
春の入門祭り2025 16本目の記事です。
はじめに
はじめまして、フューチャーアーキテクト、製造エネルギー事業部の片岡です。
データ分析基盤の構築や運用において注目を集めている dbt (data build tool) の入門記事です。dbt を活用して、データ変換の一連の手順を示すことで、これから dbt を試してみようと考えている方の導入を支援できれば幸いです。
dbt とは
dbt (data build tool) は、dbt Labs, Inc. が提供するデータ変換ツールです。SQL をコンパイルして実行することで、データウェアハウスにテーブルやビューを作成できます。
dbt には以下の 2 種類のプロダクトがあります。
- dbt Cloud: Web ベースの UI を通じて、開発、テスト、スケジュール実行などを行うフルマネージドサービス
- dbt Core: コマンドラインを通じてインストール・管理するオープンソースツール
今回の記事では、dbt Core を利用します。
やりたいこと
- dbt を利用して、BigQuery に登録したデータの変換処理を実現します
- 具体的には、下記のサンプルで用意した店舗の売上データを、dbt を利用して分析してみようと思います
| 店舗 ID | 商品 ID | 売上日 | 売上個数 | 売上金額 | 顧客 ID |
|---|---|---|---|---|---|
| 1 | 1 | 2023/1/1 | 10 | 1000 | 1 |
| 1 | 2 | 2023/1/1 | 5 | 500 | 2 |
| 1 | 3 | 2023/1/2 | 20 | 2000 | 3 |
| 2 | 1 | 2023/1/1 | 15 | 1500 | 4 |
| 2 | 2 | 2023/1/1 | 10 | 1000 | 1 |
| 2 | 3 | 2023/1/2 | 30 | 3000 | 5 |
| 3 | 1 | 2023/1/1 | 2 | 200 | 6 |
| 3 | 2 | 2023/1/2 | 12 | 1200 | 7 |
| 3 | 3 | 2023/1/2 | 50 | 5000 | 8 |
環境構築
まずは、dbt を利用するために環境構築をします。
(公式の環境構築ガイドはこちらです)
前提条件
- Python 3.9 以上がインストールされていること
- Google Cloud のプロジェクトが作成されていること
- 今回は dbt に接続するプラットフォームとして、BigQuery を利用します
dbt を install する
pip コマンドを用いて、dbt Core と BigQuery アダプターをインストールします。
python -m pip install dbt-core dbt-bigquery |
dbt プロジェクトを作成する
dbt initコマンドを実行し、dbt プロジェクトフォルダを作成します。
今回は dbt_trial という名前のプロジェクトを作成します。
# dbt init <プロジェクト名> |
補足: プロジェクト名やデータベースの設定は、環境に合わせて適切に選択してください。
BigQuery に接続する
dbt プロジェクトが作成されると、~/.dbt/ディレクトリに profiles.yml が作成されます。このファイルに、dbt が BigQuery に接続するための認証情報などを記述します。
もし作成されていない場合は、~/.dbt/ディレクトリを作成し、下記のファイルをコピーしてください。
dbt_trial: |
注意: project にはご自身の GCP プロジェクト ID を、dataset には dbt でテーブルを作成する BigQuery のデータセット名を指定してください。location はデータセットのロケーションに合わせてください。
作成した dbt プロジェクトフォルダの直下でdbt debugコマンドを実行し、BigQuery への接続が正常に確立できるかを確認します。
dbt debug |
dbt のサンプルのモデルを作成してみる
作成した dbt プロジェクトには、初期状態ではシンプルなサンプルモデルが含まれています。以下のコマンドを実行して、このサンプルモデルが正常に実行できるか試してみましょう。
dbt run |
以下のように、サンプルのモデルが BigQuery 上に作成されたら、dbt の基本的な環境構築は完了です!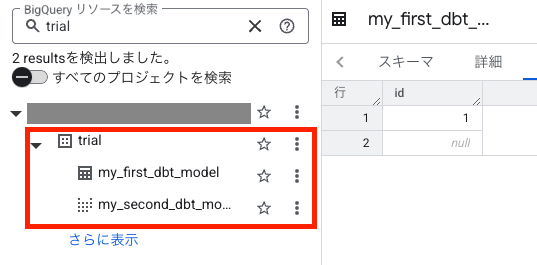
dbt を利用してデータ変換を実行してみる。
環境構築ができたので、早速データ変換を実施してみようと思います。
- 本記事では、売り上げデータの分析として、日付ごとの売上の合計を取得してみようと思います。
- 実装にあたり、dbt にはレイヤという考え方があり、レイヤの作成方針のベストプラクティスに倣ってデータ変換処理を実装していきます。
dbt のレイヤの考え方
dbt におけるレイヤは、データの変換プロセスを整理し、管理しやすくするための重要な概念です。以下のようなレイヤ構成がベストプラクティスとされています。
- Staging レイヤ: データソースからロードされた生データに対して、データ型を整えたり、カラム名を分かりやすいように変更するなど、最低限の変換を行います。このレイヤのモデルは、通常、データソースの構造を反映した形になります
- Intermediate レイヤ : staging レイヤのデータを基に、複数のテーブルを結合したり、ビジネスロジックに基づいた集計や計算を行ったりするなど、より複雑な変換を行います。このレイヤは、分析に必要な基本的なデータセットを準備する役割を担います。
- Mart レイヤ: Staging・Intermediate レイヤで準備されたデータセットを、特定の分析目的やレポート作成に合わせてさらに集計・加工し、最終的な分析に利用しやすい形に整理します。例えば、日次の売上集計、顧客ごとの購買履歴などがこのレイヤに作成されます。
下記のような手順でデータ変換を実施していきます。
- CSV で保存されている売上データを BigQuery に投入
- staging レイヤのモデルを作成
- mart レイヤにて日付ごとの売り上げを合計を取得するモデルを作成
CSV で保存されている売上データを BigQuery に投入
こちらは、データ変換ではないのですが、データ変換のもとなるデータを BiqQuery に投入する手順となります。
以下の CSV ファイルを、dbt プロジェクト内の dbt_trial/seeds/ ディレクトリ配下にコピー&ペーストします。
今回は sales.csv のみ利用します。
それ以外のデータはデータ分析用のサンプルデータとしてご利用ください。(生成 AI を利用して作成しております。)
sales.csv(店舗の売り上げデータ)
store_id,item_id,sales_date,sales_quantity,sales_amount,customer_id |
store.csv(店舗のマスタデータ)
store_id,store_name,address,latitude,longitude |
item.csv(商品のマスタデータ)
item_id,item_name,category,unit_price |
customer.csv(顧客のマスタデータ)
customer_id,customer_name,address,gender,date_of_birth |
作成した dbt プロジェクトの直下でdbt seedコマンドを実行して、これらの CSV データを BigQuery に投入します。dbt は seeds ディレクトリ内の CSV ファイルを BigQuery のテーブルとしてロードします。
dbt seed |
下記のようにテーブルが作成され、データがロードされていれば OK です。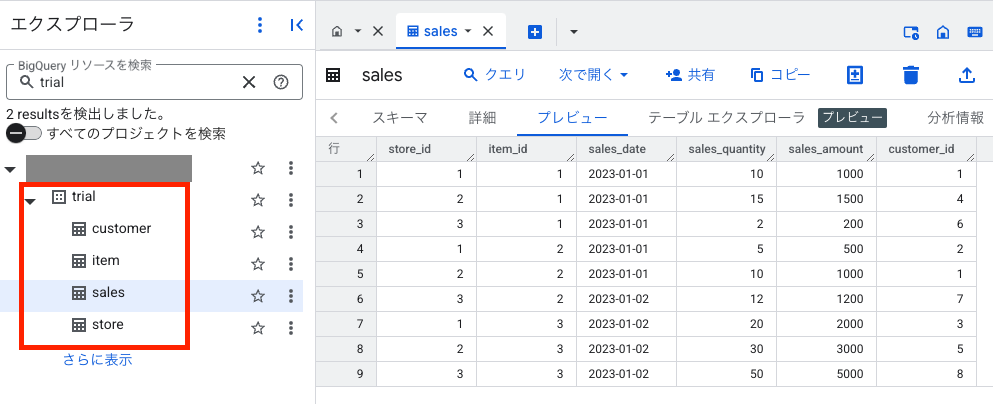
補足:dbt seed コマンドは、dbt プロジェクトの seeds ディレクトリに配置された CSV ファイルを、データウェアハウス(ここでは BigQuery)にテーブルとしてロードするためのコマンドです。主に、分析に必要な参照テーブルや、頻繁には変更されない比較的小さなデータセットを管理するのに適しています。
staging レイヤのモデルを作成する
- dbt_trial/models 直下に staging ディレクトリを作成します。
- 作成した staging ディレクトリ配下に、以下の 3 つのファイルを新規作成し、それぞれの内容をコピー&ペーストしてください。
- 本記事では、BigQuery に投入したデータソース(sales.csv)の内容を、そのまま staging レイヤのモデルとして利用します。
stg_sales.sql
{{ config(schema='staging') }} |
stg_sales.sql
version: 2 |
_stg__sources.yml
sources: |
dbt runコマンドを実行し、stg_sales を作成します。
dbt run --select "dbt_trial.staging.stg_sales" |
下記のような View テーブルが作成されます。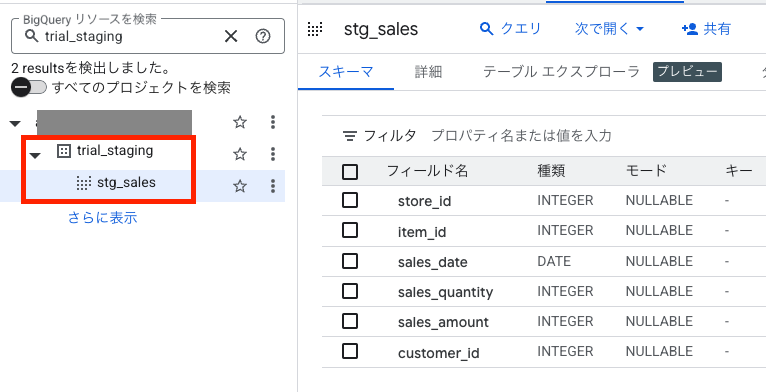
stg_sales.sql などの SQL ファイルには、データの抽出、変換、ロード(ETL の T と L)のロジックを記述し、対応する YAML ファイル(_stgmodels.yml、_stgsources.yml)には、モデルのメタ情報(説明、カラム定義、テストなど)やデータソースの定義を記述します。
mart レイヤのモデルを作成する
- 作成した dbt プロジェクトの models ディレクトリ内に、mart という名前のディレクトリを作成します。
- 作成した mart ディレクトリ配下に、以下の 2 つのファイルを新規作成し、それぞれの内容をコピー&ペーストしてください。
- mart_sales_amount_per_day では、stg_sales モデルを日付で集約し、日付毎の売り上げを取得するロジックを実装しています。
mart_sales_amount_per_day.sql
{{ config(schema='mart') }} |
_marts__models.yml
version: 2 |
dbt run コマンドを実行し、mart_sales_amount_per_day を作成する。
dbt run --select "dbt_trial.mart.mart_sales_amount_per_day" |
下記のような View テーブルが作成されます。
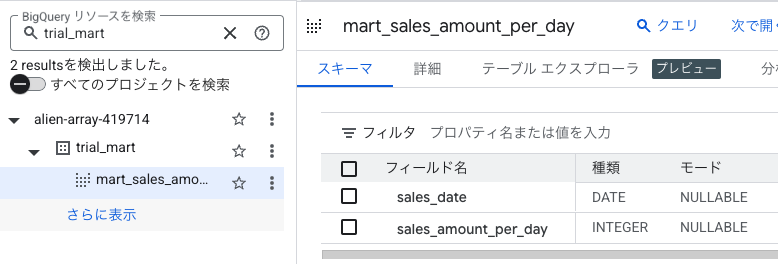
View テーブルの中身を確認すると、日付毎に集約された売上金額の合計が取得できていることがわかります。
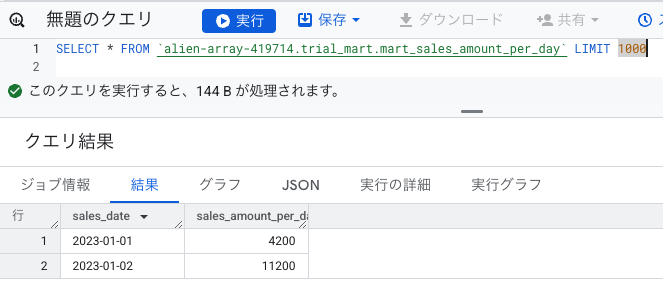
これにて、本記事でやりたいことが実現できました!
まとめ
今回の記事では、dbt Core を用いた簡単なデータ変換処理実装の流れを記載しました。
- dbt の環境構築から BigQuery への接続
- CSV データの BigQuery への投入 (dbt seed)
- staging レイヤと mart レイヤのモデル作成 (dbt run)
dbt に入門しようとしている人にとって、dbt に関するイメージを具体的にする助けとなれば幸いです!