本記事は「珠玉のアドベントカレンダー記事をリバイバル公開します」企画のために、以前Qiitaに投稿した記事を7年ぶりに改訂したものです。
筆者自身もコミッターとして関わるJavaのDB永続化ライブラリ「uroboroSQL」の紹介です。

https://github.com/future-architect/uroborosql
はじめに
エンタープライズシステム開発では、まだまだJavaで作られていることが多く、システム特性上、やはりRDBを利用するケースが多いですよね。
Amazon AuroraやCloud Spannerといったプロダクトに注目が集まるのも、時代の変化とともにDBも並列分散型でスケールアウトはしたいけれども、トランザクションもSQLも使いたいというCAP定理を覆す特徴を持っていることが要因だと思います。
2016/12/24にクリスマス・イブにCockroachDBに負荷をかけてみるという記事を投稿したのですが、このCockroachDBもそんな理想を追い求めるプロダクトで、RDBでNoSQLのメリットを教授したいニーズはもはやエンジニアが切望する夢なんですね✨️
2024年6月追記
現在では、TiDB、yugabyteDBなどの選択肢も増えました。
CockroachDBもしぶとく生き残っていて何よりです。
JavaとRDBの歴史
2000年代前半にJavaで作られたシステムは、JDBCのAPIをそのまま利用することも多かったのですが、その後、Hibernate、iBatis(現在のMyBatis)、SeaserプロジェクトのS2Daoなどをはじめとして、O/Rマッパー(O/Rマッパ)が開発され、利用されるようになりました。
その後、2006年にJPA(Java Persistence API)の1.0がJava標準の永続化フレームワークとして策定され、2009年にJPA2.0、2013年にJPA2.1と、Java SEでも利用はできるのですが、Java EEのEJBと共に進化を続けているという状況ですね。
なお、2017年時点のライブラリ比較については、2017年度 Java 永続化フレームワークについての考察(1)の記事が非常に参考になります(残念ながらこれから紹介するuroboroSQLは入ってません😢)。
2024年6月追記
執筆から6年半ほど経ち、改めて調査してみましたが、大きな変化はないように思います。
ここ数年でアプリケーションフレームワークの領域は、Spring Boot以外に、Quarkus、Micronautのようなマイクロサービス、コンテナネイティブ、ネイティブビルド最適化されたものが登場していますが、O/Rマッパは独立して選定されているように感じます。
(SpringBootの場合、王道的にSpring Data JPAを選定しているケースも多いとは思います)
uroboroSQLとは
uroboroSQLは、JavaにおけるDB永続化ライブラリの1つであり、基本的にはJavaからSQLを生成することよりも、SQLに足りないところをJavaで補うアプローチを採用しています。
もちろん、1レコードのINSERT/UPDATE/DELETEでSQLをいちいち書くのも辛いので、O/RマッパとしてのAPIも提供しています。
2017年にOSSとして公開後も、社内で脈々と使い続け、都度フィードバックを受けて、2024年6月現在までバージョンアップを継続しています。
特徴的な機能
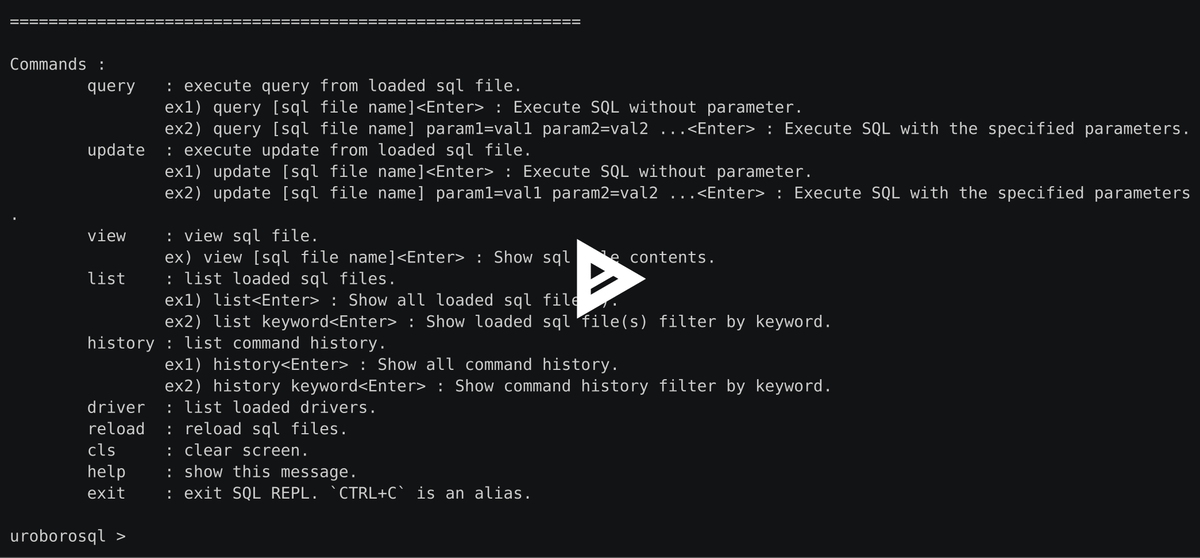
開発時に便利なREPL機能搭載
2Way-SQLでの開発時にビルド不要で即試すことが可能です。
カバレッジレポート
SQL文の条件分岐を集計してカバレッジレポートを行うことが可能です。

その他の特徴
| 項目 | uroboroSQLの対応 |
|---|---|
| ライセンス | MIT |
| 体制 | OSS |
| latest | v0.26.8 (2024/05) |
| SQL外部化 | ○ |
| DSL | × |
| Java | 8<= |
| Stream Lamdba対応 | ○ |
| エンティティ自動生成 | ○ |
| 区分値対応 | ○(列挙体、定数クラスいずれも可) |
| ストアドプロシージャ呼出 | ○ |
| ResultSetのカスタマイズ | ○ |
| Oracle | ○ |
| DB2 | - |
| MySQL | ○ |
| PostgreSQL | ○ |
| MariaDB | - |
| MS-SQL | ○ |
| H2 | ○ |
| Derby | ○ |
| Sybase | - |
| SQLite | ○ |
| 依存(必須) | slf4j-api |
| 依存(任意) | ognl,spring-expression,jline,jansi,logback-classic |
※2024/06/25時点最新バージョンとなるv0.26.8時点
uroboroSQLのコードサンプル
さて、ライブラリを理解するには、利用時にどんな実装になるのか見るのが手っ取り早いですよね。
というわけで、よく利用する実装をサンプルとして、まとめました。
2017年の初版執筆時点では、公式ドキュメントよりも豊富だと思っていましたが、2024年時点では公式ドキュメントが充実していますので、是非こちら↓もご覧ください。
https://future-architect.github.io/uroborosql-doc/
接続
SqlConfig config = UroboroSQL.builder("jdbc:h2:mem:test;DB_CLOSE_DELAY=-1", "sa", "sa").build(); |
トランザクション
| トランザクションタイプ | トランザクション有り | トランザクションなし |
|---|---|---|
| required | トランザクション内で処理を実行 | 新たなトランザクションを開始して処理を実行 |
| requiresNew | 既存のトランザクションを停止し、新たなトランザクションを開始して処理を実行。 トランザクションが終了すると停止していたトランザクションを再開させる |
新たなトランザクションを開始して処理を実行 |
try (SqlAgent agent = config.agent()) { |
SQLファイルインタフェース(2way-SQL)
SELECT /* _SQL_ID_ */ |
INSERT /* _SQL_ID_ */ |
UPDATE /* _SQL_ID_ */ |
DELETE /* _SQL_ID_ */ |
S2Dao等と同じ文法で、SQL内でコメント標記で分岐を記述することができます。
SELECT(リスト取得)
try (SqlAgent agent = config.agent()) { |
SELECT(Stream取得、Map型)
try (SqlAgent agent = config.agent()) { |
SELECT(Stream取得、モデル型)
try (SqlAgent agent = config.agent()) { |
SELECT(1件取得、Map型、取得できない場合例外)
try (SqlAgent agent = config.agent()) { |
SELECT(1件取得、モデル型、取得できない場合例外)
try (SqlAgent agent = config.agent()) { |
SELECT(1件取得、Map型、Optional)
try (SqlAgent agent = config.agent()) { |
SELECT(1件取得、モデル型、Optional)
try (SqlAgent agent = config.agent()) { |
SELECT(1件のみ取得、モデル型、取得できない場合と2件以上取得した場合に例外)
try (SqlAgent agent = config.agent()) { |
INSERT/UPDATE/DELETE
try (SqlAgent agent = config.agent()) { |
INSERT/UPDATE/DELETE(バッチ実行)
List<Map<String, Object>> inputList = new ArrayList<>(); |
DAOインタフェース
下記のようなモデルクラスがある前提とします。
|
@Id/@GeneratedValueが付与されたフィールドはDBの自動採番を利用することをマークします。@Versionが付与されたフィールドは楽観ロック用のバージョン情報としてuroboroSQLが認識し、UPDATE時にはSET句で+1され、WHERE句の検索条件に追加されてSQLを発行し、更新件数が0の場合にOptimisticLockExceptionを発生させます。
SELECT(主キー検索)
try (SqlAgent agent = config.agent()) { |
SELECT(条件指定検索、ソート順、悲観ロック)
try (SqlAgent agent = config.agent()) { |
INSERT
try (SqlAgent agent = config.agent()) { |
UPDATE
try (SqlAgent agent = config.agent()) { |
MERGE
PKによるレコードの検索を行い、レコードがない場合はINSERT、ある場合はUPDATEします。
try (SqlAgent agent = config.agent()) { |
DELETE / TRUNCATE
try (SqlAgent agent = config.agent()) { |
おわりに
この記事の初版公開から7年ぶりに更新しようとしたら、自分でも驚くほど機能追加されていて、よい振り返りとなりました。
OSSにしても社内プロダクトにしても、継続的にアップデートし続けるのが一番大変だなとしみじみ感じますね。
顧客向けの大規模エンタープライズ開発では、リリースしてから5-10年後にさくっと全部作り直しましょうというケースのほうが稀で、長く使い続けたいというニーズが強いため、下位互換性を失うにしても移行しやすいかどうかも重要なので、これからも継続の価値と意義を再認識して、アップデートを続けていきたいと思います。
参考:uroboroSQLドキュメント、ツール、サンプル
- uroboroSQL日本語ドキュメント
- uroboroSQLの紹介 (OSC2017 Nagoya) #oscnagoya
- uroboroSQL ソースジェネレータ
- uroboroSQL サンプルCLIアプリケーション
- uroboroSQL サンプルWebアプリケーション(with Spring Boot)