本記事は「珠玉のアドベントカレンダー記事をリバイバル公開します」企画のために、以前Qiitaに投稿した記事を一部ブラッシュアップしたものになります。
はじめに
最近は鶏胸肉弁当のバリエーションを増やすことに情熱を捧げている、HealthCare Innovation Groupの山本です。
今回はリバイバル企画ということで、2022年12月に書いた「画像生成AIは医療の未来を創れるのか?」の記事から、時代の流れを追ってセルフリバイバルします。
2年弱の時が過ぎ去ったわけですが、果たして画像生成AIは医療の未来を作れたのでしょうか? あるいは、より広い医療の未来を作れるようになったのでしょうか?
画像生成AIの歴史
医療における画像生成の話をする前に、直近の画像生成AIのトレンドを振り返ってみます。
以下に、代表的なものを一部だけ抜き出してみました。
| 時系列 | 技術・サービス名称 | 概要 |
|---|---|---|
| 2013.12 | VAE | データの潜在表現を学習し、デコーダーで類似画像のを生成する |
| 2014.06 | GAN | Genarator(生成ネットワーク)とDiscriminator(識別ネットワーク)の2つで敵対的学習をさせることで、高品質画像生成にアプローチ |
| 2018.12 | StyleGAN | GeneratorとDiscriminatorを段階的に追加することでより高品質画像生成を可能に |
| 2021.02 | CLIP | テキストと画像のペアから学習した、マルチモーダルモデル。事前学習モデルとして活用可能 |
| 2022.04 | DALL-E2 | CLIPとVAEを使用することで、テキスト指示で画像を生成可能に。個人のサービスとして利用可能 |
| 2022.07 | Midjourney | テキスト指示で画像を生成可能に。個人のサービスとして利用可能。 |
| 2022.08 | Stable Diffusion | CLIP、U-Net、VAEなどを組み合わせた拡散モデルの画像生成 |
| 2023.02 | ControlNet | 拡散モデルを制御するためのニューラルネットワーク。追加の入力条件に対応させることなどが可能に |
| 2023.03 | Adobe Firefly | Adobe性のtext2imageのモデルおよびサービス |
| 2023.07 | SDXL(Stable Diffusion XL) | Base, Refinerという2層構造でより高画質に生成可能に |
| 2023.09 | DALL-E3 | DALL-E2から更に高画質な出力が可能に。拡散モデルを適用 |
| 2024.02 | Stable Diffusion3 | Stable Diffusionの最新モデル |
2014年ごろにはVAE、GAN、CLIPなどが代表的なトレンドとして挙げられると思います。(犬猫の画像をGANで生成してわいわいしてた時代が懐かしいですね。。)
そこから、これらの技術を組み合わせて改善する他に、大きなトレンドとしてStable Diffusionなどのような拡散モデルの進出が挙げられると思います。
これは、高品質な画像生成が可能になったほか、text-to-imageの技術が成熟してユーザーがテキストで画像生成の指示を与えられるようになったことが大きなインパクトであると思います。更には、ユーザーがWeb上で使用可能なサービスとして提供されたことで一般ユーザーに普及が広がりました。
前回記事を書いた2022年ごろは、まさにこれらの技術・サービスが爆発的に拡大した黎明期といったイメージでした。
今に至るまでの差分を振り返ると、更にユーザーライクに、高品質に出力できる画像生成AIが活用されるようになったのではないかと感じます。
また、画像生成AIだけでなく、2024年にはSoRAに挙げられるような動画生成AIのモデル・サービスの進出したことがあると思います。
技術の進歩もここまで極まれり、という感じですね。
医療×画像生成AIを調べてみる
ここからは、リバイバル企画の本題に入っていきます。2022年12月に記事を執筆した際には、以下のような論文やユースケースを私は調べていたようです。
GANによる脳腫瘍画像データ合成
Brain tumor image generation using an aggregation of GAN models with style transfer
Paper: https://www.nature.com/articles/s41598-022-12646-y
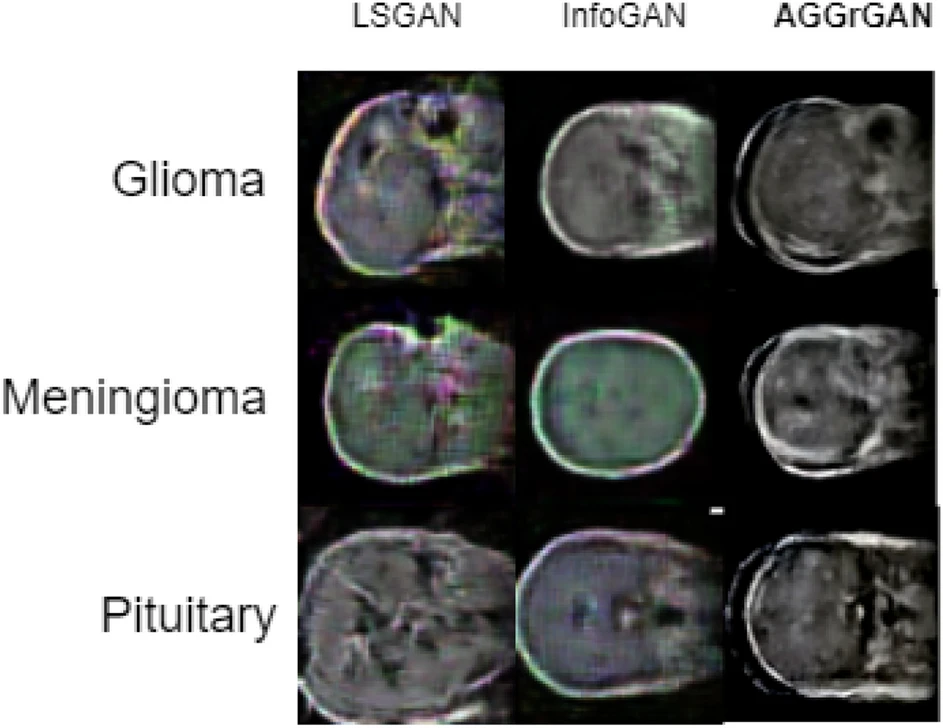
この論文では、公開されている2つの脳腫瘍データセットを学習データとして、AGGrGANというGANベースの画像生成手法を提案しています。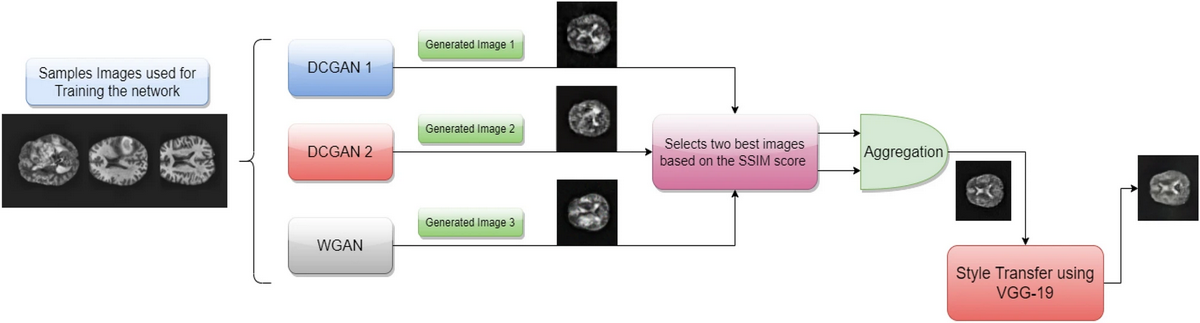
この手法の特徴としては。3つのGAN(レイヤーを変えたDCGAN、WGAN)で生成した3つの画像から、SSIM(2つの画像の類似度)を評価とし2つの画像を選択、合成した後に、学習済みのVGG-19ネットワークを用いてスタイル転送することで画像を生成しています。
病理画像から病理画像への変換
BCI: Breast Cancer Immunohistochemical Image Generation through Pyramid Pix2pix
arxiv: https://arxiv.org/pdf/2204.11425v2.pdf
GitHub: https://github.com/bupt-ai-cz/BCI
Image-to-Imageの取り組みとして、特定の病理画像から、他の病理画像へと変換するような取り組みもあります。
こちらの論文では、乳がん検査に用いられるIHC(免疫組織化学染色)の画像を、HE(ヘマトキシリン・エオジン)の画像から直接合成しようとしています。
意義としては、かなり高い検査が必要なものを、他の安価な検査で代替できるということですね。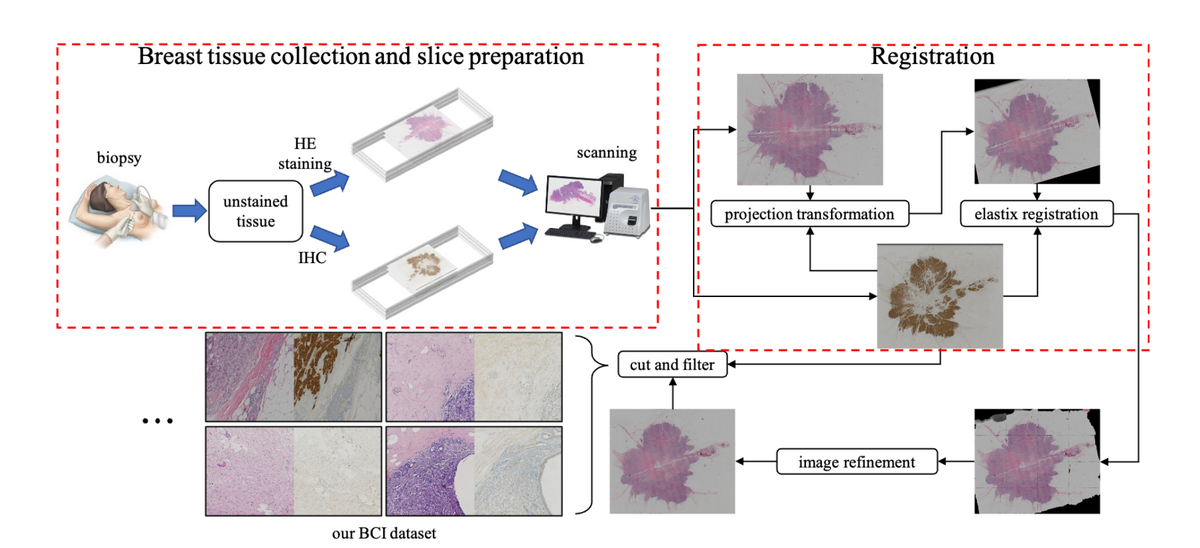
顕微鏡画像の品質UP
Correction of out-of-focus microscopic images by deep learning
paper: https://www.sciencedirect.com/science/article/pii/S2001037022001192?via%3Dihub
GitHub: https://github.com/jiangdat/COMI
こちらの論文では、低コストの顕微鏡で撮影した画像は焦点があっていないことが多い、という課題をCycleGANで修正しようとしています。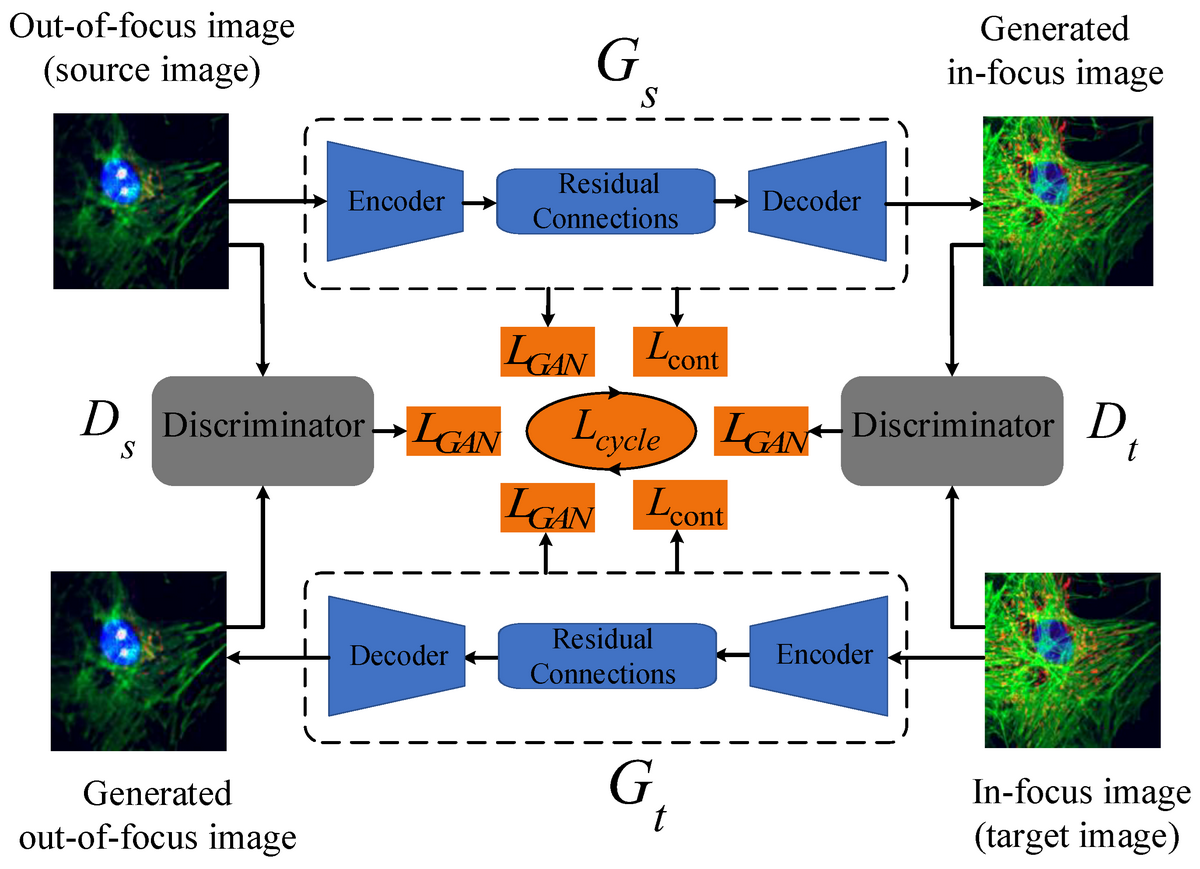
当時拡散モデルが爆発的なトレンドだった割には、GANをベースとした研究などが多かった印象ですね。
では、2023-2024ではどうでしょうか?
What Does DALL-E 2 Know About Radiology?
近年の画像生成AIの代表格のひとつである、DALL-E2について興味深い論文があったので紹介します。
「DALL-E2は放射線学について何を知っていますか?」というタイトルのままですが、放射線学における応用可能性を調査したものです。
https://www.ncbi.nlm.nih.gov/pmc/articles/PMC10131692/
テキストから、X線画像を出力したところ、以下のようになったとのことです。
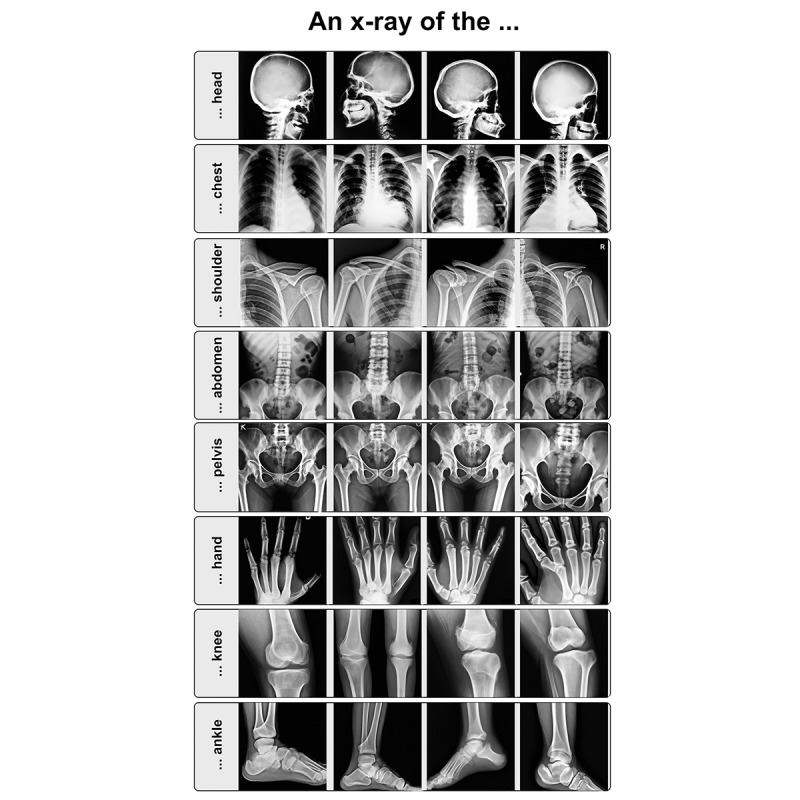
傍目にはかなり信憑性のありそうなものが出力されていますね。論文では、X線画像については一定の品質を担保できるものの、CTやMRIなどの生成能力は劣るとのことで締められていました。
Medical Diffusion: Denoising Diffusion Probabilistic Models for 3D Medical Image Generation
https://arxiv.org/pdf/2211.03364
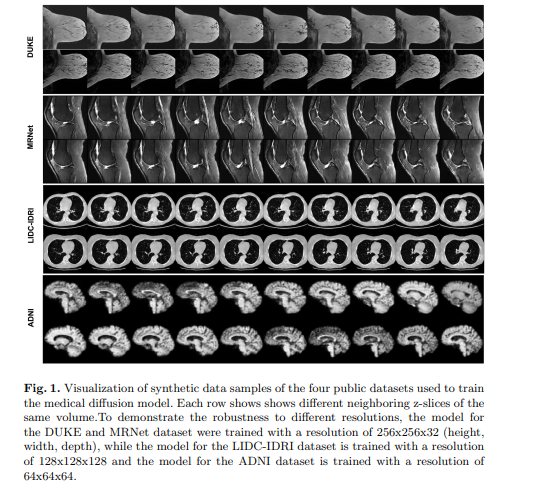
次に、拡散モデルの研究例を紹介します。以下の画像は、脳MRI、胸部CT、膝MRIなどの公開データから学習して生成したものとのことです。
かなり現実的な画像が生成されていますね。医療の分野においては、ボトルネックが多く少数の教師データしか用意できないことが多いです。データ増幅という意味で実用的な段階に達してきているのではないでしょうか?
Project MONAI
次に、医療における生成モデルのオープンソースプラットフォームであるMONAIを紹介します。
https://github.com/Project-MONAI
こちらのプロジェクトでは、研究者や開発者が生成モデルをかんたんに訓練、評価、共有できるようにプラットフォームとしての構築をしています。例えば、以下のような 脳MRIの生成モデルが公開されていたりします。
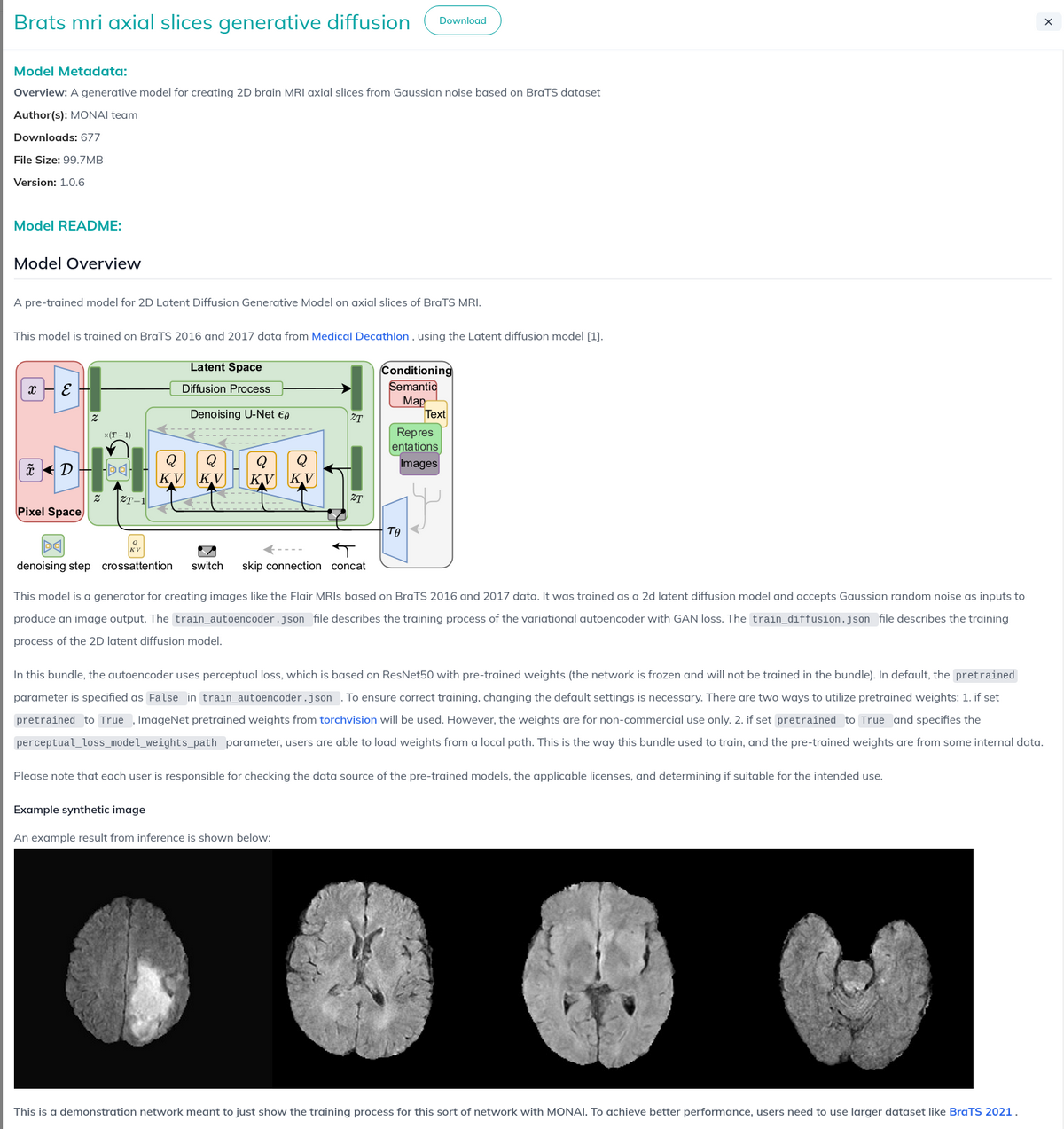 (https://monai.io/model-zoo)
(https://monai.io/model-zoo)
全体として、GANをベースにしていた時代からの技術の進歩により、高画質・実用的な画像を生成できるような時代が近づいていることを感じますね。
また、2年前と比較して拡散モデルを取り入れた研究も多くなっていました。
画像生成AIの医療における活用について
最後に、生成AIと医療の活用について考えてみます。画像生成に限らずビデオも生成できるようになりつつある今、どのようなことができると考えられるでしょうか?
教師データの作成、少数学習データでの精度向上
GANの時代から活用展望として言われていたことですが、データについて増幅することで新規モデル作成の精度向上をする、ということが現実的になってきました。
実際に、紹介した論文の中でも拡散モデルを使用した半教師あり学習の事例で精度が向上する事例として紹介されています。
今までは、小規模な病院であったり、希少疾患を対象としたものはそもそものデータが少ないことで学習モデルを作成しづらい、という課題がありました。
これが克服されることで、より医療の現場での機械学習の適用可能性があがるのではないでしょうか。
画像の高画質化
拡散モデルの発展により、かなり大きな影響がある部分として画像の高画質化が挙げられます。例えば、医療現場において高品質なカメラを使用することが難しい場合においても、安価なアプローチとして導入することが期待できると思います。
これらが現実的な選択肢となってきたのではないでしょうか?
最後に
2年弱ごしのリバイバル企画ということで、2022年の拡散モデルが盛り上がっていたころからの変遷と、医療における適用可能性について調べ・考えてみました。
画像に限らず、発展を続けている生成AIの分野ですが、マイナスな側面としては倫理的な課題、品質面での課題などが完全に解消されたとは言えない現状でもあるとおもっています。
しかしながら、技術の進歩とともに画像生成AIは品質も向上し、研究者に限らず一般のユーザーでも利用できるところに手が届くようになりました。
これにより、医療の分野においてもまだまだ発展をつづけ、価値を発揮できる領域である。
動画生成AIをはじめ、マルチモーダルなモデルについても発展が進んでいることで、さまざまなデータや操作の掛け合わせができるようになってきました。
2024年においてもまだまだ革新的な変化をつづけている分野であり、医療分野にも大きな価値を発揮することがまだまだ期待できると私は思っています。
今後もキャッチアップをつづけ、私自身も医療分野に価値を発揮できるように頑張りたいものです。
参考文献
- https://www.nature.com/articles/s41598-022-12646-y
- https://arxiv.org/pdf/1709.01872.pdf
- https://healthgym.ai/datasets/
- https://github.com/bupt-ai-cz/BCI
- https://www.sciencedirect.com/science/article/pii/S2001037022001192?via%3Dihub
- https://www.ncbi.nlm.nih.gov/pmc/articles/PMC10131692/
- https://arxiv.org/pdf/2211.03364
- https://github.com/Project-MONAI
- https://monai.io/model-zoo