はじめに
本記事は、プレビュー版のAzure Prompt Flowを扱っています。
操作画面等の内容は2023年9月13日現在の内容であることにご注意ください。
こんにちは、SAIG/MLOpsチームでアルバイトをしている板野です。
今回は、AzureのPrompt Flowを使ってLLMに入力するプロンプト評価の管理を行います。
プロンプト評価の管理を行いたい背景として、以下のような状況が考えられます。
- チーム内で我流のプロンプトがはびこっている
- プロンプト・出力・評価値をスプレッドシートに手入力するのが煩わしくなってきた
- 良いプロンプトとその評価結果が結びついておらず、「あのプロンプト良かったけどどこ行った?」となる
このような状況を改善するため、客観的・定量的なプロンプト評価を行い、管理していきたいところです。
すなわち、 プロンプトの実験管理 が行いたいのです。
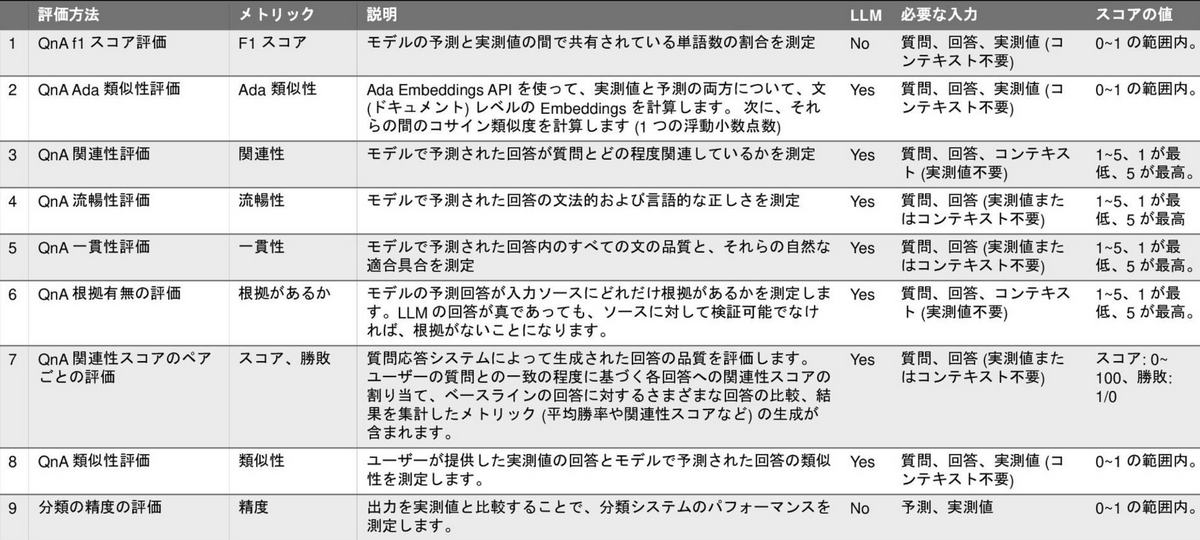
例えば、複数の評価指標を自動で算出し、以下のような表形式にして任意の評価指標に対してソートできればプロンプトの実験管理の効率が向上します。
| プロンプト | 評価指標A | 評価指標B | 評価指標C |
|---|---|---|---|
| プロンプト01 | 9.6 | 8.9 | 1 |
| プロンプト02 | 8.5 | 7.8 | 1 |
| プロンプト03 | 6.3 | 7.7 | 0 |
今回はこのような表を自動で得られるようにすることを目標とします。
LLMには、追加学習による精度の改善だけでなく、入力するプロンプトの改善による精度向上の余地があります。
今回は、通常の機械学習の実験管理とは異なり、LLM, プロンプトの2変数のうち、LLMを固定します。仮に精度が向上した場合、それが「LLMを改善したから」なのか「プロンプトを改善したから」なのかが分からなくなってしまうからです。
本記事ではプロンプトという用語を「システムプロンプト」の意味で使っています。すなわち、(ユーザーからの)質問文は最終的にはプロンプトに含まれることにはなりますが、ここでは質問文をプロンプトとは別の要素として扱います。
プロンプトの評価
プロンプトの評価に必要なもの
以下の4つが全て揃えば大体どんな評価もできます。
最低限*印の項目があればそれなりの評価ができます。
- 質問文*
- LLMの回答*
- 理想の回答
- コンテキスト
プロンプトの評価指標例
プロンプトの評価指標は、原則「プロジェクト・タスクによりけり」です。
ここでは評価指標を定めるための参考として、いくつか事例を集めたので以下にご紹介します。
事例(1): Prompt Flowの組み込み評価指標
AzureのPrompt Flowにはいくつか組み込みの評価指標が用意されています。
このうちの大半はLLMが評価を下す仕組みとなっています。
例えば、「以下に質問と回答の対を示します。回答は質問の内容に沿っているか10段階で評価してください」といったプロンプトを入力するとLLMが評価値を返してくれます。
LLMベースの評価は、プロンプト次第であらゆる評価結果を数値として出力してくれるでしょう。
しかし、LLMは確率モデルであるという特性上、同じ入力をすると必ず同じ評価値が返ってくる保証はありません。何度か同じ入力をして得られた評価値の統計(平均値や中央値など)を取ることで、多少はLLMのばらつきを抑えられる可能性があります。
[参考]
- Azure Machine Learning Prompt flow 評価メトリクス解説
- Azure Machine Learning の Prompt flow の評価メトリクス紹介 ― ChatGPT どう評価する?
事例(2): Pythonのみで実装できる独自定義の評価指標
こちらの事例では、Prompt Flowを使ってPythonのみで実装できる評価指標を実装しています。
「決算書のPDFから必要なデータをJSON形式で抽出する」タスクに対し、以下の2つの評価指標を定めています。
correct_keys_percentage: 正しく抽出できたキーの割合correct_values_percentage: 抽出したキーのうち、正しく抽出できた値の割合
[参考]
Prompt Flowでプロンプト評価の管理を行う
取り扱うタスク
今回は文書検索を伴う質疑応答タスクを扱います。
文書検索を伴う質疑応答用のフロー(標準フロー)は実装済みであるとします。文書検索を伴う質疑応答用のフローを作るにはこちらの記事が参考になりますので、ご参照ください。
どんな内容であれ、「質問文」に対する「LLMの回答」が得られる標準フローが作成できていればOKです。
この標準フローのプロンプトを評価するために、評価フローと呼ばれるフローを別途実装していきます。
評価指標
文書検索を伴う質疑応答フローの評価指標として以下の3点を定めます。
- (A)
consistency: 質問の内容に沿った回答ができているか(1~10の整数値) - (B)
easiness: 簡単な表現で分かりやすいか(1~10の整数値) - (C)
has_source: ソースの参照を行っているか(2値)
(A)(B)は、先の事例(1)を参考にLLMベースの評価指標を作成します。
(C)については、先の事例(2)を参考にPythonのみで実装できるものを作成します。
Prompt Flowでプロンプト評価の管理を行う
(1)評価フローを実装する
ここからは実際にPrompt Flowを使ってプロンプト自動評価の仕組みを実装していきます。
Prompt Flowでは標準フローではなく、評価フローと呼ばれるフローを実装していきます。
今回実装した評価フローの概略です。
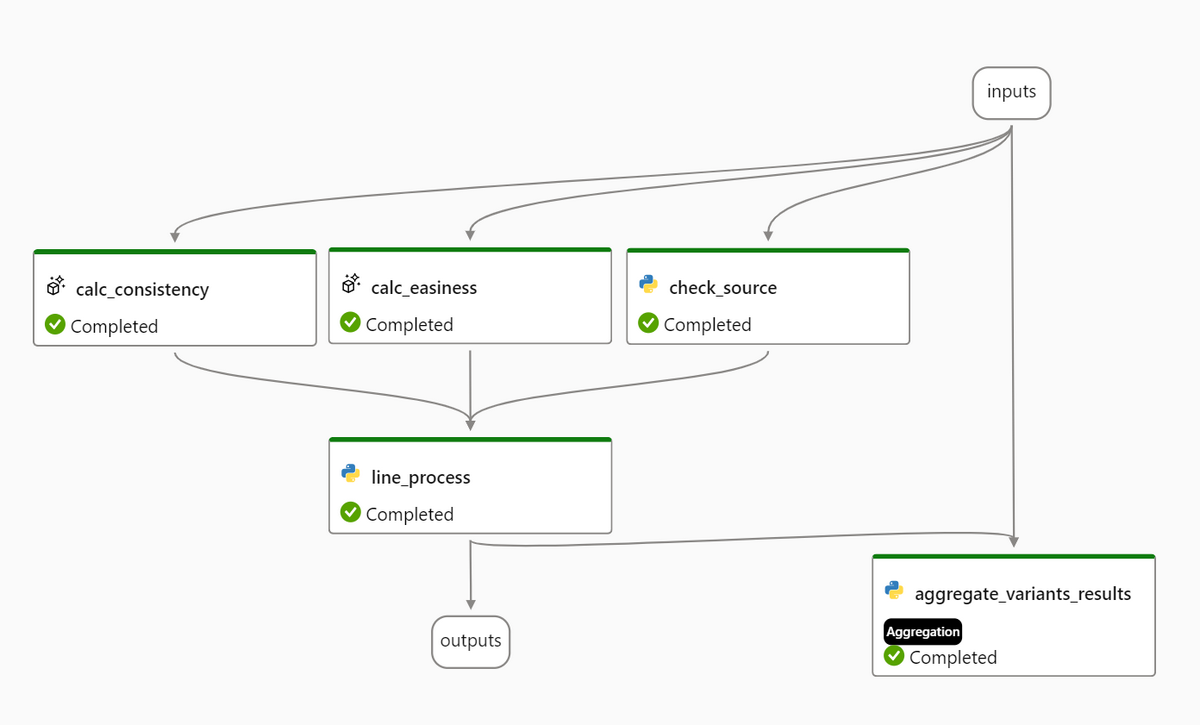
以下、入出力および各要素について説明します。
入力(inputs)
入力は以下のように設定します。値は任意の値でOKです。
questionは質問文、answerはLLMの回答を表します。

line_numberとvariant_idについてはAzureのドキュメントに以下のような記載がありました。
標準フローと違い評価フローは特殊なので、これらの入力もを用意する必要があるようです。
長くなるのでlineとvariantについての説明は省略しますが、詳細は以下のソースをご覧ください。
標準フローとは異なり、評価方法はテストされているフローの後で実行され、複数のバリアントが含まれる場合があります。
したがって、評価では、出力の生成元になったデータ サンプルやバリアントなど、一括テストで受け取ったフロー出力のソースを区別する必要があります。
一括テストで使用できる評価方法を構築するには、line_number と variant_id(s) の 2 つの追加入力が必要です。
calc_consistency
LLMを使って「質問に対する回答の一貫性」を評価する部分です。質問文とLLMの回答を入力として受け取り、評価値を1から10の10段階で返します。
プロンプトの中では、いくつか例示(Few-shot Learning)をしています。
実装は以下画像の通りです。
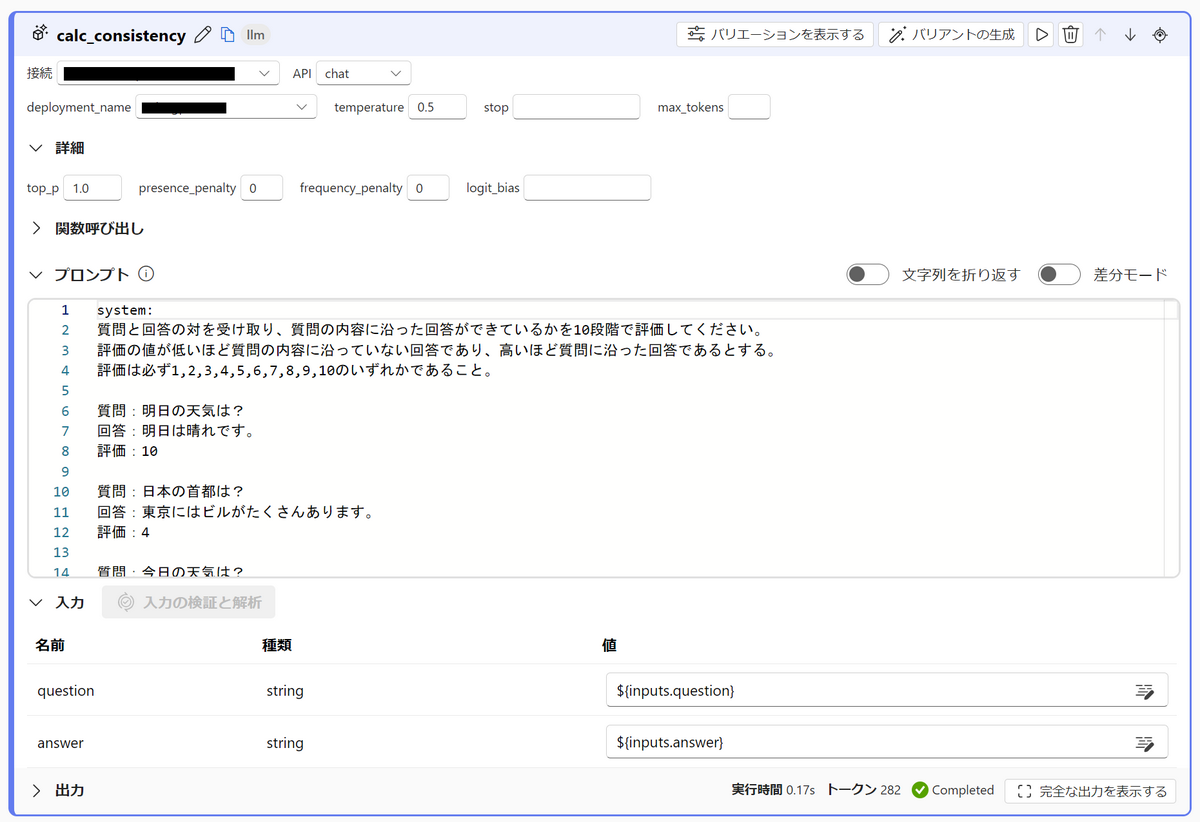
プロンプト例
system: |
calc_easiness
LLMを使って「回答の分かりやすさ」を評価する部分です。質問文とLLMの回答を入力として受け取り、評価値を1から10の10段階で返します。
実装はcalc_consistencyと同様です。
.png)
プロンプト例
system: |
has_source
「回答がソース(文書)を参照できているか」を評価する部分です。質問文とLLMの回答を入力として受け取り、できていれば1, できていなければ0を返します。
アルゴリズムは非常に簡単で、回答に”source”という文字列が含まれていればソース参照できていると判定します。
以下のようにPythonコードのみで実装しています。
※手順解説のため、サンプルとして簡易なロジックを実装
.png)
コード例
from promptflow import tool |
line_process
calc_consistency, calc_easiness, has_sourceの各出力を集約し、1つの辞書型として出力するPythonコードです。
.png)
コード例
from promptflow import tool |
aggregate_variants_results
Variant毎に結果を集約するPythonコードです。
今回はVariant機能を使っていませんが、評価フローでは、集約(Aggregation)を行うための特別なPythonコードを定義する必要があるので公式ドキュメント(英語)を参考に、以下のように実装しました。
.png)
コード例
from typing import List |
出力(outputs)
出力は以下のように設定します。

最後に右上の「保存」を押して評価フローの作成は完了です。
この時点で、「質問文」と「LLMの回答」を入力した際、consistency, easiness, has_sourceの3つの評価指標の値を出してくれる評価フローが出来上がりました。
(2)評価フローを実行する
それでは、実際に評価を行っていきます。
文書検索を伴う質疑応答用のフロー(標準フロー)の編集画面に入り、「一括テスト」を押します。
以下の画面では一括テストの設定を編集します。一括テストとは、複数の質問文を一括で受けつけて回答を出力してくれる機能です。
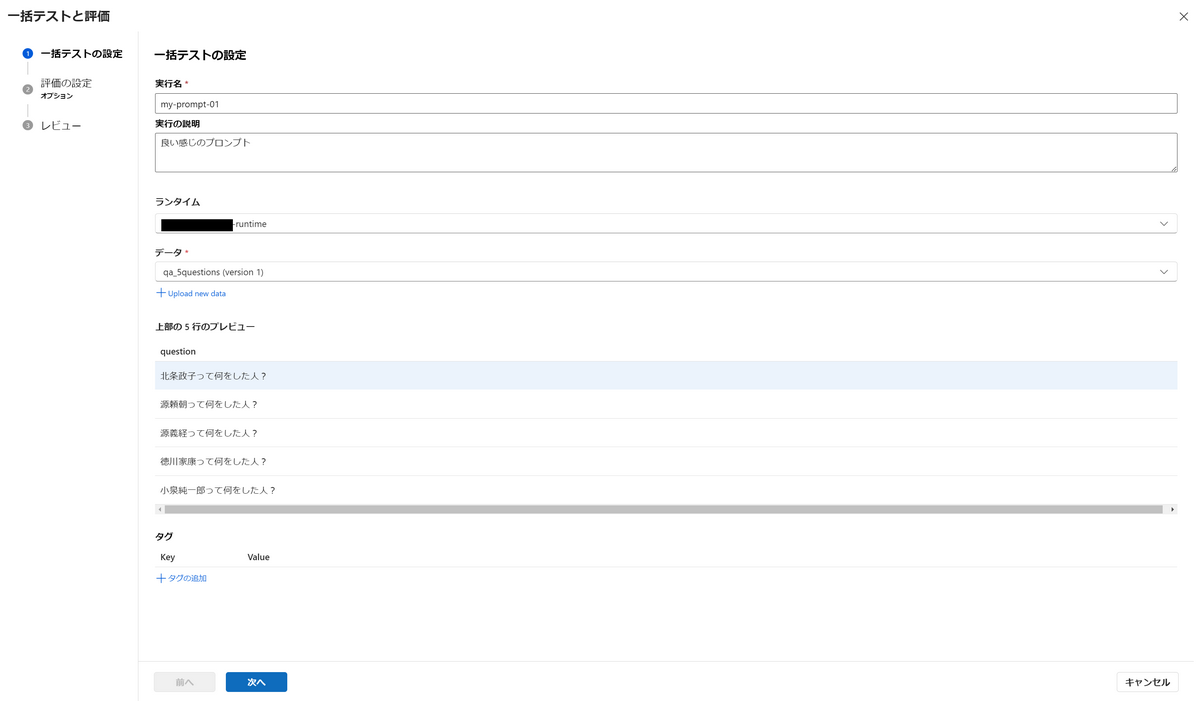
データは自分で以下のようなCSVファイルを作成し、アップロードします。
下例のようにあらゆるケースの質問文を用意したり、同じ質問文を複数記載して結果(評価値)の平均をとってLLMによるばらつきに対処したりもできます。
question |
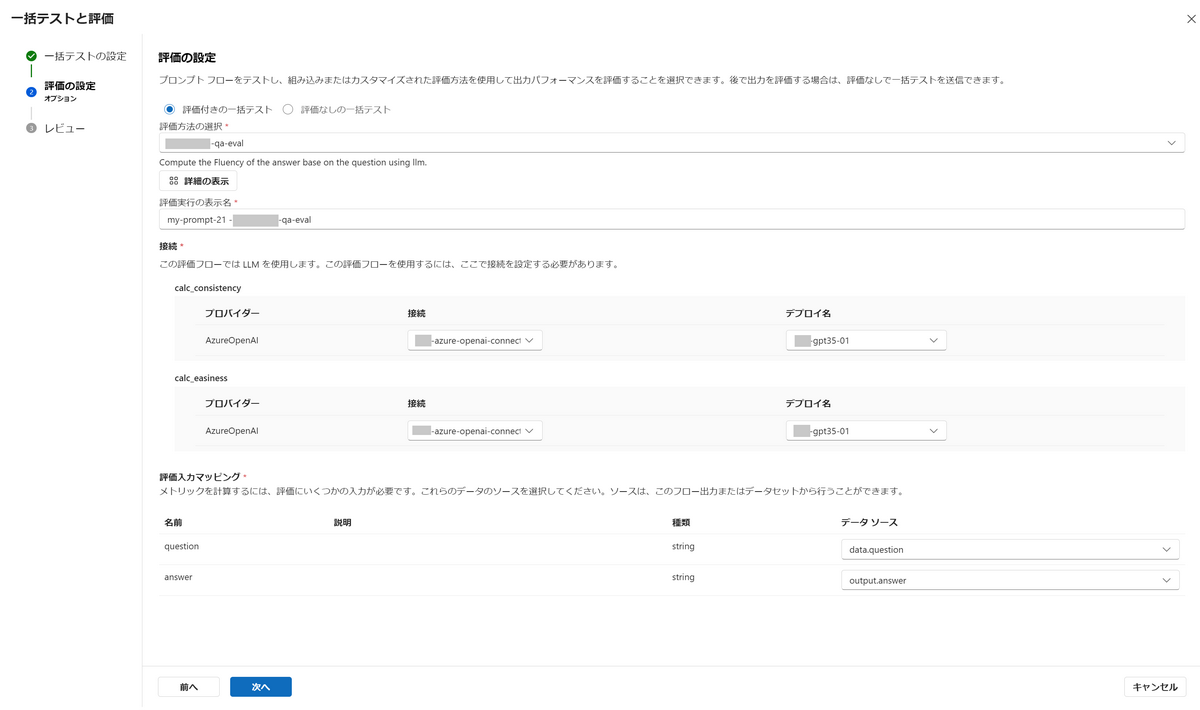
続いて、評価の設定を編集します。
評価方法の選択では、先程作成した評価フローを選択します。
評価入力マッピングの部分について、questionのデータソースはdata.questionを選択します。これは一括テストの設定でアップロードしたCSVファイルのquestion列のデータに相当します。answerのデータソースはoutput.answerを選択します。これはLLMからの出力に相当します。
「次へ」を押すとレビューの画面が出ますが、最終確認の画面なので問題なければ「送信」を押します。
別のプロンプトで実行したい場合は、プロンプトを変えて以上の操作を繰り返します。
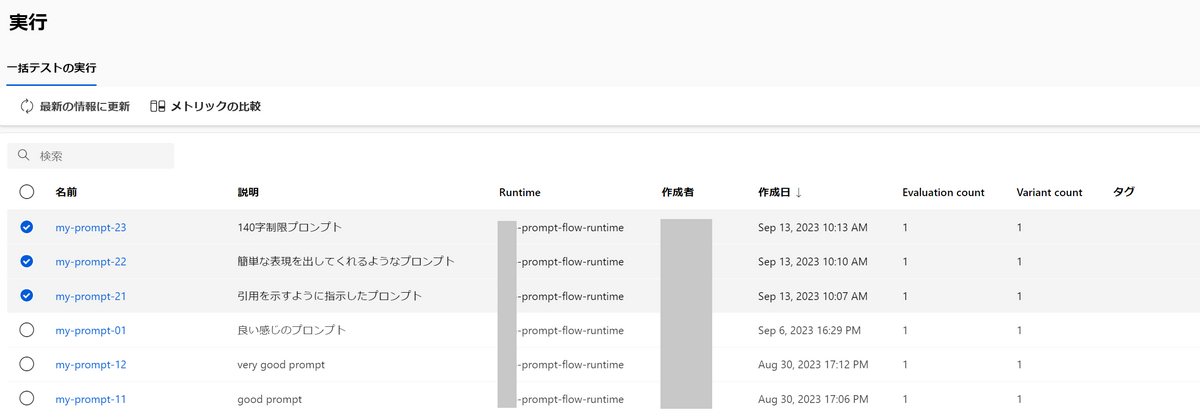
フロー編集画面上部の「一括実行の表示」を押すと過去の実行が見られます。

過去の実行は以下のようにリスト化されています。
ここで、いくつかの実行をチェックボックスで選択し、「メトリックの比較」を押してみましょう。
すると、以下のように各実行に対する評価指標を比較できます。
もちろん、任意の評価指標についてソートすることもできます。
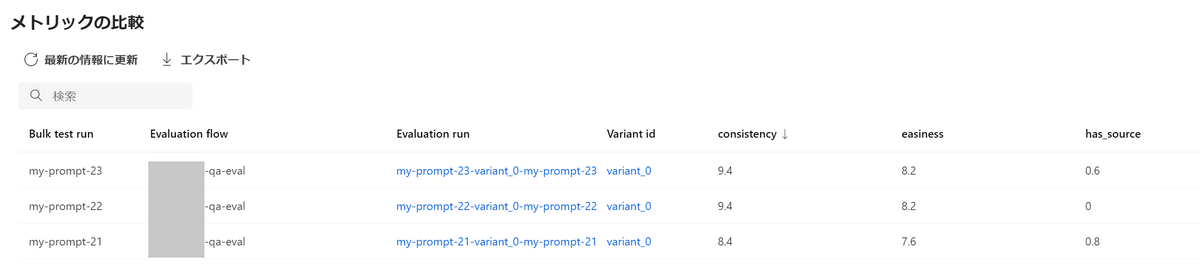
以上で今回目標としていたことが達成できました。
補足
本来であればVariant機能を使って複数のプロンプトを一括で評価したいところです。
しかし、Variant機能を使って実行しようとしたところ、記事執筆当時(2023年9月13日)では下図のように列方向に展開されてしまい、結果の比較が行いにくいと感じました。

このため今回はVariant機能を使わず、プロンプトを変える毎に逐一実行する方法を取りました。
Prompt Flowのプレビュー版が終わり完成版が登場する頃には改善されているかもしれないので、今後に期待です。
おわりに
本記事ではPrompt Flowでプロンプトの実験管理を行う方法をご紹介しました。
LLMの開発や運用に携わっている方々の参考となれば幸いです。