表的
- ライブラリを使うことで、「長い文章をベクトル化してプロンプトに含める」や「ベクトルDBから検索したい文章を抽出しプロンプトに含める」等の処理が実装できる
- (4)ベクトルDB
- ベクトルデータを扱えるデータベース
- 社内文書など、様々なテキストデータをベクトル化し、得られたベクトルをデータベースに格納する
- 検索する時は、検索したいキーワードのベクトルと類似のベクトルをデータベースから検索する
- ベクトルDB・全文検索エンジンとして、ChromaやElasticsearch等が挙げられる
- (5)LLM
- 自力でファインチューニングしたモデルやプロプライエタリモデルを使用する
- (6)後処理
- LLMの出力の品質を保つために、出力に後処理を施す
- Guardrails AIというライブラリを使うと、生成されたテキストに偏りがないか、生成されたコードにバグがないかなどを検証ができる
- この後処理部分は、プロンプト生成部にまとめても良い
クラウドサービスを用いた構成例
上記の、クラウドサービスに依存しないチャットによる文書検索システムに似たものを三大クラウドサービス(Azure, AWS, GCP)で構成する場合は以下のようになります。
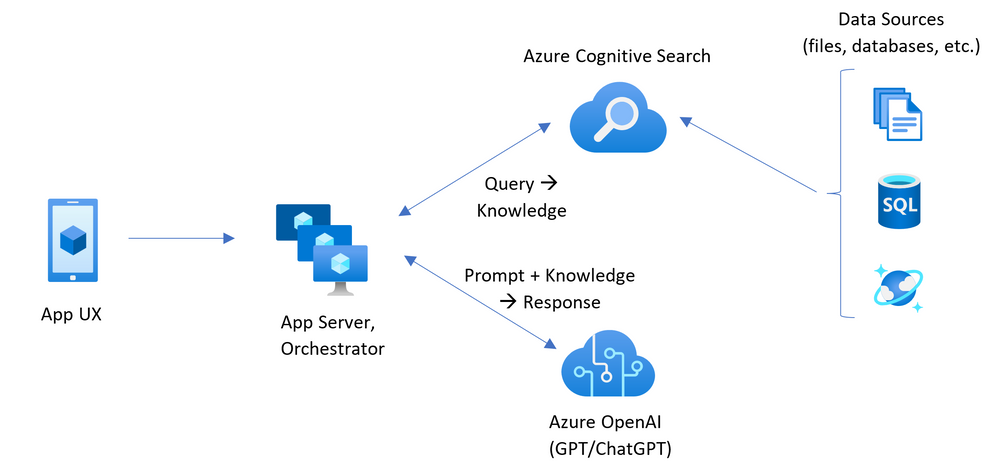
Azure
AzureにおけるLLMを活用したシステム開発の特徴は以下の通りです。
- Azure OpenAI Serviceにより、OpenAIが提供しているGPT-4やGPt-3.5、Codex等が利用可能
- 文書検索にはAzure Cognitive Searchというサービスを使うことで、PDFやHTML,Microsoft Office形式など様々なデータソースから検索可能
- OpenAIのAPIと比べて、プライベートネットワーク、リージョンの可用性、責任あるAIコンテンツのフィルター処理などの機能が利用可能
※ただし、6/27現在、新規の利用者はモデルのファインチューニングを行うことができない点に注意が必要です。
構成図
AWS
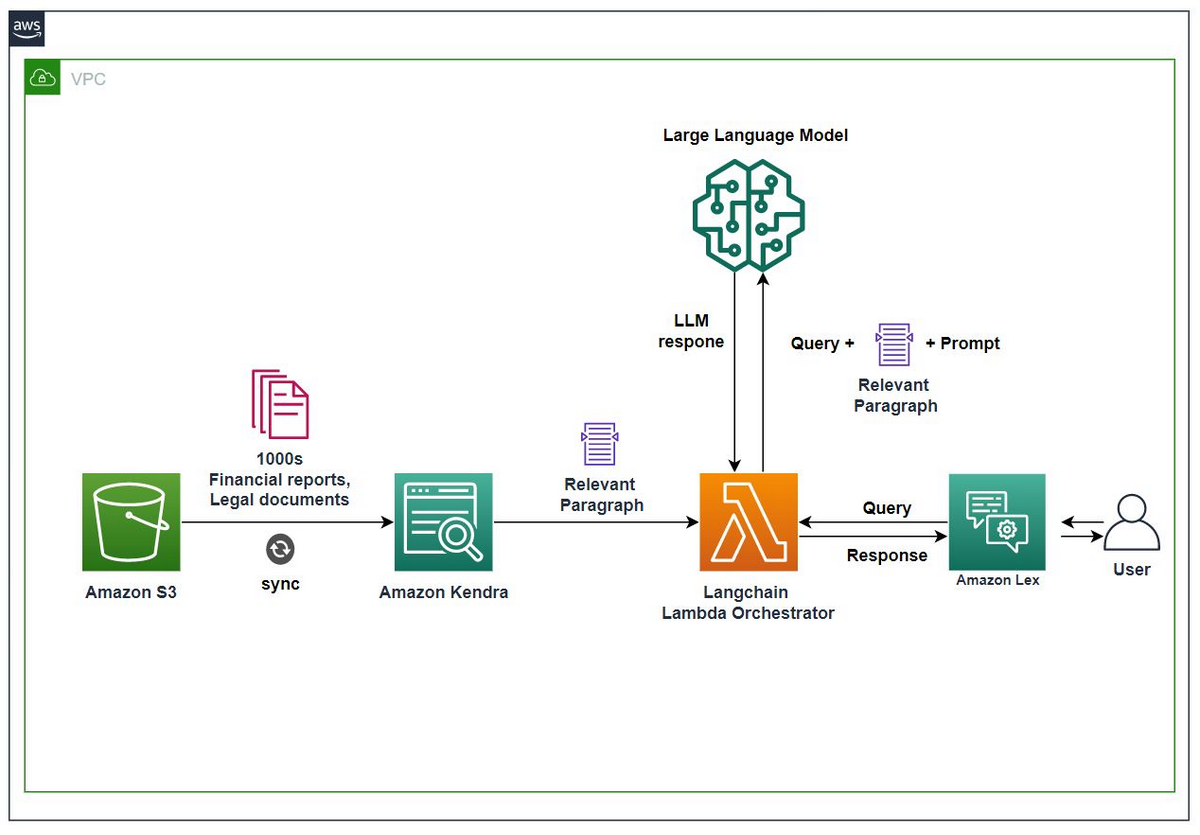
AWSにおけるLLMを活用したシステム開発の特徴は以下の通りです。
- AWS独自のLLMであるAmazon TitanやそれらをAPI経由で利用できるAmazon Bedrockを用いて開発が可能
- LangChainを実行するサーバーとしてLambdaを活用し、サーバーレスなシステムを構築可能
- 文書検索にはAmazon Kendraというサービスを使うことで、S3上のPDFやHTML,Microsoft Office形式など様々なデータソースから検索可能
- Amazon SageMakerと統合されており、複数モデルをテストするための実験や基盤モデルを大規模に管理するためのパイプライン等の機能が利用可能
構成図
GCP
GCPにおけるLLMを活用したシステム開発の特徴は以下の通りです。
- LLMのモデルには、Model GardenにてGoogle製のLLMであるPaLM、Imagen、Codey、Chirp等が利用可能
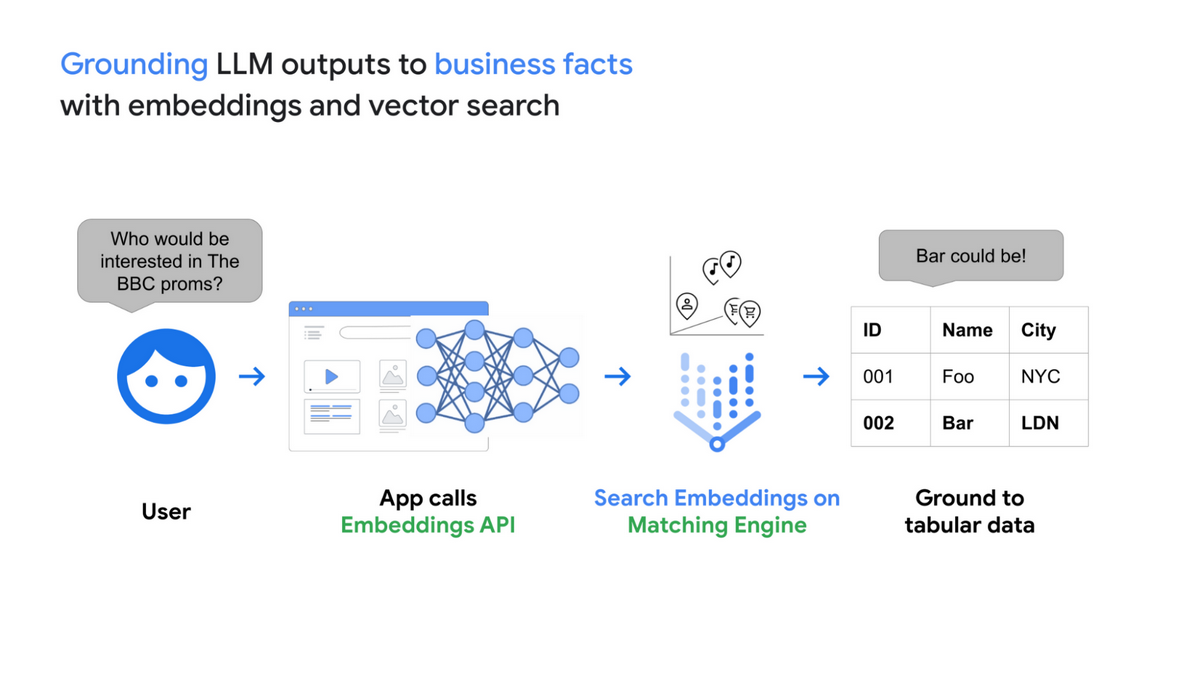
- 文書検索(グラウンディング)にはVertex AI Embeddings for TextとVertex AI Matching Engineを使うことで、外部のビジネスデータから所望の文書を検索可能
- Generative AI Studioという開発環境が用意されており、プロンプトの設計/テスト、基盤モデルのファインチューニングができる
構成図
記事執筆現在(2023年6月14日)GCPにおける、LLMを含む構成例は見当たりませんでしたが、
以下にグラウンディング(=LLMモデルがLLM外部のデータに接続すること)の構成の概略を示します。
おわりに
本記事では、「LLM開発のためにMLOpsチームがやるべきこと」というテーマでLLMのMLOpsに関連する部分を幅広くご紹介しました。
これからLLM開発を検討している方々やMLOpsに携わっている方々の参考となれば幸いです。
【LLMOps】LLMの実験管理にTruLens-Evalを使ってみたの記事も公開されました。合わせてご覧ください。
(2023年9月19日追記)関連して Prompt Flowでプロンプト評価の管理を行う という記事も公開しました。