
はじめに
こんにちは、コアテクノロジーグループの金澤です。
JDK 23のリリースを記念して、バージョン21~23にかけての変更点を紹介する連載が始まります。
1本目としてJDK 21でのアップデート内容を取り上げます。
すでにリリースから1年が経過していますので詳しい情報は他にお任せし、ここではJDK 23をキャッチアップする際のおさらいとして正式採用となったものから主要な変更をピックアップしてご紹介します。
主な変更点は以下の通りです。
- JEP431: Sequenced Collections (順序を保持するコレクションのインターフェース)
- JEP439: Generational ZGC (世代別のZGC)
- JEP440: Record Patterns (レコードパターン)
- JEP441: Pattern Matching for switch (switchでのパターンマッチング)
- JEP444: Virtual Threads (仮想スレッド)
また、テンプレートリテラルやf文字列など他の言語に慣れ親しんでいる方の多くが正式採用を待ち望んでいたであろう、Previewで追加された以下の変更はJDK 23で取り下げとなりました。
文字列テンプレートの取り下げについては以下の記事が詳しいです。
https://nipafx.dev/inside-java-newscast-71/
JEP431:Sequenced Collections (順序を保持するコレクションのインターフェース)
要素の順序を保持するコレクションに対して、一貫した操作を提供するための新しいインターフェースです。具体的には、以下の3つの新しいインターフェースが導入されました。
interface SequencedCollection<E> extends Collection<E> { |
これにより、順序が保証されているかどうかに注意して実装クラスを選択しなければならなかった部分が、インターフェースを確認することですぐに判別できるようになりました。HashMap のような利用頻度の高いかつ順序が保証されないクラスはJava初学者にとってハマりやすいポイントなので、これからは学習のハードルを下げ、問題解決の助けになるのではないかと思います。
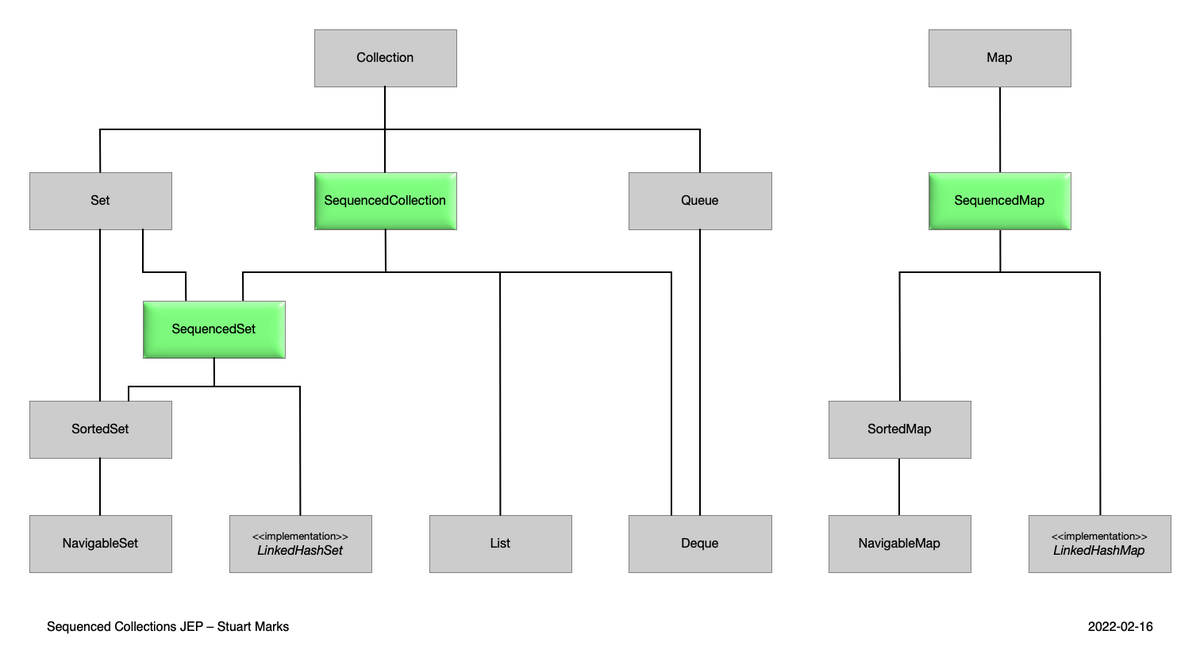
(図はJEP431より)
従来のJavaコレクションでは、List や Deque などが順序付けられたデータを扱うために使用されてきました。しかし、これらのインターフェースは特定のデータ構造に密接に関連しており、共通の操作を一貫して提供するものではありませんでした。
例えば、List はインデックスによる要素アクセスが可能ですが、先頭や末尾での要素の追加・削除を効率的に行うためのメソッドは提供していません。一方、Deque は先頭や末尾での要素の追加・削除を効率的に行うためのメソッドがあります。
シーケンス化コレクションの導入により、順序付けられたコレクションに対して共通の操作を提供し、コードの一貫性と可読性を向上させることができます。
SequencedCollection インターフェースは、以下の主要なメソッドを提供します。
addFirst(E e):要素をコレクションの先頭に追加しますaddLast(E e):要素をコレクションの末尾に追加しますgetFirst():コレクションの先頭要素を取得しますgetLast():コレクションの末尾要素を取得しますremoveFirst():コレクションの先頭要素を削除しますremoveLast():コレクションの末尾要素を削除しますreversed():コレクションの逆順ビューを取得します
便利なところとして、今まで List の最後の要素を取得する際にはインデックスにサイズ-1を指定するように書くということが広く行われていましたが、
var list = List.of(1, 2, 3); |
getLast() で取得できるようになりました。
var list = List.of(1, 2, 3); |
SortedSet Deque でも統一して getLast() で取得できます。
var deque = new ArrayDeque<Integer>(List.of(1, 2, 3)); |
また、反転した順序で欲しい場合には reversed() で反転させて取得できるようになりました。
var list = new ArrayList<>(Arrays.asList(1, 2, 3)); |
現在の実装では取得されるのは元のインスタンスの参照なので、要素を変更すると元のインスタンスに反映される点は注意が必要です。
var list = new ArrayList<>(Arrays.asList(1, 2, 3)); |
他にもここで紹介していないメソッドも多くありますので、詳細は以下のAPIドキュメントをご参照ください。
JEP439: Generational ZGC (世代別のZGC)
ZGCに世代別GCが導入されて、古いオブジェクトと古いオブジェクトの世代を別々に維持することによりパフォーマンスが向上しました。
JDK 21で有効にするには以下のオプションを設定する必要があります。
java -XX:+UseZGC -XX:+ZGenerational |
リリース時には将来のリリースでこの世代別GCをデフォルトにする予定としており、
JDK 23にて世代別GCがZGCのデフォルトになりました。
こちらは武田さんのJDK 23の紹介記事にて記載されておりますので併せてご参照ください。
JEP440:Record Patterns (レコードパターン)
JDK 16からはJEP394で instanceof 演算子を使用して型を判別した後にキャストが不要になり、パターン変数として統合して宣言できるようになりました。
// JDK 16以前 |
JDK 21からはレコードパターンが導入され、レコードの構成要素へと分解できるようになりました。
レコードパターンは、Javaのパターンマッチング機能を拡張するものです。具体的には、レコードクラスの内部にあるコンポーネントを直接抽出し、それらを変数にバインドすることができます。これにより、複雑なデータ構造を簡潔に処理することが可能になります。
record Point(int x, int y) {} |
レコードパターンはネストすることもできますので、レコードの中にレコードがある場合でも一度に必要な情報を抽出できます。
以下は レコード Rectangle にレコード ColoredPoint がネストされている例です。
record Point(int x, int y) {} |
レコード Rectangle については構成要素の ColoerdPoint に分解することができますが、構成要素がレコードの場合さらに分解することができます。
static void printColorOfUpperLeftPoint(Rectangle r) { |
従来、複雑なオブジェクトから情報を取り出すには、キャストやgetterを使う必要がありました。これはコードを冗長にし、可読性を下げる要因となっていました。レコードパターンを使うことで、これらの操作が簡潔になり、コードの意図が明確になります。
JEP441:Pattern Matching for switch (switchでのパターンマッチング)
switch でのパターンマッチングが正式採用されました。この拡張により、switch 文や式がより簡潔で読みやすくなりました。
// JDK 21以前 |
JEP440でも登場したパターンマッチングは、オブジェクトをパターンに対してテストし、マッチした場合にその構成要素を抽出してパターンのスコープ内で直接使用できる機能です。JDK 16では、instanceof チェックにパターンマッチングが導入され、より簡潔な型チェックとキャストが可能になっていました。
switch のパターンマッチングは、この概念を switch 文や式に拡張したものです。
実際にswitchのパターンマッチングがどのように機能するか、いくつかの例を見てみます。
when を使用してパターンに条件を追加できます。
public static String categorizeNumber(Number num) { |
switch のパターンマッチングは null にも対応できます。
public static String processValue(Object obj) { |
sealed クラスを使用している場合、switch のパターンマッチングはすべてのサブクラスが処理されることを保証できます。
以下のような定義があったと仮定します。
sealed interface Operation permits Add, Subtract, Multiply, Divide {} |
default 句は不要になります。また、レコードパターンとの併用が可能です。
public static double calculate(Operation op) { |
JEP444:Virtual Threads (仮想スレッド)
JVMが管理する軽量スレッド、仮想スレッドが正式採用になりました。
仮想スレッドは、軽量なスレッド実装であり、大量のスレッドを効率的に管理するために設計されています。従来のJavaのスレッド(プラットフォームスレッド)は、OSレベルのスレッドに1対1でマッピングされており、作成やコンテキストスイッチにコストがかかります。一方、仮想スレッドはJVM内で管理され、非常に軽量です。
現代のアプリケーションは、高い並行性とスケーラビリティが求められます。従来のプラットフォームスレッドを大量に使用すると、リソースの消費やパフォーマンスの低下が問題となります。仮想スレッドはこれらの問題を解決し、大量のスレッドを効率的に扱うことを可能にします。
内部的には、仮想スレッドはJVMによって少数のOSスレッド上でスケジュールされます。仮想スレッドがブロッキング操作(I/Oなど)を行うと、JVMはOSスレッドをブロックせずに仮想スレッドを一時停止でき、他の仮想スレッドを実行できるので、CPUの待ち時間をほぼ無くせる分スループットが高くなるという仕組みです。
従来のスレッドと仮想スレッドの違い、性能検証についてはJJUG CCC 2024 SpringのToru Takahashiさんの資料が分かりやすくまとめられていましたので参考までにご参照ください。
https://speakerdeck.com/tttol/virtual-threadsdeshi-xian-suruxing-neng-gai-shan?slide=18
ここからはどのように使用するのか、実際の例をいくつか見ていきます。Thread.ofVirtual() メソッドをコールして、仮想スレッドを作成するための Thread.Builder のインスタンスを作成します。
Thread thread = Thread.ofVirtual().start(() -> System.out.println("Hello")); |
Thread.Builder インタフェースを使用すると、今まで new Thread() で作成していたような一般的なスレッドを作成できます。Thread.Builder.OfPlatform によってプラットフォーム・スレッドが作成され、Thread.Builder.OfVirtual によって仮想スレッドが作成されます。
また、エグゼキュータを使用すると、アプリケーションの他の部分からスレッド管理と作成を分離できます。
次の例では、Executors.newVirtualThreadPerTaskExecutor() メソッドを使用してExecutorService を作成します。ExecutorService.submit(Runnable) がコールされるたびに、新しい仮想スレッドが作成され、タスクを実行するために開始されます。
try (ExecutorService myExecutor = Executors.newVirtualThreadPerTaskExecutor()) { |
そのほか仮想スレッドの詳細や採用ガイドについては以下をご参照ください。
さいごに
JDK 21での変更点はProject Amberの内容が多く、より見やすく安全なコードが書けるよう文法を改良する変更となっています。
本記事では取り上げていませんが、組み合わせることでより簡潔に記述できるようになる無名パターンと無名変数のPreviewの追加もあり、そちらは後続のJDK 22にて正式採用になっているなどより便利に記述できるよう改善が進んでいる印象です。
ピックアップ以外の変更やPreview、Incubatorについては以下のページをご参照ください。
次回は前川さんのJDK 22の紹介記事です。