※担当チーム都合で、記事の公開が執筆次期から期間を空けてしまいました。
当時から変更がある可能性がある旨はご承知おきください。
初めに
こんにちは、SAIG/MLOpsチームでインターンをしていた菅野です。
データ処理やデータ管理を効率化できるAzure Data FactoryとAzure Purviewを検証しました。
背景
MLOpsとは
近年、チャットボットによる問い合わせ対応や、ECサイトのレコメンデーションなど機械学習を用いたサービスが増えるとともに、これらのシステムを効率的に運用することが重要になってきました。
そこで重要になってくるのがMLOps(Machine Learning Operations)です。MLOpsは、機械学習(ML)プロジェクトのライフサイクルを管理・効率化するために、DevOpsの原則を適用する概念です。機械学習のプロジェクトにおいて、モデルの作成・学習は全体の一部であり、他の作業が大きな割合を占めています。下記の画像はビジネスにおける機械学習に関して書かれた有名な論文から引用したものです。モデル作成はシステムの一部であり、モデル作成以外が大きな割合を占めていることが分かります。MLOpsは、そのような周辺の作業を含めた、機械学習プロジェクト全体の作業を効率化し、コスト削減をするためのものです。
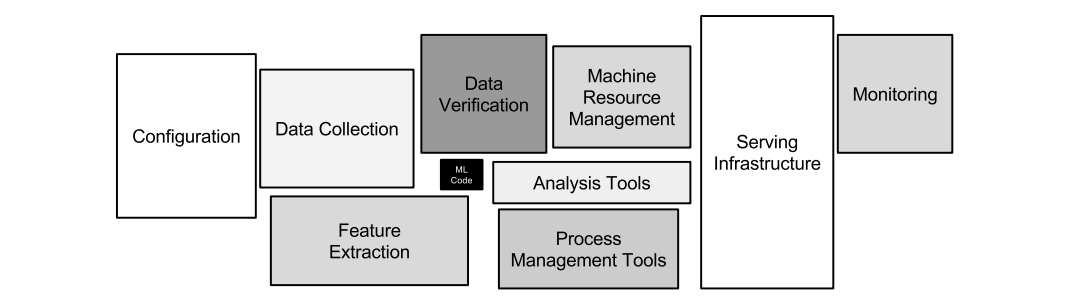
▲ 「Hidden Technical Debt in Machine Learning Systems」(D.scully らNIPS 2015)より引用
本記事ではMLOpsを推進するためのツールとして、Azure Data FactoryとAzure Purviewについて検証します。
RAG(Retrieval Augmented Generation)
様々なタスクをこなせる便利な生成AIですが、こなすことができないタスクもあります。それは学習データに含まれていない情報に基づく回答を生成することです。
生成AIは公開されているテキストデータを基に訓練されており、そこに含まれていない情報に関しては知識を持っていません。例えば、自社の社内規定や議事録について質問しても正しく回答ができません。
この課題を解決するためによく用いられる手法が RAG(Retrieval Augmented Generation) です。RAGを用いることで、生成AIが社内情報などに基づいた回答できるようになります。
RAGには、検索フェーズと生成フェーズの2段階が存在します。
- 検索フェーズ: 生成AIにない知識を補うために、自社に蓄積された社内情報や外部の最新情報を取得します。
- ユーザーが質問を入力
- 入力された質問に関する情報を検索
- 検索結果データを取得
- 生成フェーズ: 検索フェーズで取得した文章と、ユーザーの質問文の2つを生成AIに入力することで回答を生成します
- ユーザーの質問と3で取得した検索結果データを生成AIに入力
- 入力されたデータをもとに、生成AIが回答を作成
- 作成された回答をユーザーに出力
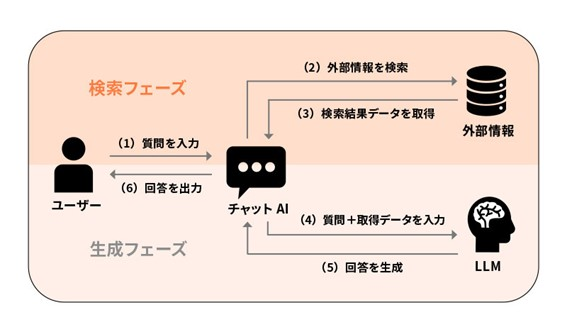
▲ RAGとは?仕組みと導入メリット、使用の注意点をわかりやすく解説
このようなRAGシステムを導入するにあたって、課題となるのは検索フェーズの精度です。入力された質問に関連する情報を検索する際の精度が、RAGシステムの品質に直結します。そこで本記事では、優秀な検索エンジンと噂の、Azureサービスで提供されているAzure AI Searchを用いてRAGシステムを運用することを想定します。
また、Azure AI Searchで効率的な検索するためには事前にチャンキングや、エンベディングなどの前処理を行いインデックスに登録しておく必要があります。
インデックスの詳細は以下のサイトを参照してください。
- 検索インデックスの概要 - Azure AI Search | Microsoft Learn
- 基本概念から理解するAzure AI Search - Azure OpenAI Serviceとの連携まで - 電通総研 テックブログ
Azure AI Searchを用いたRAGにおける課題
優秀な検索エンジンであるAzure AI Searchですが、RAGを実現する際に2つ課題があります。
Azure AI Searchが非Azureサービスとの連携に弱い
Azure AI Searchは、インデクサーというコンポーネントを用いて、データの読み込みからインデックスに登録するまでを自動化できます。これにより手作業でAzure AI Searchにデータを登録する必要がなくなり運用コストを抑えることができます。
どのような前処理を経て、Azure AI Searchに登録されたのかわからない
Azure AI Searchのインデックスに登録するためには、チャンキングや、テキストをベクトルに変換するエンベディングなどの前処理が必要になります。しかし現状のシステムだと、どのような前処理を経てAzure AI Searchに保存されたのかがわからなく、正確性が担保できません。
目的
上記の課題を解決することが本検証の目的となります。本記事では、Azure Data FactoryとAzure Purviewを用いて、課題解決を目指します。
- Azure Data Factoryを用いて、複数データソースからAzure AI Searchに登録
多様なデータベースと連携ができるAzure Data Factoryを用いて、Azure AI Searchが連携できないデータベースと連携し、前処理を行ったうえで、Azure AI Searchに保存します。またAzure Data Factoryの自動トリガー機能やアラート機能を活用してコスト削減する。 - Azure Purviewを用いて、リネージ管理
どのデータを基に、どのような前処理を経て、どのファイルに保存したのかを記録し管理することをリネージ管理といいます。このリネージ管理をAzure Purviewの機能を用いて実現します。
ツールの紹介
今回検証するAzure Data FactoryとAzure Purviewについて紹介します。
Azure Data Factoryとは
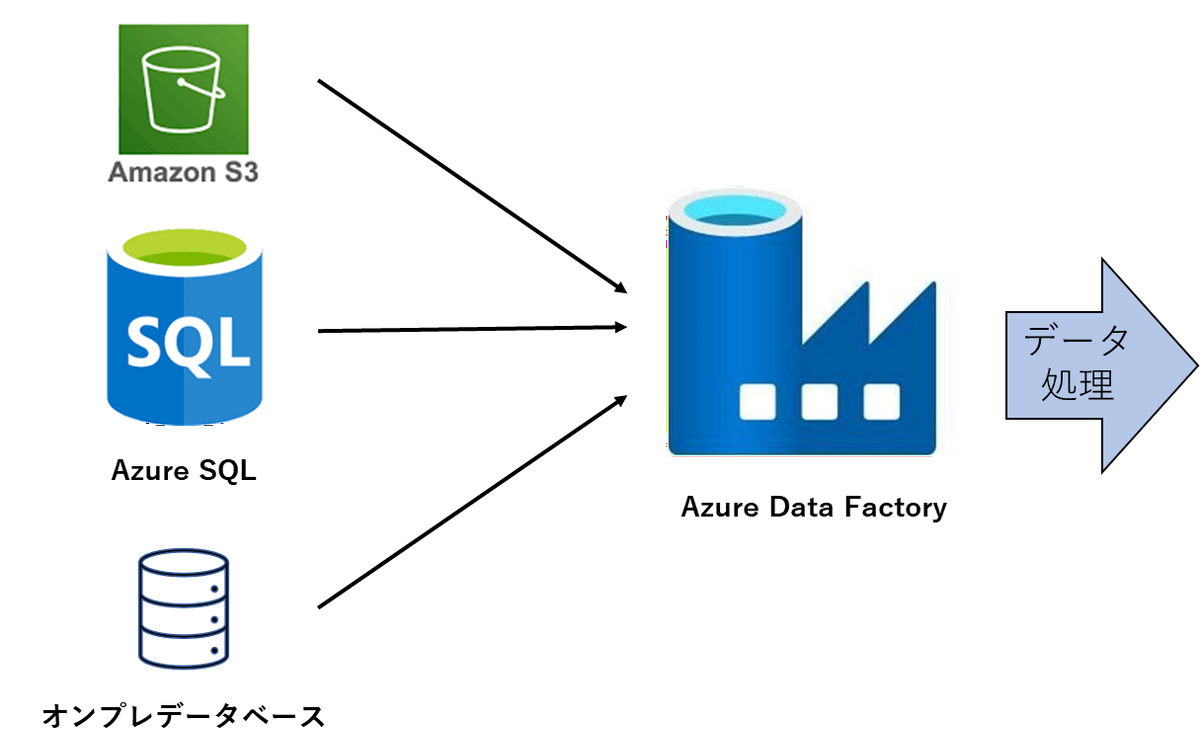
Azure Data Factoryは、Microsoftが提供するクラウド型のデータ統合サービスで、オンプレミスにあるデータやクラウド上にあるデータを効率的に移動・変換・統合が可能です。Azure Data Factoryを利用することで、異なるデータソースからのデータを収集・統合・変換して、機械学習モデルの訓練や評価に必要な形式に整えることができます。
▼参考:Azure Data Factory とは何ですか。
Azure Logic Appsとの違い
データの統合や自動化を目的としたツールとして、Azure Data Factoryに類似したツールであるLogic Appsがあります。ユースケースに合わせて使い分ける必要があります(参考)
大規模なデータ処理を行う際はAzure Data Factory、軽量な処理などにはLogic Appsを用いるイメージです。
| 特徴 | Logic Apps | Azure Data Factory |
|---|---|---|
| 目的とユースケース | イベント駆動型アプリ・ビジネスプロセスの自動化 | 大規模データ処理・高度なETL/ELT処理 |
| データ処理のスケーラビリティ | 軽量なデータ処理・リアルタイムイベントの処理 | 高スループットのデータ処理・バッチ処理 |
| コネクタとサービスの統合 | SaaSアプリ・APIとの広範な統合 | データの移動と変換を中心に多くのデータソースに対応 |
| ワークフローの自動化 | ビジネスプロセスの多段階自動化 | データパイプラインの設計・自動実行 |
Azure Purviewとは
Azure Purviewは、オンプレおよびクラウドに散在しているデータを管理し、統制する「データガバナンス」ソリューションです。主に、データの保護、データソースを跨いだデータ検索、データがどのように処理されたのかを管理するデータリネージの機能などがあります。本検証では特にデータリネージ機能について検証します。
Azure Data FactoryとAzure Purviewでできること
Azure Data Factoryを用いることで、様々なデータソースからデータを取得して処理を行うことができます。
またAzure Data FactoryとAzure Purviewを組み合わせることで、データ処理とデータ管理にかかる人的コストを削減ができます。
1. コスト削減
Azure Data Factoryでは、インフラの管理やメンテナンスが不要です。また、データ処理を自動化することで、エンジニアが定期的にプログラムを実行する手間を省くことができます。さらにAzure Purviewを用いることで、どのデータからどのようなプロセスを経て作成されたかなどのリネージ管理をおこなうことができます。データの正確性を担保することでデータの再利用がしやすくなり、再びデータ処理などをする手間がなくなります。
2. データの一元化
Azure Data Factoryは多様なデータソース(オンプレミスやクラウド、構造化データや非構造化データ)をサポートしており(参考:対応しているデータソース)、簡単にデータを取り込み、統合ができます。一度登録したデータソースであれば、すぐに呼び出して使うことができます。また、Azure Purviewを用いることでデータソースを跨いだデータの検索、参照できます。
3. 可視化
Azure Data FactoryとAzure Purviewにはビジュアルインタフェースがあり、データ処理のフローやデータ依存関係を視覚的に管理できます。これにより、処理の流れやデータの関係性を素早く理解ができます。
検証
本記事で検証したAzureのUIは2024年9月時点でのものです。
Azure Data FactoryとAzure Purviewの利用手順
初期設定
Azure Data FactoryとAzure Purviewで作業を始めるための設定の流れです。
Azureポータルでリソースを作成
以下のリソースを作成します。- Azure Data Factory
- Azure Purview
- キーコンテナ
- ストレージアカウント
Azure Purviewでコレクションを作成
Azure Purviewでは、コレクションごとに管理します。コレクションには複数のデータソースを登録でき、またアクセス制御などもコレクションごとに行えます。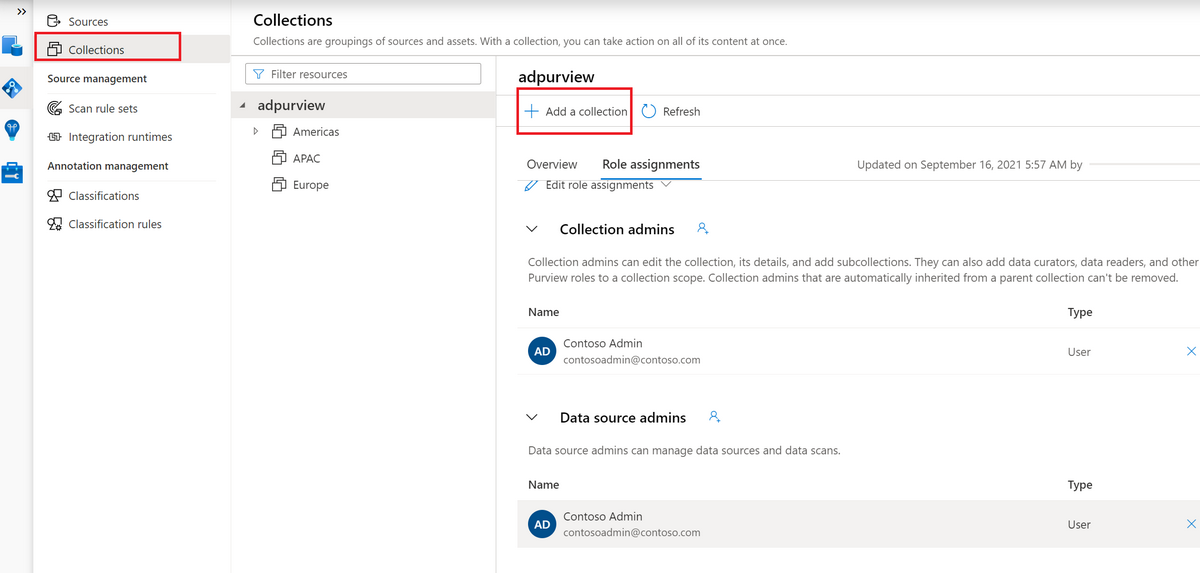
Azure Data FactoryとAzure Purviewの接続
Azure Purviewの「管理」画面から「系列接続」を選び、Azure Data Factoryの項目で設定します。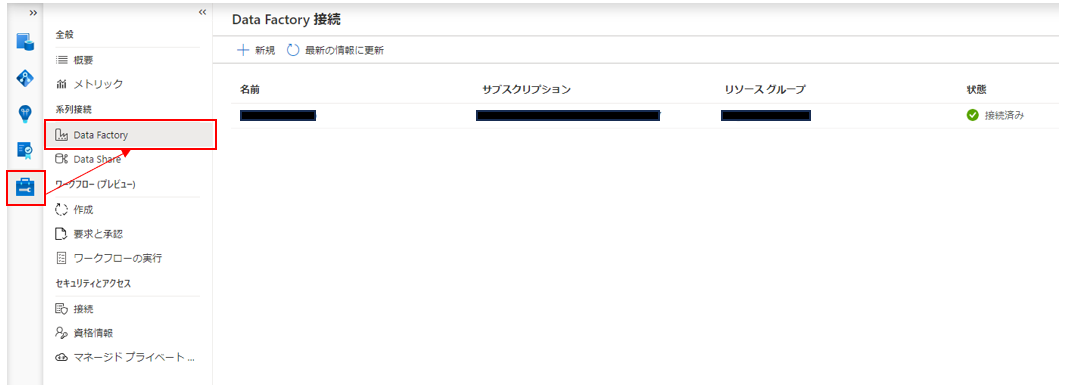
ストレージアカウントとAzure Purviewの接続
キーコンテナを使用して接続します- キーコンテナのアクセス権限を編集します
- アクセス制御画面で自分のAzureアカウントにキーコンテナ管理権限を付与
- アクセスポリシー画面でAzure Purviewリソースに「シークレットのアクセス許可」の「取得」権限を付与
- ストレージアカウントでアクセスキーを発行し、キーコンテナに登録します
- Azure Purviewでソースメニューの適切なコレクションから「登録」アイコンを選択し、新しいAzure Blobデータソースを登録します
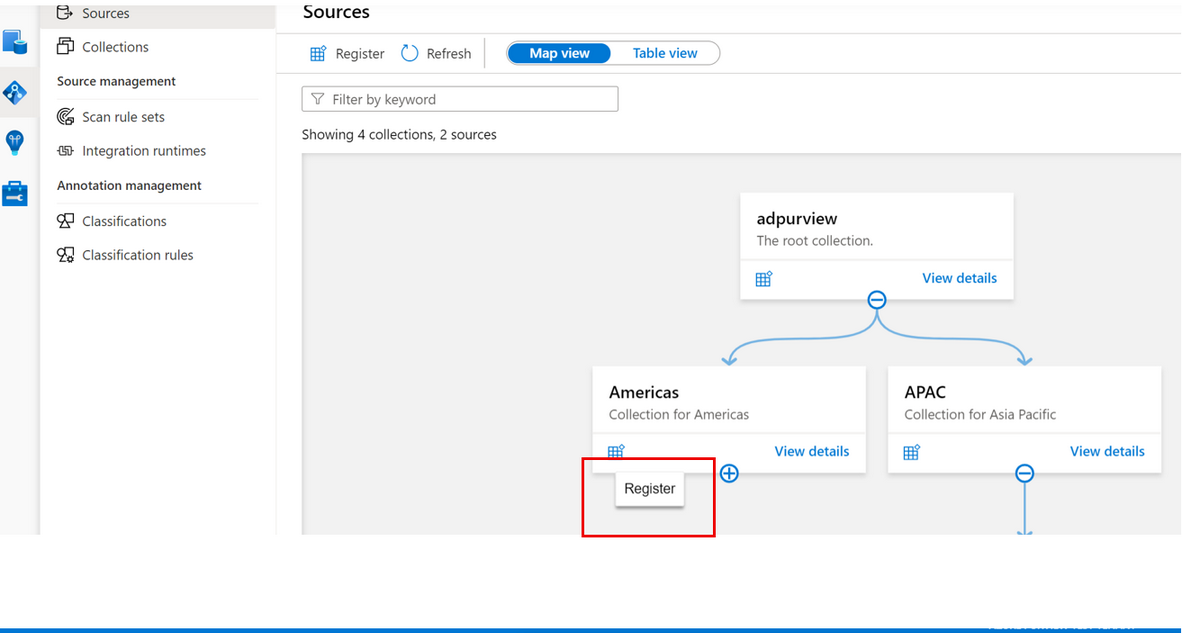
- キーコンテナのアクセス権限を編集します
Azure Data Factoryによるデータソースの登録
以下の手順で登録します。
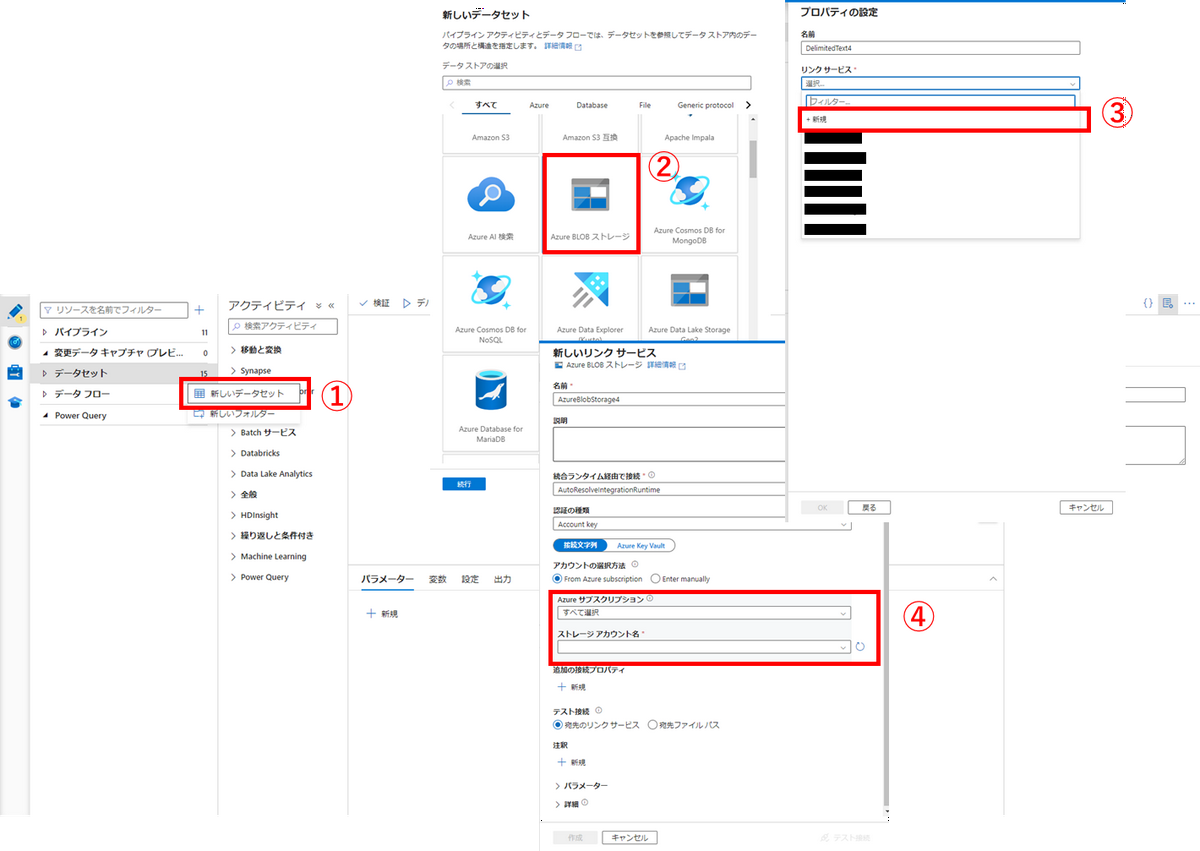
Azure Data Factoryによるパイプライン作成
Azure Data Factoryは、データセット、パイプライン、データフローという3つの要素から構成されます。
- データセット:各種データサービスとの連携を設定します
- パイプライン:データ処理全体の流れを記載します
- データフロー:実際にデータ処理を行います。パイプラインから呼び出します
パイプラインとデータフローには以下のアクティビティがあります。アクティビティとは、プログラミングにおける関数のようなもので、アクティビティ内に行いたい処理を記載し、それらを呼び出すことでデータ処理を行います。一度作成したアクティビティは再利用可能で、他のパイプラインやデータフローに使用できます。アクティビティに用意されていない複雑なデータ処理を行いたい場合は、Azure関数やDataBricksを呼び出すことで、コードベースによるデータ処理も行うことができます。
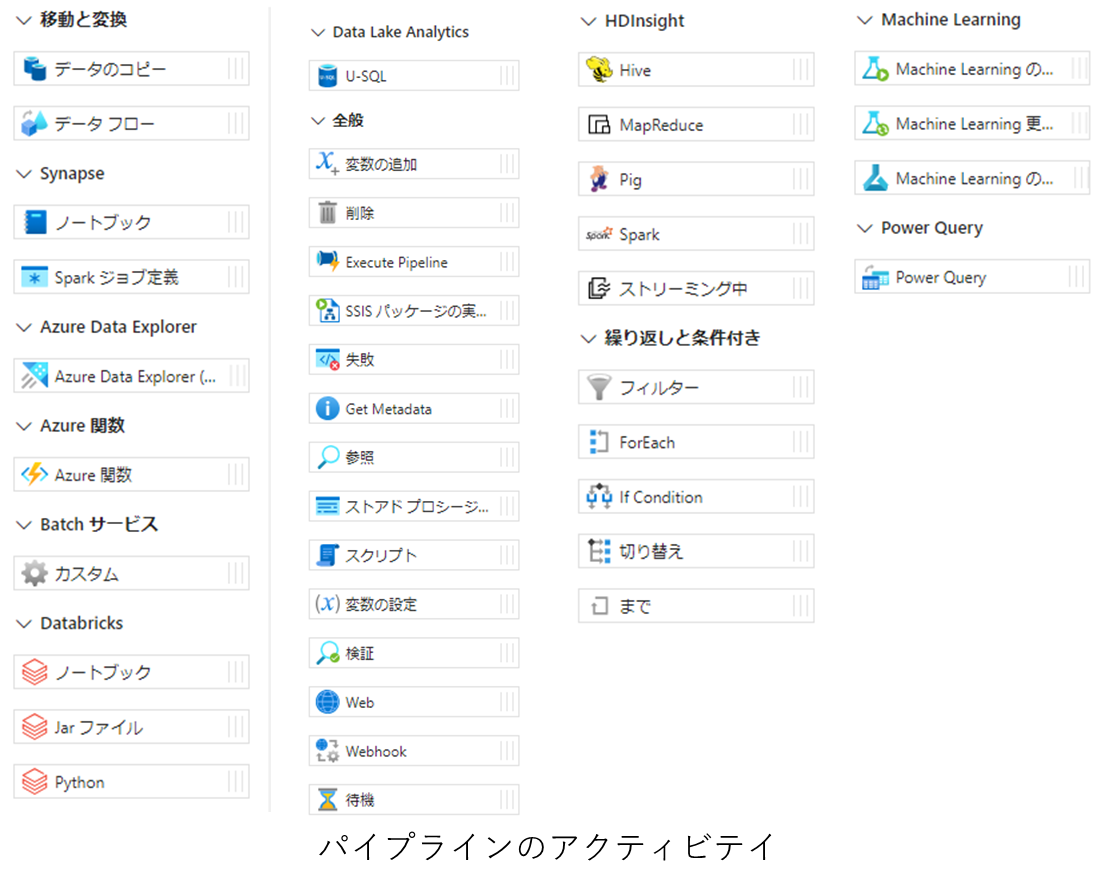
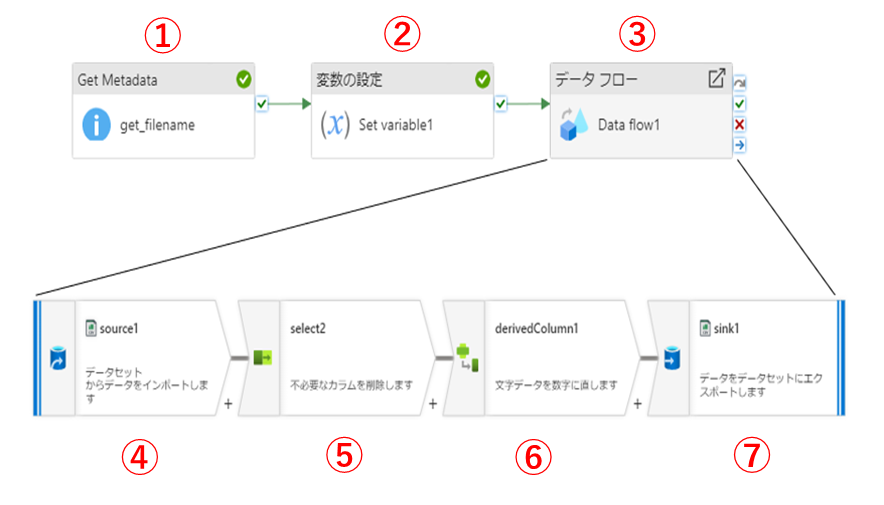
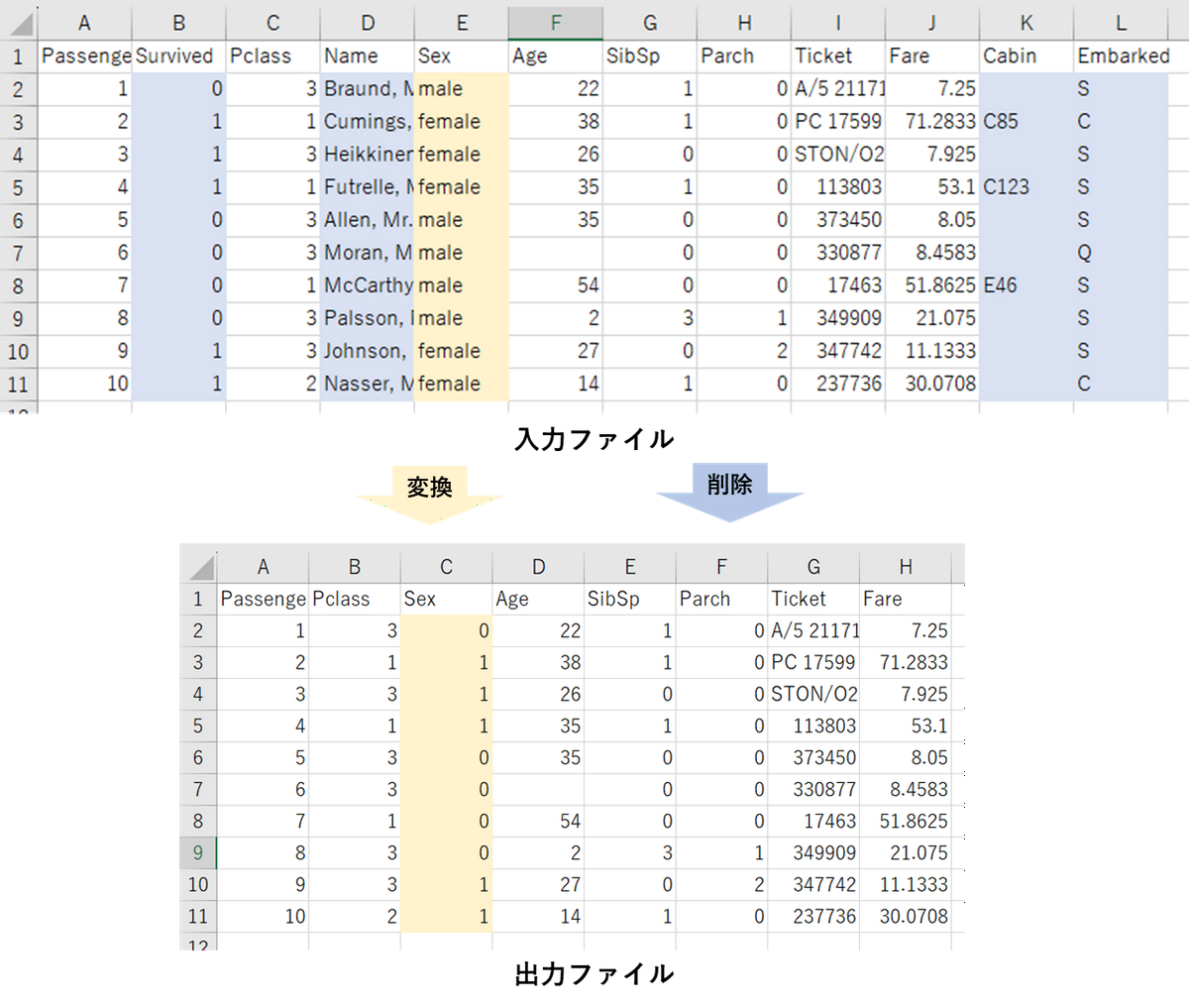
Azure Data Factoryに慣れるため、以下のようなパイプラインを作成しました。
- 特定のディレクトリからファイル名の一覧を取得します
- 取得したファイル名を変数に設定してデータフローに渡します
- データフローを呼び出します
- データを読み込みます
- 不要なカラムを削除します
- 「male」や「female」などの文字カテゴラルデータを数字に変換します
- 変換後のデータを保存します
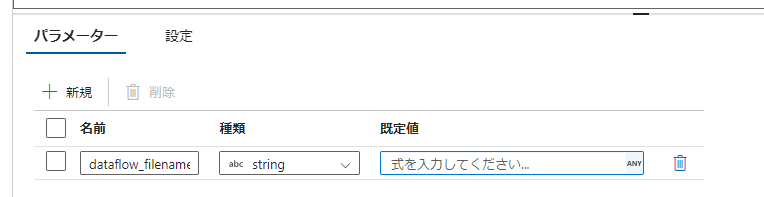
パイプラインで設定した変数やデータは、データフロー内で使えません。使いたい場合は、データフローのパラメーターに渡す必要があります。具体例を説明します。
まず、データフロー側でパラメーターを設定します。
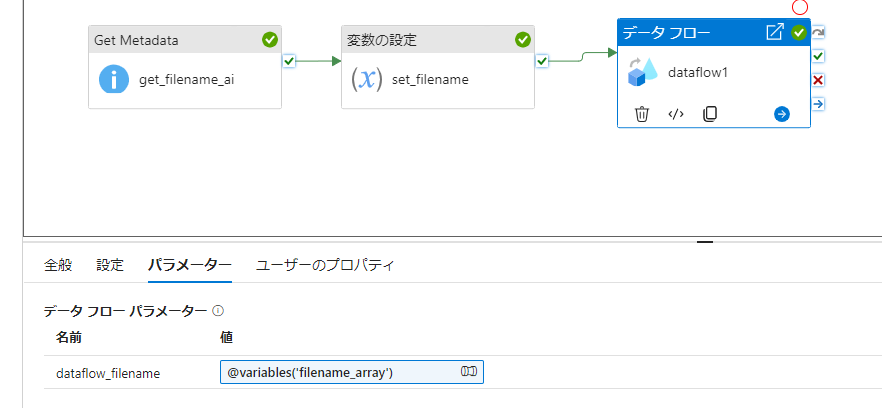
次に、パイプライン側からデータフローのパラメーターに変数を設定します。
Azure Data FactoryとAzure Purviewの動作確認
作成したパイプラインを用いて、Azure Data FactoryとAzure Purviewの機能を確認します。
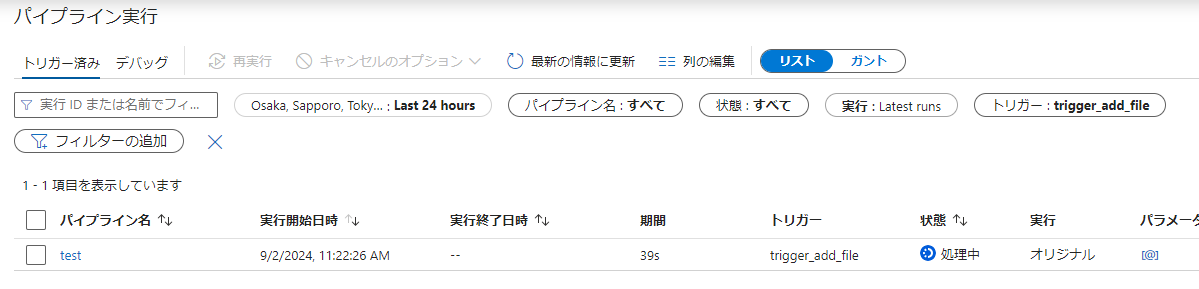
作成したパイプラインの処理結果
作成したパイプラインをKaggleのtitanicデータに対して、実行してみると正しくデータ処理を行えていることが確認できました。
パイプラインの自動トリガー
Azure Data Factoryで作成したパイプラインは、様々な方法で実行させることができます。
- API/SDKを使用した実行
.NET SDK、Azure PowerShell、REST API、Python SDKを使用してパイプラインを実行できます。(参考) - スケジュール
日時に関する条件をトリガーにパイプラインを実行できます。 - ストレージイベント
ファイルの追加/削除などのストレージに関する条件をトリガーにパイプラインを実行できます。 - カスタムイベント
自分で作成したトリガー条件によってパイプラインを実行できます。
今回はストレージイベントを使用して、指定したディレクトリにファイルが追加されたらパイプラインを実行するようにしました。3ステップで簡単に設定できます。
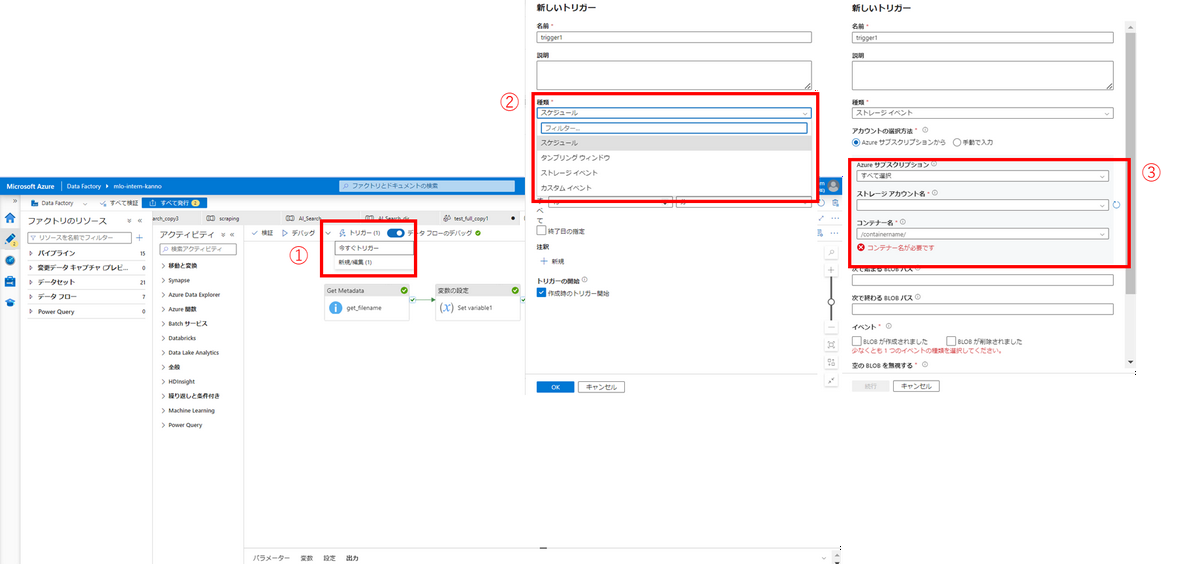
ディレクトリにファイルを追加すると、設定したしたトリガーによってパイプラインが実行されていることがわかります。
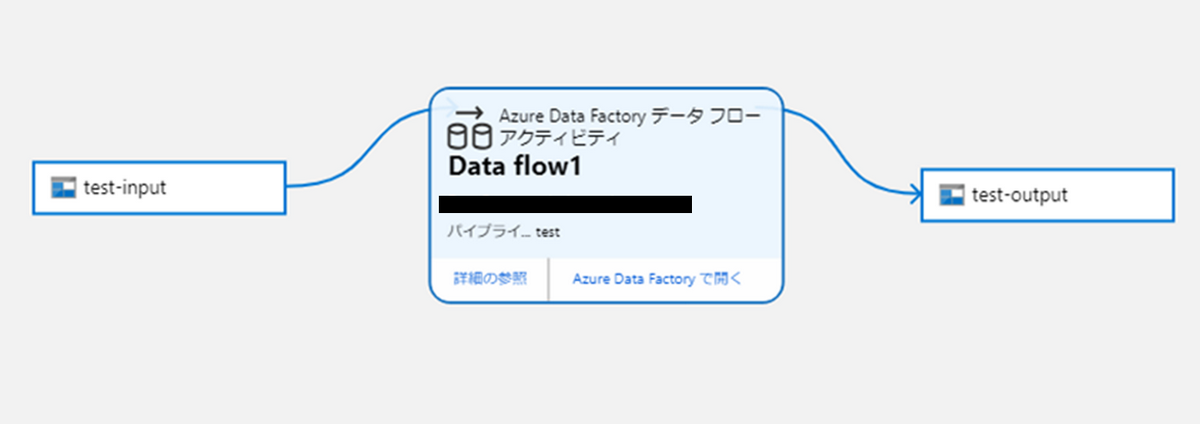
リネージ管理
接続しておいたAzure Purviewから、リネージを確認してみます。
test-inputが、Data flow 1で処理されて、test-outputに保存されていることが確認できます。
Data flow 1の処理内容が知りたいときは、「Azure Data Factoryで開く」をクリックすることで確認しに行けます。
Azure AI Searchのインデックスに登録
使い方が分かったところで、Azure Data Factoryを用いて、Azure AI Searchのインデックスにフューチャー技術ブログのテキストを登録してみようと思います。
初期設定
Azure AI Searchのインデックス登録のために、以下のリソースを作成します。
- Azure Open AI
作成したリソース内でテキストエンベディングのを行うモデルをデプロイします。今回はtext-embedding-ada-002モデルを使用します。 - Azure AI Search
手法
今回は以下の流れでテキストデータをAzure AI Searchインデックスに登録します。
- フューチャー技術ブログからテキストデータを取得/保存
- テキストファイルからテキストデータを取得
- Azure OpenAIでベクトル化
- 文章、タイトル、ベクトル等をAzure AI Searchインデックスに登録する
また 2~3 の処理をAzure Data Factory内で行うことで、Azure AI Searchに保存する処理までを自動化します。
Azure Purviewによって各データ処理を監視することで、リネージを管理します。
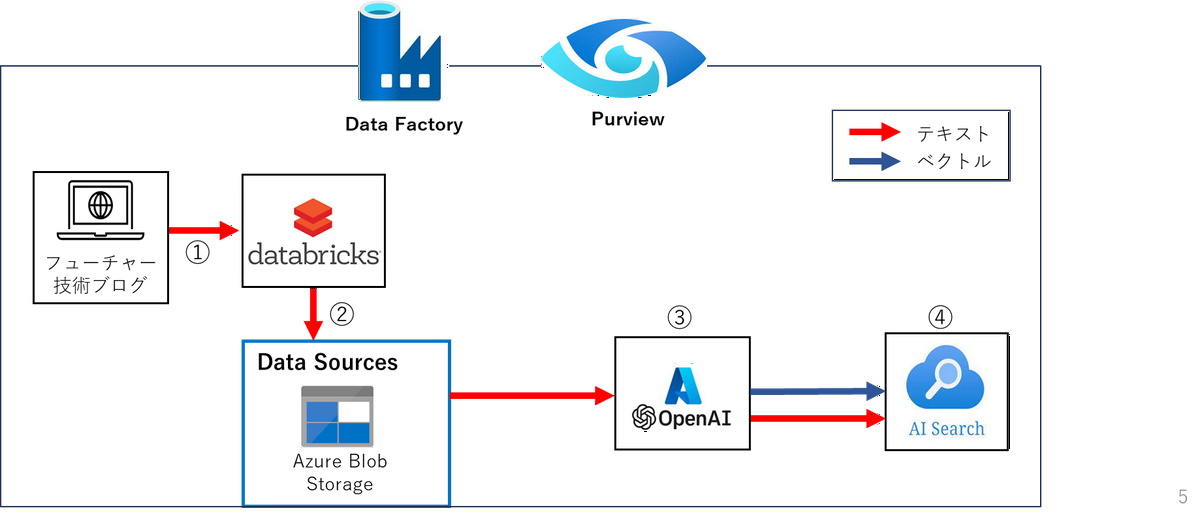
AI Searchインデックスに登録するパイプラインは以下のようになります。
1. フューチャー技術ブログからテキストデータを取得/保存
Databricksを用いて、フューチャー技術ブログの情報を取得し、Azure Blobストレージに保存します。
Azure Data FactoryのWebアクティビティを用いて、フューチャー技術ブログの情報を取得もできますが、Databricksを用いました。
2. テキストファイルからテキストデータを取得
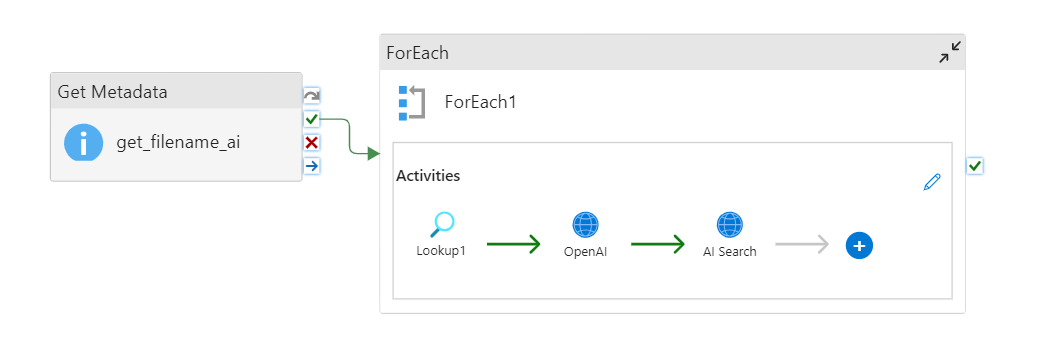
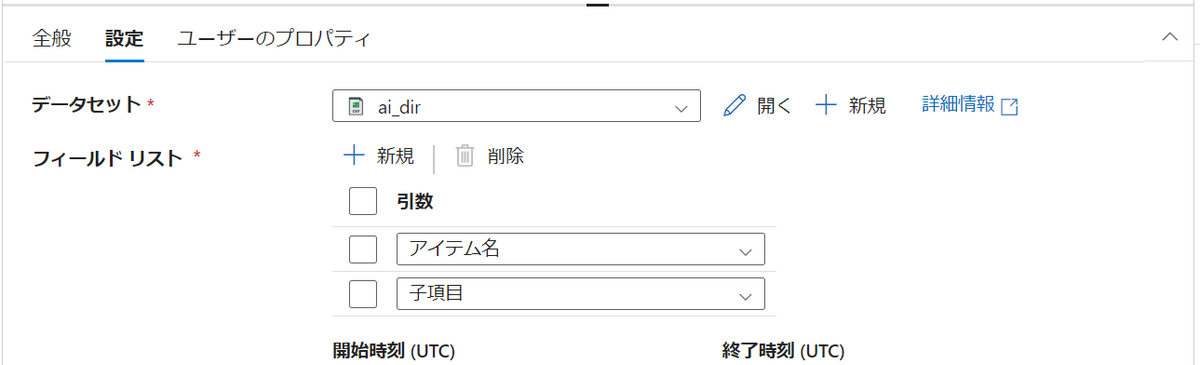
まず、「Get Metadata」アクティビティを用いて、ディレクトリ内のファイル名を配列として取得します。データセットを指定することで、そのデータセットに関する情報を取得できます。今回は以下の3つを取得します。
- アイテム名(ディレクトリ名)
- 子項目(ディレクトリ内の各ファイル情報)
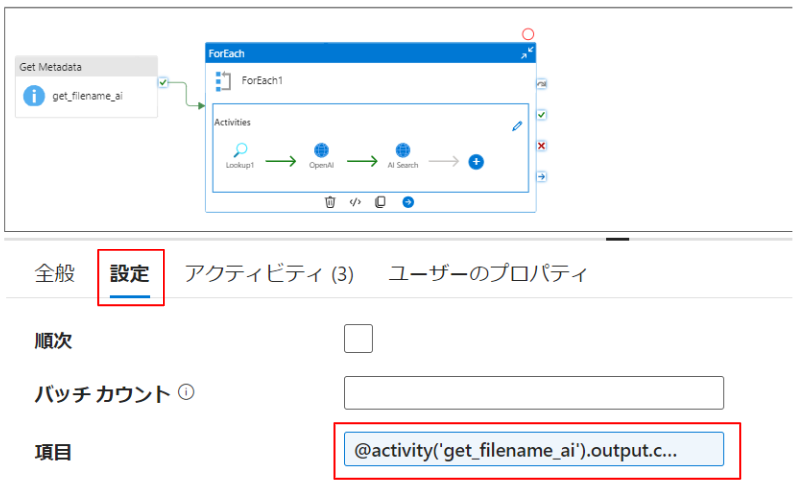
次に「ForEach」アクティビティを作成し、取得したファイル名それぞれに対して処理できるようにします。
「ForEach」アクティビティ→設定→項目に以下のように記載することで「ForEach」アクティビティ内で取得した配列を扱えるようになります。
@activity('「Get Metadata」アクティビティ名').output.childItems |
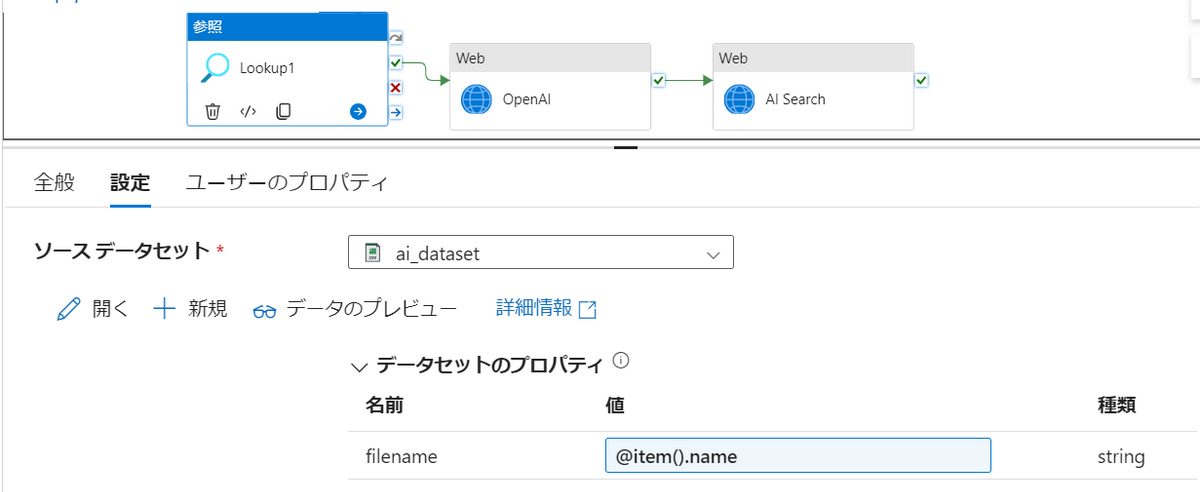
最後に、「ForEach」アクティビティ内に「参照」アクティビティを作成して、テキストデータを取得します。
ソースデータセットと値を下記のように設定します。
取得したテキストデータは@{activity(‘Lookup1’).output}という変数に格納されます。
3. Azure OpenAIでベクトル化
読み取った文章をAPI経由でAzure OpenAIに渡してベクトル化します。
「Web」アクティビティを作成:
- UIから指定すると動作が不安定な場合があるので、JSONを直接編集することをお勧めします
テキストのエンベディングモデルを作成:
- Azure OpenAIのリソースからエンベディングモデルをデプロイします
- 今回は
text-embedding-ada-002を使用します
URLの指定規則:
- 以下の形式に従います
https://<OpenAIのリソース名>.openai.azure.com/openai/deployments/<デプロイしたモデル名>/embeddings?api-version=<APIのバージョン>
inputにエンベディングしたい文章を指定:
- 作成した「Web」アクティビティのjsonのtypePropertiesの箇所を以下のように編集します
- 取得したテキストデータはbody→inputに設定されています
"typeProperties": {
"method": "POST",
"headers": {
"api-key": "YOUR API KEY",
"Content-Type": "application/json"
},
"url": "https://OpenAIのリソース名.openai.azure.com/openai/deployments/OpenAIの中でデプロイしたモデル名/embeddings?api-version=APIのバージョン",
"body": {
"input": "@{activity('<アクティビティ名>').output.firstRow.Prop_0}",
"model": "text-embedding-ada-002"
}
}
4. 文章、タイトル、ベクトル等をAzure AI Searchインデックスに登録
Azure OpenAIから作成したベクトルや、本文をAPIを経由してAzure AI Searchに保存します。
「Web」アクティビティを選択
- api-key、URL、本文を指定します
URLの指定規則
- 以下の形式に従います
https://Azure AI Searchのリソース名-free.search.windows.net/indexes/Azure AI Search内のインデックス名/docs/index?api-version=your api version
本文に登録したいデータを設定
Azure AI Searchのインデックスに登録したい情報を設定します。
今回は、ファイル名、id、文章、ベクトル化した文章を設定しました。idには記号を設定できないため、ファイル名から記号を取り除いたものを設定しています。任意に設定してください。"@search.action": "upload",
"file_name": "@{item().name}",
"id": "@{concat(base64(replace(replace(replace(replace(item().name, '/', '_'), '-', '_'), '.', '_'), ' ', '_')), '_', formatDateTime(utcNow(), 'yyyyMMddTHHmmssZ'))}",
"content": "@{activity('<アクティビティ名>').output.firstRow.Prop_0}",
"content_vec": "@{activity('<アクティビティ名>').output.data[0].embedding}"
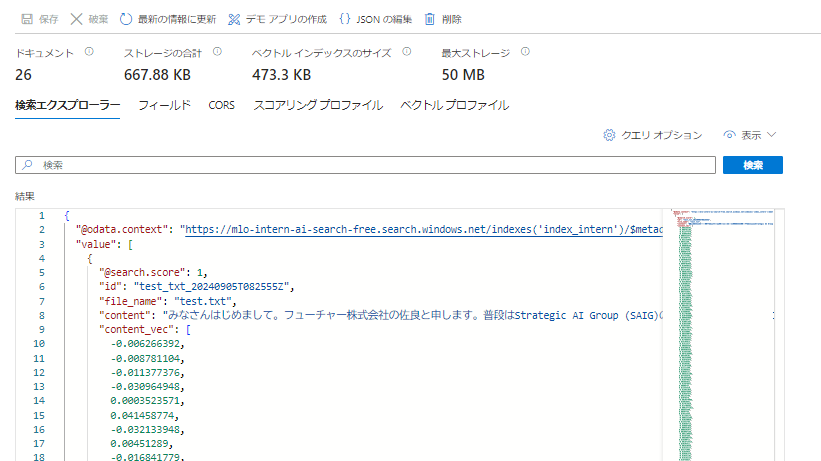
動作確認
Azure AI Searchのインデックスを見てみます。ファイル名や文章、ベクトルが正しく保存されていることがわかります。このインデックスを用いてRAGを実現できます。
Azure Purviewによるリネージ管理
Azure Purviewを用いたリネージ管理は今回実現できませんでした。考えられる原因は以下です。
- Azure PurviewがAzure AI Searchに対応していない
- APIで行った処理はAzure Purviewで追跡できない
解決策として、前処理を行った後のベクトル等のデータを一度どこかのストレージに保存することなどが考えられます。
まとめ
今回の検証では以下を行いました。
- Azure Data FactoryとAzure Purviewの利用手順の確認
- Azure Data Factoryを用いたデータ処理の自動化
- Azure Purviewを用いたリネージ管理
- テキストファイルからAzure AI Searchのインデックスに自動登録
また検証を通してそれぞれのツールに対して感じたことは以下です。
Azure Data Factory
- メリット
- 幅広いデータソースとの連携
- 作成したアクティビティの再利用
- 自動トリガーやアラート機能などの周辺機能
- デメリット
- アクティビティとして用意されていない処理を行いたい時に不便
Azure Purview
- メリット
- リネージ管理が便利
- データソースを跨いだ検索やタグ付けが優秀(未検証)
- デメリット
- 軽く導入するには費用が高い点
- Azure Data Factory側で、適切な設定をしないとリネージ管理されない点
展望
インターン期間の関係で検証しきれなかった点があるので記載いたします。
- Azure Data Factory内のwebアクティビティを用いて、Webサイトからテキストを抽出できるか
- Azure Data Factoryから、リンクサービスとしてAzure AI Searchに登録ができるか
- Azure Purviewを用いて、AI Searchインデックスのリネージ管理を実現できるか
またAzure Data FactoryとAzure Purview以外の検証事項について以下があります。
- Azure AI Searchのセマンティックランカー/ハイブリッド検索
- 適切なチャンク分けを行い、Azure AI Searchに登録
- Azure AI Searchの検索精度
感想
Engineer Campに参加させていただき、これまで触れてこなかったAzureサービスに初めて触れることができ、とても新鮮な体験となりました。普段プログラムを作成して行っている処理を、驚くほど簡単に実現できることに衝撃をうけ、クラウドサービスがこれほど流行している理由が理解できました。
また、1ヶ月のインターンを通じて、開発から発表まで一通りの業務を行う中で、相談の重要性やプレゼンテーションの構成方法、スモールスタートを意識した課題解決のアプローチなど、多くの貴重な学びを得ることができました。資料作成スキルなど、自身の課題も浮き彫りになり、成長すべき点を具体的に認識できたことも大きな収穫でした。
非常に有意義な時間を過ごさせていただき、ありがとうございました。