
はじめに
こんにちは、SAIG/MLOpsチームでインターンをしている吉田です。
LLMの実験管理ツール候補として、TruLens-Evalを検証しました。合わせて、LLMの実験管理についてまとめてみました。
背景と目的
LLMOpsとは
近年、大規模言語モデル(LLM)の性能が飛躍的に向上し、その高度な自然言語処理能力によって様々な領域での課題解決が期待されています。LLMは文章生成、翻訳、要約、質問応答など多岐にわたるタスクにおいて驚異的な成果を示しており、その応用範囲はますます広がっています。
LLMOpsは、LLMを組み込んだアプリケーション開発・運用の効率化を目指すプラクティスです。アプリケーションの種類や開発規模などによってLLMOpsのワークフローは大きく変わりますが、いずれの場合もLLMの性能評価や挙動の解析のために度重なる実験が必要となります。開発過程で行われる実験を適切に管理することは、LLMアプリケーションの開発を効率化させます。
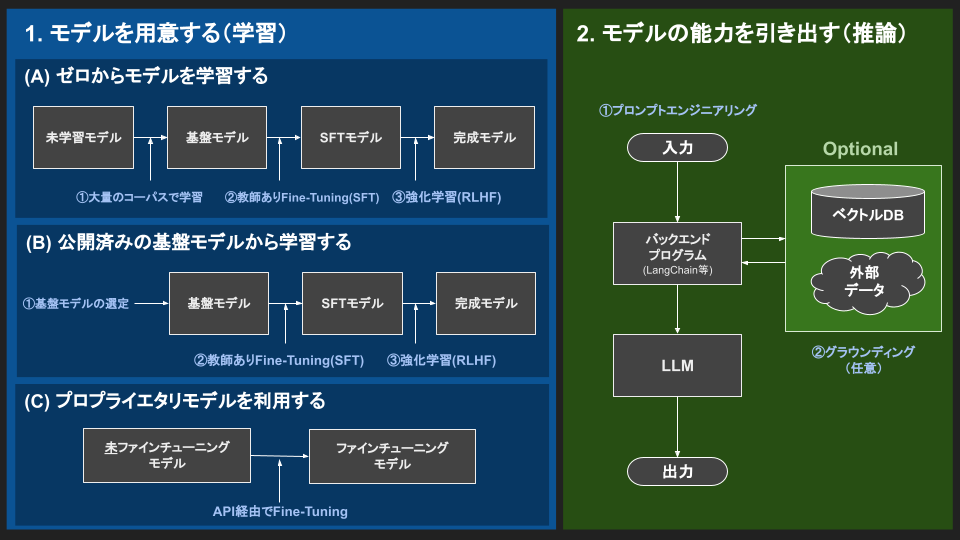
引用:LLM開発のフロー
LLMの実験管理
LLMに対してタスクを実行させるためには、その処理結果を適切に評価し、モデルの性能や振る舞いについて理解する必要があります。そのため、何度も実験を繰り返すことが想定されます。しかし、LLMの性能評価や挙動解析は複雑であり、多くの要因が絡み合うことから、適切な実験管理が必要です。実験管理により、過去の実験設計や結果を簡単にアクセスできるようにすることで、アプリケーション開発の効率を上げることを目指します。
実験管理はこれまでのMLでも実施されてきましたが、MLの実験管理とLLMの実験管理は下記のように異なるため、あらためてやるべきことを整理する必要があります。
- プロンプトエンジニアリングやファインチューニングが主な性能向上方法となること。
- モデル性能の定量的評価が難しく、用いる評価指標の検討や人間による評価が必要となること。
本記事では、プロンプトエンジニアリングにおける実験管理を想定します。
プロンプトとはLLMに与える指示や要求のことを指します。タスクに合ったプロンプトを使用することで、LLMアプリケーションの質の向上が期待できます。タスクに特化したプロンプトの例はこちらにまとめられています。
以下の図は、プロンプトエンジニアリングにおける主な実験の流れです。
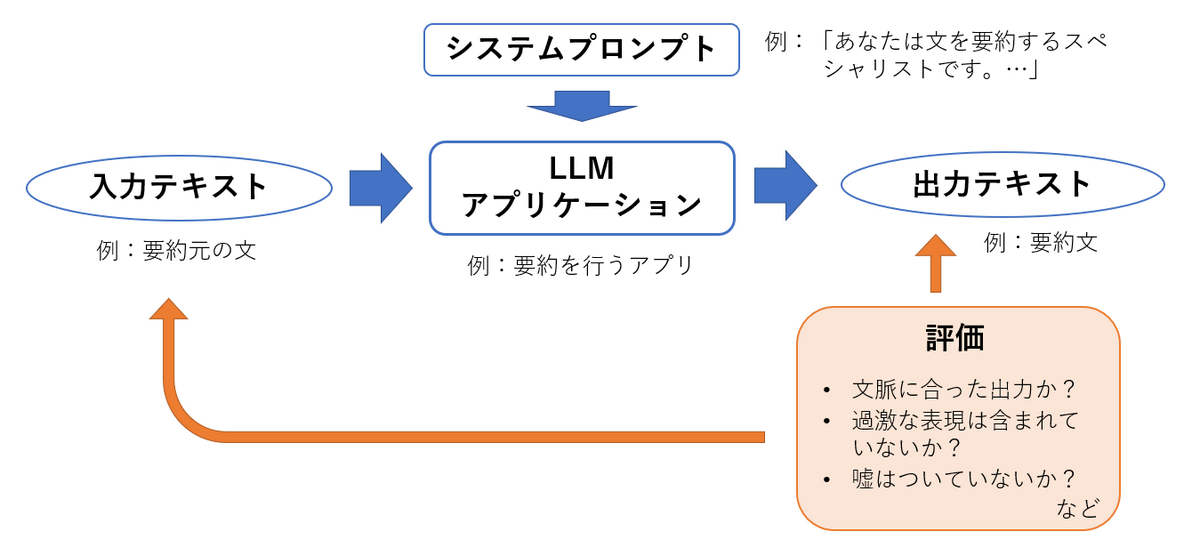
プロンプトエンジニアリングのための実験管理は以下の項目を中心に管理することになると考えます。
(〇:TruLens-Evalで実現可能、△:LangChainと組み合わせることにより実現可能、×:現状単独では対応していないと思われる)
- 再現可能性
- 入力テキスト(〇)
- 出力テキスト(〇)
- システムプロンプト(△)
- モデルのパラメータ(〇)
- コードのバージョン管理(×)
- 実験詳細
- 実行ユーザ(×)
- タイムスタンプ(〇)
- 実行時間(〇)
- エラー文(〇)
- 精度の評価
- ルールベースの評価スコア(〇)
- LLMによる評価スコア(〇)
- 人間による評価スコア(〇)
- 人間によるテキストレビュー(×)
検証概要
Python向けのOSSであるTruLens-Evalを使ってみました。TruLens-Evalを導入することで、LLMの実験管理に必要な情報を自動的にトラッキングし、ブラウザを通して簡単に閲覧できるようになります。また、実験ごとに評価方法を設定することで、実行と同時に評価処理を行い結果を保存してくれます。
TruLens-Eval
TruLensは大規模言語モデルを含むニューラルネットの開発およびモニタリングを行うためのツールセットを提供しています。TruLensは、LLMベースのアプリケーションを評価するTruLens-Evalと、ディープラーニングモデルの説明可能性を実現するTruLens-Explainの2つのツールから構成されます。今回はLLM実験管理を目的とするため、TruLens-Evalについて調査しました。
図はTruLens-Evalの概要について説明したものです。
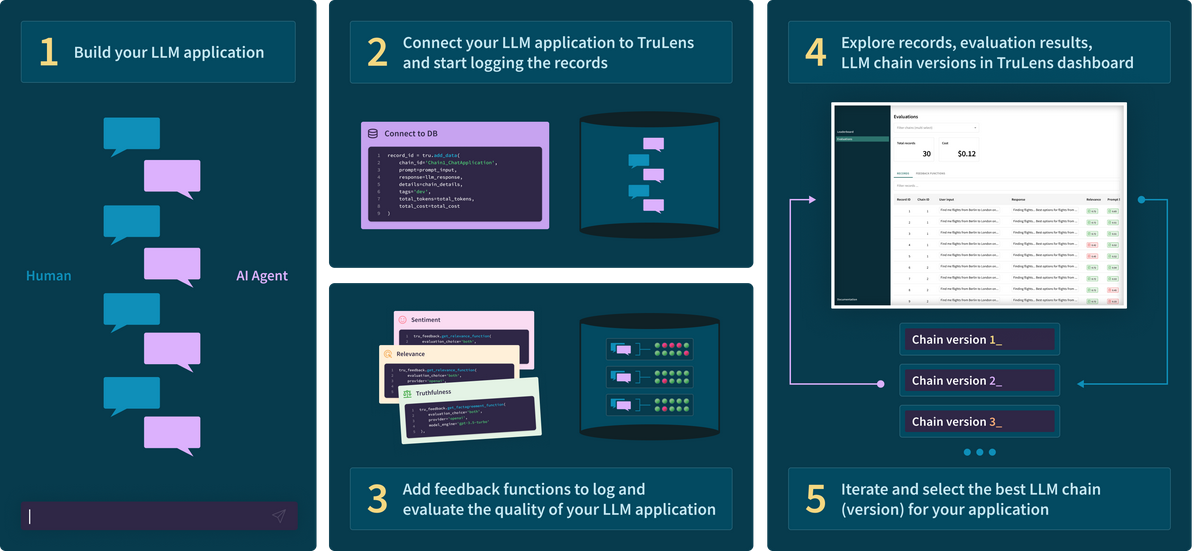
引用:Evaluate and Track your LLM Experiments: Introducing TruLens
- LLMアプリケーションを作成する。
- LLMアプリケーションをTruLensに接続し、ロギングを行う。
- feedback関数をログに追加し、LLMアプリケーションの性能を評価する。
- TruLens dashboardを使ってレコードや評価結果LLM chainのバージョンなどを確認する。
- 一番性能の良いLLM chainを得る。
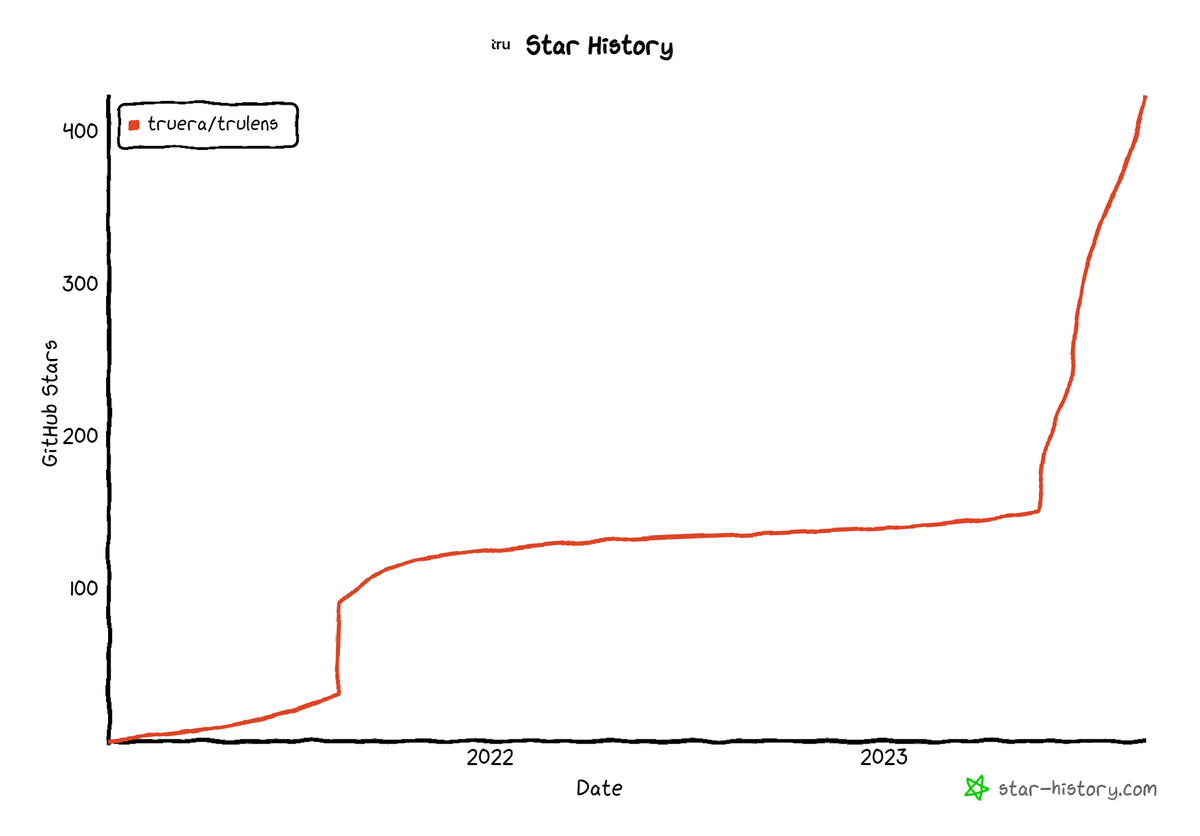
昨今LLM開発が注目を集めているため、TruLens-EvalのGitHubリポジトリのスター数は現在急増しています。
なぜTruLens-Evalか
TruLens-EvalはUIの見やすさやシステムの軽量さ、GitHubのスターが増加傾向にあるOSSである点などの特徴から調査の対象としました。
TruLens-Evalは、LLMアプリケーションの性能に対する評価をサポートし、実験管理の一部として保存します。プロンプトエンジニアリングに必要と考えられる実験管理に主な焦点を置いたツールです。
タスクによって最適な評価指標は変化します。また、最適な評価指標は定まっておらず、どのような指標を用いればよいのかという検討も必要になります。TruLens-Evalは実験評価について整理されたシステムを提供しているため、評価指標の検討も円滑に進めながらより質の高いアプリケーション開発を目指すことができると考えられます。
TruLens-Evalでできること
- feedback関数を利用することにより、実験の評価を円滑に実行できます。feedback関数とは、LLMアプリケーションが生成するテキストを分析し、LLMアプリケーションの性能をスコアリングします。
- LLMアプリケーションを実行するだけで、feedback関数の実行やLLMの利用状況のトラッキングを自動で行い、データベースに保存できます。
- ブラウザから実験結果を閲覧でき、実験結果の分析をサポートします。
- データベースには後から情報を追加できるため、人による評価などを管理できます。
ブラウザから閲覧できる情報について説明します。
- LLMをアプリケーションとして扱い、アプリケーション毎に実験管理をできます。一覧できる情報は次の通りです。
- 実験回数
- 実行時間の平均
- 実行によるコスト(OpenAIモデルのような従量課金の場合)
- 合計トークン数
- 評価スコア
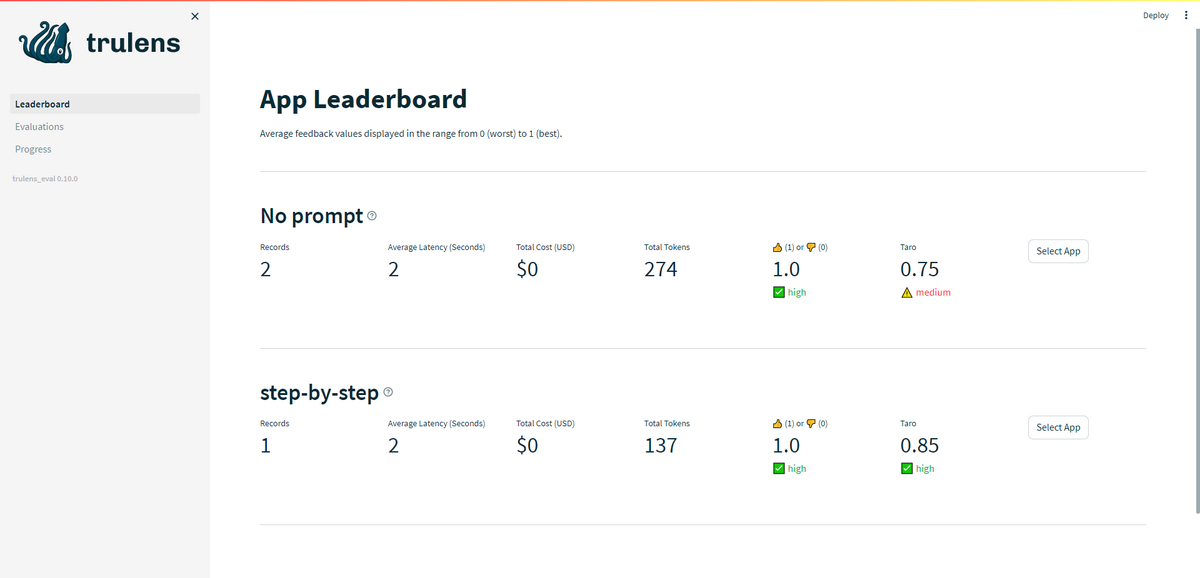
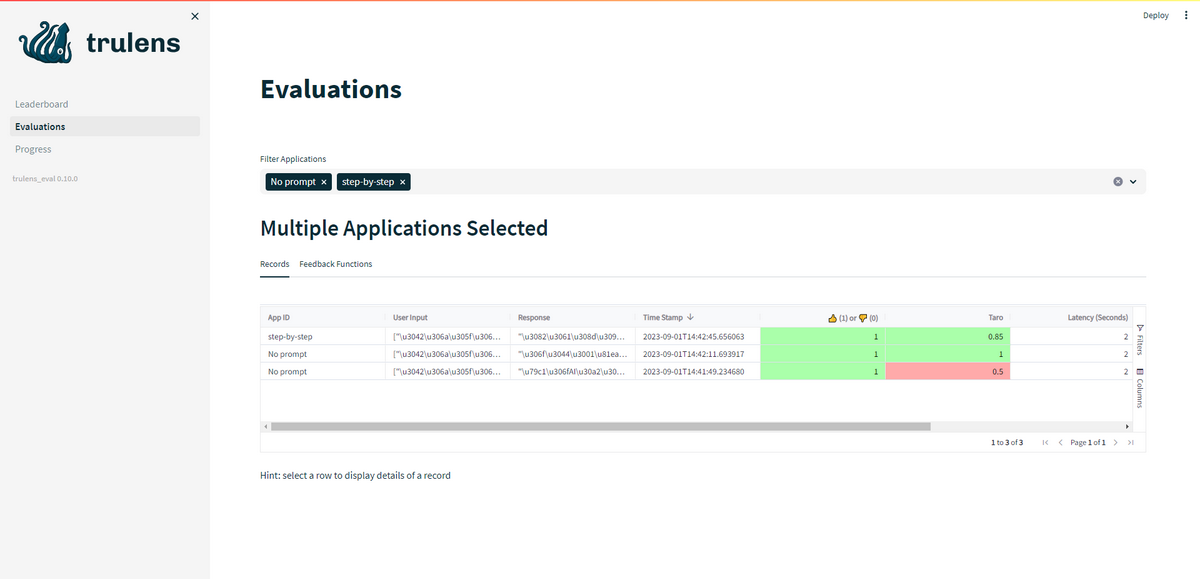
- 実験の詳細をテーブルとして表示できます。アプリケーション名によるフィルタリングや評価スコアによる並び替え機能などが用意されています。比較できる情報は次の通りです。
- 入力プロンプト(現在日本語(Unicode)に未対応)
- 出力結果(現在日本語(Unicode)に未対応)
- 実行時間
- タイムスタンプ
- 合計トークン数
- タグ
- 評価スコア(色付き) など
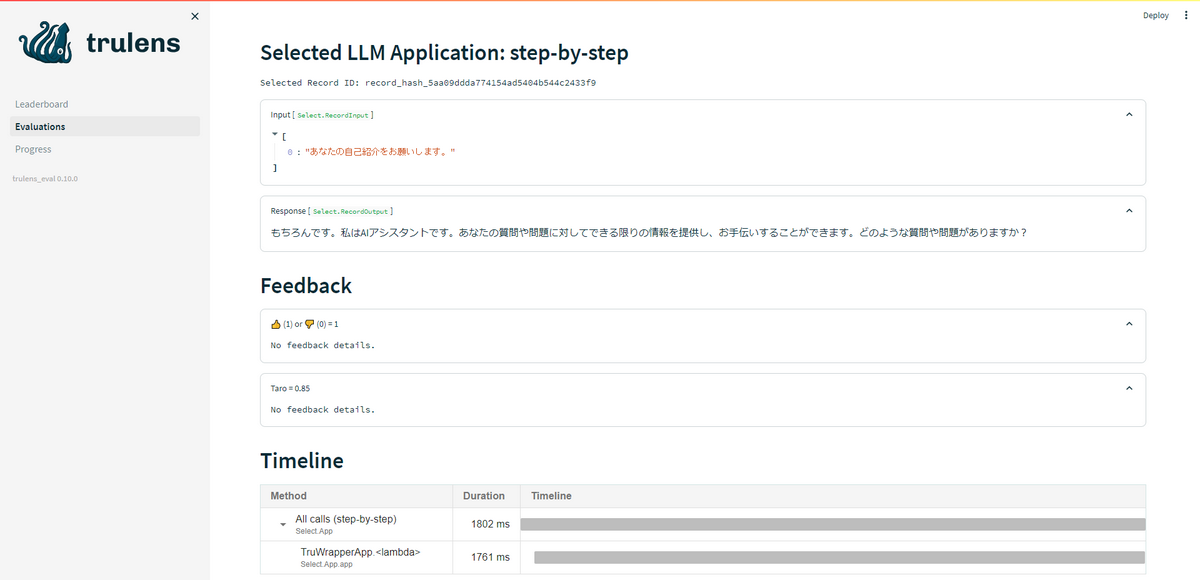
- 実験毎に詳細を確認できます。
- 入力プロンプト
- 出力結果
- コンポーネント毎の実行時間
- 評価スコア など
また、LangChainを用いた場合は、モデル毎の入出力とハイパーパラメータを確認できます(未検証)
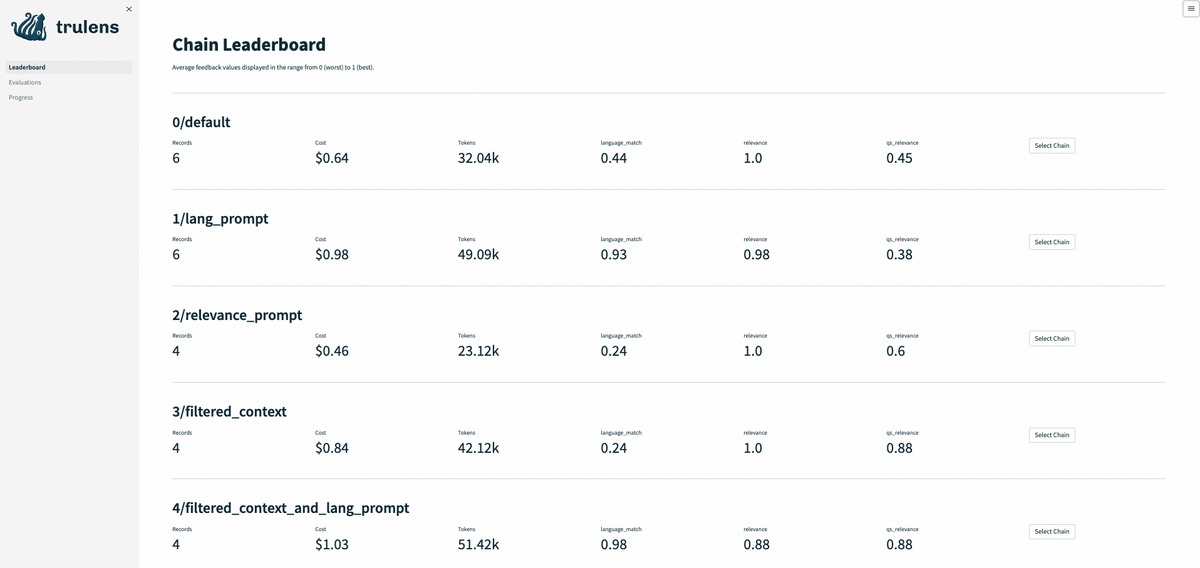
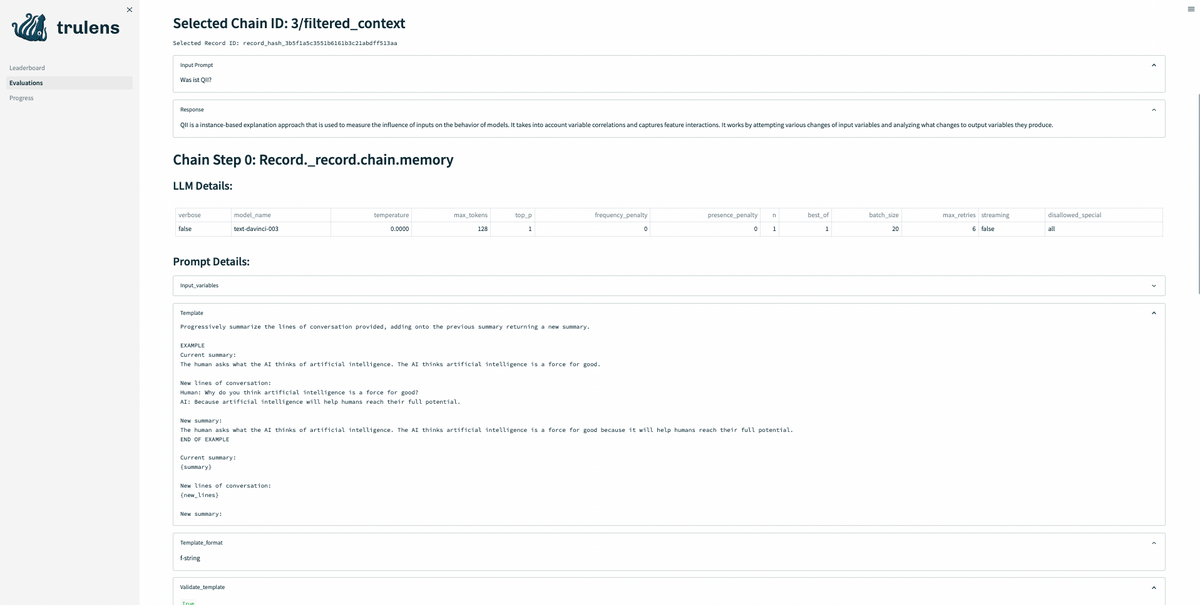
TruLens-Eval & LangChain(未検証)
TruLens-EvalはLangChainの利用をサポートしているため、複数のモデルにより構成されるLLMアプリケーションについてもトラッキングが可能となります。
LangChainを導入することで、モデルパラメータやシステムプロンプトの保存だけでなく、各LLMコンポーネントの評価についても同時に処理を行うことができます。単一のLLMのみを用いる場合においても、システムプロンプトを管理できることからLangChainの利用が推奨されると考えられます。
TruLens-Evalの利用手順
TruLens-Evalの利用手順の説明します。ここでは、システムプロンプトを含めたLLMアプリケーションの評価のため、実験を行う状況を想定します。
LLMアプリ(fix) → システムプロンプト(fix) → 入力プロンプト → 実行&評価 → 入力プロンプト → …
LLMアプリの関数化
はじめにLLMアプリの定義を行います。文字列を引数とする、文字列を返す関数を定義します。
例) OpenAIのモデルを使った簡単なアプリケーション
def llm_standalone(prompt): |
LLMアプリのラッピング化と実行
定義したLLMアプリにアプリ名やフィードバック関数の情報を付与する形でラッピング化します。その後作成したインスタンスでLLMアプリの実行を行い、結果を取得します。このとき、実験管理に必要な情報はトラッキングされ、データベースに保存されます。
例) 定義したllm_standaloneのラッピング化と実行
prompt_input="テストするプロンプトを入力" |
ブラウザから閲覧
シェルで以下のコマンドを実行すると、Webサーバが立ち上がりブラウザから実験結果を閲覧できます。
trulens-eval |
人による評価について
Truクラスを利用することで、データベースに任意の情報を追加・削除したり、Webサーバの起動などができます。そのため、後から評価の追加が可能です。これを応用することで、人による評価について検討できます。以下は考えられる運用例です。
- 開発者毎に実験結果に対する評価を行い、チームによるレビューとして管理する。
- 評価指標(根拠性、関連性、毒性など)毎に開発者が評価を行い、統計する。
feedback関数
入力プロンプトや出力結果に対して評価を行うfeedback関数を定義することで、実験の評価を自動的に行うことができます。TruLensはOpenAIやHuggingFaceのモデルを用いたfeedback関数を既に用意しているため、基礎的な評価については簡単に導入できます。
feedback関数の実装
まず、Providerクラスを継承する形で、feedback関数の定義を保持するクラスを作成します。Providerクラスのメンバーメソッドとしてfeedback関数を定義します。
from trulens_eval import Provider, Feedback |
feedback関数は以下の形式で実装します。str型の引数を1つまたは2つとり、戻り値として0.0~1.0のfloat型で返します。ここで関数定義に使われる関数名および引数名は内部的に保存されています。特に、関数名が評価カテゴリの識別名として用いられます。また、多出力に関してもサポートされています(参考)。
def my_feedback(self, text1: str, ...) -> float: |
feedback関数が実装されたProviderクラスをインスタンス化します。その後、引数に関する情報を付与する形で、feedback関数をラッピングします。また、多出力の場合はここで統計処理方法を設定できます(詳細)。
my_feedbacks = MyFeedbacks() |
前述の「LLMアプリのラッピング化と実行」に加える形で、feedback関数を複数設定できます。これにより、実行時に自動的にfeedback関数も実行され、結果が記録されます。また、後から実験結果に対してfeedback関数を実行することも可能です(詳細)。
basic_app = TruBasicApp(llm_standalone, app_id="my_function", feedbacks=[input_function, output_function, inout_function]) |
用意されているfeedback関数
TruLens-EvalはいくつかのOpenAIやHuggingFaceが提供しているモデルやサービスを利用したfeedback関数をいくつか用意しています(詳細)
ここではfeedback関数の例としていくつか紹介したいと思います。
- Relevance(関連性)
OpenAIのChatCompletionを用いて、2つのテキスト(入力と出力)の関連性を数値評価します(スモークテストはこちら)。また、与えられたコンテキストとユーザの質問文がどの程度関連しているか判定するfeedback関数も用意されています(qs_relevance)。
以下はRelevanceがChatCompletionに与えるシステムプロンプトです。
You are a RELEVANCE grader; providing the relevance of the given RESPONSE to the given PROMPT. |
- Moderation(節度)
ModerationはOpenAIが提供しているAPIであるopenai.Moderationをラッピングしたものになります。これを用いることで、差別的、暴力的、性的などの評価軸で、テキストを数値評価できます。
ユースケース
以上の機能を踏まえて、実験管理の使用例について検討しました。
良いプロンプトの検討
各評価指標における良いプロンプトは何か、整理して検討することに役立ちます。評価指標については、ルールベースなものからLLMを用いた評価、人による評価についても対応できます。また、あらかじめ評価指標を決定する必要はなく、後から遡って実験結果を評価することもできます。
実験結果を各評価指標によって並べ替えることができます。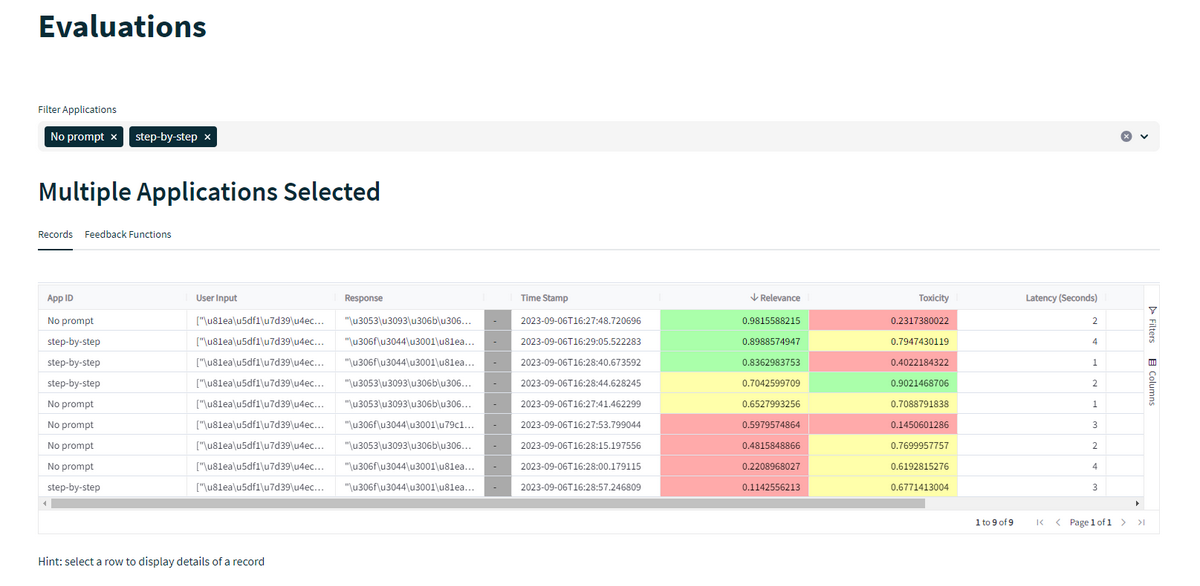
各評価指標のヒストグラムを作成できます。アプリケーション名によるフィルタリングができます。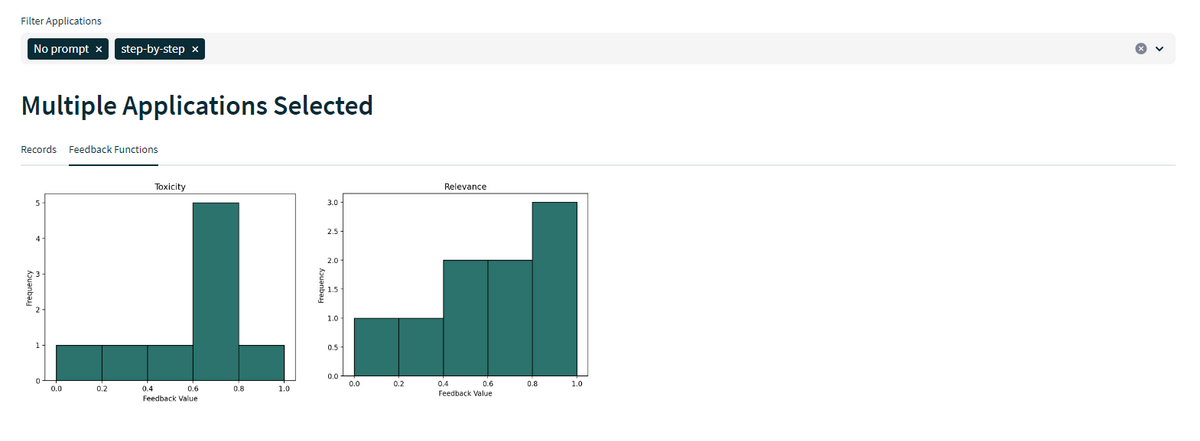
各アプリケーションの評価スコアの平均値を一覧できます。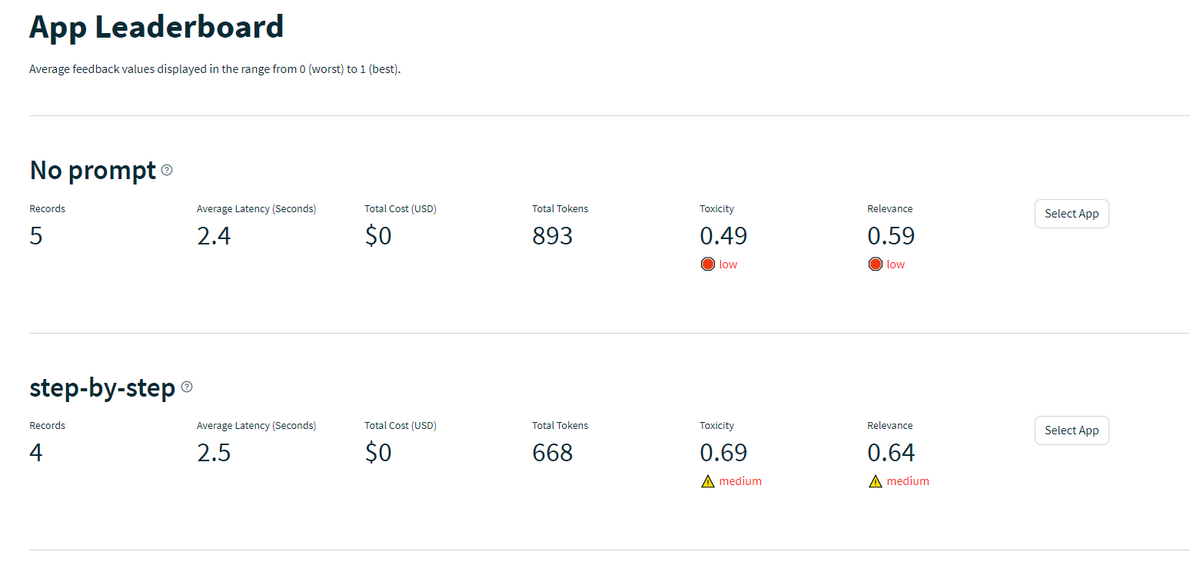
新しい評価指標の検討
- feedback関数の実装に関するテンプレートがあるため、検討したfeedback関数の確認や新たなfeedback関数の追加などが簡潔になると思われます。
今後に向けて
TruLens-Evalの懸念点
TruLens-Evalを本格導入する際は、下記懸念があるため、対応が必要かもしれません。
- 実験結果のテーブル表示に関して、日本語(Unicode)対応していない部分がある。(ただし、issueが立っている)
- 階層的な管理ができない。
- Appの名前に工夫
- モデル毎にデータベースを変える
- ドキュメントが少ない。公式ドキュメントの情報も十分とは言えない。(Slackのコミュニティがあるため、そこに情報があるかも)
- ブラウザUIによる情報追加がサポートされていない。(人による評価がやりづらい)
- ユーザカスタムな実験情報を含める柔軟性がない。
- タグやfeedback関数を使った工夫が必要
- 同一入力プロンプトでも揺らぎがあるため、複数回実行して統計を取りたいがサポートされていない。
- 評価方法にLLMを利用している場合、feedback関数についても揺らぎが生じると考えられる。
他の候補について
他にもLLMの実験管理として有力な候補があるので、検証していきたいです。
- MLflow
- MLflow.evaluate()を拡張することで、LLMOpsに対応(未調査)
- Weights & Biases
- LLMOps用にW&B promptを公開。
- TruLensでサポートされているようなトラッキングシステムを利用できる。
- MLOpsのシステムと組み合わせることでLLMのファインチューニングの管理も可能。
関連して Prompt Flowでプロンプト評価の管理を行う という記事も公開しました。