概要 Dify (DeFiではない)と Anthropic Claude (OpenAI でも OpenRouter 経由の何かでもOK)を使って簡単に生成AIアプリケーションを構築する方法をご紹介します。
前編:ノーコードで生成AIアプリケーションを構築するチュートリアル
後編 :自作プログラムで機能追加して生成AIの指向性と精度を高めるサンプル
の2本立ての予定です。
対象読者
生成AIに興味があるがまだチャット以上の利用法を見出せず手を出せていない方
お試しに手軽に生成AIアプリケーションを構築してみたい方
特にOpenAIに月額費用に躊躇っている方
前提知識・環境
Docker (Docker Compose)。Windows なら Docker Desktop。後編ではホスト名 host.docker.internal を使用します
“時々生成AIをチャットで活用している”程度のプロンプト操作の知識
取り上げない話題 何が実現可能になるかを示唆する事にフォーカスするので、手段は深堀しません。例えばRAGには触れません。
準備 Anthropic API のAPIキーを取得し、Difyをローカルで起動します。
サービスとして提供されている https://dify.ai/ を使ってもいいですが、APIキーを預けるのは何となく不安なので&後編で便利なのでローカルで話を進めます。
Anthropic API でAPIキー取得 https://console.anthropic.com/settings/plans で電話番号認証後の初回だけ5ドル分の無料お試し枠が貰えます。既に OpenAI や OpenRouter に課金されている方はそちらでも良いですが以下でモデルを指定する箇所では適宜読み替えてください。
モデルによりトークン当たりのクレジットの消費量が異なりますが、コスト軸での選択の目安は以下の通りです。
Haiku:ガンガン使っても殆ど減らないので感触を探る間は当面これで
Sonnet:試行錯誤していると目に見えて減っていくので残高注意
Opus:ごっそり減るのでお試し中の常用は非推奨。比較検証したい時のワンポイントで
もうAnthropicの無料枠を消化してしまった人は https://openrouter.ai/ が使えるかもしれません。入金しなくても謎に0.2ドル程度をタダで使わせてくれたり、仮想通貨(PolygonネットワークのUSDC)決済が出来たりします。
Difyセットアップ インストール git clone https://github.com/langgenius/dify するか、https://github.com/langgenius/dify/tree/main/docker の docker-compose.yaml と nginx ディレクトリをダウンロードして、 docker-compose.yaml のある場所で docker compose up -d します。
実行時のディレクトリ直下にボリュームディレクトリ volumes が作成されます。
nginx がポート 80 で起動するので空けておくか services.nginx.ports を適当な値に変えてください。
初期設定 http://localhost/ にアクセスすると初回は「管理者アカウントの設定」画面が表示されます。メールアドレスは適当な値で大丈夫ですが次のサインイン画面で使うので何を入れたかは忘れないでください。undefined になったりしてしまうので出来れば英語の方がお勧めです。
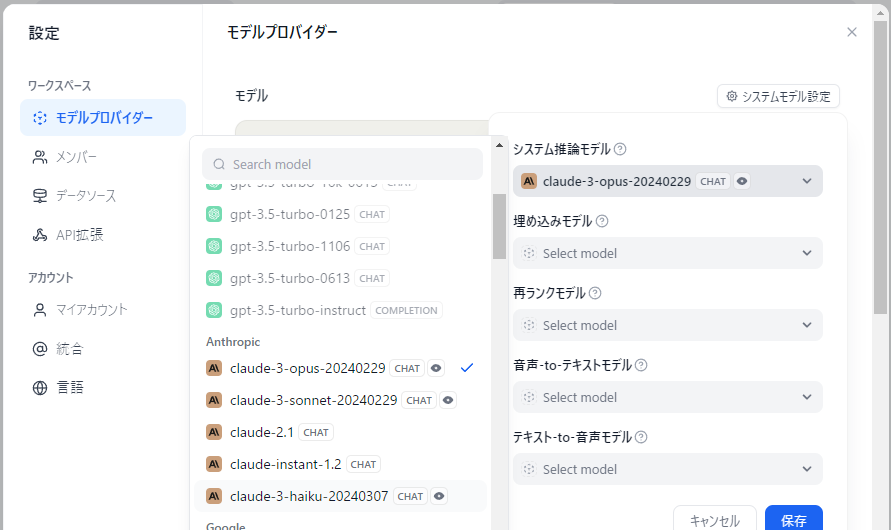
サインインしたら、右上のアカウント名をクリックして設定→モデルプロバイダー→Anthropicにマウスオーバーしてセットアップ、と進んでAPIキーを入力します。そのままだとシステムモデルに Claude 3 Opus が使われてしまうので Haiku を選択します。寄稿時点では claude-3-haiku-20240307 というモデル名でした。ここでClaudeシリーズが選択できない場合は何かしらエラーが発生しています。原因が分からなければAPIキーを再発行&再入力してください。
ちなみに OpenRouter を使用するなどして OpenAI 互換のモデルを使用する場合は一番下の Model providers compatible with OpenAI's API standard, such as LM Studio. で使用できます。が、恐らくDifyの不具合でそれだけではモデルとして使用可能になりません。一度保存したモデル情報を開いて保存しなおすと使用可能になります。
チュートリアル1:シンプルな生成AIチャットbot 特定のテーブル定義に対して特化したSQLを生成するチャットbotを作ってみましょう。
開発
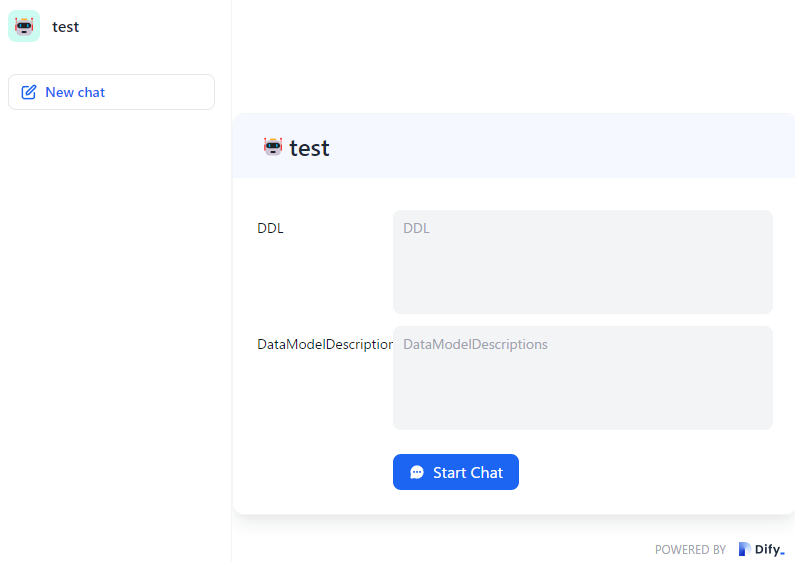
画面上部のスタジオ →新しいアプリを作成する、をクリック。タイプにアシスタントを選択し、適当な名前を付けます。後から変更可能です(実はおなじみのAIチャットとして使うだけならここまでで完成してしまっています)
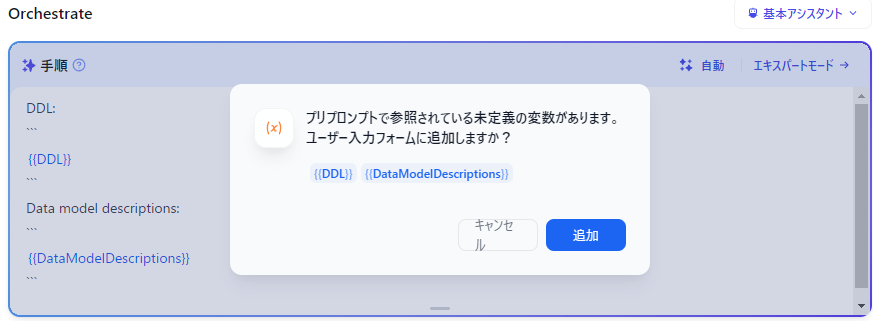
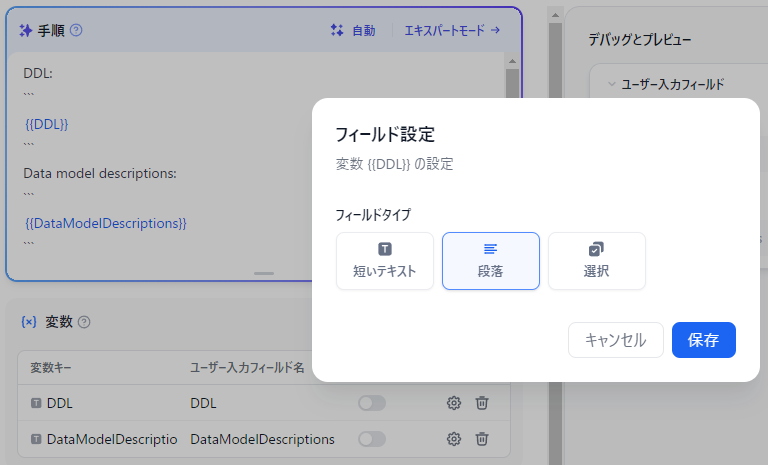
画面左の「手順」に以下を入力します。フォーカスを外すと変数追加をリコメンドしてくれます。追加後このままだと短文しか入力できないので両方 ⚙ で「段落」に変更します。
You can behave as an expert of database expert. Provide a clear answer to the main purpose of the order. Omit preamble, phase, and repeating the order. DDL: ``` {{DDL}} ``` Data model descriptions: ``` {{DataModelDescriptions}} ```
動作確認
ここで画面右上の「公開」をクリックしてください。しなくても動作確認は出来ますが、変更が保存されていません。実はこの時点で完成したアプリケーションとして公開されてしまいますが、これ以外に開発中のアプリケーションを保存する方法が見当たりませんでした。
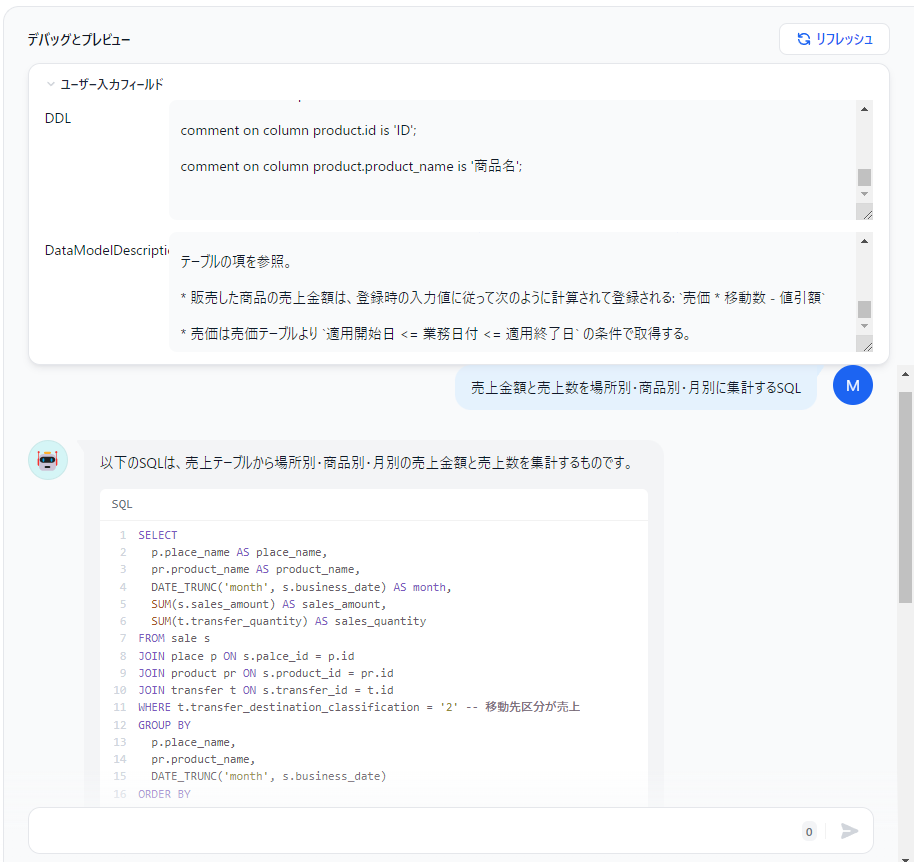
DDL に CREATE TABLE ~ などのDDLを貼り付けてください。DataModelDescriptions に各テーブルの内容や結合方式などについての説明文を貼り付けてください。必須ではありませんがこれが無いとAIはすぐ存在しないカラムの幻覚を見始めるので強く推奨します。1 画面右下に薄っすらと入力欄が有るのでそこにSQL生成を依頼するプロンプトを入力してください。
速い安い旨いの Haiku でも3,4テーブル程度の結合・集約なども結構な高精度で生成してくれます。
参考までに私が使用した変数の値を下記に貼り付けておきます。少し実務みのある区分値やリレーションを設定してあります。
DDL
drop table if exists sale cascade;create table sale ( id integer not null , palce_id integer not null , product_id integer not null , selling_price_ID integer not null , business_date date not null , sales_at timestamp not null , transfer_id integer not null , discount_amount integer , sales_amount integer not null , constraint sale_PKC primary key (id) ) ; drop table if exists transfer cascade;create table transfer ( id integer not null , place_id integer not null , product_id integer not null , business_date date not null , transfer_at timestamp , transfer_classification character varying not null , transfer_quantity integer not null , transfer_destination_classification character varying not null , transfer_destination_place_id integer , constraint transfer_PKC primary key (id) ) ; drop table if exists stock cascade;create table stock ( place_id integer not null , product_id integer not null , business_date date not null , stock_quantity integer not null , constraint stock_PKC primary key (place_id,product_id,business_date) ) ; create index stock_IX1 on stock(product_id,business_date); drop table if exists selling_price cascade;create table selling_price ( id integer not null , product_id integer not null , selling_price_classification character varying not null , start_date date not null , end_date date not null , selling_price integer not null , constraint selling_price_PKC primary key (id) ) ; create unique index selling_price_IX1 on selling_price(product_id,selling_price_classification); drop table if exists place cascade;create table place ( id integer not null , place_name character varying not null , selling_price_classification character varying not null , constraint place_PKC primary key (id) ) ; drop table if exists product cascade;create table product ( id integer not null , product_name character varying not null , constraint product_PKC primary key (id) ) ; comment on table sale is '売上' ; comment on column sale.id is 'ID' ; comment on column sale.palce_id is '場所ID' ; comment on column sale.product_id is '商品ID' ; comment on column sale.selling_price_ID is '売価ID' ; comment on column sale.business_date is '業務日付' ; comment on column sale.sales_at is '売上日時' ; comment on column sale.transfer_id is '入出荷ID' ; comment on column sale.discount_amount is '値引額' ; comment on column sale.sales_amount is '売上金額' ; comment on table transfer is '移動' ; comment on column transfer.id is 'ID' ; comment on column transfer.place_id is '場所ID' ; comment on column transfer.product_id is '商品ID' ; comment on column transfer.business_date is '業務日付' ; comment on column transfer.transfer_at is '移動日時' ; comment on column transfer.transfer_classification is '入出荷区分:1:入荷、2:出荷' ; comment on column transfer.transfer_quantity is '移動数' ; comment on column transfer.transfer_destination_classification is '移動先区分:1:場所間移動、2:売上、3:仕入' ; comment on column transfer.transfer_destination_place_id is '移動先場所ID' ; comment on table stock is '在庫' ; comment on column stock.place_id is '場所ID' ; comment on column stock.product_id is '商品ID' ; comment on column stock.business_date is '業務日付' ; comment on column stock.stock_quantity is '在庫数' ; comment on table selling_price is '売価' ; comment on column selling_price.id is 'ID' ; comment on column selling_price.product_id is '商品ID' ; comment on column selling_price.selling_price_classification is '売価区分:区分値: 1:プロパー, 2:B品, 3:アウトレット, 4:催事' ; comment on column selling_price.start_date is '適用開始日' ; comment on column selling_price.end_date is '適用終了日' ; comment on column selling_price.selling_price is '売価' ; comment on table place is '場所' ; comment on column place.id is 'ID' ; comment on column place.place_name is '場所名' ; comment on column place.selling_price_classification is '売価区分:区分値: 1:プロパー, 2:B品, 3:アウトレット, 4:催事' ; comment on table product is '商品' ; comment on column product.id is 'ID' ; comment on column product.product_name is '商品名' ;
Data Model Descriptions
# データモデル概要 ## 売価テーブル ( `selling_price` ) * 売価は商品別・売価区分別・業務日付別に登録される。但し業務日付は日々ではなく開始日~終了日の範囲指定で登録される。 * 売価区分にはプロパー・B品・アウトレット・催事の4種類がある。つまり商品ごとに最大で4つの売価が設定されうる。 * 売価区分の定義は以下の通り。 | 売価区分 | 意味 | | - | - | | プロパー | 発売当初の定価 | | B品 | 傷物など、商品個体の不具合により販売場所(以下「売場」と呼ぶ)の判断で値下げを要する場合の売価 | | アウトレット | 商品のターゲットシーズンを過ぎて値下げした後の売価 | | 催事 | 催事場で使用される特別売価 | ## 場所テーブル( `place` ) * 場所テーブルには場所の名前と標準の売価区分が登録されている。 * 場所に設定されている売価区分によって、その場所で発生しうる売上の売価区分が制限される。組み合わせは以下の通り。 | 場所の売価区分 | 売上として発生しうる売価区分 | | - | - | | プロパー | プロパー・B品・アウトレット | | アウトレット | プロパー・B品・アウトレット | | 催事 | プロパー・催事 | * 場所の売価区分としてB品は選択できない。 ## 移動テーブル( `transfer` ) * 移動テーブルにはある場所で発生した商品の入出荷情報が全て登録される。仕入による入荷、販売による出荷、場所間での移動による入荷/出荷など。 * 場所間で発生した移動の場合、 * 移動元の場所において出荷、移動先の場所において入荷のレコードが登録される。互いのレコードの移動数は一致する。 * 移動先場所IDカラムに移動先の場所IDが登録される。 ## 在庫テーブル( `stock` ) * 在庫テーブルには日々の当初の場所別・商品別の在庫数が記録される。 * 移動テーブルに全ての入出荷情報が登録されているため、ある日の在庫レコードの在庫数は `前日の在庫レコードの在庫数 + 前日の移動テーブルの入荷分の移動数の合計 - 前日の移動テーブルの出荷分の移動数の合計` と一致する。 ## 売上テーブル( `sale` ) * 売上テーブルには場所別・商品別・売価別の売上情報が登録される。 * 売上の登録に際して必要な入力値は場所ID・商品ID・売価区分・売上数・値引額の4個。 * 売上数は売上テーブル上では管理しない。売上の発生に伴い移動テーブルに入出荷区分:出荷、移動先区分:売上、移動数:売上数のレコードが登録される。そのレコードのIDが売上レコードの移動IDカラムに保持される。 * 売価区分は売上を登録する時点で任意に選択される。 * 但し、その売場に該当する場所テーブル上の売価区分の設定値により、取り得る売価区分は制限される。詳細は場所テーブルの項を参照。 * 販売した商品の売上金額は、登録時の入力値に従って次のように計算されて登録される: `売価 * 移動数 - 値引額` * 売価は売価テーブルより `適用開始日 <= 業務日付 <= 適用終了日` の条件で取得する。
プロンプト:「売上金額と売上数を場所別・商品別・月別に集計するSQL」
アプリケーション公開 ここまでの操作で(公開をクリックした時点で)既にDify上で動作するアプリケーションが完成し公開されています。
チュートリアル2:外部ツールの使用 文章を生成するだけのLLMに、外部サイトの情報を収集する機能と、グラフを描画する機能を追加します。
開発
また画面上部のメニューからスタジオ→新しいアプリを作成する→アシスタントを選択して適当な名前で作成してください。
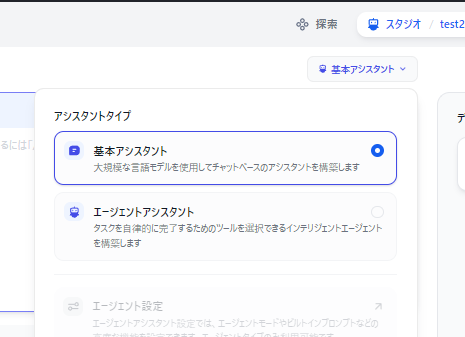
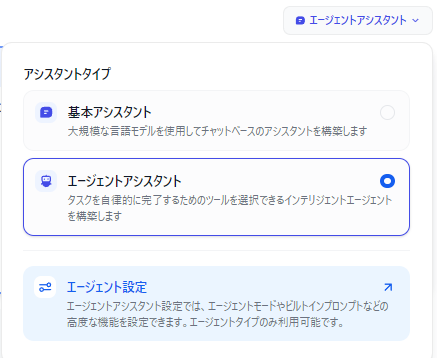
「基本アシスタント」をクリックして「エージェントアシスタント」を選択します。
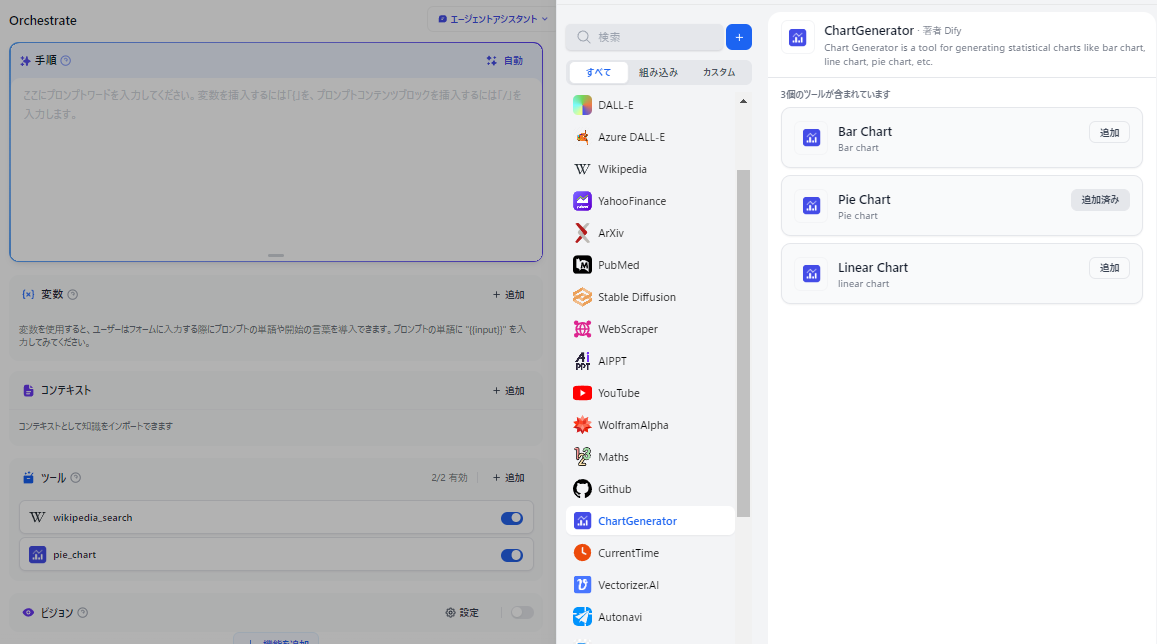
画面左側に「ツール」エリアが出現するので、「+追加」をクリックして、 Wikipedia と ChartGenerator の Pie Chart を追加します。
「手順」に ユーザの入力したプロンプトについてWikipediaで検索し、数値の情報をもとにパイチャートを作成してください。 と入力します。無くても動作はしますがそのままだと LLM が Wikipedia を参照せず手持ちの情報で回答してしまいがちなので念を押しておきます。
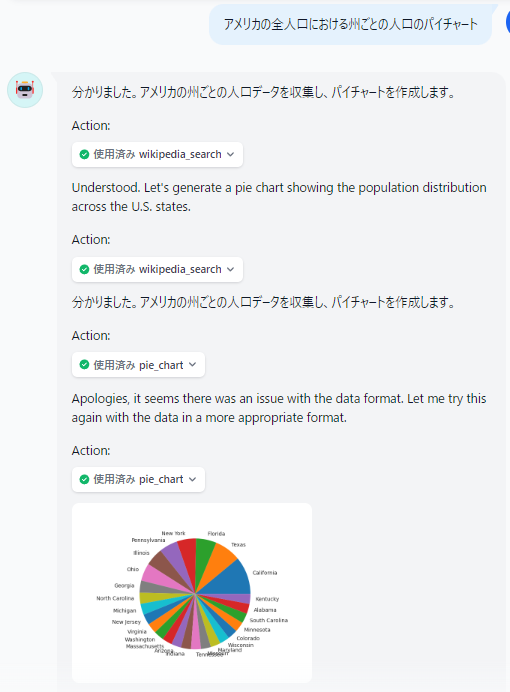
動作確認 「公開」をクリックしてプロンプトに「アメリカの全人口における州ごとの人口のパイチャート」と入力すると若干怪しい動きを見せつつ作図されます。
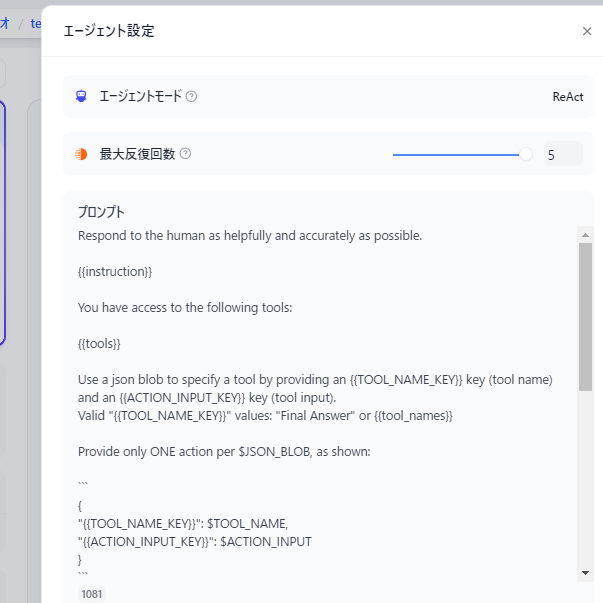
実は残念ながら現時点では Anthropic の Functions & external tools には直接対応していないらしく、エージェント設定を見るとエージェントモードが ReAct になっています(GPTやGPT互換だと Function Calling のはず)。どうもこの場合Difyは、「LLMが生成した文字列からツール用パラメータっぽい部分をパースしてツールに中継する」という形で Function Calling を模した機能を提供するようで、生成された文字列が一部でもJSONとして破綻(値の中で改行など)していると失敗します。ツールの呼び出しに失敗するとツールを呼び出そうとした文字列がそのまま最終回答文として出力されます。
後編に続く 前編では下記のステップを辿りました。
チャットbotに手順(Instruction)を与えて特定の問題領域に特化したチャットbotを作る
既製のToolを使用して自然言語処理以外の機能を獲得する
後編 はこれらを進めて以下の内容を書きます。
Toolを自作して機能を拡張する
生成AIに自分の生成した回答を自己レビューさせる