
はじめに
Apache Airflowはワークフロー管理サービスで、スケジュールされた時間に一連の処理を行ってくれる便利なサービスです。ただ、運用には結構コストがかかるサービスです。
そのため、Google CloudではCloud Composer、AWSではAmazon Managed Workflows for Apache Airflow (Amazon MWAA)といった運用を楽にするためのマネージドなサービスが展開されています。
とは言え、マネージドなAirflowでさえも運用は難しく、色々な問題が起こりがちです。Cloud Composer自体、v1から始まり既にv3へと進化1を遂げていることから、提供するGoogle側でも試行錯誤と努力の過程が見え透けてきます。
そこで本記事では、Cloud Composerを運用するプロジェクトにインフラ担当として2年ほど関わっきた中で経験的に得られたTipsを紹介します2。
※本記事のTipsはCloud Composer v2をベースに話をしています。Airflow単体で当てはまる部分が多いとは思いますが、Cloud Composer v1やv3、Amazon MWAAでは一部当てはまらない可能性があることを考慮して読んで頂ける幸いです。
Airflowのお約束事
Airflowにてワークフローを記述するDirected Acyclic Graph(DAG)は決定的でべき等でなければなりません。
以下の記事に詳しく説明があります。
- 決定的:特定の入力によって常に同じ出力が生成される必要
- べき等:DAG を何度トリガーしても、毎回同じ効果 / 結果が得られなければならない
Cloud Composerを運用してる中でDAGとして定義されたワークフローのタスクは結構よくわからないタイミングで失敗します。原因は内部的なネットワーク上の問題だったり、データベースへのアクセス過多だったり、どうしようもない場合がよくあります。
AirflowのDAGでは標準でリトライ機能が搭載されているので、いつでもリトライを実施できるようにしておくためにも、決定的でべき等なDAGを定義しておくことが大切です。
ベストプラクティス回り
Airflowの公式ページにてベストプラクティスが公開されています。
https://airflow.apache.org/docs/apache-airflow/stable/best-practices.html
このべスプラ、結構大事なことが書いてあるのですが見落とされがちです。運用する中でどうしても守ってほしい2点についてここで紹介致します。
Python Codeにおけるトップレベルでの処理
https://airflow.apache.org/docs/apache-airflow/stable/best-practices.html#top-level-python-code
書いてある通りなのですが、DAGを構成するPythonファイルのトップレベルで無意味な重い処理を書かないようにしましょう。
特に見落としがちなのが、import処理に関しても同様なので注意が必要です。以下のようにtensorflowやtorchなどLoadに時間のかかるライブラリはBad exampleの様なimportは避けて、Good exampleの様にタスク関数内で呼び出すのがべスプラになります。
import random |
import random |
なぜこれが良くないかと言うと、Airflowでは各DAGを管理し、時間通りに実行できるようにスケジュールする管理役のSchedulerコンテナが存在しており、このコンテナが定期的にデプロイ済みのPythonファイルを実行可能かどうかを解析しています。そのため、トップレベルに重い処理があると解析時間が伸びてしまい、ワークフローのスケジュールに影響を及ぼしてしまいます。
Airflow scheduler executes the code outside the Operator’s execute methods with the minimum interval of min_file_process_interval seconds. This is done in order to allow dynamic scheduling of the DAGs - where scheduling and dependencies might change over time and impact the next schedule of the DAG. Airflow scheduler tries to continuously make sure that what you have in DAGs is correctly reflected in scheduled tasks.
Airflow Variablesの呼び出し
https://airflow.apache.org/docs/apache-airflow/stable/best-practices.html#airflow-variables
こちらも前章と似たような内容ですが、トップレベルでAirflow Variablesの呼び出しはできるだけ少なくしましょう。理由としては、ネットワーク上の呼び出しやデータベースへのアクセス処理が伴うため、こちらもスケジューラの定期的な解析処理に影響を及ぼします。
Using Airflow Variables yields network calls and database access, so their usage in top-level Python code for DAGs should be avoided as much as possible, as mentioned in the previous chapter, Top level Python Code.
コマンド回り
デプロイにはgcloud storage rsyncを使う
Cloud ComposerにDAGをデプロイするには、環境が指定するGCS Bucketへファイルを配置する必要がありますが、いちいち手動でやっていると事故ることが多いです。そこで、GitHubやGitLabなどの本番用ブランチをSingle Source of TruthとしてJenkins、GitHub Actions、GitLab CIなどでデプロイ用のJobを用意すると思います。その際、gcloud storage cpでDAGをコピーするよりもgcloud storage rsyncがお勧めです。
https://cloud.google.com/sdk/gcloud/reference/storage/rsync
理由としてはgcloud storage rsyncはコピー元を正として、コピー先を同じ状態にします。そのため、本番ブランチから削除されたDAGのPythonファイルは削除され、運用中のDAGのみがディレクトリへ残ることになります。
もちろんDAG内でschedule_intervalをNoneにすることでも無効化はできますが、常にAirflowの環境に運用中のワークフローのみを置きたい場合はこれできれいな状態を保つことができます。
Airflow CLIを使う
AirflowにはCLIが用意されており、例えばAirflow UI内での操作権限を制御(AdminやOpの付与)するためにコマンド操作が必要となります。これらのコマンド操作はgcloudコマンド経由でAirflowのCLIにアクセスすることができます。
https://cloud.google.com/composer/docs/composer-2/access-airflow-cli?hl=ja
https://cloud.google.com/composer/docs/composer-2/airflow-rbac?hl=ja
リソース周り
Cloud Composerは結構お金のかかるサービスなので、初期構築時にリソースをできるだけ抑えたくなります。ただ、抑えすぎるとAirflowが処理し切れなくなり、スケジュールされていたが実行されなかったゾンビタスクと呼ばれるエラーが発生します。
ゾンビタスクは、実行されるはずであるが実行されていないタスクです。これは、タスクのプロセスが終了済みか応答していない場合、Airflow ワーカーが過負荷のためにタスク ステータスを時間内に報告しなかった場合、またはタスクが実行された VM がシャットダウンされた場合に発生します。Airflow はそのようなタスクを定期的に検出し、タスクの設定に応じて、失敗するか、再試行します。
https://cloud.google.com/composer/docs/composer-2/troubleshooting-dags?hl=ja#zombie-tasks
自分もゾンビタスクには散々苦しめられましたので、その中で得られたTipsを紹介します。
WorkerやSchedulerの初期値
Cloud Composer環境を構築する際、WorkerやSchedulerのCPUコア数やメモリを予め決める必要があります(もちろん、後から変更できます)。
その場合、実装予定のDAGの数をある程度想定し、それらDAGを並列に実行したい数やタスクを並列に実行したい数から以下のように逆算することができます。
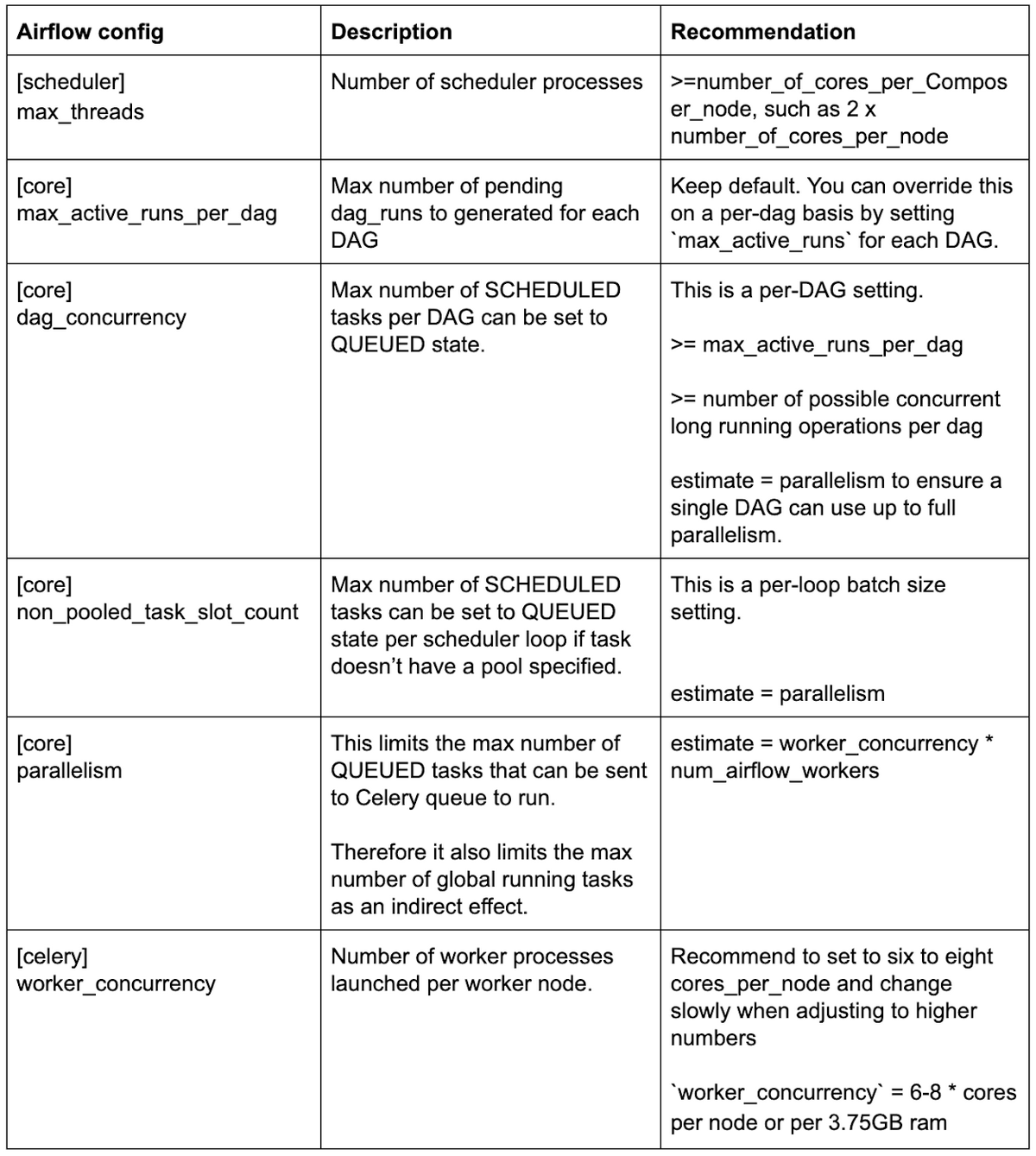
Airflowの各パラメータの決め方
画像引用元:https://cloud.google.com/blog/ja/products/data-analytics/scale-your-composer-environment-together-your-business
Schedulerのリソース侮るなかれ
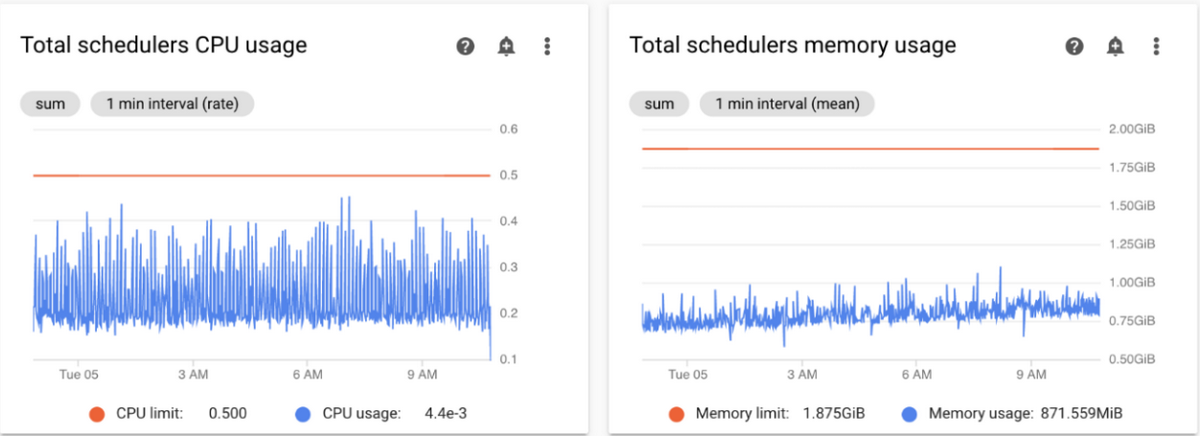
Schedulerのリソース使用状況
画像引用元: https://cloud.google.com/composer/docs/composer-2/optimize-environments?hl=ja
ゾンビタスクが発生した際、ワークフローを実行する主体であるWorkerに関してはCPUやメモリの使用率に対して感度高く見るかと思います。もちろんWorkerのリソース不足に起因する場合が多いのですが、ワークフローのまとめ役であるSchedulerが起因している場合もあるので、CPUやメモリの使用率が高くなっていないか気を配ってあげてください。SchedulerのCPU使用率が常に上限に張り付いてしまい、DAGが予定通りスケジュールされなかった!みたいなケースを何度か見てきました。
もしお金に余裕がある場合は、SchedulerのPodを2台構成にするのもおススメです。予測できないタイミングでSchedulerの再起動(クラッシュ?)が発生し、1台構成がゆえにスケジューリングに失敗してしまったというパターンもありました。
Airflowデータベースのクリーンアップを導入する
実運用の中でAirflowデータベースへのアクセスが発生しないので見落とされがちなのですが、Airflowでは時間の経過とともに環境のAirflowデータベースに保存されるデータが増えていきます。蓄積されるデータは過去のDAG実行やタスクなどオペレーションに関連する情報で、ほとんどのケースで恒久的に必要となる情報ではありません。
そしてドキュメントには以下のように記載されており、データベースのストレージはなるべく圧迫しないようにしておく必要があるようです。
- Airflow データベースのサイズが 16 GB を超える場合、環境を新しいバージョンにアップグレードすることはできません。
- Airflow データベースのサイズが 20 GB を超える場合、スナップショットを作成することはできません。
また、これはサポートケースへの問い合わせの中でご教示頂いたのですが、データベースクリーンアップがゾンビタスク撲滅にある程度の効果を発揮するとのことでした。
導入方法は以下で紹介されており、基本的にコピペしてデプロイするだけなので是非導入してみてください。
https://cloud.google.com/composer/docs/composer-2/cleanup-airflow-database?hl=ja
/dataにはなるべくファイル放置しない
タスクが生成して使用するデータを保存するのにCloud Composer環境のGCS Bucketにはdataというディレクトリが存在します。
https://cloud.google.com/composer/docs/composer-2/cloud-storage?hl=ja#folders_in_the_bucket
Cloud Composerの全体アーキを見るとわかるのですが、このGCS BucketはGCS Fuseを介してSchedulerやWorkerのPodに中身が同期される仕組みとなっております。
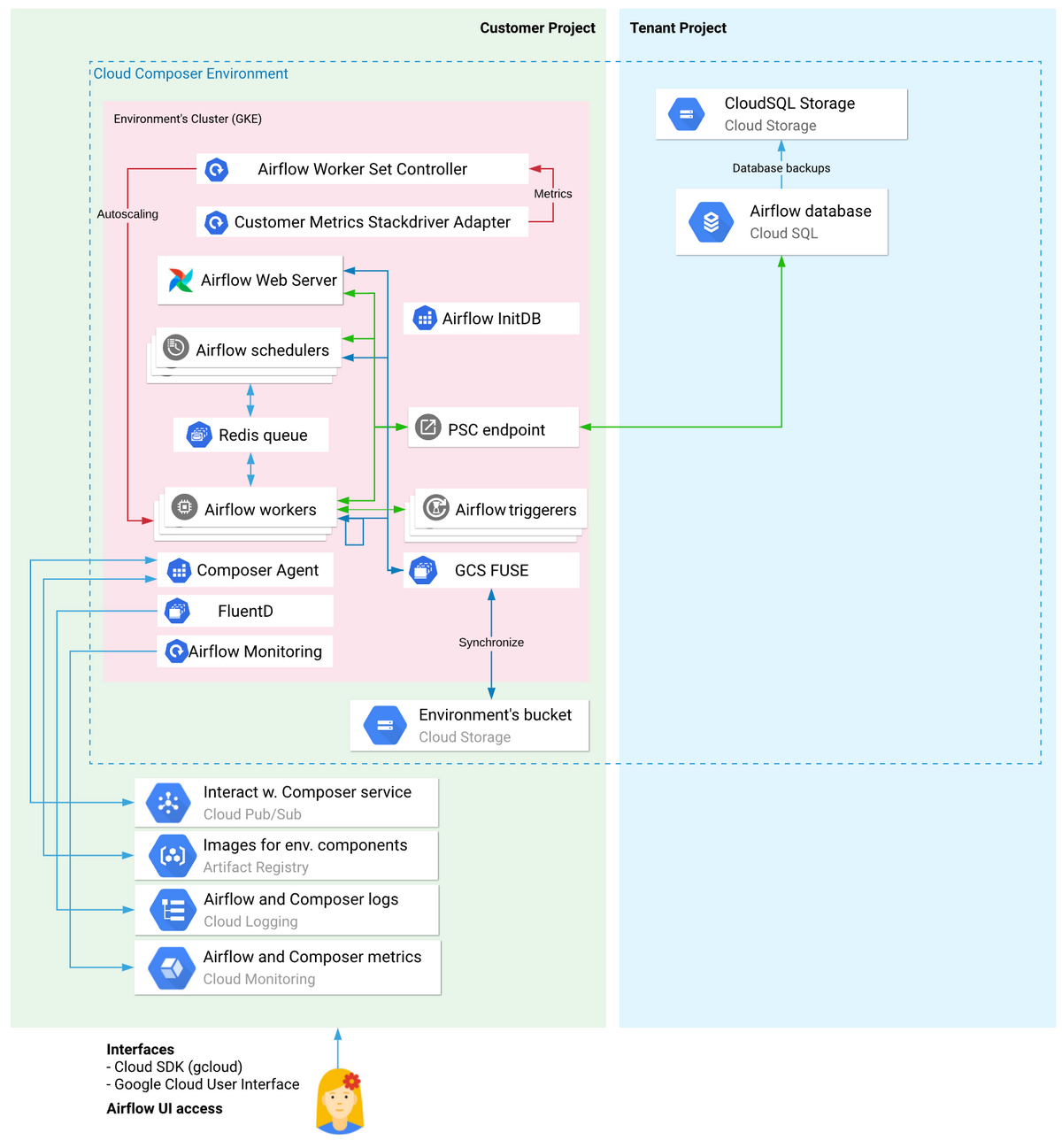
プライベートIP環境のアーキテクチャ
画像引用元:https://cloud.google.com/composer/docs/composer-2/environment-architecture?hl=ja
/data配下に関してもGCS FuseによってSchedulerやWorkerのPodへ同期される仕組みとなっており、過去に生成したファイルが大量に/data配下に残っていると同期のパフォーマンスに影響を及ぼす可能性があります。実際にGCS Fuseが大暴れして障害に発展したパターンも遭遇しました。
/dataに配置したファイルは用が済み次第、削除するように心がけましょう。
まとめ
Cloud ComposerもといApache Airflowを運用する中で得られたTipsを主にインフラの観点で紹介しました。
これらのTipsがAirflow運用者の一助になれば幸いです。
アイキャッチ画像はGoogle Cloud公式ページ、Apache Airflow公式ページからの引用させて頂きました。