はじめに
はじめまして。Strategic AI Group (SAIG) の神戸です。
2024.09.04(水)から09.06(金)にかけて開催されたYANS2024に参加したのでその様子をご報告します。
当社はプラチナスポンサーとしてSAIGから7名のメンバーが学会に参加し、スポンサーブースでの会社紹介やポスター・チュートリアルの聴講に加え、今年度はフューチャーから1件のポスター発表も行いました。
言語処理若手シンポジウム(YANS)とは
YANSは自然言語処理、およびその関連分野の研究発表が行われるシンポジウムです。2024年で19回目の開催となる本シンポジウムは大阪の梅田スカイビルにて開催されました。
本シンポジウムではポスター発表だけでなく、分野交流ハッカソンや招待講師によるチュートリアル、参加者がスポンサーブースを回るスポンサーツアーなど様々なプログラムが開催されました。
「ことばがつむぐ、新たなつながり ~分野の境界を超えて~」という本シンポジウムのスローガンにもある通り、自然言語処理だけでなく関連する周辺分野のポスター発表やチュートリアルも行われていました。
公式の発表によれば今年度の参加人数は411人と、前年度の300人を大きく上回る参加者数となっています。発表件数も前年度に比べ56件多い196件と過去最多の発表件数となっており、現地でもその盛況ぶりを感じることができました。

スポンサーブース
スポンサーブースでは自然言語処理に関する取り組みだけでなくAIに関する取り組み全般の紹介を行いました。自然言語処理に関する取り組みはもちろん、それ以外のAIに関する取り組みについても興味を持って聞いて下さる参加者の方が多く、当社の取り組みについて多くの方に知っていただく機会になったと思います。
ブースに来ていただいた参加者の方にはノベルティとしてパンフレットとトートバッグを配布させていただきました。ノベルティは多めに用意していたのですが、ブースに足を運んで下さった参加者の方が想定よりも多く、シンポジウム2日目の午前中には配り終えてしまいました。改めてブースに足を運んでくださった皆様に感謝申し上げます。

スポンサー賞
当社のスポンサー賞には [S4-P25] 日本語の単語を対象とした複数時期の意味変化パターン分析 の発表を選定させていただきました。選定理由は以下の通りです。
本研究は日本語の単語の意味や使われ方が年代とともにどのように変化したのかを分析する手法を提案しています。 意味変化の仕方をクラスタリングすることで、コロナ禍で使われ方が変わった単語のグループが表出するなど興味深い結果が得られており、今後の発展に期待が持てます。 また、聴講者からの質問に対する補足資料の提示をタブレットを用いて行うなど、発表に対する十分な準備ができている点も高く評価しました。
副賞として「九州産黒毛和牛A5ランク ITADAKIセット」を送付させていただきました。

当社の発表
今年のYANSでは、フューチャーからも1件の発表を行いました。
現在当社で自然言語処理の研究開発に関するアルバイトをお願いしているNAIST 西田さんとの共同研究成果です。
フューチャーでは基礎から応用まで幅広く研究開発を進めており、今後も様々な学会でその成果を公表していきます。
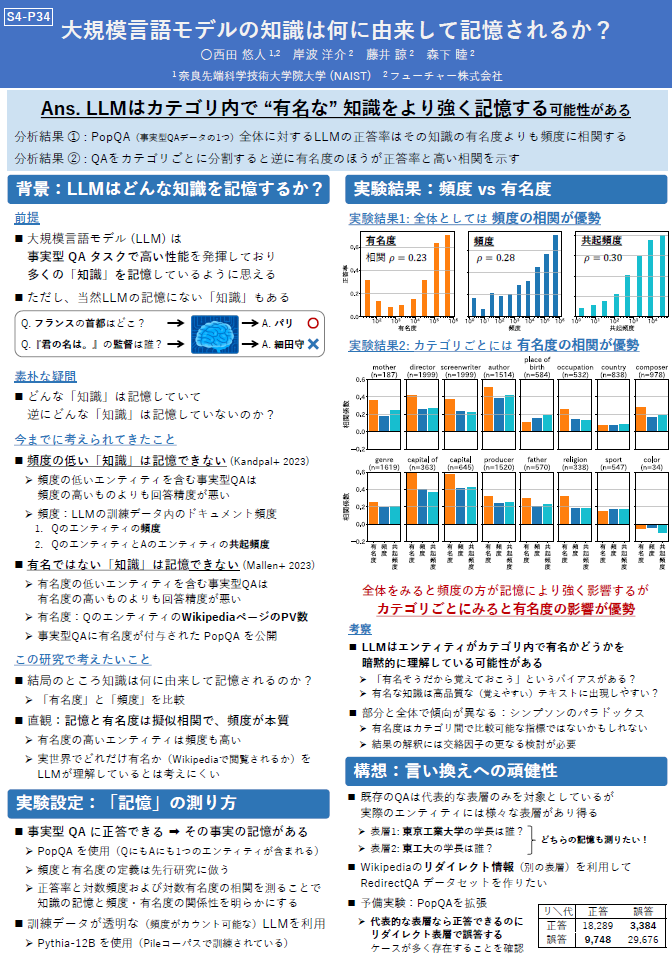
[S4-P34] 大規模言語モデルの知識は何に由来して記憶されるか?
西田 悠人 (NAIST/フューチャー), 岸波 洋介 (フューチャー), 藤井 諒 (フューチャー), 森下 睦 (フューチャー)
大規模言語モデル (LLM) は「『ハムレット』の著者は誰ですか?」のような事実に関する知識が必要な質問に答えられることがあります。これまで、LLMがどのような事実知識を記憶しているかについて研究が行われており、「訓練データ中の頻度が低い知識ほど記憶しにくい」「有名ではない知識ほど記憶しにくい」ということが知られていました。では、頻度と有名度のどちらがLLMの記憶により寄与しているのでしょうか?本研究では、記憶の強さと知識の頻度や有名度との相関を比較することで、LLMの記憶の主要因を調査しました。実験の結果、我々の直観に反して、知識のカテゴリごとにみると頻度よりも有名度と記憶の相関のほうが優勢であることが明らかになりました。このことは、ある知識が有名かどうかをLLMが暗黙的に理解している可能性を示唆しました。
第一著者コメント
今回のYANSでは、始まりたての萌芽的な研究を発表させていただきました。発表を聞きに来てくださった参加者の皆様から、さまざまな質問やコメントをいただき、今後の研究の方向性についてより明確になりました。改めて、発表に足を運んでくださった皆様に感謝申し上げます。
発表紹介
スポンサー賞の他に、当社から参加したメンバーが特に面白いと感じた発表をいくつか紹介します。
[S1-P38] 指示数増加による大規模言語モデルの指示追従性能への悪影響
この研究では、大規模言語モデルが追従できるプロンプト内の指示数について調査しています。
個々の指示は単純な場合でも、数が増えるごとに追従できなくなるという問題が大規模言語モデルには見られます。この問題に対し、指示に追従できているか各指示ごとにフィードバックを行い回答を修正する手法が提案されています。提案手法によって指示追従性が改善するという結果を示しており、プロンプト中の指示の位置によって追従性が変わるのか、指示数がさらに増えた場合でも追従性が落ちないようにするために改善することは可能かなど、今後の発展が期待される研究だと感じました。(加藤)
[S3-P08] Attentionに基づく大規模言語モデルのHallucination検出手法の検討
こちらの研究では、先行研究においてハルシネーション (幻覚) 発生時特有のAttentionパターンが存在する可能性が示唆されていることから、LLMのAttention情報を特徴量としてハルシネーション検出器を学習する手法を提案しています。
本手法によって構築される検出器は、検出予測時のAttention情報を確認することで検出対象文におけるハルシネーション発生個所が特定できるというメリットがあります。生成AIの活用が広がるなかでハルシネーションの検出は非常に重要な技術であり、検出箇所まで特定できる本手法は応用可能性が高いと考えられます。
現状の検出精度には改善の余地があるものの、特徴量の改善や外部知識の利用など今後の方向性も十分に検討されており、これからの発展が期待される研究だと感じました。(岸波)
[S1-P17] ゲームの台詞を題材としたキャラクターらしさを構成する要素の検討
この研究では、既存キャラクターを模した対話システムにおけるそのキャラクターらしさを構成する要素を評価しています。
ユーザから得られた自由記述評価を元に、対応する「らしさ」を構成する要素へとラベル付け・スコアリングを行い、その結果からキャラクター再現において優先すべき特性を考察しています。先行研究や文献からキャラクターらしさの構成要素候補が大量に挙げられていますが、そのすべてが「らしさ」を等しく述べているわけではない、性格を反映した発話であってもケースバイケースで「らしさ」への影響の大小があるという考察は、ノベルゲーム、ソーシャルゲームの一プレイヤーとして納得感がありました。
サイバーエージェントさんでは「[S2-P27] 『IDOLY PRIDE』におけるライブスコアを用いたアイドル埋め込み評価手法の検討」も発表されており、こちらはゲームのバランス調整のたたきにLLMを活用されている旨の発表がありました(こちらも面白かったです)。自然言語処理の知見がゲームの現場でこう使われているのかと興味深く感じました。(佐藤)
[S4-P21] LLMはなぜ算数が苦手なのか? Transformerの外挿能力に関する分析
この研究では、言語モデルが与えられた例からタスクの入出力の関係性を捉え、追加の学習なしでタスクに適応する能力である In Context Learning (ICL) を、コントロールされた四則演算の設定で検証しています。
人間であれば5桁の数字どうしの計算ができれば、6桁どうしの計算にも簡単に汎化できますが、GPT-2のような言語モデルは学習時に見ていない未知の桁数どうしの足し算をほとんど解けないということを明らかにしています。
また、数字の1つ1つが独立したトークンになっていると正解率が上がるというようにトークナイズの仕方によってタスク遂行能力に大きな差が生まれる、未知の桁数の問題では例の中の同じ桁数の問題にアテンションが張られている = なんらか違うことまでは理解できていそう、などとても興味深く示唆に富んだ良い研究だと感じました。
ポスターで述べられていた四則演算以外の問題への展開はもちろん、より表現力の高い大きなモデルではどうなのか?突然 “腑落ち” して四則演算のルールを学ぶことがあるのか?など、様々な方向性から今後の展開に期待できます。(藤井)
[S4-P14] SubRegWeigh: サブワード正則化による高速アノテーション補正
こちらの研究ではデータセット中のアノテーションミスを特定しその悪影響を軽減する “アノテーション補正”に関する新しい手法を提案しています。
従来の手法ではアノテーションミスを検出するために複数のモデルを使用して検出しなければならなかったため多くの時間を必要としていたところ、こちらの研究では複数のモデルを使用する代わりに複数のサブワード系列、つまり複数のテキストの区切り方のパターンで一つのモデルに学習をさせることでアノテーションミスの検出を高速に行えるようになっています。複数のモデルによる推論を、単一モデルによる複数のサブワード系列に対する推論に置き換えるアイデアが非常に面白いと感じました。実験では従来手法に比べ高速なアノテーション補正ができるようになったことだけでなく後段タスクの精度改善も確認されており、今後のさらなる展望が期待される発表だと感じました。(神戸)
「目指せ国際会議!」セッション
国際会議経験者を招き、国際会議に関するライトニングトーク (LT) およびパネルディスカッションを行うセッションが行われました。
今回ご招待を頂き当社から森下が「国際会議でやるべきこと3選」というタイトルでLTを行いました。
1回目の国際会議では(あまり)会議のレベルを気にせず、まずはどこでも良いので投稿し発表する経験を積むことの大切さをお伝えさせていただきました。
全発表者の資料は以下に掲載されています。
おわりに
私自身が約1年半ぶりの自然言語処理系の学会への参加だったため、LLMが台頭し始めて以降の自然言語処理の動向はほとんど把握できておりませんでした。今回のシンポジウムでLLMに関する研究の雰囲気を掴むことができましたし、LLM以外の研究も依然活発に行われていることを知ることができ、良い刺激を得られました。
Futureでは一緒に働くメンバーを募集しています。特に最近ではNLPに関する採用にも力を入れており、NLPエンジニア、NLPリサーチエンジニア、シニアNLPエンジニアの募集も行っております。条件等は応相談ですので、興味を持っていただけた方は是非採用ページの内容をご確認ください。
他にも新卒採用やキャリア採用を幅広く行っておりますので、多くの方からのご応募をお待ちしております。
みなさまと一緒に働ける日を心待ちにしております!