本記事の前提
読んでほしい人
- Transformerを知っていて、その理解を深めたい人
- 大規模言語モデル (LLM: Large Language Model) がどのようにして推論しているのかを知りたい人
触れている内容
- ユーザが質問をして、Transformerが回答を生成するまでの一連(end-to-end)の処理
- Transformerの仕組みについて広く浅く
触れていない内容
- 学習時に行われる処理(MaskやDropoutなど)
- Pythonなどのプログラミング言語を用いたTransformerの実装方法
最初に「構成図」で理解する
まずは元論文「Attention Is All You Need」から引用したTransformerの構成図を図1に示します。
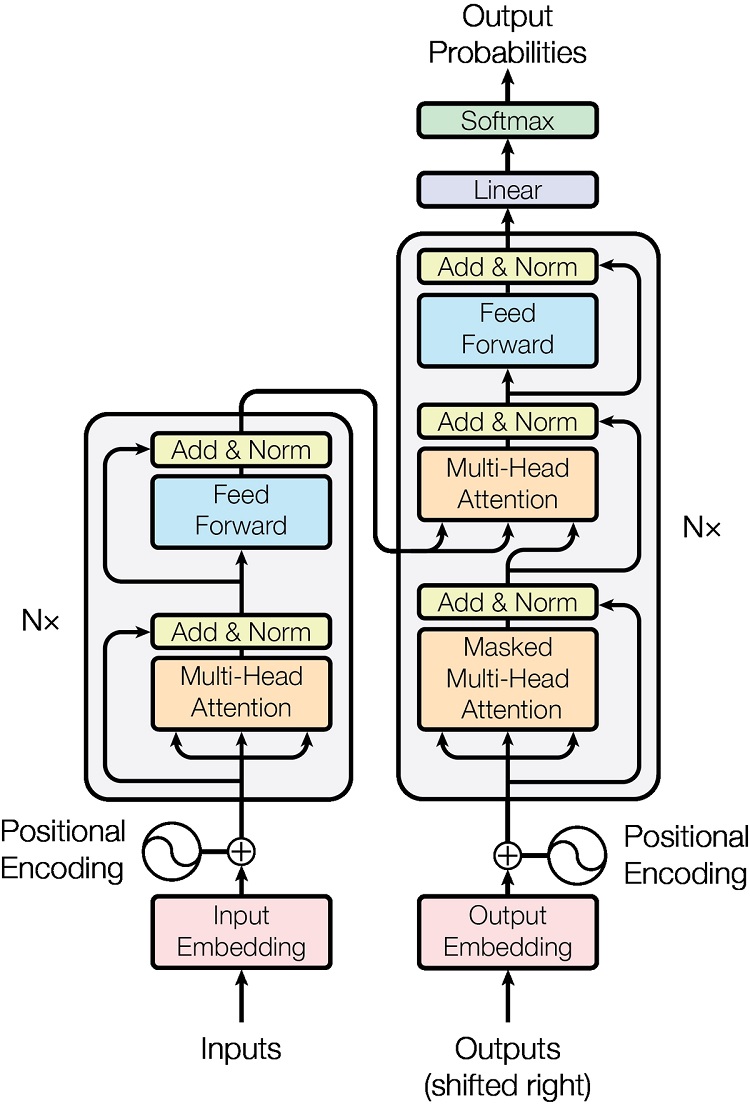
図 1.元論文から引用したTransformerの構成図
とても簡潔ですが、図からは理解できない内容が多々あるかと思います。そのため、少しだけ具体化した構成図を図2に示します。できるだけ見やすく作りたかったのですが、どうしても複雑になる箇所があるため、拡大して見ていただければと思います。図2の補足ですが、EmbeddingやLinear、Layer Normalization、Softmaxは行方向(=各Tokenのベクトル方向)に対して行われる処理であることに注意してください。
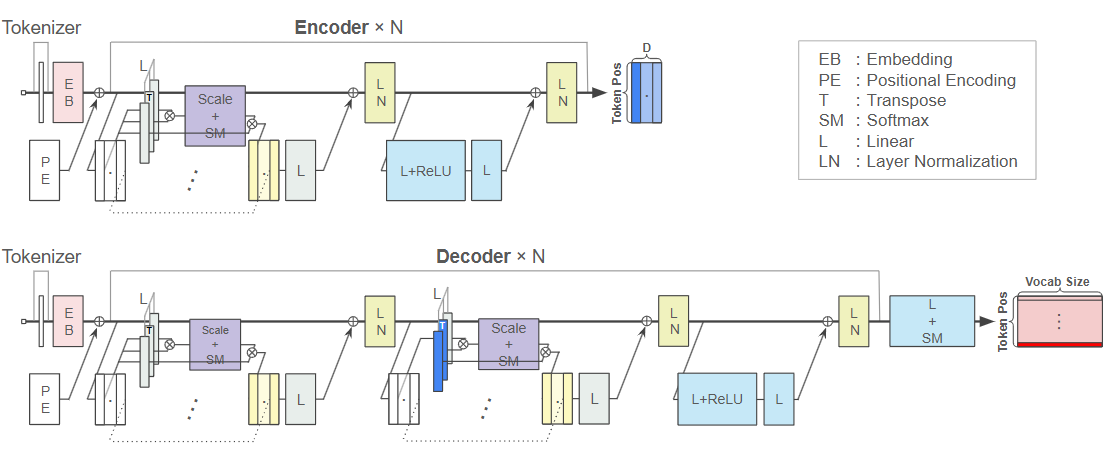
図 2.私が作った、元論文の構成図を具体化させたTransformerの構成図
次に「処理フロー」で理解する
前章で示した構成図だけでは説明が不十分であるため、次は処理フローの側面から理解を深めていただこうと思います。図2と照らし合わせながら読み進めていただくと理解しやすい気がします。
※以下の処理フローの「3-1-2~4」や「6-3-2~4」で出てくるQ,K,VはそれぞれQuery,Key,Valueのことです。図3に図2の構成図内のどれがQ,K,Vなのかを示します。
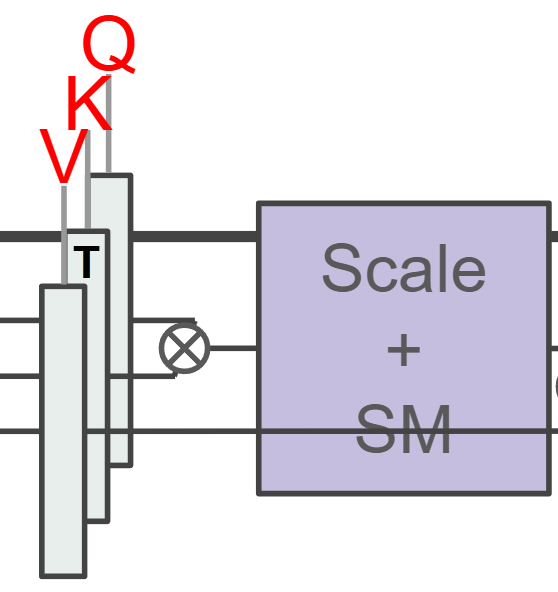
図 3.図2のQ,K,Vの対応
1.質問を入力 |
最後に「各処理の深掘り」で理解する
これまで「構成図」と「処理フロー」で見てきましたが各段階の処理を深ぼる説明がありませんでした。そのため、最後にTransformerで利用されている処理を軽く解説します。本章で触れるのは以下の処理です。
- トークナイザ(Tokenizer)
- 潜在表現(Latent Representation)
- 埋め込み(Embedding)
- 線形/全結合(Linear/Fully Connected)
- 位置符号化(Positional Encoding)
- 注意機構(Attention)
- マルチヘッド注意機構(Multi-Head Attention)
- スケール化内積注意機構(Scaled Dot-Product Attention)
- 自己注意(Self-Attention)
- 相互注意(Cross-Attention)
- 正規化(Normalization)
- レイヤー正規化(LN:Layer Normalization)
- 活性化関数(Activation Function)
- ReLU:Rectified Linear Unit
- 出力関数(Output Function)
- Softmax
トークナイザ(Tokenizer)
Transformerは入力された文章(自然言語)のまま扱うことができません。
代わりに「Token」というものを扱います。Tokenとは文章を「Subword」に分割したものを指します。例えば「日本の首都は?」が入力された場合、「[日本, の, 首都, は, ?]」のように単語単位(Subword)に分割し、「[1234, 654, 58295, 219, 179]」のように 各自然言語に対応する ID に変換します。
この処理を行うものが「Tokenizer」であり、「Word Piece」や「BPE: Byte Pair Encoding」が有名です。「Learn about language model tokenization」ではGPT4やGPT4oのTokenizerのデモができます。
このサイトのTokenizerはBPEベースの「Tiktoken」というモデルを利用しています。
埋め込み(Embedding)
Tokenizerで得たTokenの潜在表現を抽出します。例えば「[1234, 654, 58295, 219, 179]」のようなTokenを「[[1.0, 0.2, ..., 0.3], [0.4, 0.2, ..., 1.0], [0.2, 0.2, ..., 0.1], [0.5, 0.3, ..., 0.7], [0.9, 0.2, ..., 0.1]]」のように、各Tokenの値をD次元に拡張します。そうすることで、類似した意味を持つTokenを同じ方向や、同じ大きさのベクトルとして表現することができます。
Embeddingは事前に学習された重みを利用することもあります。
線形/全結合(Linear/Fully Connected)
学習可能なパラメータを利用して入力した潜在表現を変換します。学習可能なパラメータの数は調整することができ、この調整次第で変換後の次元数を増減させることができます。
位置符号化(Positional Encoding)
Embeddingで得られた潜在表現には 時系列情報がありません。これは「[日本, の, 首都, は, ?]」と「[の, 首都, ?, 日本, は]」が同じ文章と言っているようなものです。そのため、時系列の意味合いを持つ値を各潜在表現に加算することで時系列情報を付与します。
Embeddingで得られた潜在表現に悪影響を及ぼさない大きさで、相対的な変化を持たせやすい値を加算する必要があります。元論文では以下の式で算出される値を加算しています。sinとcosの1波長は2πであるため、「pos = 2π*10000」が一意の位置情報を付与できるToken数の上限であることがわかります。
マルチヘッド注意機構(Multi-Head Attention)
次で説明する「Scaled Dot-Product Attention」をN個に分割して処理するための機構です。
Embeddingで各TokenをD次元に拡張しますが、分割がない場合、1点の尺度でToken間の関連度を求めることになります。Multi-Head Attentionを導入し、D次元をN個に分割して並列で処理させることで、N点の尺度でToken間の関連度を求めることができるようになります。
これがMulti-Head Attentionの強みです。各ヘッドの次元数は「D/ヘッド数」です。
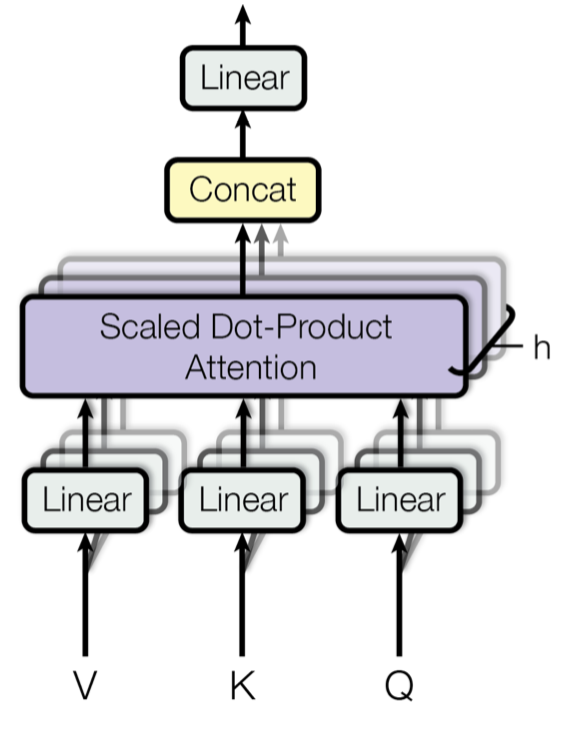
図 4.元論文から引用したMulti-Head Attentionの構成図
スケール化内積注意機構(Scaled Dot-Product Attention)
トークン間の類似度を内積で求めます。はじめに、QとKで行列積をとり、Dの平方根で除算します。Dの平方根を除算している理由はQとKの行列積の値を標準化するためです。
行列積の値はDの値が大きくなるほど最大値が大きくなります。それだと学習が進まなくなるため、Dの平方根を除算して学習の安定化をしています。次に、除算した行列とVで行列積をとり、後で説明するSoftmax関数に通すことでトークン間の類似度が確率分布で求まります。
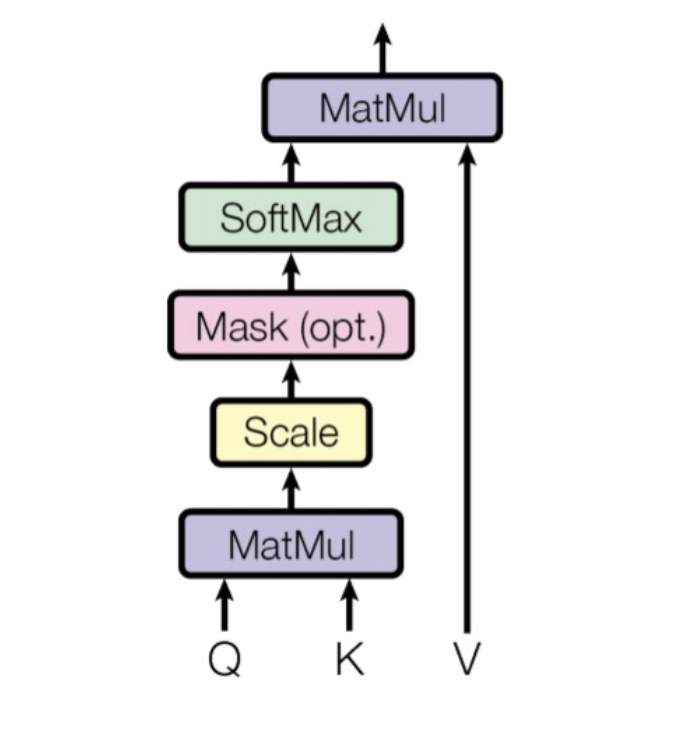
図 5.元論文から引用したScaled-Dot Product Attentionの構成図
Transformerでは「自己注意(Self-Attention)」と「相互注意(Cross-Attention)」が登場します。Self-AttentionとはEncoderとDecoderで登場し、「Q」と「K」と「V」に同じ行列を与える方法です。Cross-AttentionとはDecoderでのみ登場する「Q」と「KとV」で異なる行列を与える方法です。
レイヤー正規化(LN:Layer Normalization)
各Tokenのベクトル方向に正規化行う手法です。正規化手法には他にもBatch NormalizationやInstance Normalizationなどありますが、入力長が可変のTransformerではInstance Normalizationが有効です。
ReLU:Rectified Linear Unit
非線形変換を行う関数です。0以下の入力を0にするだけのシンプルな関数です。ReLUの傾きは0か1なので、層を増やしても勾配を消失させにくい特性があります。(最近は活性化関数として使われることが少なくなりましたが、Sigmoid関数は傾きの範囲が0~0.25で、層が増えると勾配が0になってしまう「勾配消失問題」が発生します。)
Softmax
行列の和が1.0(100%)になるように確率分布に変換します。Transformerではvocab size分の単語が生成対象として存在しています。eで計算している理由は、出力がマイナスにならないことや微分してもeのままであること、値の強調(=非線形な変化)が可能なことがあります。
おわりに
Transformerの仕組みを「構成図」「処理フロー」「各処理の深掘り」で解説してきました。今回は推論の処理の理解を深めることができましたが、学習時の理解はまだできておりません。今後は学習時の理解も深め、続編を出したいなと思っています。少しでも皆様のTransformerの理解を深めることへの手助けになれば幸いです。